《Python源码剖析》之pyc文件
前言
前面我们主要围绕pyObject和pyTypeObject聊完了python的内建对象部分,现在我们将开启新的篇章—python虚拟机,将聚焦在python的执行部分,搞懂从“代码”到“执行”的过程。开启新的篇章之前,你也许会有一个疑惑:我们写的代码是如何执行的?从表面看,我只要按照python的正确语法书写一段代码,然后“剩下的”交给python解释器,代码就能被执行了!这也许就是大部分人能够给出的解释了,在没有学习此篇章之前,我也是这么认为的,因为我也没有探究过“剩下的部分”python解释器是如何去操作的。因此,从这一篇博客开始,让我们一起带着这个问题,“钻进”python的解释器中,看看它到底做了个啥!🔍🔍🔍
开始
作为python开发者,我相信大家对pyc文件应该并不陌生,它虽然经常“藏”在我们看不到的地方,但有时作用可不小,你也许为了提速,将整个项目的py文件转成pyc文件,然后再去执行;或者你为了加密,将py文件转成pyc文件再发给别人…等等这些,都和pyc文件的特性有关系,这样看来,pyc文件似乎比py文件更“抢手”?这其中似乎有什么蹊跷?还是python解释器对pyc文件有偏心?因此,在开启“python执行过程”的探索,pyc文件似乎比py文件更有研究价值🧐?
什么是pyc文件?
细心的小伙伴应该早就发现了:我们写的py文件夹中,有时候会多一个额外的文件夹:__pychache_,点开这个文件夹,你可能还会发现,这里面会有一些以.pyc结尾的文件,同时,你还会发现它们的文件名和上级目录中的py文件名是有一些对应关系的。
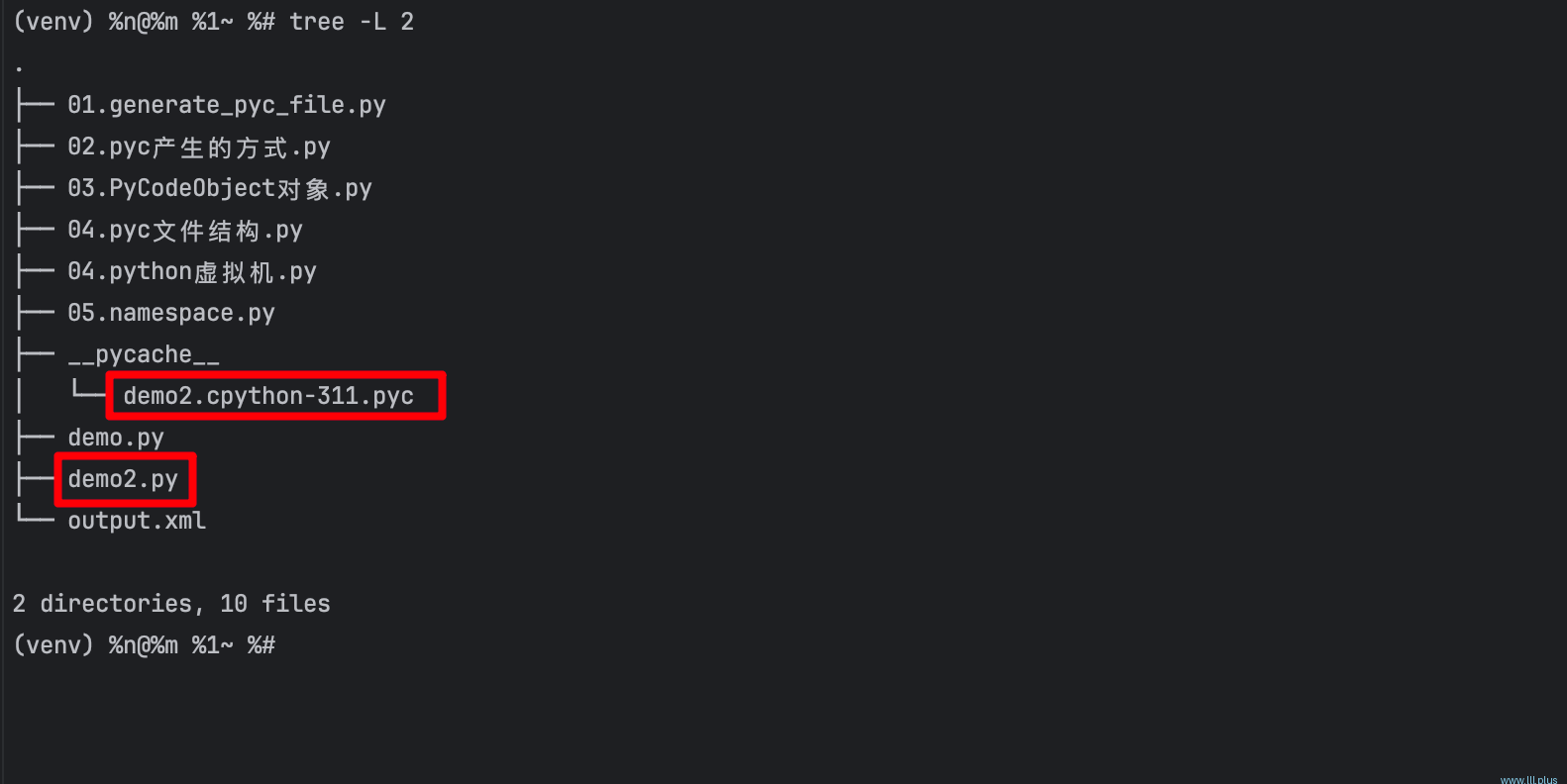
这里的以.pyc结尾的文件就是我们常说的pyc文件,看看它的目录名:__pycache_,根据目录名,我想大家应该猜到它的作用是什么了,没错,我们就可以把它当作是对py文件的一个缓存文件,缓存的主要目的:就是为了提(加载)速!
pyc文件是怎么产生的?
