基于Pytorch框架的深度学习ShufflenetV2神经网络十七种猴子动物识别分类系统源码
第一步:准备数据
17种猴子动物数据:
self.class_indict = ["白头卷尾猴", "弥猴", "山魈", "松鼠猴", "叶猴", "银色绒猴", "印度乌叶猴", "疣猴", "侏绒","白秃猴", "赤猴", "滇金丝猴", "狒狒", "黑色吼猴", "黑叶猴", "金丝猴", "懒猴"],总共有1800张图片,每个文件夹单独放一种数据

第二步:搭建模型
本文选择一个ShufflenetV2网络,其原理介绍如下:
shufflenet v2是旷视提出的shufflenet的升级版本,并被ECCV2018收录。论文说在同等复杂度下,shufflenet v2比shufflenet和mobilenetv2更准确。shufflenet v2是基于四条准则对shufflenet v1进行改进而得到的,这四条准则如下:
(G1)同等通道大小最小化内存访问量 对于轻量级CNN网络,常采用深度可分割卷积(depthwise separable convolutions),其中点卷积( pointwise convolution)即1x1卷积复杂度最大。这里假定输入和输出特征的通道数分别为C1和C2,经证明仅当C1=C2时,内存使用量(MAC)取最小值,这个理论分析也通过实验得到证实。更详细的证明见参考【1】
(G2)过量使用组卷积会增加MAC 组卷积(group convolution)是常用的设计组件,因为它可以减少复杂度却不损失模型容量。但是这里发现,分组过多会增加MAC。更详细的证明见参考【1】
(G3)网络碎片化会降低并行度 一些网络如Inception,以及Auto ML自动产生的网络NASNET-A,它们倾向于采用“多路”结构,即存在一个lock中很多不同的小卷积或者pooling,这很容易造成网络碎片化,减低模型的并行度,相应速度会慢,这也可以通过实验得到证明。
(G4)不能忽略元素级操作 对于元素级(element-wise operators)比如ReLU和Add,虽然它们的FLOPs较小,但是却需要较大的MAC。这里实验发现如果将ResNet中残差单元中的ReLU和shortcut移除的话,速度有20%的提升。
根据前面的4条准则,作者分析了ShuffleNet v1设计的不足,并在此基础上改进得到了ShuffleNetv2,两者模块上的对比下图所示

第三步:训练代码
1)损失函数为:交叉熵损失函数
2)训练代码:
import os
import math
import argparseimport torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import torch.optim.lr_scheduler as lr_schedulerfrom model import shufflenet_v2_x1_0
from my_dataset import MyDataSet
from utils import read_split_data, train_one_epoch, evaluatedef main(args):device = torch.device(args.device if torch.cuda.is_available() else "cpu")print(args)print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')tb_writer = SummaryWriter()if os.path.exists("./weights") is False:os.makedirs("./weights")train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),"val": transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}# 实例化训练数据集train_dataset = MyDataSet(images_path=train_images_path,images_class=train_images_label,transform=data_transform["train"])# 实例化验证数据集val_dataset = MyDataSet(images_path=val_images_path,images_class=val_images_label,transform=data_transform["val"])batch_size = args.batch_sizenw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workersprint('Using {} dataloader workers every process'.format(nw))train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,pin_memory=True,num_workers=nw,collate_fn=train_dataset.collate_fn)val_loader = torch.utils.data.DataLoader(val_dataset,batch_size=batch_size,shuffle=False,pin_memory=True,num_workers=nw,collate_fn=val_dataset.collate_fn)# 如果存在预训练权重则载入model = shufflenet_v2_x1_0(num_classes=args.num_classes).to(device)if args.weights != "":if os.path.exists(args.weights):weights_dict = torch.load(args.weights, map_location=device)load_weights_dict = {k: v for k, v in weights_dict.items()if model.state_dict()[k].numel() == v.numel()}print(model.load_state_dict(load_weights_dict, strict=False))else:raise FileNotFoundError("not found weights file: {}".format(args.weights))# 是否冻结权重if args.freeze_layers:for name, para in model.named_parameters():# 除最后的全连接层外,其他权重全部冻结if "fc" not in name:para.requires_grad_(False)pg = [p for p in model.parameters() if p.requires_grad]optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=4E-5)# Scheduler https://arxiv.org/pdf/1812.01187.pdflf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosinescheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)for epoch in range(args.epochs):# trainmean_loss = train_one_epoch(model=model,optimizer=optimizer,data_loader=train_loader,device=device,epoch=epoch)scheduler.step()# validateacc = evaluate(model=model,data_loader=val_loader,device=device)print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3)))tags = ["loss", "accuracy", "learning_rate"]tb_writer.add_scalar(tags[0], mean_loss, epoch)tb_writer.add_scalar(tags[1], acc, epoch)tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch)torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--num_classes', type=int, default=17)parser.add_argument('--epochs', type=int, default=100)parser.add_argument('--batch-size', type=int, default=4)parser.add_argument('--lr', type=float, default=0.01)parser.add_argument('--lrf', type=float, default=0.1)# 数据集所在根目录# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgzparser.add_argument('--data-path', type=str,default=r"G:\demo\data\monkeys\training")# shufflenetv2_x1.0 官方权重下载地址# https://download.pytorch.org/models/shufflenetv2_x1-5666bf0f80.pthparser.add_argument('--weights', type=str, default='./shufflenetv2_x1-5666bf0f80.pth',help='initial weights path')parser.add_argument('--freeze-layers', type=bool, default=False)parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')opt = parser.parse_args()main(opt)
第四步:统计正确率

