通过注意力调节实现更好的文本到图像生成对齐
近年来,生成性AI技术在众多领域取得了前所未有的进步。大规模预训练模型的出现激发了各种下游任务中的新应用。这在文本到图像生成领域尤为明显,例如Stable Diffusion、DALL-E 2和Imagen等模型已经显著展示了它们的能力。尽管如此,复杂提示中包含多个实体和复杂属性时会出现挑战。生成的图像质量下降,导致实体泄露和属性不对齐等问题。目前,大多数最先进模型使用预训练的语言模型对提示进行编码,然后将文本嵌入集成到注意力模块中,其中高斯噪声扩散到最终生成的图像中。然而,最近的研究已经确定,与次优生成图像相关的许多问题与注意力机制的缺陷密切相关。
扩散模型在各种内容生成领域取得了显著的成功,其核心概念是通过输入提示引导的扩散过程,在潜在空间中从噪声迭代重建图像。现有的基于扩散的图像生成模型在大规模数据集上训练,并且与以前的方法相比,性能有了显著提高。然而,在处理复杂输入提示时,这些生成模型的保真度往往无法得到保证。最近,基于扩散的文本到视频模型Sora被公布,展示了在生成高保真度、长时间、高分辨率视频方面的强能力。实验结果在各种对齐场景中表明此模型以最小的额外计算成本实现了更好的图像-文本对齐。
方法
研究团队提出了一种创新的注意力控制机制,旨在改善文本到图像生成任务中的实体对齐和属性分配问题。这种方法不需要额外的训练过程,通过调整自注意力和交叉注意力模块来实现对生成模型的精细控制。
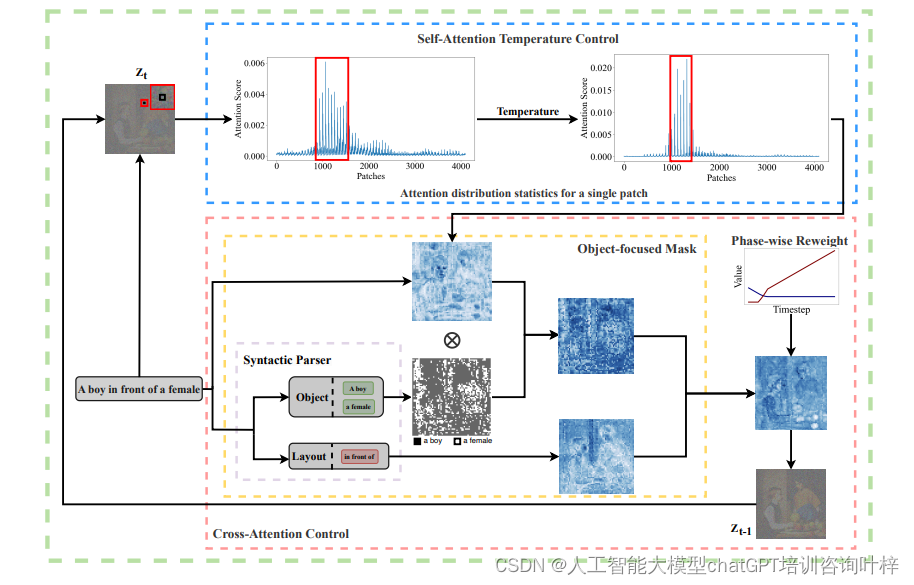
自注意力温度控制
自注意力温度控制是一种调整模型在生成图像时如何分配注意力的机制。在文本到图像的生成任务中,自注意力层允许模型的每个部分(或称为补丁)评估与其他部分的关系,从而确定在生成图像时如何相互影响。然而,如果没有适当的控制,补丁可能会对周围较大区域内的其他补丁产生高响应值,这可能导致生成的图像中对象的边界不清晰或对象特征混淆。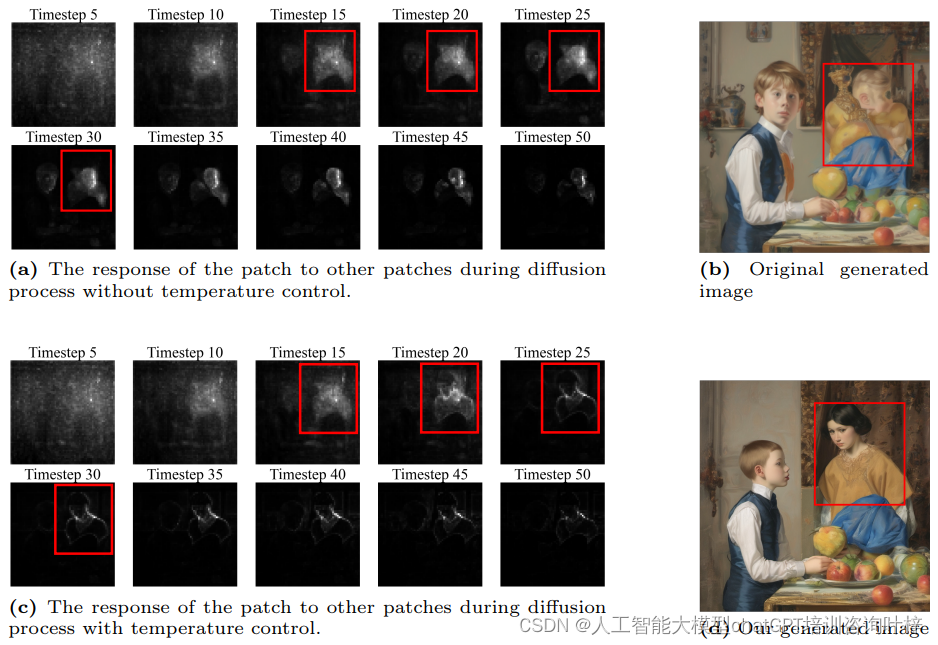
在图2中,自注意力温度控制的效果通过对比展示了。在没有温度控制的情况下(图2a),一个特定的补丁可能对多个其他补丁有较高的注意力值,这在自注意力图中表现为一个较广泛的高响应区域。这种广泛的注意力分布可能导致模型在生成图像时无法精确区分各个实体,比如无法明确区分“一个男孩”和“一个女孩”的边界,导致图像中出现实体融合或特征错误。
为了解决这个问题,研究者引入了温度控制机制(如图2c所示)。通过调整一个超参数τ,即温度,改变了自注意力层中softmax函数的尺度。温度控制的数学表达式如下:
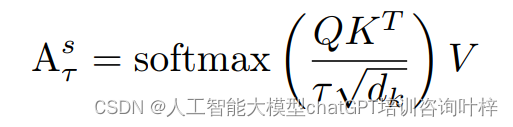
通过这种温度操作,增强了相关性较强的补丁之间的高注意力值,同时抑制了不相关补丁之间的低注意力值。这使得每个补丁能够与高度相关的补丁组合在一起,从而产生更加真实的轮廓。在图2c中,应用温度控制后,补丁只与周围较小区域内的补丁相对应,这有助于在最终生成的图像中构建正确的轮廓。需要注意的是,由于自注意力控制直接改变了补丁之间的关系,这种控制必须是精确和适度的;否则,它可能会影响到最终图像的整体内容。温度操作应用于扩散模型自注意力层的早期生成阶段。
对象聚焦的掩蔽机制
接下来,引入了一种对象聚焦的掩蔽机制来解决属性不对齐的问题。对象聚焦的掩蔽机制是为了提高文本到图像生成任务的准确性而设计的一种创新方法。这种方法特别针对于解决当文本提示中包含多个不同对象时,模型在生成图像的过程中可能出现的对象边界不清晰或对象特征混淆的问题。
在传统的生成模型中,由于补丁之间的注意力分布可能过于分散,导致生成的图像无法准确反映文本提示中的各个独立对象及其属性。为了克服这一难题,研究团队采用了句法解析技术来分析文本提示,识别出其中的所有实体和属性。这一步骤是基础,因为它帮助理解了文本提示的结构和语义内容。
基于句法解析的结果,研究团队为图像中的每个补丁指定了最有可能对应的实体组。在生成过程中,研究团队为每个补丁创建了一个掩蔽,这个掩蔽确保补丁只关注与它指定的实体组相关的信息。这意味着,如果一个补丁通过句法分析被确定与“一个男孩”这一实体相关,那么在生成过程中,这个补丁的注意力将主要集中于与“一个男孩”相关的特征,而不是其他不相关的对象或属性。
