【ML Olympiad】预测地震破坏——根据建筑物位置和施工情况预测地震对建筑物造成的破坏程度
文章目录
- Overview 概述
- Goal 目标
- Evaluation 评估标准
- Dataset Description 数据集说明
- Dataset Source 数据集来源
- Dataset Fields 数据集字段
- Data Analysis and Visualization 数据分析与可视化
- Correlation 相关性
- Hierarchial Clustering 分层聚类
- Adversarial Validation 对抗验证
- Target 目标
- Model 模型
- Vote 投票
- Score Models 模型评分
Overview 概述
ML Olympiad - Predicting Earthquake Damage是一个由Kaggle和DrivenData合作举办的比赛,旨在通过机器学习算法来预测尼泊尔地震后房屋的损坏程度。这个比赛提供了一个数据集,其中包含了尼泊尔地震期间房屋的各种特征信息,以及每个房屋的损坏程度标签。
参赛者需要利用提供的数据集构建一个模型,通过分析房屋的特征信息来预测房屋的损坏程度。挑战在于需要处理大量的结构化数据,并建立一个高效的预测模型。参赛者可以使用各种机器学习算法、特征工程技巧和模型调优方法来提高他们的预测准确性。

Goal 目标
该比赛的目标是帮助相关组织和机构更好地了解地震对房屋造成的破坏程度,从而提前做好灾害应对和救援准备。通过参与这个比赛,参赛者不仅可以提升他们的机器学习建模能力,还可以为社会做出积极的贡献。
Evaluation 评估标准
macro F score,也称为macro-averaged F1 score,是用于评估多类分类模型性能的指标。它代表了所有类别的平均F1分数,将每个类别视为相等,而不考虑其大小或重要性。
Dataset Description 数据集说明
Dataset Source 数据集来源
本次比赛的合成数据是根据 Richter’s Predictor:Modeling Earthquake Damage 创建的,包含2015年廓尔喀地震建筑位置和施工细节的数据集。这些数据是通过Kathmandu生活实验室和尼泊尔国家计划委员会秘书处下属的中央统计局的调查收集的。这项调查是有史以来收集到的最大灾后数据集之一,包含有关地震影响、家庭状况和社会经济人口统计数据的宝贵信息。文件包括:
train.csv:训练数据集。该数据集包含了4000行和 36 列。
test.csv:测试数据集。与训练数据集类似,该数据集包括 1000 行和 35 列。
sampleSubmission.csv: 示例提交文件。该文件是由最后生成的实际预测结果导出的表格。

