AI大模型探索之路-实战篇7:Function Calling技术实战:自动生成函数
系列篇章💥
AI大模型探索之路-实战篇4:深入DB-GPT数据应用开发框架调研
AI大模型探索之路-实战篇5:探索Open Interpreter开放代码解释器调研
AI大模型探索之路-实战篇6:掌握Function Calling的详细流程
目录
- 系列篇章💥
- 一、前言
- 二、Function Calling函数封装
- 1、定义客户端
- 2、API调用测试
- 3、定义函数
- 4、定义参数数据格式
- 5、定义一个标准的funcation call函数
- 6、取出注释说明信息
- 7、生成JSON Schema对象
- 8、清理返回对象的特殊字符
- 9、转换为JSON格式
- 10、查看悟空函数信息
- 11、调用API生成JSON格式函数信息
- 12、输出原始函数对比
- 三、定义自动输出function 参数的函数
- 1、自动输出funcation的函数
- 2、自动生成funcation函数调用测试
- 3、定义参数数据
- 4、调用API测试
- 5、定义第二个函数
- 6、两个函数生成测试
- 7、两个工具函数一起调用API测试
- 四、结语
一、前言
继前文对Function Calling操作流程的详细回顾之后,本文将进一步探讨OpenAI的Function Calling技术在实际应用中的表现。通过利用大型模型的强大能力自动生成function函数,我们旨在提升代码的通用性与扩展性。这一深入分析的核心目标是为智能数据分析平台的顺利部署打下坚实的技术基础。
这种基于人工智能的Function Calling技术探索是未来软件开发和维护领域的重要发展方向,它不仅能提高开发效率,还能大幅降低维护成本,提高软件的适应性和灵活性。通过本文的深入分析,我们希望为读者提供更全面的了解和应用视角,促进技术的进一步发展和应用。
二、Function Calling函数封装
在本章节中,我们将继续深入探索大模型自动生成function函数的全过程。此技术不仅体现了人工智能领域的前沿进展,还具有实际应用的重要可行性。我们将通过具体的步骤和实践案例,分析这一技术的具体工作原理及其在实际应用中的执行效果。
1)获取函数的注释说明
首先,为了有效利用大模型生成function函数,我们需要从已有的代码中获取目标函数的注释说明。这些注释将提供函数的目的、输入参数以及预期输出等关键信息。精确而详尽的注释是确保大模型能正确理解并生成符合需求的函数定义的前提。
2)将注释说明提供给大模型,由大模型生成相应的JSON Schema
获得注释后,我们将其提供给大模型。模型将根据这些注释自动生成一个对应的JSON Schema。这一步骤是自动化过程中的关键,因为它直接关系到最终生成的function函数是否能满足实际的业务需求。
3) 对大模型生成的JSON Schema进行检查和补充
虽然大模型能够根据注释生成JSON Schema,但手动检查和补充这一环节仍然不可或缺。我们需确保生成的JSON Schema与手工创建的完全一致,包括所有细节和特定条件。这一过程可能需要开发者与模型之间的多次迭代,直到达到最优的输出结果。
通过这一系列的步骤,我们将能够有效地利用大模型自动生成function函数,从而提升开发效率并减少人为错误。
1、定义客户端
import openai
import os
import numpy as np
import pandas as pd
import json
import io
from openai import OpenAI
#获取API KEY
openai.api_key = os.getenv("OPENAI_API_KEY")
#创建客户端
client = OpenAI(api_key=openai.api_key)
2、API调用测试
response = client.chat.completions.create(#model="gpt-4-0613",model="gpt-3.5-turbo",# 这里最好使用gpt4messages=[{"role": "user", "content": "什么是JSON Schema?"}]
)response.choices[0].message.content
输出:
'JSON Schema是一种用于描述和验证JSON数据结构的规范。它定义了数据的类型、格式、约束和关系,使得可以对JSON数据进行验证和验证。通过JSON Schema,开发人员可以确保数据的完整性、准确性和一致性,以及在不同应用程序和平台之间的数据交换的有效性。JSON Schema可以被用来验证输入数据、生成文档和测试数据等各种用途。'
3、定义函数
def sunwukong_function(data):"""孙悟空算法函数,该函数定义了数据集计算过程:param data: 必要参数,表示带入计算的数据表,用字符串进行表示:return:sunwukong_function函数计算后的结果,返回结果为表示为JSON格式的Dataframe类型对象"""data = io.StringIO(data)df_new = pd.read_csv(data, sep='\s+', index_col=0)res = df_new * 10return json.dumps(res.to_string())
4、定义参数数据格式
# 创建一个DataFrame
df = pd.DataFrame({'x1':[1, 2], 'x2':[3, 4]})df_str = df.to_string()data = io.StringIO(df_str)df_new = pd.read_csv(data, sep='\s+', index_col=0)
5、定义一个标准的funcation call函数
# 定义工具函数
sunwukong={"type": "function","function": {"name": "sunwukong_function","description": "用于执行孙悟空算法函数,定义了一种特殊的数据集计算过程","parameters": {"type": "object","properties": {"data": {"type": "string","description": "执行孙悟空算法的数据集"},},"required": ["data"],},}}#将函数放入工具列表
tools = [sunwukong]#定义工具函数字典
available_tools = {"sunwukong_function": sunwukong_function,
}
6、取出注释说明信息
import inspect
# 取出注释信息
print(inspect.getdoc(sunwukong_function))
输出:
孙悟空算法函数,该函数定义了数据集计算过程
:param data: 必要参数,表示带入计算的数据表,用字符串进行表示
:return:sunwukong_function函数计算后的结果,返回结果为表示为JSON格式的Dataframe类型对象
7、生成JSON Schema对象
取出注释信息,调用大模型API生成JSON Schema对象
function_description = inspect.getdoc(sunwukong_function)
response = client.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "system", "content": "以下是孙悟空函数的函数说明:%s" % function_description},{"role": "user", "content": "请帮我编写一个JSON Schema对象,用于说明孙悟空函数的参数输入规范。输出结果要求是JSON Schema格式的JONS类型对象,不需要任何前后修饰语句。"}]
)
# 使用gpt3.5发现有时候生成正确,但是有时候生成的json信息还是有些缺少,gpt.4会更稳定
response.choices[0].message.content
输出:

8、清理返回对象的特殊字符
# 将变量 response.choices[0].message.content 中的字符串中的 "" 和 "json" 替换为空字符串
r=response.choices[0].message.content.replace("```","").replace("json","")
9、转换为JSON格式
json.loads(r)
输出:
{'type': 'object','required': ['data'],'properties': {'data': {'type': 'string','description': 'Represents the data table to be calculated'}}}
10、查看悟空函数信息
# 打印悟空函数的json格式,与上面模型生成的json对比
sunwukong
输出:
{'type': 'function','function': {'name': 'sunwukong_function','description': '用于执行孙悟空算法函数,定义了一种特殊的数据集计算过程','parameters': {'type': 'object','properties': {'data': {'type': 'string', 'description': '执行孙悟空算法的数据集'}},'required': ['data']}}}
#打印参数信息
sunwukong['function']['parameters']
输出:
{'type': 'object','properties': {'data': {'type': 'string', 'description': '执行孙悟空算法的数据集'}},'required': ['data']}
11、调用API生成JSON格式函数信息
system_prompt = '以下是某的函数说明:%s' % function_description
user_prompt = '根据这个函数的函数说明,请帮我创建一个JSON格式的字典,这个字典有如下5点要求:\1.字典总共有三个键值对;\2.第一个键值对的Key是字符串name,value是该函数的名字:%s,也是字符串;\3.第二个键值对的Key是字符串description,value是该函数的函数的功能说明,也是字符串;\4.第三个键值对的Key是字符串parameters,value是一个JSON Schema对象,用于说明该函数的参数输入规范。\5.输出结果必须是一个JSON格式的字典,且不需要任何前后修饰语句' % function_name
response = client.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": user_prompt}]
)
response.choices[0].message.content
输出:

清理特殊字符后,转化JSON格式输出
json_function_description=json.loads(response.choices[0].message.content.replace("```","").replace("json",""))
json_function_description
输出:
{'name': 'sunwukong_function','description': '孙悟空算法函数,该函数定义了数据集计算过程','parameters': {'type': 'object','properties': {'data': {'type': 'string','description': '必要参数,表示带入计算的数据表,用字符串进行表示'}},'required': ['data']}}
12、输出原始函数对比
# 输出悟空函数,和生成的函数信息对比
sunwukong
输出:
{'type': 'function','function': {'name': 'sunwukong_function','description': '用于执行孙悟空算法函数,定义了一种特殊的数据集计算过程','parameters': {'type': 'object','properties': {'data': {'type': 'string', 'description': '执行孙悟空算法的数据集'}},'required': ['data']}}}
补充缺少的部分信息
# 补充缺少的部分信息
json_str={"type": "function","function":json_function_description}
json_str
输出:
{'type': 'function','function': {'name': 'sunwukong_function','description': '孙悟空算法函数,该函数定义了数据集计算过程','parameters': {'type': 'object','properties': {'data': {'type': 'string','description': '必要参数,表示带入计算的数据表,用字符串进行表示'}},'required': ['data']}}}
再次输出悟空函数,进行对比,基本上已经一摸一样了
三、定义自动输出function 参数的函数
继前文的探讨和实验验证了利用大模型自动生成function参数的函数的可行性之后,本章节将专注于如何有效地封装这一功能,并通过提供多个函数工具,进行具体的调用测试来展示其实用性。
1、自动输出funcation的函数
def auto_functions(functions_list):"""Chat模型的functions参数编写函数:param functions_list: 包含一个或者多个函数对象的列表;:return:满足Chat模型functions参数要求的functions对象"""def functions_generate(functions_list):# 创建空列表,用于保存每个函数的描述字典functions = []# 对每个外部函数进行循环for function in functions_list:# 读取函数对象的函数说明function_description = inspect.getdoc(function)# 读取函数的函数名字符串function_name = function.__name__system_prompt = '以下是某的函数说明:%s' % function_descriptionuser_prompt = '根据这个函数的函数说明,请帮我创建一个JSON格式的字典,这个字典有如下5点要求:\1.字典总共有三个键值对;\2.第一个键值对的Key是字符串name,value是该函数的名字:%s,也是字符串;\3.第二个键值对的Key是字符串description,value是该函数的函数的功能说明,也是字符串;\4.第三个键值对的Key是字符串parameters,value是一个JSON Schema对象,用于说明该函数的参数输入规范。\5.输出结果必须是一个JSON格式的字典,且不需要任何前后修饰语句' % function_nameresponse = client.chat.completions.create(model="gpt-3.5-turbo",messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": user_prompt}])json_function_description=json.loads(response.choices[0].message.content.replace("```","").replace("json",""))json_str={"type": "function","function":json_function_description}functions.append(json_str)return functions## 最大可以尝试4次max_attempts = 4attempts = 0while attempts < max_attempts:try:functions = functions_generate(functions_list)break # 如果代码成功执行,跳出循环except Exception as e:attempts += 1 # 增加尝试次数print("发生错误:", e)if attempts == max_attempts:print("已达到最大尝试次数,程序终止。")raise # 重新引发最后一个异常else:print("正在重新运行...")return functions
定义函数列表
functions_list = [sunwukong_function]
2、自动生成funcation函数调用测试
tools = auto_functions(functions_list)
查看生成后的工具函数
tools'description': '孙悟空算法函数,该函数定义了数据集计算过程','parameters': {'type': 'object','properties': {'data': {'type': 'string','description': '表示带入计算的数据表,用字符串进行表示'}},'required': ['data']}}}]
3、定义参数数据
df_str = pd.DataFrame({'x1':[1, 2], 'x2':[3, 4]}).to_string()
df_str

4、调用API测试
使用自动生成的funcation call函数,调用OpenAI测试,看大模型能否找到函数
messages=[{"role": "system", "content": "数据集data:%s,数据集以字符串形式呈现" % df_str},{"role": "user", "content": "请在数据集data上执行孙悟空算法"}
]
response = client.chat.completions.create(model="gpt-3.5-turbo",messages=messages,tools=tools,tool_choice="auto", )
response.choices[0].message
输出:从输出结构中可以看到,已经正常找到生成的工具函数