通过这种方式,研究团队有效地过滤了补丁需要处理的信息,减少了无关信息的干扰。这不仅提高了对象的边界清晰度,还减少了属性错误分配的风险。例如,如果文本提示中提到“一个戴帽子的年轻男孩”,我们的掩蔽机制将确保与“年轻男孩”相关的补丁不会错误地生成与“帽子”无关的特征,比如将帽子错误地分配给图像中的其他对象。
掩蔽机制还考虑了全局信息,如图像的布局和动作等。这意味着即使在关注特定实体的同时,模型也能够保持对整体场景的一致性和连贯性,从而生成结构合理、符合文本描述的图像。
对象聚焦的掩蔽机制通过精确控制补丁的注意力焦点,显著提升了模型对文本提示中多个对象和属性的处理能力,从而在生成图像时实现了更高的准确性和真实性。这种方法在处理复杂提示时尤其有效,能够生成更加细致和符合预期的图像结果。
阶段性动态重新加权机制
阶段性动态重新加权机制是为了进一步提升文本到图像生成任务中属性对齐的准确性而设计的一种策略。这种机制的核心思想是,在图像生成过程的不同阶段,模型应该关注不同类型的信息:在早期阶段关注全局信息,如整体布局;而在中后期则逐渐转移到对象的具体细节。
在扩散模型的早期阶段,图像的大体结构和布局是首先需要确定的。随着生成过程的进行,模型需要逐渐细化这些结构,填充具体的对象特征。为了适应这种阶段性的信息关注需求,研究团队设计了两种权重控制曲线:一种针对全局信息,另一种针对实例细节。
全局信息的权重控制曲线会随着时间步的增加而逐渐减小。这意味着在生成过程的早期,模型会更加关注文本提示中的全局信息,如场景的布局和整体结构。随着时间的推进,这种关注会逐渐减弱,为对象细节的生成让出空间。
相对地,实例细节的权重控制曲线则随着时间步的增加而逐渐增大。这确保了在生成过程的中后期,模型会更多地关注文本提示中的具体对象和它们的属性,如颜色、形状和大小等。这种权重的增加帮助模型在图像的细节层面上实现更高的准确性和丰富性。
通过这种动态的权重调整,模型能够在正确的时间关注正确的信息,从而在生成的图像中实现更好的实体和背景区分。这种机制使得生成的图像不仅在宏观上结构合理,也在微观上细节丰富,更贴近文本提示的描述。
在实际应用中,这种阶段性动态重新加权机制可以通过调整自注意力和交叉注意力层中的权重来实现。通过精心设计的权重控制曲线,模型在生成过程中的每一步都能够适应性地调整其关注焦点,确保生成的图像在不同阶段都能够与文本提示保持高度一致。
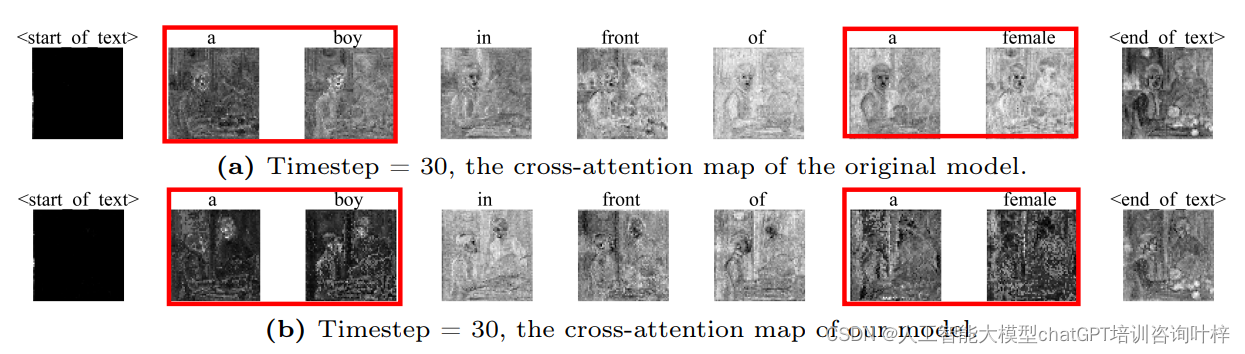
Fig. 3比较了原始模型与创新方法在时间步30时的交叉注意力图。给定的文本提示是“一个男孩在一个女孩前面”,通过这个例子,我们可以直观地看到两种方法在处理对象对齐方面的差异。
在原始模型中,扩散过程中的交叉注意力图,其中某些token(例如“男孩”和“女孩”)的语义信息在整个图像中扩散。这种扩散可能导致生成的图像中对象的界限模糊,对象特征混淆,最终导致对齐效果差。例如,如果“女孩”的语义信息扩散到了整个图像,模型可能无法确定女孩的具体位置,导致生成的图像中女孩的形象不清晰或者与背景或其他对象混合。
相比之下,对象聚焦掩蔽机制和阶段性动态重新加权机制后的交叉注意力图与实体相对应的token信息变得更加集中。这意味着每个对象的语义信息被更精确地定位在图像中的相应区域,从而改善了对象的对齐和整体图像的生成质量。
通过对象聚焦掩蔽机制,确保了每个补丁主要关注与它最相关的实体组,减少了与其他对象的无关信息的干扰。阶段性动态重新加权机制进一步确保了在生成过程的不同阶段,模型能够适当地关注全局信息和细节信息。在早期阶段,模型可能更关注于整体布局,而在后期阶段,则更多地关注于对象的具体特征。
实验
本研究中采用了无需训练的注意力控制机制,旨在改善文本到图像生成任务中的实体泄露和属性不对齐问题。使用了COCO2014验证集作为评估数据,并选取了最新的Stable Diffusion XL 1.0作为基线模型,与本模型进行比较。