第五步:搭建GUI界面


第六步:整个工程的内容
有训练代码和训练好的模型以及训练过程,提供数据,提供GUI界面代码

代码的下载路径(新窗口打开链接):基于Pytorch框架的深度学习ShufflenetV2神经网络十七种猴子动物识别分类系统源码

有问题可以私信或者留言,有问必答
相关文章:
基于Pytorch框架的深度学习ShufflenetV2神经网络十七种猴子动物识别分类系统源码
第一步:准备数据 17种猴子动物数据: self.class_indict ["白头卷尾猴", "弥猴", "山魈", "松鼠猴", "叶猴", "银色绒猴", "印度乌叶猴", "疣猴", "侏绒"…...

Leetcode260
260. 只出现一次的数字 III - 力扣(LeetCode) class Solution {public int[] singleNumber(int[] nums) {//通过异或操作,使得最终结果为两个只出现一次的元素的异或值int filterResult 0;for(int num:nums){filterResult^num;}//计算首个1(从右侧开始)…...

Webpack性能调优:从加载器到插件的全面优化
Webpack 是一个模块打包工具,它将项目中的各种资源(JavaScript、CSS、图片等)转换成一个或多个浏览器可识别的输出文件。优化 Webpack 的性能主要涉及减少构建时间、减小输出文件大小和提高应用加载速度。 2500G计算机入门到高级架构师开发资…...

cin-getline缓存区
更多资源请关注纽扣编程微信公众号 cin.sync()清除缓存区 如果需要输入如下内容 3 This is C language. This is JAVA language. This is Python language. 写如下程序 #include<bits/stdc.h> using namespace std; string str[100]; int main(){int n;cin>&…...
(附文档))
牛客前端面试高频八股总结(1)(附文档)
1.html语义化 要求使用具有语义的标签:header footer article aside section nav 三点好处: (1)提高代码可读性,页面内容结构化,更清晰 (2)无css时,时页面呈现出良好…...

韦专家:广告投放方式和内容运营底层方法论逻辑上有什么关系?
继续转推朋友这篇文章,标题稍有修改。广告投放跟内容运营逻辑是相似的,其实做SEO推广也是相似的。我们除了研究SEO流量,同样要真正理解广告投放的方式和内容运营底层方法论,这样会让你更好做好全网SEO营销! 最近陆陆续…...

