如何确保大模型 RAG 生成的信息是基于可靠的数据源?
在不断发展的人工智能 (AI) 领域中,检索增强生成 (RAG) 已成为一种强大的技术。
RAG 弥合了大型语言模型 (LLM) 与外部知识源之间的差距,使 AI 系统能够提供更全面和信息丰富的响应。然而,一个关键因素有时会缺失——透明性。
我们如何能够确定 RAG 系统呈现的信息是基于可靠来源的?
本文介绍了一种引人注目的解决方案:使用结构化生成的带源突出显示的 RAG。这种创新的方法不仅利用了 RAG 检索相关信息的能力,还突出了支持生成答案的具体来源。喜欢本文记得收藏、点赞、关注,希望大模型技术交流的文末加入我们。
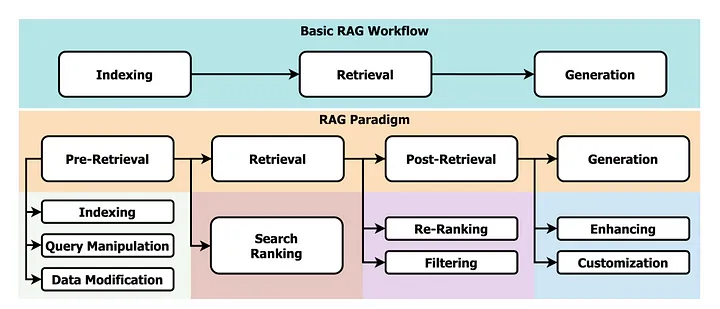
理解基础构件
在深入探讨之前,让我们先建立核心概念的基础:
结构化生成:这种技术引导大型语言模型 (LLM) 的输出遵循预定义的结构。可以将其想象为为 LLM 提供一张路线图,确保生成的文本符合特定格式。
带源突出显示的 RAG 的优势
RAG 和结构化生成的整合提供了诸多优点:
- 增强信任和透明性:突出显示的来源使用户能够评估所呈现信息的可信度。这有助于培养对系统的信任,并使用户能够深入了解支持证据。
- 改善可解释性:通过明确指出答案背后的来源,系统变得更加透明。用户能够深入了解推理过程,便于调试和进一步探索知识库。
- 更广泛的适用性:这种方法适用于用户不仅需要答案,还需要理由和清晰的审计记录的场景。它在教育、研究和法律领域尤为有价值。

