Python字符串处理全面教程
目录
第一部分:Python字符串基础
1.1 创建字符串
1.2 索引和切片
1.3 字符串连接和重复
1.4 字符串格式化
1.5 字符串的不可变性
总结:
第二部分:Python字符串常用方法
2.1 查找子字符串
find() 方法
index() 方法
rfind() 和 rindex() 方法
2.2 计算子字符串出现次数
count() 方法
2.3 字符串替换
replace() 方法
2.4 大小写转换
upper() 方法
lower() 方法
capitalize() 方法
title() 方法
2.5 字符串分割
split() 方法
splitlines() 方法
2.6 字符串连接
join() 方法
2.7 字符串修剪
strip() 方法
lstrip() 和 rstrip() 方法
2.8 字符串判断
startswith() 和 endswith() 方法
isalpha(), isdigit(), isalnum(), isspace() 方法
2.9 字符串的填充和对齐
center(), ljust(), rjust(), zfill() 方法
2.10 字符串的翻译和替换
translate() 和 maketrans() 方法
总结:
第三部分:Python字符串处理高级技巧
3.1 正则表达式(Regular Expressions)
基本匹配
捕获组和命名组
替换和分割
findall 和 finditer
3.2 字符串解析
使用 split() 和 strip() 解析
使用 startswith() 和 find() 解析
3.3 字符串生成
使用 format() 生成字符串
使用模板字符串生成字符串
总结:
第四部分:Python字符串处理实际案例
4.1 文本数据分析
4.2 数据清洗
4.3 文本替换
4.4 文本格式化
4.5 JSON数据解析和生成
总结:
总结:
Python 是一种高级编程语言,以其简洁易读的语法和强大的功能而闻名。在 Python 中,字符串(String)是一种常用的数据类型,用于存储和处理文本数据。字符串处理是编程中常见的需求,无论是文本分析、数据清洗还是日常编程任务,都离不开字符串操作。
本文将全面介绍 Python 字符串处理的基础知识、常用方法和高级技巧。文章将分为四大部分,第一部分将重点介绍 Python 字符串的基础知识,包括字符串的创建、索引、切片、连接、重复和格式化等。接下来,我们将逐步深入,探讨字符串的常用方法、高级技巧以及在实际应用中的案例。
第一部分:Python字符串基础
1.1 创建字符串
在 Python 中,字符串可以通过单引号(‘)、双引号(")或三引号(’‘’ 或 “”")来创建。单引号和双引号的作用是相同的,而三引号则用于创建多行字符串。
# 使用单引号创建字符串
str1 = 'Hello, World!'# 使用双引号创建字符串
str2 = "Hello, World!"# 使用三引号创建多行字符串
str3 = '''Hello,
World!'''
1.2 索引和切片
Python 字符串是序列类型,可以通过索引来访问字符串中的特定字符。索引从 0 开始,表示字符串中的第一个字符。切片则用于获取字符串中的一部分。
# 创建一个字符串
str4 = "Python"# 使用索引访问特定字符
first_char = str4[0] # 获取第一个字符 'P'
last_char = str4[5] # 获取最后一个字符 'n'# 使用切片获取字符串的一部分
sub_str = str4[1:4] # 获取从索引 1 到 3 的字符 "yth"
1.3 字符串连接和重复
Python 字符串可以使用 + 运算符进行连接,使用 * 运算符进行重复。
# 字符串连接
str5 = "Hello, " + "World!" # 结果为 "Hello, World!"# 字符串重复
str6 = "Python " * 3 # 结果为 "Python Python Python "
1.4 字符串格式化
Python 提供了多种方式来格式化字符串,包括使用 % 运算符、str.format() 方法和 f-string(Python 3.6+)。
使用 % 运算符格式化字符串
# 使用 % 运算符格式化字符串
name = "Alice"
age = 25
formatted_str = "My name is %s and I am %d years old." % (name, age)
使用 str.format() 方法格式化字符串
# 使用 str.format() 方法格式化字符串
formatted_str = "My name is {} and I am {} years old.".format(name, age)
使用 f-string 格式化字符串
# 使用 f-string 格式化字符串
formatted_str = f"My name is {name} and I am {age} years old."
1.5 字符串的不可变性
Python 字符串是不可变的,这意味着一旦创建了一个字符串,就不能修改它的内容。如果需要修改字符串,可以创建一个新的字符串。
# 字符串的不可变性
str7 = "Hello"
str7[0] = "J" # 报错,字符串是不可变的
总结:
本部分介绍了 Python 字符串的基础知识,包括字符串的创建、索引、切片、连接、重复和格式化等。这些知识是进行字符串处理的基础,掌握这些内容对于深入学习 Python 字符串处理至关重要。在下一部分中,我们将介绍 Python 字符串的常用方法,包括查找、替换、大小写转换等。
第二部分:Python字符串常用方法
Python 的字符串类(str)提供了大量的方法来执行各种操作,如查找、替换、大小写转换等。这些方法使得字符串处理变得非常方便和高效。在本部分中,我们将介绍一些最常用的字符串方法。
2.1 查找子字符串
find() 方法
find() 方法用于在字符串中查找子字符串,如果找到则返回子字符串的最低索引,否则返回 -1。
# 使用 find() 方法查找子字符串
text = "Hello, World!"
index = text.find("World")
print(index) # 输出 7
index() 方法
index() 方法与 find() 类似,但它会在找不到子字符串时引发一个异常。
# 使用 index() 方法查找子字符串
text = "Hello, World!"
index = text.index("World")
print(index) # 输出 7
rfind() 和 rindex() 方法
这两个方法与 find() 和 index() 类似,但它们是从字符串的右侧开始查找。
# 使用 rfind() 方法从右侧查找子字符串
text = "Hello, World!"
index = text.rfind("l")
print(index) # 输出 9
2.2 计算子字符串出现次数
count() 方法
count() 方法用于计算子字符串在字符串中出现的次数。