003 ++ --
文章目录 --为了解决这个问题,你可以使用 synchronized 关键字来确保每次只有一个线程可以访问 increment() 方法:或者,你也可以使用 AtomicInteger,这是一个线程安全的整数类:乐观锁 – 在Java中, 和 –…...
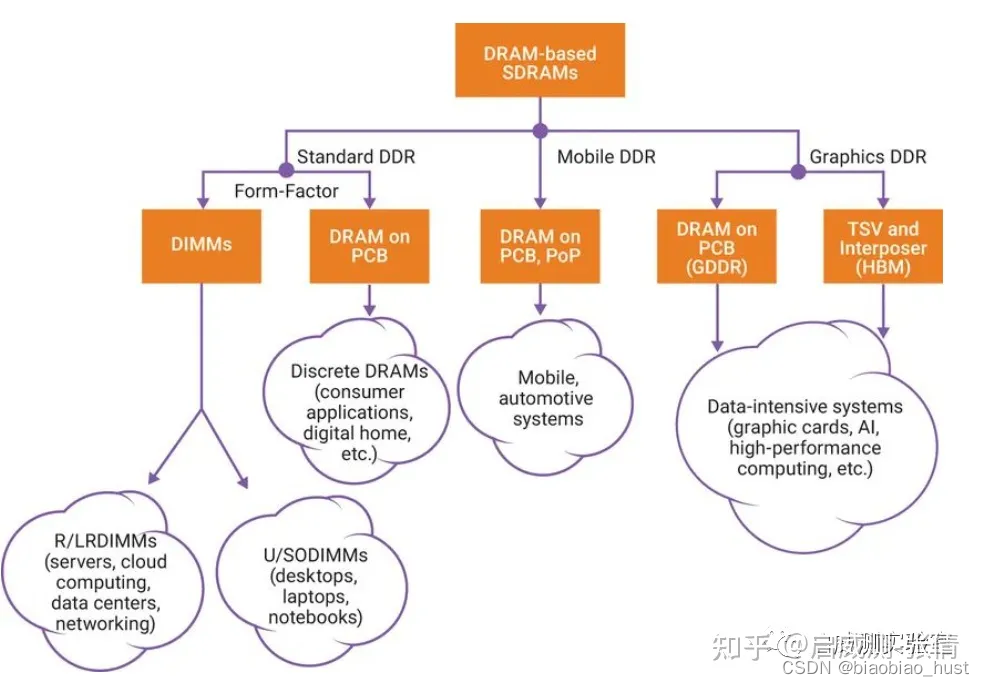
DDR、LPDDR和GDDR的区别
1、概况 以DDR开头的内存适用于服务器、云计算、网络、笔记本电脑、台式机和消费类应用,支持更宽的通道宽度、更高的密度和不同的形状尺寸。 以LPDDR开头的内存适合面向移动和汽车这些对规格和功耗非常敏感的领域,提供更窄的通道宽度和多种低功耗运行状态…...

【附代码】@hydra.main 没有返回值,如何解决函数返回?
hydra.main 是一个 Python 装饰器,通常与 Hydra 深度学习框架一起使用。它的作用是标识 Hydra 配置文件中的主函数。在 Hydra 中,主函数是一个负责组织整个程序执行流程的函数。这个装饰器告诉 Hydra 这个函数是主函数,但并不要求它有返回值。…...

js深入理解对象的 属性(properties)的特殊 特性(attributes)
对象 js对象 // 构造一个对象 let obj {}; let obj new Object(); 我们知道js中一切皆对象,对象是一个键值对集合(key: value),一个键(key)对应一个值(value),而每个键都是这个对象的属性,我们可以通过对象的属性来…...

【MATLAB】去除趋势项(解决频谱图大部分为零的问题)
1.概 述 在许多实际信号分析处理中信号经FFT变换后得到的频谱谱线值几乎都为0,介绍这是如何形成的,又该如何去解决。 2.案例分析 读入一组实验数据文件(文件名为qldata.mat),作出该组数据的频谱图。程序清单如下: clear; clc; close all;…...
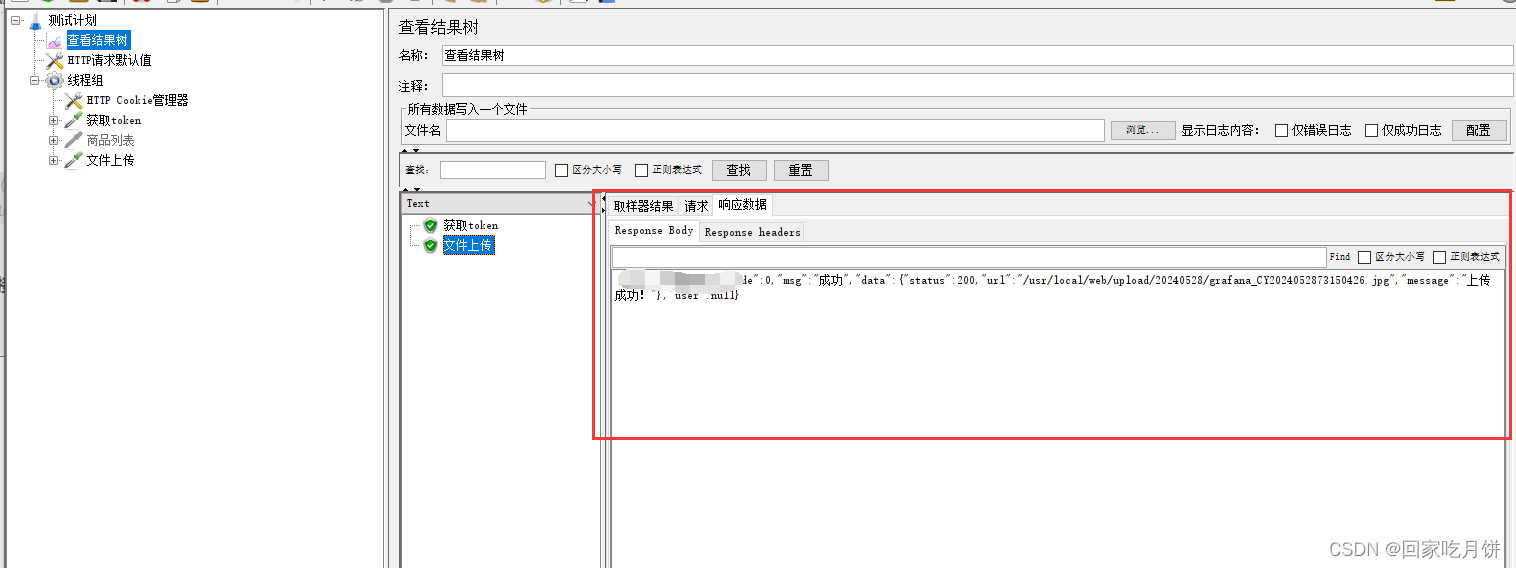
jmeter发送webserver请求和上传请求
有时候在项目中会遇到webserver接口和上传接口的请求,大致参考如下 一、发送webserver请求 先获取登录接口的token,再使用cookie管理器进行关联获取商品(webserver接口),注意参数一般是写在消息体数据中,消息体有点像HTML格式 执…...

