【MySQL精通之路】索引优化(2)
目录
1 MySQL如何使用索引
2 主键优化
3 空间索引优化
4 外键优化
5 列索引
6 多列索引
7 验证索引使用情况
8 InnoDB和MyISAM索引统计集合
9 B树索引与哈希索引的比较
9.1 B-树索引特征
9.2 哈希索引特征
10 索引扩展的使用
11 优化器使用生成的列索引
12 不可见索引
13 降序索引
14 TIMESTAMP列的索引查询
1 MySQL如何使用索引
索引用于快速查找具有特定列值的行。
如果没有索引,MySQL必须从第一行开始,然后读取整个表以找到相关的行。
表越大,耗时就越多。
如果表中有相关列的索引,MySQL可以快速确定要在数据文件中查找的位置,而无需查看所有数据。这比按顺序读取每一行要快得多。
大多数MySQL索引(PRIMARY KEY、UNIQUE、INDEX和FULLTEXT)都存储在B+树中。
例外:
空间数据类型的索引使用R树;
MEMORY表还支持Hash索引;
InnoDB对FULLTEXT索引使用反向链表。
通常,索引的使用方式如下所述。
下文第9节“B树和哈希索引的比较”中描述了哈希索引(如MEMORY表中所用)的特定特性。
MySQL使用索引进行以下操作:
快速查找与WHERE子句匹配的行。
将行排除在考虑范围之外。如果在多个索引之间进行选择,MySQL通常使用查找行数最少的索引(最具选择性的索引)。
如果表具有多列索引,则优化器可以使用索引最左边的任何前缀来查找行。例如,如果您在(col1,col2,col3)上有一个三列索引,则您在(coll1)、(col1、col2)和(col1和col2,coll3)上具有索引搜索功能。有关更多信息,请参阅“多列索引”。
在执行联接查询时从其他表中检索行。
如果列被声明为相同的类型和大小,MySQL可以更有效地使用列上的索引。
在这种情况下,如果VARCHAR和CHAR被声明为相同的大小,则它们被认为是相同的。例如,VARCHAR(10)和CHAR(10)的大小相同,但VARCHAR(10)与CHAR(15)的大小不同。
对于非二进制字符串列之间的比较,两列应使用相同的字符集。例
如,将utf8mb4列与latin1列进行比较会排除索引的使用。
如果在不进行转换的情况下无法直接比较值,则比较不同列(例如,将字符串列与时间列或数值列进行比较)可能会阻止使用索引。
对于给定的值,如数字列中的1,它可能与字符串列中的任意数量的值(如“1”、“1”,“00001”或“01.e1”)进行比较。
这就排除了对字符串列使用任何索引的可能性。
查找特定索引列key_col的MIN()或MAX()值。
这是由一个预处理器优化的,该预处理器检查您是否在索引中key_col之前出现的所有键部分上使用WHERE key_part_N=常量。在这种情况下,MySQL为每个MIN()或MAX()表达式执行单个关键字查找,并将其替换为常量。如果所有表达式都替换为常量,则查询将立即返回。例如
SELECT MIN(key_part2),MAX(key_part2)FROM tbl_name WHERE key_part1=10;
如果排序或分组是在可用索引的最左边前缀上完成的,则对表进行排序或分组(例如ORDER BY key_part1、key_part2)。
如果所有字段部分后面都跟着DESC,则按相反顺序读取该字段部分。
(或者,如果索引是降序索引,则按正向顺序读取键。)
请参阅“排序优化”、“分组优化“,“降序索引”。后续更新
在某些情况下,可以优化查询以检索值,而无需查询数据行。(为查询提供所有必要结果的索引称为覆盖索引。)如果查询仅从表中使用某些索引中包含的列,则可以从索引树中检索所选值以提高速度:
SELECT key_part3 FROM tbl_nameWHERE key_part1=1
对于小表或查询处理大部分或全部行的大表上的查询,索引不那么重要。当查询需要访问大部分行时,按顺序读取比通过索引更快。
即使不是查询需要所有的行,顺序读取也可以最大限度地减少磁盘查找。
有关详细信息,请参阅“避免全表扫描”。
【MySQL精通之路】SQL优化(1)-查询优化(23)-避免全表扫描-CSDN博客
2 主键优化
表的主键表示在最重要的查询中使用的列或列集。
它有一个关联的索引,用于快速查询性能。查询性能得益于NOT NULL优化,因为它不能包含任何NULL值。
使用InnoDB存储引擎,可以对表数据进行物理组织,以根据主键列进行超快速查找和排序。
如果表很大且很重要,但没有一个明显的列或一组列用作主键,则可以创建一个单独的列,并使用自动递增值作为主键。当您使用外键联接表时,这些唯一的ID可以作为指向其他表中相应行的指针。
3 空间索引优化
MySQL允许在NOT NULL几何值列上创建空间索引
(请参见“创建空间索引”)。
优化器检查索引列的SRID属性,以确定要使用哪个空间参考系统(SRS)进行比较,并使用适用于SRS的计算。
(在MySQL 8.0之前,优化器使用笛卡尔计算对空间索引值进行比较;如果列包含非笛卡尔SRID的值,则此类操作的结果是未定义的。)
为了使比较正常工作,SPATIAL索引中的每一列都必须受到SRID限制。
也就是说,列定义必须包括显式SRID属性,并且所有列值都必须具有相同的SRID。
优化器只考虑SRID限制列的SPATIAL索引:
1.限制为笛卡尔SRID的列上的索引启用笛卡尔边界盒子计算。
2.限制为地理SRID的列上的索引可以进行地理边界盒子计算。
优化器忽略没有SRID属性(因此不受SRID限制)的列上的空间索引。MySQL仍然维护这样的索引,如下所示:
4.它们会针对表修改(INSERT、UPDATE、DELETE等)进行更新。即使列可能包含笛卡尔和地理值的混合,更新也会像索引是笛卡尔的一样发生。