Dataset Fields 数据集字段
此处以train.csv为例,描述数据集中的字段及其含义:
| 字段 | 含义 |
|---|---|
| building_id | 建筑物ID |
| count_floors_pre_eq | 地震前楼层数 |
| age | 建筑物年龄 |
| area_percentage | 地块占比 |
| height_percentage | 高度占比 |
| land_surface_condition | 土地表面条件 |
| foundation_type | 基础类型 |
| roof_type | 屋顶类型 |
| ground_floor_type | 底层类型 |
| other_floor_type | 其他楼层类型 |
| position | 位置 |
| plan_configuration | 平面配置 |
| has_superstructure_adobe_mud | 是否有土坯结构 |
| has_superstructure_mud_mortar_stone | 是否有泥砂砂浆石结构 |
| has_superstructure_stone_flag | 是否有石质结构标志 |
| has_superstructure_cement_mortar_stone | 是否有水泥砂砂浆石结构 |
| has_superstructure_mud_mortar_brick | 是否有泥砂砂浆砖结构 |
| has_superstructure_cement_mortar_brick | 是否有水泥砂砂浆砖结构 |
| has_superstructure_timber | 是否有木结构 |
| has_superstructure_bamboo | 是否有竹结构 |
| has_superstructure_rc_non_engineered | 是否有非工程钢筋混凝土结构 |
| has_superstructure_rc_engineered | 是否有工程钢筋混凝土结构 |
| has_superstructure_other | 是否有其他结构 |
| legal_ownership_status | 法律所有权状态 |
| count_families | 家庭数量 |
| has_secondary_use | 是否有次要用途 |
| has_secondary_use_agriculture | 是否有农业次要用途 |