定性分析 通过视觉检查生成图像与文本提示的对齐程度。如图5所示,展示了Stable Diffusion、Structured Diffusion以及创新方法的生成结果。可以观察到,现有模型在处理涉及多个对象和属性的复杂提示时仍然存在挑战。例如,在数字对齐方面,现有模型常常无法准确复现提示中指定的数量,如在图5的第一和第四列中,与提示相比,生成的长颈鹿和鸟的数量明显过多。而本方法能够减少这类数值错误的发生,如图5的(i)(l)所示。
定量分析 使用FID(Fréchet Inception Distance)、CLIP Score和ImageReward等指标来评估生成图像的质量。FID用于衡量生成图像与真实图像之间的分布差异,CLIP Score基于CLIP模型评估图像与文本的一致性,而ImageReward则是学习并评估人类对生成图像的偏好。实验结果表明,本模型在这些指标上都取得了更好的成绩,表明生成的图像与输入提示的对齐度更高,图像质量也更优。
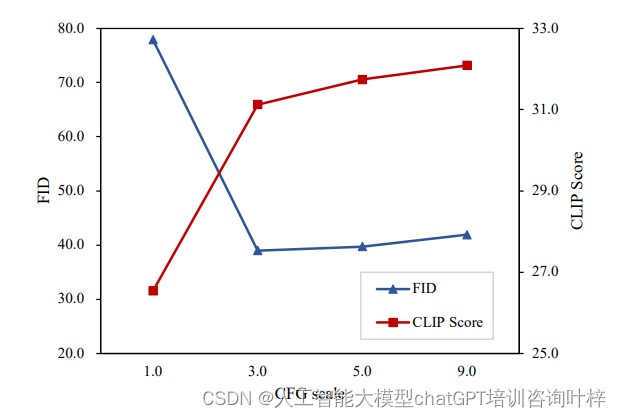
在Fig. 6中,我们可以看到随着CFG规模的增加,FID和CLIP分数如何变化。FID分数衡量的是生成图像与真实图像分布之间的差异,而CLIP分数则衡量生成图像与输入文本提示的一致性。理想情况下,我们希望FID分数越低越好,CLIP分数越高越好,这表示生成图像不仅与真实图像相似,而且与输入的文本提示也高度一致。
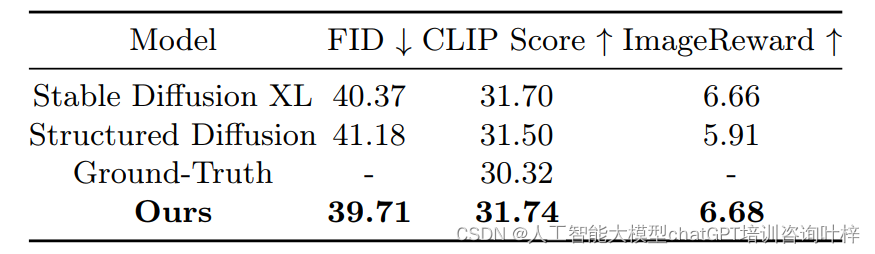
Table 1提供了创新方法与现有方法在定量评估上的比较结果,包括FID、CLIP Score和ImageReward三个指标。本方法在这些指标上与Stable Diffusion XL和Structured Diffusion进行了对比,这些指标共同衡量了生成图像的质量与输入文本提示的对齐程度。
具体来说,FID分数衡量生成图像与真实图像集合之间的分布差异,分数越低表示生成图像与真实图像越相似。CLIP Score评估生成图像与文本描述的匹配度,分数越高表示匹配度越好。ImageReward则是基于人类偏好的学习评估指标。
在Table 1中,我们可以看到,与Stable Diffusion XL和Structured Diffusion相比,本方法在FID分数上略高,但与真实图像(Ground-Truth)相比仍具有竞争力,这表明本模型在图像质量上有所提升。在CLIP Score上,本方法与Stable Diffusion XL得分相近,均高于Structured Diffusion,显示出在图像与文本对齐方面的优势。这些结果证明了本方法在改善文本到图像生成任务中的有效性,尤其是在提升图像质量和文本对齐方面。
半人工评估 除了定量指标,还设计了半人工评估来更细致地考察模型在特定对齐任务上的表现。随机选取了50个提示,并使用基线模型和我们的模型生成图像。然后,利用GPT-4生成与这些图像相关的一系列问题,从不同角度评估图像的对齐性能,包括颜色、内容、数量、表面/纹理、时间和位置对齐。通过人工检查这些问题,发现本模型在所有对齐任务上都取得了优于基线模型的结果。
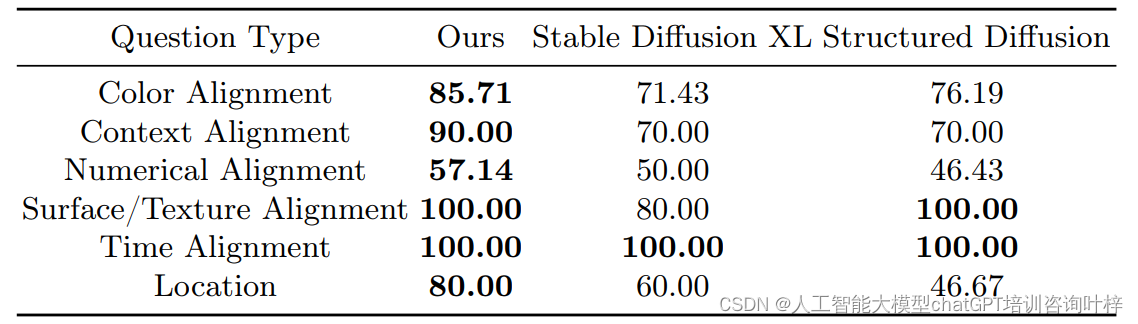
Table 2在论文中展示了半人工评估的结果,这些结果是基于GPT-4生成的问题对不同模型生成的图像进行评估的准确性。在这个表中,研究人员手动检查并修订了基于GPT-4答案的比较结果,以确定每种模型在各种对齐任务上的表现。