看上面👆的那个截图发现,__pycache__中似乎只有一个.pyc文件,为什么其他的py文件没有对应的pyc文件呢?这也许从侧面说明了一点:pyc文件不是必须的,应该只在特定情况下才能触发生成。(如果你还是有点怀疑,可以查看自己的py文件目录)
是和我们写的代码有关系吗?答案是肯定的!
实际上,当我们每次通过import导入一个py文件时,都可能会触发这个“生成pyc文件”的开关。
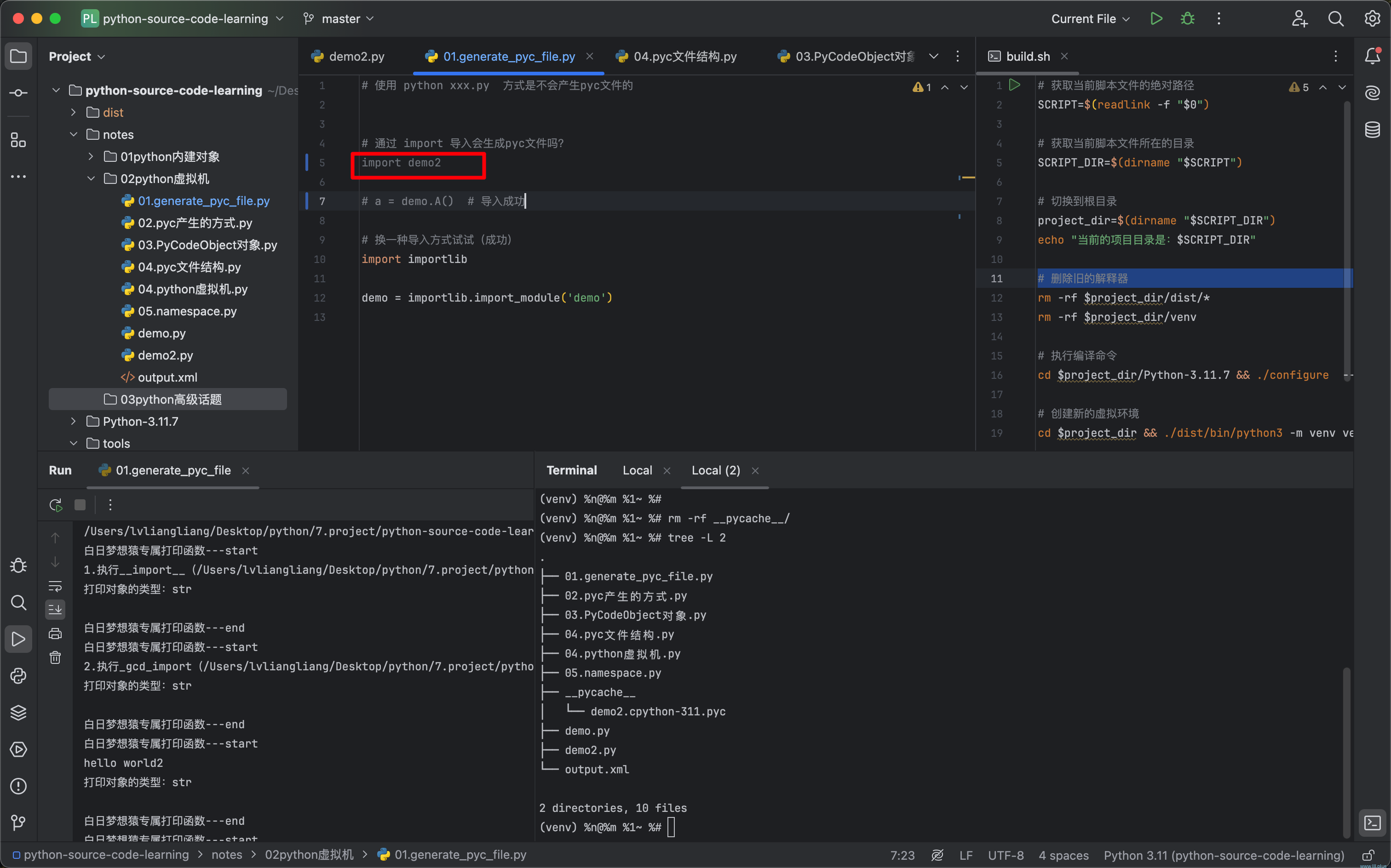
在当前目录所有的py文件中,我只对demo2.py文件进行了导入操作,没有对其他的py文件执行导入操作,因此实际上就是import机制触发了pyc文件的产生。当然,如果你想手动生成,也是可以的,下面是通过代码生成pyc文件的一个方法:
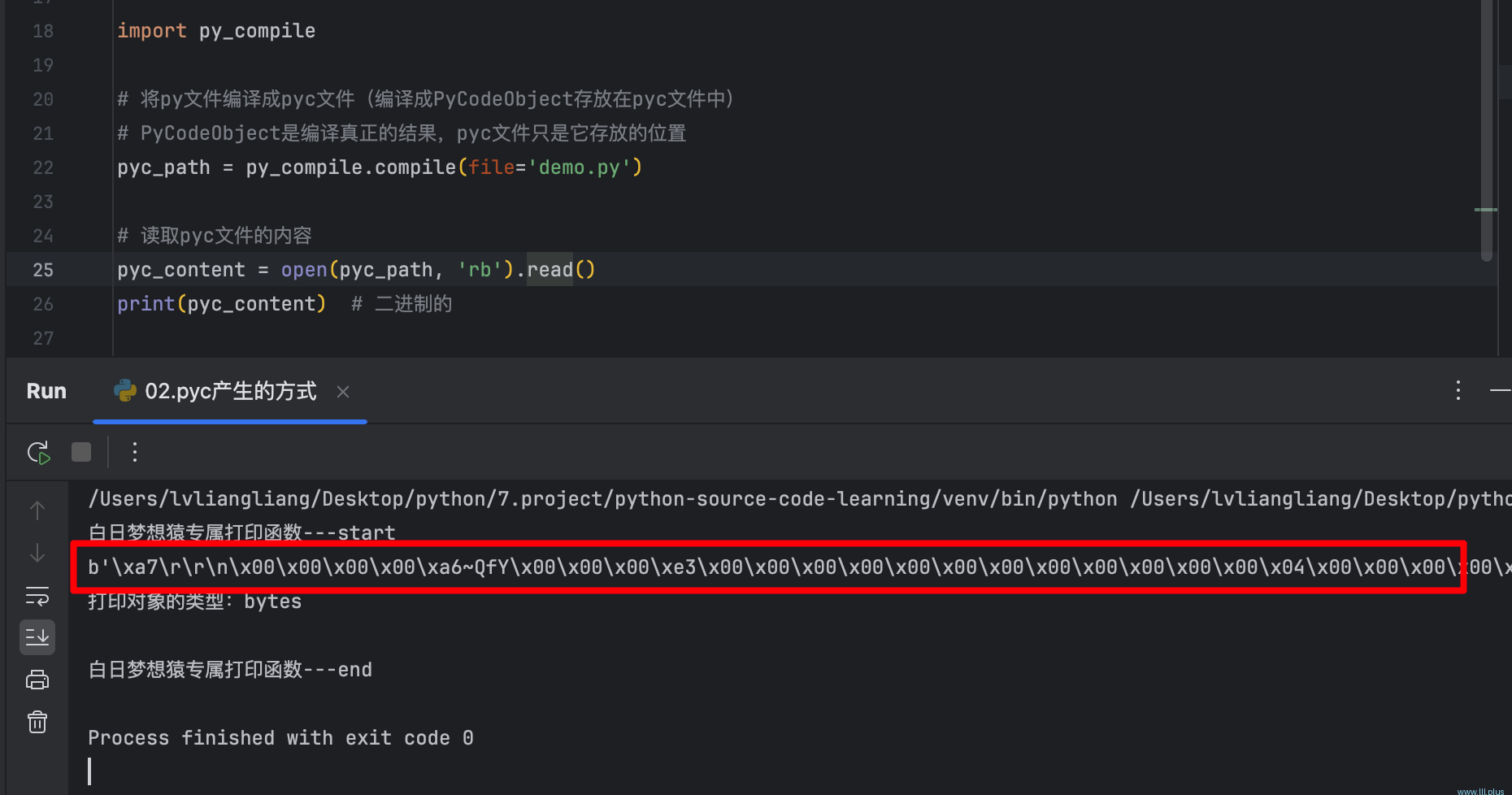
import py_compile# 将py文件编译成pyc文件(编译成PyCodeObject存放在pyc文件中)
# PyCodeObject是编译真正的结果,pyc文件只是它存放的位置
pyc_path = py_compile.compile(file='demo.py')# 读取pyc文件的内容
pyc_content = open(pyc_path, 'rb').read()
print(pyc_content) # 二进制的
通过读取pyc文件的内容可以发现,它实际上是一个二进制文件。
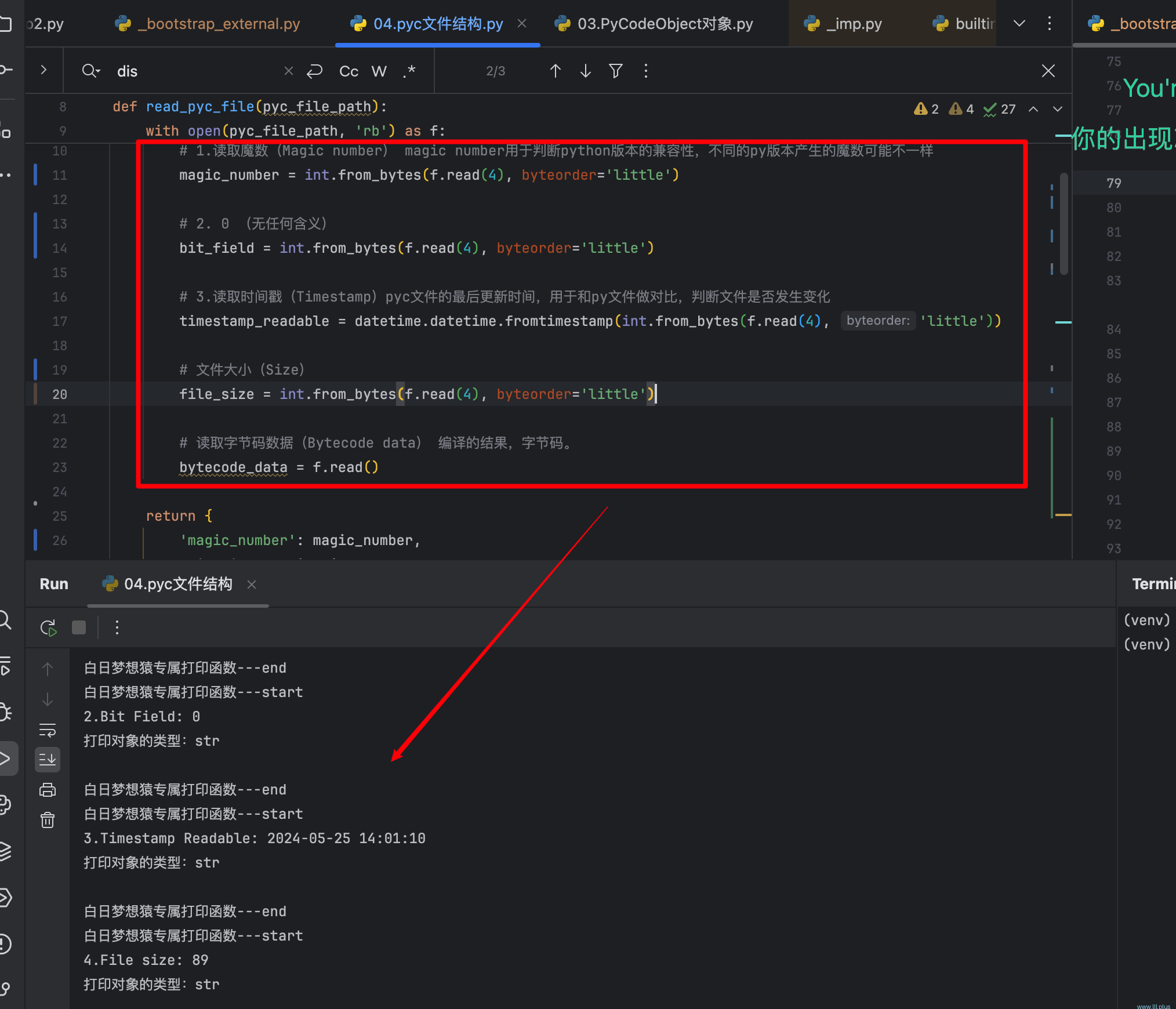
pyc文件的结构
到目前为止,我们已经知道pyc文件是一个二进制文件,用于缓存py文件,那么它的结构是怎样的呢?它里面包含了哪些东西?你是不是不知道该何从下手了?别担心!你是否还记得它是可以通过import机制生成的?那么就说明import机制中一定包含了它生成的逻辑!所以那就让我们一起顺藤摸瓜吧!
”顺着import摸瓜“
当我在阅读《python源码剖析》时,书中介绍的创建pyc的过程是在import.c这个文件中产生的,但我找了很长时间都没有找到相应的逻辑,最后通过查阅各种资料和AI发现这个逻辑已经放在标准库importlib中实现了(这里可能是版本的关系导致的,或许有出入,但问题不大)。

