软件设计师笔记1
分享一下学习软考时做的笔记,笔者太懒了,后续篇章都没咋记录,现在放出来水几篇文章
另外,本章内容都是结合教材,B站课堂记录。下一篇软考笔记知识点来自真题
软考笔记
第一章
1. 计算机的组成
1. 控制器
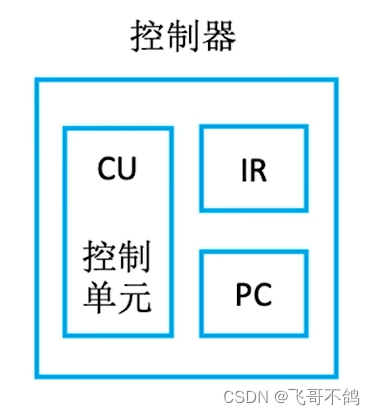
控制器由程序计数器(PC,Program Counter)、指令寄存器(IR,Instruction Register)、指令译码器(ID,Instruction Decoder)、时序产生器(Timing Generator)、操作控制器(Control Unit)组成。
控制器
- 功能:
- 控制CPU的工作,决定运算过程的自动化
- 指令控制逻辑、时序控制逻辑、总线控制逻辑、中断控制逻辑
- 执行过程
- 取指令
- 指令译码
- 指令执行
- 下一条指令地址
- 重要部件
- 指令寄存器IR:将内存中的指令读取到缓冲寄存器,然后送入IR暂存。指令译码器根据IR的内容产生各种微操作指令,控制其它部件完成功能
- 程序计算器PC:PC寄存信息,计数。PC存储下一个指令的所在地址。大多数指令都是顺序执行,因此PC++即可寻找到吓一跳指令的地址。如果遇到转移指令,CPU修改PC内容,获取地址。
- 地址寄存器AR:保存当前CPU访问的内存单元的地址。
- 寄存器组:专用寄存器和通用寄存器。
2. 主存
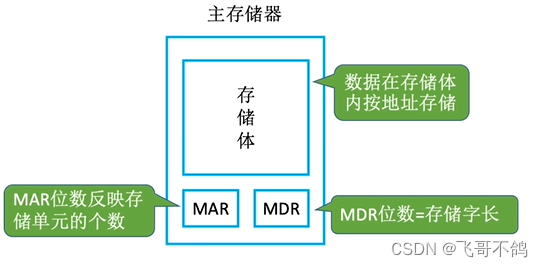
用于存储程序运行时的数据。
MAR:存储地址存储器
MDR:存储数据存储器
3. 运算器
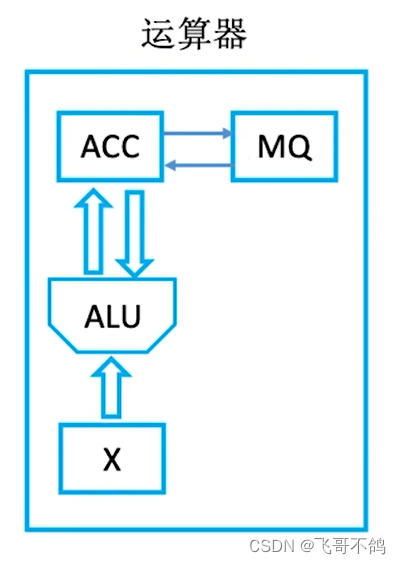
运算器
- 功能:
- 执行所有算数运算。包括加减乘除以及附加运算
- 执行逻辑运算与逻辑测试:与或非、零值测试、两个值比较
-
运算器重要组件
-
算数逻辑单元ALU:实现数据运算与逻辑运算
-
累加寄存器ACC:在计算过程中,为ALU提供一个工作区,存储中间结果。
-
乘商寄存器MQ:乘商寄存器,在乘、除运算时,用于存放操作数或运算结果。
-
数据缓冲寄存器DR:对内存读写时,DR暂时存放存储器读写的一条指令,或者一个数据字段。
-
状态条件寄存器PSW:计算条件状态码。主要分为状态标志,控制标志
- 进位标志(C)
- 溢出标志(V)
- 为0标志(Z)
- 负结果标志(N)
- 中断标志(I)
- 方向标志(D)
- 单步标志
-
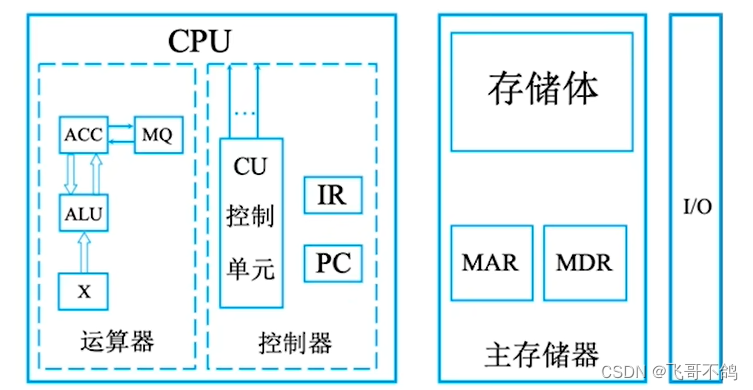
计算机的各个功能部件按照下述形式,组合在一起。协调工作,实现计算机的复杂功能。
2. 数据表示
2.1 原码
1). 正数
短除法计算,看下图
[ 45 ] 原 = 10110 1 2 [45]_{原} = 101101_{2} [45]原=1011012
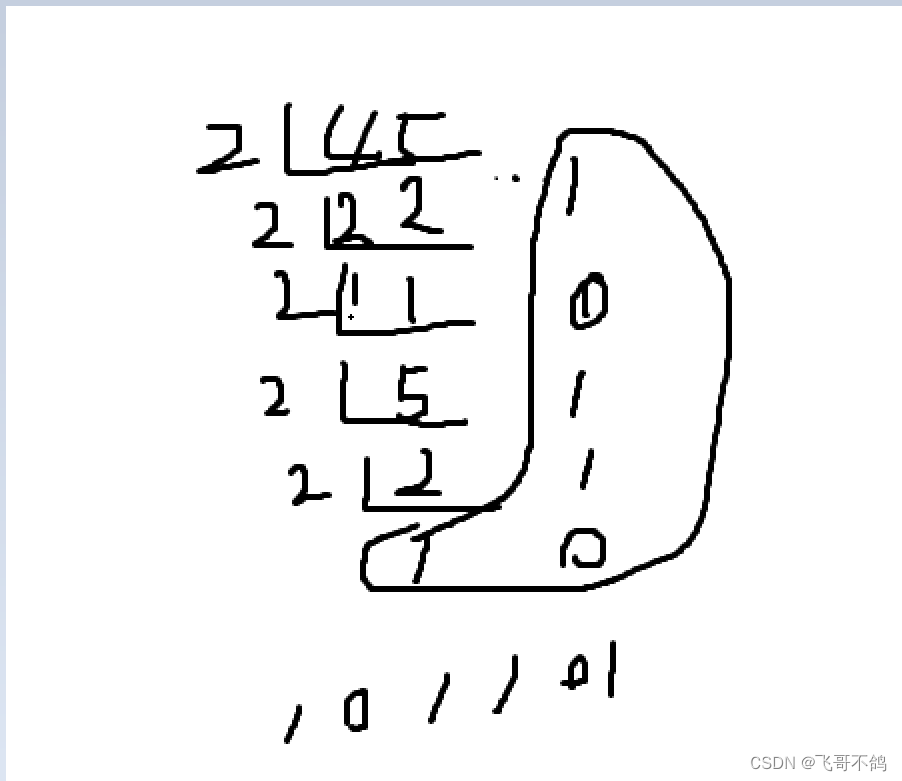
2). 负数
取其绝对值,计算原码。在其最高位上补1,用于表示符号位
- 将负数的绝对值转换为二进制数。
- 如果二进制数的位数不足,可以在左侧用零进行填充,使其达到所需的位数。
- 在最高位添加符号位,通常为 1(表示负数)。
举例来说,将十进制的 -5 转换为 4 位二进制原码:
- 将 5 转换为二进制:
101 - 由于是 4 位原码,需要在左侧用零进行填充:
0101 - 添加符号位 1(表示负数),最终的 4 位二进制原码为
1101。
3). 小数
整数部分正常转换,小数部分按照乘以 2 并记录整数部分的方式来完成
举例说明,将十进制的 5.625 转换为原码:
- 整数部分 5 转换为二进制:
101- 小数部分 0.625 转换为二进制:
0.101- 合并整数和小数部分:
101.101- 因为是正数,符号位为 0。
5.625 的二进制原码表示为
0101.101
所谓的x2记录法,是对小数做x2处理。每次取整数部分作为结果。留下小数部分作为下次x2处理。持续迭代,指导位数达到要求或者小数为0。
对于十进制的小数 0.61825,我们可以使用 “乘以2并记录” 的方法进行转换为二进制。以下是详细步骤:
- 0.61825 乘以 2 等于 1.2365,记录整数部分 1。
- 取新的小数部分 0.2365,再次乘以 2 等于 0.473,记录整数部分 0。
- 取新的小数部分 0.473,再次乘以 2 等于 0.946,记录整数部分 0。
- 取新的小数部分 0.946,再次乘以 2 等于 1.892,记录整数部分 1。
- 取新的小数部分 0.892,再次乘以 2 等于 1.784,记录整数部分 1。
- 取新的小数部分 0.784,再次乘以 2 等于 1.568,记录整数部分 1。
持续进行以上操作,直到小数部分为0或者达到了所需的二进制位数。在这个例子中,我们得到的二进制表示是
0.1010011001100101101
4). 负小数
取小数绝对值,得到原码。然后在最高位补1.表示符号
2.2 反码
负数的反码=负数的原码,除了符号位不变,其余位置全部取反。
小数的反码=整数部分取反 【符号位不变】+ 小数部分取反
tip: 正数的原码=正数的反码
2.3 补码
正数:不变
负数:反码+1
负小数:小数反码 的最后一位 + 1
3. 定点数和浮点数
定点数的补码和移码可以表示 2 n 2^n 2n个数,原码和反码只能表示 2 n − 1 2^{n}-1 2n−1个数(0占用2个编码)。
在十进制中,83.125 可以写成 1 0 3 × 0.083125 10^{3}\times 0.083125 103×0.083125,那么二进制中;二进制数1011.10101可以写成 2 4 × 0.101110101 2^{4}\times 0.101110101 24×0.101110101。因此我们可以得知,一个二进制数N可以写为如下形式: N = 2 E × F N=2^{E}\times F N=2E×F
E称为阶码,F称为尾数。这种表示方式称为浮点表示法
浮点数的表示方式如下:
**|阶符| 阶码 | 数符 | 尾数| **
阶码决定数的范围,尾数决定精度
浮点数规格化,规定尾数范围落在[0.5, 1]之间
3.1 IEEE 754浮点数
浮点数的3中格式
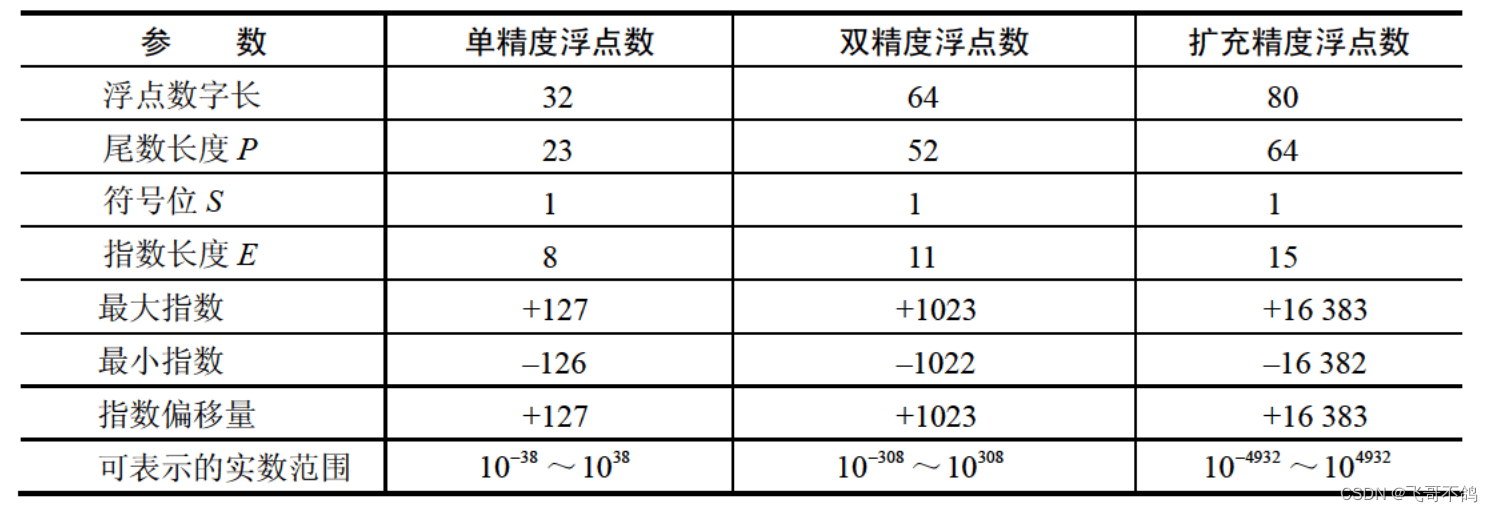
浮点数可以表示为 ( − 1 ) s 2 E ( b 0 b 1 … b p − 1 ) (-1)^s 2^E (b_0 b_1\dots b_{p-1}) (−1)s2E(b0b1…bp−1)
其中, ( − 1 ) s (-1)^s (−1)s为浮点数的数符,当S为0时表示正数,1时为负数。E为指数(阶码),用移码表示。偏移位数由浮点数精度决定。 ( b 0 b 1 … b p − 1 ) (b_0 b_1\dots b_{p-1}) (b0b1…bp−1)为尾数,长度为P位,用原码表示
eg: 用IEEE 754 将176.0625写成单精度浮点数
将176.0625转换为二进制形式。整数部分和小数部分分别转换。
- 整数部分的二进制表示为:10110000
- 小数部分的二进制表示为:0001。
将整数部分和小数部分合并,得到176.0625的二进制表示为10110000.0001。
根据IEEE 754标准,确定符号位、指数位和尾数位的长度。
- 符号位:1位,表示正负号,0表示正数,1表示负数。
- 指数位:8位,用于存储指数部分的偏移量。
- 尾数位:23位,用于存储小数部分的有效位数。
确定符号位:
由于176.0625是正数,所以符号位为0。
规格化二进制数:
将10110000.0001规格化为1.01100000001 × 2^7。
计算偏移量:
指数偏移量为127(单精度浮点数的偏移量是2^(8-1)-1=127),所以偏移量为7 + 127 = 134,对应的二进制为10000110。
将指数和尾数合并:
指数为134的二进制表示为10000110,尾数部分只保留小数点后的23位有效位,即01100000001000000000000。
得到IEEE 754表示:
最后,将符号位、指数位和尾数位合并,得到单精度浮点数的IEEE 754表示为:
0 10000110 01100000001000000000000
因此,176.0625的IEEE 754表示为01000011001100000000100000000000。
浮点数+ -
- 对阶,移动尾数小数点,使得阶数E处于同一数量级。
- 尾数携带符号,进行±计算
- 对得到的结果重新规格化
浮点数x➗
- 阶数相±
- 尾数乘除
- 修改符号位
- 规格化
4. 校验码
4.1 奇偶校验
通过额外添加一个数位,来使原先编码所中1的个数为奇数或偶数。
4.2 海明码
设:数据有m(message)位,校验码有p(parity)位;
则:校验码一共有 2 p 2^p 2p种取值;
若想通过检验码指出任意一位上出现错误,那么必须满足以下式子
2 p − 1 ≥ m + p 2^p - 1 \geq m + p 2p−1≥m+p
理解:p位校验码能够表示 2 p 2^p 2p个数,其中有一种是表示正确的情况。因此,只有 2 p − 1 2^p - 1 2p−1个数能表示错误情况。而海明码的m + p 位都有可能出错,因此校验码最少能够表示m + p个错误。因此得出上述等式。
现在,我们要发送1010数据,数据长度m = 4,由上述式子得出 p >= 3,取最小值 p = 3。校验码一共有三位
现在,我们创建如下表格,将数据填入其中
校验码p1p2p3每一位填写在 2 n ( n = 0 、 1 、 2 … ) 2^n(n=0、1、2\dots) 2n(n=0、1、2…)位置上,剩下位置添加数据码