| has_secondary_use_hotel | 是否有酒店次要用途 |
| has_secondary_use_rental | 是否有出租次要用途 |
| has_secondary_use_institution | 是否有机构次要用途 |
| has_secondary_use_school | 是否有学校次要用途 |
| has_secondary_use_industry | 是否有工业次要用途 |
| has_secondary_use_health_post | 是否有医疗设施次要用途 |
| has_secondary_use_gov_office | 是否有政府办公室次要用途 |
| has_secondary_use_use_police | 是否有警察局次要用途 |
| has_secondary_use_other | 是否有其他次要用途 |
| damage_grade | 损坏等级 |
Data Analysis and Visualization 数据分析与可视化
Correlation 相关性
使用斯皮尔曼相关系数计算数据集中数值型特征与目标变量之间的相关性,并创建一个热力图来可视化这些相关性。热力图中的颜色深浅表示了相关性的强弱,同时在图中还显示了具体的相关系数数值。此外,通过掩码操作,对角线以下的相关性值被遮盖,以避免重复显示。
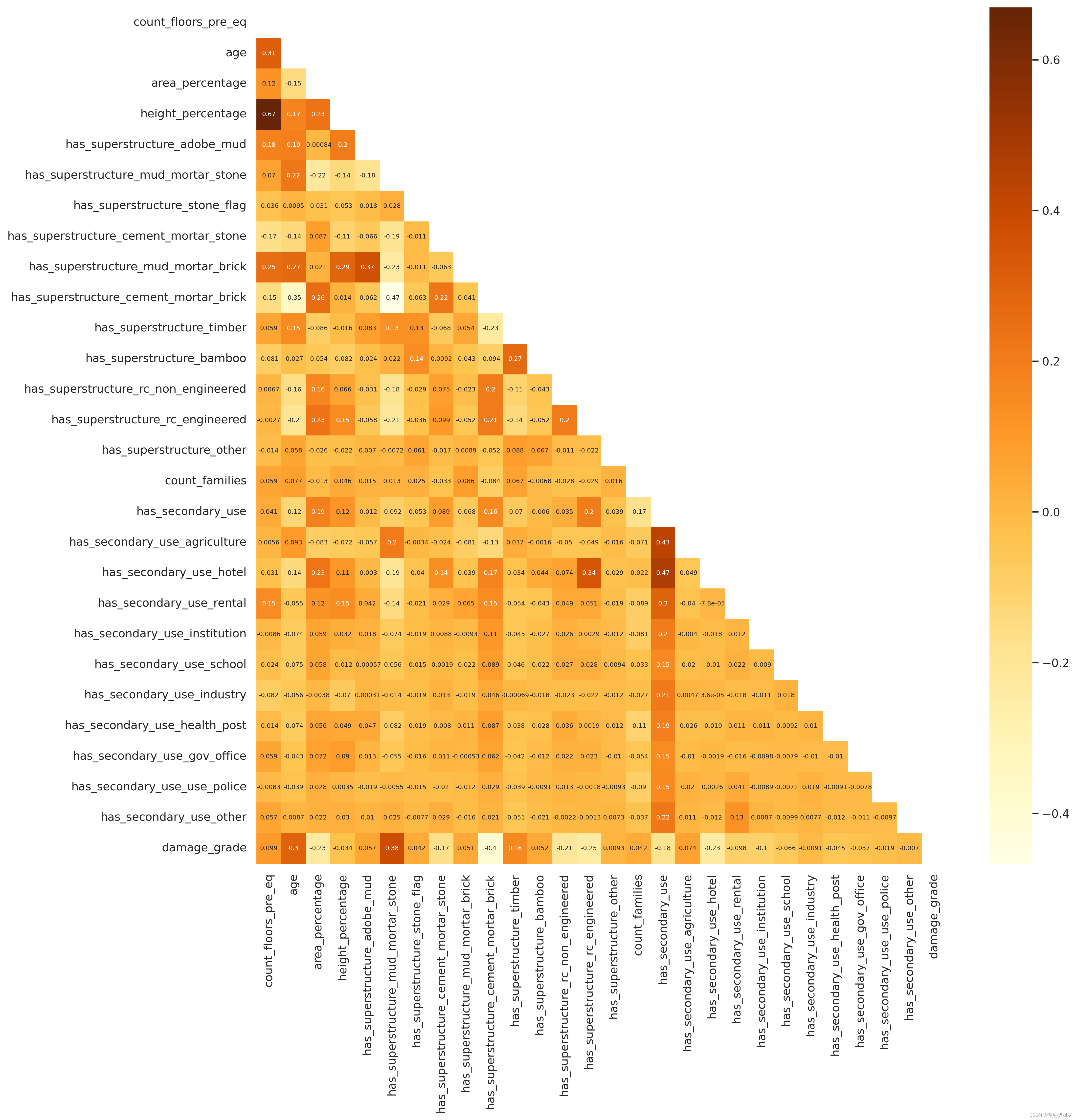
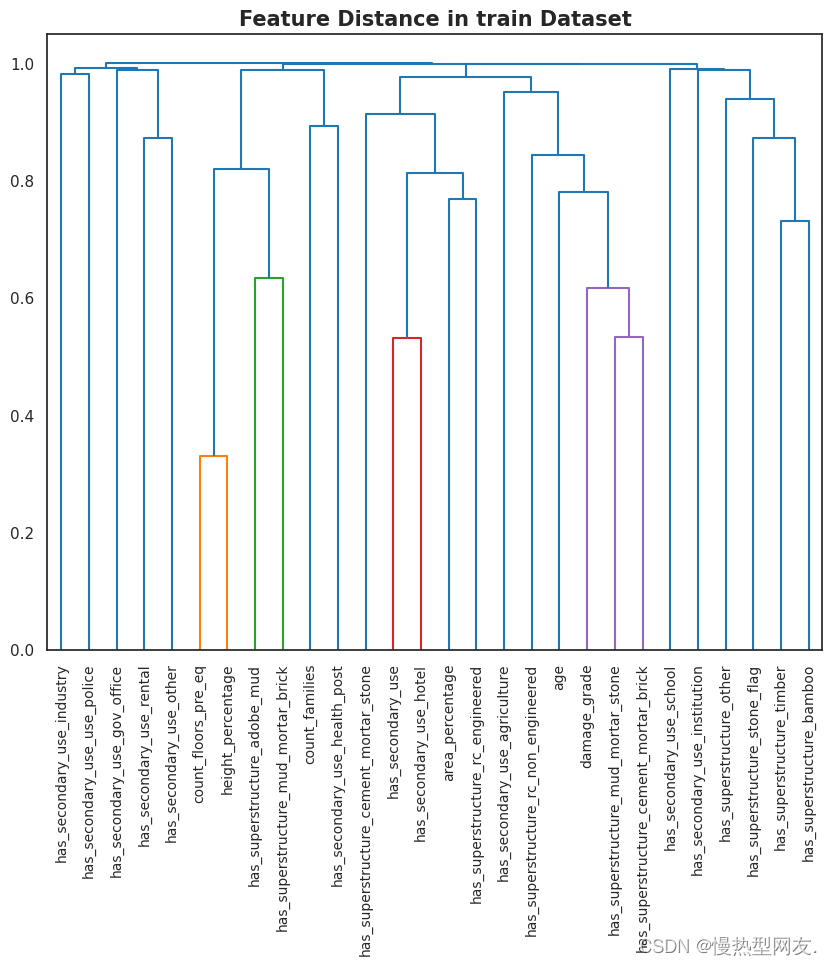
Hierarchial Clustering 分层聚类
通过分层聚类的方法将特征进行聚类。函数接受数据集、标签和方法参数作为输入。首先,它计算特征之间的相关性矩阵,然后利用相关性矩阵构建聚类树。接着,使用函数生成特征之间的链接矩阵表示特征的相似性。最后,通过以树状图的形式可视化特征的聚类结果,并在图表上显示特征的标签。
Adversarial Validation 对抗验证
绘制一个包含多个子图的图表,用于显示训练数据集和测试数据集中数值型特征的分布情况。在每个子图中,使用直方图来展示该特征在训练数据集和测试数据集中的分布情况,其中训练数据集的直方图以红色表示,测试数据集的直方图以绿色表示。同时,对于没有特征对应的子图,将其隐藏。整个图表的标题用于描述特征在不同数据集中的分布情况,并在图例中标识了训练数据集和测试数据集。

