一点点 cv 经验 1:cv方向、模型评估、输入尺寸、目标检测器设计
一点点 cv 经验 1:cv方向、模型评估、输入尺寸、目标检测器设计
- cv 方向
- Pytorch
- 数据集划分
- 模型评估
- 误差=偏差+方差+噪声
- 输入尺寸
- 方法一:让数据适应模型
- 方法二:修改模型适应数据
- 方法三:划分Patch,分别处理
- 目标检测器结构设计思路
- 从哪几个方面分析目标检测器
- YOLO 系列
- Anchor-Based
cv 方向
cv 各个方向:https://github.com/amusi/Computer-Vision-Tasks-Survey
CV的研究大致分为以下几个方向:
二维:
- 图像:图像分类、图像分割、目标检测、人脸识别、文字识别、姿态估计、异常检测、图像检索、图像增强、风格迁移、图像生成等等
- 视频:视频分类、目标跟踪、重识别、行为识别、视频目标分割、视频内容分析
三维:
- 三维目标检测、位姿估计
- 点云生成
- 深度估计
- 三维重建:物、场景、人
- 视觉重定位
- 视觉SLAM
Pytorch
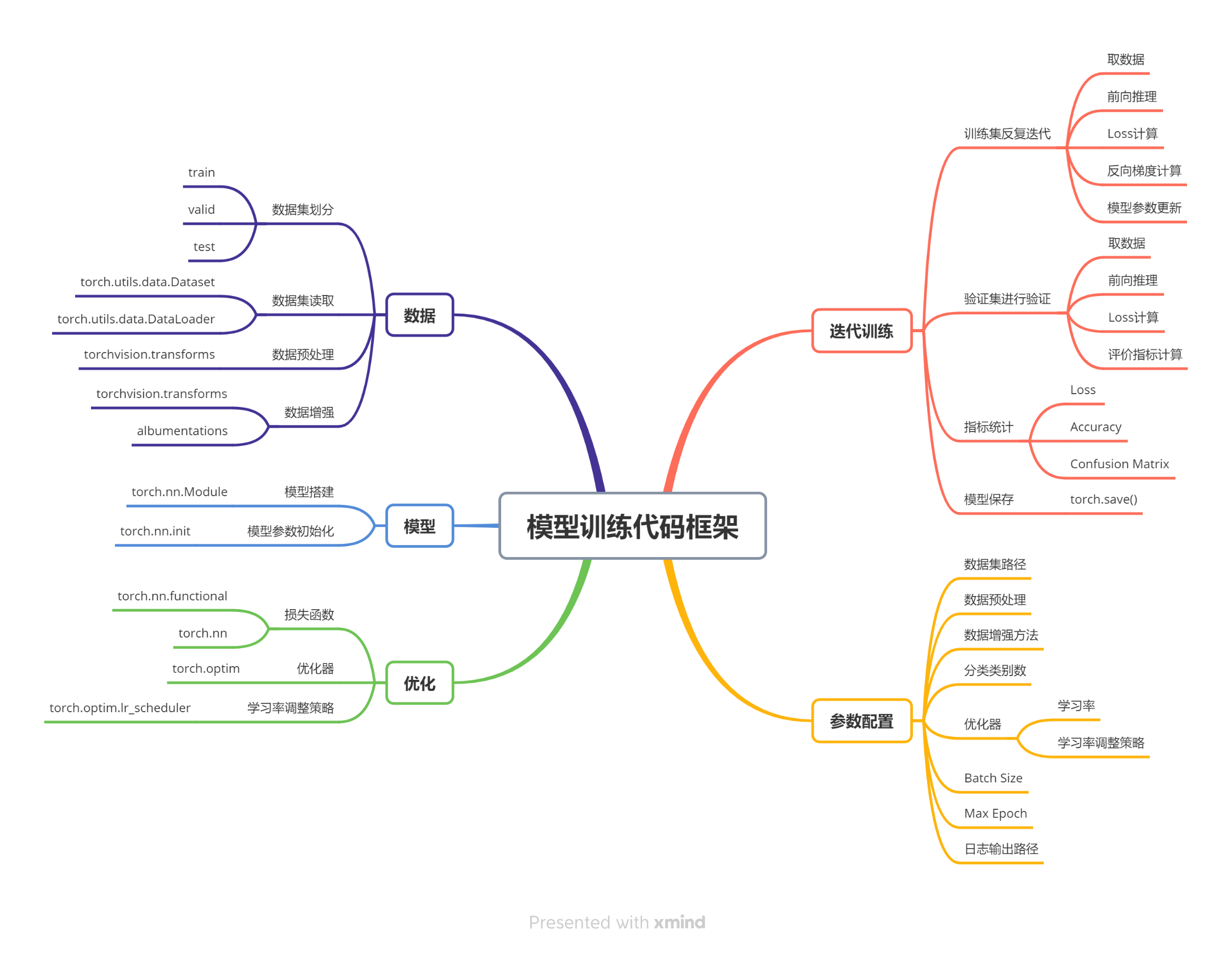
数据集划分
import os # 导入 os 模块,用于处理文件和目录路径
import random # 导入 random 模块,用于随机化数据
import shutil # 导入 shutil 模块,用于文件操作,例如复制文件# 定义函数:将图像列表复制到指定子目录下
def copy_file(img_list, target_dir, setname="train"): # 没有提供setname参数选择,那么函数将使用默认值“train”img_dir = os.path.join(target_dir, setname) # 目标子目录路径os.makedirs(img_dir, exist_ok=True) # 创建目标子目录for p in img_list: # 遍历图像列表shutil.copy(p, img_dir) # 复制图像到目标子目录print(f"{setname} dataset: copy {len(img_list)} images to {img_dir}") # 打印复制信息# 主程序入口
if __name__ == "__main__":# 指定花朵图像所在的目录img_dir = r"E:\data\flowers_data\jpg"# 获取指定目录下所有图像文件的路径列表img_list = [os.path.join(img_dir, name) for name in os.listdir(img_dir)]random.seed(10086) # 设置随机种子,以确保每次运行时随机结果的一致性random.shuffle(img_list) # 随机打乱图像路径列表# 定义训练集和验证集所占比例train_ratio = 0.8valid_ratio = 0.2# 计算总图像数量和训练集图像数量num_img = len(img_list)num_train = int(num_img * train_ratio)num_valid = num_img - num_train# 获取训练集和验证集图像路径列表train_list = img_list[: num_train]valid_list = img_list[num_train: ]# 获取花朵图像目录的父目录作为目标目录target_dir = os.path.abspath(os.path.dirname(img_dir))# 将训练集图像复制到新的 train 子目录下copy_file(train_list, target_dir, "train")# 将验证集图像复制到新的 valid 子目录下copy_file(valid_list, target_dir, "valid")
列表生成器作用:
这两行代码的作用是获取指定目录下所有图像文件的路径列表。
假设你有一个目录结构如下:
E:
└── data└── flowers_data└── jpg├── flower1.jpg├── flower2.jpg├── flower3.jpg└── ...
其中,E:\data\flowers_data\jpg 是存放花朵图像的目录,里面有很多花朵的图片文件,比如flower1.jpg、flower2.jpg等。
那么这两行代码做的事情就是:
img_dir = r"E:\data\flowers_data\jpg":将花朵图像所在的目录路径存储在变量img_dir中。img_list = [os.path.join(img_dir, name) for name in os.listdir(img_dir)]:os.listdir(img_dir):获取目录img_dir下的所有文件名列表,比如['flower1.jpg', 'flower2.jpg', 'flower3.jpg', ...]。os.path.join(img_dir, name):将目录路径img_dir与每个文件名name拼接起来,形成完整的文件路径,比如'E:\data\flowers_data\jpg\flower1.jpg'。- 最终,
img_list中存储的就是所有花朵图像的完整文件路径列表,例如['E:\data\flowers_data\jpg\flower1.jpg', 'E:\data\flowers_data\jpg\flower2.jpg', ...]。
这样,img_list就包含了目标目录下所有花朵图像的文件路径。
怎么调用:
这个代码的作用是将一个目录中的图像分成训练集和验证集,并将它们复制到新的目录中的子目录中。
你可以按照以下步骤来使用这个代码:
-
准备数据:
- 确保你有一组花朵图像,这些图像应该存储在一个目录中(在这个例子中是
E:\data\flowers_data\jpg)。
- 确保你有一组花朵图像,这些图像应该存储在一个目录中(在这个例子中是
-
保存代码:
- 将代码保存为一个Python文件,比如
split_data.py。
- 将代码保存为一个Python文件,比如
-
运行代码:
- 在命令行或终端中,进入到存放代码的目录。
- 执行代码:
python split_data.py。
-
查看结果:
- 运行完代码后,会在原始图像目录的父目录中生成两个子目录:
train和valid。 train目录中包含80%的训练集图像,valid目录中包含20%的验证集图像。
- 运行完代码后,会在原始图像目录的父目录中生成两个子目录:
确保在运行代码之前,你已经安装了Python,并且已经安装了用到的shutil、os和random模块。
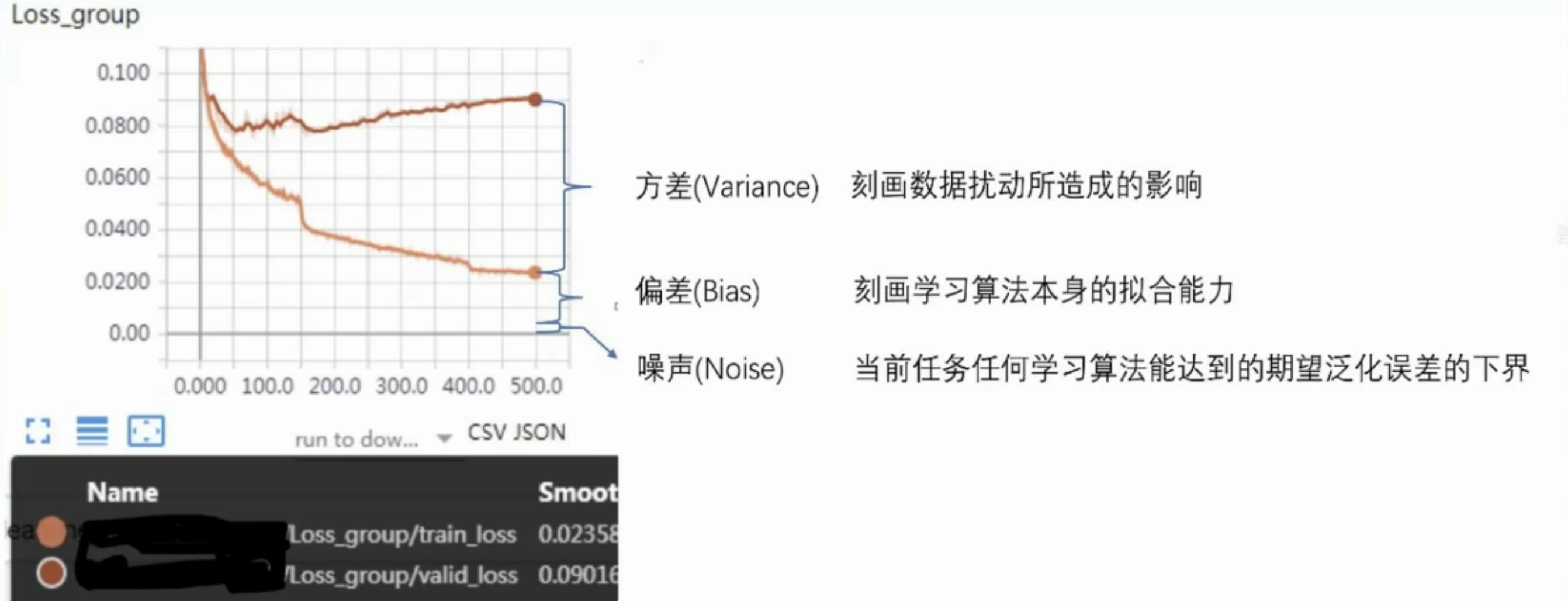
模型评估
误差=偏差+方差+噪声
假设我们正在使用YOLO算法来检测图像中的交通标志。我们有一个包含交通标志及其位置标注的数据集。我们将误差分解为偏差、方差和噪声,来解释模型的表现。
-
偏差(Bias):
假设我们选择了一个简单的YOLO模型,它只有少量的卷积层和池化层,无法很好地捕捉交通标志的复杂形状和背景。由于模型过于简单,它可能会错过一些交通标志,导致在训练集和测试集上都无法很好地检测到交通标志。这种情况下,偏差会很高,表明模型的拟合能力不足。 -
方差(Variance):
假设我们选择了一个非常复杂的YOLO模型,它有很多卷积层和池化层,以及大量的参数。这个模型在训练集上表现非常好,可以准确地检测到交通标志。然而,由于模型过于复杂,它对训练集中的数据点非常敏感。如果我们稍微改变训练集中的一些图像,可能会导致模型产生很大的变化。因此,模型在训练集和测试集上的性能差异很大,方差会很高。 -
噪声(Noise):
假设我们的数据集中存在一些图像质量较差、光照不足或者遮挡的情况,这些因素会影响模型的检测性能。即使我们使用最好的模型,也无法完全消除这些影响。噪声表示模型在当前任务上任何学习算法所能达到的期望泛化误差的下界。
偏差表示模型的拟合能力,方差表示模型对数据的敏感性,噪声表示数据的不确定性。