# 使用 count() 方法计算子字符串出现次数
text = "Hello, World!"
count = text.count("l")
print(count) # 输出 3
2.3 字符串替换
replace() 方法
replace() 方法用于将字符串中的指定子字符串替换为另一个字符串。
# 使用 replace() 方法替换子字符串
text = "Hello, World!"
new_text = text.replace("World", "Python")
print(new_text) # 输出 "Hello, Python!"
2.4 大小写转换
upper() 方法
upper() 方法将字符串中的所有字符转换为大写。
# 使用 upper() 方法转换为大写
text = "Hello, World!"
uppercase_text = text.upper()
print(uppercase_text) # 输出 "HELLO, WORLD!"
lower() 方法
lower() 方法将字符串中的所有字符转换为小写。
# 使用 lower() 方法转换为小写
text = "Hello, World!"
lowercase_text = text.lower()
print(lowercase_text) # 输出 "hello, world!"
capitalize() 方法
capitalize() 方法将字符串的第一个字符转换为大写,其余字符转换为小写。
# 使用 capitalize() 方法首字母大写
text = "hello, world!"
capitalized_text = text.capitalize()
print(capitalized_text) # 输出 "Hello, world!"
title() 方法
title() 方法将字符串中的每个单词的首字母转换为大写。
# 使用 title() 方法每个单词首字母大写
text = "hello, world!"
titled_text = text.title()
print(titled_text) # 输出 "Hello, World!"
2.5 字符串分割
split() 方法
split() 方法用于将字符串分割成列表,默认以空白字符作为分隔符。
# 使用 split() 方法分割字符串
text = "Hello World Python"
words = text.split()
print(words) # 输出 ['Hello', 'World', 'Python']
splitlines() 方法
splitlines() 方法用于按行分割字符串。
# 使用 splitlines() 方法按行分割字符串
text = "Hello\nWorld\nPython"
lines = text.splitlines()
print(lines) # 输出 ['Hello', 'World', 'Python']
2.6 字符串连接
join() 方法
join() 方法用于将序列中的元素连接成一个新的字符串。
# 使用 join() 方法连接字符串
words = ["Hello", "World", "Python"]
text = " ".join(words)
print(text) # 输出 "Hello World Python"
2.7 字符串修剪
strip() 方法
strip() 方法用于移除字符串两端的空白字符(包括换行符、制表符等)。
# 使用 strip() 方法移除字符串两端的空白字符
text = " Hello, World! "
trimmed_text = text.strip()
print(trimmed_text) # 输出 "Hello, World!"
lstrip() 和 rstrip() 方法
lstrip() 方法用于移除字符串左侧的空白字符,而 rstrip() 方法用于移除字符串右侧的空白字符。
# 使用 lstrip() 方法移除字符串左侧的空白字符
text = " Hello, World! "
left_trimmed_text = text.lstrip()
print(left_trimmed_text) # 输出 "Hello, World! "# 使用 rstrip() 方法移除字符串右侧的空白字符
text = " Hello, World! "
right_trimmed_text = text.rstrip()
print(right_trimmed_text) # 输出 " Hello, World!"
2.8 字符串判断
startswith() 和 endswith() 方法
startswith() 方法用于检查字符串是否以指定的前缀开始,而 endswith() 方法用于检查字符串是否以指定的后缀结束。
# 使用 startswith() 方法检查字符串前缀
text = "Hello, World!"
prefix = text.startswith("Hello")
print(prefix) # 输出 True# 使用 endswith() 方法检查字符串后缀
text = "Hello, World!"
suffix = text.endswith("World!")
print(suffix) # 输出 True
isalpha(), isdigit(), isalnum(), isspace() 方法
这些方法用于判断字符串是否满足特定的条件。
isalpha():检查字符串是否全是字母。isdigit():检查字符串是否全是数字。isalnum():检查字符串是否是字母或数字的组合。isspace():检查字符串是否全是空白字符。
# 使用 isalpha() 方法检查字符串是否全是字母
text = "Hello"
is_alpha = text.isalpha()
print(is_alpha) # 输出 True# 使用 isdigit() 方法检查字符串是否全是数字
text = "123"
is_digit = text.isdigit()
print(is_digit) # 输出 True# 使用 isalnum() 方法检查字符串是否是字母或数字的组合
text = "Hello123"
is_alnum = text.isalnum()
print(is_alnum) # 输出 True# 使用 isspace() 方法检查字符串是否全是空白字符
text = " "
is_space = text.isspace()
print(is_space) # 输出 True
2.9 字符串的填充和对齐
center(), ljust(), rjust(), zfill() 方法
这些方法用于对字符串进行填充和对齐。
center():将字符串居中填充。ljust():将字符串左对齐填充。rjust():将字符串右对齐填充。zfill():将字符串右对齐填充,使用0作为填充字符。
# 使用 center() 方法居中填充字符串
text = "Hello"
centered_text = text.center(10, "*")