该说不说,python中有一个非常好用的东西,那就是它的异常栈,当一个函数有多处实现,不知道具体是哪个地方的时候,我们在每一个地方“埋雷”,当python解释器不小心踩到我们的雷,它的执行路线就会像多米洛骨牌连续翻倒一样,清晰的展现在我们面前:
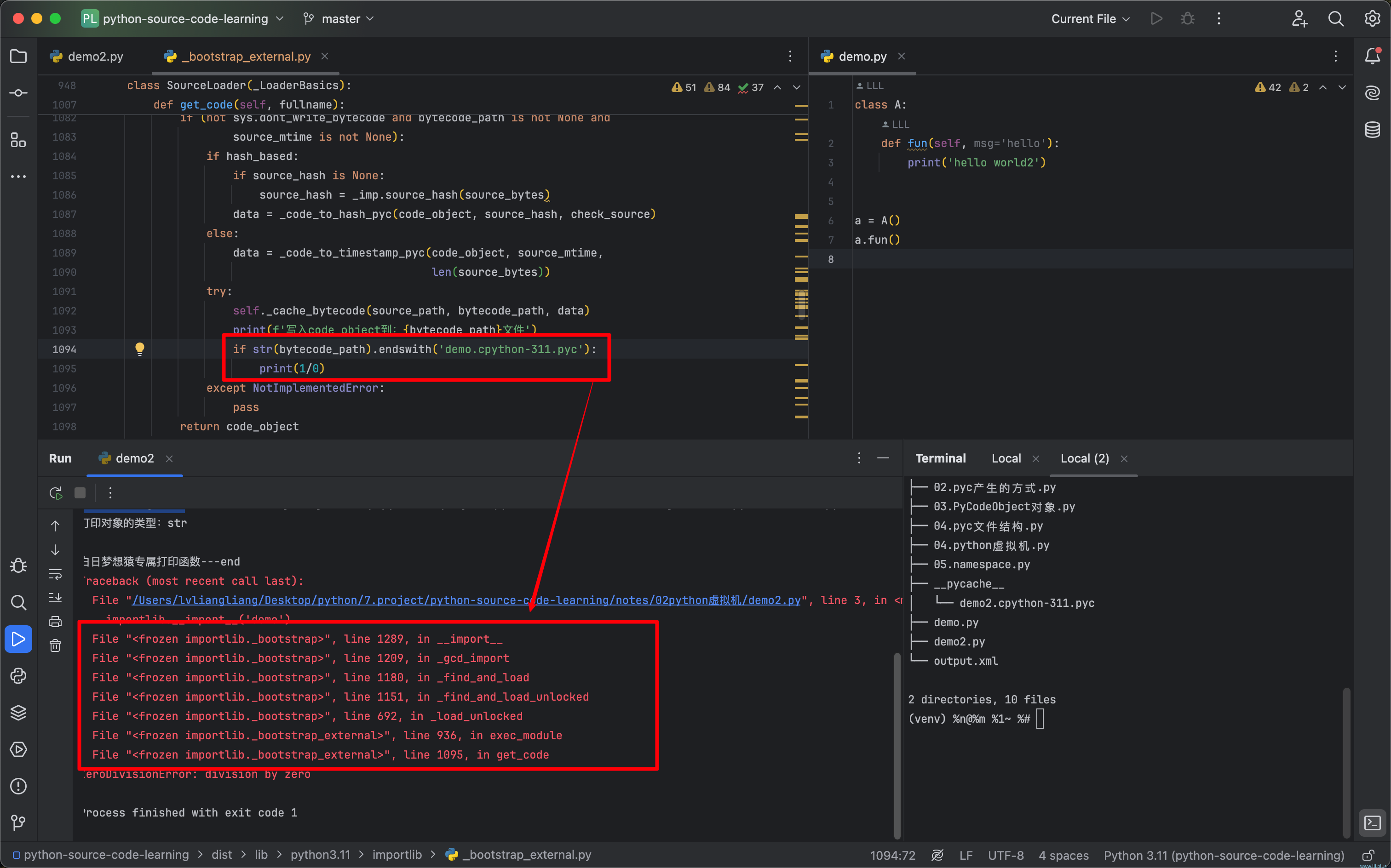
可以看到,import一个模块时,它会走到一个名为get_code的函数中,在此函数中,就包含了pyc文件生成的逻辑,这段代码的大概逻辑就是:
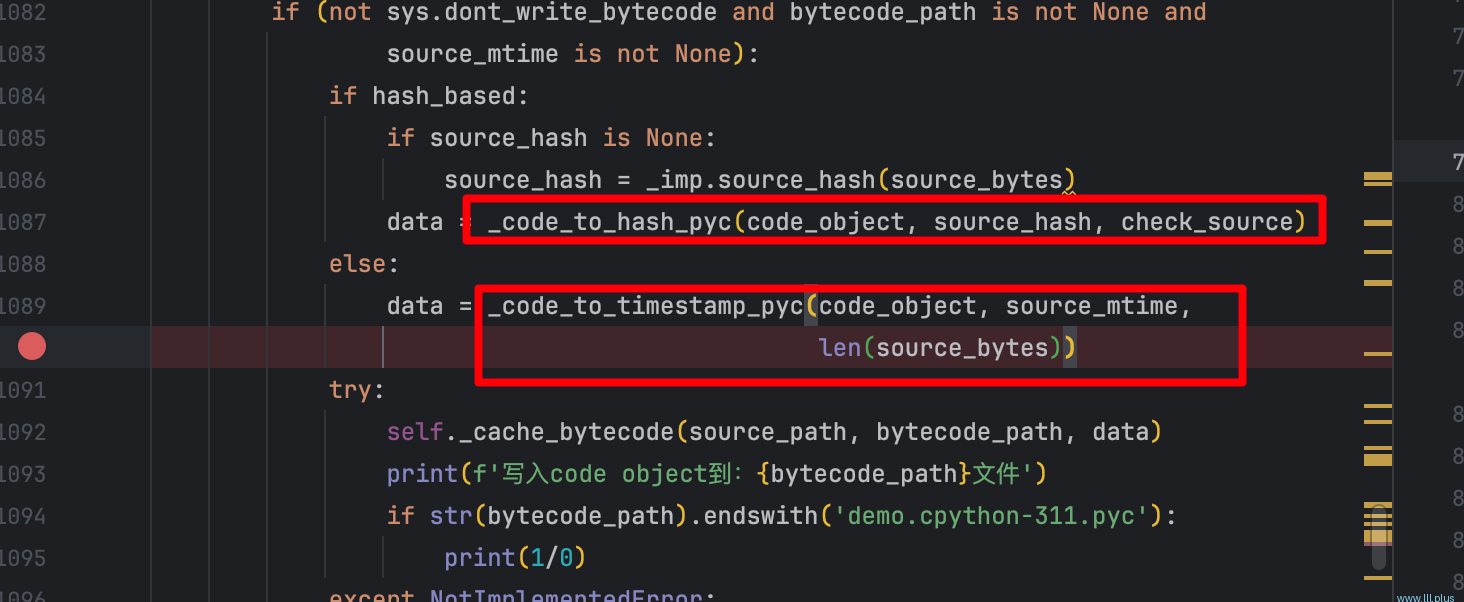
找到模块对应的py路径,根据py路径找到它对应的pyc路径;尝试从pyc中读取,如果读取成功,校验它和py文件中的内容是否一致(这里有两种校验方式:基于hash和基于时间戳),如果是一致的就直接返回;如果发生了变化,就从py中读取得到code obejct,并写入到对应的pyc文件,之后再返回;最后调用exec方法执行返回的code obejct。
def get_code(self, fullname):"""Concrete implementation of InspectLoader.get_code.Reading of bytecode requires path_stats to be implemented. To writebytecode, set_data must also be implemented."""source_path = self.get_filename(fullname)source_mtime = Nonesource_bytes = Nonesource_hash = Nonehash_based = Falsecheck_source = Truetry:# 获取py文件对应的pyc文件的路径bytecode_path = cache_from_source(source_path)except NotImplementedError:bytecode_path = Noneelse:try:"""- 'mtime' (mandatory) is the numeric timestamp of last sourcecode modification;- 'size' (optional) is the size in bytes of the source code."""st = self.path_stats(source_path)except OSError:passelse:# py文件最后的修改时间source_mtime = int(st['mtime'])try:data = self.get_data(bytecode_path)except OSError:passelse:exc_details = {'name': fullname,'path': bytecode_path,}try:flags = _classify_pyc(data, fullname, exc_details)bytes_data = memoryview(data)[16:]hash_based = flags & 0b1 != 0if hash_based:check_source = flags & 0b10 != 0if (_imp.check_hash_based_pycs != 'never' and(check_source or_imp.check_hash_based_pycs == 'always')):source_bytes = self.get_data(source_path)source_hash = _imp.source_hash(_RAW_MAGIC_NUMBER,source_bytes,)_validate_hash_pyc(data, source_hash, fullname,exc_details)else:_validate_timestamp_pyc(data,source_mtime,st['size'],fullname,exc_details,)except (ImportError, EOFError):passelse:_bootstrap._verbose_message('{} matches {}', bytecode_path,source_path)return _compile_bytecode(bytes_data, name=fullname,bytecode_path=bytecode_path,source_path=source_path)if source_bytes is None:source_bytes = self.get_data(source_path)code_object = self.source_to_code(source_bytes, source_path)_bootstrap._verbose_message('code object from {}', source_path)if (not sys.dont_write_bytecode and bytecode_path is not None andsource_mtime is not None):if hash_based:if source_hash is None:source_hash = _imp.source_hash(source_bytes)data = _code_to_hash_pyc(code_object, source_hash, check_source)else:data = _code_to_timestamp_pyc(code_object, source_mtime,len(source_bytes))try:self._cache_bytecode(source_path, bytecode_path, data)print(f'写入code object到:{bytecode_path}文件')if str(bytecode_path).endswith('demo.cpython-311.pyc'):print(1/0)except NotImplementedError:passreturn code_object
直白一点就是:如果有现成的,判断一下是不是最新的,如果是就用现成的(pyc);如果没有(或者不是最新的),就现场生成一个。所以,这里就是pyc能够提升加载速度的逻辑,在加载一个模块时,python解释器会先把我们写的代码进行“编译”,然后将“编译”好的代码再拿去执行,同时会将编译的结果写到pyc文件中,当再次需要导入这个模块时,如果已经有编译好的pyc文件,并且是最新的,就直接使用它就好,这样就省去了“编译”的时间。其实就是一个缓存的逻辑!
pyc文件的内容
还是在get_code这个函数中,我们可以找到两种生成pyc文件的方式:
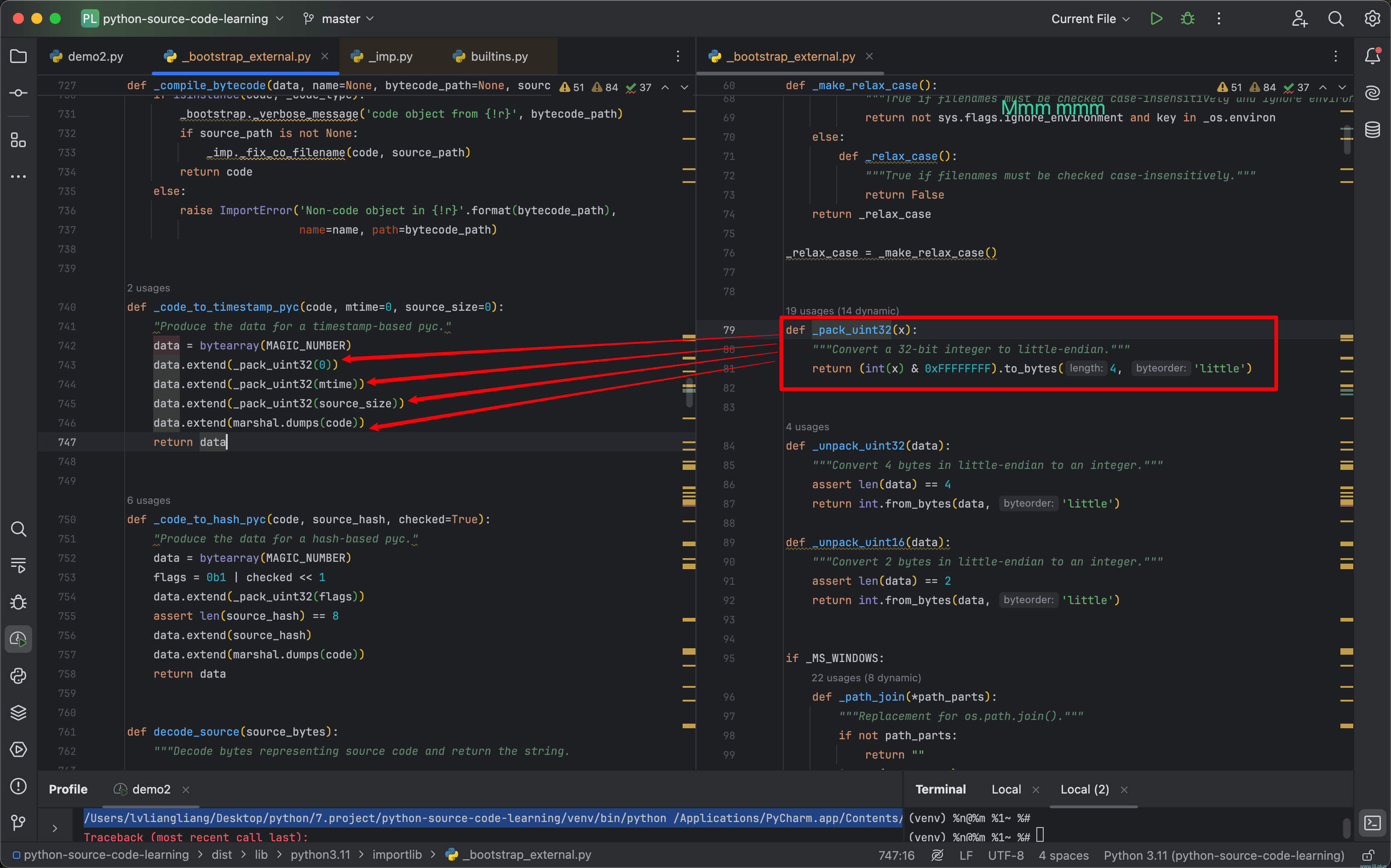
分别是基于时间戳和hash值的两种方式,以基于时间戳的方式为例,它的具体逻辑如下:
基于当前的python解释器的版本MAGIC_NUMBER生成一个字节数组,之后在添加其他的一些数据:mtime(源文件最后的编辑时间),source_size(源文件的大小),code(源码编译后的结果)以及一个无任何含义的0(可能是官方预留的),注意:除了code以外,其他数据的长度都是4,这就是pyc文件的所有内容,它们分别是:magic_number,mtine,0,source_size,code(不同的python版本内容可能有出入,我这里是py3-11-7)。
tips:magic_number主要用于判断解释器和当前要执行的python代码是否兼容,你可以尝试用py3-7编译一个pyc文件,然后用py3-11去执行,它会抛出一个magic_number不兼容的错误。
为了证实pyc真的就是如上那些内容,我们可以试着解析一个pyc文件试试!
code object