现在,我们建立p和数据各位之间的关系
p 1 m 3 m 5 m 7 p 2 m 3 m 6 m 7 p 3 m 5 m 6 m 7 p_1 \ \ \ m_3 \ \ \ m_5 \ \ \ m_7 \\ p_2 \ \ \ m_3 \ \ \ m_6 \ \ \ m_7 \\ p_3 \ \ \ m_5 \ \ \ m_6 \ \ \ m_7 \\ p1 m3 m5 m7p2 m3 m6 m7p3 m5 m6 m7
p与m之间的关系,取决于二进制数的位置。例如** p 1 p_1 p1,m对应下标的二进制数**,只要第一位是1,那么就需要和 p 1 p_1 p1构建联系。同理,p2所寻找的m需要满足下标二进制的第二位是1。p3则是二进制第三位是1。
寻找到p与m的关系,就只需要按照奇偶检验码的规则确定p
p 1 0 奇 , 1 偶 1 0 0 p 2 1 奇 , 0 偶 1 1 0 p 3 0 奇 , 1 偶 0 1 0 p_1 \ \ \ 0奇,1偶 \ \ \ 1 \ \ \ 0 \ \ \ 0 \\ p_2 \ \ \ 1奇,0偶 \ \ \ 1 \ \ \ 1 \ \ \ 0 \\ p_3 \ \ \ 0奇,1偶 \ \ \ 0 \ \ \ 1 \ \ \ 0 \\ p1 0奇,1偶 1 0 0p2 1奇,0偶 1 1 0p3 0奇,1偶 0 1 0
将数据填写回表格

现在,我们规定采用奇校验规则,发送方发送数据0110010,接收方收到的数据为0110011,现在接收方进行数据校验,具体校验规则如下
e 1 p 1 m 3 m 5 m 7 e 2 p 2 m 3 m 6 m 7 e 3 p 3 m 5 m 6 m 7 e_1 \ \ \ p_1 \ \ \ m_3 \ \ \ m_5 \ \ \ m_7 \\ e_2 \ \ \ p_2 \ \ \ m_3 \ \ \ m_6 \ \ \ m_7 \\ e_3 \ \ \ p_3 \ \ \ m_5 \ \ \ m_6 \ \ \ m_7 \\ e1 p1 m3 m5 m7e2 p2 m3 m6 m7e3 p3 m5 m6 m7
将接受方接收到的数据上表
e 1 0 1 0 1 e 2 1 1 1 1 e 3 0 0 1 1 e_1\ \ \ 0 \ \ \ 1 \ \ \ 0 \ \ \ 1 \\ e_2 \ \ \ 1 \ \ \ 1 \ \ \ 1 \ \ \ 1 \\ e_3 \ \ \ 0 \ \ \ 0 \ \ \ 1 \ \ \ 1 \\ e1 0 1 0 1e2 1 1 1 1e3 0 0 1 1
根据奇校验规则,解得e1 = 1,e2 = 1,e3 = 1。组合得到e3e2e1 = 111,既m7错误。对比发送数据,发现雀氏是第7位出错。接收方自动将第7位置取0,完成自动纠错
tip: 由e1, e2, e3组合出错误位置时,需要记得顺时针旋转,得到e3e2e1,而不是e1e2e3
4.3 循环冗余校验码 CRC
核心是利用冗余的数据位,检验出错误的数据位。而检验的方式是:模2除法。
假设需要发送的数据是101001,协议规定的除数是1101,确定余数(冗余码)的方法如下:
- 余数长度 = 除数长度 - 1,本题中,余数长度 = 3
- 在发送数据后面添加4个0,得到101001 000
- 用除数循环除以101001 000,具体过程如下

最终计算结果,余数位1. 因为冗余码长度为3,所以最终结果需要在1左边补0.得到001
5. 指令流水
5.1 执行方式
一条指令的执行过程可以分为多个阶段,大部分计算机的指令都可以分为取指,分析,执行三个阶段
顺序执行

指令穿行执行,一条指令执行完后,才能执行下一条指令。
这种执行模式,对于硬件来说实现很容易,但硬件的利用率很低。一般来说,指令的三个阶段所用到的硬件是不同的,也就是说,
取值k结束后可以立刻进行取值k+1,分析k和取指k+1用到不同的硬件,所以可以并行执行
总耗时 T = 3nt
一次重叠执行