5、定义第二个函数
#在定义一个工具函数,一起测试
def tangseng_function(data):"""唐僧算法函数,该函数定义了数据集计算过程:param data: 必要参数,表示带入计算的数据表,用字符串进行表示:return:tangseng_function函数计算后的结果,返回结果为表示为JSON格式的Dataframe类型对象"""data = io.StringIO(data)df_new = pd.read_csv(data, sep='\s+', index_col=0)res = df_new * 1000000return json.dumps(res.to_string())
#两个函数一起放入工具列表
functions_list=[sunwukong_function,tangseng_function]
6、两个函数生成测试
# 使用gpt3.5发现有时候生成正确,但是有时候生成的json信息还是有些缺少,gpt.4会更稳定
tools = auto_functions(functions_list)
tools
输出:
[{'type': 'function','function': {'name': 'sunwukong_function','description': '孙悟空算法函数,该函数定义了数据集计算过程','parameters': {'type': 'object','properties': {'data': {'type': 'string', 'description': '表示带入计算的数据表'}},'required': ['data']}}},{'type': 'function','function': {'name': 'tangseng_function','description': '唐僧算法函数,该函数定义了数据集计算过程','parameters': {'type': 'object','properties': {'data': {'type': 'string','description': '必要参数,表示带入计算的数据表,用字符串进行表示'}},'required': ['data']}}}]
7、两个工具函数一起调用API测试
messages=[{"role": "system", "content": "数据集data:%s,数据集以字符串形式呈现" % df_str},{"role": "user", "content": "请在数据集data上执行唐僧算法函数"}
]
response = client.chat.completions.create(model="gpt-3.5-turbo",messages=messages,tools=tools,tool_choice="auto", )
response.choices[0].message
输出:根据输出可以看到,已经成功找到工具函数

四、结语
在本文的探讨和实践过程中,我们深入探索了利用大规模语言模型的生成能力来自动构建function函数的可能性和方法。通过精心设计的实验和不断的调优,我们成功实现了利用这些先进模型自动生成高质量的function函数,这不仅大大提高了开发效率,还为函数的多样性和创新性打开了新的大门。
此外,我们还专注于提高这些自动生成的函数在实际应用中的通用性和扩展性。这意味着所开发的函数不仅适用于当前的特定任务,还能在不同的应用环境和项目中轻松调整和扩展,从而保证长远的可用性和持续的价值。这一目标的实现显著增强了代码的复用性和适应性,为软件开发行业带来了新的工作效率和创新思路。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
相关文章:
AI大模型探索之路-实战篇7:Function Calling技术实战:自动生成函数
系列篇章💥 AI大模型探索之路-实战篇4:深入DB-GPT数据应用开发框架调研 AI大模型探索之路-实战篇5:探索Open Interpreter开放代码解释器调研 AI大模型探索之路-实战篇6:掌握Function Calling的详细流程 目录 系列篇章Ὂ…...
Android14 - 绘制系统 - 概览
从Android 12开始,Android的绘制系统有结构性变化, 在绘制的生产消费者模式中,新增BLASTBufferQueue,客户端进程自行进行queue的生产和消费,随后通过Transation提交到SurfaceFlinger,如此可以使得各进程将缓…...

Add object from object library 从对象库中添加内置器件
Add object from object library 从对象库中添加内置器件 正文正文 对于 Lumerical,有些时候我们在使用中,可能需要从 Object library 中添加器件,通常我们的做法是手动添加。如下图所示,我们添加一个 Directional Coupler 到我们的工程文件中: 但是这种操作方式不够智能…...

天诚公租房/人才公寓WiFi人脸识别物联网智能门锁解决方案
人才是引领城市高质量发展的重要因素,城市要想吸纳人才的保障便是人才公寓。近年来,全国各地一二三线城市都在大力建设人才公寓,集聚菁英人才,倾力打造人才高地。 一、人才公寓如火如荼建设 2023年底,山东德州提出三年…...