在对抗验证中看到,训练和测试数据可能不遵循相同的分布,但是,从视觉上看,一些数值变量在两者中具有相同的分布。
Target 目标
针对训练数据集中目标变量的不同取值,绘制一个柱状图来展示每个取值对应的样本数量。
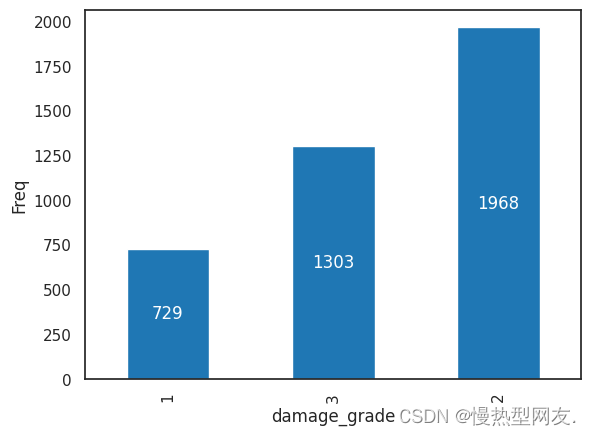
这是一个具有不平衡类的数据集,在这种情况下,我们将选择在验证中使用 Stratified K-Fold。
Stratified K-Fold 是一种交叉验证的方法,它能够在划分数据集时保持每个折叠中各个类别样本的比例与整个数据集中各个类别样本的比例相似。在机器学习中,特别是在处理不平衡类别的数据集时,使用 Stratified K-Fold 能够更好地确保模型在交叉验证过程中对各个类别的预测能力。这种方法有助于减少由于不平衡数据引起的模型评估偏差,提高模型评估的准确性和稳健性。
Model 模型
对多个分类模型进行了交叉验证,并记录了它们的性能评分。
models = [('log', LogisticRegression(random_state = SEED, max_iter = 1000000)),('bnb', BernoulliNB()),('rf', RandomForestClassifier(random_state = SEED)),('et', ExtraTreesClassifier(random_state = SEED)),('xgb', XGBClassifier(random_state = SEED)),('lgb', LGBMClassifier(random_state = SEED,verbosity=0)),('gb', GradientBoostingClassifier(random_state = SEED)),('hgb', HistGradientBoostingClassifier(random_state = SEED))
]
这些模型的性能评估结果如下:
Val Score: 0.53032 ± 0.01052 | Train Score: 0.54762 ± 0.00718 | log
Val Score: 0.52955 ± 0.00822 | Train Score: 0.53774 ± 0.00188 | bnb
Val Score: 0.53408 ± 0.01000 | Train Score: 0.99584 ± 0.00076 | rf
Val Score: 0.51914 ± 0.00924 | Train Score: 0.99584 ± 0.00076 | et
Val Score: 0.52693 ± 0.01181 | Train Score: 0.89624 ± 0.00137 | xgb
Val Score: 0.52754 ± 0.01253 | Train Score: 0.83933 ± 0.00353 | lgb
Val Score: 0.52542 ± 0.01657 | Train Score: 0.63977 ± 0.00856 | gb
Val Score: 0.52613 ± 0.00736 | Train Score: 0.88695 ± 0.00303 | hgb
根据结果来看,各个模型的验证集得分(Val Score)大致在 0.52 到 0.53 之间,训练集得分(Train Score)则普遍较高。这可能表明模型存在一定程度的过拟合,即在训练集上表现优秀,但在验证集上的表现较差。特别地,随机森林(rf)和极端随机树(et)模型在训练集上获得了接近1的得分,可能存在过拟合的风险。
Vote 投票
定义了一个投票分类器 voting,将之前定义的多个模型 models 作为投票的选项,并使用软投票策略进行投票。
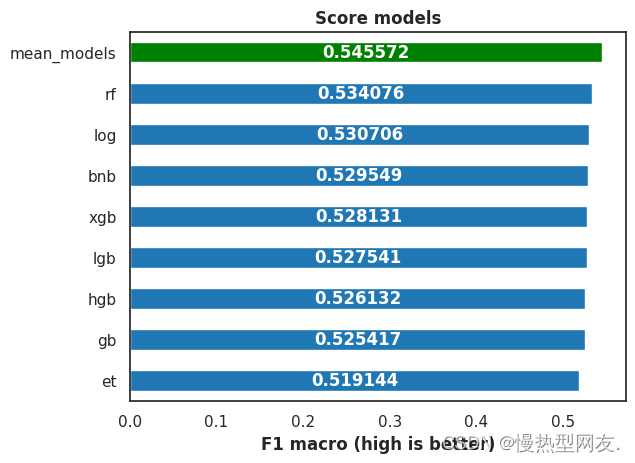
Val Score: 0.54648 ± 0.01122 | Train Score: 0.96209 ± 0.00166 | mean_models
根据结果来看,使用投票分类器进行软投票(voting=‘soft’)得到的验证集得分为 0.54648,训练集得分为 0.96209。与之前单个模型相比,投票分类器在验证集上的得分略有提升,说明投票策略可以有效地改善模型性能。
Score Models 模型评分
对模型评分进行可视化展示,以便更清晰地展示模型评分的信息。
相关文章:
【ML Olympiad】预测地震破坏——根据建筑物位置和施工情况预测地震对建筑物造成的破坏程度
文章目录 Overview 概述Goal 目标Evaluation 评估标准 Dataset Description 数据集说明Dataset Source 数据集来源Dataset Fields 数据集字段 Data Analysis and Visualization 数据分析与可视化Correlation 相关性Hierarchial Clustering 分层聚类Adversarial Validation 对抗…...