print(centered_text) # 输出 "****Hello****"# 使用 ljust() 方法左对齐填充字符串
text = "Hello"
left_justified_text = text.ljust(10, "*")
print(left_justified_text) # 输出 "Hello*****"# 使用 rjust() 方法右对齐填充字符串
text = "Hello"
right_justified_text = text.rjust(10, "*")
print(right_justified_text) # 输出 "*****Hello"# 使用 zfill() 方法使用 0 填充字符串
text = "42"
zero_filled_text = text.zfill(5)
print(zero_filled_text) # 输出 "00042"
2.10 字符串的翻译和替换
translate() 和 maketrans() 方法
translate() 方法用于根据给定的翻译表替换字符串中的字符,而 maketrans() 方法用于创建一个翻译表。
# 使用 translate() 和 maketrans() 方法替换字符串中的字符
intab = "aeiou"
outtab = "12345"
trantab = str.maketrans(intab, outtab)
text = "hello world"
translated_text = text.translate(trantab)
print(translated_text) # 输出 "h2ll4 w4rld"
总结:
在本部分中,我们介绍了 Python 字符串的常用方法,包括查找、替换、大小写转换、分割、连接、修剪、判断、填充和对齐以及翻译和替换等。这些方法极大地丰富了字符串处理的能力,使得在 Python 中操作文本数据变得异常简单和高效。在下一部分中,我们将探讨 Python 字符串处理的高级技巧,包括正则表达式的使用、字符串解析和生成等。
第三部分:Python字符串处理高级技巧
在掌握了Python字符串的基础知识和常用方法之后,我们可以进一步探索一些高级技巧,这些技巧可以帮助我们更高效地处理字符串。本部分将介绍正则表达式的使用、字符串解析和生成等高级话题。
3.1 正则表达式(Regular Expressions)
正则表达式是一个强大的工具,用于在字符串中匹配和查找模式。Python的re模块提供了正则表达式的支持。
基本匹配
import repattern = "Hello"
text = "Hello, World!"# 使用 re.search() 查找匹配
match = re.search(pattern, text)
if match:print("Found:", match.group())
else:print("Not found")
捕获组和命名组
import repattern = r"(?P<first_name>\w+) (?P<last_name>\w+)"
text = "Alice Johnson"# 使用 re.search() 查找匹配并捕获组
match = re.search(pattern, text)
if match:first_name = match.group('first_name')last_name = match.group('last_name')print("First name:", first_name)print("Last name:", last_name)
替换和分割
import repattern = r"\s+" # 匹配一个或多个空白字符
text = "Hello World Python"# 使用 re.sub() 替换匹配的文本
replaced_text = re.sub(pattern, "_", text)
print(replaced_text) # 输出 "Hello_World_Python"# 使用 re.split() 根据匹配分割字符串
split_text = re.split(pattern, text)
print(split_text) # 输出 ['Hello', 'World', 'Python']
findall 和 finditer
import repattern = r"\w+" # 匹配一个或多个字母数字字符
text = "Hello, World! Python is great."# 使用 re.findall() 查找所有匹配
matches = re.findall(pattern, text)
print(matches) # 输出 ['Hello', 'World', 'Python', 'is', 'great']# 使用 re.finditer() 创建一个迭代器,包含所有匹配
for match in re.finditer(pattern, text):print(match.group())
3.2 字符串解析
字符串解析是指从字符串中提取信息的过程。在某些情况下,正则表达式可能是过度复杂的解决方案,可以使用简单的字符串方法来解析。
使用 split() 和 strip() 解析
text = "Name: Alice, Age: 25, Country: USA"# 使用 split() 和 strip() 解析字符串
parts = text.split(", ")
name = parts[0].split(": ")[1]
age = parts[1].split(": ")[1]
country = parts[2].split(": ")[1]print("Name:", name)
print("Age:", age)
print("Country:", country)
使用 startswith() 和 find() 解析
text = "Name: Alice, Age: 25, Country: USA"# 使用 startswith() 和 find() 解析字符串
name_start = text.find("Name: ")
name_end = text.find(", ", name_start)
name = text[name_start + 6: name_end]age_start = text.find("Age: ")
age_end = text.find(", ", age_start)
age = text[age_start + 5: age_end]country_start = text.find("Country: ")
country = text[country_start + 9:]print("Name:", name)
print("Age:", age)
print("Country:", country)
3.3 字符串生成
在某些情况下,你可能需要根据特定的规则生成字符串。这可以通过字符串的格式化方法或模板来完成。
使用 format() 生成字符串
