[自动驾驶技术]-8 Tesla自动驾驶方案之硬件(AI Day 2022)
特斯拉在AI Day 2022先介绍了AI编译器,后面又介绍了Dojo的硬件软件,软件部分和AI编译器有部分重叠,本文介绍还是延用AI Day的思路,分为三部分:AI编译和推理,Dojo硬件,Dojo软件。
特斯拉车道检测网络


特斯拉车道网络使用稀疏点预测和计算来识别和预测车道线的位置和形状,极大地减少了计算量,使得网络可以在高帧率下运行,提供实时的车道信息。稀疏点预测和计算是特斯拉FSD推理系统的重要组成部分,通过高效的计算和存储策略,优化了稀疏点的预测和处理过程。
1 稀疏点预测
热图生成:网络首先预测最可能的空间位置点的热图(heat map),这一步骤使用卷积神经网络或其他适合的架构生成每个可能位置的概率分布。
ArgMax操作:对生成的热图应用ArgMax操作,找到概率最高的空间位置索引,这一步骤确定了最可能的稀疏点的位置。
One-hot编码:将找到的空间位置索引转换为one-hot编码。one-hot编码是一种稀疏表示,只在一个位置上有1,其余位置都是0。
2 稀疏计算
嵌入向量选择:使用one-hot编码从嵌入表(embedding table)中选择对应的嵌入向量。嵌入表是在训练期间学习的,包含了各个位置的特征表示;特斯拉在SRAM中构建了一个查找表,设计了嵌入向量的维度,使得可以通过矩阵乘法来实现高效查找。
嵌入缓存:选中的嵌入向量存储在一个token缓存中,这一缓存机制避免了每次迭代都重新计算嵌入,从而提高了计算效率和速度。
矩阵乘法实现查找:通过矩阵乘法实现嵌入查找和计算,这种方式利用了硬件加速器(如特斯拉FSD芯片)对矩阵运算的优化,提高了计算效率。
3 稀疏点处理
特征融合:稀疏点的特征通过自回归和迭代的方式逐步融合,每一步处理都结合前一步的稀疏点特征,逐步构建全局的空间表示。
迭代优化:每次迭代中,网络生成新一轮的稀疏点预测,并将这些点的特征与之前的结果结合,进行进一步处理,这一过程反复进行,直到得到最终的稀疏点集合。
特斯拉的AI编译器

特斯拉的AI编译器是为其自动驾驶系统优化深度学习模型推理而设计的,主要目标是将复杂的神经网络图优化为高效的推理代码,以在FSD计算硬件上运行。
1 AI编译器功能
特斯拉的AI编译器旨在处理大规模神经网络图,将其分割、优化并生成适合在其自研硬件上运行的高效代码。这个编译器处理的图包含了数十万的节点和连接,涵盖了自动驾驶系统中的各种任务,包括感知、预测和规划。
2 编译器工作流程
(可结合之前介绍的AI编译器背景内容:[编译器]-2 AI编译器介绍)
1)图分割与划分(Graph Partitioning and Splitting):编译器首先接收一个完整的神经网络图,该图可能包含多个任务和子任务,使用图分割技术,将大图分割成多个独立的子图,每个子图代表一个相对独立的计算单元,可以在硬件上独立运行。
2)子图优化(Subgraph Optimization):对每个子图进行独立优化,利用特斯拉硬件的特性进行定制化调整。具体优化包括操作融合、常量折叠和子图内的并行化等。
3)生成高效代码(Code Generation):编译器将优化后的子图转换为适合FSD硬件运行的低级代码,生成的代码能够充分利用硬件的特性,如硬件加速的矩阵运算和特定的AI计算单元。
4)链接与调度(Linking and Scheduling):将各个独立的子图代码链接起来,形成一个完整的推理程序,通过优化的调度算法,确保子图之间的数据传输和计算顺序最优化,以实现最低的推理延迟和最高的计算效率。
3 常规优化策略
1)操作融合(Operation Fusion):将多个相邻的算子融合为一个算子,减少中间数据存储和传输的开销。例如将卷积操作和激活函数融合在一起,直接计算激活后的结果。
2)常量折叠(Constant Folding):在编译时预计算所有可能的常量表达式,减少运行时的计算量。例如将所有不依赖于输入数据的固定计算提前计算并存储。
3)内存优化(Memory Optimization):优化内存分配和数据布局,以减少内存访问延迟和带宽消耗。利用内存复用技术,使得同一块内存区域可以在不同时间段存储不同的数据,减少总的内存需求。
4)并行化(Parallelization):充分利用FSD硬件的多核架构和并行计算能力,将计算任务拆分并行执行,利用专用AI加速单元的并行计算特性,提高整体计算速度。
5)稀疏计算(Sparse Computation):针对稀疏神经网络图,利用稀疏矩阵乘法和稀疏激活函数等技术减少无效计算,通过只计算非零值的操作,减少总体计算量。
6)流水线和批处理(Pipelining and Batching):利用流水线技术将不同计算任务的执行重叠起来,提高计算资源的利用率。通过批处理技术,将多个输入数据同时处理,减少单次推理的平均计算时间。
DOJO硬件