kafka监控配置和告警配置
Kafka的监控配置和告警配置是确保Kafka集群稳定运行的关键部分。以下是一些关于Kafka监控配置和告警配置的建议: 一、Kafka监控配置 集群级别参数监控: log.retention.hours:用于控制消息在日志中保留的时间。监控此参数的值,确…...

关于智慧校园安全用电监测系统的设计
人生人身安全是大家关注的话题,2019年12月中国消防统计近五年发生在全国学生宿舍的火灾2314起(中国消防2019.12.应急管理部消防救援局官方微博),违规电器是引发火灾的主因。如果在各寝室安装智能用电监测器实时监督线路参数&#…...

Flutter 中的 FormField 小部件:全面指南
Flutter 中的 FormField 小部件:全面指南 在Flutter的世界里,表单是用户输入数据的基本方式之一。FormField是一个强大的小部件,它将表单字段的创建、验证和管理集成到了一个易于使用的抽象中。本文将为您提供一个全面的指南,帮助…...
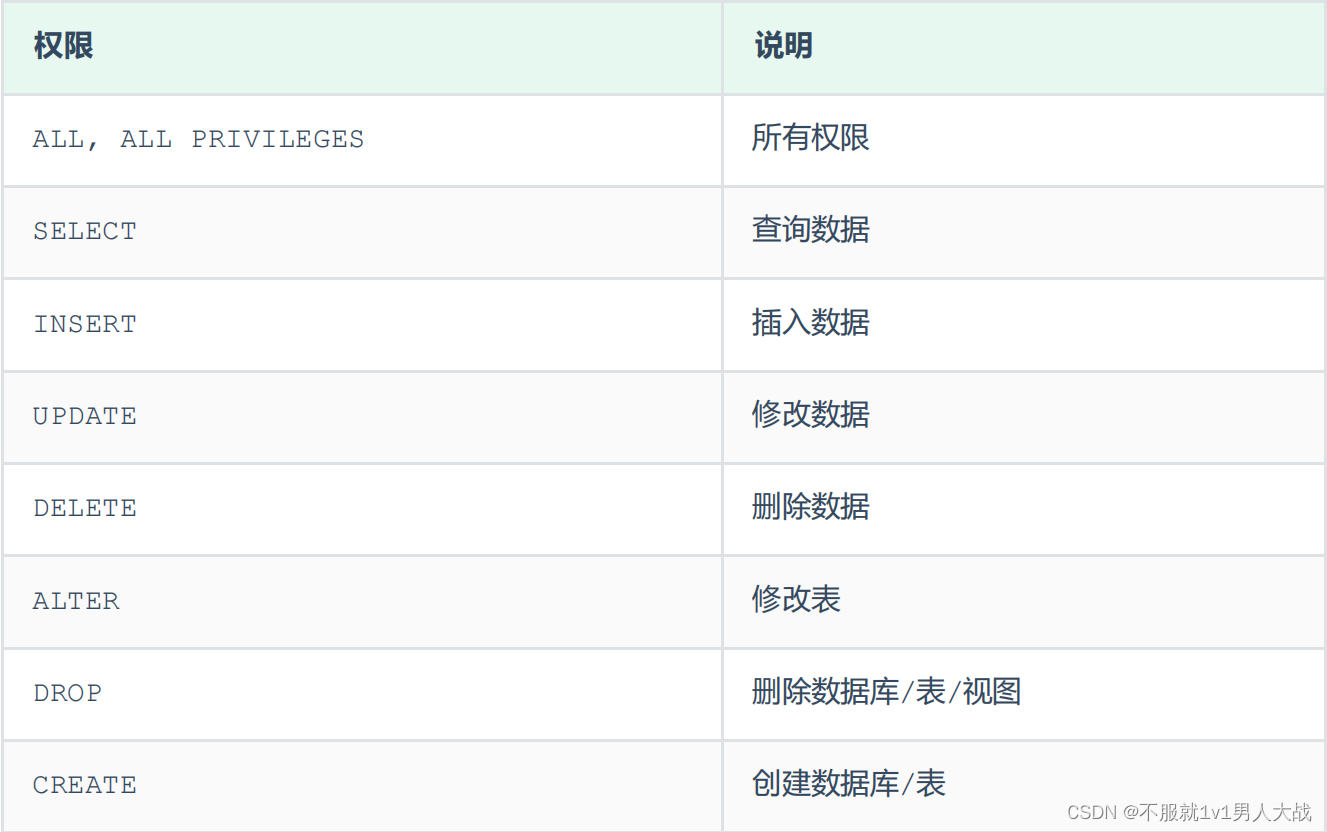
数据库DCL语句
数据库DCL语句 介绍: DCL英文全称是Data Control Language(数据控制语言),用来管理数据库用户、控制数据库的访 问权限。 管理用户: 查询用户: select * from mysql.user;创建用户: create user 用户名主机名 identified by 密码;修改用…...

