SQLite查询优化
文章目录
- 1. 引言
- 2. WHERE子句分析
- 2.1. 索引项使用示例
- 3. BETWEEN优化
- 4. OR优化
- 4.1. 将OR连接的约束转换为IN运算符
- 4.2. 分别评估OR约束并取结果的并集
- 5. LIKE优化
- 6. 跳跃扫描优化
- 7. 连接
- 7.1. 手动控制连接顺序
- 7.1.1. 使用 SQLITE_STAT 表手动控制查询计划
- 7.1.2. 使用 CROSS JOIN 手动控制查询计划
- 8. 在多个索引之间进行选择
- 8.1. 使用一元 "+" 取消 WHERE 子句条件
- 8.2. 范围查询
- 9. 覆盖索引
- 10. ORDER BY 优化
- 10.1. 通过索引部分 ORDER BY
- 11. 子查询展平
- 12. 子查询协同程序
- 12.1. 在排序后使用协同程序延迟工作
- 13. MIN/MAX 优化
- 14. 自动查询时索引
- 14.1. 哈希连接
- 15. WHERE 子句下推优化
- 16. OUTER JOIN 强度减小优化
- 17. 省略 OUTER JOIN 优化
- 18. 常量传播优化
1. 引言
给定一个SQL语句,可能有数十种、数百种,甚至数千种方法来实现该语句,这取决于语句本身的复杂性和底层数据库模式的复杂性。查询计划的任务是选择最小化磁盘I/O和CPU开销的算法。
2. WHERE子句分析
在分析之前,进行以下转换,将所有的连接约束转移到WHERE子句中:
- 所有的NATURAL连接被转换为带有USING子句的连接。
- 所有的USING子句(包括上一步创建的)被转换为等效的ON子句。
- 所有的ON子句(包括上一步创建的)作为新的连接词(AND连接的项)添加到WHERE子句中。
SQLite不区分出现在WHERE子句中的连接约束和内连接的ON子句中的约束,因为这种区别不会影响结果。然而,外连接的ON子句约束和WHERE子句约束是有区别的。因此,当SQLite将一个外连接的ON子句约束移动到WHERE子句时,它会在抽象语法树(AST)中添加特殊的标签,以指示约束来自外连接,并且来自哪个外连接。在纯SQL文本中无法添加这些标签。因此,SQL输入必须在外连接上使用ON子句。但在内部AST中,所有的约束都是WHERE子句的一部分,因为将所有的内容放在一个地方可以简化处理。
在所有的约束都转移到WHERE子句之后,WHERE子句被分解为连接词(以下称为"项")。换句话说,WHERE子句被分解为由AND运算符分隔的片段。如果WHERE子句由OR运算符(析取式)分隔的约束组成,则整个子句被视为一个"项",对其应用OR子句优化。
分析WHERE子句的所有项,看看它们是否可以使用索引来满足。要被索引使用,项通常必须是以下形式之一:
column = expressioncolumn IS expressioncolumn > expressioncolumn >= expressioncolumn < expressioncolumn <= expressionexpression = columnexpression IS columnexpression > columnexpression >= columnexpression < columnexpression <= columncolumn IN (expression-list)column IN (subquery)column IS NULLcolumn LIKE patterncolumn GLOB pattern
如果使用像这样的语句创建索引:
CREATE INDEX idx_ex1 ON ex1(a,b,c,d,e,...,y,z);
那么如果索引的初始列(a、b等列)出现在WHERE子句项中,那么可能会使用该索引。索引的初始列必须使用=或IN或IS操作符。使用的最右边的列可以使用不等式。对于使用的索引的最右边的列,可以有多达两个不等式,这些不等式必须将列的允许值夹在两个极端之间。
并非索引的每一列都必须出现在WHERE子句项中,才能使用该索引。然而,使用的索引列之间不能有间隙。因此,对于上面的示例索引,如果没有WHERE子句项约束列c,那么约束列a和b的项可以使用索引,但不能使用约束列d到z的项。同样,索引列通常不会被使用(用于索引目的),如果它们在仅受不等式约束的列的右边。(请参阅下面的跳过扫描优化以获取例外。)
在表达式上的索引的情况下,无论上述文本中何时使用“列”这个词,都可以替换为“索引表达式”(意思是出现在CREATE INDEX语句中的表达式的副本),一切都会按照相同的方式运行。
2.1. 索引项使用示例
对于上面的索引和类似这样的WHERE子句:
... WHERE a=5 AND b IN (1,2,3) AND c IS NULL AND d='hello'
索引的前四列a、b、c和d将是可用的,因为这四列形成了索引的前缀,并且都被等式约束。
对于上面的索引和类似这样的WHERE子句:
... WHERE a=5 AND b IN (1,2,3) AND c>12 AND d='hello'
只有索引的a、b和c列将是可用的。d列将不可用,因为它出现在c的右边,而c只受不等式约束。
对于上面的索引和类似这样的WHERE子句:
... WHERE a=5 AND b IN (1,2,3) AND d='hello'
只有索引的a和b列将是可用的。d列将不可用,因为列c没有受到约束,索引可用的列集合中不能有空隙。
对于上面的索引和类似这样的WHERE子句:
... WHERE b IN (1,2,3) AND c NOT NULL AND d='hello'
索引完全不可用,因为索引的最左边的列(列"a")没有受到约束。假设没有其他索引,上述查询将导致全表扫描。
对于上面的索引和类似这样的WHERE子句:
... WHERE a=5 OR b IN (1,2,3) OR c NOT NULL OR d='hello'
索引不可用,因为WHERE子句的项由OR而不是AND连接。这个查询将导致全表扫描。然而,如果添加了三个额外的索引,这些索引包含了列b、c和d作为它们的最左边的列,那么可能会应用OR子句优化。
3. BETWEEN优化
如果WHERE子句的一个项是以下形式:
expr1 BETWEEN expr2 AND expr3
那么将添加两个"虚拟"项,如下所示:
expr1 >= expr2 AND expr1 <= expr3
虚拟项仅用于分析,不会生成任何字节码。如果两个虚拟项最终都被用作索引的约束,那么原始的BETWEEN项将被省略,对输入行不进行相应的测试。因此,如果BETWEEN项最终被用作索引约束,那么对该项的测试永远不会被执行。另一方面,虚拟项本身永远不会导致对输入行的测试。因此,如果BETWEEN项没有被用作索引约束,而必须用来测试输入行,那么expr1表达式只会被评估一次。
4. OR优化
由OR而不是AND连接的WHERE子句约束可以用两种不同的方式处理。
4.1. 将OR连接的约束转换为IN运算符
如果一个项由多个包含公共列名的子项组成,并由OR分隔,如下所示:
column = expr1 OR column = expr2 OR column = expr3 OR ...
那么该项将被重写为以下形式:
column IN (expr1,expr2,expr3,...)
然后重写的项可能会按照IN运算符的正常规则约束索引。请注意,列必须在每个OR连接的子项中都是相同的列,尽管列可以出现在=运算符的左边或右边。
4.2. 分别评估OR约束并取结果的并集
如果且仅当先前描述的将OR转换为IN运算符的方法不起作用时,将尝试第二个OR子句优化。假设OR子句由多个子项组成,如下所示:
expr1 OR expr2 OR expr3
单个子项可以是单个比较表达式,如a=5或x>y,也可以是LIKE或BETWEEN表达式,或者子项可以是带括号的由AND连接的子子项列表。每个子项都被分析,就像它本身是整个WHERE子句一样,以查看该子项是否可以单独进行索引。如果OR子句的每个子项都可以单独进行索引,那么可能会对OR子句进行编码,以便对OR子句的每个项使用单独的索引。可以这样想象SQLite如何为每个OR子句项使用单独的索引:想象一下,WHERE子句被重写为以下形式:
rowid IN (SELECT rowid FROM table WHERE expr1UNION SELECT rowid FROM table WHERE expr2UNION SELECT rowid FROM table WHERE expr3)
上面的重写表达式是概念性的;包含OR的WHERE子句实际上并没有以这种方式重写。实际上,OR子句的实现使用了一种更高效的机制,即使对于WITHOUT ROWID表或"rowid"不可访问的表也可以工作。然而,通过上述语句可以捕捉到实现的本质:对于每个OR子句项,使用单独的索引查找候选结果行,最终结果是这些行的并集。
请注意,在大多数情况下,SQLite只会为查询的FROM子句中的每个表使用一个索引。这里描述的第二个OR子句优化是该规则的例外。对于OR子句,每个子项可能使用不同的索引。
对于任何给定的查询,这里描述的OR子句优化可以使用的事实并不保证它会被使用。SQLite使用基于成本的查询计划器,估计各种竞争查询计划的CPU和磁盘I/O成本,并选择它认为最快的计划。如果WHERE子句中有许多OR项,或者如果某些OR子句子项上的索引不是很有选择性,那么SQLite可能会决定使用不同的查询算法,甚至全表扫描。应用程序开发人员可以在语句前面使用EXPLAIN QUERY PLAN前缀,以获取所选查询策略的高级概述。