总耗时 T = 2nt + t
总耗时减小1/3,但硬件布线复杂
二字重叠
类似,不再赘述
5.2 流水线的性能指标
1.吞吐率
吞吐率:吞吐率是指在单位时间内,流水线完成的任务总数
设任务数为n:处理完成n个任务所用的时间为 T k T_k Tk
则计算流水线吞吐率(TP)的最基本公式为 T P = n T k TP = \frac{n}{T_k} TP=Tkn
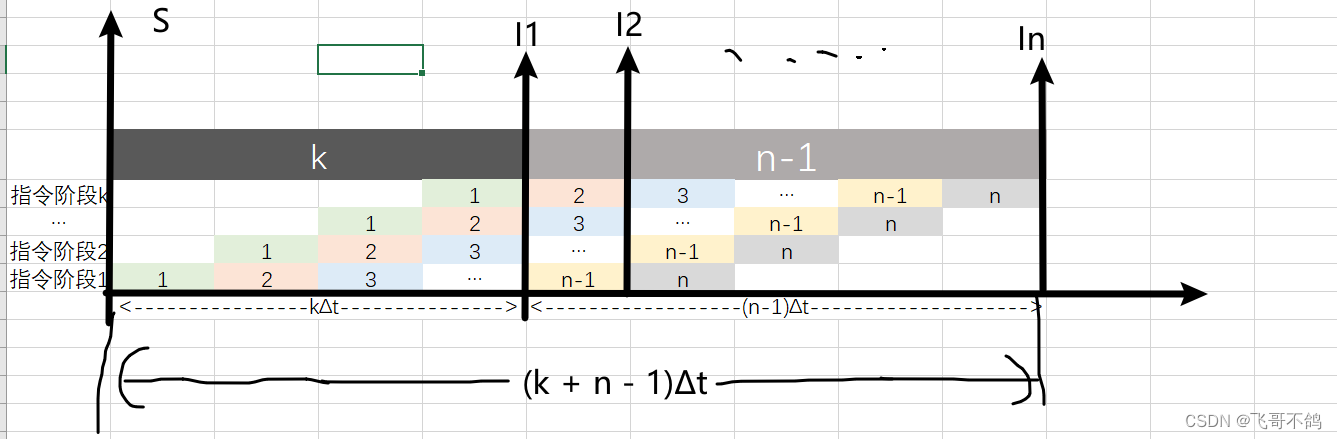
一条指令的执行分为k个阶段,每个阶段耗时Δt,一般取Δt=一个时钟周期,执行n条指令耗时(k + n - 1)Δt,所以吞吐率为
T P = n ( k + n − 1 ) Δ t 当 n − > ∞ 时,取得最大吞吐率 T P m a x = 1 Δ t TP = \frac{n}{(k + n - 1)\Delta t} \\ 当n -> \infty时,取得最大吞吐率 TP_{max} = \frac{1}{\Delta t} TP=(k+n−1)Δtn当n−>∞时,取得最大吞吐率TPmax=Δt1
一般来说,0->I1称为装入时间, I2->In称为排空时间
TP意度量处理任务速度
2.加速比
加速比:完成同一批任务,不适用流水线所用时间与使用流水线的时间之比
设 T 0 T_0 T0为不适用流水线所需时间, T k T_k Tk为使用流水线所需时间,那么可以得到 S = T 0 T k S = \frac{T_0}{T_k} S=TkT0
以上图为例,得到等式如下
S = n k Δ t ( k + n − 1 ) Δ t = n k k + n − 1 当 n − > ∞ , S m a x = k S = \frac{nk\Delta t}{(k + n - 1)\Delta t} = \frac{nk}{k + n - 1} \\ 当n-> \infty ,S_{max} = k S=(k+n−1)ΔtnkΔt=k+n−1nk当n−>∞,Smax=k
理想情况下,引入流水线后,cpu加速了k倍
3.效率
效率:流水线利用率称为流水线效率
在时空图中,意思为完成n个任务占用的时空区有效面积 与 n个任务所用的时间与k个流水段所围成的时空区总面积之比