它们的存在只是为了向后兼容(例如,在MySQL 5.7中执行转储和在MySQL 8.0中执行恢复的能力)。因为没有SRID限制的列上的SPATIAL索引对优化器没有用处,所以应该修改每个这样的列:
验证列中的所有值是否具有相同的SRID。要确定几何体列col_name中包含的SRID,请使用以下查询:
SELECT DISTINCT ST_SRID(col_name) FROM tbl_name;如果查询返回多行,则该列包含SRID的混合。在这种情况下,请修改其内容,使所有值都具有相同的SRID。
将列重新定义为具有显式SRID属性。
重新创建空间索引。
4 外键优化
如果一个表有许多列,并且查询了许多不同的列组合,那么将不太频繁使用的数据拆分成单独的表,每个表有几列,并通过复制主表中的数字ID列将它们关联回主表,这可能会更有效。
这样,每个小表都可以有一个主键来快速查找其数据,并且可以使用联接操作只查询所需的列集。根据数据的分布方式,查询可能会执行更少的I/O,占用更少的缓存内存,因为相关列被打包在磁盘上。(为了最大限度地提高性能,查询尝试从磁盘中读取尽可能少的数据块;只有几列的表可以在每个数据块中容纳更多的行。)
5 列索引
最常见的索引类型包括一列,将该列中的值的副本存储在数据结构中,从而可以快速查找具有相应列值的行。
B树数据结构使索引能够快速找到一个特定值、一组值或一系列值,这些值对应于WHERE子句中的运算符,如=、>、≤、BETWEEN、IN等。
每个表的最大索引数和最大索引长度是按存储引擎定义的。请参阅第17章“InnoDB存储引擎”和第18章“替代存储引擎”。所有存储引擎都支持每个表至少16个索引,总索引长度至少为256字节。大多数存储引擎都有更高的限制。
有关列索引的更多信息,请参阅“CREATE INDEX语句”。
5.1 索引前缀
在字符串列的索引规范中使用col_name(N)语法,可以创建仅使用列的前N个字符的索引。以这种方式仅对列值的前缀进行索引会使索引文件变得更小。为BLOB或TEXT列编制索引时,必须为索引指定前缀长度。例如
CREATE TABLE test (blob_col BLOB, INDEX(blob_col(10)));对于使用REDUNDANT或COMPACT行格式的InnoDB表,前缀长度可达767字节。
对于使用DYNAMIC或COMPRESED行格式的InnoDB表,前缀长度限制为3072字节。
对于MyISAM表,前缀长度限制为1000字节。
注意:
前缀限制以字节为单位测量,而CREATE TABLE、ALTER TABLE和CREATE INDEX语句中的前缀长度被解释为非二进制字符串类型(CHAR、VARCHAR、TEXT)的字符数和二进制字符串类型的字节数(binary、VARBINARY、BLOB)。为使用多字节字符集的非二进制字符串列指定前缀长度时,请考虑这一点。
如果搜索项超过索引前缀长度,则使用索引排除不匹配的行,并检查其余行是否可能匹配。
有关索引前缀的更多信息,请参阅“CREATE INDEX语句”。
5.2 FULLTEXT索引
FULLTEXT索引用于全文搜索。只有InnoDB和MyISAM存储引擎支持FULLTEXT索引,并且仅支持CHAR、VARCHAR和TEXT列。索引总是在整列上进行,不支持列前缀索引。
有关详细信息,请参阅“全文搜索功能”。
优化应用于针对单个InnoDB表的某些类型的FULLTEXT查询。具有这些特征的查询特别有效:
仅返回文档ID或文档ID和搜索排名的FULLTEXT查询。
FULLTEXT查询按得分降序对匹配行进行排序,并应用LIMIT子句获取前N个匹配行。为了应用此优化,必须没有WHERE子句,只有一个按降序排列的ORDER BY子句。
FULLTEXT查询只检索与搜索项匹配的行的COUNT(*)值,不包含其他WHERE子句。将WHERE子句编码为WHERE MATCH(text)ANTION('other_text'),不包含任何>0的比较运算符。
对于包含全文表达式的查询,MySQL会在查询执行的优化阶段评估这些表达式。优化器不仅仅查看全文表达式并进行估计,它实际上还在开发执行计划的过程中对它们进行评估。
这种行为的一个含义是,全文查询的EXPLAIN通常比优化阶段未进行表达式求值的非全文查询慢。
全文查询的EXPLAIN可能会在Extra列中显示由于优化过程中发生匹配而优化的Select表;在这种情况下,在以后的执行过程中不需要进行表访问。
5.3 空间索引
可以对空间数据类型创建索引。MyISAM和InnoDB支持空间类型上的R树索引。其他存储引擎使用B树对空间类型进行索引(ARCHIVE除外,它不支持空间类型索引)。
5.4 MEMORY存储引擎中的索引
MEMORY存储引擎默认使用HASH索引,但也支持BTREE索引。
6 多列索引
MySQL可以创建复合索引(即多列上的索引)。一个索引最多可以由16列组成。对于某些数据类型,可以对列的前缀进行索引(请参阅第10.3.5节“列索引”)。
MySQL可以对测试索引中所有列的查询使用多个列索引,也可以只测试第一列、前两列、前三列的查询等等。如果在索引定义中按正确的顺序指定列,单个复合索引可以加快同一表上的多种查询。
多列索引可以被视为排序数组,其中的行包含通过连接索引列的值而创建的值。
笔记
作为复合索引的替代方案,您可以引入一个基于其他列的信息进行“哈希”处理的列。如果此列很短,并且具有合理的唯一性和索引,那么它可能比许多列上的“宽”索引更快。在MySQL中,使用这个额外的列非常容易:
SELECT * FROM tbl_nameWHERE hash_col=MD5(CONCAT(val1,val2))AND col1=val1 AND col2=val2;
假设一个表具有以下规范:
CREATE TABLE test (id INT NOT NULL,last_name CHAR(30) NOT NULL,first_name CHAR(30) NOT NULL,PRIMARY KEY (id),INDEX name (last_name,first_name)
);名称索引是对last_name和first_name列的索引。该索引可用于查询中的查找,这些查询为last_name和first_name值的组合指定了已知范围内的值。它也可以用于仅指定last_name值的查询,因为该列是索引的最左边前缀(如本节稍后所述)。因此,名称索引用于以下查询中的查找:
SELECT * FROM test WHERE last_name='Jones';SELECT * FROM testWHERE last_name='Jones' AND first_name='John';SELECT * FROM testWHERE last_name='Jones'AND (first_name='John' OR first_name='Jon');SELECT * FROM testWHERE last_name='Jones'AND first_name >='M' AND first_name < 'N';但是,名称索引不用于以下查询中的查找:
SELECT * FROM test WHERE first_name='John';SELECT * FROM testWHERE last_name='Jones' OR first_name='John';假设您发出以下SELECT语句:
SELECT * FROM tbl_nameWHERE col1=val1 AND col2=val2;如果col1和col2上存在多列索引,则可以直接提取相应的行。如果col1和col2上存在单独的单列索引,优化器会尝试使用索引合并优化(请参阅第10.2.1.3节“索引合并优化”),或者尝试通过决定哪个索引排除更多行并使用该索引提取行来找到限制性最强的索引。
如果表具有多列索引,则优化器可以使用索引最左边的任何前缀来查找行。例如,如果您在(col1,col2,col3)上有一个三列索引,则您在(coll1)、(col1、col2)和(col1和col2,coll3)上具有索引搜索功能。
如果列不构成索引的最左边前缀,MySQL就不能使用索引来执行查找。假设您的SELECT语句如下所示:
SELECT * FROM tbl_name WHERE col1=val1;
SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2;SELECT * FROM tbl_name WHERE col2=val2;
SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3;如果(col1、col2、col3)上存在索引,则只有前两个查询使用该索引。第三个和第四个查询确实涉及索引列,但不使用索引来执行查找,因为(col2)和(col2,col3)不是(col1,col2,coll3)的最左边前缀。
7 验证索引使用情况
始终检查您的所有查询是否真的使用了您在表中创建的索引。使用EXPLAIN语句,
如“使用EXPLAIN优化查询”所述。
8 InnoDB和MyISAM索引统计集合
存储引擎收集有关表的统计信息以供优化器使用。表统计信息基于值组,其中值组是具有相同键前缀值的一组行。出于优化器的目的,一个重要的统计信息是平均值组大小。
MySQL通过以下方式使用平均值组大小:
估计每次引用访问必须读取的行数
估计一个部分联接产生的行数,即窗体的一个操作产生的行的数量
(...) JOIN tbl_name ON tbl_name.key = expr
随着索引的平均值组大小的增加,索引对这两个目的的用处就越小,因为每次查找的平均行数也会增加:为了使索引更好地用于优化目的,最好每个索引值都以表中的少量行为目标。当给定的索引值产生大量行时,该索引的用处就小了,MySQL也不太可能使用它。
平均值组大小与表基数有关,表基数是值组的数量。SHOW INDEX语句显示基于N/S的基数值,其中N是表中的行数,S是平均值组大小。该比率得出了表中值组的大致数量。
对于基于<=>比较运算符的联接,NULL与任何其他值都没有区别:NULL<=>NULL,就像N<=>N表示任何其他N一样。
但是,对于基于=运算符的联接,NULL与非NULL值不同:当expr1或expr2(或两者)为NULL时,expr1=expr2不为true。这会影响tbl_name.key=expr形式的比较的ref访问:如果expr的当前值为NULL,MySQL不会访问该表,因为比较不可能为true。
对于=比较,表中有多少NULL值并不重要。出于优化目的,相关值是非NULL值组的平均大小。然而,MySQL目前无法收集或使用该平均大小。
对于InnoDB和MyISAM表,您可以分别通过InnoDB_stats_method和MyISAM_stats_method系统变量对表统计信息的收集进行一些控制。这些变量有三个可能的值,其差异如下:
当变量设置为nulls_equal时,所有NULL值都被视为相同(即,它们都形成一个值组)。
如果NULL值组大小远高于非NULL值组的平均大小,则此方法会使平均值组大小向上倾斜。这使得索引在优化器看来不如对于查找非NULL值的联接实际有用。因此,nulls_equal方法可能会导致优化器在应该使用索引进行ref访问时不使用索引。
当变量设置为nulls_equival时,NULL值不被视为相同。相反,每个NULL值形成一个单独的值组,大小为1。
如果有许多NULL值,此方法会向下倾斜平均值组的大小。如果非NULL值组的平均大小较大,则将每个NULL值计算为一个大小为1的组会导致优化器高估查找非NULL值的联接的索引值。因此,当其他方法可能更好时,nulls_equival方法可能会导致优化器使用此索引进行ref查找。