1 Dojo Tile
Dojo Tile是Dojo加速器的核心计算单元,每个Tile包含25个D1芯片(并行处理大规模的矩阵乘法运算),这些芯片专门设计用于高效的矩阵运算和深度学习任务。Tile的设计考虑了高带宽、低延迟的特点,使其能够在大规模计算任务中保持高效。
2 System Tray
System Tray是Dojo加速器中一个关键的组件,高度集成的系统托盘负责机械和热管理,并集成了高功率传输功能;每个托盘支持六个Tile,总计算能力达到54 PetaFLOPS,配备640 GB高带宽内存。具体特点如下:
1)层压母线(Laminated Bus Bar):这是一种高功率传输组件,能够在极高的功率密度下进行机械和热管理。它的高度为75毫米,能够支持六个Tile,总重量为135千克。
2)数据接口:System Tray提供高带宽的DRAM接口,用于存储训练数据,并通过TTP(Tesla Transfer Protocol)客户协议与训练Tile进行通信,确保了数据能够高效地传输到每个Tile。
3 Exapod
Exapod是Dojo系统的更大级别的集成单元,旨在将多个Dojo加速器组合在一起,总计算能力达到一ExaFLOP,确保大规模机器学习任务的高效处理。配备冗余电源,可以将三相480伏交流电转换为52伏直流电,确保系统在高功率需求下的稳定运行。
DOJO软件
特斯拉全自动驾驶(FSD)软件系统依赖于高度优化的软硬件协同工作,主要组件包括JIT神经网络编译器、LLVM后端、数据摄取流水线等。
JIT NN编译器和LLVM后端:JIT NN编译器即时编译神经网络模型,将高层次的神经网络代码转换为低层次的机器指令。LLVM后端利用LLVM编译器基础设施生成高效的机器代码,使得编译后的代码能够在Dojo硬件上高效运行。
摄取流水线(Ingest Pipeline):负责将数据高效地传输到硬件中,确保硬件始终有足够的数据进行处理,避免因数据饥饿而导致的性能下降。

1 性能优化
性能的提升依赖于利用率(utilization)和加速器占用率(occupancy)。
硬件提供了高峰值性能,编译器的任务是从硬件中提取最大化的利用率,而摄取流水线的任务是确保数据吞吐量足够高。特斯拉的Dojo系统设计用于高利用率处理大规模模型,不仅加速计算密集型部分,还加速延迟敏感部分(如Batch Normalization)和带宽敏感部分(如梯度汇总和参数聚合)。
2 编译器优化策略
1)提取并行性
模型并行:在多个加速器上并行执行不同部分的模型。
数据并行:在多个加速器上并行处理不同批次的数据。
张量并行:在多个加速器上并行处理单个张量的不同部分。
2)SRAM中的张量存储:张量通常在SRAM中分片存储,并在执行层时即时复制。
3)重叠计算和数据传输:在计算的同时进行数据传输,最大限度地利用计算资源。
3 性能测试结果
一句话,特斯拉的硬件性能远超行业其它GPU。