以上图为例,可得公式
E = k n Δ t k ( k + n − 1 ) Δ t = n k + n − 1 当 n − > ∞ 时, E m a x = 1 E = \frac{kn\Delta t}{k(k + n - 1)\Delta t} = \frac{n}{k + n - 1} \\ 当n->\infty时,E_{max} = 1 E=k(k+n−1)ΔtknΔt=k+n−1n当n−>∞时,Emax=1
E趋近于1意味着引入流水线,硬件几乎都在忙碌
5.3 缓存
为了缓解CPU处理数据速度和内存存取数据速度严重不符的问题,在CPU和内存之间添加新的层次结构,也就是缓存。缓存的处理数据的速度,介于CPU和内存之间。能够有效的提高系统整体的工作效率
1. 缓存-内存系统取值时间
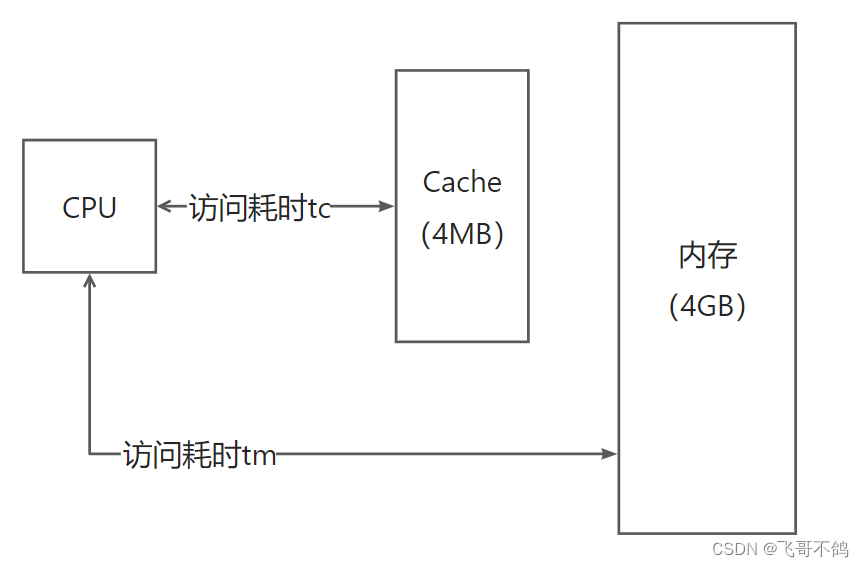
如上图所示,CPU存在两种取值方案
方案一:先去Cache中取值,如果命中则终止取值行为,否则再去内存中取值
方案二:同时去Cache,内存中取值,如果Cache命中,终止内存取值行为,否则等待内存取值完成
现在,假设 t c t_c tc为访问Cache所需时间, T m T_m Tm为内存所需时间。 H H H为CPU在Cache中找到所需数据的概率(命中率)
如果采取方案一,则系统平均访问时间为
t = H t c + ( 1 − H ) ( t c + t m ) t = Ht_c + (1 - H)(t_c + t_m) t=Htc+(1−H)(tc+tm)
如果是方案二,则平均时间为
t = H t c + ( 1 − H ) t m t = Ht_c + (1-H)t_m t=Htc+(1−H)tm
2. 缓存-内存系统,数据交换单位
Cache 存储内存的数据,是以块为单位。我们将主存进行分块,块的大小为1KB。以此为数据交换的单位
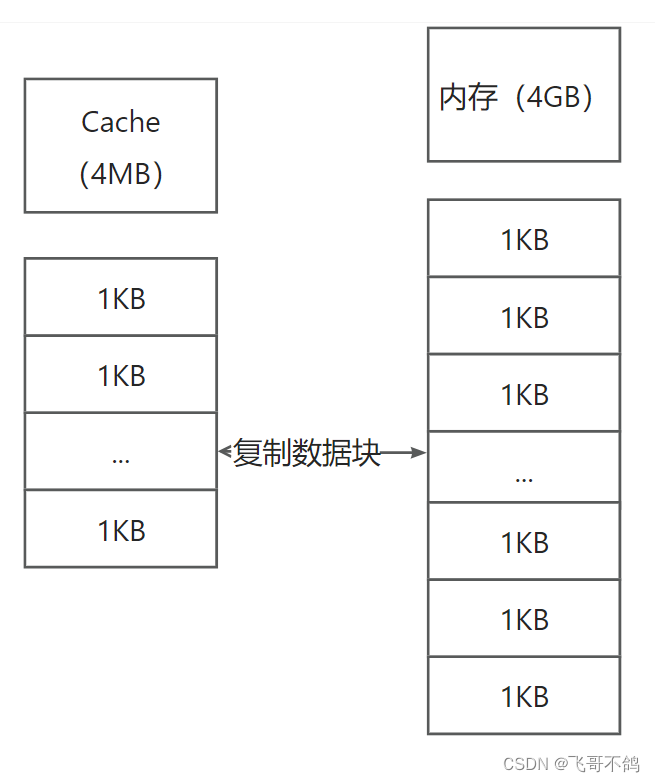
CPU访问Cache,如果数据没有命中,CPU会访问内存。在内存中找到的数据会以数据块的形式缓存到Cache中
3. 缓存-内存系统,数据映射
全相连映射
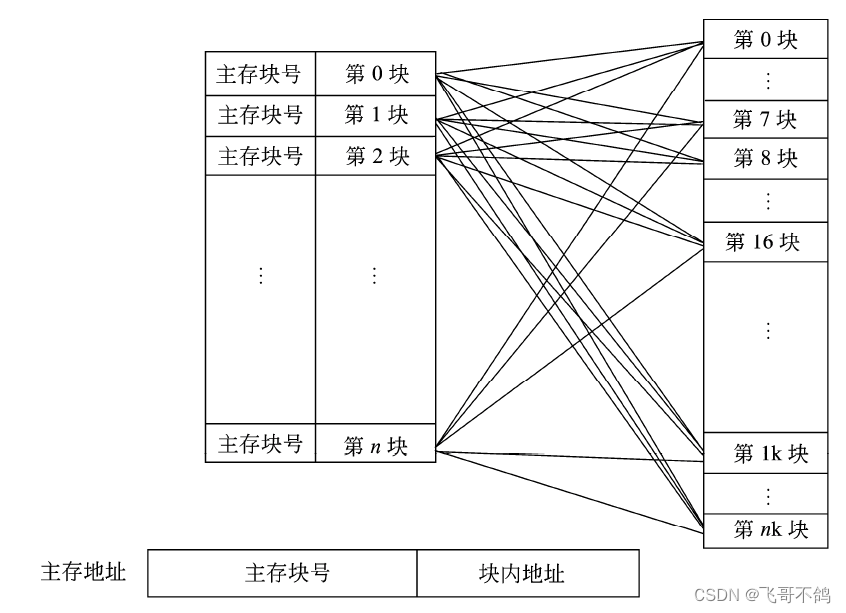
这种映射允许内存块中的任意一块数据,存储在Cache中的任意一行。在将内存数据缓存Cache时,需要在缓存中额外记录当前存储的数据是来自主存的那个区块。
例如,主存为 64MB,Cache 为 32KB,块的大小为4KB(块内地址需要 12 位),因此主存分为 16384 块,块号从 0~16383,表示块号需要 14 位,Cache 分为8块,块号为 0~7,表示块号需3位。
存放主存块号的相联存储器需要有 Cache 块个数相同数目的单元(该例中为 8)相联存储器中每个单元记录所存储的主存块的块号,该例中相联存储器每个单元应为 14 位,共8个单元。
主存地址包含主存块号,块内地址。本例中,主存为64MB,64MB = 2 26 2^{26} 226,主存块号需要14位,那么块内地址需要 26 - 14 = 12位。
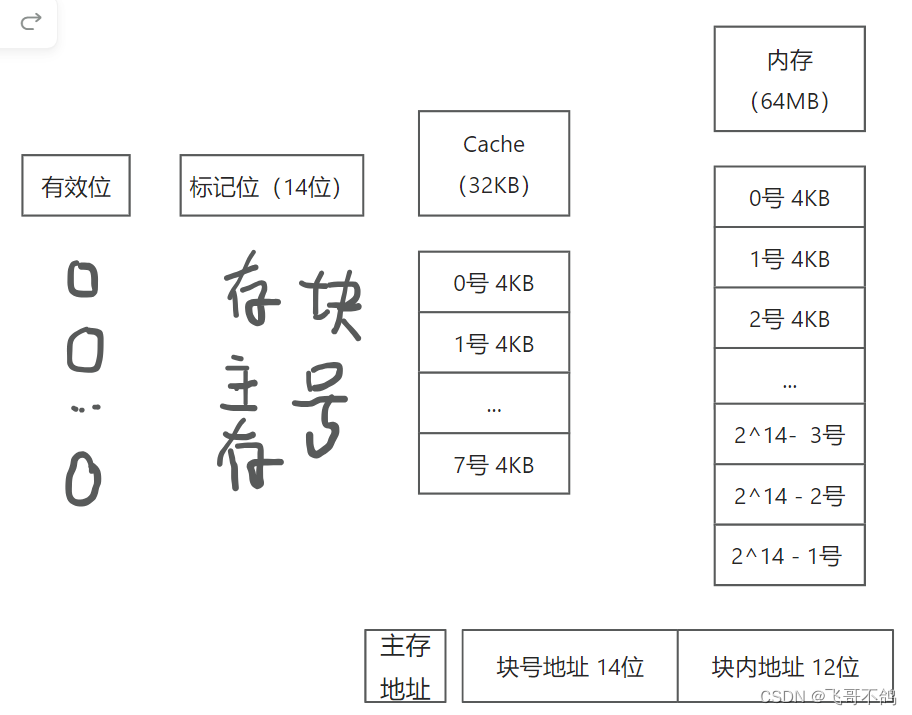
CPU在访问主存地址 1101 1011 1011 101101 1111 1011,主存地址的前14位存放的是主存块号信息。取前14位和标记位进行比对
如果标记位匹配并且有效位有效,那么Cache命中,访问块内1101 1111 1011号地址的数据。
如果没有匹配或标记位为0,那么取主存中寻址,获取数据。同时将数据缓存在Cache中,更改有效位,存储标记位。
直接映射
主存块在Cache中的 位置 = 贮存块号 % C a c a h e 总块数 位置 = 贮存块号 \ \ \% \ \ Cacahe总块数 位置=贮存块号 % Cacahe总块数
通过取余的方式,我们可以将主存块划分为若干个区间。区间内的块数据依次映射到Cache中
这种方式有个很大的缺陷,每个区间相同位置的数据会映射到同一个Cache块上。比如0区间的第一块数据,和1区间第一块数据映射在Cache的同一个位置。后者需要缓存时,必须覆盖前者数据
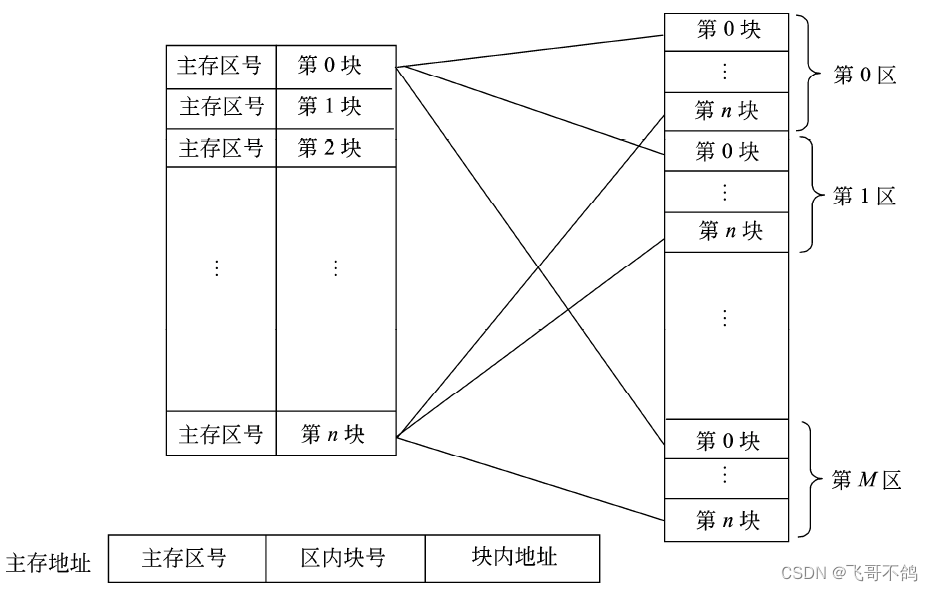
组相连映射
组相联映像。这种方式是前面两种方式的折中。具体方法是将 Cache 中的块再分成组。例如,假定 Cache 有 16 块,再将每两块分为1组,则 Cache 就分为8组。主存同样分区,每区 16 块,再将每两块分为1组,则每区就分为8组。
组相联映像就是规定组采用直接映像方式而块采用全相联映像方式。也就是说,主存任何区的0组只能存到 Cache 的0组中,1组只能存到 Cache 的1组中,依此类推。组内的块则采用全相联映像方式,即一组内的块可以任意存放。也就是说,主存一组中的任一块可以存入Cache 相应组的任一块中。
在这种方式下,通过直接映像方式来决定组号,在一组内再用全相联映像方式来决定 Cache中的块号。由主存地址高位决定的主存区号与 Cache 中区号比较可决定是否命中。主存后面的地址即为组号。
4. 缓存-内存系统,替换算法
替换算法的目标就是使 Cache 获得尽可能高的命中率。常用算法有如下几种。
- 随机替换算法(RANDOM)。就是用随机数发生器产生一个要替换的块号,将该块替换出去。
- 先进先出算法(FIFO)。就是将最先进入 Cache 的信息块替换出去。
- 近期最少使用算法(LRU,Least Recently Used)。这种方法是将近期最少使用的 Cache 中的信息块替换出去。
- 最不经常使用算法(LFU)。这种方法必须先执行一次程序,统计 Cache 的替换情况。有了这样的先验信息,在第二次执行该程序时便可以用最有效的方式来替换。
替换算法只在使用全相联映射,组相连映射时才有用,直接映射不存在替换算法。
直接映射,主存中的每一块存放的位置都是固定的,主存如果要缓存新的数据块,必须覆盖Cache中原有的数据块
6. 数据传输控制
数据传输是由cpu控制,数据从内存流向外存。内存的速度要快于外存,二者之间存在速率差异,因此需要进行控制,以保证数据正确传输
1. 程序控制
- 无条件传送
在此情况下,外设总是准备好的,它可以无条件地随时接收 CPU发来的输出数据,也能够无条件地随时向 CPU 提供需要输入的数据。 - 程序查询方式
在这种方式下,利用查询方式进行输入/输出,就是通过 CPU 执行程序来查询外设的状态判断外设是否准备好接收数据或准备好了向 CPU 输入的数据。根据这种状态,CPU 有针对性地为外设的输入/输出服务。
为了更好的理解,我们可以把CPU比作老师,老师为了检查学生是否学懂知识,不断地询问班上每一位同学。CPU为了感知外存是否接收完毕数据,需要轮询外存
2. 程序中断
中断的意思是:I/O系统进行数据传输时,不需要CPU轮询。当I/O设备准备好时,发出中断通知CPU。CPU保存当前工作状态,处理I/O数据传输。完成I/O传输后,恢复本来的工作。
我们可以理解为:学生举手告诉老师,这样就不需要老师轮询
3. 直接存储器存取
直接内存存取(Direct Memory Access,DMA)是指数据在内存与 IO 设备间的直接成块传送,即在内存与 IO 设备间传送一个数据块的过程中,不需要 CPU 的任何干涉,只需要 CPU在过程开始启动(即向设备发出“传送一块数据”的命令)与过程结束(CPU 通过轮询或中断得知过程是否结束和下次操作是否准备就绪)时的处理,实际操作由 DMA 硬件直接执行完成,CPU 在此传送过程中可做别的事情
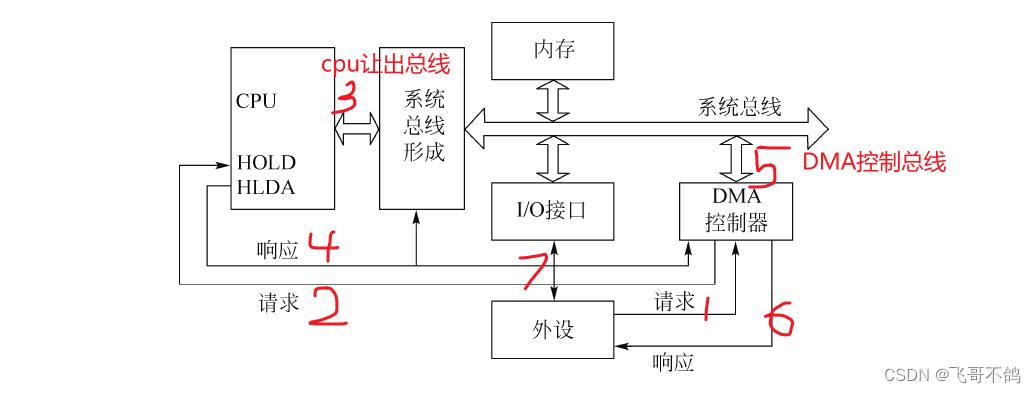
在此期间,CPU不会干预DMA数据传输,由DMA
7. 计算机系统可靠性(可用性)与可靠性模型
1. 可靠性(可用性)
计算机可靠性:计算机开始运行到一段时间内,正常运行的概率,一般用 R ( t ) R(t) R(t)表示
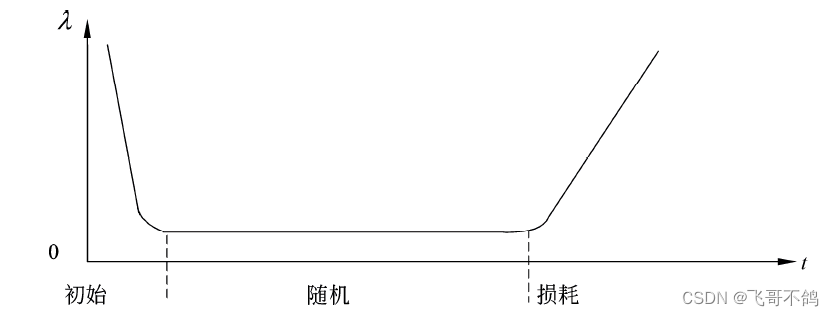
失效率:单位时间内,失效的元件数与原件总数的比例,用 λ \lambda λ表示。当 λ \lambda λ为常熟时,可靠性与失效率的关系为
R ( t ) = e − λ t R(t) = e^{-\lambda t} R(t)=e−λt
如下是典型的失效率与时间的关系图
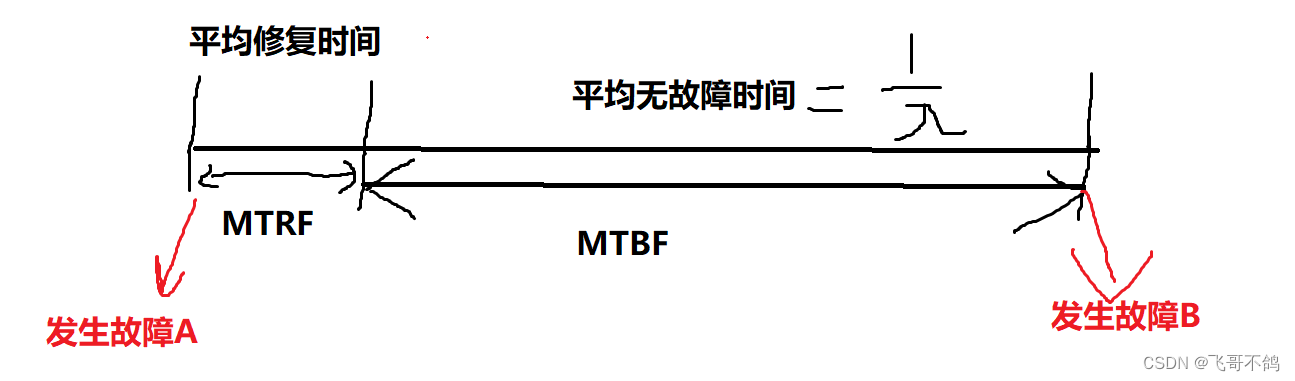
平均修复时间(MTRF):故障需要修复的平均时间,参数用于表示计算机的可维修性,即维修效率
无故障时间(MTBF):两次故障间,系统正常工作的平均时间,即 M T B F = 1 / λ MTBF = 1/\lambda MTBF=1/λ
计算机的可用性:指计算机的使用效率,用系统在任意时刻,正常工作的概率A表示,即
A = M T B F M T B F + M T R F A = \frac{MTBF}{MTBF + MTRF} A=MTBF+MTRFMTBF
计算机的可靠性:MTBF/(1+MTBF)
2. 可靠性模型
计算机系统非常复杂。我们可以拆解为若干个子系统,简化分析计算机的可靠性
1.串联系统
假设一个系统有N个子系统,只有所有子系统都正常运行,系统才能正常运行。这样的系统称为串联系统。