mysql-日志管理-error.log
日志管理 默认的数据库日志 vim /etc/my.cnf //错误日志 log-error/usr/local/mysql/mysql.log查看数据库日志 tail -f /usr/local/mysql/mysql.log1 错误日志 :启动,停止,关闭失败报错。rpm安装日志位置 /var/log/mysqld.log #默认开启 2 …...
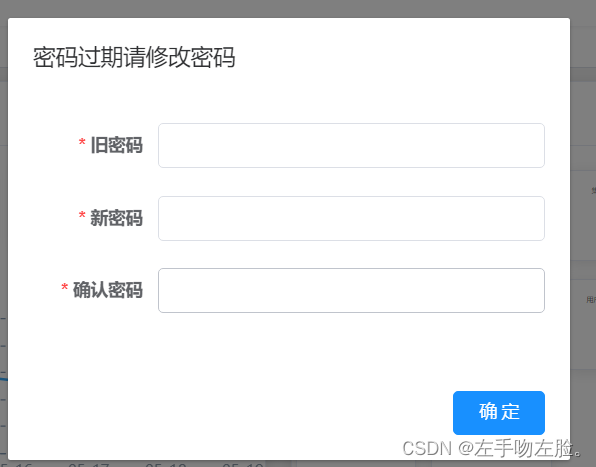
弱密码系统登录之后强制修改密码
在你登录的时候,获取到弱密码,然后将他存到vuex里面,在登录进去之后,index页面再去取,思路是这样的 一、vuex里面定义密码字段 我是直接在user.js里面写的 import { login, logout, getInfo } from /api/login impo…...

解释Python中的多线程和多进程编程
在Python中,多线程(Multithreading)和多进程(Multiprocessing)是两种常见的并发编程技术,用于同时执行多个任务。然而,由于Python的全局解释器锁(GIL,Global Interpreter…...

【LeetCode】【1】两数之和(1141字)
文章目录 [toc]题目描述样例输入输出与解释样例1样例2样例3 提示进阶Python实现哈希表 个人主页:丷从心 系列专栏:LeetCode 刷题指南:LeetCode刷题指南 题目描述 给定一个整数数组nums和一个整数目标值target,请在该数组中找出…...

【论文速读】|探索ChatGPT在软件安全应用中的局限性
本次分享论文:Exploring the Limits of ChatGPT in Software Security Applications 基本信息 原文作者:Fangzhou Wu, Qingzhao Zhang, Ati Priya Bajaj, Tiffany Bao, Ning Zhang, Ruoyu "Fish" Wang, Chaowei Xiao 作者单位:威…...

部门来了个测试开发,听说是00后,上来一顿操作给我看蒙了...
公司新来了个同事,听说大学是学的广告专业,因为喜欢IT行业就找了个培训班,后来在一家小公司实习半年,现在跳槽来我们公司。来了之后把现有项目的性能优化了一遍,服务器缩减一半,性能反而提升4倍!…...
小程序-修改用户头像
1、调用拍照 / 选择图片 // 修改头像 const onAvatarChange () > { // 调用拍照 / 选择图片 uni.chooseMedia({ // 文件个数 count: 1, // 文件类型 mediaType: [image], success: (res) > { console.log(res) // 本地临时文件路径 (本地路径) const { tempFilePath } …...

PCIe总线-事物层之TLP请求和完成报文格式介绍(六)
1.概述 TLP报文按照类型,可以大致分为4中类型,分别是IO请求报文、存储器请求报文、配置请求报文、完成报文和消息请求报文。IO请求报文可分为IO读请求(不携带数据)和IO写请求(携带数据)。存储器请求报文可…...

从 0 开始实现一个网页聊天室 (小型项目)
实现功能 用户注册和登录好友列表展示会话列表展示: 显示当前正在进行哪些会话 (单聊 / 群聊) , 选中好友列表中的某个好友, 会生成对应的会话实时通信, A给B发送消息, B的聊天界面 / 会话界面能立刻显示新的消息 TODO: 添加好友功能用户头像显示传输图片 / 表情包历史消息搜…...
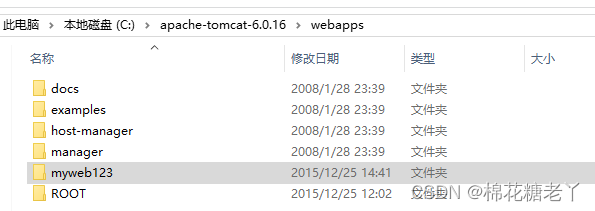
Tomcat部署项目的方式
目录 1、Tomcat发布项目的方式 方式1: 直接把项目发布到webapps目录下 方式2:项目发布到ROOT目录 方式3:虚拟路径方式发布项目 方式4:(推荐)虚拟路径,另外的方式! 方式5:发布多个网站 1、…...