相关文章:
[自动驾驶技术]-8 Tesla自动驾驶方案之硬件(AI Day 2022)
特斯拉在AI Day 2022先介绍了AI编译器,后面又介绍了Dojo的硬件软件,软件部分和AI编译器有部分重叠,本文介绍还是延用AI Day的思路,分为三部分:AI编译和推理,Dojo硬件,Dojo软件。 特斯拉车道检测…...

人力资源管理信息化系统如何支持企业开展管理诊断?
华恒智信人力资源顾问有限公司致力于帮助企业开展人力资源管理方面的各项提升改进工作,在长期的咨询工作中,最常听到企业提到的问题莫过于管理诊断方面的问题,事实上,很多企业在日常工作中,都意识到企业内部存在管理方…...
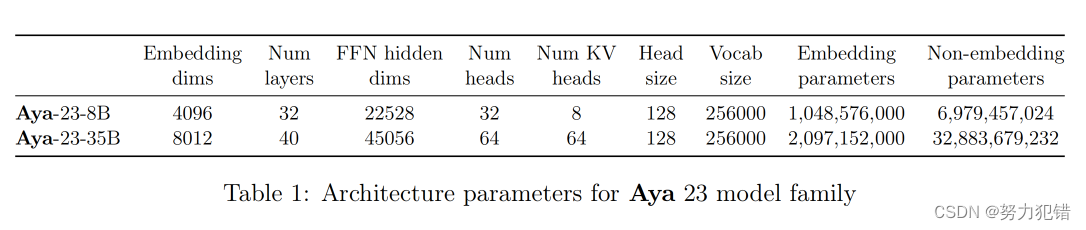
Cohere继Command-R+之后发布大模型Aya-23,性能超越 Gemma、Mistral 等,支持中文
前言 近年来,多语言大模型(MLLM)发展迅速,但大多数模型的性能依然存在显著差距,尤其是在非英语语言方面表现不佳。为了推动多语言自然语言处理技术的发展,Cohere团队发布了新的多语言指令微调模型家族——…...

身为UI设计老鸟,不学点3D,好像要被潮流抛弃啦,卷起来吧。
当前3D原则在UI设计中运用的越来越多,在UI设计中,使用3D元素可以为界面带来以下几个价值: 增强视觉冲击力:3D元素可以通过立体感和逼真的效果,为界面增添视觉冲击力,使得设计更加生动、吸引人,并…...