通过误差分解,我们可以更好地理解模型在训练和测试过程中的表现,从而选择合适的模型和优化策略。
输入尺寸
在处理机器学习和特别是计算机视觉问题时,输入尺寸的管理是一个重要的方面,因为模型通常要求所有输入数据具有一致的尺寸。
方法一:让数据适应模型
这种方法涉及调整数据以匹配模型的预设输入要求。
例如,如果你使用的模型设计为接收 256x256 像素的图像,你需要将所有输入图像调整为这个尺寸。
这通常通过以下技术实现:
- 缩放:改变图像的尺寸以匹配模型的输入尺寸。
- 裁剪:从原始图像中裁剪出符合模型输入尺寸的部分。
- 填充:如果原始图像比需要的尺寸小,可以在图像周围添加像素(通常是黑色或白色)以达到所需的尺寸。
这种方法的优点是实现简单,可以直接使用预训练模型而无需修改模型架构。
缺点是可能会引入几何变形或丢失信息,特别是当原始图像的宽高比与模型所需的宽高比不一致时。
在实践中,有一些模型会固定输入尺寸,而一些模型则可以接受变化的输入尺寸。
模型固定输入尺寸的情况:
-
传统的卷积神经网络(例如VGG、ResNet):
- 这些经典的卷积神经网络通常在设计时会固定输入尺寸,例如224x224像素。这样做的好处是可以更轻松地设计网络结构,并且在训练和推理过程中的计算量是确定的。
-
一些定制的网络架构:
- 有些特定任务或特定领域的网络架构可能会要求固定的输入尺寸,这是因为网络的设计与输入尺寸有关。
模型灵活接受不同输入尺寸的情况:
-
YOLO(You Only Look Once)目标检测算法:
- YOLO算法是一种可以处理任意尺寸的图像的目标检测算法。它将输入图像分成网格,并在每个网格上预测目标的边界框和类别。因此,YOLO不需要固定的输入尺寸,可以处理各种尺寸的图像。
-
FCN(Fully Convolutional Network)语义分割网络:
- FCN是一种用于图像分割的网络,可以接受任意尺寸的输入图像,并输出相同尺寸的语义分割结果。这种网络通过使用卷积和反卷积操作来实现对变尺寸输入图像的处理。
-
深度变换器网络(Spatial Transformer Network,STN):
- STN是一种可以对输入图像进行空间变换的网络,可以处理不同尺寸和角度的输入图像,并生成相应的变换后图像。
总的来说,有些模型需要固定的输入尺寸,而有些模型则可以接受不同尺寸的输入。
对于需要固定输入尺寸的模型,需要在训练和推理过程中将所有输入图像调整为相同的尺寸;而对于可以接受不同尺寸的模型,可以灵活处理不同大小的输入图像。
方法二:修改模型适应数据
这种方法涉及修改模型的架构以适应不同尺寸的输入数据。
这通常意味着使用更灵活的网络结构,例如全卷积网络,它们能够处理任意尺寸的输入。例如:
- 调整网络层:修改模型的第一层或其他层,使其能够接受不同尺寸的输入。
- 使用自适应池化层:使用自适应池化(如自适应平均池化或自适应最大池化)来保证网络的输出尺寸独立于输入尺寸。
修改模型使之适应不同的输入尺寸可以使模型更加灵活,不再受限于特定的输入尺寸。然而,这可能需要较深的技术知识来调整网络结构,且有时候可能导致训练效率降低。
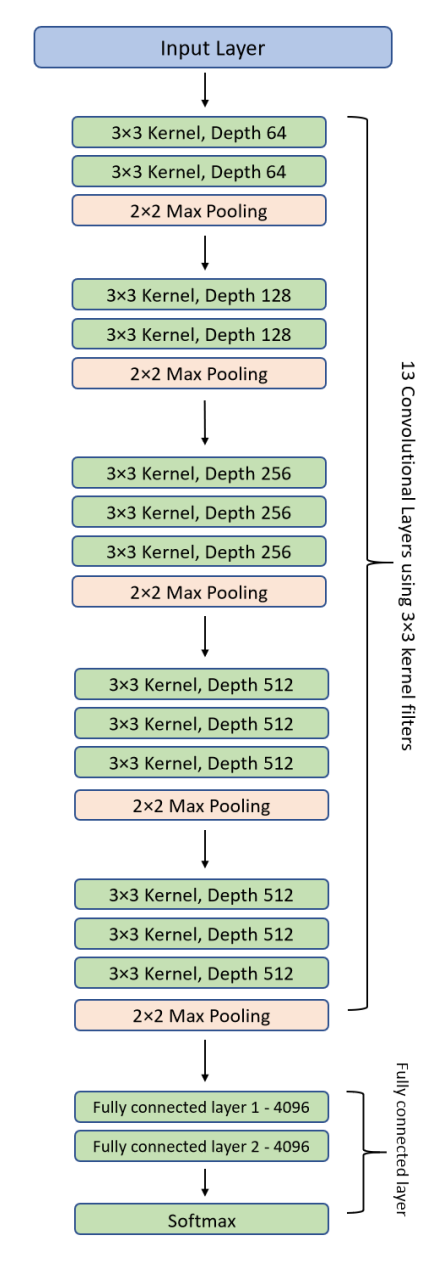
在提供的图像中,模型架构包括多个卷积层、池化层和全连接层。
这是一个经典的卷积神经网络,通常用于图像识别任务。
五种方法,我们可以对此模型进行修改,以适应不同的输入尺寸需求。这些修改分别影响模型的接受输入尺寸和特征提取的能力:
- 删除一个Pooling层,使224x224变为可接收112x112
- 删除一个Pooling层(比如2x2 Max Pooling),减少了图像尺寸下降的速度。这样模型可以在更小的输入尺寸(如112x112)上运行而不会太快减小特征图的维度,保留更多的特征信息。
- 增加一个Pooling层,使224x224变为可接收448x448
- 增加一个Pooling层可以使网络在处理更大尺寸的输入图像(如448x448)时,快速减小特征图的尺寸,以避免在网络深层中处理过大的数据量。