到目前为止,我们一直围绕着pyc文件在转,从它的生成逻辑到它结构内容,以及它的意义,对它的了解应该算是了如指掌了!但是我们似乎忽略了一个重要的环节—“编译”,源文件是如何被编译的,以及它的编译结果是什么?
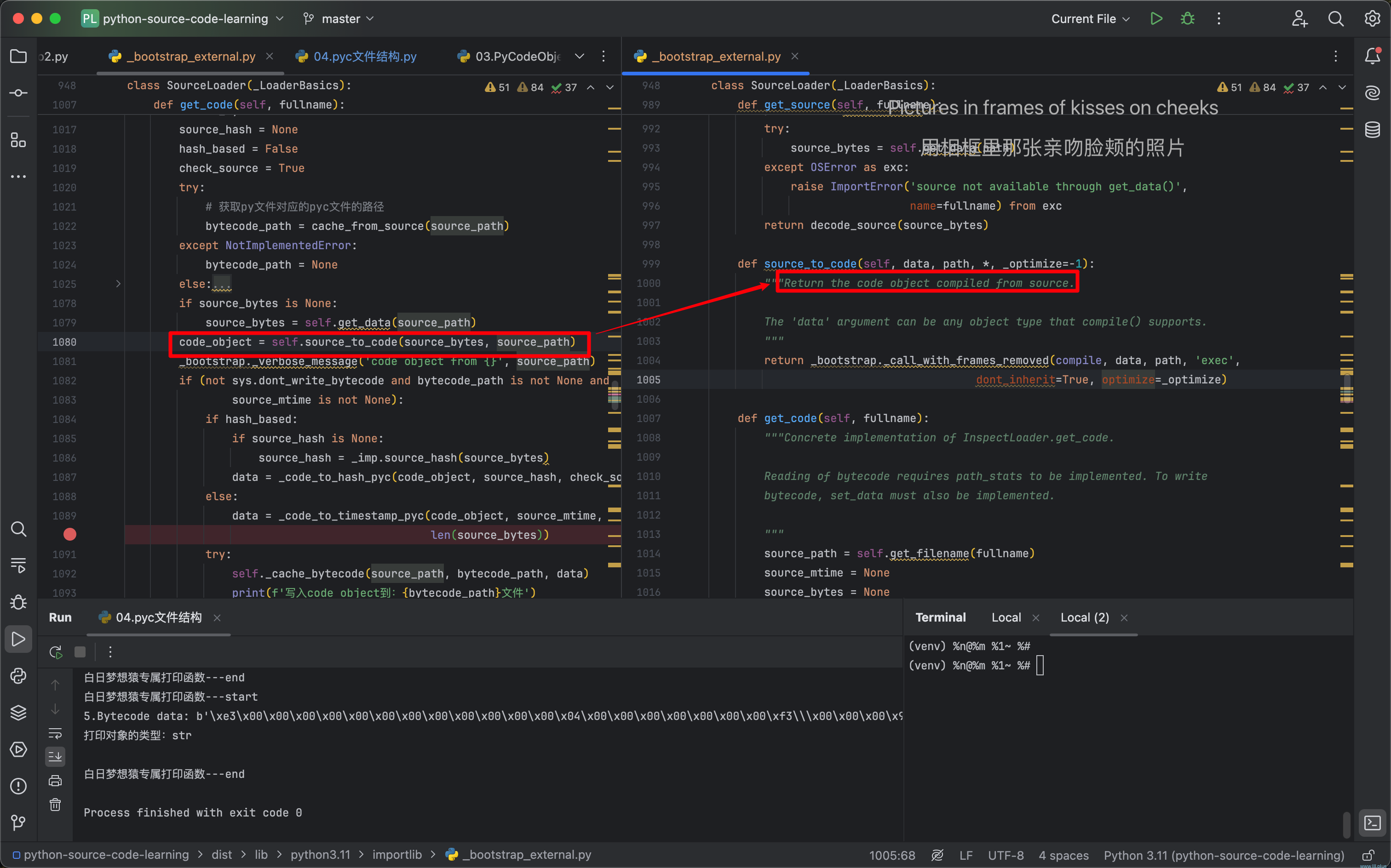
通过源代码可以发现,其实就是调用了内置的compile方法对源文件的内容进行了“编译”,编译的结果通过调用type方法可以知道是:code object。
tips:关于compile内部是如何执行的,可以参考python源文件中的Python/compile.c文件。
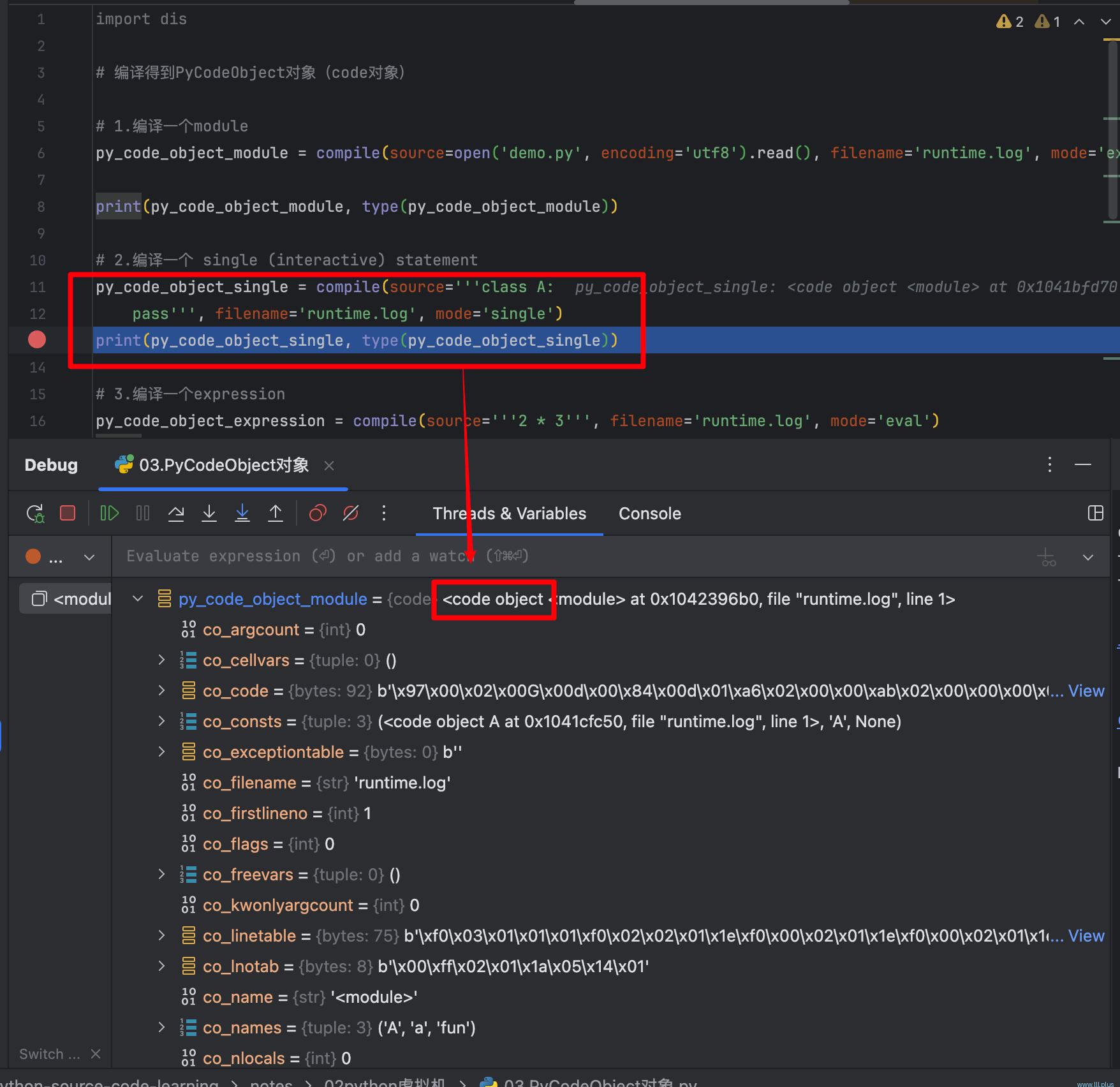
code object的结构
在探究code object的结构之前,我们可以先来看一下它所对应的源码的内容是怎样的,以demo.py文件为例,它的内容如下:
class A:def fun(self, msg='hello'):print('hello world2')a = A()
a.fun()
可以看到:它包含了一个类A,类下面包含了一个方法fun,fun有两个参数,一个是self,另外一个是msg,fun中执行了一个打印字符串“hello world2”,同时在全局下,它还包含了一个变量a,a调用了方法fun,这就是所有的内容,如果你是python的开发者,你会如何将它“编译”成你需要的内容?
想一想,这里面是不是一个嵌套关系:在全局下,它包含了一个类型A和一个实例a;在类型A中,它包含了一个方法fun;在方法fun中,它包含了一个位置参数self和一个关键字参数msg,且默认值是“hello”,同时它内部还包含了一个字符串“hello world2”;如何存储这些信息以及它们之间的关系呢?
实际上code object也是类似于这样的一个嵌套对象,每一个code object对象有它自己的属性,同时code object里面可以包含其他code object,每一个code object都可以看成是一个域(或者是一个code block(代码块)),而这个域就可以是上面说的哪些对象:可以是一个模块,可以是一个类,可以是一个函数,可以是一个方法…
demo.py编译得到的code object如下:
code object各属性含义如下:
| 属性名称 | 含义 |
|---|---|
| co_argcount | 位置参数的数量。 |
| co_kwonlyargcount | 关键字参数的数量。 |
| co_nlocals | 局部变量的数量。 |
| co_stacksize | 所需的栈大小。 |
| co_flags | 编译标志。 |
| co_code | 实际的字节码指令。 |
| co_consts | 常量池(字面量、元组等)。 |
| co_names | 在字节码中使用的名称列表。 |
| co_varnames | 局部变量名列表。 |
| co_filename | 源代码文件名。 |
| co_name | 代码对象的名称。 |
| co_firstlineno | 第一行的行号。 |
| co_lnotab | 行号表(字节码到源代码行号的映射)。 |
| co_freevars | 自由变量的名称(闭包中使用的变量)。 |
| co_cellvars | 闭包中绑定的局部变量的名称。 |
每一个code object中都有一个重要的属性,就是co_code,它存储了字节码指令,在实际执行的时候,会根据不同的字节码指令执行不同的操作;当前code object如果包含了其他的code object,它们都会被存储在co_consts这个属性中。
解析code object对象
为了更加清晰地看到code object的嵌套结构,我们可以使用json或者xml结构来展示它的结构:
import dis
import types
import xml.etree.ElementTree as ET
from notes.utils import utils
import marshal
import pprintdef parse_code_object(code_object, result={}):"""将code对象转成json"""# 反编译当前的code object对象,得到字节码指令print(f'{code_object.co_name}')dis.dis(code_object)keys = ['co_name', 'co_names', 'co_consts', 'co_argcount', 'co_cellvars', 'co_code', 'co_exceptiontable','co_filename','co_firstlineno', 'co_flags', 'co_freevars', 'co_kwonlyargcount', 'co_lines', 'co_linetable', 'co_lnotab','co_nlocals', 'co_positions', 'co_posonlyargcount', 'co_qualname', 'co_stacksize', 'co_varnames', 'replace']# 赋值for key in keys:result[key] = getattr(code_object, key)result['co_consts'] = []co_consts = code_object.co_constsfor co_const in co_consts:if isinstance(co_const, types.CodeType):_result = {}parse_code_object(co_const, _result)result['co_consts'].append(_result)else:result['co_consts'].append(co_const)def code_object_to_xml(co, parent_element):code_element = ET.SubElement(parent_element, 'code')code_element.attrib['co_name'] = co.co_nameET.SubElement(code_element, 'co_name').text = co.co_nameET.SubElement(code_element, 'co_filename').text = co.co_filenameET.SubElement(code_element, 'co_firstlineno').text = str(co.co_firstlineno)ET.SubElement(code_element, 'co_argcount').text = str(co.co_argcount)ET.SubElement(code_element, 'co_kwonlyargcount').text = str(co.co_kwonlyargcount)ET.SubElement(code_element, 'co_nlocals').text = str(co.co_nlocals)ET.SubElement(code_element, 'co_stacksize').text = str(co.co_stacksize)ET.SubElement(code_element, 'co_flags').text = str(co.co_flags)ET.SubElement(code_element, 'co_varnames').text = str(co.co_varnames)ET.SubElement(code_element, 'co_names').text = str(co.co_names)# ET.SubElement(code_element, 'co_consts').text = str(co.co_consts)ET.SubElement(code_element, 'co_lnotab').text = co.co_lnotab.hex()co_code_element = ET.SubElement(code_element, 'co_code')co_code_element.text = co.co_code.hex()# Recursively process nested code objectsfor const in co.co_consts:if isinstance(const, types.CodeType):co_consts = ET.SubElement(code_element, 'co_consts')code_object_to_xml(const, co_consts)# code object它是可能是一个嵌套的对象,可以转成json或者xml进行可视化展示pyc_file_path = '__pycache__/demo.cpython-311.pyc'