【C语言】实现贪吃蛇--项目实践(超详细)
前言: 贪吃蛇游戏大家都玩过吧?这次我们要用C语言来亲手制作一个!这个项目不仅能让我们复习C语言的知识,还能了解游戏是怎么一步步做出来的。我们会一起完成蛇的移动、食物的生成,还有碰撞检测等有趣的部分。准备好了…...
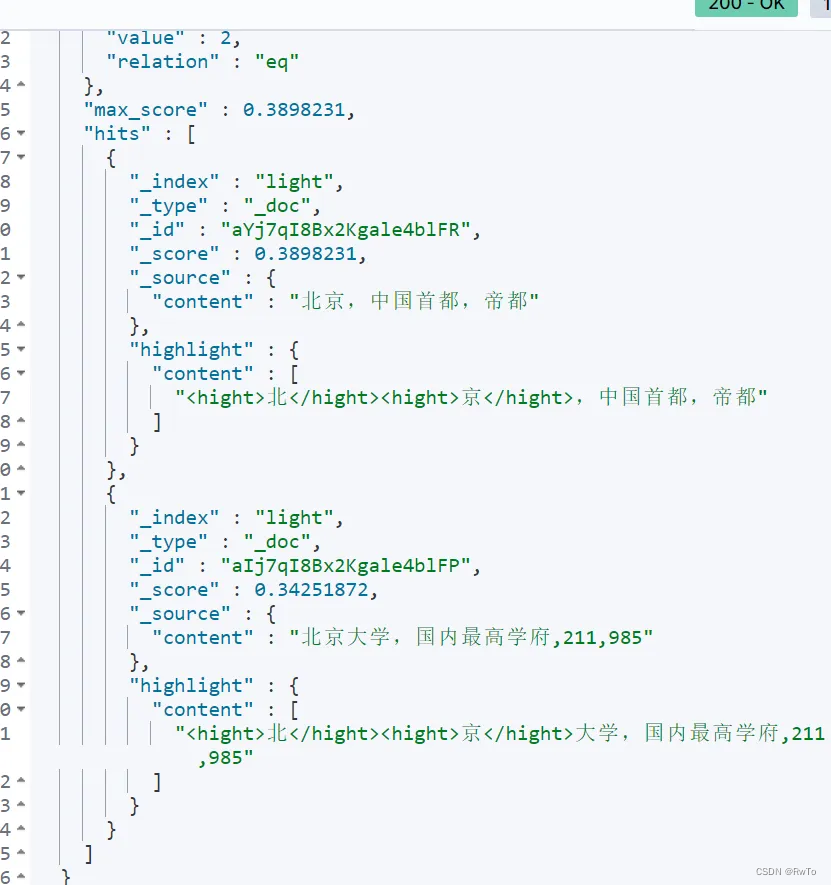
Elasticsearch 分析器的高级用法一(同义词,高亮搜索)
Elasticsearch 分析器的高级用法一(同义词,高亮搜索) 同义词简介分析使用同义词案例 高亮搜索高亮搜索策略unifiedplainvh 同义词 简介 在搜索场景中,同义词用来处理不同的查询词,有可能是想表达相同的搜索目标。 例…...
Python 开心消消乐
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...

mysql - 索引基本知识梳理
mysql索引基本知识梳理 索引介绍 官方介绍索引是帮助MySQL高效获取数据的数据结构, 原理为以空间换时间, mysql的索引采用的是B树的结构 索引的优缺点 优点: 提高查询效率降低数据库IO成本通过索引对数据进行排序, 降低排序成本, 降低CPU消耗 缺点:…...

Nginx SSL/TLS配置:搭建安全的HTTPS网站
随着互联网安全性的日益提升,HTTPS已经成为网站安全通信的标配。Nginx作为一款高性能的HTTP和反向代理服务器,支持SSL/TLS协议,使得我们可以轻松地搭建安全的HTTPS网站。下面,我们将详细介绍如何在Nginx上配置SSL/TLS,…...