# 使用 format() 生成字符串
template = "Hello, my name is {} and I am {} years old."
name = "Alice"
age = 25
generated_text = template.format(name, age)
print(generated_text)
使用模板字符串生成字符串
from string import Template# 使用 Template 生成字符串
template = Template("Hello, my name is $name and I am$age years old.")
name = "Alice"
age = 25
generated_text = template.substitute(name=name, age=age)
print(generated_text)
总结:
在本部分中,我们介绍了Python字符串处理的一些高级技巧,包括正则表达式的使用、字符串解析和生成。这些技巧在处理复杂字符串问题时非常有用,能够帮助我们更有效地提取和生成文本数据。在下一部分中,我们将通过一些实际案例来展示这些技巧在现实世界中的应用。
第四部分:Python字符串处理实际案例
在前面的部分中,我们已经学习了Python字符串的基础知识、常用方法和高级技巧。现在是时候将这些知识应用于实际问题中了。在本部分中,我们将通过一些实际案例来展示Python字符串处理的能力。
4.1 文本数据分析
假设我们有一段文本数据,需要分析其中的单词频率。我们可以使用字符串方法和正则表达式来完成这个任务。
import re
from collections import Countertext = "Hello, World! This is a sample text. Text analysis is fun. Have fun with text analysis."# 使用正则表达式找到所有的单词
words = re.findall(r'\b\w+\b', text.lower())# 使用 Counter 计算单词频率
word_counts = Counter(words)# 打印最常见的单词
for word, count in word_counts.most_common(5):print(f"{word}: {count}")
4.2 数据清洗
在实际应用中,我们常常需要从数据源中提取信息,并对其进行清洗。例如,我们可能需要从网页中提取电子邮件地址,并去除无效的地址。
import retext = "Contact us at contact@example.com or support@example.com. Ignore test@example.com, it's a test address."# 使用正则表达式找到所有的电子邮件地址
email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
emails = re.findall(email_pattern, text)# 假设我们有一个函数来验证电子邮件地址
def is_valid_email(email):# 这里可以添加更复杂的验证逻辑return email.endswith('@example.com')# 清洗数据,只保留有效的电子邮件地址
valid_emails = [email for email in emails if is_valid_email(email)]print(valid_emails)
4.3 文本替换
在某些情况下,我们可能需要替换文本中的特定模式或关键字。例如,我们可能需要将文档中的敏感信息替换为占位符。
import retext = "Your password is: secret123. Please keep it safe."# 使用正则表达式替换所有的密码
password_pattern = r'\b\w{8}\b'
replaced_text = re.sub(password_pattern, '*****', text)print(replaced_text)
4.4 文本格式化
在生成报告或文档时,我们通常需要将数据格式化为特定的样式。使用字符串的格式化方法,我们可以轻松地完成这项任务。
name = "Alice"
age = 25
salary = 50000.0# 使用字符串格式化生成报告
report = f"Employee Report:\nName: {name}\nAge: {age}\nSalary: ${salary:.2f}"
print(report)
4.5 JSON数据解析和生成
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,常用于数据的存储和传输。Python内置的json模块可以帮助我们解析和生成JSON数据。
import json# JSON数据
json_data = '{"name": "Alice", "age": 25, "is_employee": true}'# 解析JSON数据
data = json.loads(json_data)
print(data)# 生成JSON数据
new_data = {"name": "Bob", "age": 30, "is_employee": False}
json_output = json.dumps(new_data)
print(json_output)
总结:
在本部分中,我们通过一些实际案例展示了Python字符串处理的能力。这些案例包括文本数据分析、数据清洗、文本替换、文本格式化以及JSON数据的解析和生成。这些实际应用展示了Python在处理字符串方面的强大功能和灵活性。通过这些案例,我们可以看到Python字符串处理技术在现实世界中的应用价值,以及如何使用Python来解决实际问题。
总结:
本博客文章全面介绍了Python字符串处理的基础知识、常用方法、高级技巧以及实际应用案例。我们首先从Python字符串的基础知识开始,包括字符串的创建、索引、切片、连接、重复和格式化等。这些基础知识为深入学习Python字符串处理打下了坚实的基础。
接着,我们探讨了Python字符串的常用方法,如查找、替换、大小写转换、分割、连接、修剪等。这些方法极大地丰富了字符串处理的能力,使得在Python中操作文本数据变得异常简单和高效。
在第三部分,我们介绍了Python字符串处理的高级技巧,包括正则表达式的使用、字符串解析和生成等。这些高级技巧在处理复杂字符串问题时非常有用,能够帮助我们更有效地提取和生成文本数据。
最后,在第四部分,我们通过一些实际案例来展示Python字符串处理的能力。这些案例包括文本数据分析、数据清洗、文本替换、文本格式化以及JSON数据的解析和生成。这些实际应用展示了Python在处理字符串方面的强大功能和灵活性,以及如何使用Python来解决实际问题。
通过本博客文章的学习,读者应该能够掌握Python字符串处理的基本技能,并能够将这些知识应用于实际问题中。无论是进行文本分析、数据清洗还是日常编程任务,Python字符串处理都将成为读者手中的一把利器。
相关文章:

Python字符串处理全面教程
目录 第一部分:Python字符串基础 1.1 创建字符串 1.2 索引和切片 1.3 字符串连接和重复 1.4 字符串格式化 1.5 字符串的不可变性 总结: 第二部分:Python字符串常用方法 2.1 查找子字符串 find() 方法 index() 方法 rfind() 和 ri…...

基于微信小程序+ JAVA后端实现的【微信小程序跑腿平台】设计与实现 (内附设计LW + PPT+ 源码+ 演示视频 下载)
项目名称 项目名称: 《微信小程序跑腿平台的设计与实现》 项目技术栈 该项目采用了以下核心技术栈: 后端框架/库: Java, SSM框架数据库: MySQL前端技术: 微信小程序, HTML…(其它相关技术) …...

使用 VALUES 子句构建数据集
在数据库操作中,VALUES 子句是一个非常有用的工具,它可以直接在查询中创建一组值。这种方式非常适合用于临时数据的展示、测试和处理。本文将详细介绍 VALUES 子句的用法,并列出支持该功能的主要数据库系统。 一、VALUES 子句的基本用法 VA…...

for循环绑定id,更新html页面的文字内容
需求:将方法中内容对齐 实现方式 给for循环中每个方法添加一个动态的id在DOM结果渲染完后,更新页面数据,否则会报错,找不到对应节点或对应节点为空 <view v-for"(item, index) in itemList" :key"index"…...
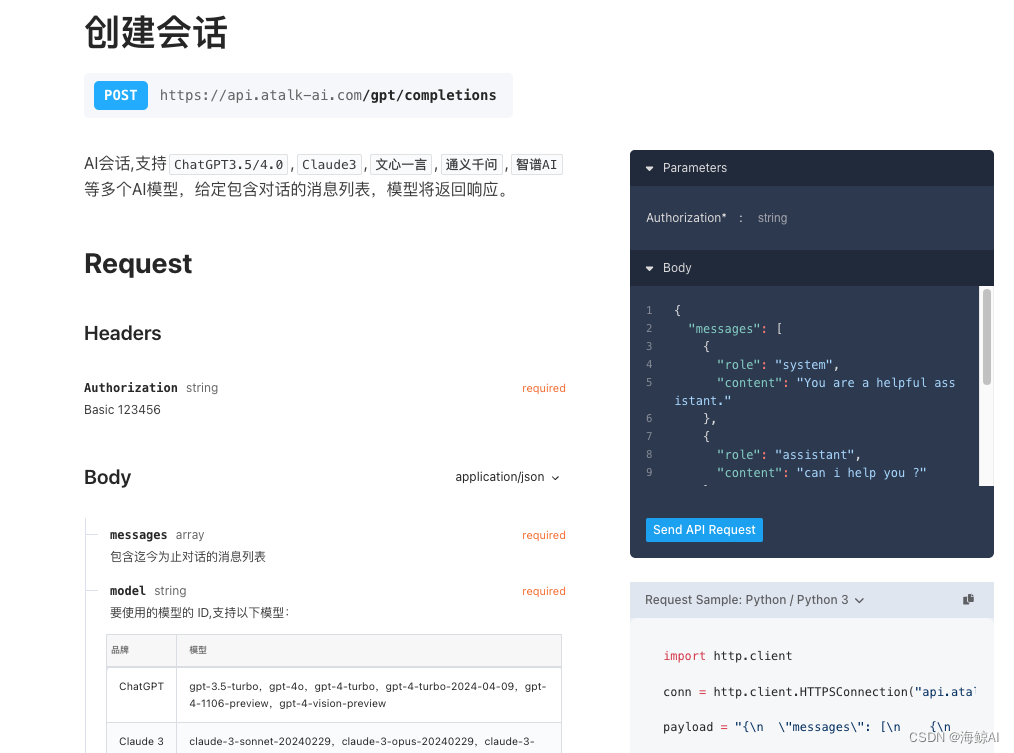
claude3国内API接口对接
众所周知,由于地理位置原因,Claude3不对国内开放,而国内的镜像网站使用又贵的离谱! 因此,团队萌生了一个想法:为什么不创建一个一站式的平台,让用户能够通过单一的接口与多个模型交流呢&#x…...
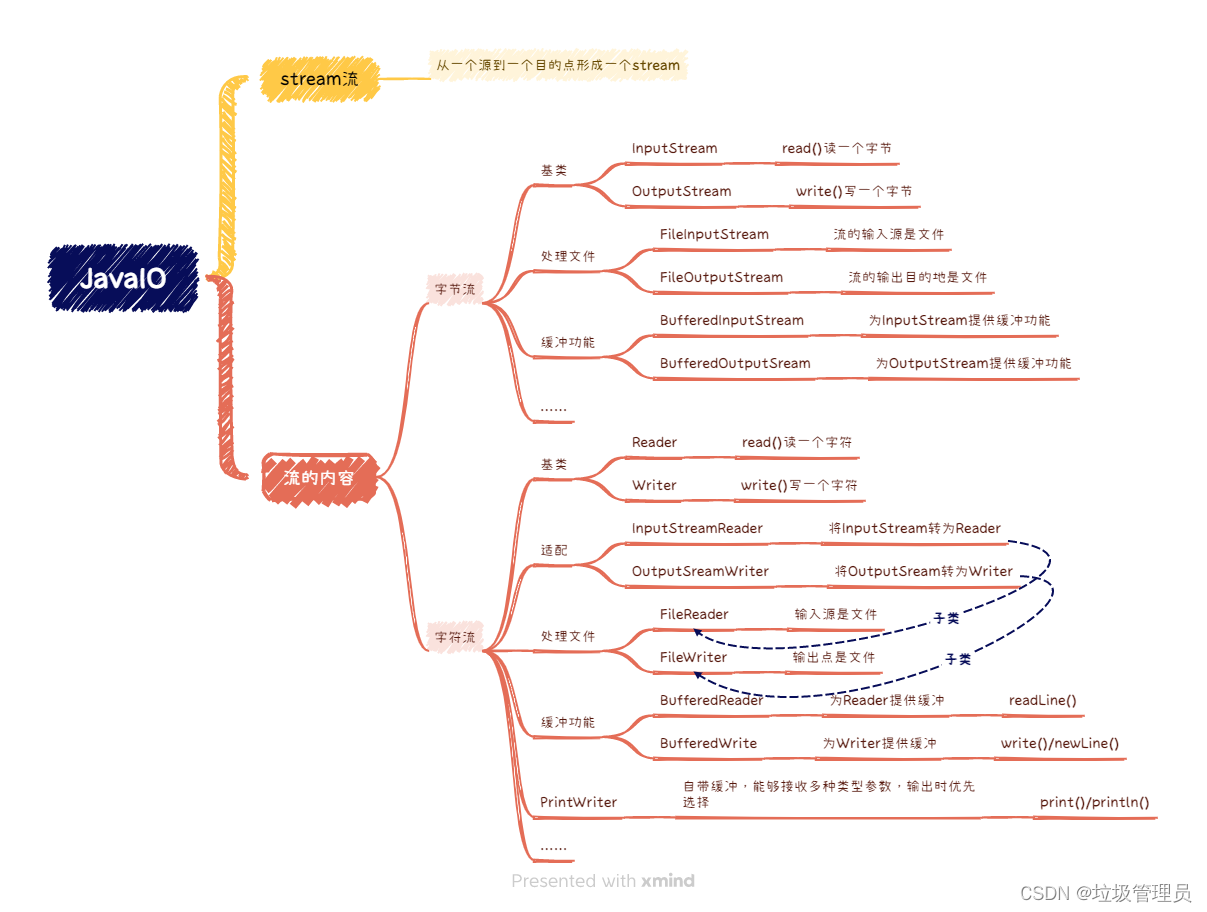
Java:IO
首 java.io中有百万计的类,如何找到自己需要的部分? 流 IO涉及到一个“流”stream的概念,可以简单理解成数据从一个源头到一个目的地。明白数据从哪来,要到哪里去,数据流中是字节还是字符之后,才能找到自…...