推荐一个快速开发接私活神器
文章目录 前言一、项目介绍二、项目地址三、功能介绍四、页面显示登录页面菜单管理图表展示定时任务管理用户管理代码生成 五、视频讲解总结 前言 大家好!我是智航云科技,今天为大家分享一个快速开发接私活神器。 一、项目介绍 人人开源是一个提供多种…...
——C++的输入输出运算符)
输入输出(4)——C++的输入输出运算符
目录 一、输入运算符>> 二、输出运算符<< 三、 输入与输出运算符的重载 (一)必须重载为类的友元函数 (二)返回类型应是对象的引用 一、输入运算符>> 输人运算符“>>”也称为流提取运算符,是一个二目…...
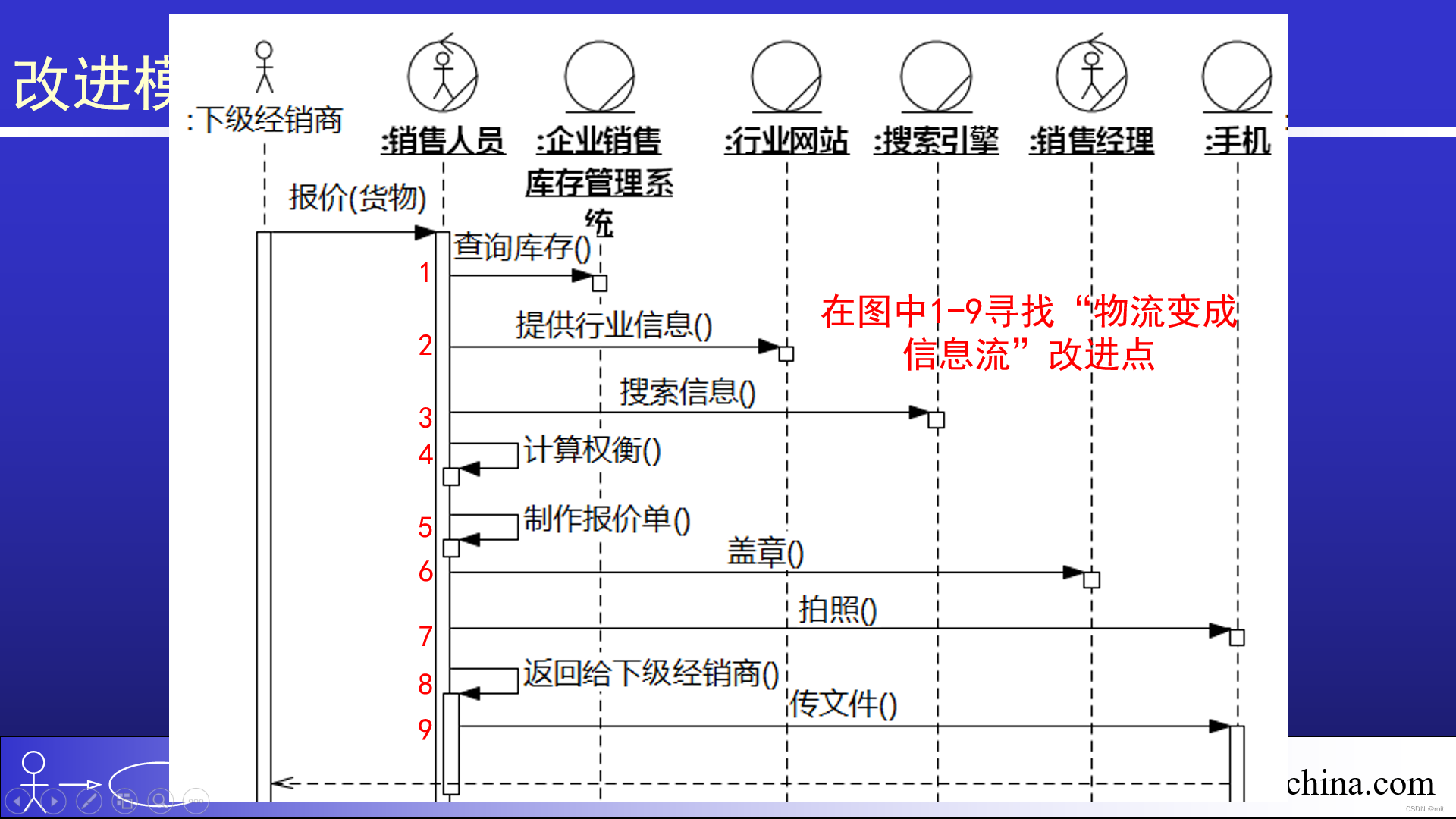
[图解]产品经理创新模式01物流变成信息流
1 00:00:01,570 --> 00:00:04,120 有了现状的业务序列图 2 00:00:04,960 --> 00:00:08,490 我们就来改进我们的业务序列图了 3 00:00:08,580 --> 00:00:11,010 把我们要做的系统放进去,改进它 4 00:00:13,470 --> 00:00:15,260 怎么改进?…...