具体来说,Table 2列出了以下几种类型的对齐任务,并为每种任务提供了不同模型的性能百分比(准确率):
- 颜色对齐(Color Alignment):评估图像中指定对象的颜色是否与文本提示中的颜色准确生成。
- 内容对齐(Context Alignment):检查图像中的场景、对象和角色动作是否与文本提示一致。
- 数量对齐(Numerical Alignment):验证图像是否准确地表示了文本提示中指定的不同对象的数量。
- 表面/纹理对齐(Surface/Texture Alignment):判断生成的对象是否具有与文本提示描述一致的纹理。
- 时间对齐(Time Alignment):确认图像中呈现的环境时间是否与文本提示中描述的时间相匹配。
- 位置对齐(Location):评估图像中生成的环境设置和空间关系是否与文本提示一致。
表中列出了几种模型的名称,包括基线模型(如Stable Diffusion XL和Structured Diffusion)和本模型(即采用新提出的注意力控制机制的模型)。每种模型在上述任务上的表现会以百分比形式展示,百分比越高,表示模型在该对齐任务上的准确率越高,生成的图像与文本提示的一致性越好。
消融研究 通过消融研究深入探讨了自注意力控制策略、对象聚焦掩蔽机制和动态重新加权策略这三种组件对模型性能的影响。
研究团队首先单独测试了自注意力控制策略。这一策略通过调整自注意力层中的温度参数,优化了补丁间的注意力分布。结果显示,即使只使用这一策略,模型的FID和CLIP Score也比基线模型有所改善,这表明自注意力控制在提升图像质量和文本对齐方面起到了积极作用。
接着,单独评估了对象聚焦掩蔽机制。这一机制通过句法解析确定文本提示中的实体,并为每个补丁创建掩蔽,以集中注意力于相关实体。消融研究的结果显示,对象聚焦掩蔽机制同样在单独使用时提升了模型性能,减少了属性不对齐和实体泄露的问题。
当单独应用动态重新加权策略时,效果并不理想。动态重新加权策略根据生成过程的不同阶段调整不同语义组成部分的权重。在没有掩蔽机制配合的情况下,这一策略可能会无意中增强了不必要的注意力分布,导致生成效果不佳。
当将这三个组件结合起来使用时,模型的性能得到了显著提升。这表明这些组件之间存在互补关系,通过协同作用,能够有效地提升模型的整体性能。结合使用时,自注意力控制和对象聚焦掩蔽机制能够确保注意力的准确分配,而动态重新加权策略则在这一基础上进一步优化了不同阶段的注意力重点。
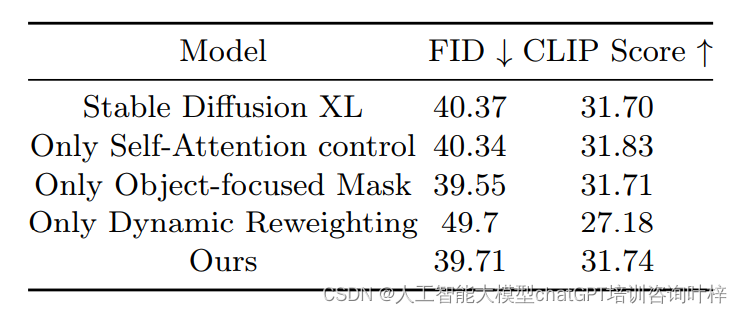
以上表格展示了不同配置下的FID和CLIP Score,清晰地呈现了每种组件以及它们组合使用时对模型性能的具体影响。
结论
在本文中,我们提出了一种无需训练的阶段性注意力控制机制。我们在自注意力模块中集成了新颖的温度控制,并在交叉注意力模块中进行了阶段特定的掩蔽控制。这些注意力控制使模型能够更有效地将图像补丁塑造成连贯的对象,并显著缓解实体融合和不对齐的问题。在我们的实验中,我们使用现有的基准指标和针对不同对齐场景量身定制的半人工评估来评估我们的模型。实验结果证明了我们的模型在对齐聚焦的图像生成任务中的鲁棒性和有效性。
相关文章:
通过注意力调节实现更好的文本到图像生成对齐
近年来,生成性AI技术在众多领域取得了前所未有的进步。大规模预训练模型的出现激发了各种下游任务中的新应用。这在文本到图像生成领域尤为明显,例如Stable Diffusion、DALL-E 2和Imagen等模型已经显著展示了它们的能力。尽管如此,复杂提示中…...