echarts 折线图流光效果偏移或不显示
x轴数据需要字符串数组...
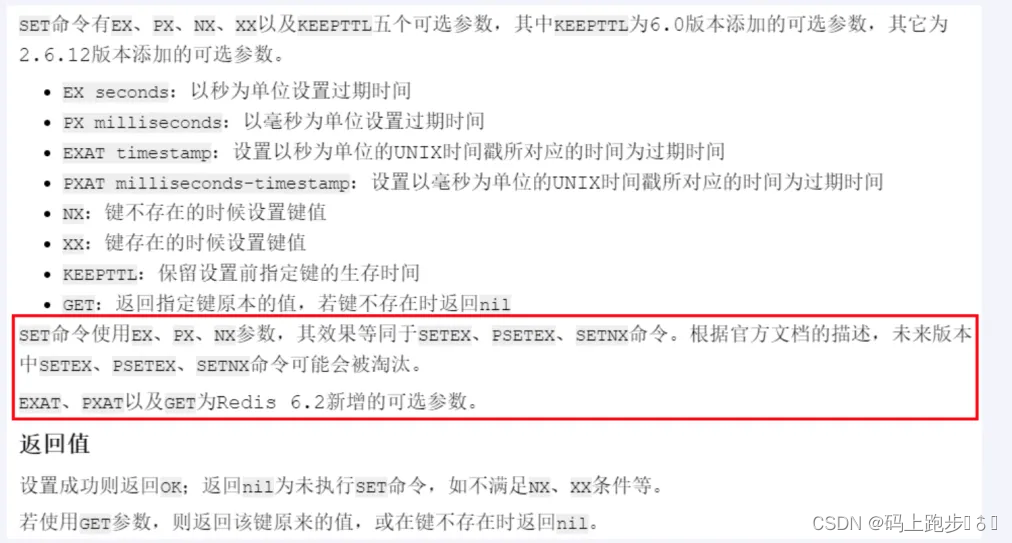
Redis数据类型(上篇)
前提:(key代表键) Redis常用的命令 命令作用keys *查看当前库所有的keyexists key判断某个key是否存在type key查看key是什么类型del key 删除指定的keyunlink key非阻塞删除,仅仅将keys从keyspace元数据中删除,真正的…...
VMware虚拟机安装Linux
1.下载Linux的ISO镜像文件 阿里镜像源网站: https://developer.aliyun.com/mirror/ 清华大学镜像源网站: https://mirrors.tuna.tsinghua.edu.cn/本人选择的是:Centos7.9.2009标准版 https://mirrors.tuna.tsinghua.edu.cn/centos/7.9.2009/isos/x86_64/ 标准版&a…...

slurm是什么,怎么用? For slurm和For Pytorch有什么区别和联系?
1.slurm是什么? Slurm(Simple Linux Utility for Resource Management)是一种开源的、用于集群和超级计算机的作业调度系统。它主要用于管理和调度大规模计算任务,使得用户可以有效地利用集群中的计算资源。Slurm提供了一套功能强…...

类和对象【六】友元和内部类
文章目录 友元友元的作用友元的缺点友元函数语法:特点: 友元类语法:特点: 内部类概念特点 友元 友元的作用 友元提供了一种打破封装的方式,有时提供了便利。 友元的主要作用就是打破封装 即可以让一个类的友元函数…...
一点点 cv 经验 1:cv方向、模型评估、输入尺寸、目标检测器设计
一点点 cv 经验 1:cv方向、模型评估、输入尺寸、目标检测器设计 cv 方向Pytorch数据集划分 模型评估误差偏差方差噪声 输入尺寸方法一:让数据适应模型方法二:修改模型适应数据方法三:划分Patch,分别处理 目标检测器结构…...

Java-SpringBoot集成Langchain4j文本嵌入模型实现向量相似度查询
集成Pg数据库并创建vector字段类型 运行pgvector容器 根据需要进行容器目录挂载 docker run --name pgvector \-e POSTGRES_PASSWORD123456 \-p 5432:5432 \-d --platform linux/amd64 ankane/pgvector:latest 进入docker容器并创建vector字段类型 docker exec -it pgvecto…...

正宇软件:引领数字人大新纪元,开启甘肃人大代表履职新篇章
在数字化强国的主旋律之下,政府工作的数字化、智能化转型已成为提升治理效能、增强人民满意度的关键一环。在这个大背景下,正宇软件技术开发有限公司以其卓越的技术实力和丰富的行业经验,成为了政府信息化建设的杰出代表。甘肃省人大代表履职…...

UniApp中,在页面显示时触发子组件的重新渲染
在UniApp中,要在页面显示时触发子组件的重新渲染,可以利用生命周期钩子函数来实现。具体来说,可以在页面的onShow生命周期钩子中调用子组件的方法或者改变子组件的props,从而触发子组件的重新渲染。 首先,确保子组件有…...
Linux(三)
Linux(三) Linux网络配置管理网络基础知识 IP地址A类 由1个字节网络地址3个字节主机地址B类 由2个字节网络地址2个主机地址C类 由3个字节网络地址1个主机地址D类:主要用于组播E类:为将来使用保留 子网掩码子网掩码作用网关DNS服务器 Linux用户管理用户的…...