代码实现
让我们深入了解使用结构化生成的带源突出显示的 RAG。
步骤 I:安装库
!pip install pandas json huggingface_hub pydantic outlines accelerate -q
步骤 II:导入库
import pandas as pd
import json
from huggingface_hub import InferenceClientpd.set_option("display.max_colwidth", None)repo_id = "meta-llama/Meta-Llama-3-8B-Instruct"llm_client = InferenceClient(model=repo_id, timeout=120)
步骤 III:提示模型
RELEVANT_CONTEXT = """
Document:The weather is really nice in Paris today.
To define a stop sequence in Transformers, you should pass the stop_sequence argument in your pipeline or model.
"""RAG_PROMPT_TEMPLATE_JSON = """
Answer the user query based on the source documents.Here are the source documents: {context}You should provide your answer as a JSON blob, and also provide all relevant short source snippets from the documents on which you directly based your answer, and a confidence score as a float between 0 and 1.
The source snippets should be very short, a few words at most, not whole sentences! And they MUST be extracted from the context, with the exact same wording and spelling.Your answer should be built as follows, it must contain the "Answer:" and "End of answer." sequences.Answer:
{{"answer": your_answer,"confidence_score": your_confidence_score,"source_snippets": ["snippet_1", "snippet_2", ...]
}}
End of answer.Now begin!
Here is the user question: {user_query}.
Answer:
"""USER_QUERY = "How can I define a stop sequence in Transformers?" prompt = RAG_PROMPT_TEMPLATE_JSON.format(context=RELEVANT_CONTEXT, user_query=USER_QUERY)print(prompt)
输出:
Answer the user query based on the source documents.Here are the source documents:
Document:The weather is really nice in Paris today.
To define a stop sequence in Transformers, you should pass the stop_sequence argument in your pipeline or model.You should provide your answer as a JSON blob, and also provide all relevant short source snippets from the documents on which you directly based your answer, and a confidence score as a float between 0 and 1.
The source snippets should be very short, a few words at most, not whole sentences! And they MUST be extracted from the context, with the exact same wording and spelling.Your answer should be built as follows, it must contain the "Answer:" and "End of answer." sequences.Answer:
{"answer": your_answer,"confidence_score": your_confidence_score,"source_snippets": ["snippet_1", "snippet_2", ...]
}
End of answer.Now begin!
Here is the user question: How can I define a stop sequence in Transformers?.
Answer:
继续代码:
answer = llm_client.text_generation(prompt,max_new_tokens=1000,
)answer = answer.split("End of answer.")[0]
print(answer)
输出:
{"answer": "You should pass the stop_sequence argument in your pipeline or model.","confidence_score": 0.9,"source_snippets": ["stop_sequence", "pipeline or model"]
}
步骤 IV:受限解码
from pydantic import BaseModel, confloat, StringConstraints
from typing import List, Annotatedclass AnswerWithSnippets(BaseModel):answer: Annotated[str, StringConstraints(min_length=10, max_length=100)]confidence: Annotated[float, confloat(ge=0.0, le=1.0)]source_snippets: List[Annotated[str, StringConstraints(max_length=30)]]# Using text_generation
answer = llm_client.text_generation(prompt,grammar={"type": "json", "value": AnswerWithSnippets.schema()},max_new_tokens=250,temperature=1.6,return_full_text=False,
)
print(answer)# Using post
data = {"inputs": prompt,"parameters": {"temperature": 1.6,"return_full_text": False,"grammar": {"type": "json", "value": AnswerWithSnippets.schema()},"max_new_tokens": 250,},
}
answer = json.loads(llm_client.post(json=data))[0]["generated_text"]
print(answer)
输出:
{"answer": "You should pass the stop_sequence argument in your modemÏallerbate hassceneable measles updatedAt原因","confidence": 0.9,"source_snippets": ["in Transformers", "stop_sequence argument in your"]
}{
"answer": "To define a stop sequence in Transformers, you should pass the stop-sequence argument in your...giÃ",
"confidence": 1,
"source_snippets": ["seq이야","stration nhiên thị ji是什么hpeldo"]
}
结论
使用结构化生成的带源突出显示的 RAG 代表了 AI 驱动的信息检索领域的重要进步。
通过为用户提供透明且有据可查的答案,这种技术培养了信任,促进了可解释性,并扩大了 RAG 系统在各个领域的适用性。
随着 AI 的不断发展,这种创新方法为用户能够自信地依赖 AI 生成的信息奠定了基础,使他们理解背后的推理和证据。
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了算法面试和技术交流群,相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:来自CSDN + 技术交流
通俗易懂讲解大模型系列
-
重磅消息!《大模型面试宝典》(2024版) 正式发布!
-
重磅消息!《大模型实战宝典》(2024版) 正式发布!
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
相关文章:
如何确保大模型 RAG 生成的信息是基于可靠的数据源?
在不断发展的人工智能 (AI) 领域中,检索增强生成 (RAG) 已成为一种强大的技术。 RAG 弥合了大型语言模型 (LLM) 与外部知识源之间的差距,使 AI 系统能够提供更全面和信息丰富的响应。然而,一个关键因素有时会缺失——透明性。 我们如何能够…...
 + Supervisor 实现多进程redis消息队列)
Laravel(Lumen8) + Supervisor 实现多进程redis消息队列
相关文章:Supervisor守护进程工具安装与使用 1、通用消息队列 /App/Job/CommonJob.php: <?phpnamespace App\Jobs; use Illuminate\Support\Facades\Log; use Illuminate\Support\Str;class CommonJob extends Job {public $timeout; //超时时间protected $data; //队列…...