当变量设置为nulls_ignored时,将忽略NULL值。
如果您倾向于使用许多使用<=>而不是=的联接,则NULL值在比较中并不特殊,一个NULL等于另一个NULL。在这种情况下,nulls_equal是适当的统计方法。
innodb_stats_method系统变量具有全局值;myisam_stats_method系统变量同时具有全局值和会话值。设置全局值会影响相应存储引擎中表的统计信息收集。设置会话值仅影响当前客户端连接的统计信息收集。这意味着您可以通过设置myisam_stats_method的会话值,在不影响其他客户端的情况下,强制使用给定方法重新生成表的统计信息。
要重新生成MyISAM表统计信息,可以使用以下任意方法:
执行myisamchk--stats_method=method_name--analyze
更改表以使其统计信息过期(例如,插入一行,然后删除它),然后设置myisam_stats_method并发出ANALYZE table语句
关于innob_stats_method和myisam_stats_method的使用的一些注意事项:
可以强制显式收集表统计信息,如前所述。但是,MySQL也可以自动收集统计信息。例如,如果在为表执行语句的过程中,其中一些语句修改了表,MySQL可能会收集统计信息。(例如,这可能发生在大容量插入或删除,或某些ALTER TABLE语句中。)如果发生这种情况,则会使用innodb_stats_method或myisam_stats_method当时的任何值来收集统计信息。因此,如果您使用一种方法收集统计信息,但当稍后自动收集表的统计信息时,系统变量被设置为另一种方法,则会使用另一种方式。
无法判断使用哪种方法为给定的表生成统计信息。
这些变量仅适用于InnoDB和MyISAM表。其他存储引擎只有一种收集表统计信息的方法。通常它更接近于nulls_equal方法。
9 B树索引与哈希索引的比较
了解B-树和散列数据结构有助于预测不同查询在索引中使用这些数据结构的不同存储引擎上的执行情况,特别是对于允许您选择B-树或散列索引的MEMORY存储引擎。
9.1 B-树索引特征
B树索引可用于使用=、>、>=、<、<=或BETWEEN运算符的表达式中的列比较。如果LIKE的参数是不以通配符开头的常量字符串,则索引也可用于LIKE比较。例如,以下SELECT语句使用索引:
SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%';
SELECT * FROM tbl_name WHERE key_col LIKE 'Pat%_ck%';在第一个语句中,只考虑具有“Patrick”<=key_col<“Patricl”的行。在第二个语句中,只考虑“Pat”<=key_col<“Pau”的行。
以下SELECT语句不使用索引:
SELECT * FROM tbl_name WHERE key_col LIKE '%Patrick%';
SELECT * FROM tbl_name WHERE key_col LIKE other_col;在第一条语句中,LIKE值以通配符开头。在第二个语句中,LIKE值不是常量。
如果您使用。。。类似于“%string%”,字符串长度超过三个字符,MySQL使用Turbo Boyer-Moore算法初始化字符串的模式,然后使用此模式更快地执行搜索。
如果对col_name进行了索引,则使用col_name IS NULL的搜索将使用索引。
任何不跨越WHERE子句中所有AND级别的索引都不会用于优化查询。换句话说,为了能够使用索引,必须在每个AND组中使用索引的前缀。
以下WHERE子句使用索引:
... WHERE index_part1=1 AND index_part2=2 AND other_column=3/* index = 1 OR index = 2 */
... WHERE index=1 OR A=10 AND index=2/* optimized like "index_part1='hello'" */
... WHERE index_part1='hello' AND index_part3=5/* Can use index on index1 but not on index2 or index3 */
... WHERE index1=1 AND index2=2 OR index1=3 AND index3=3;这些WHERE子句不使用索引:
/* index_part1 is not used */
... WHERE index_part2=1 AND index_part3=2/* Index is not used in both parts of the WHERE clause */
... WHERE index=1 OR A=10/* No index spans all rows */
... WHERE index_part1=1 OR index_part2=10有时MySQL不使用索引,即使有可用的索引。发生这种情况的一种情况是,优化器估计使用索引需要MySQL访问表中很大比例的行。(在这种情况下,表扫描可能会更快,因为它需要更少的查找。)然而,如果这样的查询使用LIMIT只检索其中的一些行,MySQL无论如何都会使用索引,因为它可以更快地找到结果中返回的几行。
9.2 哈希索引特征
哈希索引的特性与刚才讨论的有些不同:
它们仅用于使用=或<=>运算符的相等性比较(但速度非常快)。它们不用于查找值范围的比较运算符,如<。依赖于这种类型的单值查找的系统被称为“键值存储”;要将MySQL用于此类应用程序,请尽可能使用哈希索引。