npm 上传包
将自己做好的包做好后上传 1. 切换镜像(只能通过官网代理来上传) npm config set registry https://registry.npmjs.org/ 2. 添加用户(等价登录) npm addUser 3. 提交 npm publish 4. 删除 npm unpublish [<pkg>][&…...

Python 小游戏——贪吃蛇
Python 小游戏——贪吃蛇 文章目录 Python 小游戏——贪吃蛇项目介绍环境配置代码设计思路1. 初始化和变量定义2. 创建游戏窗口和FPS控制器3. 初始化贪吃蛇和食物的位置4. 控制贪吃蛇的方向和分数5. 主游戏循环 难点分析源代码呈现代码结果 项目介绍 贪吃蛇游戏是一款通过上下…...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

文件-语言-系统:基础IO-2.0——IO重定向接口,语言层缓冲区,系统级缓冲区。内核级分析!
bit::Shadow✧(≖ ◡ ≖✿ 目录 重定向接口dup2() ">" ">>" "<" 函数原型 输出重定向1和2的使用 文件描述符表 ./a.out运行: "./a.out >"默认重定向是fd 1 合并标准输入输出 缓冲区 什么是缓冲…...
P2P聊天程序)
基于C#实现(WinForm)P2P聊天程序
♻️ 资源 大小: 29.8MB ➡️ 资源下载:https://download.csdn.net/download/s1t16/87430269 p2p聊天程序 一、功能介绍 1.1 登录 用户凭用户名和密码登录系统,可以更换服务器 IP 和端口,以防网络不畅通,连接服务…...

手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器
手机也能玩转无人机仿真:用安卓QGC App连接同一WiFi下的PX4 JMAVSim模拟器 无人机开发者和爱好者们,是否曾想过用手机就能完成整个无人机仿真测试流程?告别笨重的电脑束缚,只需一部安卓设备,就能在沙发上调试飞控算法。…...

利用 Taotoken 多模型能力为智能客服场景提供备份路由
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 多模型能力为智能客服场景提供备份路由 智能客服系统是许多企业与用户交互的关键入口,其响应能力和服务…...

揭秘Midjourney云雾渲染失效真相:3大隐性提示词冲突、2类SDXL迁移兼容漏洞及实时雾浓度校准公式
更多请点击: https://intelliparadigm.com 第一章:揭秘Midjourney云雾渲染失效真相:3大隐性提示词冲突、2类SDXL迁移兼容漏洞及实时雾浓度校准公式 Midjourney V6 在启用云雾(mist/fog/haze)类视觉效果时,…...

Godot 4.3随机地图性能优化:避开TileMap与RNG陷阱
1. 为什么刚写完第一版随机地图就崩溃?——从“能跑”到“能用”的真实断层你兴冲冲地照着教程敲完几十行GDScript,RandomNumberGenerator初始化了,for x in range(width)循环也套好了,甚至还在_draw()里用draw_rect()把每个格子都…...

XZ9971,60V,5A,NMOS 封装:SOT223
封装:SOT223类型:NVDS:60V VGS: 20V ID:5ARDS(ON):10V <50mΩRDS(ON):4.5V <60mΩ型号: XZ9971 封装:SOT223类型&…...

Qri入门教程:如何在5分钟内开始使用分布式数据集版本控制
Qri入门教程:如何在5分钟内开始使用分布式数据集版本控制 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一款强大的分布式数据集版本控制工具,它比电子表格更强大,比数…...

从‘调参苦手’到‘一击即中’:实战解读glmnet中lambda.min与lambda.1se到底怎么选
从‘调参苦手’到‘一击即中’:实战解读glmnet中lambda.min与lambda.1se到底怎么选 在机器学习的世界里,LASSO回归就像一位精明的裁缝,能够为数据量身定制最合身的模型。而glmnet包中的lambda.min和lambda.1se,则是这位裁缝手中的…...