假设每个子系统的可靠性用 R 1 , R 2 … R N R_1,R_2\dots R_N R1,R2…RN表示,那么系统的可靠性 R = R 1 R 2 … R N R=R_1R_2\dots R_N R=R1R2…RN
2.并联系统
假设一个系统的某个功能有多个子系统实现,当一个子系统崩溃时,存在其它子系统代替崩溃的子系统工作,那么这样的系统称为并联系统

系统的可靠性 R = 1 − ( 1 − R 1 ) ( 1 − R 2 ) … ( 1 − R N ) R = 1-(1-R_1)(1-R_2)\dots(1-R_N) R=1−(1−R1)(1−R2)…(1−RN)
如果要让并联系统崩溃,则需要所有子系统全部崩溃。单个子系统崩溃的概率为 1 − R n 1-R_n 1−Rn。所有子系统同时崩溃的概率为 ( 1 − R 1 ) ( 1 − R 2 ) … ( 1 − R N ) (1-R_1)(1-R_2)\dots(1-R_N) (1−R1)(1−R2)…(1−RN),那么整体系统不崩溃的概率即为 1 − 子系统同时崩溃的概率 1 - 子系统同时崩溃的概率 1−子系统同时崩溃的概率,也即 R = 1 − ( 1 − R 1 ) ( 1 − R 2 ) … ( 1 − R N ) R = 1-(1-R_1)(1-R_2)\dots(1-R_N) R=1−(1−R1)(1−R2)…(1−RN)
3. 计算机性能指标
主频:表示计算机1s内有多少次脉冲。(2.4GHZ表示1s内有2.4G次脉冲)
时钟周期:表示计算机1次脉冲有多少秒,一个时钟周期C包含多少秒。(1s/2.4GHZ)
时钟周期(C) = 1/主频 。时钟周期将1s分配给脉冲
CPI:CPI代表着 C/I,C表示时钟周期,I表示指令。CPI表示1条指令所包含的时钟周期个数
P代表着
每,也就是 /
IPC:I/C,意味着单位时钟周期包含的指令数
IPC = 1/CPI
MIPS:百万条指令 / 1s,即 M I P S = 指令条数 / ( 执行时间 × 1 0 6 ) = 主频 / C P I = 主频 × I P C MIPS = 指令条数/(执行时间 \times 10^6)=主频/CPI = 主频 \times IPC MIPS=指令条数/(执行时间×106)=主频/CPI=主频×IPC
M = 百万(million)
MFLOPS : 浮点数操作次数,即 M F L O P S = 浮点数操作次数 / ( 执行时间 × 1 0 6 ) MFLOPS = 浮点数操作次数 / (执行时间 \times 10^6) MFLOPS=浮点数操作次数/(执行时间×106)
吞吐量:一定时间内,完成的任务量(请求) Task/Time
吞吐率:单位时间内,完成的任务量 (请求)Task/1s
响应时间(RT):提交请求到完成请求的时间
例如在文本编辑器中打字,从按下键盘到显示字母的时间就是RT
完成时间(TAT):指令执行完成的时间
tip:
在时间的范围内,存在如下的单位转换形式
1 K H Z = 1 0 3 H Z , 1 M H Z = 1 0 3 K H Z , 1 G H Z = 1 0 3 M H Z 1KHZ = 10^3HZ,1MHZ = 10^3KHZ,1GHZ = 10^3MHZ 1KHZ=103HZ,1MHZ=103KHZ,1GHZ=103MHZ
在存储的范围内,存在如下的单位转换形式
1 B ( 字节 ) = 8 b ( 比特 b i t ) , 1 K B = 2 10 B , 1 M B = 2 10 K B , 1 G B = 2 10 M B 1B(字节) = 8b(比特bit),1KB=2^{10}B,1MB=2^{10}KB,1GB=2^{10}MB 1B(字节)=8b(比特bit),1KB=210B,1MB=210KB,1GB=210MB
第二章
1.编译过程概述
2.文法和语言的描述形式
3. 词法分析
1. 正规表达式和正规集
2. 有限自动机
- 确定的有限自动机(DFA),确定的有限自动机是五元组 ( S , ∑ , f , s 0 , Z ) (S,\sum,f,s_0,Z) (S,∑,f,s0,Z)
- S是一个有限集,其每个元素称为一个状态。
- ∑是一个有穷字母表,其每个元素称为一个输入字符。
- f是 SxΣ→S 上的单值部分映像。f(A,a)=Ω 表示当前状态为 A、输入为a时,将转换到下一状态 Ω,称 Ω为A的一个后继状态。
- s 0 ∈ S s_0\in S s0∈S,是唯一的一个开始状态。
- Z是非空终止状态集合, Z ⊆ S Z\subseteq S Z⊆S
一个DFA可以由两种图示表示:状态转换图,状态转移矩阵
例:
已知有 D F A M 1 = ( { s 0 , s 1 , s 2 , s 3 } , { a , b } , f , s 0 , { s 3 } ) ,其中 f 为 : f ( s 0 , a ) = s 1 , f ( s 0 , b ) = s 2 , , f ( s 1 , a ) = s 3 , f ( s 1 , b ) = s 2 , f ( s 2 , a ) = s 1 , f ( s 2 , b ) = s 3 , f ( s 3 , a ) = s 3 ; 已知有 DFA \ \ M_1=(\{s_0,s_1,s_2,s_3\},\ \ \{a,b\}, \ \ f, \ \ s_0, \ \ \{s_3\}),其中f为: f(s_0,a)=s_1,\\f(s_0,b)=s_2,,f(s_1,a)=s_3,f(s_1,b)=s_2,f(s_2,a)=s_1,f(s_2,b)=s_3,f(s_3,a)=s_3; 已知有DFA M1=({s0,s1,s2,s3}, {a,b}, f, s0, {s3}),其中f为:f(s0,a)=s1,f(s0,b)=s2,,f(s1,a)=s3,f(s1,b)=s2,f(s2,a)=s1,f(s2,b)=s3,f(s3,a)=s3;
则状态转换图,转移矩阵如下
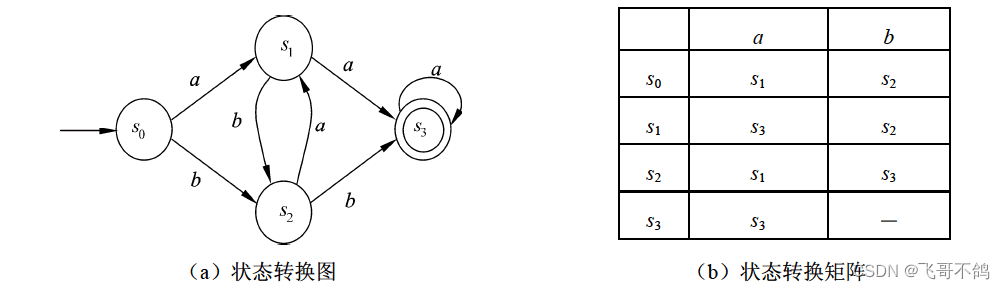
对于上例, ∑ \sum ∑中的任意字符串 Ω \Omega Ω,存在一条路径使得从初始状态走向终止状态,那么称DFA M1能够识别 Ω \Omega Ω。
DFA 所能识别的语言$ L(M) = {\Omega | \Omega 是从M的初态到终态的路径上的弧上标记形成的串 }$
- 不确定有限自动机(NFA)
NFA和DFA的区别如下
- 当前状态的后继状态并不唯一
- 有向弧的标记可以是 ε \varepsilon ε
3. NFA -> DFA
NFA转化到DFA算法步骤