Java开发大厂面试第26讲:生产环境如何排查问题和优化 JVM?
通过前面几个课时的学习,相信你对 JVM 的理论及实践等相关知识有了一个大体的印象。而本课时将重点讲解 JVM 的排查与优化,这样就会对 JVM 的知识点有一个完整的认识,从而可以更好地应用于实际工作或者面试了。 我们本课时的面试题是&#x…...

计算机科学的先驱者们
1. 艾伦图灵(Alan Turing): 图灵是计算机科学和人工智能的先驱之一,他提出了“图灵机”的概念,这是一种理论上的计算模型,奠定了现代计算机理论的基础。在第二次世界大战期间,图灵领导了一个团…...

哈希双指针
文章目录 一、哈希1.1两数之和1.2字母异位词分组1.3最长子序列 二、双指针2.1[移动零](https://leetcode.cn/problems/move-zeroes/description/?envTypestudy-plan-v2&envIdtop-100-liked)2.2[盛最多水的容器](https://leetcode.cn/problems/container-with-most-water/d…...
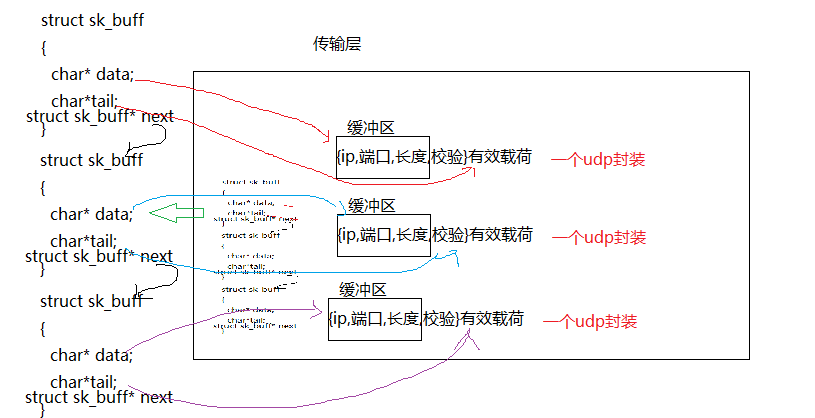
【网络】UDP协议
应用层协议是请求与响应服务,客户端的请求与服务器的响应是通过应用层传输到网络中的,但再实际上,应用层并不能直接通信,需要将数据进行报头的封装,向下层交付,贯穿整个协议栈。我们已经谈到应用层协议负责…...