5. LIKE优化
使用LIKE或GLOB运算符的WHERE子句项有时可以与索引一起使用,以进行范围搜索,就像LIKE或GLOB是BETWEEN运算符的替代品一样。这种优化有许多条件:
- LIKE或GLOB的右侧必须是一个字符串字面量,或者一个绑定到不以通配符字符开头的字符串字面量的参数。
- 不能通过在LIKE或GLOB运算符的左侧有一个数值(而不是字符串或blob)使LIKE或GLOB运算符为真。这意味着:
- LIKE或GLOB运算符的左侧是具有TEXT亲和性的索引列的名称,或者
- 右侧的模式参数不以负号(“-”)或数字开头。
这个约束源于数字不按字典顺序排序的事实。例如:9<10但’9’>‘10’。
- 不能使用sqlite3_create_function() API来重载实现LIKE和GLOB的内置函数。
- 对于GLOB运算符,列必须使用内置的BINARY排序序列进行索引。
- 对于LIKE运算符,如果启用了case_sensitive_like模式,则列必须使用BINARY排序序列进行索引,如果禁用了case_sensitive_like模式,则列必须使用内置的NOCASE排序序列进行索引。
- 如果使用了ESCAPE选项,则ESCAPE字符必须是ASCII,或者在UTF-8中是单字节字符。
LIKE运算符有两种模式,可以通过pragma设置。默认模式是让LIKE比较对于拉丁1字符的大小写不敏感。因此,默认情况下,以下表达式为真:
'a' LIKE 'A'
如果启用了case_sensitive_like pragma,如下所示:
PRAGMA case_sensitive_like=ON;
那么LIKE运算符将注意大小写,上面的示例将被评估为假。注意,大小写不敏感只适用于拉丁1字符 - 基本上是ASCII的低127字节代码中的英文大写和小写字母。SQLite中的国际字符集是大小写敏感的,除非提供了考虑非ASCII字符的应用程序定义的排序序列和like() SQL函数。如果提供了应用程序定义的排序序列和/或like() SQL函数,那么这里描述的LIKE优化将永远不会被采用。
LIKE运算符默认是大小写不敏感的,因为这是SQL标准要求的。你可以在编译时使用SQLITE_CASE_SENSITIVE_LIKE命令行选项更改默认行为。
LIKE优化可能会发生,如果运算符左边的列名使用内置的BINARY排序序列进行索引,并且case_sensitive_like已经打开。或者优化可能会发生,如果列使用内置的NOCASE排序序列进行索引,并且case_sensitive_like模式关闭。这些是LIKE运算符将被优化的唯一两种组合。
GLOB运算符总是区分大小写。GLOB运算符左边的列必须始终使用内置的BINARY排序序列,否则不会尝试使用索引优化该运算符。
只有当GLOB或LIKE运算符的右侧是字面字符串或绑定到字面字符串的参数时,才会尝试LIKE优化。字符串字面量不能以通配符开头;如果右侧以通配符字符开头,则不会尝试此优化。如果右侧是绑定到字符串的参数,那么只有在包含表达式的预编译语句使用sqlite3_prepare_v2()或sqlite3_prepare16_v2()编译时,才会尝试此优化。如果右侧是参数,并且语句使用sqlite3_prepare()或sqlite3_prepare16()准备,则不会尝试LIKE优化。
假设LIKE或GLOB运算符的右侧的非通配符字符的初始序列是x。我们使用单个字符来表示这个非通配符前缀,但读者应该理解,前缀可以由多于1个字符组成。让y是与/x/长度相同但比x大的最小字符串。例如,如果x是’hello’,那么y将是’hellp’。然后,LIKE或GLOB优化将运算符重写为以下形式:
column >= x AND column < y
然后,优化器将尝试使用索引来满足这两个新的虚拟约束。如果成功,那么将使用索引来满足LIKE或GLOB运算符。如果失败,那么将回退到全表扫描。在任何情况下,都将使用LIKE或GLOB运算符对所有候选行进行测试,以确保它们符合LIKE或GLOB模式。这是因为索引只能用于确定前缀匹配。索引不能用于处理LIKE或GLOB模式中可能出现的通配符。
6. 跳跃扫描优化
一般规则是,索引只有在 WHERE 子句约束了索引的最左侧列时才有用。然而,在某些情况下,即使索引的前几列被 WHERE 子句省略,但后面的列被包含,SQLite 也能够使用索引。
考虑如下表:
CREATE TABLE people(name TEXT PRIMARY KEY,role TEXT NOT NULL,height INT NOT NULL, -- in cmCHECK( role IN ('student','teacher') )
);
CREATE INDEX people_idx1 ON people(role, height);
people 表包含了一个大型组织中的每个人的条目。每个人要么是 “student”,要么是 “teacher”,由 “role” 字段确定。该表还记录了每个人的身高(以厘米为单位)。角色和身高都被索引。注意,索引的最左侧列的选择性不高 - 它只包含两个可能的值。
现在考虑一个查询,找出组织中身高为180cm或更高的每个人的名字:
SELECT name FROM people WHERE height>=180;
因为索引的最左侧列没有出现在查询的 WHERE 子句中,人们可能会得出索引在这里无法使用的结论。然而,SQLite 能够使用索引。从概念上讲,SQLite 使用索引就像查询更像下面的形式:
SELECT name FROM peopleWHERE role IN (SELECT DISTINCT role FROM people)AND height>=180;
或者这样:
SELECT name FROM people WHERE role='teacher' AND height>=180
UNION ALL
SELECT name FROM people WHERE role='student' AND height>=180;
上面显示的替代查询公式只是概念性的。SQLite 并没有真正改变查询。实际的查询计划是这样的:SQLite 定位到 “role” 的第一个可能值,它可以通过将 “people_idx1” 索引倒回到开始并读取第一条记录来做到这一点。SQLite 将这个第一个 “role” 值存储在一个我们在这里称为 “ r o l e " 的内部变量中。然后 S Q L i t e 运行一个类似于 " S E L E C T n a m e F R O M p e o p l e W H E R E r o l e = role" 的内部变量中。然后 SQLite 运行一个类似于 "SELECT name FROM people WHERE role= role"的内部变量中。然后SQLite运行一个类似于"SELECTnameFROMpeopleWHERErole=role AND height>=180” 的查询。这个查询在索引的最左侧列上有一个相等约束,所以索引可以用来解决这个查询。一旦这个查询完成,SQLite 然后使用 “people_idx1” 索引来定位 “role” 列的下一个值,使用的代码在逻辑上类似于 “SELECT role FROM people WHERE role>$role LIMIT 1”。这个新的 “role” 值覆盖了 $role 变量,这个过程重复,直到检查了所有可能的 “role” 值。
我们称这种索引使用方式为 “跳跃扫描”,因为数据库引擎基本上是在对索引进行全扫描,但是通过偶尔跳跃到下一个候选值来优化扫描(使其少于 “全”)。
SQLite 可能会在索引上使用跳跃扫描,如果它知道第一列或更多列包含许多重复值。如果在索引的最左侧列中有太少的重复项,那么简单地向前走到下一个值,从而进行全表扫描,会比在索引上进行二分搜索来定位下一个左列值更快。
SQLite 只有在对数据库运行 ANALYZE 命令后才能知道索引的最左侧列中有许多重复项。没有 ANALYZE 的结果,SQLite 不得不猜测表中数据的 “形状”,默认猜测是在索引的最左侧列中每个值有平均10个重复项。当重复项的数量大约为18个或更多时,跳跃扫描才变得有利可图(它只是比全表扫描更快)。因此,在没有分析过的数据库上,永远不会使用跳跃扫描。
7. 连接
SQLite 通过嵌套循环实现连接。在连接的嵌套循环的默认顺序中,FROM 子句中最左侧的表形成外循环,最右侧的表形成内循环。然而,如果这样做有助于选择更好的索引,SQLite 将以不同的顺序嵌套循环。
内连接可以自由重新排序。然而,外连接既不可交换也不可关联,因此不会被重新排序。如果优化器认为这样做是有利的,那么外连接左侧和右侧的内连接可能会被重新排序,但外连接总是按照它们出现的顺序进行评估。
SQLite 对 CROSS JOIN 运算符进行特殊处理。从理论上讲,CROSS JOIN 运算符是可交换的。然而,SQLite 选择永远不重新排序 CROSS JOIN 中的表。这提供了一种通过编程方式强制 SQLite 选择特定循环嵌套顺序的机制。
在选择连接中的表顺序时,SQLite 使用了一种高效的多项式时间图算法,该算法在下一代查询规划器文档中有描述。正因为如此,SQLite 能够在微秒级别规划具有50个或60个连接的查询。
连接重新排序是自动的,通常工作得很好,程序员不必考虑它,特别是如果已经使用 ANALYZE 收集了有关可用索引的统计信息,尽管偶尔需要程序员的一些提示。例如,考虑以下模式:
CREATE TABLE node(id INTEGER PRIMARY KEY,name TEXT
);
CREATE INDEX node_idx ON node(name);
CREATE TABLE edge(orig INTEGER REFERENCES node,dest INTEGER REFERENCES node,PRIMARY KEY(orig, dest)
);
CREATE INDEX edge_idx ON edge(dest,orig);
上述模式定义了一个有向图,可以在每个节点处存储一个名称。现在考虑针对此模式的查询:
SELECT *FROM edge AS e,node AS n1,node AS n2WHERE n1.name = 'alice'AND n2.name = 'bob'AND e.orig = n1.idAND e.dest = n2.id;
这个查询要求的是从标有 “alice” 的节点到标有 “bob” 的节点的所有边的信息。SQLite 查询优化器基本上有两种选择来实现这个查询。(实际上有六种不同的选择,但我们在这里只考虑其中的两种。)下面是演示这两种选择的伪代码。
选项 1:
foreach n1 where n1.name='alice' do:foreach n2 where n2.name='bob' do:foreach e where e.orig=n1.id and e.dest=n2.idreturn n1.*, n2.*, e.*endend
end
选项 2:
foreach n1 where n1.name='alice' do:foreach e where e.orig=n1.id do:foreach n2 where n2.id=e.dest and n2.name='bob' do:return n1.*, n2.*, e.*endend
end
这两个实现选项中,每个循环都使用相同的索引来加速。这两个查询计划的唯一区别是循环的嵌套顺序。
那么哪个查询计划更好呢?结果取决于节点表和边表中的数据类型。
假设有 M 个 alice 节点,N 个 bob 节点。考虑两种情况。在第一种情况中,M 和 N 都为2,但每个节点有数千条边。在这种情况下,选项1更优。对于选项1,内循环检查一对节点之间是否存在边,并在找到时输出结果。因为只有2个 alice 和 bob 节点,所以内循环只需要运行四次,查询就非常快了。选项2在这里会花费更长的时间。选项2的外循环只执行两次,但因为每个 alice 节点都有大量的边,所以中间循环必须迭代数千次。它会慢得多。所以在第一种情况下,我们更倾向于使用选项1。
现在考虑 M 和 N 都为3500的情况。Alice 节点非常多。这次假设这些节点中的每一个只通过一两条边连接。现在选项2更优。对于选项2,外循环仍然需要运行3500次,但是每个外循环中,中间循环只运行一次或两次,内循环只有在每个中间循环中才会运行一次,如果有的话。所以内循环的总迭代次数大约是7000次。另一方面,选项1必须分别运行其外循环和中间循环3500次,导致中间循环的迭代次数达到1200万次。因此,在第二种情况下,选项2比选项1快近2000倍。
所以你可以看到,根据表中数据的结构,查询计划1或查询计划2可能更好。SQLite 默认选择哪个计划呢?在3.6.18版本中,如果没有运行 ANALYZE,SQLite 将选择选项2。如果运行了 ANALYZE 命令以收集统计信息,如果统计信息表明另一种选择可能运行得更快,可能会做出不同的选择。
7.1. 手动控制连接顺序
SQLite 几乎总是自动选择最佳的连接顺序。很少有开发者需要干预来给查询规划器提供关于最佳连接顺序的提示。最好的策略是使用 PRAGMA optimize 确保查询规划器可以访问数据库中数据形状的最新统计信息。
本节描述了开发者如何控制 SQLite 中的连接顺序,以解决可能出现的任何性能问题。然而,除非作为最后的手段,否则不推荐使用这些技术。
如果你遇到一个情况,即使在运行 PRAGMA optimize 后,SQLite 仍然选择了次优的连接顺序,请在 SQLite 社区论坛上报告你的情况,以便 SQLite 的维护者可以对查询规划器进行新的改进,使得不需要手动干预。
7.1.1. 使用 SQLITE_STAT 表手动控制查询计划
SQLite 提供了一种能力,让高级程序员可以控制优化器选择的查询计划。一种方法是在 sqlite_stat1 表中篡改 ANALYZE 的结果。
7.1.2. 使用 CROSS JOIN 手动控制查询计划
程序员可以通过使用 CROSS JOIN 运算符而不是 JOIN、INNER JOIN、NATURAL JOIN 或 “,” 连接,强制 SQLite 使用特定的循环嵌套顺序。尽管理论上 CROSS JOIN 是可交换的,但 SQLite 选择永远不重新排序 CROSS JOIN 中的表。因此,CROSS JOIN 的左表总是相对于右表处于外循环。
在以下查询中,优化器可以自由地以任何方式重新排序 FROM 子句中的表:
SELECT *FROM node AS n1,edge AS e,node AS n2WHERE n1.name = 'alice'AND n2.name = 'bob'AND e.orig = n1.idAND e.dest = n2.id;
在以下逻辑等效的相同查询中,将 “,” 替换为 “CROSS JOIN” 意味着表的顺序必须是 N1、E、N2。
SELECT *FROM node AS n1 CROSS JOINedge AS e CROSS JOINnode AS n2WHERE n1.name = 'alice'AND n2.name = 'bob'AND e.orig = n1.idAND e.dest = n2.id;
在后一个查询中,查询计划必须是选项2。注意,我们必须使用关键字 “CROSS” 才能禁用表重新排序优化;INNER JOIN、NATURAL JOIN、JOIN 和其他类似的组合就像逗号连接一样,优化器可以自由地根据需要重新排序表。(在外连接上也禁用了表重新排序,但这是因为外连接既不是关联的也不是可交换的。重新排序 OUTER JOIN 中的表会改变结果。)
8. 在多个索引之间进行选择
查询的 FROM 子句中的每个表最多可以使用一个索引(除非 OR 子句优化起作用),SQLite 尽力在每个表上使用至少一个索引。有时,两个或多个索引可能是单个表的候选索引。例如:
CREATE TABLE ex2(x,y,z);
CREATE INDEX ex2i1 ON ex2(x);
CREATE INDEX ex2i2 ON ex2(y);
SELECT z FROM ex2 WHERE x=5 AND y=6;
对于上述 SELECT 语句,优化器可以使用 ex2i1 索引查找 ex2 中包含 x=5 的行,然后针对 y=6 项测试每一行。或者,它可以使用 ex2i2 索引查找 ex2 中包含 y=6 的行,然后针对 x=5 项测试每个行。
在面临两个或多个索引的选择时,SQLite 尝试估计使用每个选项执行查询所需的总工作量。然后选择估计工作量最少的选项。
为了帮助优化器更准确地估计使用各种索引涉及的工作量,用户可以选择运行 ANALYZE 命令。ANALYZE 命令扫描数据库中可能在两个或多个索引之间进行选择的所有索引,并收集有关这些索引的选择性的统计信息。此扫描收集的统计信息存储在以 “sqlite_stat” 开头的特殊数据库表中。这些表的内容不会随着数据库的更改而更新,因此在进行重大更改后,重新运行 ANALYZE 可能是明智的。ANALYZE命令的结果仅对在 ANALYZE 命令完成后打开的数据库连接可用。
各种 sqlite_statN 表包含有关各种索引选择性的信息。例如,sqlite_stat1 表可能指示,列 x 上的等式约束平均将搜索空间减少到10行,而列 y 上的等式约束平均将搜索空间减少到3行。在这种情况下,SQLite 会更喜欢使用 ex2i2 索引,因为该索引更具选择性。
8.1. 使用一元 “+” 取消 WHERE 子句条件
请注意,以这种方式取消 WHERE 子句条件不是推荐的做法。这是一种变通方法。只有在作为最后手段来获得所需性能时才这样做。
可以通过在列名前加上一元 + 运算符来手动取消 WHERE 子句中的条件以用于索引。一元 + 是一个空操作,不会在预处理语句中生成任何字节码。然而,一元 + 运算符将阻止该项约束索引。因此,在上面的示例中,如果查询被重写为:
SELECT z FROM ex2 WHERE +x=5 AND y=6;
x 列上的 + 运算符将阻止该项约束索引。这将强制使用 ex2i2 索引。
注意,一元 + 运算符还会从表达式中删除类型关联,而在某些情况下,这可能导致表达式含义的微妙变化。在上面的示例中,如果列 x 具有 TEXT 关联,则比较 “x=5” 将作为文本进行。+ 运算符删除了关联。因此,比较 “+x=5” 将把列 x 中的文本与数字值 5 进行比较,结果总是为假。
8.2. 范围查询
考虑一个稍微不同的场景:
CREATE TABLE ex2(x,y,z);
CREATE INDEX ex2i1 ON ex2(x);
CREATE INDEX ex2i2 ON ex2(y);
SELECT z FROM ex2 WHERE x BETWEEN 1 AND 100 AND y BETWEEN 1 AND 100;