深度学习复盘与小实现
文章目录 一、查漏补缺复盘1、python中zip()用法2、Tensor和tensor的区别3、计算图中的迭代取数4、nn.Modlue及nn.Linear 源码理解5、知识杂项思考列表6、KL散度初步理解 二、处理多维特征的输入1、逻辑回归模型流程2、Mini-Batch (N samples) 三、加载数据集1、Python 魔法方法…...
)
算法刷题笔记 高精度加法(C++实现)
文章目录 题目描述题目思路和代码 题目描述 给定两个正整数(不含前导0),计算它们的和。 输入格式 共两行,每行包含一个整数。 输出格式 共一行,包含所求的和。 题目思路和代码 基本思路:模拟竖式计算…...

php祛除mqtt 返回数据中包含的特殊字符
function cleanseMessage($message) {// 定义特殊字符的正则表达式$pattern /[[:^print:]]/;// 使用正则表达式替换特殊字符为空字符串$cleanedMessage preg_replace($pattern, , $message);return $cleanedMessage; }// 假设接收到的MQTT消息是: $rawMessage &q…...

2024,java开发,已经炸了吗?
网友: 炸的透透的了,坐标南京。 一月底,一个好哥们,双休朝九晚六不加班18K,被裁。 入职不到两年,算是工资和年终奖才赔了6.5W左右。 上周五新公司入职,周六开始加班。现在每周134加班到晚上八…...

c++基础篇
一、命名空间: 1.1命名空间存在的意义: 1.1要知道c是对c语言缺点的完善,而在c语言中我们是知道,定义变量、函数名或者全域名是不能相同的,否则会产生冲突,但要知道这都是大量存在的,就像一个名…...

卫浴行业All in 智能化,国货品牌拿到了先手棋
想要了解一个行业的趋势和风向,展会可以说是最佳的窗口。 比如半个月前在上海举办的第28届中国国际厨房、卫浴设施展览会上,1500多家国内外企业同台竞技,给出了各自的解决方案,其中“智能化”已成为出镜率最高的词汇。 走在数智…...

分享10个国内可以使用的GPT中文网站
在今天的人工智能领域,基于对话的语言模型已成为研究的热点,尤其是像 ChatGPT 这样因其出色的语言理解与对话交互能力而广受关注的模型。本文将介绍10个国内可以直接使用GPT的网站,旨在为大家在选择和使用这些优秀的AI工具时提供有价值的参考…...

golang实现mediasoup的tcp服务及channel通道
tcp模块 定义相关类 Client:表示客户端连接,包含网络连接conn、指向服务器的指针Server和Channel指针c。server:表示TCP服务器,包含服务器地址address、TLS配置config以及三个回调函数: onNewClientCallback…...

Spring:IoC容器(基于注解管理bean)
1. HelloWorld * 引入依赖* 开启组件扫描* 使用注解定义 Bean* 依赖注入 2.开启组件扫描 <?xml version"1.0" encoding"UTF-8"?> <beans xmlns"http://www.springframework.org/schema/beans"xmlns:xsi"http://www.w3.org/20…...

如何解决Redis缓存雪崩问题?
解决Redis缓存雪崩问题,可以从多个方面入手来确保系统在高并发和缓存失效时能够保持稳定运行。以下是一些具体的解决策略: 合理设置缓存过期时间: 避免大量缓存设置相同的过期时间,这样会导致在某一时刻缓存同时失效,…...

vue3的组件通信v-model使用
一、组件通信 1.props 》 父向子传值 props 主要用于父组件向子组件通信。再父组件中通过使用:msgmsg绑定需要传给子组件的属性值,然后再在子组件中用props接收该属性值 方法一 普通方式:// 父组件 传值<child :msg1"msg1" :list"list">…...