牛马真的沉默了,入职第一天就干活
入职第一天就干活的,就问还有谁,搬来一台N手电脑,第一分钟开机,第二分钟派活,第三分钟干活,巴适。。。。。。 打开代码发现问题不断 读取配置文件居然读取两个配置文件,一个读一点,…...

解决在cmd里下载的库,但IDLE还是显示不存在的问题
原因一: 环境变量配置 首先,你需要确认你安装库的时候使用的Python环境是否和IDLE使用的Python环境是同一个。如果cmd中你使用的是系统路径下的Python,而IDLE使用的是另一个路径下的Python,那么你在cmd中下载的库,IDL…...

嵌入式全栈开发学习笔记---C语言笔试复习大全23
目录 联合体 联合体的定义 联合体的长度 如果来判断设备的字节序? 如何把大端数据转换成小端数据? 枚举 枚举的定义 上一篇复习了结构体,这一节复习联合体和枚举。 说明:我们学过单片机的一般都是有C语言基础的了ÿ…...

C++函数指针,键值对集合的学习
这段代码使用了 std::unordered_map 来存储 std::wstring 作为键(key),而对应的值(value)是一个 std::function<void(std::array<int, 5>, SomeClass&, int)> 类型的函数指针。这个结构使得根据字符串…...
新人攻略:避开这3大坑,让老员工主动带你飞!
进入职场的新人们,常常会感到困惑和挑战。他们可能会发现自己在与老员工的交流中遇到难题,甚至发现老员工并不愿意花费时间和精力去指导他们。这背后的原因是什么呢?又该如何改善这一现象呢?本文将从新员工的角度出发,…...