进一步假设列 x 包含分布在 0 到 1,000,000 之间的值,列 y 包含分布在 0 到 1,000 之间的值。在这种情况下,列 x 上的范围约束应该使搜索空间减少 10,000 倍,而列 y 上的范围约束应该使搜索空间减少 10 倍。因此,应该优先使用 ex2i1 索引。
SQLite 会做出这个决定,但前提是它已经使用 SQLITE_ENABLE_STAT3 或 SQLITE_ENABLE_STAT4 编译。SQLITE_ENABLE_STAT3 和 SQLITE_ENABLE_STAT4 选项会使 ANALYZE 命令在 sqlite_stat3 或 sqlite_stat4 表中收集列内容的直方图,并使用此直方图为上述范围约束等情况做出更好的查询选择。STAT3 和 STAT4 之间的主要区别在于,STAT3 仅记录索引最左侧列的直方图数据,而 STAT4 记录索引所有列的直方图数据。对于单列索引,STAT3 和 STAT4 的工作方式相同。
直方图数据仅在约束的右侧是简单的编译时常量或参数而不是表达式时有用。
直方图数据的另一个限制是它只适用于索引的最左侧的列。考虑以下情况:
CREATE TABLE ex3(w,x,y,z);
CREATE INDEX ex3i1 ON ex2(w, x);
CREATE INDEX ex3i2 ON ex2(w, y);
SELECT z FROM ex3 WHERE w=5 AND x BETWEEN 1 AND 100 AND y BETWEEN 1 AND 100;
这里的不等式在 x 和 y 列上,它们不是最左侧的索引列。因此,收集的直方图数据对于选择 x 和 y 列上的范围约束无用。
9. 覆盖索引
在对一行进行索引查找时,通常的过程是在索引上进行二分查找以找到索引条目,然后从索引中提取 rowid,并使用该 rowid 在原始表上进行二分查找。因此,典型的索引查找涉及两次二分查找。然而,如果所有要从表中获取的列已经在索引中可用,SQLite 将使用索引中的值,而永远不会查找原始表行。这节省了每行的一次二分查找,可以使许多查询运行速度加倍。
当一个索引包含查询所需的所有数据,并且原始表永远不需要被查询时,我们称该索引为 “覆盖索引”。
10. ORDER BY 优化
SQLite 尝试使用索引来满足查询的 ORDER BY 子句。当面临使用索引满足 WHERE 子句约束或满足 ORDER BY 子句的选择时,SQLite 会进行上述的成本分析,并选择它认为会得到最快答案的索引。
SQLite 还会尝试使用索引来帮助满足 GROUP BY 子句和 DISTINCT 关键字。如果可以将连接的嵌套循环排列成对于 GROUP BY 或 DISTINCT 来说是连续的等价行,那么 GROUP BY 或 DISTINCT 逻辑只需通过比较当前行和前一行就可以判断当前行是否属于同一组或是否与当前行不同。这比比较每一行和所有先前的行要快得多。
10.1. 通过索引部分 ORDER BY
如果查询包含具有多个项的 ORDER BY 子句,SQLite 可能可以使用索引使行按 ORDER BY 中的某些前缀项的顺序出现,但 ORDER BY 的后续项可能无法满足。在这种情况下,SQLite 进行块排序。假设 ORDER BY 子句有四个项,并且查询结果的自然顺序使行按前两个项的顺序出现。当每一行由查询引擎输出并进入排序器时,当前行中与 ORDER BY 的前两个项对应的输出与前一行进行比较。如果它们已经改变,当前的排序就结束并输出,然后开始新的排序。这会导致排序稍微快一些。更大的优点是需要在内存中保存的行数少得多,减少了内存需求,并且在核心查询运行完成之前就可以开始出现输出。
11. 子查询展平
当一个子查询出现在 SELECT 的 FROM 子句中时,最简单的行为是将子查询评估为一个临时表,然后针对临时表运行外部 SELECT。这样的计划可能是次优的,因为临时表不会有任何索引,而外部查询(可能是一个连接)将被迫对临时表进行完全表扫描,或者在查询时构造一个临时表索引,这两者都可能不太快。
为了克服这个问题,SQLite 尝试展平 SELECT 的 FROM 子句中的子查询。这涉及将子查询的 FROM 子句插入到外部查询的 FROM 子句中,并重写在外部查询中引用子查询结果集的表达式。例如:
SELECT t1.a, t2.b FROM t2, (SELECT x+y AS a FROM t1 WHERE z<100) WHERE a>5
使用查询展平重写为:
SELECT t1.x+t1.y AS a, t2.b FROM t2, t1 WHERE z<100 AND a>5
必须满足一长串条件才能进行查询展平。其中一些约束由斜体文本标记为过时。这些额外的约束保留在文档中以保留其他约束的编号。
这里的重点是,展平规则是微妙而复杂的。多年来,由于过于激进的查询展平导致了多个错误。另一方面,如果查询展平更保守,那么复杂查询和/或涉及视图的查询的性能可能会受到影响。
查询展平是使用视图时的重要优化。视图是嵌套查询,因此查询展平通常可以将视图查询的部分或全部并入调用查询,从而提高性能。
在某些情况下,查询展平可能会导致查询性能下降。这主要是因为展平的查询可能会导致更大的联接,而更大的联接可能会导致查询计划的搜索空间变得更大,从而导致查询优化器无法找到最佳的查询计划。SQLite 允许在视图和子查询名之前加上 “NOT INDEXED” 来禁止查询展平。例如:
SELECT * FROM my_view NOT INDEXED WHERE ...;
在上面的查询中,“my_view” 视图将被评估为一个单独的临时表,然后临时表将被插入到外部查询中。这可能会导致查询性能下降,但如果查询展平导致查询优化器无法找到最佳的查询计划,那么这可能会提高性能。在这种情况下,“NOT INDEXED” 是一种有用的工具。
12. 子查询协同程序
SQLite 以三种方式之一实现 FROM 子句子查询:
- 将子查询展平到其外部查询
- 将子查询评估为一个临时表,该表在执行的一个 SQL 语句的持续时间内存在,然后针对该临时表运行外部查询。
- 在与外部查询并行运行的协同程序中评估子查询,根据需要向外部查询提供行。
本节描述了第三种技术:将子查询实现为协同程序。
协同程序类似于子程序,它在与调用者相同的线程中运行,并最终将控制权返回给调用者。不同之处在于协同程序还具有在完成之前返回的能力,然后在下次调用时从中断的地方继续。
当子查询作为协同程序实现时,生成字节码以实现子查询,就像它是一个独立的查询一样,只是在计算每一行后,协同程序将控制权返回给调用者,而不是将结果行返回给应用程序。调用者可以使用计算出的一行作为其计算的一部分,然后在准备好下一行时再次调用协同程序。
与在临时表中存储子查询的完整结果集相比,协同程序更好,因为协同程序使用的内存更少。对于协同程序,只需要记住结果的一行,而对于临时表,需要存储所有结果行。此外,由于协同程序在外部查询开始工作之前不需要运行到完成,因此输出的第一行可以更快地出现,并且如果整个查询在完成之前被放弃,总体工作量会减少。
另一方面,如果子查询的结果必须多次扫描(例如,因为它是连接中的一个表),那么最好使用临时表来记住子查询的整个结果,以避免多次计算子查询。
12.1. 在排序后使用协同程序延迟工作
从 SQLite 版本 3.21.0(2017-10-24)开始,查询规划器将始终优先使用协同程序实现包含 ORDER BY 子句且不是连接的 FROM 子句子查询,当外部查询的结果集是“复杂”的时候。此功能允许应用程序在排序后将昂贵的计算从排序前移出,从而实现更快的操作。例如,考虑以下查询:
SELECT expensive_function(a) FROM tab ORDER BY date DESC LIMIT 5;
此查询的目标是计算表中最近五个条目的某个值。在上面的查询中,“expensive_function()”在排序之前调用,因此对表的每一行都调用,即使由于 LIMIT 子句最终省略了一些行。可以使用协同程序来解决这个问题:
SELECT expensive_function(a) FROM (SELECT a FROM tab ORDER BY date DESC LIMIT 5
);
在修订后的查询中,子查询由协同程序实现,计算 “a” 的五个最近值。这五个值从协同程序传递到外部查询,其中只对应用程序关心的特定行调用 “expensive_function()”。
未来版本的 SQLite 查询规划器可能会变得足够智能,可以自动实现上述转换,反向转换。也就是说,未来版本的 SQLite 可能会将第一种形式的查询转换为第二种形式,或者将以第二种方式编写的查询转换为第一种形式。截至 SQLite 版本 3.22.0(2018-01-22),如果外部查询在其结果集中不使用任何用户定义的函数或子查询,查询规划器将展平子查询。然而,对于上面显示的示例,SQLite 按照编写的查询实现每个查询。
13. MIN/MAX 优化
包含单个 MIN() 或 MAX() 聚合函数的查询,其参数是索引的最左列,可以通过执行单个索引查找而不是扫描整个表来满足。例如:
SELECT MIN(x) FROM table;
SELECT MAX(x)+1 FROM table;
14. 自动查询时索引
当没有索引可用于辅助查询评估时,SQLite 可能会创建一个仅在单个 SQL 语句的持续时间内存在的自动索引。自动索引有时也称为“查询时索引”。由于构造自动或查询时索引的成本是 O(NlogN)(其中 N 是表中的条目数),而执行完整表扫描的成本仅为 O(N),因此仅当 SQLite 预计在 SQL 语句执行过程中查找将运行超过 logN 次时,才会创建自动索引。考虑一个例子:
CREATE TABLE t1(a,b);
CREATE TABLE t2(c,d);
-- 向 t1 和 t2 插入许多行
SELECT * FROM t1, t2 WHERE a=c;
在上面的查询中,如果 t1 和 t2 都有大约 N 行,那么在没有任何索引的情况下,查询将需要 O(N*N) 时间。另一方面,创建表 t2 上的索引需要 O(NlogN) 时间,使用该索引评估查询需要额外的 O(NlogN) 时间。在没有 ANALYZE 信息的情况下,SQLite 猜测 N 是一百万,因此它相信构造自动索引将是更便宜的方法。
自动查询时索引还可以用于子查询:
CREATE TABLE t1(a,b);
CREATE TABLE t2(c,d);
-- 向 t1 和 t2 插入许多行
SELECT a, (SELECT d FROM t2 WHERE c=b) FROM t1;
在这个例子中,t2 表用于子查询来转换 t1.b 列的值。如果每个表包含 N 行,SQLite 预计子查询将运行 N 次,因此它会认为首先在 t2 上构建一个自动的临时索引,然后使用该索引满足子查询的 N 个实例是更快的方法。
使用自动索引功能可以在运行时使用 automatic_index 条目禁用。自动索引默认是开启的,但可以使用 SQLITE_DEFAULT_AUTOMATIC_INDEX 编译时选项将其更改为默认关闭。通过使用 SQLITE_OMIT_AUTOMATIC_INDEX 编译时选项完全禁用创建自动索引的功能。
在 SQLite 版本 3.8.0(2013-08-26)及更高版本中,每次准备使用自动索引的语句时,都会将 SQLITE_WARNING_AUTOINDEX 消息发送到错误日志。应用程序开发人员可以并且应该使用这些警告来识别模式中需要新的持久性索引的需求。
请勿将自动索引与有时用于实现 PRIMARY KEY 约束或 UNIQUE 约束的内部索引(名称类似于 “sqlite_autoindex_table_N”)混淆。这里描述的自动索引仅在单个查询的持续时间内存在,永远不会持久化到磁盘,并且仅对单个数据库连接可见。内部索引是实现 PRIMARY KEY 和 UNIQUE 约束的一部分,是长期持久化到磁盘的,并且对所有数据库连接可见。内部索引的名称中出现了 “autoindex” 一词是由于历史原因,并不表明内部索引和自动索引有关。
14.1. 哈希连接
自动索引几乎与哈希连接相同。唯一的区别是使用 B-Tree 而不是哈希表。如果你愿意说为自动索引构造的临时 B-Tree 实际上只是一个花哨的哈希表,那么使用自动索引的查询就是一个哈希连接。
SQLite 在这种情况下构造临时索引而不是哈希表,因为它已经有了一个健壮且高性能的 B-Tree 实现,而哈希表需要添加。为了处理这一情况而添加一个单独的哈希表实现会增加库的大小(该库设计用于低内存嵌入式设备)并带来最小的性能增益。SQLite 可能会在某一天增强哈希表实现,但是现在在客户端/服务器数据库引擎可能使用哈希连接的情况下继续使用自动索引似乎更好。
15. WHERE 子句下推优化
如果子查询不能展平到外部查询,可能仍然可以通过将 WHERE 子句中的项从外部查询“下推”到子查询来提高性能。考虑一个例子:
CREATE TABLE t1(a INT, b INT);
CREATE TABLE t2(x INT, y INT);
CREATE VIEW v1(a,b) AS SELECT DISTINCT a, b FROM t1;SELECT x, y, bFROM t2 JOIN v1 ON (x=a)WHERE b BETWEEN 10 AND 20;
视图 v1 不能被展平,因为它是 DISTINCT。它必须作为子查询运行,结果存储在一个临时表中,然后在 t2 和临时表之间进行连接。下推优化将 “b BETWEEN 10 AND 20” 项下推到视图中。这使得临时表更小,并且如果在 t1.b 上有索引,可以帮助子查询更快地运行。结果的评估如下:
SELECT x, y, bFROM t2JOIN (SELECT DISTINCT a, b FROM t1 WHERE b BETWEEN 10 AND 20)WHERE b BETWEEN 10 AND 20;
WHERE 子句下推优化不能总是使用。例如,如果子查询包含 LIMIT,那么从外部查询下推 WHERE 子句的任何部分都可能改变内部查询的结果。还有其他限制,这在源代码中实现此优化的 pushDownWhereTerms() 函数的注释中有解释。
不要将此优化与 MySQL 中名称相似的优化混淆。MySQL 的下推优化改变了 WHERE 子句约束的评估顺序,使得可以仅使用索引而不需要找到对应的表行的约束先被评估,从而避免在约束失败时不必要的表行查找。为了消除歧义,SQLite 称其为 “MySQL 下推优化”。SQLite 也做了 MySQL 下推优化,除了 WHERE 子句下推优化。但是,本节的重点是 WHERE 子句下推优化。
16. OUTER JOIN 强度减小优化
OUTER JOIN(LEFT JOIN,RIGHT JOIN 或 FULL JOIN)有时可以简化。LEFT 或 RIGHT JOIN 可以转换为普通(INNER)JOIN,或者 FULL JOIN 可能被转换为 LEFT 或 RIGHT JOIN。如果 WHERE 子句中的条件可以保证简化后的结果相同,那么就可以发生这种情况。例如,如果 LEFT JOIN 的右表中的任何列必须为非 NULL 以使 WHERE 子句为真,那么 LEFT JOIN 就降级为普通 JOIN。
确定连接是否可以简化的定理证明器是不完美的。它有时会返回假阴性。换句话说,有时它无法证明减小 OUTER JOIN 的强度是安全的,实际上它是安全的。例如,证明器不知道 datetime() SQL 函数如果其第一个参数为 NULL,总是返回 NULL,因此它不会认识到以下查询中的 LEFT JOIN 可以进行强度减小:
SELECT urls.urlFROM urlsLEFT JOIN(SELECT *FROM (SELECT url_id AS uid, max(retrieval_time) AS rtimeFROM lookups GROUP BY 1 ORDER BY 1)WHERE uid IN (358341,358341,358341)) recentON u.source_seed_id = recent.xyz OR u.url_id = recent.xyzWHEREDATETIME(recent.rtime) > DATETIME('now', '-5 days');
可能未来对证明器的增强可能使其能够识别到某些内置函数的 NULL 输入总是导致 NULL 答案。然而,并非所有内置函数都具有该属性(例如 coalesce()),当然,证明器将永远无法推理出应用程序定义的 SQL 函数。
17. 省略 OUTER JOIN 优化
有时可以完全从查询中省略 LEFT 或 RIGHT JOIN,而不改变结果。只有在所有以下条件都为真时,才会发生这种情况:
- 查询不是聚合
- 查询是 DISTINCT,或者 OUTER JOIN 的 ON 或 USING 子句约束连接,使其只匹配一行
- LEFT JOIN 的右表或 RIGHT JOIN 的左表在查询中的任何地方都不会在其自己的 USING 或 ON 子句之外使用。
当 OUTER JOIN 用于视图内部,然后以不引用 LEFT JOIN 的右表或 RIGHT JOIN 的左表的任何列的方式使用视图时,通常会出现 OUTER JOIN 消除。
这是省略 LEFT JOIN 的一个简单示例:
CREATE TABLE t1(ipk INTEGER PRIMARY KEY, v1);
CREATE TABLE t2(ipk INTEGER PRIMARY KEY, v2);
CREATE TABLE t3(ipk INTEGER PRIMARY KEY, v3);SELECT v1, v3 FROM t1 LEFT JOIN t2 ON (t1.ipk=t2.ipk)LEFT JOIN t3 ON (t1.ipk=t3.ipk)
在上面的查询中,t2 表在查询中完全未使用,因此查询规划器能够实现查询,就像它是这样写的:
SELECT v1, v3 FROM t1 LEFT JOIN t3 ON (t1.ipk=t3.ipk)
在撰写本文时,只有 LEFT JOIN 被省略。此优化尚未推广到 RIGHT JOIN,因为 RIGHT JOIN 是 SQLite 的一个相对新的添加。这种不对称性可能会在未来的版本中得到纠正。
18. 常量传播优化
当 WHERE 子句包含两个或多个由 AND 运算符连接的等式约束,且所有约束的亲和性都相同时,SQLite 可能会使用等式的传递性构造新的“虚拟”约束,以简化表达式和/或提高性能。这被称为“常量传播优化”。
例如,考虑以下模式和查询:
CREATE TABLE t1(a INTEGER PRIMARY KEY, b INT, c INT);
SELECT * FROM t1 WHERE a=b AND b=5;
SQLite 查看 “a=b” 和 “b=5” 约束,并推断出如果这两个约束为真,那么 “a=5” 也必须为真。这意味着可以使用 5 作为 INTEGER PRIMARY KEY 快速查找所需的行。
相关文章:

SQLite查询优化
文章目录 1. 引言2. WHERE子句分析2.1. 索引项使用示例 3. BETWEEN优化4. OR优化4.1. 将OR连接的约束转换为IN运算符4.2. 分别评估OR约束并取结果的并集 5. LIKE优化6. 跳跃扫描优化7. 连接7.1. 手动控制连接顺序7.1.1. 使用 SQLITE_STAT 表手动控制查询计划7.1.2. 使用 CROSS …...

UE4编辑器End键Actor贴近地面
void UXXXEditorFunctionLibrary::SnapToFloor(AActor* Actor) { if (Actor) { Actor->Modify(); GEditor->SnapObjectTo(FActorOrComponent(Actor), false, false, false, false); Actor->InvalidateLightingCache(); Actor->UpdateComponentTransforms(); } }...
2024儿科常用心理评估量表汇总,附详细操作步骤与评定标准
在社会的快速发展以及家庭教育模式的转变下,儿童心理健康问题正逐步成为公众瞩目的焦点。焦虑症、抑郁症、适应障碍等儿科常见的症状,不仅对孩子的身心健康构成威胁,更可能在他们的学习旅程和社交互动中制造重重障碍。 儿科医师常用评估量表…...
Python 脚本化 Git 操作:简单、高效、无压力
前言 如何判定此次测试是否达标,代码覆盖率是衡量的标准之一。前段时间,利用fastapi框架重写了覆盖率统计服务,核心其实就是先获取全量代码覆盖率,然后通过diff操作统计增量代码覆盖率,当然要使用diff操作,…...