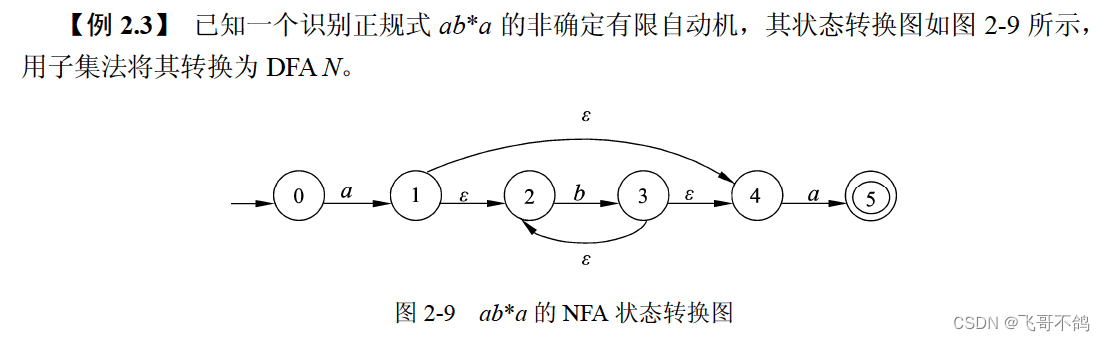

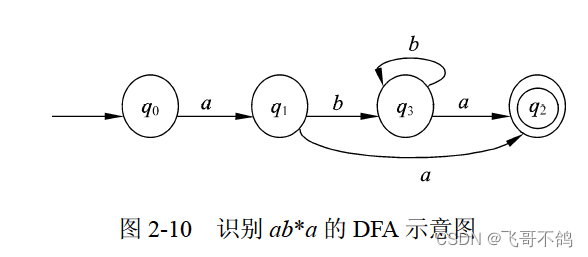
4. DFA最小化
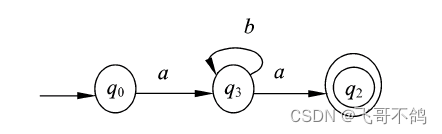
采用Hopcroft算法,算法的计算方式如下
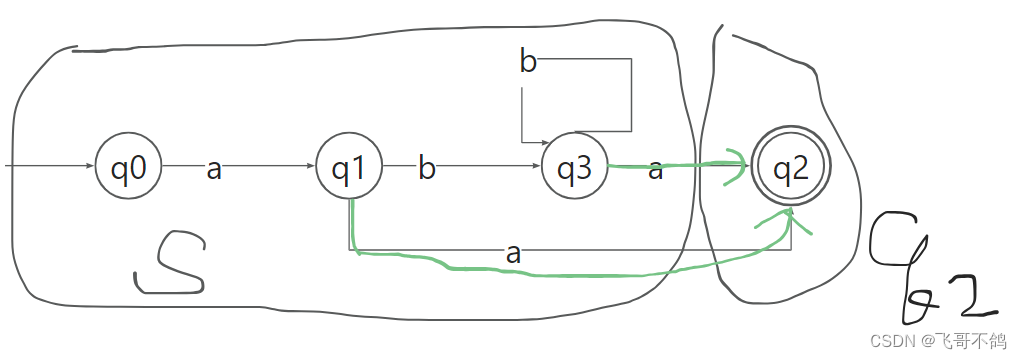
将非终止点和终止点划分为两类,分别取名S,q2。q2无法继续划分,无需考察划分情况。
对于S,我们考察边b。q0-b->q1(S),q1-b->q3(S),q3-b->q3(S),S中的所有节点在b的作用下都指向S集合,因此b无法划分S集合
我们考察边a。q0-a->q1(S),q1-a->q2(q2),q3-a->q2(q2)。S中的节点在边a的作用下划分为两类,一类指向S本身(q0),另一类指向q2(q1, q3),因此S可以继续划分,划分结果如下图
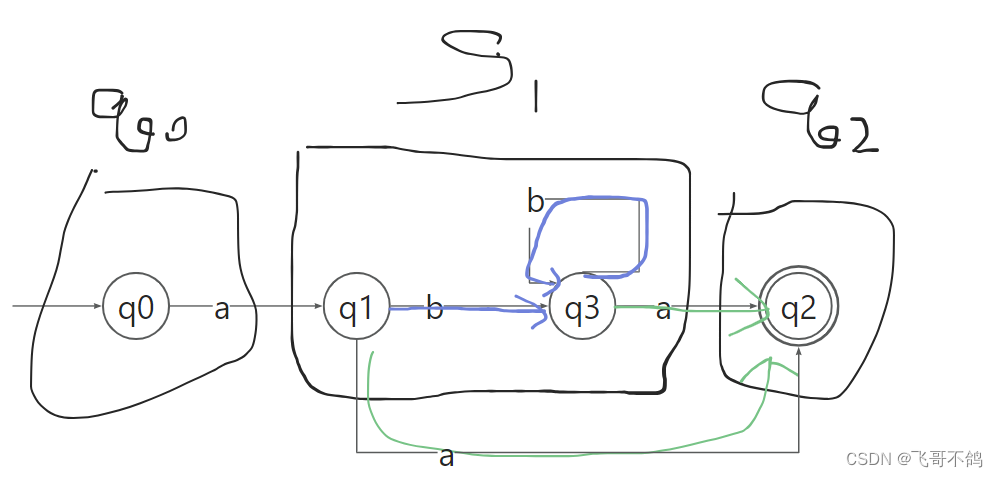
考察集合q0,已经无法划分
考察集合S1,边b使得q1, q3都指向S1,因此b无法划分S1;边a使得q1, q3都指向q2,因此无法划分。所以S1无法划分。
最终得到如下的最小DFA
5. 正规式与有限自动机之间的转换
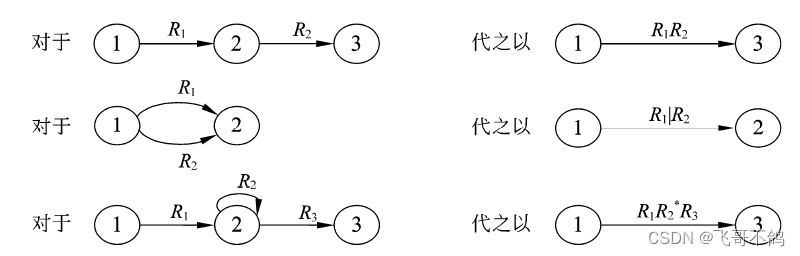
1. 有限自动机转换正规式
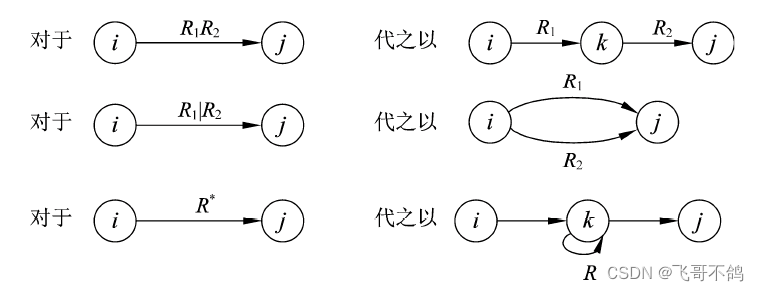
2. 正规式到有限自动机
6. 语法分析
1. LL(1)分析算法
从左(L)向右读入程序,最左(L)推导,采用一个(1)前看符号。算法基本思想是表驱动的分析算法
第三章
3.4. 树
3.4.3 生成树及最小生成树
1.基础概念
连通图:存在一条路径使得从任意一个节点开始,都能到达连通图其它的所有节点。
极小连通子图:在连通图的基础上,需要保证边数是最少的。这意味着如果移除任意一条边,图将不在连通。
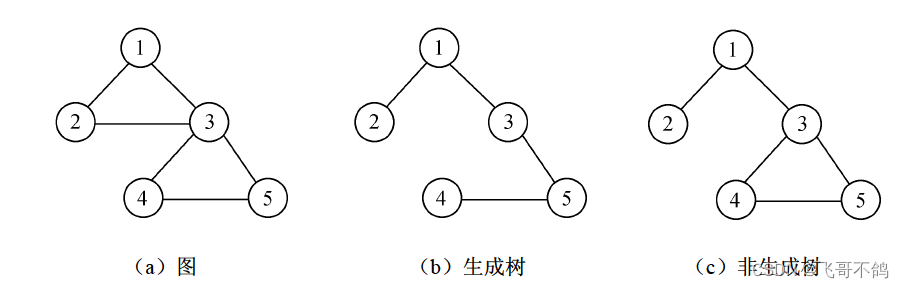
生成树:连通的无向图中的一个子图,需要满足以下特性。1. 连通性:生成树包含原图的所有顶点;2.无环性:不存在回路;3. 最小行:去除任何边都会导致不连通,满足边数量=顶点数 - 1
2.生成最小树
(1)普里姆(Prim)算法
普里姆算法构造最小生成树的过程是以一个顶点集合 [-{g}作为初态,不断寻找与 U中顶点相邻且代价最小的边的另一个顶点,扩充 U集合直到 UV时为止。
如下是Prim算法生成最小树的过程
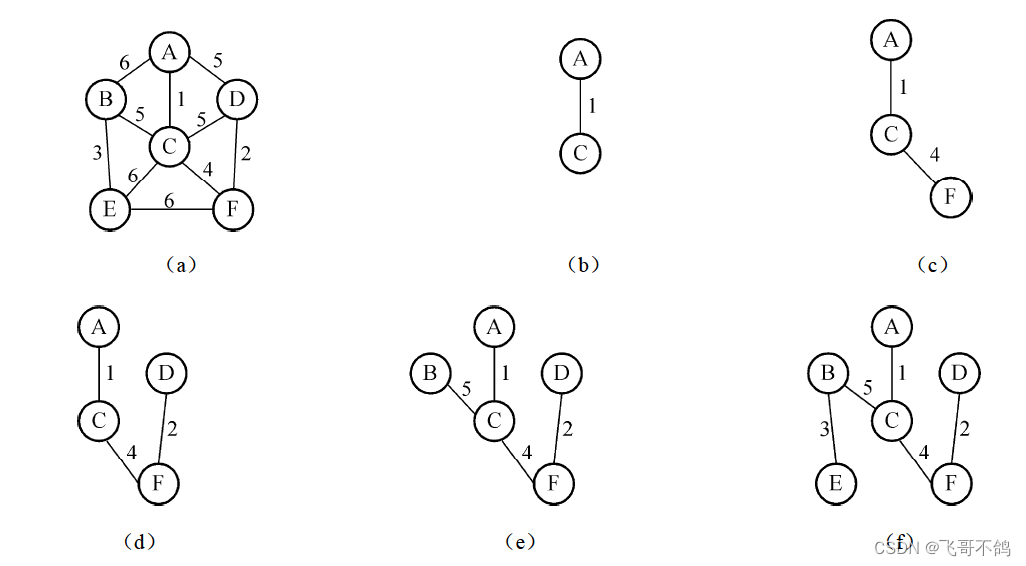
(2)克鲁斯卡尔(Kruskal)算法
克鲁斯卡尔求最小生成树的算法思想为:假设连通网 N = ( V . E ) N = (V.E) N=(V.E),令最小生成树的初始状态为只有 n个顶点而无边的非连通图$ T=(V,{}) ,图中每个顶点自成一个连通分量。在 ,图中每个顶点自成一个连通分量。在 ,图中每个顶点自成一个连通分量。在E 中选择代价最小的边,若该边依附的顶点落在 中选择代价最小的边,若该边依附的顶点落在 中选择代价最小的边,若该边依附的顶点落在T$中不同的连通分量上,则将此边加入到T中,否则舍去此边而选择下一条代价最小的边。依此类推,直到T中所有顶点都在同一连通分量上为止。
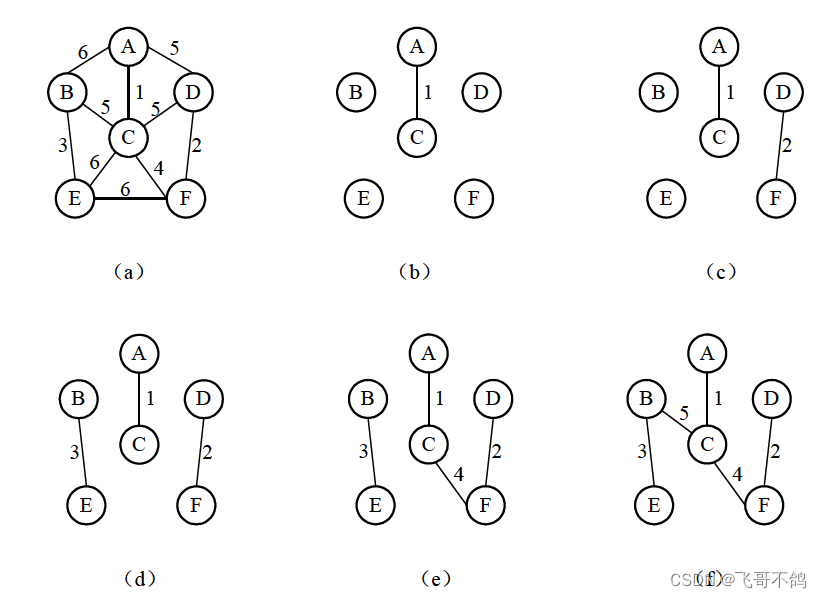
3.4.3 拓扑排序和关键路径
1. AOV网
AOV网是一种图论模型,用于表示一个工程或项目的活动及其执行顺序关系
顶点:每一个顶点表示一个独立的活动或任务
有向边:用于表示活动之间的优先关系或依赖关系。比如A->B。表示B的开始依赖于A的结束
无环性质:AOV网络是有向无环图(DAG)
2.拓扑排序极其算法
拓扑排序就是将AOV网拍布成一个线性序列的过程。此过程保证满足AOV网对所有任务依赖的要求,保证能够按照顺序解决工程问题。
一个可行的算法如下:
(1)在 AOV 网中选择一个**入度为0(没有前驱)**的顶点且输出它
(2)从网中删除该顶点及与该顶点有关的所有弧。
(3)重复上述两步,直到网中不存在入度为0的顶点为止。
以AOV网(a)为例,按照上述计算步骤,得到如下有序序列:6 1 4 3 2 5
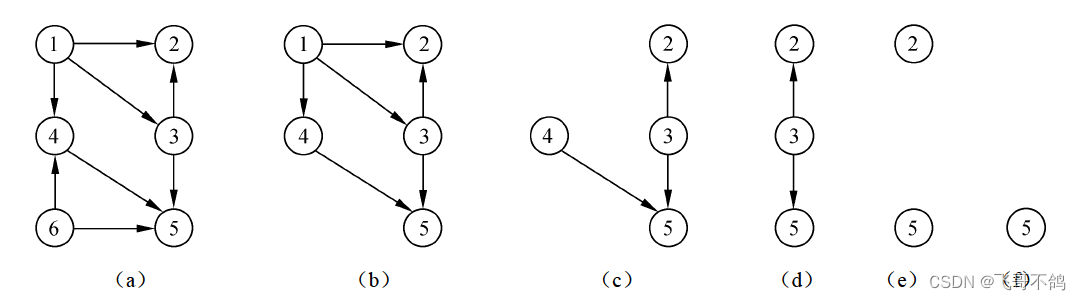
3. AOE网
若在带权有向图G中以顶点表示事件,以有向边表示活动,以边上的权值表示该活动持续的时间,则这种带权有向图称为用边表示活动的网(Activity On Edge network,AOE 网)。
通常在 AOE 网中列出了完成预定工程计划所需进行的活动、每项活动的计划完成时间、活动开始或结束的事件以及这些事件和活动间的关系,从而可以分析该项工程是否实际可行并估计工程完成的最短时间,以及影响工程进度的关键活动;进一步可以进行人力、物力的调度和分配,以达到缩短工期的目的。
4. 关键路径和关键活动
关键路径
AOE网中最长的路径称为关键路径,关键路径上的所有活动都是关键活动。
第四章
4.2 进程管理
4.2.1 基本概念
3. 进程的状态及其状态间的切换
三态模型
- 运行:进程在cpu上运行时,称为运行状态
- 就绪:一个进程得到了除cpu外的一切资源,只要有cpu即可运行
- 阻塞:进程在等待这某一个事件的发生,因而将cpu让出。即使这时将cpu分配给进程也不会让他运行。
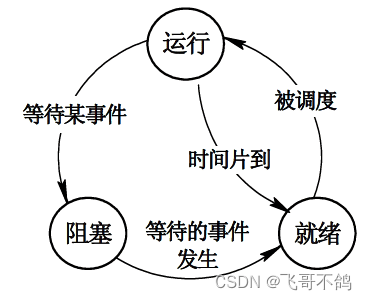
五态模型
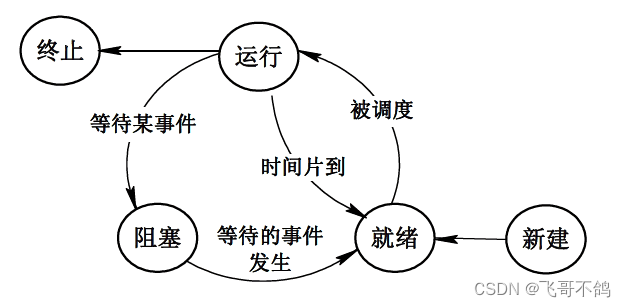
有挂起的状态转换
- 活跃就绪:进程在主存并且处于可调度状态
- 静止就绪:就绪进程被交换到辅存时的状态,他是不能被直接调度的状态
- 活跃阻塞:进程在主存,一旦等待的事件产生便进入活跃就绪状态
- 静止阻塞:阻塞进程交换到辅存,一旦发生事件就进入到静止就绪状态
4.2.3 进程间通讯
相关文章:
软件设计师笔记1
分享一下学习软考时做的笔记,笔者太懒了,后续篇章都没咋记录,现在放出来水几篇文章 另外,本章内容都是结合教材,B站课堂记录。下一篇软考笔记知识点来自真题 软考笔记 第一章 1. 计算机的组成 1. 控制器 控制器由…...