- 卷积步长stride=2 的,改为stride=1,使输入可变为112x112
- 当卷积层的步长从2改为1时,特征图的尺寸下降速度减慢。这样,较小的输入尺寸(如112x112)也能够在网络中保持足够的特征图尺寸,避免在深层中特征图尺寸过小。
- 卷积步长stride=1 的,改为stride=2,使输入可变为448x448
- 相反地,增加卷积层的步长可以加快特征图的尺寸下降。这样,在处理较大尺寸的输入(如448x448)时,可以避免特征图在网络深层中过大,有助于减少计算量和内存消耗。
- 使用全局平均池化(GAP)
- 引入全局平均池化层可以替换传统的全连接层,它会计算每个特征图的平均值形成一个固定大小的特征向量。这种方法的优势在于它使得网络可以处理任意尺寸的输入图像,因为无论输入图像的尺寸如何变化,全局平均池化输出的维度总是固定的。
这些修改使模型更加灵活,能够适应不同尺寸的输入,同时也影响模型的计算效率和特征提取能力。通过这样的调整,可以根据实际应用需求定制模型,优化其性能和资源使用效率。
方法三:划分Patch,分别处理
在某些应用中,尤其是图像尺寸非常大(如遥感影像或数字病理图像)时,可以将大图像划分为较小的片段(Patch),然后分别处理这些片段。例如:
- 图像分割:将大尺寸图像分割为多个较小的图像块,每个块符合模型的输入尺寸。
- 独立处理:对每个图像块独立应用模型,然后可能需要合并这些模型的输出以得到最终结果。
这种方法使得处理大尺寸图像变得可行,特别是当图像太大而无法直接输入到网络中时。这种方法的挑战在于如何有效地合并或解释这些独立处理块的结果,以确保整体结果的连贯性和准确性。
通过上述不同的方法,可以有效地管理和处理不同尺寸的输入数据,以满足特定模型的需求或优化模型性能。
目标检测器结构设计思路
目标检测,其目标是识别图像或视频中的物体,并确定它们的位置。这个任务通常包括两个子任务:分类和回归。
-
分类:这意味着识别图像中的物体属于哪一类别。例如,在一张道路场景的图像中,分类任务可能是识别汽车、行人、自行车等。
-
回归:这涉及确定物体的位置,通常是通过边界框来表示。边界框是一个矩形,用于描述物体在图像中的位置和大小。回归任务的目标是预测这些边界框的位置和尺寸,使其紧密地包围物体。
以YOLO(You Only Look Once)为例,它是一种流行的目标检测算法之一。
YOLO使用单个神经网络模型来同时执行分类和回归任务。
它将输入图像分成网格,并为每个网格预测边界框和类别。
这样,YOLO可以在一次前向传播中快速而准确地检测图像中的物体,因此它在实时应用中具有很高的性能。
目标检测(对一块区域分类+回归)算法设计:
- 需要自己构造样本;
- 需要自己为构造的样本分配标签;
- 除了分类任务外, 还有一个额外的回归任务。
- 反映在损失函数上, 除了分类损失函数外, 还应有一个额外的回归损失函数。
这种最简目标检测器(YOLO V1)将目标检测任务转换为滑窗区域的分类任务。
-
转换为分类任务:传统的目标检测任务涉及检测图像中的物体并定位它们。而这种方法则将目标检测任务简化为对图像中每个滑窗区域进行分类。滑窗是指图像上以固定大小和步长滑动的小方块区域。
-
使用分类模型的 Backbone:为了实现这个目标,可以直接使用一个预训练的图像分类模型的主干网络(backbone),如VGG、ResNet等。这样可以利用图像分类任务中已经学到的特征来帮助分类滑窗区域中是否包含目标物体。
-
构造分类损失函数:针对每个滑窗区域,构造分类损失函数来衡量模型对该区域的分类准确性。这个损失函数通常使用交叉熵损失函数来衡量模型对图像中目标物体的分类准确性。
-
每个滑窗区域作为一个样本:每个滑窗区域都被视为一个样本,并且被送入网络进行分类。因此,图像中的每个滑窗都会生成一个类别预测结果。
-
输出为M×N个向量:与传统的图像分类任务不同,网络的输出不再是一个单一的向量,而是包含了M×N个向量,每个向量对应一个滑窗区域的分类结果。
举个例子,假设我们有一张图像,大小为300×300像素。