手搓顺序表(C语言)
目录 SeqList.h SeqList.c 头插尾插复用任意位置插入 头删尾删复用任意位置删除 SLtest.c 测试示例 顺序表优劣分析 SeqList.h //SeqList.h#pragma once#include <stdio.h> #include <assert.h> #include <stdlib.h> #define IN_CY 3typedef int S…...

一文搞懂oracle事务提交以及脏数据落盘的原则
本文基于oracle 19c 做事务提交以及oracle脏数据落盘的相关解读 第一章 相关进程及组件介绍: 1.LGWR: 重做日志条目在系统全局区域 (SGA) 的重做日志缓冲区中生成。LGWR 按顺序将重做日志条目写入重做日志文件。如果数据库具有…...
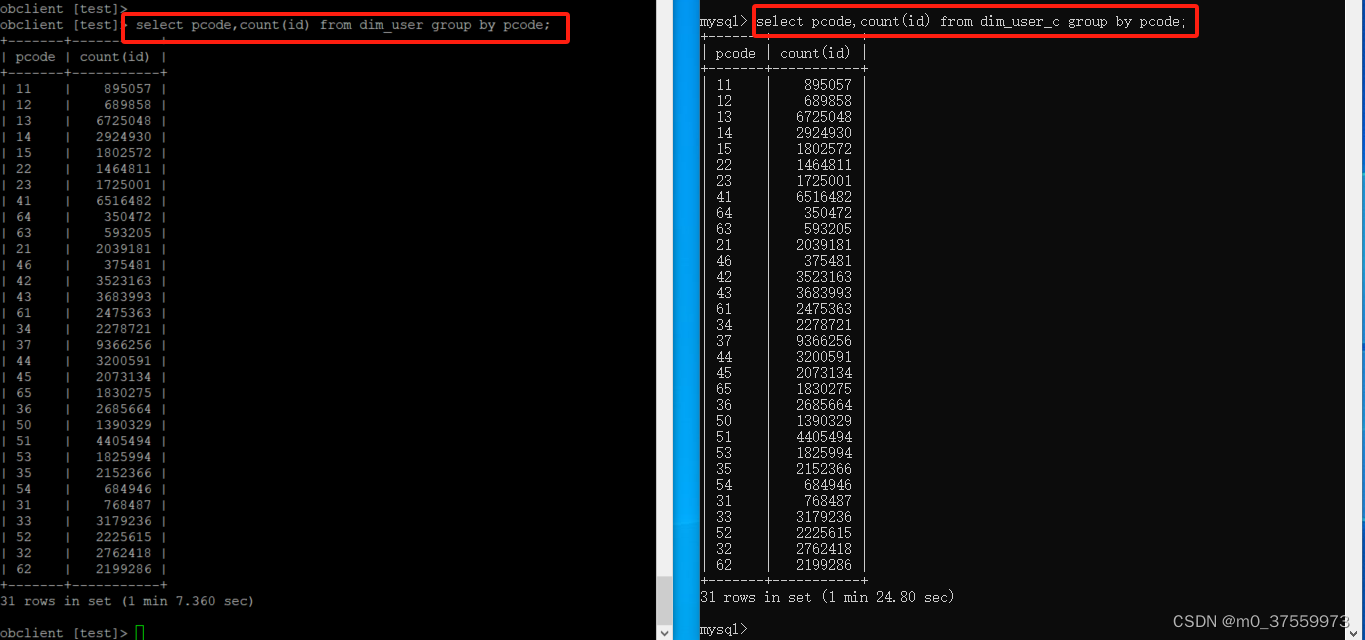
OceanBase:列存储
目录 1、列存储的定义 1、默认创建列存表 3、指定创建列存表 4、指定创建列存行存冗余表 5、行、列存储查询测试 1、列存储的定义 行存储(Row-based Storage):行存储是以行为单位进行组织和存储数据。在这一模式下,数据库将…...