springboot集成mybatis 单元测试
1、依赖 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0…...

ecc dsa rsa des
ECC(椭圆曲线密码学)、DSA(数字签名算法)、RSA(一种公钥加密技术)和DES(数据加密标准)都是密码学领域中重要的加密和安全技术。下面是对这四种技术的简要介绍: 椭圆曲线密…...
)
Gitee的原理及应用详解(三)
本系列文章简介: Gitee是一款开源的代码托管平台,是国内最大的代码托管平台之一。它基于Git版本控制系统,提供了代码托管、项目管理、协作开发、代码审查等功能,方便团队协作和项目管理。Gitee的出现,在国内的开发者社…...

Mia for Gmail for Mac:Mac用户的邮件管理首选
对于追求高效工作的Mac用户来说,Mia for Gmail for Mac无疑是邮件管理的首选工具。它以其卓越的性能和丰富的功能,为用户带来了前所未有的高效邮件管理体验。 Mia for Gmail for Mac不仅支持多帐号登录和标签选择功能,还提供了邮件分类、垃圾…...
如何在忘记密码的情况下解锁 iPhone? 6 种方法分享
您是否因为没有密码而无法解锁您的 iPhone? 别担心,这种情况比你想象的更常见!忘记密码是 iPhone 用户面临的最常见问题之一,而且可能非常令人沮丧 - 但不要绝望。 在这篇文章中,我们将与您分享绕过 iPhone 屏幕密码…...

国产操作系统上使用rsync恢复用户数据 _ 统信 _ 麒麟 _ 中科方德
原文链接:国产操作系统上使用rsync恢复用户数据 | 统信 | 麒麟 | 中科方德 Hello,大家好啊!今天给大家带来一篇关于在国产操作系统上使用rsync备份并还原用户数据的文章。rsync是一款功能强大的文件同步和备份工具,广泛用于Linux系…...

Elastic Cloud 将 Elasticsearch 向量数据库优化配置文件添加到 Microsoft Azure
作者:来自 Elastic Serena Chou, Jeff Vestal, Yuvraj Gupta 今天,我们很高兴地宣布,我们的 Elastic Cloud Vector Search 优化硬件配置文件现已可供 Elastic Cloud on Microsoft Azure 用户使用。 此硬件配置文件针对使用 Elasticsearch 作…...
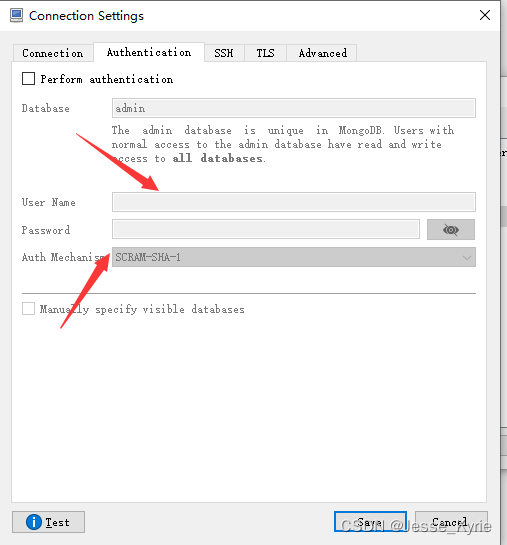
Mongodb 可视化工具Robot 3t安装【windows环境下】
下载应用 打开连接点我 选择windows版本并点击下载 下载完毕,双击并傻瓜安装 连接数据库 点击图标, 点击create创建连接 填写host和port 如果有用户名密码的,在authentication里填写 5. save 并连接即可使用!...

【MATLAB】信号的熵
近似熵、样本熵、模糊熵、排列熵|、功率谱熵、奇异谱熵、能量熵、包络熵 代码内容: 获取代码请关注MATLAB科研小白的个人公众号(即文章下方二维码),并回复信号的熵本公众号致力于解决找代码难,写代码怵。各位有什么急需…...
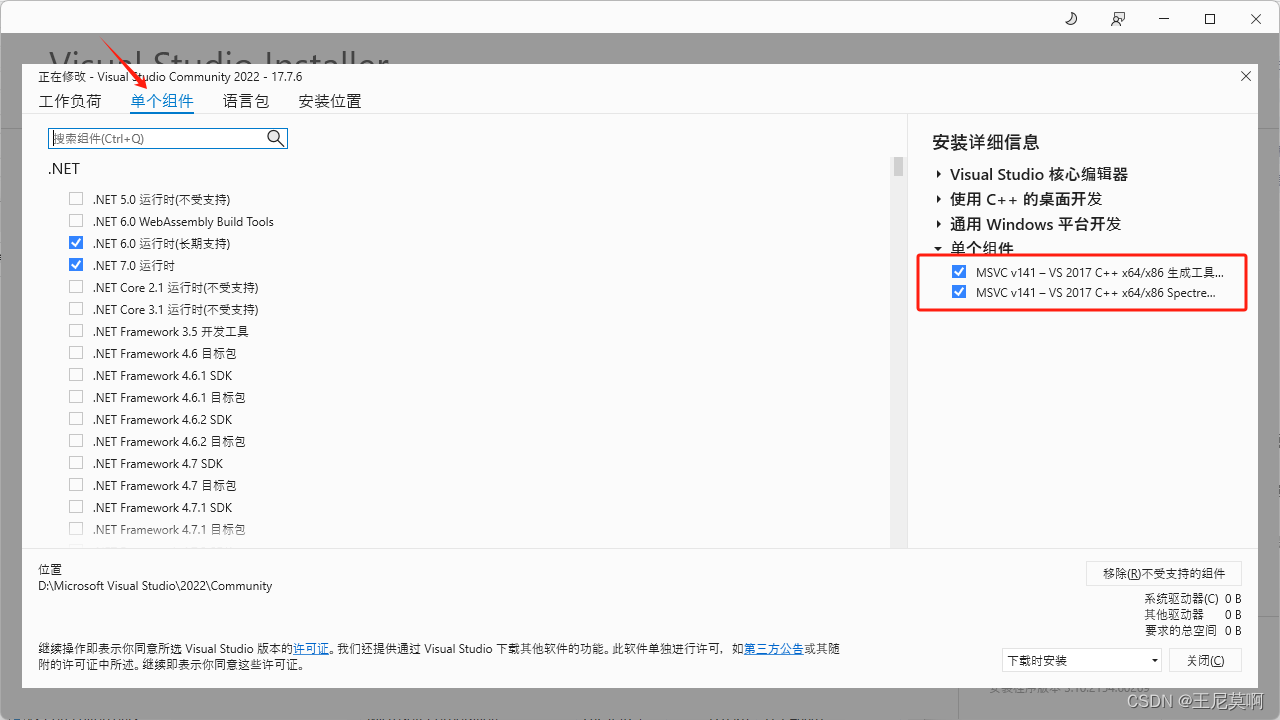
【QT环境配置】节约msvc2017灰色不可用问题
1. 问题 msvc2017不可用,2019、2022都同理解决。 2. 解决 打开控制面板->程序->程序和功能->找到自己安装的vs程序->鼠标右键后出现卸载更改->点击更改 找到下面组件即可。(msvc2019就找msvcv142)...

MyBatis框架的使用:mybatis介绍+环境搭建+基础sql的使用+如何使用Map传入多个参数+返回多个实体用List或者Map接收+特殊sql的使用
MyBatis框架的使用:mybatis介绍环境搭建基础sql的使用如何使用Map传入多个参数返回多个实体用List或者Map接收特殊sql的使用 一、MyBatis介绍1.1 特性1.2 下载地址1.3 和其它持久层技术对比 二、搭建环境2.1配置maven2.2 创建mybatis配置文件2.3 搭建测试环境 三、基…...

linux centos nginx配置浏览器访问后端(tomcat日志)
1、配置nginx访问tomcat日志路径 vim /usr/local/nginx/conf/nginx,conflocation ^~ /logs {autoindex on;autoindex_exact_size on;autoindex_localtime on;alias /home/tomcat/apache-tomcat-9.0.89-1/logs;}###配置讲解### 1、location ^~ /logs { … }: location…...