优化器不能使用哈希索引来加快ORDER BY操作的速度。(这种类型的索引不能用于按顺序搜索下一个条目。)
MySQL无法大致确定两个值之间有多少行(这是范围优化器用来决定使用哪个索引的)。如果将MyISAM或InnoDB表更改为哈希索引的MEMORY表,这可能会影响某些查询。
只有整排关键字才能用于搜索一行。(对于B-树索引,键的任何最左边的前缀都可以用来查找行。)
10 索引扩展的使用
InnoDB通过将主键列附加到每个辅助索引上来自动扩展它
CREATE TABLE t1 (i1 INT NOT NULL DEFAULT 0,i2 INT NOT NULL DEFAULT 0,d DATE DEFAULT NULL,PRIMARY KEY (i1, i2),INDEX k_d (d)
) ENGINE = InnoDB;该表定义了列(i1,i2)上的主键。它还在列(d)上定义了一个辅助索引k_d,但InnoDB在内部扩展了这个索引,并将其视为列(d,i1,i2)。
优化器在确定如何以及是否使用扩展的辅助索引时,会考虑该索引的主键列。这可以带来更高效的查询执行计划和更好的性能。
优化器可以将扩展的辅助索引用于ref、range和index_merge索引访问、松散索引扫描访问、联接和排序优化以及MIN()/MAX()优化。
以下示例显示了优化器是否使用扩展的二级索引对执行计划的影响。假设t1由以下行填充:
INSERT INTO t1 VALUES
(1, 1, '1998-01-01'), (1, 2, '1999-01-01'),
(1, 3, '2000-01-01'), (1, 4, '2001-01-01'),
(1, 5, '2002-01-01'), (2, 1, '1998-01-01'),
(2, 2, '1999-01-01'), (2, 3, '2000-01-01'),
(2, 4, '2001-01-01'), (2, 5, '2002-01-01'),
(3, 1, '1998-01-01'), (3, 2, '1999-01-01'),
(3, 3, '2000-01-01'), (3, 4, '2001-01-01'),
(3, 5, '2002-01-01'), (4, 1, '1998-01-01'),
(4, 2, '1999-01-01'), (4, 3, '2000-01-01'),
(4, 4, '2001-01-01'), (4, 5, '2002-01-01'),
(5, 1, '1998-01-01'), (5, 2, '1999-01-01'),
(5, 3, '2000-01-01'), (5, 4, '2001-01-01'),
(5, 5, '2002-01-01');现在考虑这个查询:
EXPLAIN SELECT COUNT(*) FROM t1 WHERE i1 = 3 AND d = '2000-01-01'执行计划取决于是否使用扩展索引。
当优化器不考虑索引扩展时,它只将索引k_d视为(d)。查询的EXPLAIN会产生以下结果:
mysql> EXPLAIN SELECT COUNT(*) FROM t1 WHERE i1 = 3 AND d = '2000-01-01'\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t1type: ref
possible_keys: PRIMARY,k_dkey: k_dkey_len: 4ref: constrows: 5Extra: Using where; Using index当优化器考虑索引扩展时,它将k_d视为(d,i1,i2)。在这种情况下,它可以使用最左边的索引前缀(d,i1)来生成更好的执行计划:
mysql> EXPLAIN SELECT COUNT(*) FROM t1 WHERE i1 = 3 AND d = '2000-01-01'\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t1type: ref
possible_keys: PRIMARY,k_dkey: k_dkey_len: 8ref: const,constrows: 1Extra: Using index当优化器考虑索引扩展时,它将k_d视为(d,i1,i2)。在这种情况下,它可以使用最左边的索引前缀。在这两种情况下,key表示优化器使用辅助索引k_d,但EXPLAIN输出显示了使用扩展索引的这些改进:
key_len从4个字节变为8个字节,这表明密钥查找使用的是列d和i1,而不仅仅是d。
ref值从const变为const,const是因为键查找使用了两个键部分,而不是一个。
行数从5减少到1,这表明InnoDB应该需要检查更少的行才能产生结果。
Extra值从Using where更改;使用索引到使用索引。这意味着可以仅使用索引读取行,而无需查询数据行中的列。
使用扩展索引时优化器行为的差异也可以从SHOW STATUS中看出:
FLUSH TABLE t1;
FLUSH STATUS;
SELECT COUNT(*) FROM t1 WHERE i1 = 3 AND d = '2000-01-01';
SHOW STATUS LIKE 'handler_read%'前面的语句包括用于刷新表缓存和清除状态计数器的FLUSH TABLES和FLUSH STATUS。
在没有索引扩展的情况下,SHOW STATUS会产生以下结果:
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Handler_read_first | 0 |
| Handler_read_key | 1 |
| Handler_read_last | 0 |