从关键新闻和最新技术看AI行业发展(2024.5.6-5.19第二十三期) |【WeThinkIn老实人报】
写在前面 【WeThinkIn老实人报】旨在整理&挖掘AI行业的关键新闻和最新技术,同时Rocky会对这些关键信息进行解读,力求让读者们能从容跟随AI科技潮流。也欢迎大家提出宝贵的优化建议,一起交流学习💪 欢迎大家关注Rocky的公众号&…...
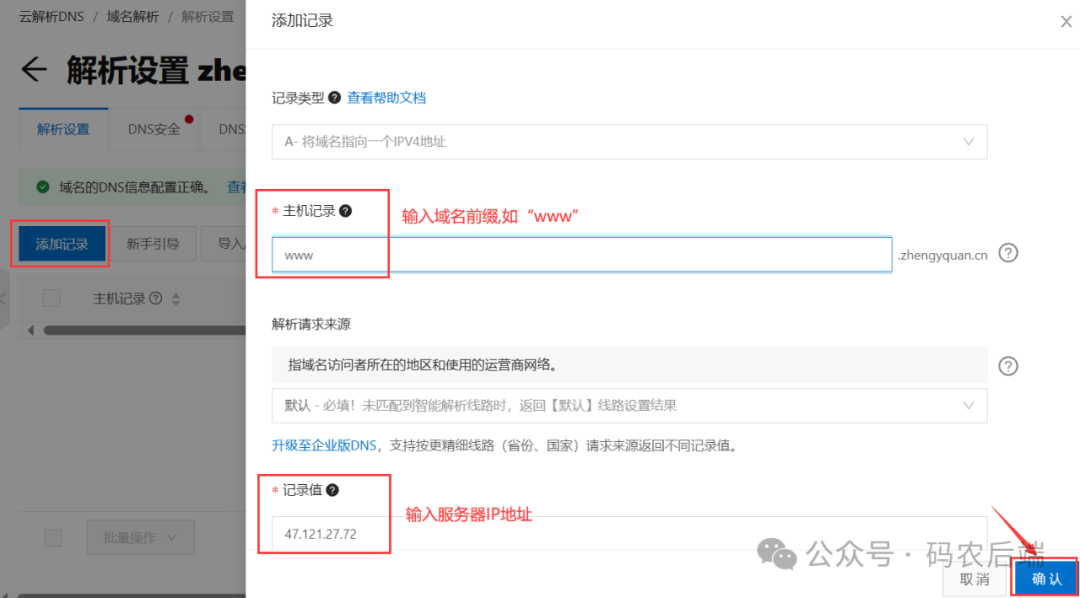
一文带你学会如何部署个人博客到云服务器,并进行域名备案与解析!
哈喽,大家好呀!这里是码农后端。之前我给大家介绍了如何快速注册一个自己的域名,并创建一台自己的阿里云ECS云服务器。本篇将介绍如何将个人博客部署到云服务器,并进行域名备案与解析。 1、域名备案 注册了域名并购买了云服务器之…...

YoloV8实战:复现基于多任务的YoloV8方案
摘要 自动驾驶中多任务学习,特别是通过设计一种自适应、实时且轻量级的模型来同时处理目标检测、可行驶区域分割和车道线分割,是一种非常有用的研究方法,其中最出名的当属YOLOP模型。然后,YoloP在实时性上并没有得到满足,本文复现基于YoloV8的对任务方案,并在BDD100K数据…...

专题汇编 | ChatGPT引领AIGC新浪潮(一)
ChatGPT的产生与迭代 2022年11月末,美国人工智能研究实验室OpenAI推出ChatGPT。上线的ChatGPT只用了2个月,活跃用户数就突破了1亿,创造了应用增速最快的纪录。 ChatGPT是什么 ChatGPT是一种人工智能技术驱动的自然语言处理(Natural Language Processing,NLP)工具,使用的…...
Excel分类汇总,5个做法,提高数据处理效率!
在日常的工作中,我们经常需要使用Excel中的各种功能,Excel分类汇总功能无疑是数据分析和报告制作中的一把利器,它极大地提高了数据处理的效率和准确性。在现代商业环境中,数据无处不在,而如何从这些数据中提取有效信息…...