我们选择一个大小为50×50像素的滑窗,并使用步长为10像素来滑动图像。
这样,我们就可以得到大约20×20=400个滑窗区域。
然后,我们将每个滑窗区域作为一个样本,送入预训练的分类模型进行分类。
最终,我们会得到400个分类结果,每个结果指示该滑窗区域是否包含目标物体。
从哪几个方面分析目标检测器
- Backbone:提取图像特征
- Neck:对特征图进行多尺度特征融合,并把这些特征传递给head层
- Head(分类分支、 回归分支):负责执行具体的任务,如分类、目标检测和图像分割等。通过输入经过Neck处理过的特征,产生最终的输出,从而实现模型的预测和分类任务.
- Anchor的选取方式
- 正负样本的分配方式
- 损失函数: 分类损失、 回归损失
从主干网络中得到特征图,每个位置都得到一个分类和回归的预测,有密集预测的问题,会漏掉部分目标。
一阶段目标检测算法(YOLO)都有这种问题,后来还有俩阶段目标检测算法,再加一个head层,俩个head,一个粗调,一个精调,更慢但效果更好。
YOLO 系列
v1:在图上做各个局部做卷积得到特征图,在特征图上寻找物体和具体位置
v2:v1特征图都是正方形框,但实际物体长的都不是正正方方,改进了预测框的自定义形状,如不同比例的长方形
v3:v2在处理图像有很多层,层越深感受野越大,最后一层输出层,就越适合大目标检测
那小目标咋办,v3打算分类处理,引入多个输出层,越前面的输出层适合小目标,中间的输出层适合中目标,最后一个输出层适合大目标。
v4:把别的论文中,最新的好用模块,改到Yolo中,反正视觉算法都是要提特征的,这种思想一直在持续,导致Yolo特别适合水论文,满大街都是各种Yolo论文
v5:从个人论文到团队项目,在不断维护,适合做项目
v6:略。
v7:推理加速,原先的Yolo加了很多分支结构,互相等导致速度变慢,训练时候可以不管用,但推理阶段你得合并,如卷积和bn层合并,配合gpu优化11补零凑出33卷积,多卷积核分支合并。
v8:v5团队续作,适合工程项目。做了一个集成,不仅能做检测,还能搞分割,分类,追踪,姿态估计,只需要改输出头,如分割只需要把最后一个输出层改一下
v9:v4 v7作者续作,v9解决神经网络因为链式结构的层层传播导致的信息丢失,那就开更短的辅助支路,解决浅层神经网络信息丢失问题。
v10:解决冗余预测问题和提高模型效率与准确度的策略。
首先,通过持续双重分配策略,包括双重标签分配和一致匹配度量,解决了后处理中的冗余预测问题,消除了对NMS的需求。
其次,在模型架构方面,通过轻量级分类头、空间-通道解耦下采样和rank引导block设计等方法提高了效率;同时,采用大核卷积和部分自注意力模块增强了模型的准确度。
这些改进使得模型在保持高效率的同时,在训练和推理过程中都能取得更优异的性能表现。
假设我们有一个YOLO模型用于物体检测,但在后处理过程中存在冗余预测问题,导致输出结果中有大量的重叠框。
想通过改进后处理步骤来解决这个问题,并同时提高模型的效率和准确度。
首先,引入了持续双重分配策略。
在训练过程中,为每个目标物体分配两个标签:一个主要标签和一个次要标签。
这样,模型在学习时可以得到更丰富和更和谐的监督信号。
在推理过程中,使用一致匹配度量来对预测结果进行过滤,而不是传统的非极大值抑制(NMS)方法。这消除了对NMS的需求,提高了推理的效率,并保持了竞争性的性能水平。
其次,对模型架构进行了全面的优化。
设计了轻量级分类头,减少了计算冗余。
同时,采用了空间-通道解耦下采样和rank引导block设计,进一步提高了模型的计算效率。
为了增强模型的准确度,我们引入了大核卷积和部分自注意力模块,以提高模型的感知能力和性能表现。
Anchor-Based
相关文章:
一点点 cv 经验 1:cv方向、模型评估、输入尺寸、目标检测器设计
一点点 cv 经验 1:cv方向、模型评估、输入尺寸、目标检测器设计 cv 方向Pytorch数据集划分 模型评估误差偏差方差噪声 输入尺寸方法一:让数据适应模型方法二:修改模型适应数据方法三:划分Patch,分别处理 目标检测器结构…...