别再折腾LibreOffice了!CentOS 7.9上老牌Apache OpenOffice 4.1.14的完整部署与避坑指南
企业级文档服务选型:Apache OpenOffice 4.1.14在CentOS 7.9的深度实践当我们需要在Linux服务器上搭建文档处理服务时,开源办公套件的选择往往令人纠结。Apache OpenOffice作为历经20年发展的老牌解决方案,在企业级环境中仍有一席之地。本文将…...

C166架构下XDATA解决全局变量内存溢出问题
1. 问题现象与背景分析在C166架构的嵌入式开发中,当程序包含大量初始化全局变量时,开发者经常会遇到两个经典错误:*** ERROR 172 IN LINE 9 OF test.c: HDATA0: length exceeded: act172032, max65536 Error 106: Section Overflow Section: …...

Redis分布式锁进阶第五十六篇
Redis分布式锁进阶第二十五篇:联锁深度拆解 多资源交叉死锁根治 复杂业务多级加锁绝对有序方案一、本篇前置衔接 第二十四篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实…...

范畴论视角下的概率机器学习:从Giry单子到贝叶斯推理的统一框架
1. 项目概述:当范畴论遇见概率机器学习如果你在机器学习领域摸爬滚打了一段时间,尤其是深度涉足过贝叶斯方法或概率图模型,你可能会对“不确定性”的数学表达感到既熟悉又头疼。我们习惯了用概率分布来描述数据噪声、参数先验和预测置信度&am…...

Cortex-R82集成ELA-600调试模块的信号连接问题解析
1. Cortex-R82与ELA-600集成时的信号连接问题解析在基于Arm Cortex-R82处理器的开发过程中,集成ELA-600(Embedded Logic Analyzer)调试模块是一个常见但容易产生困惑的环节。许多工程师在YAML配置文件中添加ELA-600支持后,会发现系…...

Claude学术写作辅助应用:3天写出SCI初稿?实测7个被顶刊编辑默许的Prompt技巧
更多请点击: https://intelliparadigm.com 第一章:Claude学术写作辅助应用:3天写出SCI初稿?实测7个被顶刊编辑默许的Prompt技巧 为什么Claude比GPT更适配学术写作场景 Claude系列模型(尤其是Claude 3.5 Sonnet&#…...

《Java 基础必学:ArrayList、HashMap 和泛型详解》
一、引言 1.为什么这些是 Java 基础的重点? ArrayList、HashMap 和泛型是Java集合框架的核心组成部分,广泛应用于实际开发中。 ArrayList:基于动态数组实现,支持快速随机访问,适合频繁查询和遍历的场景。HashMap&…...

企业部署 AI Agent Harness Engineering 的第一道坎不是技术,是信任
企业部署 AI Agent Harness Engineering 的第一道坎不是技术,是信任 引言 各位正在关注 AI Agent 落地企业生产环境的技术负责人、CTO、架构师、开发者们: 去年我在国内某头部 SaaS 公司做内部 Hackathon 的评委时,看到了一支由 3 个应届毕业的计算机科学博士和 2 个资深后…...

AI医疗Agent如何72小时通过NMPA二类证审批:附2024最新审评问答清单与材料模板
更多请点击: https://intelliparadigm.com 第一章:AI医疗Agent的监管合规本质与NMPA二类证核心逻辑 AI医疗Agent并非通用大模型的简单应用延伸,而是以临床决策支持、病灶识别、报告生成等具体医疗器械功能为边界的技术实体。其监管合规本质在…...

Unity打包踩坑实录:用了EPPlus读取Excel,为什么PC打包后报错?附I18N.dll解决方案
Unity开发实战:EPPlus集成与PC打包的I18N.dll解决方案 在Unity项目开发中,Excel表格作为游戏配置数据的载体被广泛使用。EPPlus作为一款优秀的.NET Excel操作库,因其无需Office环境支持、性能优异等特点,成为Unity开发者的热门选择…...