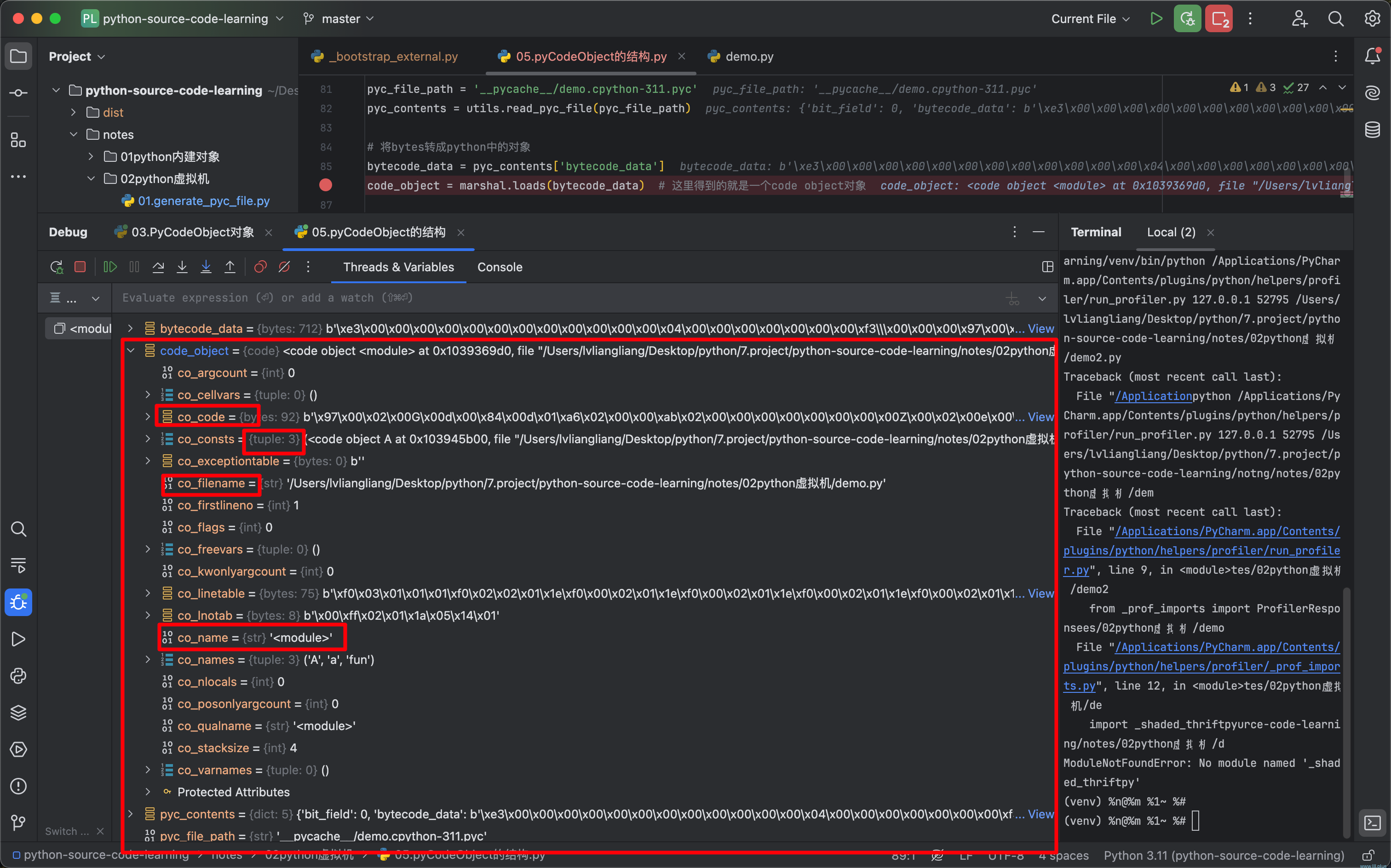
pyc_contents = utils.read_pyc_file(pyc_file_path)# 将bytes转成python中的对象
bytecode_data = pyc_contents['bytecode_data']
code_object = marshal.loads(bytecode_data) # 这里得到的就是一个code object对象# xml
root = ET.Element('root')
code_object_to_xml(code_object, root)
tree = ET.ElementTree(root)
file_path = 'output.xml'
tree.write(file_path, encoding='utf-8', xml_declaration=True)# json
result = {}
parse_code_object(code_object, result)pprint.pprint(result, sort_dicts=False)
解析的xml结构如下:
<?xml version='1.0' encoding='utf-8'?>
<root><code co_name="<module>"><co_name><module></co_name><co_filename>/Users/lvliangliang/Desktop/python/7.project/python-source-code-learning/notes/02python虚拟机/demo.py</co_filename><co_firstlineno>1</co_firstlineno><co_argcount>0</co_argcount><co_kwonlyargcount>0</co_kwonlyargcount><co_nlocals>0</co_nlocals><co_stacksize>4</co_stacksize><co_flags>0</co_flags><co_varnames>()</co_varnames><co_names>('A', 'a', 'fun')</co_names><co_lnotab>00ff02011a051401</co_lnotab><co_code>970002004700640084006401a6020000ab0200000000000000005a0002006500a6000000ab0000000000000000005a016501a0020000000000000000000000000000000000000000a6000000ab000000000000000000010064025300</co_code><co_consts><code co_name="A"><co_name>A</co_name><co_filename>/Users/lvliangliang/Desktop/python/7.project/python-source-code-learning/notes/02python虚拟机/demo.py</co_filename><co_firstlineno>1</co_firstlineno><co_argcount>0</co_argcount><co_kwonlyargcount>0</co_kwonlyargcount><co_nlocals>0</co_nlocals><co_stacksize>2</co_stacksize><co_flags>0</co_flags><co_varnames>()</co_varnames><co_names>('__name__', '__module__', '__qualname__', 'fun')</co_names><co_lnotab>0a01</co_lnotab><co_code>970065005a0164005a026404640284015a0364035300</co_code><co_consts><code co_name="fun"><co_name>fun</co_name><co_filename>/Users/lvliangliang/Desktop/python/7.project/python-source-code-learning/notes/02python虚拟机/demo.py</co_filename><co_firstlineno>2</co_firstlineno><co_argcount>2</co_argcount><co_kwonlyargcount>0</co_kwonlyargcount><co_nlocals>2</co_nlocals><co_stacksize>3</co_stacksize><co_flags>3</co_flags><co_varnames>('self', 'msg')</co_varnames><co_names>('print',)</co_names><co_lnotab>0201</co_lnotab><co_code>97007401000000000000000000006401a6010000ab010000000000000000010064005300</co_code></code></co_consts></code></co_consts></code>
</root>
我们写的代码是如何执行的?
还记得我们最开始的疑惑吗?—”我们写的代码是如何执行的?“,到现在为止,我们从pyc文件“下手”,搞懂了一个模块被加载时,它的源代码会被编译成code object对象,这是一个嵌套的对象,它包含了执行源代码需要的所有信息,为了提高加载速度,这个对象也会被缓存到对应的pyc文件中,所以,从这一点看,pyc文件只不过是一个载体,用于暂时存储code object罢了,code object才是我们后续研究的重点!想象一下,现在我们已经拿到包含字节码(虽然目前我们还不知道这是啥)的code object对象,虽然不知道它后续是什么样的,但是我们能够肯定的是:我们离python解释器已经更近一步了,离我们的代码被它执行的距离也越来越近了,这是一个好的开始!暂且记录我们的进度为50%吧,当我们的这个进度为100时,我们就能彻底搞清楚这个执行的过程啦!加油,后面我们再继续探索!🐢🐢🐢
更多内容可以关注博主的个人博客系统:《Python源码剖析》之pyc文件
相关文章:
《Python源码剖析》之pyc文件
前言 前面我们主要围绕pyObject和pyTypeObject聊完了python的内建对象部分,现在我们将开启新的篇章—python虚拟机,将聚焦在python的执行部分,搞懂从“代码”到“执行”的过程。开启新的篇章之前,你也许会有一个疑惑:我…...
Python零基础-中【详细】
接上篇继续: Python零基础-上【详细】-CSDN博客 目录 十、函数式编程 1、匿名函数lambda表达式 (1)匿名函数理解 (2)lambda表达式的基本格式 (3)lambda表达式的使用场景 (4&…...