汽车液态电池隔膜的作用
标签: 汽车液态电池隔膜的作用; 聚乙烯(PE);聚丙烯(PP) 问题:汽车液态电池隔膜的作用? 汽车液态电池隔膜的作用 汽车液态电池中的隔膜是一个至关重要的组件,它在电池的性能、安全性和寿命方面起着关键作用。下面详细讲述隔膜的主要功能和作用: 1. 电化学隔离 隔…...

汽车液态电池充电时,充电时的化学反应是怎样的? 电池电量是怎么充满的?
标签: 汽车液态电池充电时的化学反应; 电池充电过程;锂电池,石墨负极 问题:汽车液态电池充电时,充电时的化学反应是怎样的? 电池电量是怎么充满的? 汽车液态电池充电时的化学反应 汽车液态电池(如锂离子电池)在充电时,通过电化学反应将电能转化为化学能并储存在电…...
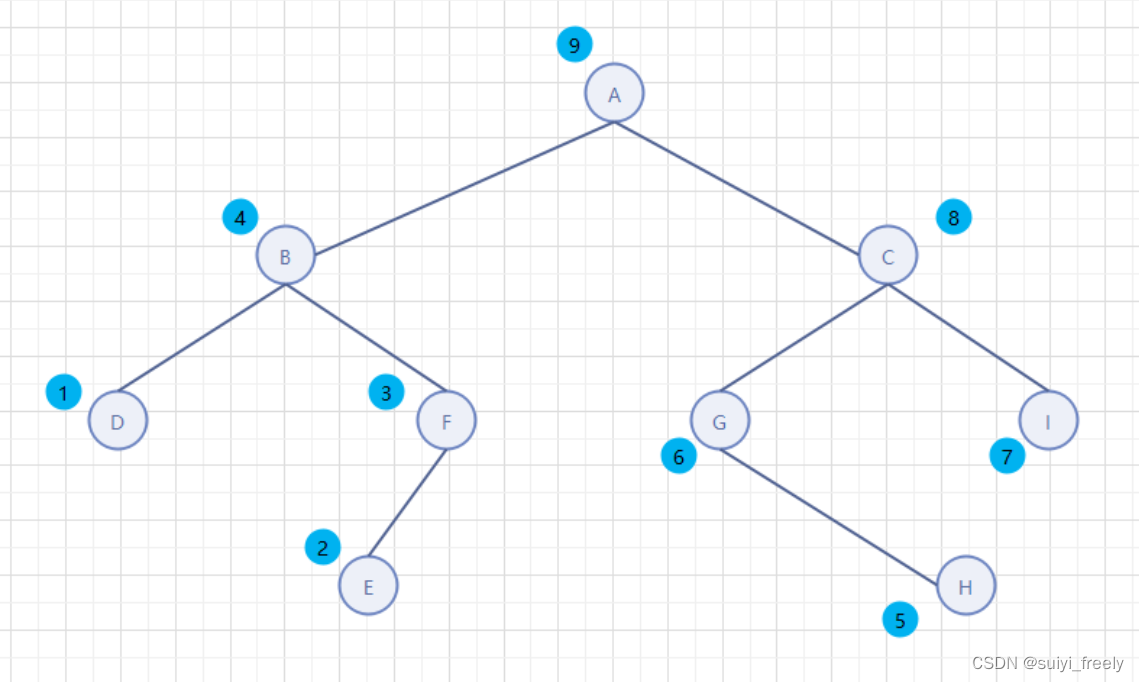
Topk问题以及二叉树的三种层序遍历和基本操作
一、Topk问题 1、问题描述 TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。 比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。 2、思路 对于Top-K问题,能想到的最简单直接的…...

深度学习设计模式之桥接模式
文章目录 前言一、介绍二、详细分析1.核心组成2.实现步骤3.代码示例4.优缺点优点缺点 5.使用场景 总结 前言 桥接模式是将抽象部分与实现部分分离,使它们都可以独立的变化。 一、介绍 桥接模式是结构型设计模式,主要是将抽象部分与实现部分分离&#x…...
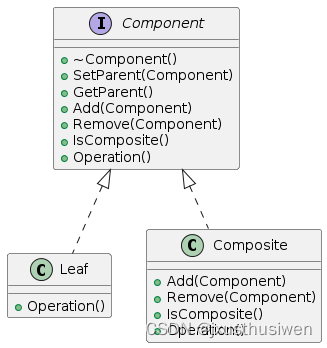
设计模式 17 组合模式 Composite Pattern
设计模式 17 组合模式 Composite Pattern 1.定义 组合模式(Composite Pattern),又叫部分整体模式,是用于把一组相似的对象当作一个单一的对象。组合模式依据树形结构来组合对象,用来表示部分以及整体层次。这种类型的设…...