使用Nginx实现高可用HTTP和TCP代理:健康检查与最佳实践配置20240523
使用Nginx实现高可用HTTP和TCP代理:健康检查与最佳实践配置 在现代分布式系统中,确保应用的高可用性至关重要。Nginx作为一个高性能的HTTP服务器和反向代理,同时也支持TCP代理,通过合理配置可以大大提高系统的可用性。本文将深入…...

代码随想录算法训练营Day52 | 300.最长递增子序列、674. 最长连续递增序列、718. 最长重复子数组 | Python | 个人记录向
注:Day51休息。 本文目录 300.最长递增子序列做题看文章 674. 最长连续递增序列做题看文章 718. 最长重复子数组做题看文章 以往忽略的知识点小结个人体会 300.最长递增子序列 代码随想录:300.最长递增子序列 Leetcode:300.最长递增子序列 …...

Thorium浏览器技术深度解析:基于Chromium的极致性能优化与隐私增强机制
Thorium浏览器技术深度解析:基于Chromium的极致性能优化与隐私增强机制 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are toward…...

韭菜盒子VSCode插件:开发者的终极投资情报中心完整指南
韭菜盒子VSCode插件:开发者的终极投资情报中心完整指南 【免费下载链接】leek-fund :chart_with_upwards_trend: 韭菜盒子VSCode插件,可以看股票、基金、期货等实时数据。 LeekFund turns your VS Code and Cursor into a real-time stock, fund, and fu…...

告别VNC客户端!用noVNC在浏览器里远程操控CentOS桌面,附Xshell/Xftp联动技巧
浏览器原生远程桌面方案:noVNC与终端工具链的高效整合指南每次连接远程服务器都要切换多个客户端的日子该结束了。想象一下这样的场景:清晨的咖啡馆里,你只需打开浏览器就能直接访问CentOS的图形界面,同时在一个标签页里用Xshell执…...

BiliBiliCCSubtitle架构解析:C++实现的B站CC字幕高效下载与转换技术方案
BiliBiliCCSubtitle架构解析:C实现的B站CC字幕高效下载与转换技术方案 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle BiliBiliCCSubtitle是一款基于C…...

Windows资源管理器的视觉革命:让iPhone照片在Windows上“活“起来
Windows资源管理器的视觉革命:让iPhone照片在Windows上"活"起来 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails…...

从API调用日志看Taotoken在访问控制与审计上的价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从API调用日志看Taotoken在访问控制与审计上的价值 对于将大模型能力集成到业务流程中的团队而言,API调用不仅是功能实…...
:单例模式——全局唯一实例的正确打开方式)
设计模式实战解读(一):单例模式——全局唯一实例的正确打开方式
本文是「设计模式实战解读」系列第一篇。系列文章统一按照 定义 → 痛点场景 → 模式结构 → 核心实现 → 真实应用 → 常见变种 → 优缺点 → 避坑指南 → FAQ 的结构展开,每篇聚焦一个模式讲透。一句话定义 单例模式(Singleton):…...

以下是 MaxWell 工业上位机项目的最终完整补充
以下是 MaxWell 工业上位机项目的最终完整补充:1. Region 管理面板(Region Management Panel) 这是一个用于运行时监控和管理 Region 的调试/管理界面,适合工业项目开发和维护阶段使用。 RegionManagementView.xaml <!-- Views…...

机器学习结合对称性描述符高效预测硅带隙温度依赖性
1. 项目概述:当机器学习遇见声子物理在材料计算领域,我们常常面临一个“鱼与熊掌”的困境:一方面,基于第一性原理的密度泛函理论(DFT)计算能给出相当可靠的基态电子结构,比如硅的晶格常数、能带…...

5分钟成为网页资源管理高手:猫抓插件让你的浏览器无所不能
5分钟成为网页资源管理高手:猫抓插件让你的浏览器无所不能 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经在浏览网页时&…...