Java-SpringBoot集成Langchain4j文本嵌入模型实现向量相似度查询
集成Pg数据库并创建vector字段类型 运行pgvector容器 根据需要进行容器目录挂载 docker run --name pgvector \-e POSTGRES_PASSWORD123456 \-p 5432:5432 \-d --platform linux/amd64 ankane/pgvector:latest 进入docker容器并创建vector字段类型 docker exec -it pgvecto…...

正宇软件:引领数字人大新纪元,开启甘肃人大代表履职新篇章
在数字化强国的主旋律之下,政府工作的数字化、智能化转型已成为提升治理效能、增强人民满意度的关键一环。在这个大背景下,正宇软件技术开发有限公司以其卓越的技术实力和丰富的行业经验,成为了政府信息化建设的杰出代表。甘肃省人大代表履职…...

UniApp中,在页面显示时触发子组件的重新渲染
在UniApp中,要在页面显示时触发子组件的重新渲染,可以利用生命周期钩子函数来实现。具体来说,可以在页面的onShow生命周期钩子中调用子组件的方法或者改变子组件的props,从而触发子组件的重新渲染。 首先,确保子组件有…...
Linux(三)
Linux(三) Linux网络配置管理网络基础知识 IP地址A类 由1个字节网络地址3个字节主机地址B类 由2个字节网络地址2个主机地址C类 由3个字节网络地址1个主机地址D类:主要用于组播E类:为将来使用保留 子网掩码子网掩码作用网关DNS服务器 Linux用户管理用户的…...