01-03.Vue:v-on的事件修饰符
01-03.Vue:v-on的事件修饰符 前言v-on的事件修饰符.stop的举例.capture举例.prevent的举例1.prevent的举例2.self举例 前言 我们接着上一篇文章 01-02.Vue的常用指令(二) 来讲 下一篇文章 01-04.Vue的使用示例:列表功能 v-on的事件修饰符 v-on 提供了很…...
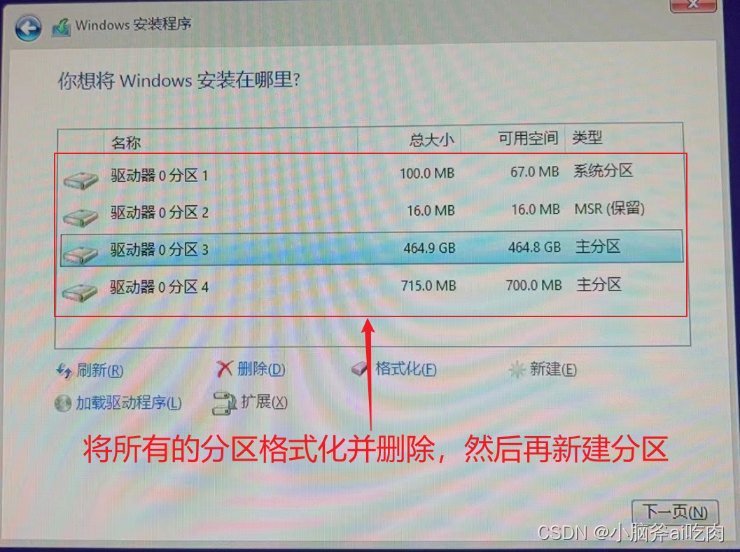
MSI U盘重装系统
MSI U盘重装系统 1. 准备一块U盘 首先需要将U盘格式化,这个格式化并不是在文件管理中将U盘里面的所有东西都删干净就可以了,需要在磁盘管理中,将这块U盘格式化,如果这块U盘有分区的话,那将所有的分区都格式化并且删除…...

ubuntu如何安装gitlab runner
一、什么是GitLab Runner GitLab Runner 是 GitLab 提供的一个开源工具,用于在构建、测试和部署过程中执行作业。它是 GitLab 持续集成和持续部署(CI/CD)工作流的核心组件之一。 GitLab Runner 有以下主要功能: 作业执行:GitLab Runner 会接收来自 GitLab 的作业请求,并在指定…...
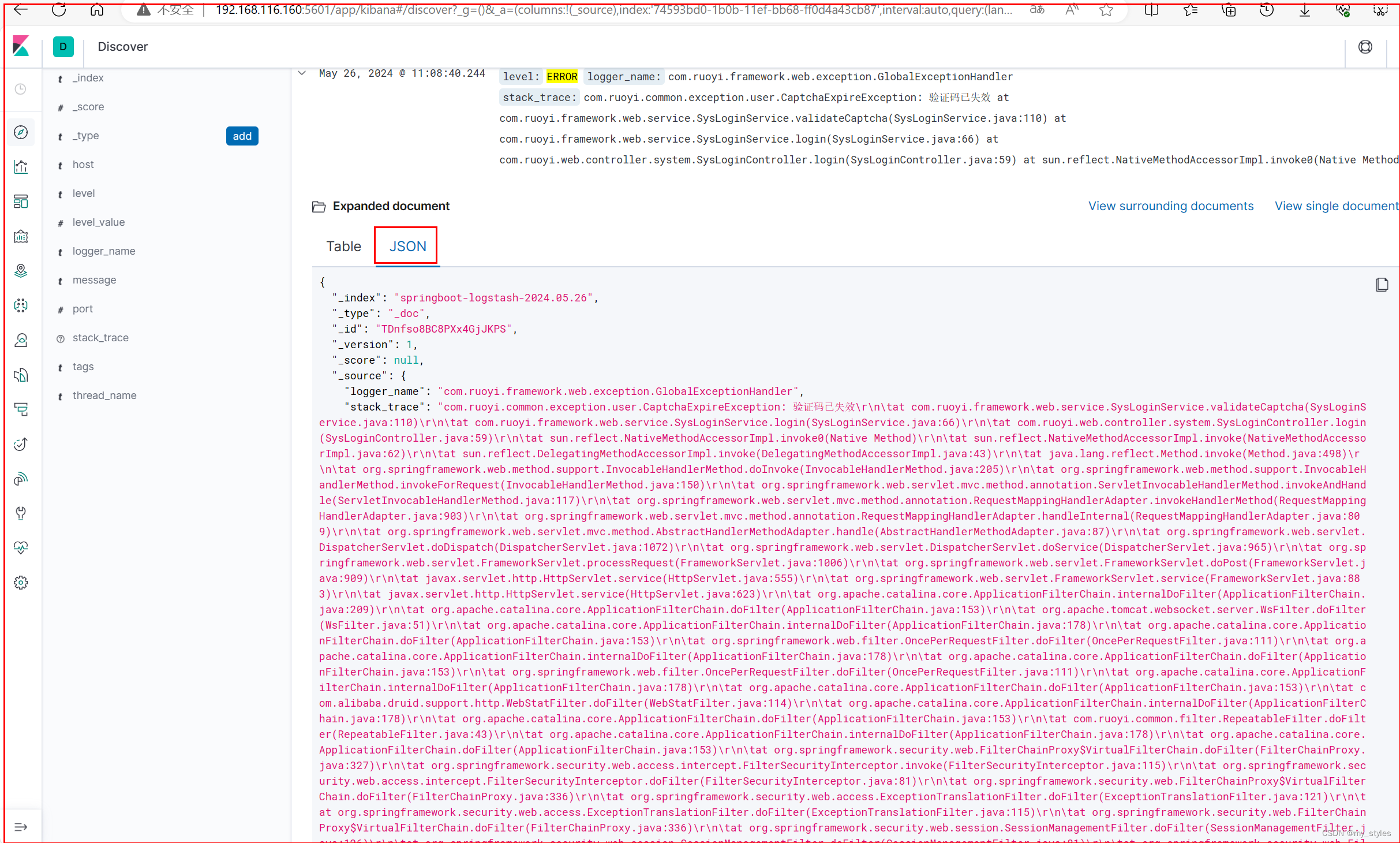
Java整合ELK实现日志收集 之 Elasticsearch、Logstash、Kibana
简介 Logstash:用于收集并处理日志,将日志信息存储到Elasticsearch里面 Elasticsearch:用于存储收集到的日志信息 Kibana:通过Web端的可视化界面来查看日志(数据可视化) Logstash 是免费且开放的服务器端数…...
如何判断自己的情商高低?
什么是情商? 情商(简称为EQ),也叫情绪智力,和我们通常提到的智商智力有所不同(侧重于理性思维),情商更贴近实际生活,如:情绪识别和自我管理,自我…...

JAVA:Spring Boot整合MyBatis Plus持久层
1、简述 MyBatis Plus是MyBatis的增强工具包,它在MyBatis的基础上进行了扩展,提供了许多便捷的功能,例如通用CRUD操作、分页插件、代码生成器等。使用MyBatis Plus,开发者可以更加方便地进行持久层操作,并且减少了很多…...

如何选择优质的气膜体育馆工程服务商—轻空间
随着现代生活的便利化和时代感的增强,气膜体育馆成为越来越多人的选择。这种美观实用的建筑在学校、社区和体育中心等地广泛应用。许多投资者和客户都有意建造气膜体育馆,但在选择工程服务商时,往往面临困惑。以下几点将帮助您做出明智的选择…...

DeepSeek总结的将 Rust Delta Kernel 集成到 ClickHouse
来源:https://clickhouse.com/blog/integrating-rust-delta-kernel 将 Rust Delta Kernel 集成到 ClickHouse 作者: Melvyn Peignon, Kseniia Sumarokova, Ral Marn 日期: 2026年5月22日 阅读时间: 24分钟 除非你过去几年一直呆在没有互联网的洞穴里,否则…...

面霸AI · 用 Multi-Agent 让面试模拟卷出天际
🧑💻 博主介绍 & 诚邀关注 作者:专注于 Java、Python、前端开发的技术博主 | 全网粉丝 30 万 在校期间协助导师完成毕业设计课题分类、论文格式初审及代码整理工作;工作后持续分享毕设思路,助力毕业生顺利完成…...

【AI工具成本真相报告】:开源≠免费!TCO测算显示中大型项目3年隐性成本反超商业工具37%
更多请点击: https://kaifayun.com 第一章:【AI工具成本真相报告】:开源≠免费!TCO测算显示中大型项目3年隐性成本反超商业工具37% 开源AI工具常被默认等同于“零许可费用”,但真实总拥有成本(TCO…...

OBS计时器插件:如何用6种模式轻松掌控直播时间
OBS计时器插件:如何用6种模式轻松掌控直播时间 【免费下载链接】obs-advanced-timer 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-timer 还在为直播时间管理头疼吗?作为内容创作者的你,是否经常因为时间控制不当而影响…...

DeepL Chrome翻译插件:让高质量翻译触手可及
DeepL Chrome翻译插件:让高质量翻译触手可及 【免费下载链接】deepl-chrome-extension A DeepL Translator Chrome extension 项目地址: https://gitcode.com/gh_mirrors/de/deepl-chrome-extension 在信息爆炸的今天,我们每天都会接触到大量外文…...

具身智能的发展趋势对就业市场的影响是什么?
具身智能对就业的核心影响是结构性重塑:短期替代大量重复性岗位、长期创造更高价值的新岗位,整体呈现 “替代 — 创造 — 转型” 的震荡再平衡过程。下面从替代、创造、结构变化、技能与分配、时间线五个方面展开。一、岗位替代:低技能、高重…...

Windows电脑安装安卓应用:告别模拟器的轻量级解决方案
Windows电脑安装安卓应用:告别模拟器的轻量级解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经渴望在Windows电脑上运行安卓应用…...

NVIDIA显卡终极色彩校准指南:novideo_srgb让广色域显示器回归真实色彩
NVIDIA显卡终极色彩校准指南:novideo_srgb让广色域显示器回归真实色彩 【免费下载链接】novideo_srgb Calibrate monitors to sRGB or other color spaces on NVIDIA GPUs, based on EDID data or ICC profiles 项目地址: https://gitcode.com/gh_mirrors/no/novi…...

5步实现Realtek RTL8125网卡在VMware ESXi 6.7上的完整驱动适配解决方案
5步实现Realtek RTL8125网卡在VMware ESXi 6.7上的完整驱动适配解决方案 【免费下载链接】r8125-esxi Realtek RTL8125 driver for ESXi 6.7 项目地址: https://gitcode.com/gh_mirrors/r8/r8125-esxi 在虚拟化环境中,Realtek RTL8125 2.5G网卡驱动适配是许多…...

如何永久保存微信聊天记录:WeChatMsg完整解决方案让你真正拥有数据主权
如何永久保存微信聊天记录:WeChatMsg完整解决方案让你真正拥有数据主权 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_T…...