回溯 leetcode
22. 括号生成 数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 1: 输入:n 3 输出:["((()))","(()())","(())()","()(())"…...

Android firebase消息推送集成 FCM消息处理
FirebaseMessagingService 是 Firebase Cloud Messaging (FCM) 提供的一个服务,用于处理来自 Firebase 服务器的消息。它有几个关键的方法,你提到的 onMessageReceived、doRemoteMessage 和 handleIntent 各有不同的用途。下面逐一解释这些方法的作用和用…...

react中怎么为props设置默认值
在React中,你可以使用ES6的类属性(class properties)或者函数组件中的默认参数(default parameters)来定义props的默认值。 1.类组件中定义默认props 对于类组件,你可以在组件内部使用defaultProps属性来…...
企业如何做好 SQL 质量管理?
研发人员写 SQL 操作数据库想必一定是一类基础且常见的工作内容。如何避免 “问题” SQL 流转到生产环境,保证数据质量?这值得被研发/DBA/运维所重视。 什么是 SQL 问题? 对于研发人员来说,在日常工作中,大部分都需要…...

半年不在csdn写博客,总结一下这半年的学习经历,coderfun的一些碎碎念.
前言 自从自己建站一来,就不在csdn写博客了,但是后来自己的网站因为资金问题不能继续维护下去,所以便放弃了自建博客网站来写博客,等到以后找到稳定,打算满意的工作再来做自己的博客网站。此篇博客用来记录自己在csdn…...