如何看centos 有没有安装x11
在CentOS系统中,可以通过检查是否存在X11相关的包来判断是否安装了X11。你可以使用yum工具来查询是否安装了xorg-x11-server-Xorg包,这通常是X11服务器的包名。 打开终端,输入以下命令: yum list installed | grep xorg-x11-ser…...
超详细的前后端实战项目(Spring系列加上vue3)前后端篇(四)(一步步实现+源码)
兄弟们,继昨天的代码之后,继续完成最后的用户模块开发, 昨天已经完成了关于用户的信息编辑页面这些,今天再完善一下, 从后端这边开始吧,做一个拦截器,对用户做身份校验, 拦截器 这…...
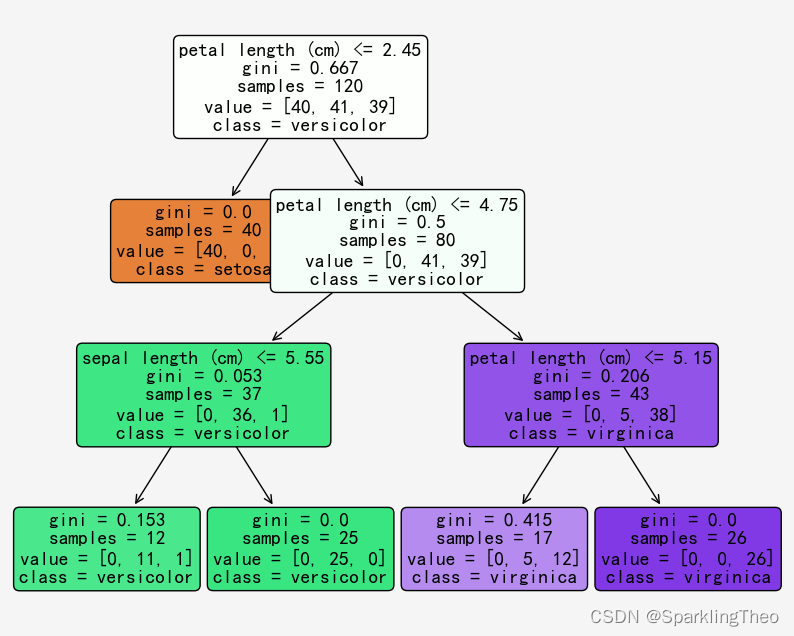
决策树|随机森林 GBDT XGBoost|集成学习
文章目录 1 决策树模型1.1 决策树模型简介1.2 决策树模型核心问题1.2.1 分类划分标准1.2.1.1 信息增益1.2.1.2 增益率1.2.1.3 基尼系数 1.2.2 停止生长策略1.2.3 剪枝策略 1.3 决策树 - python代码1.3.1 结果解读1.3.2 决策树可视化1.3.3 CV - 留一法 2 集成学习2.1 Boosting2.…...

【C语言实现TCP通信】
要在C语言中实现TCP通信,您可以遵循以下步骤: 创建Socket:使用socket()函数创建套接字,指定协议族为AF_INET(IPv4)或AF_INET6(IPv6),类型为SOCK_STREAM表示使用TCP协议。…...