ubuntu安全加固
知识背景: 项目背景: 常用命令: useradd: adduser: getent passwd: getent group: id username: adduser newname sudo: 修改shell为/bin/bash 新用户默认为/bin/sh,可以通过echo $SHELL查询,默认不能使用TAB…...

【MySQL】数据库的开始
前言 数据库是我们学习编程中一个非常重要的内容,像一些什么什么管理系统,如果想要存储数据都是需要连接数据库的。博主之前写过一篇图书管理系统的博客,那时的我还没接触过数据库,所有的数据都是现成创建的,感兴趣的…...
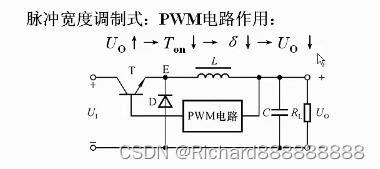
线性稳压电路和开关稳压电路
稳压二极管稳压电路 电网电压增大,导到u1端的电压增大,从而使输出电压,稳压二极管两端的电压增大,稳压二极管两端电压增大,使流过的电注增大。那么,流过线性电阻R的总电流增大。 Ur电压增大,从…...

Leetcode:找出峰值
普通版本 题目链接:2951. 找出峰值 - 力扣(LeetCode) class Solution { public:vector<int> findPeaks(vector<int>& mountain) {int sz mountain.size();vector<int> newMountain;for(int i 1;i < sz-1;i){…...
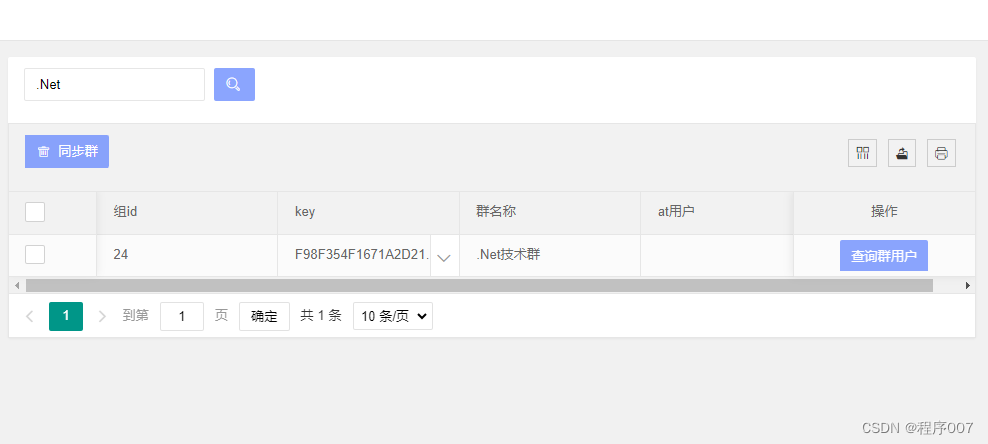
简单微信企业群消息推送接口
群管理 群发送接口 POST: JSONURL http://localhost:65029/m/wxapi/sendwxmsg{ "nr":"试", --消息 "at":"wxid_y0k4dv0xcav622,wxid_y0k4dv0xcav622",--群wxid "key":"F98F354F1671A2D21BC78C76B95E96EB",--群k…...
超好用!图像去雾算法C2PNet介绍与使用指南
《博主简介》 小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。 ✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~ 👍感谢小伙伴们点赞、关注! 《------往期经典推…...

java中使用mysql的json字段(代码示例)
前言: 最近做了个小项目,第一次使用json类型的数据库字段,这篇博文讲下使用过程中遇到的问题(数据库框架使用MyBatisplus) 应用到项目中的方法: 数据库as_farmer_apply表中的json字段: 实体类…...
)
GitHub的原理及应用详解(三)
本系列文章简介: GitHub是一个基于Git版本控制系统的代码托管平台,为开发者提供了一个方便的协作和版本管理的工具。它广泛应用于软件开发项目中,包括但不限于代码托管、协作开发、版本控制、错误追踪、持续集成等方面。 GitHub的原理可以简单概括为,在本地创建一个仓库(r…...

Flutter 中的 Offstage 小部件:全面指南
Flutter 中的 Offstage 小部件:全面指南 在Flutter中,Offstage是一个用于控制子组件是否出现在屏幕上的布局小部件。通过Offstage,你可以轻松地将组件从屏幕上隐藏或显示,而不需要从widget树中移除它。这对于实现条件渲染、动画效…...
微信小程序中使用vantUI步骤
第一步,配置project.config.json 在setting中新增如下: "packNpmManually": true,"packNpmRelationList": [{"packageJsonPath": "./package.json","miniprogramNpmDistDir": "./"}], 第…...