c++中的命名空间与缺省参数
一、命名空间 1、概念:在C/C中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存 在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化, 以避免命名冲突或…...
SpringBoot整合WebSocket实现聊天室
1.简单的实现了聊天室功能,注意页面刷新后聊天记录不会保存,后端没有做消息的持久化 2.后端用户的识别只简单使用Session用户的身份 0.依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-…...

llama-factory学习个人记录
框架、模型、数据集准备 1.llama-factory部署 # 克隆仓库 git clone https://github.com/hiyouga/LLaMA-Factory.git # 创建虚拟环境 conda create --name llama_factory python3.10 # 激活虚拟环境 conda activate llama_factory # 安装依赖 cd LLaMA-Factory pip install -…...
VLC播放器(全称VideoLAN Client)
一、简介 VLC播放器(全称VideoLAN Client)是一款开源的多媒体播放器,由VideoLAN项目团队开发。它支持多种音视频格式,并能够在多种操作系统上运行,如Windows、Mac OS X、Linux、Android和iOS等。VLC播放器具备播放文件…...

跟小伙伴们说一下
因为很忙,有一段时间没有更新了,这次先把菜鸟教程停更一下,因为自己要查缺补漏一些细节问题,而且为了方便大家0基础也想学C语言,这里打算给大家开一个免费专栏,这里大家就可以好好学习啦,哪怕0基…...

学 C/C++ 具体能干什么?
学习 C 和 C 后,你可以从事许多不同的工作和项目,这两种语言以其高性能和低级控制而闻名,特别适合以下几个领域: 1. 系统编程 C 和 C 是系统编程的首选语言,适用于操作系统、驱动程序和嵌入式系统开发。 操作系统开发…...

Django之Ajax实战笔记--城市级联操作
1. 项目架构搭建 1.1 创建项目tpdemo,创建应用myapp # 创建项目框架tpdemo$ django-admin startproject tpdemo$ cd tpdemo# 在项目中创建一个myapp应用$ python manage.py startapp myapp# 创建模板目录$ mkdir templates$ mkdir templates/myapp$ cd ..$ tree tpdemotpdemo…...
基于Netty实现WebSocket服务端
本文基于Netty实现WebSocket服务端,实现和客户端的交互通信,客户端基于JavaScript实现。 在【WebSocket简介-CSDN博客】中,我们知道WebSocket是基于Http协议的升级,而Netty提供了Http和WebSocket Frame的编解码器和Handler&#…...