黑马点评-短信登录
Override public Result sendCode(String phone) { // 1.检验手机号 if (RegexUtils.isPhoneInvalid(phone)) { // 这里抛出异常和return fail有什么区别吗?———> 有区别,抛出异常会被全局异常处理器捕获,返回fail不会 throw ne…...
CentOS7 部署单机版 elasticsearch
一、环境准备 1、准备一台系统为CentOS7的服务器 [rootlocalhost ~]# cat /etc/redhat-release CentOS Linux release 7.9.2009 (Core) 2、创建新用户,用于elasticsearch服务 # elastic不允许使用root账号启动服务 [rootlocalhost ~]# useradd elastic [rootlo…...
Mujoco仿真【xml文件的学习 4】
在学习Mujoco仿真的过程中,mujoco的版本要选择合适。先前我将mujoco的版本升级到了mujoco-3.1.4,在运行act的仿真代码时遇到了问题,撰写了博客: Aloha机械臂的mujoco仿真问题记录-CSDN博客 下面在进行mujoco仿真时,统…...
vue数据持久化仓库
本文章是一篇记录实用性vue数据持久化仓的使用! 首先在src中创建store文件夹,并创建一个根据本页面相关的名称, 在终端导入:npm i pinia 和 npm i pinia-plugin-persistedstate 接下来引入代码: import { defineSt…...

Linux服务器入侵排查:7类关键日志快速定位攻击链
1. 别急着重装系统——日志才是你手里的“监控录像”很多人服务器被黑后的第一反应是:赶紧重装系统、换密码、关端口。我见过太多人花两小时重装完,结果三天后又被打穿——因为攻击者留的后门根本没清干净,而你连对方是从哪个漏洞进来的都不知…...

GD32 MCU与RT-Thread OS融合实战:从芯片选型到物联网节点开发全解析
1. 项目概述:一次技术路演的深度复盘最近,我作为深度参与者,完整经历了兆易创新与RT-Thread联合举办的MCU技术路演活动。这不仅仅是一场简单的产品推介会,更像是一次面向广大嵌入式开发者、硬件工程师和产品经理的“技术公开课”。…...

Taotoken的模型广场如何辅助开发者进行技术选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken的模型广场如何辅助开发者进行技术选型 对于需要集成大模型能力的开发者而言,面对市场上众多的模型提供商、复…...

3个步骤实现浏览器中魔兽争霸与星际争霸模型渲染的完整指南
3个步骤实现浏览器中魔兽争霸与星际争霸模型渲染的完整指南 【免费下载链接】mdx-m3-viewer A WebGL viewer for MDX and M3 files used by the games Warcraft 3 and Starcraft 2 respectively. 项目地址: https://gitcode.com/gh_mirrors/md/mdx-m3-viewer 你是否曾因…...

歌词滚动姬:5分钟掌握专业级歌词制作的艺术
歌词滚动姬:5分钟掌握专业级歌词制作的艺术 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 歌词滚动姬(LRC Maker)是一款完全免费…...

RDP Wrapper终极指南:Windows家庭版开启多用户远程桌面的完整解决方案
RDP Wrapper终极指南:Windows家庭版开启多用户远程桌面的完整解决方案 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap RDP Wrapper Library是一款让Windows家庭版支持多用户远程桌面连接的革命性工具&a…...

Java解析支付宝PKCS#8私钥失败的根源与解决方案
1. 这不是密钥格式错了,是Java对PKCS#8私钥的“认知偏差”在作祟 你刚把支付宝开放平台下载的 .pem 私钥文件丢进 Java 项目,调用 AlipayClient.execute() 就立刻报错:“RSA2签名遭遇异常,请检查私钥格式是否正确”。第一反应…...

树莓派4B部署YOLOv8保姆级避坑指南:从PyTorch版本选择到模型推理全流程
树莓派4B部署YOLOv8实战手册:从版本适配到高效推理的深度解析 引言 在嵌入式设备上部署现代计算机视觉模型,就像给一辆微型赛车装上F1引擎——潜力巨大但挑战重重。最近帮朋友在树莓派4B上部署YOLOv8时,我们花了三天时间才走出"依赖地狱…...

瑞萨MCU集成AI加速器:嵌入式开发者的边缘智能实战指南
1. 项目概述:当传统MCU巨头按下AI加速键最近在半导体圈里,一个消息引发了不小的讨论:瑞萨电子,这家在微控制器领域常年稳坐头把交椅的巨头,宣布要全面拥抱人工智能。你可能对这个名字有点陌生,但你的车里、…...

spring boot 11
一、分组校验(Spring Validation)1. 核心概念分组校验是 Spring Validation 提供的功能,用于在不同业务场景(新增 / 更新)下,对同一个实体类执行不同的校验规则,避免重复定义实体类。2. 分组校验…...