2024年郫都区区级农业生产社会化服务重点服务组织评定申报条件材料、程序要求
第一章 总 则 第一条 为深入贯彻《中共中央办公厅 国务院办公厅关于促进小农户和现代农业发展有机衔接的意见》《农业农村部关于加快发展农业社会化服务的指导意见》精神,充分发挥农业生产社会化服务组织在引领现代农业发展、打造新时代更高水平“天府粮仓”郫都…...

Java入门须知术语
文章目录 前言JVM (Java Virtual Machine)JVM的组成部分JVM的作用为什么需要JVM JRE(Java Runtime Environment)JRE的组成部分JRE的作用为什么需要JRE JDK(Java Development Kit,Java开发工具包)JDK的组成部分JDK的作用…...

Spring Boot中集成WebSocket
目录 WebSocket简介WebSocket原理WebSocket的使用场景在Spring Boot中集成WebSocket 创建Spring Boot项目添加依赖配置WebSocket创建WebSocket处理器配置WebSocket端点前端使用WebSocket添加WebSocket拦截器 WebSocket简介 WebSocket是一种在单个TCP连接上进行全双工通信的…...

18.多分类问题代码实现
在机器学习中,多分类问题是一类常见的问题,它涉及到将输入数据划分为多个类别中的一个。例如,在图像识别中,我们可能需要将图像分为不同的类别,如手写数字识别(MNIST数据集)就是将手写数字图像分…...
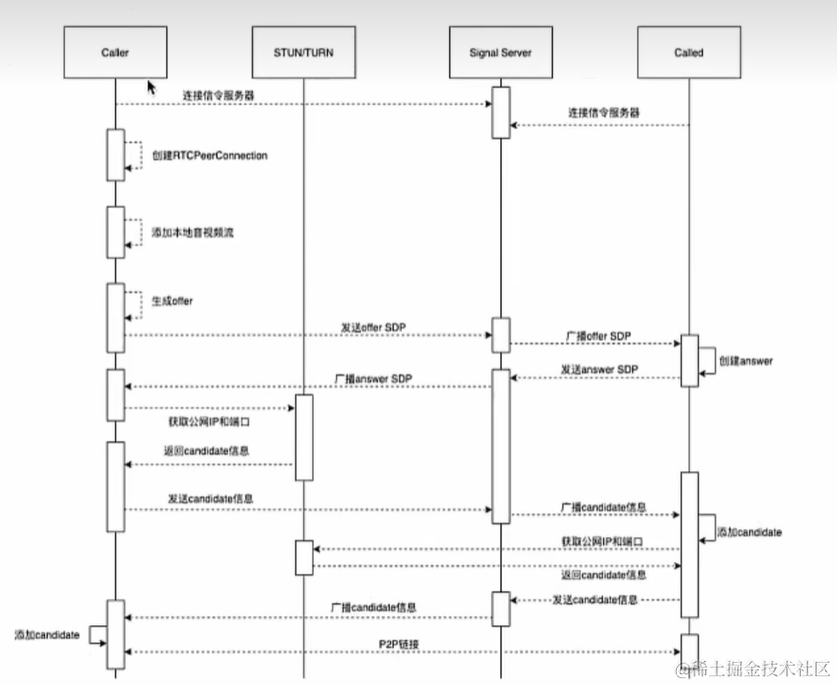
实时通信的方式——WebRTC
文章目录 基于WebRTC实现音视频通话P2P通信原理如何发现对方? 不同的音视频编解码能力如何沟通?(媒体协商SDP)如何联系上对方?(网络协商) 常用的API音视频采集getUserMedia核心对象RTCPeerConne…...
Android 使用 ActivityResultLauncher 申请权限
前面介绍了 Android 运行时权限。 其中,申请权限的步骤有些繁琐,需要用到:ActivityCompat.requestPermissions 函数和 onRequestPermissionsResult 回调函数,今天就借助 ActivityResultLauncher 来简化书写。 步骤1:创…...
如何将前端项目打包并部署到不同服务器环境
学习源码可以看我的个人前端学习笔记 (github.com):qdxzw/frontlearningNotes 觉得有帮助的同学,可以点心心支持一下哈(笔记是根据b站尚硅谷的前端讲师【张天禹老师】整理的,用于自己复盘,有需要学习的可以去b站学习原版视频&…...

什么样的展馆场馆才是科技满满?就差一张智慧场馆大屏
随着科技的飞速发展,传统的场馆展示方式已经无法满足现代人对信息获取和体验的需求。智慧场馆大屏作为一种新型的展示方式,应运而生。它将高清大屏显示技术、智能交互技术、数据分析技术等融为一体,为观众带来更加丰富、生动的展示体验。 一…...
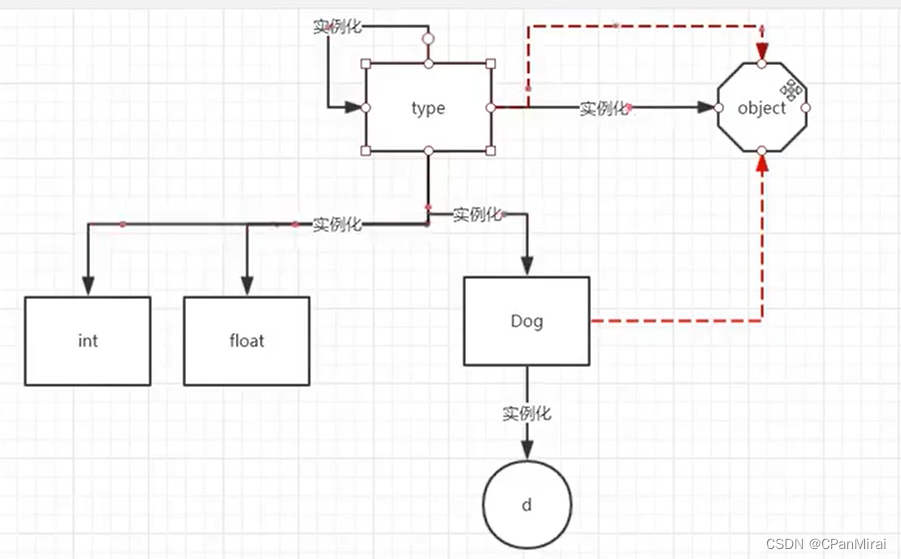
python核心编程(二)
python面向对象 一、基本理论二、 面向对象在python中实践2.1 如何去定义类2.2 通过类创建对象2.3 属性相关2.4 方法相关 三、python对象的生命周期,以及周期方法3.1 概念3.2 监听对象的生命周期 四、面向对象的三大特性4.1 封装4.2 继承4.2.1 概念4.2.1 目的4.2.2 分类4.2.3 t…...
【wiki知识库】02.wiki知识库SpringBoot后端的准备
📝个人主页:哈__ 期待您的关注 目录 一、🔥今日目标 二、📂打开SpringBoot项目 2.1 导入所需依赖 2.2修改application.yml配置文件 2.3导入MybatisPlus逆向工程工具 2.4创建一个公用的返回值 2.5创建CopyUtil工具类 2.6创建…...
)
python tuple(元组)
python list(列表)、创建、访问、内置index、判断in、not in、添加元素、insert、append、extend、列表排序、颠倒顺序、删除元素、remove、pop、clear-CSDN博客 目录 tuple: 元组的主要特点包括: tuple的创建 单个元组需要注…...

opencv调用摄像头保存视频
opencv调用摄像头保存视频 文章目录 opencv调用摄像头保存视频保存视频(采用默认分辨率640 x 480)保存视频(指定分辨率,例1280720) 保存视频(采用默认分辨率640 x 480) import cv2 import time # 定义视频捕捉对象 cap cv2.Vide…...