JAVA学习-练习试用Java实现“子集”
问题: 给定一个整数数组 nums,数组中的元素互不相同。返回该数组所有可能的子集(幂集)。解集不能包含重复的子集。可以按任意顺序返回解集。 示例 1: 输入:nums [1,2,3] 输出:[[],[1],[2],[…...

揭秘《庆余年算法番外篇》:范闲如何使用维吉尼亚密码解密二皇子密信
❤️❤️❤️ 欢迎来到我的博客。希望您能在这里找到既有价值又有趣的内容,和我一起探索、学习和成长。欢迎评论区畅所欲言、享受知识的乐趣! 推荐:数据分析螺丝钉的首页 格物致知 终身学习 期待您的关注 导航: LeetCode解锁100…...
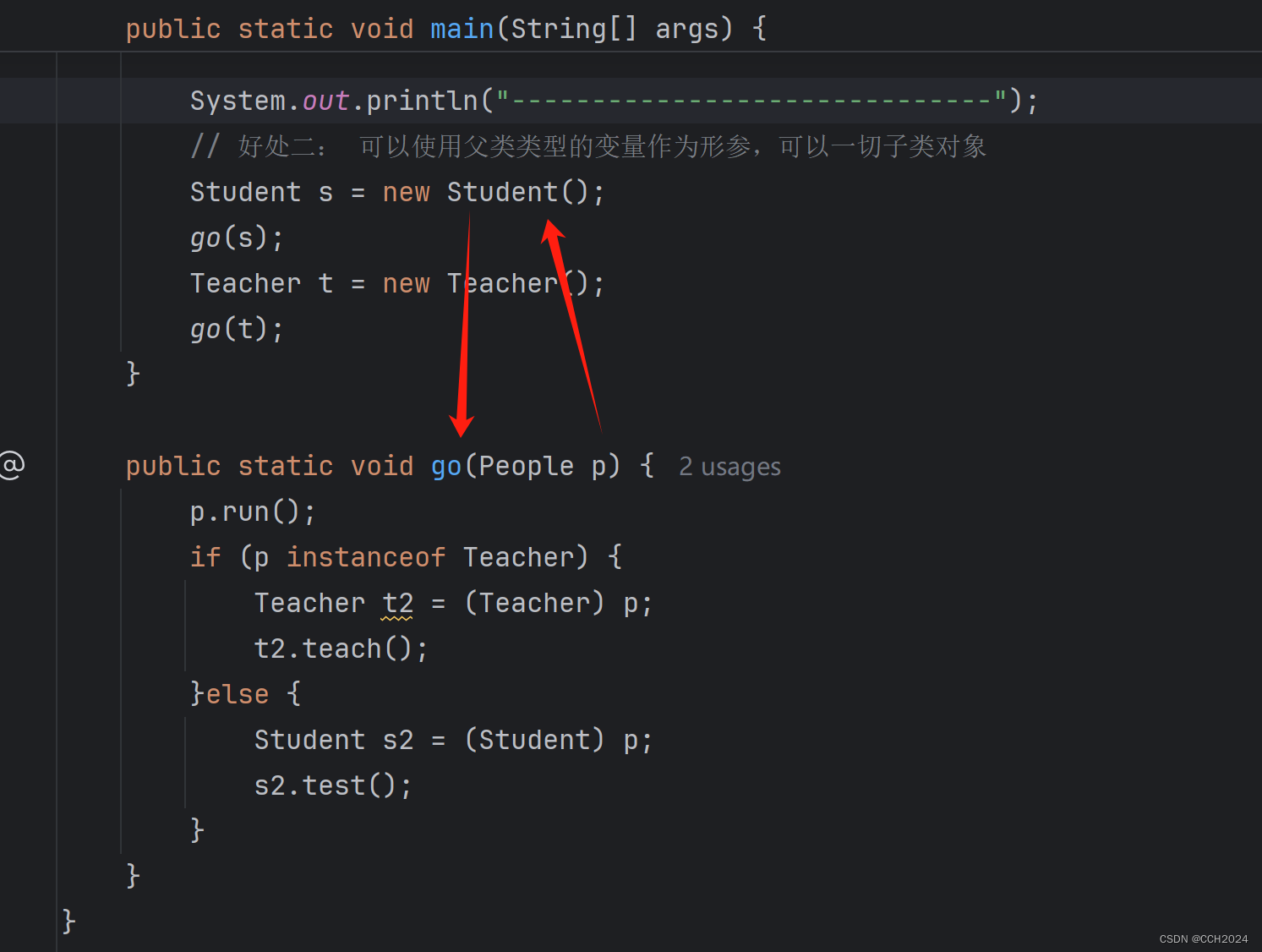
Java进阶学习笔记11——多态
什么是多态? 多态是在继承/实现情况下一种现象,表现为:对象多态和行为多态。 同一个对象,在不同时刻表现出来的不同形态。 多态的前提: 要有继承/实现关系 要有方法的重写 要有父类引用指向子类对象。 多态的具体代码…...