【经典论文阅读10】MNS采样——召回双塔模型的最佳拍档
这篇发表于2020 WWW 上的会议论文,提出一种MNS方式的负样本采样方法。众所周知,MF方法难以解决冷启动问题,于是进化出双塔模型,但是以双塔模型为基础的召回模型的好坏十分依赖负样本的选取。为了解决Batch内负样本带来的选择性偏差…...
介绍)
串行低功耗芯片间媒体总线(SLIMbus)介绍
文章目录 SLIMbus简介slimbus设备和设备类Manager DeviceFramer DeviceInterface DeviceGeneric Device (Function)SLIMbus组件简单的SLIMbus组件复杂的SLIMbus组件SLIMbus的DATA和CLKSLIMbus的Clock Frequencies和GearsCells, Slots, Subframes, Frames, and...

esp32-S3 使用自带的大模型,实现本地文字转语言tts
目录 CMakeLists.txt文件中: 初始化以及实际运用代码: 在partitions.csv 内存分配文件中,添加voice_data项...
)
Redis事务(1)
什么是事务? Redis 的事务和 MySQL 的事务概念上是类似的. 都是把⼀系列操作绑定成⼀组. 让这⼀组能够批量执行。 但是注意体会 Redis 的事务和 MySQL 事务的区别: 弱化的原⼦性: redis 没有 “回滚机制”. 只能做到这些操作 “批量执⾏”. 不能做到 “⼀个失败就…...
等级考试试卷(四级))
202206青少年软件编程(Python)等级考试试卷(四级)
第 1 题 【单选题】 有如下 Python 程序, 包含 lambda 函数, 运行该程序后, 输出的结果是? ( ) g = lambda x,y:x*yprint(g(2,3))A :2 B :3 C :6 D :8 正确答案:C 试题解析: g = lambda x, y: x*y, lambda 函数返回参数 x 和 y 的积, 因此选 C。 第 2 题 【单选…...

无机布防火卷帘门价格怎么算?按尺寸定制,按需报价
无机布防火卷帘门作为建筑防火分区的核心设备,价格一直是工程采购的关注重点。很多用户在询价时,会发现不同厂家的报价差异较大,这是因为无机布防火卷帘门的价格并非按统一单价计算,而是完全根据项目的实际需求定制化核算。 &…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

翻译 GDB 官方文档
翻译 GDB 官方文档项目地址官方文档地址下载源码包编译html运行翻译程序项目地址 https://github.com/shootercheng/gdb-translate.git 项目结构 $ tree -L 1 . ├── cmd ├── go.mod ├── input ├── internal ├── LICENSE ├── output ├── README.md ├─…...

Burp Suite拦截与替换机制深度解析:从协议层到规则链
1. 这不是“点开就能用”的功能,而是你和目标系统之间的一道可编程闸门很多人第一次在Burp Suite里点开Proxy → Intercept,看到HTTP请求被拦下来,兴奋地改个User-Agent、删个Cookie就点Forward,以为自己已经掌握了“拦截与替换”…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...

从RD、CS到WK:一文讲透SAR主流成像算法的演进与选型实战
从RD、CS到WK:SAR成像算法选型实战指南 当无人机掠过灾区上空,或卫星扫描地球表面时,合成孔径雷达(SAR)正通过电磁波穿透云层和黑暗,将地面信息转化为高分辨率图像。而决定图像质量的关键,在于工…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...

网飞成立 AI 动画工作室,开启流媒体“原生 AI 制片时代”,中外布局逻辑有何不同?
1. Netflix“偷跑”在影视巨头关于 AIGC 的军备竞赛中,Netflix 再次加速。据外媒 TheVerge 报道,网飞于今年 3 月成立了名为 "INKubator" 的工作室,这是全球流媒体巨头中首个以生成式人工智能为核心的动画制作部门。此动作引发全球…...

从‘找不到dll’到流畅运行:一份给VS2022新手的Zbar+OpenCV3.6.0环境配置避坑指南
从“找不到dll”到流畅运行:VS2022下ZbarOpenCV3.6.0环境配置全解析 当你第一次在Visual Studio 2022中尝试整合Zbar和OpenCV 3.6.0时,可能会遇到各种令人沮丧的错误提示。最常见的就是那个让人头疼的“找不到libzbar64-0.dll”问题。本文将带你一步步解…...

Safe Exam Browser 虚拟化检测绕过技术深度实践
Safe Exam Browser 虚拟化检测绕过技术深度实践 【免费下载链接】safe-exam-browser-bypass A VM and display detection bypass for SEB. 项目地址: https://gitcode.com/gh_mirrors/sa/safe-exam-browser-bypass 在现代教育技术领域,Safe Exam Browser&…...