Rust:WIndows 环境下交叉编译 Linux 平台程序
在Windows下交叉编译Rust程序以在x86_64位的CentOS操作系统上运行,你需要遵循几个步骤来设置交叉编译环境并编译你的程序。以下是一个大致的指南: 1. 安装Rust和Cargo 首先,确保你已经在Windows上安装了Rust和Cargo。你可以从Rust官方网站下…...

从零学爬虫:使用比如说说解析网页结构
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、引言 二、网页结构概述 示例:查看网页结构 三、使用比如说说解析网页 1.…...

C#数据类型变量、常量
一个变量只不过是一个供程序操作的存储区的名字。 在 C# 中,变量是用于存储和表示数据的标识符,在声明变量时,您需要指定变量的类型,并且可以选择性地为其分配一个初始值。 在 C# 中,每个变量都有一个特定的类型&…...

Java高级面试问题及答案
Java高级面试问题及答案 问题1: 请描述Java内存模型(JMM)及其在并发编程中的重要性。 探讨过程: 在并发编程中,多个线程之间如何协调对共享变量的访问是一个核心问题。Java内存模型定义了一组规则,来确保在多线程环境中对共享变量的修改能够…...
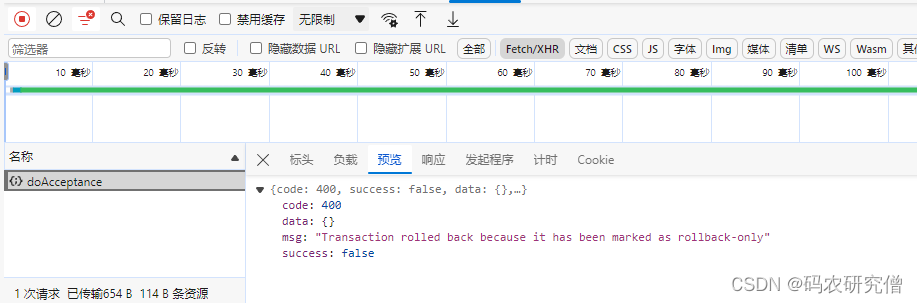
出现 Transaction rolled back because it has been marked as rollback-only 解决方法
目录 1. 问题所示2. 原理分析3. 解决方法1. 问题所示 用户反馈的Bug如下所示: Transaction rolled back because it has been marked as rollback-only截图如下: 浏览器终端同样显示: 2. 原理分析 错误表明,在事务的生命周期内,遇到了某个异常或条件,导致该事务被标记…...

数据结构算法题day03
数据结构算法题day03 题目 题目 2.设计一个高效算法,将顺序表L的所有元素逆置,要求算法的空间复杂度为O(1)算法思想: 1、常规的解法: Void reverse (sqlist &L){Elemtype temp; //辅助变量for(i 0,i < L.length; i){temp…...

深入分析C#中的“编写器”概念——代码修改、注解与重构
文章目录 1. 编写器(Writer)的概念2. 编写器的作用和工作原理3. 编写器的重要性4. 写入器常用方法5. 写入器示例6. 编写器示例——使用Fody进行代码注解和重构7. 总结 在软件开发过程中,代码的维护和更新是至关重要的。C#作为一种流行的编程语…...

uview1.0 u-form表单回显校验不通过
提交到后端的数据,回显后不做任何修改无法通过表单校验 原因,u-form表单校验的类型默认为string,但是后端返回的是integer类型,导致无法通过校验 解决,既然后端返回的是整数形,那么我们就将校验规则的type…...

监控员工电脑的软件有哪些,不得不说这几款电脑监控软件太好用了
监控员工电脑的软件在市场上种类繁多,以下是几款备受好评的电脑监控软件,它们各自具有独特的功能和优势,选择前必须了解一下才能做成正确决定。 1.安企神: 这款软件支持7天试用测试,获取测试版请移驾 ↓↓↓ 安企神…...
)
【MySQL精通之路】索引优化(2)
目录 1 MySQL如何使用索引 2 主键优化 3 空间索引优化 4 外键优化 5 列索引 6 多列索引 7 验证索引使用情况 8 InnoDB和MyISAM索引统计集合 9 B树索引与哈希索引的比较 9.1 B-树索引特征 9.2 哈希索引特征 10 索引扩展的使用 11 优化器使用生成的列索引 12 不可见…...
:数组处理、计算属性与函数、class与Style绑定)
VUE3 学习笔记(5):数组处理、计算属性与函数、class与Style绑定
数组监测处理方法 VUE 提供了关于数组处理的直接方法,但并非全部都是可以处理的 如下可以直接处理: .push --向数组中增加 .pop --从数组中最后减去一个元素 .shift --从数组中第一个减去一个元素 .unshift --在数组中的头部添加一个元素 .splice --自定…...
基于springboot实现大学生一体化服务平台系统项目【项目源码+论文说明】
基于springboot实现大学生一体化服务平台系统演示 摘要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统大学生综…...

惠海 H6902B 升压恒流芯片 太阳能 风扇灯 应急灯 支持3.7V 5V 7.4V
惠海H6902B升压恒流驱动芯片是一款专为LED照明应用设计的驱动方案。该芯片具有多项产品特征,能够满足多种LED照明需求。 适用于多种电压输入范围(2.7V-80V)并具备效率(达95%以上)和工作频率(1MHzÿ…...

避坑指南:华为云Stack OBS 3.0对象存储部署,小型化与标准化方案到底怎么选?
华为云Stack OBS 3.0部署选型实战:小型化与标准化方案深度对比 当企业级用户面对华为云Stack OBS 3.0对象存储部署时,第一个关键决策点往往出现在架构形态的选择上——是采用轻量灵活的小型化方案,还是选择高扩展性的标准化部署?这…...
)
【仅限前500名设计师获取】Midjourney双色调调色板生成器(含17组经Adobe Color验证的高转化配色矩阵)
更多请点击: https://codechina.net 第一章:Midjourney双色调调色范式的底层逻辑与设计价值 双色调(Duotone)并非简单叠加两种颜色,而是基于人眼视觉感知的非线性响应特性,在Midjourney中构建的一套语义化…...

ARMv8-A架构CAS原子操作原理与优化实践
1. A64指令集的CAS原子操作基础在ARMv8-A架构中,原子操作是并发编程的基础构建块。CAS(Compare and Swap)作为最核心的原子操作之一,其工作原理可以类比为"先验货再付款"的购物过程:首先检查内存中的当前值是…...

联想笔记本BIOS解锁完整指南:一键开启隐藏高级设置
联想笔记本BIOS解锁完整指南:一键开启隐藏高级设置 【免费下载链接】LEGION_Y7000Series_Insyde_Advanced_Settings_Tools 支持一键修改 Insyde BIOS 隐藏选项的小工具,例如关闭CFG LOCK、修改DVMT等等 项目地址: https://gitcode.com/gh_mirrors/le/L…...

地质建模革命:如何使用GemPy在10分钟内构建专业3D地质模型 [特殊字符]
地质建模革命:如何使用GemPy在10分钟内构建专业3D地质模型 🚀 【免费下载链接】gempy GemPy is an open-source, Python-based 3-D structural geological modeling software, which allows the implicit (i.e. automatic) creation of complex geologic…...

口腔诊所装修性价比提升指南
口腔诊所进行装修时,提升性价比的核心在于 “精准投入” ,即在确保医疗功能、患者体验和卫生合规的前提下,实现成本的最优化。1、 规划先行:奠定性价比基石 功能布局优先: 明确划分接待、候诊、诊疗、消毒等功能区&…...

ChromeKeePass深度解析:如何实现KeePass密码自动填充的强力浏览器扩展?
ChromeKeePass深度解析:如何实现KeePass密码自动填充的强力浏览器扩展? 【免费下载链接】ChromeKeePass Chrome extensions for automatically filling credentials from KeePass 项目地址: https://gitcode.com/gh_mirrors/ch/ChromeKeePass 你是…...
)
21 鸿蒙LiteOS软件定时器实战:多定时器周期性任务完整示例(源码+解析)
鸿蒙LiteOS软件定时器实战:多定时器周期性任务完整示例(源码解析) 一、前言 在嵌入式鸿蒙(OpenHarmony LiteOS)开发中,软件定时器是实现周期性任务、延时任务、定时触发逻辑的核心内核工具,无…...
-GPIO篇)
如何学会自己写代码控制STM32(裸机)-GPIO篇
//总结自己的工作经验,帮助学习单片机的入门者,快速上手写代码该文章是基于STM32F401裸机代码编写思路,后续会更新增加STM32FreeRTOS首先想要写单片机的程序,你必须有扎实的C语言基础,从我多次面试的经验总结ÿ…...

终极指南:3分钟完成Figma中文界面汉化,设计师必备的完整翻译插件
终极指南:3分钟完成Figma中文界面汉化,设计师必备的完整翻译插件 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?作为…...