注意力机制篇 | YOLOv8改进之引入用于目标检测的混合局部通道注意力MLCA
前言:Hello大家好,我是小哥谈。注意力机制是可以帮助神经网络突出重要元素,抑制无关元素。然而,绝大多数通道注意力机制只包含通道特征信息,忽略了空间特征信息,导致模型表示效果或目标检测性能较差,且空间注意模块往往较为复杂。为了在性能和复杂性之间取得平衡,本文提…...

百度生成数据库
问题1: 帮我创建2个表student与score表,要求student表有id,createDate,userName,phone,age,sex,introduce, 要求score表有id,scoreName,result,studentId(student表的id外键)。 要求student表中插入5条学生信息,都要是中文的。 要…...
【SpringBoot】整合百度文字识别
流程图 一、前期准备 1.1 打开百度智能云官网找到管理中心创建应用 全选文字识别 1.2 保存好AppId、API Key和Secret Key 1.3 找到通用场景文字识别,立即使用 1.4 根据自己需要,选择要开通的项目 二、代码编写 以通用文字识别(高精度版&am…...

Java如何设计一个功能
流程说明:实现一组功能的步骤 1,充分了解需求,包括所有的细节,需要知道要做一个什么样的功能。 2,设计实体/表 正向工程:设计实体、映射文件 --> 建表 反向工程:设计表 --> 映射文件、实体 设计实体类型分析步骤: 1)功能模块有几个实体…...

MySQL 字符字段长度设置详解:语法、注意事项和示例
本文将详细介绍在 MySQL 数据库中如何设置字符字段的长度。将介绍字符字段的数据类型、长度限制、语法示例,并提供具体的示例,以正确设置和管理字符字段的长度。 1. MySQL 字符字段长度概述 在 MySQL 中,字符字段是用于存储文本型数据的列。…...

【对角线遍历】python
没啥思路 class Solution:def findDiagonalOrder(self, mat: List[List[int]]) -> List[int]:mlen(mat)nlen(mat[0])ret[]if len(mat)0:return retcount0#mn-1是对角线总数while count<mn-1:#x和y的和刚好是count数#偶数为右上走if count%20:xcount if(count<m)else (…...

温度检测小系统兼继电器模块和小风扇
1.思路: 代码还要封装! 延迟1秒;串口初始化;LCD1602显示屏初始化;延迟两秒;ledone不亮; while循环,延迟1秒,DHT模块读取数据;封装接收数据函数;发…...

[数据结构1.0]计数排序
读者老爷好,本鼠鼠最近学了计数排序,浅浅介绍一下! 目录 1.统计相同元素出现次数 2.根据统计的结果将序列回填到原来的序列中 3.相对映射计数排序 计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用,是非比较排…...

PostgreSQL入门教程
PostgreSQL是一种开源的关系型数据库管理系统,它具有高度的可靠性、可扩展性和性能。下面是一个简单的PostgreSQL入门教程,帮助你开始使用这个强大的数据库管理系统。 步骤1:安装PostgreSQL 首先,你需要下载并安装PostgreSQL。你…...