27【Aseprite 作图】盆栽——拆解
1 橘子画法拆解 (1)浅色3 1 0;深色0 2 3 就可以构成一个橘子 (2)浅色 2 1;深色1 0 (小个橘子) (3)浅色 2 1 0;深色1 2 3 2 树根部分 (1)底部画一条横线 (2)上一行 左空2 右空1 【代表底部重心先在右】 (3)再上一行,左空1,右空1 (4)再上一行,左突出1,…...
【开源】2024最新python豆瓣电影数据爬虫+可视化分析项目
项目介绍 【开源】项目基于pythonpandasflaskmysql等技术实现豆瓣电影数据获取及可视化分析展示,觉得有用的朋友可以来个一键三连,感谢!!! 项目演示 【开源】2024最新python豆瓣电影数据爬虫可视化分析项目 项目截图…...
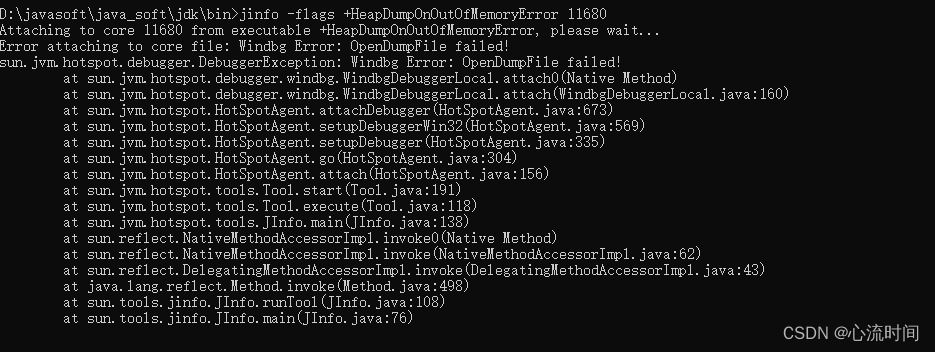
[JDK工具-5] jinfo jvm配置信息工具
文章目录 1. 介绍2. 打印所有的jvm标志信息 jinfo -flags pid3. 打印指定的jvm参数信息 jinfo -flag InitialHeapSize pid4. 启用或者禁用指定的jvm参数 jinfo -flags [|-]HeapDumpOnOutOfMemoryError pid5. 打印系统参数信息 jinfo -sysprops pid6. 打印以上所有配置信息 jinf…...
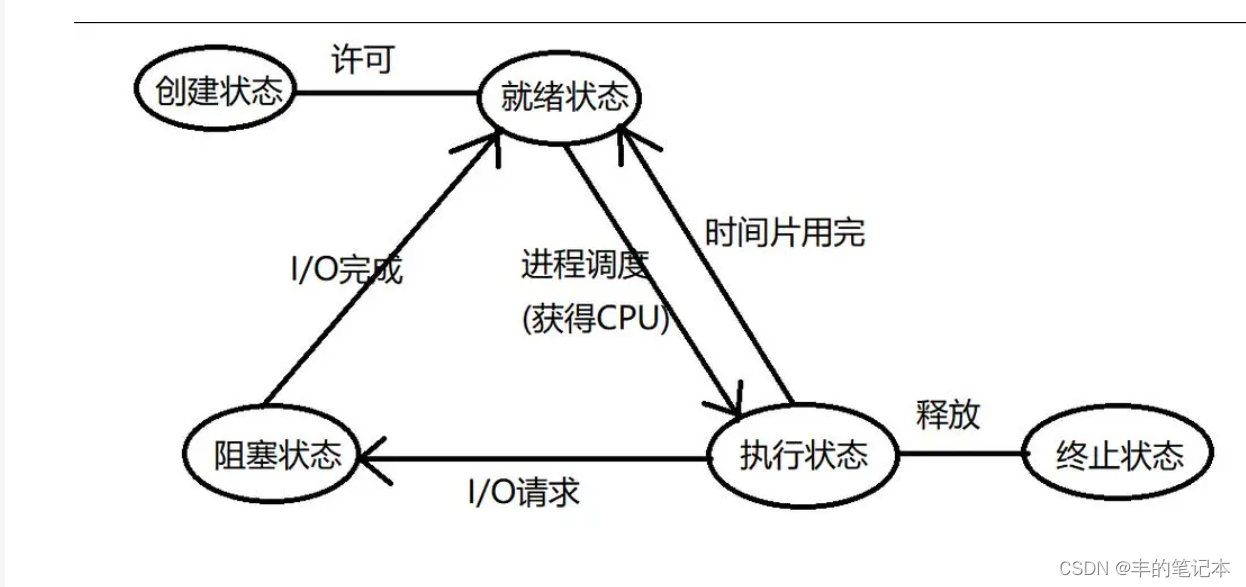
【Linux系统编程】进程概念、进程排队、进程标识符、进程状态
目录 什么是进程? 浅谈进程排队 简述进程属性 进程属性之进程标识符 进程操作之进程创建 初识fork fork返回值 原理角度理解fork fork的应用 进程属性之进程状态 再谈进程排队 进程状态 运行状态 阻塞状态 挂起状态 Linux下的进程状态 “R”(运行状…...
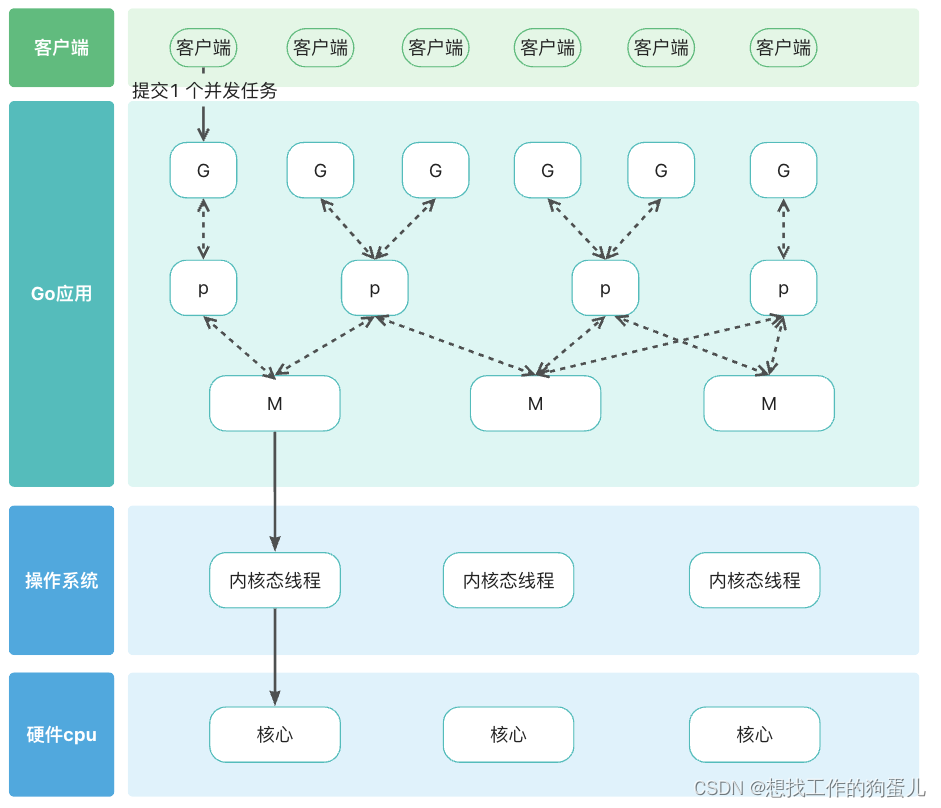
Java与GO语言对比分析
你是不是总听到go与java种种对比,其中在高并发的服务器端应用场景会有人推荐你使用go而不是 java。 那我们就从两者运行原理和基本并发设计来对比分析,看看到底怎么回事。 运行原理对比 java java 中 jdk 已经帮我们屏蔽操作系统区别。 只要我们下载并…...

机器学习赋能冷等离子体种子处理:Extra Trees模型精准预测发芽率提升
1. 项目概述与核心价值 在精准农业的探索前沿,我们常常面临一个看似简单却极其关键的挑战:如何在不损伤种子的前提下,有效提升其发芽率和幼苗活力?传统方法依赖大量重复的田间试验,周期长、成本高,且结果受…...

基于经典机器学习模型的GitHub代码审查评论情感分析实践
1. 项目概述:为什么我们需要分析代码审查评论的情感?在软件开发的日常协作中,代码审查(Code Review)是保证代码质量、促进知识共享和团队协作的核心环节。然而,审查过程不仅仅是技术逻辑的校验,…...

LLM推理解耦技术:提升大型语言模型推理效率的关键方法
1. LLM推理解耦技术概述在大型语言模型(LLM)推理服务领域,推理解耦(Inference Disaggregation)正成为突破传统性能瓶颈的关键技术路径。这项技术的核心思想是将原本耦合的推理流程拆分为具有不同计算特征的独立阶段&am…...

别再为Unity视频播放发愁了!Video Player从创建到避坑,保姆级教程带你搞定
Unity视频播放全攻略:从基础配置到高级避坑技巧在游戏开发中,视频播放功能看似简单,却暗藏诸多玄机。无论是开场动画、过场剧情还是UI背景,流畅的视频体验直接影响玩家第一印象。本文将带你深入Unity Video Player的每一个细节&am…...

序数回归实战:从KNN阈值优化到神经网络模型全解析
1. 项目概述:当回归遇上“有序”世界在机器学习的工具箱里,回归和分类是两大基石。回归预测连续值,比如房价、温度;分类预测离散标签,比如猫、狗、汽车。但现实世界并非总是非黑即白,有一种特殊的数据类型常…...

Java AI 应用开发实践:基于 Spring Boot 实现 Chat、Memory、RAG 与 Tool Calling
前言 这两年 AI 应用开发非常火,越来越多开发者开始尝试把大模型能力接入到自己的业务系统中,比如智能客服、知识库问答、企业助手、代码助手、数据分析助手等。 不过在实际开发过程中,我发现一个比较明显的问题: 很多 AI 应用框架…...
)
gmapping算法源码实现分析(一)
gmapping算法源码实现分析(一) —— slam-gmapping功能包主干流程分析 1. slam_gmapping.cpp 初始化流程: SlamGmapping() 构造函数├─> init() - 创建 GridSlamProcessor 实例,读取参数└─> startLiveSlam() - 设置订阅和回调├─&g…...

安全稀疏矩阵乘法:基于二叉树递归传播的MPC算法优化详解
1. 项目概述:当稀疏矩阵乘法遇上安全多方计算 在分布式机器学习、联合数据分析以及隐私保护推荐系统的构建中,我们常常面临一个核心矛盾:数据的所有权分散在多个互不信任的参与方手中,大家希望共同训练一个模型或进行一次计算&…...

Outlook与Gmail OAuth 2.0 Proxy 实现原理与工程实践
1. 这不是“多此一举”,而是绕不开的现实堵点你写了个邮件聚合工具,用户点击“用 Outlook 登录”——页面跳转到微软登录页,输入账号密码,授权完成,回调地址收到一个 code。你兴冲冲拿它去换 access_token,…...

用Python解放你的记忆:Genanki自动化Anki卡片生成终极指南
用Python解放你的记忆:Genanki自动化Anki卡片生成终极指南 【免费下载链接】genanki A Python 3 library for generating Anki decks 项目地址: https://gitcode.com/gh_mirrors/ge/genanki 你是否曾为手动创建数百张Anki卡片而头痛?是否想过将学…...