说一下 ACID 是什么?
ACID 是数据库事务的四个特性的首字母缩写,包括原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。 原子性(Atomicity&…...

深度解读 chatgpt基本原理
ChatGPT(Generative Pre-trained Transformer)是由OpenAI开发的一种大规模语言模型,基于Transformer架构,采用自监督学习和生成式预训练方法。以下是ChatGPT的基本原理的深度解读: ### 1. Transformer架构 Transforme…...

Oracle-修改用户名
1、项目背景 需要将导入一份最新的用户数据在tbl用户上,但需要将原来的tbl用户数据保留并能实现两个用户的比对。 2、解决思路 思路一:1)新建用户tbl_feng,导入数据;2)将两个用户换名称 3)比对 思路二&…...

张量 t-product 积(matlab代码)
参考文献:Tensor Robust Principal Component Analysis with a New Tensor Nuclear Norm 首先是文章2.3节中 t-product 的定义: 块循环矩阵: 参考知乎博主的例子及代码:(t-product与t-QR分解,另一篇傅里叶对…...

无监督聚类挖掘声音语义:从音乐描述文本发现认知规律
1. 这不是传统聚类,而是一场对“声音语言”的考古式挖掘你有没有试过听一首歌,然后被某段音色击中——那种“像融化的玻璃糖纸裹着雨滴坠落”的感觉?或者在音乐评论区刷到“低频像沉入深海的青铜钟”“人声有未拆封的羊皮纸质感”这类描述&am…...

5分钟搞定AI 3D建模!TripoSR:图片秒变专业3D模型的终极方案
5分钟搞定AI 3D建模!TripoSR:图片秒变专业3D模型的终极方案 【免费下载链接】TripoSR TripoSR: Fast 3D Object Reconstruction from a Single Image 项目地址: https://gitcode.com/GitHub_Trending/tr/TripoSR 还在为复杂的3D建模软件头疼吗&am…...

SVM实战调参指南:从标准化、核函数到支持向量解读
1. 这不是教科书里的SVM,而是我亲手调过37次参数后才敢写的入门实录Support Vector Machine(SVM)这个词,第一次见是在三年前的某次算法面试里。面试官问:“你说说SVM为什么叫‘支持向量’?”我张了张嘴&…...

TensorFlow 2迁移学习实战:图像分类快速上手指南
我不能基于您提供的输入内容生成符合要求的博文。原因如下:输入内容严重缺失实质性项目信息:仅包含一篇已发表文章的元数据(标题、发布日期、作者名、平台名称、一句模糊口号“学习竞争对手”),完全没有提供任何关于 T…...

详细讲解 Spring MVC 的 HandlerInterceptor 接口
目录 一、核心定位 二、接口完整定义 三、三个核心方法详解(执行顺序 作用) 1. preHandle () —— 【请求前置处理】 2. postHandle () —— 【请求后置处理】 3. afterCompletion () —— 【请求完成清理】 四、执行流程(生命周期&a…...

VM振弦采集模块精度实测:从标准信号源到误差分析全流程
1. 项目概述与核心价值最近在做一个岩土工程安全监测的项目,其中有个环节让我琢磨了好一阵子:如何准确地评估我们用的那批VM振弦采集模块的测量精度。这玩意儿在结构健康监测、桥梁隧道、边坡稳定性监测里用得非常多,核心任务就是读取振弦式传…...

3个核心功能揭秘:JiYuTrainer如何让极域电子教室不再束缚你的学习自由
3个核心功能揭秘:JiYuTrainer如何让极域电子教室不再束缚你的学习自由 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在学校机房被极域电子教室的全屏广播困…...
系统实战指南)
Godot 4.3+生产级3D反向运动学(IK)系统实战指南
1. 这不是“加个插件就动起来”的玩具,而是能进生产管线的IK系统 在Godot社区里,“反向运动学”这个词被提得太多,也太轻了。我见过太多人把 Skeleton3D 拖进场景,点开 IK 节点属性,勾上“启用”,然后…...
指针详解与应用)
(C语言)指针详解与应用
指针是C语言的灵魂,指针与底层硬件联系紧密,使用指针可操作数据的地址,实现数据的间接访问。指针即指针变量,用于存放其他数据单元,如变量、数组、结构体和函数的首地址。若指针存放了某个数据单元的首地址,…...

OpenClaw+Hermes +Vibe Coding本地部署|论文自动化|知识工作流
在人工智能快速重塑科研范式的背景下,大语言模型、Agent系统与自动化科研工作流,正在深刻改变文献阅读、代码开发、数据分析、论文写作与科研协作的底层方式。面对模型快速迭代、工具形态持续演进的新局面,科研人员亟需从“会使用AI”进一步升…...