【spring】@ControllerAdvice注解学习
ControllerAdvice介绍 ControllerAdvice 是 Spring 框架提供的一个注解,用于定义一个全局的异常处理类或者说是控制器增强类(controller advice class)。这个特性特别适用于那些你想应用于整个应用程序中多个控制器的共有行为,比…...
【全开源】赛事报名系统源码(Fastadmin+ThinkPHP和Uniapp)
基于FastadminThinkPHP和Uniapp开发的赛事报名系统,包含个人报名和团队报名、成绩查询、成绩证书等。 构建高效便捷的赛事参与平台 一、引言:赛事报名系统的重要性 在举办各类赛事时,一个高效便捷的报名系统对于组织者和参与者来说都至关重…...
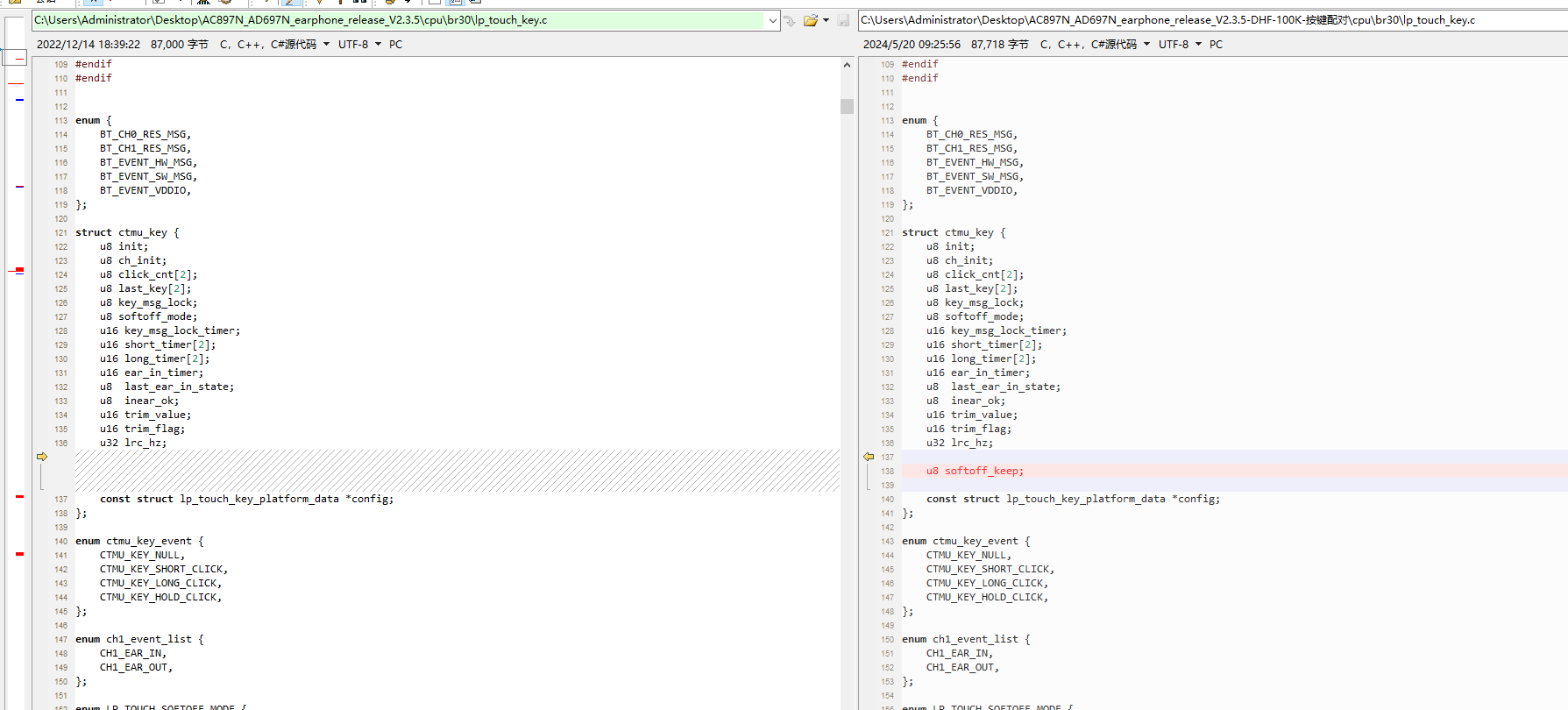
杰理-耳机进入关机关闭内内置触摸-节省功耗
杰理-耳机进入关机关闭内内置触摸-节省功耗 if (__this->init 0) {return LP_TOUCH_SOFTOFF_MODE_LEGACY; }if ((__this -> softoff_mode LP_TOUCH_SOFTOFF_MODE_ADVANCE) && (__this->softoff_keep 0)) {lp_touch_key_disable(); } __this->softoff_k…...