STM32定时器四大功能之定时器编码接口
1什么是编码器接口? 编码器接口接受编码器的正交信号,根据编码器产生的正交信号脉冲控制CNT的自增和自减,从而指示编码器的旋转方向和旋转速度。 每个高级定时器和通用定时器都有一个编码器接口,同时正交编码器产生的正交信号分…...
全国各城市间驾车耗时和距离矩阵数据集(更新至2022年)
数据简介:城市之间距离越远,耗时越长。经济发达地区的交通状况较好。各城市之间的驾车耗时和距离存在差异。有些城市之间的交通非常便捷,而有些城市之间的交通则较为不便。这表明中国的交通网络发展尚不平衡,需进一步优化。特别是…...

推荐二轮电动车仪表盘蓝牙主芯片方案-HS6621CGC
随着国内二轮电动车的火热开启,电动车的智能化程度越来越高;电动车的智能操控需求也越来越高,现在介绍蓝牙控制面板的一些功能;例如:定位(GNSS),设防,实时上报数据&#…...

BabelDOC:终极智能PDF翻译工具,完美保留格式布局的完整指南
BabelDOC:终极智能PDF翻译工具,完美保留格式布局的完整指南 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 你是否曾因学术论文翻译而烦恼?复杂的数学公式、…...

FreeTacMan系统:模块化触觉感知与多模态融合技术解析
1. FreeTacMan系统硬件架构解析FreeTacMan系统的硬件设计体现了模块化与轻量化的工程哲学。传感器主体通过主螺纹孔与夹持器基座刚性连接,这种设计可承受主要机械载荷。在相对侧,突出的定位结构与夹持器基座上的凹槽精密配合,实现了即插即用的…...

百度网盘直链解析技术实现与高速下载架构设计
百度网盘直链解析技术实现与高速下载架构设计 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 在云存储服务日益普及的今天,百度网盘作为国内用户量最大的云存储平台…...

Ubuntu 22.04 LTS下,UE5打包的程序报‘Vulkan设备找不到’?别急着重装驱动,先试试这个库文件修复法
Ubuntu 22.04 LTS下解决UE5 Vulkan设备报错的深度修复指南当你在Ubuntu 22.04 LTS上已经确认NVIDIA驱动安装成功(通过nvidia-smi验证),但Unreal Engine 5打包的程序仍然抛出"Vulkan设备找不到"的错误时,问题往往比表面看…...

LVF时序变异分析:原理、应用与EDA工具支持
1. 什么是LVF(Liberty Variance Format)?在芯片设计领域,时序分析是确保电路性能符合预期的重要环节。Liberty Variance Format(LVF)是一种用于描述时序变异的新方法,它解决了传统Stage Based O…...

【AI Agent旅游行业落地实战指南】:2024年已验证的7大高ROI应用场景与避坑清单
更多请点击: https://kaifayun.com 第一章:AI Agent旅游行业应用全景图 AI Agent正以前所未有的深度与广度重塑旅游产业的服务范式。它不再局限于单点智能响应,而是以目标驱动、多工具协同、自主规划与持续反思为特征,构建起覆盖…...

ZygiskFrida:安卓逆向中基于Zygote的零感知Frida注入方案
1. 这不是“又一个 Frida 注入工具”,而是安卓逆向工作流的物理层重构你有没有过这样的经历:在一台已 root 的测试机上调试某个金融类 App,想 hook 它的 SSL Pinning 检查逻辑,结果 Frida Server 启动失败;换用 frida-…...

FPGA在材料测试中的高精度控制与并行处理应用
1. FPGA在材料测试领域的革新价值 材料测试设备作为工业质量控制的核心装备,其性能直接影响着从汽车安全气囊到医疗植入物的产品可靠性。传统基于通用微控制器的测试系统正面临三大技术瓶颈:首先是测试标准迭代速度快,ASTM、ISO等组织每年新增…...

告别眨眼误判!用Python+OpenCV优化人脸68关键点疲劳检测的3个实用技巧
告别眨眼误判!用PythonOpenCV优化人脸68关键点疲劳检测的3个实用技巧在计算机视觉应用中,人脸关键点检测一直是热门研究方向。特别是68关键点检测技术,因其在表情识别、疲劳监测等场景中的实用性而备受关注。然而,许多开发者在实际…...

基于RTK-GPS与ResNet50的自主草坪清扫机器人系统设计与实践
1. 项目概述与核心挑战在公园维护的日常工作中,草坪垃圾清理是一项既耗费人力又效率低下的重复性劳动。传统的清扫方式要么依赖人工,要么使用大型、笨重且可能损伤草皮的设备。我们团队的目标,是设计并实现一个能够自主、高效且温和地完成这项…...