Homebrew安装、 Mac上pyenv的安装与使用,复制黏贴搞定,网上教程看得眼花缭乱的来看看,简单明了一步到胃!!
安装 Homebrew /bin/bash -c "$(curl -fsSL https://gitee.com/ineo6/homebrew-install/raw/master/install.sh)"安装pyenv brew install pyenv添加到终端使用的配置文件.zshrc、.bashrc 避免不必要的麻烦两个终端的配置文件都进行添加,文件在当前用户目…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

科华UPS电源全品类汇总:选型与场景适配指南
科华UPS电源作为国内智慧电能领域的主流产品,覆盖家用、办公、机房、工业等全场景,产品系列丰富、规格齐全,但多数用户在选型时,常因分不清系列差异、功率适配、架构类型而踩坑。本文系统汇总科华UPS电源的核心分类、主流系列、核…...

Spring Security OAuth2 /oauth/token 401原因与Content-Type规范
1. 问题现场还原:一个看似简单却让开发停摆两小时的/oauth/token请求刚接手一个老项目做安全加固,第一件事就是验证OAuth2密码模式的token获取流程。我照着文档写了一条curl命令:curl -X POST http://localhost:8080/oauth/token回车执行&…...

榨干Codex!OpenAI工程师亲授Codex真正用法
你可能把 Codex 当编程助手用,改改代码,跑跑测试。但它的能力远不止于此。OpenAI 的客户支持工程师 Jason(jxnlco)告诉你,Codex 其实是一套完整的电脑工作系统,从语音输入到自动化,从浏览器操控…...

5A智慧景区建设|对标一流!巨有科技打造数智化标杆景区
5A级景区是中国旅游的最高标准,代表着服务与管理的顶尖水平。随着5A评审标准日益严苛,“智慧化”已成为核心硬性指标。然而,不少景区的智慧化建设陷入“重硬件、轻整合”的误区,系统林立、数据孤岛,投入巨大却效果不佳…...
)
【Veo 2提示词SOP白皮书】:从模糊意图到像素级输出的8步标准化工作流(附NASA级测试用例库)
更多请点击: https://intelliparadigm.com 第一章:Veo 2提示词工程的本质与范式跃迁 Veo 2并非单纯升级的视频生成模型,而是一次提示词工程范式的根本性重构——它将传统“指令式提示”(prompt-as-command)转向“意图…...

基于STM32与LoRa的低功耗物联网气象站DIY全攻略
1. 项目概述:打造一个低功耗的家庭气象站前阵子想给家里的智能家居系统加点“环境感知”能力,琢磨着搞个能实时监测室外温湿度、风速风向的小玩意儿。市面上成品气象站要么数据出不来,要么功耗感人,不适合长期户外部署。于是&…...

NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台
NBTExplorer:让Minecraft数据编辑从专业工具变成人人可用的可视化平台 【免费下载链接】NBTExplorer A graphical NBT editor for all Minecraft NBT data sources 项目地址: https://gitcode.com/gh_mirrors/nb/NBTExplorer 你是否曾经面对Minecraft世界文件…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...

如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南
如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南 【免费下载链接】GASShooter Advanced FPS/TPS Sample Project for Unreal Engine 4s GameplayAbilitySystem plugin 项目地址: https://gitcode.com/gh_mirrors/ga/GASShooter GASShooter是Un…...