| Handler_read_next | 5 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 0 |
| Handler_read_rnd_next | 0 |
+-----------------------+-------+使用索引扩展,SHOW STATUS会产生此结果。Handler_read_next值从5减小到1,表示索引的使用效率更高:
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| Handler_read_first | 0 |
| Handler_read_key | 1 |
| Handler_read_last | 0 |
| Handler_read_next | 1 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 0 |
| Handler_read_rnd_next | 0 |
+-----------------------+-------+optimizer_switch系统变量的use_index_extensions标志允许控制优化器在确定如何使用InnoDB表的辅助索引时是否考虑主键列。默认情况下,会启用use_index_extensions。要检查禁用索引扩展是否可以提高性能,请使用以下语句:
SET optimizer_switch = 'use_index_extensions=off';优化器对索引扩展的使用受到索引中关键部分数量(16)和最大密钥长度(3072字节)的通常限制。
11 优化器使用生成的列索引
MySQL支持生成列上的索引。例如
CREATE TABLE t1 (f1 INT, gc INT AS (f1 + 1) STORED, INDEX (gc));生成的列gc被定义为表达式f1+1。列也会被索引,优化器可以在执行计划构建期间将该索引考虑在内。在下面的查询中,WHERE子句引用gc,优化器会考虑该列上的索引是否会产生更高效的计划:
SELECT * FROM t1 WHERE gc > 9;优化器可以使用生成列的索引来生成执行计划,即使在查询中没有按名称直接引用这些列的情况下也是如此。如果WHERE、ORDER BY或GROUP BY子句引用的表达式与某个索引生成列的定义匹配,就会发生这种情况。以下查询不直接引用gc,但使用了与gc定义匹配的表达式:
SELECT * FROM t1 WHERE f1 + 1 > 9;优化器识别出表达式f1+1与gc的定义匹配,并且gc已被索引,因此它在执行计划构建过程中会考虑该索引。您可以使用EXPLAIN看到这一点:
mysql> EXPLAIN SELECT * FROM t1 WHERE f1 + 1 > 9\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t1partitions: NULLtype: range
possible_keys: gckey: gckey_len: 5ref: NULLrows: 1filtered: 100.00Extra: Using index condition优化器识别出表达式f1+1与gc的定义匹配,并且gc已被索引,因此它在执行计划构建过程中会考虑该索引。您可以看到,实际上,优化器已将表达式f1+1替换为与该表达式匹配的生成列的名称。这在SHOW WARNINGS显示的扩展EXPLAIN信息中可用的重写查询中也很明显:
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************Level: NoteCode: 1003
Message: /* select#1 */ select `test`.`t1`.`f1` AS `f1`,`test`.`t1`.`gc`AS `gc` from `test`.`t1` where (`test`.`t1`.`gc` > 9)以下限制和条件适用于优化器使用生成的列索引:
要使查询表达式与生成的列定义匹配,该表达式必须相同,并且必须具有相同的结果类型。例如,如果生成的列表达式是f1+1,那么如果查询使用1+f1,或者f1+1(整数表达式)与字符串进行比较,优化器将无法识别匹配项。
优化适用于以下运算符:=、<、<=、>、>=、BETWEEN和IN()。
对于除BETWEEN和IN()之外的运算符,任一操作数都可以替换为匹配的生成列。对于BETWEEN和IN(),只有第一个参数可以替换为匹配的生成列,其他参数必须具有相同的结果类型。对于涉及JSON值的比较,还不支持BETWEEN和IN()。
生成的列必须定义为至少包含一个函数调用或前一项中提到的一个运算符的表达式。表达式不能由对另一列的简单引用组成。例如,gc INT AS(f1)STORED仅由列引用组成,因此不考虑gc上的索引。
为了将字符串与索引生成的列进行比较,这些列从返回带引号字符串的JSON函数中计算值,列定义中需要JSON_UNQUOTE()来删除函数值中的额外引号。(为了将字符串与函数结果直接进行比较,JSON比较器会处理引号删除,但索引查找不会出现这种情况。)例如,不要像这样编写列定义:
doc_name TEXT AS (JSON_EXTRACT(jdoc, '$.name')) STORED这样写:
doc_name TEXT AS (JSON_UNQUOTE(JSON_EXTRACT(jdoc, '$.name'))) STOREDdoc_name文本AS(JSON_UNQUOTE(JSON_EXTRACT(jdoc,'$.name'))已存储
使用后一种定义,优化器可以检测这两种比较的匹配:
... WHERE JSON_EXTRACT(jdoc, '$.name') = 'some_string' ... ... WHERE JSON_UNQUOTE(JSON_EXTRACT(jdoc, '$.name')) = 'some_string' ...如果列定义中没有JSON_UNQUOTE(),优化器将仅为这些比较中的第一个检测匹配。
如果优化器选择了错误的索引,则可以使用索引提示来禁用它,并强制优化器做出不同的选择。
12 不可见索引
MySQL支持不可见索引;即优化器未使用的索引。该功能适用于主键以外的索引(显式或隐式)。
默认情况下,索引是可见的。若要显式控制新索引的可见性,请使用VISIBLE或INVISIBLE关键字作为CREATE TABLE、CREATE index或ALTER TABLE的索引定义的一部分:
CREATE TABLE t1 (i INT,j INT,k INT,INDEX i_idx (i) INVISIBLE
) ENGINE = InnoDB;
CREATE INDEX j_idx ON t1 (j) INVISIBLE;
ALTER TABLE t1 ADD INDEX k_idx (k) INVISIBLE;若要更改现有索引的可见性,请将VISIBLE或INVISIBLE关键字与alter TABLE…一起使用。。。ALTER INDEX操作:
ALTER TABLE t1 ALTER INDEX i_idx INVISIBLE;
ALTER TABLE t1 ALTER INDEX i_idx VISIBLE;有关索引是可见还是不可见的信息可从Information Schema STATISTICS表或SHOW index输出中获得。例如
mysql> SELECT INDEX_NAME, IS_VISIBLEFROM INFORMATION_SCHEMA.STATISTICSWHERE TABLE_SCHEMA = 'db1' AND TABLE_NAME = 't1';
+------------+------------+
| INDEX_NAME | IS_VISIBLE |
+------------+------------+
| i_idx | YES |
| j_idx | NO |
| k_idx | NO |
+------------+------------+通过不可见索引,可以测试删除索引对查询性能的影响,而无需进行破坏性更改,如果需要索引,则必须撤消该更改。对于大表来说,删除和重新添加索引可能代价高昂,而使其不可见和可见是快速的就地操作。
如果优化器实际上需要或使用一个不可见的索引,有几种方法可以注意到它的缺失对表查询的影响:
对于包含引用不可见索引的索引提示的查询,会发生错误。
性能模式数据显示受影响查询的工作负载有所增加。
查询具有不同的EXPLAIN执行计划。
以前没有出现在慢速查询日志中的查询会出现在该日志中。
optimizer_switch系统变量的use_invisible_indexes标志控制优化器是否使用不可见索引来构建查询执行计划。如果标志关闭(默认设置),优化器将忽略不可见的索引(与引入此标志之前的行为相同)。如果该标志处于启用状态,则不可见索引保持不可见,但优化器会在构建执行计划时将其考虑在内。
使用SET_VAR优化器提示临时更新optimizer_switch的值,您可以仅在单个查询的持续时间内启用不可见索引,如下所示:
mysql> EXPLAIN SELECT /*+ SET_VAR(optimizer_switch = 'use_invisible_indexes=on') */> i, j FROM t1 WHERE j >= 50\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t1partitions: NULLtype: range
possible_keys: j_idxkey: j_idxkey_len: 5ref: NULLrows: 2filtered: 100.00Extra: Using index conditionmysql> EXPLAIN SELECT i, j FROM t1 WHERE j >= 50\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t1partitions: NULLtype: ALL
possible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: 5filtered: 33.33Extra: Using where索引可见性不影响索引维护。例如,根据表行的更改,索引将继续更新,而唯一索引可防止在列中插入重复项,无论该索引是可见还是不可见。
如果没有显式主键的表在NOT NULL列上具有任何UNIQUE索引,则该表可能仍然具有有效的隐式主键。在这种情况下,第一个这样的索引在表行上放置与显式主键相同的约束,并且不能使该索引不可见。考虑下表定义:
CREATE TABLE t2 (i INT NOT NULL,j INT NOT NULL,UNIQUE j_idx (j)
) ENGINE = InnoDB;该定义不包括显式主键,但NOT NULL列j上的索引对行的约束与主键相同,不能使其不可见:
mysql> ALTER TABLE t2 ALTER INDEX j_idx INVISIBLE;
ERROR 3522 (HY000): A primary key index cannot be invisible.现在假设表中添加了一个显式主键:
ALTER TABLE t2 ADD PRIMARY KEY (i);不能使显式主键不可见。此外,j上的唯一索引不再充当隐式主键,因此可以使其不可见:
mysql> ALTER TABLE t2 ALTER INDEX j_idx INVISIBLE;
Query OK, 0 rows affected (0.03 sec)13 降序索引
MySQL支持降序索引:索引定义中的DESC不再被忽略,而是按降序存储键值。以前,可以按相反的顺序扫描索引,但会降低性能。降序索引可以按前向顺序扫描,这样效率更高。当最有效的扫描顺序混合了某些列的升序和其他列的降序时,降序索引也使优化器可以使用多个列索引。
考虑下表定义,其中包含两列和四个两列索引定义,用于列上各种升序和降序索引的组合:
CREATE TABLE t (c1 INT, c2 INT,INDEX idx1 (c1 ASC, c2 ASC),INDEX idx2 (c1 ASC, c2 DESC),INDEX idx3 (c1 DESC, c2 ASC),INDEX idx4 (c1 DESC, c2 DESC)
);表定义产生了四个不同的索引。优化器可以对每个ORDER BY子句执行前向索引扫描,并且不需要使用文件排序操作:
ORDER BY c1 ASC, c2 ASC -- optimizer can use idx1
ORDER BY c1 DESC, c2 DESC -- optimizer can use idx4
ORDER BY c1 ASC, c2 DESC -- optimizer can use idx2
ORDER BY c1 DESC, c2 ASC -- optimizer can use idx3递减索引的使用受以下条件限制:
只有InnoDB存储引擎才支持降序索引,但有以下限制:
如果辅助索引包含降序索引键列或主键包含降序索引列,则不支持更改缓冲。
InnoDB SQL解析器不使用降序索引。对于InnoDB全文搜索,这意味着索引表的FTS_DOC_ID列上所需的索引不能定义为降序索引。有关更多信息,请参阅第17.6.2.4节“InnoDB全文索引”。
所有可使用升序索引的数据类型都支持降序索引。
普通列(非生成列)和生成列(虚拟列和存储列)都支持降序索引。
DISTINCT可以使用任何包含匹配列的索引,包括降序键部分。
具有降序键部分的索引不用于调用聚合函数但没有GROUP BY子句的查询的MIN()/MAX()优化。
BTREE支持降序索引,但不支持HASH索引。FULLTEXT或SPATIAL索引不支持降序索引。
为HASH、FULLTEXT和SPATIAL索引显式指定ASC和DESC指示符会导致错误。
您可以在EXPLAIN输出的Extra列中看到,优化器可以使用降序索引,如下所示:
mysql> CREATE TABLE t1 (-> a INT, -> b INT, -> INDEX a_desc_b_asc (a DESC, b ASC)-> );mysql> EXPLAIN SELECT * FROM t1 ORDER BY a ASC\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: t1partitions: NULLtype: index
possible_keys: NULLkey: a_desc_b_asckey_len: 10ref: NULLrows: 1filtered: 100.00Extra: Backward index scan; Using index在EXPLAIN FORMAT=TREE输出中,递减索引的使用通过在索引名称后面添加(reverse)来表示,如下所示:
mysql> EXPLAIN FORMAT=TREE SELECT * FROM t1 ORDER BY a ASC\G
*************************** 1. row ***************************
EXPLAIN: -> Index scan on t1 using a_desc_b_asc (reverse) (cost=0.35 rows=1)另请参阅EXPLAIN Extra信息。
14 TIMESTAMP列的索引查询
时间值作为UTC值存储在TIMESTAMP列中,插入TIMESTAMP和从TIMESTAMP中检索的值在会话时区和UTC之间转换。(这与CONVERT_TZ()函数执行的转换类型相同。如果会话时区是UTC,则实际上没有时区转换。)
由于当地时区更改的约定,如夏令时(DST),UTC和非UTC时区之间的转换并非双向一对一。不同的UTC值在另一个时区中可能不同。以下示例显示了在非UTC时区中变得相同的不同UTC值:
mysql> CREATE TABLE tstable (ts TIMESTAMP);
mysql> SET time_zone = 'UTC'; -- insert UTC values
mysql> INSERT INTO tstable VALUES('2018-10-28 00:30:00'),('2018-10-28 01:30:00');
mysql> SELECT ts FROM tstable;
+---------------------+
| ts |
+---------------------+
| 2018-10-28 00:30:00 |
| 2018-10-28 01:30:00 |
+---------------------+
mysql> SET time_zone = 'MET'; -- retrieve non-UTC values
mysql> SELECT ts FROM tstable;
+---------------------+
| ts |
+---------------------+
| 2018-10-28 02:30:00 |
| 2018-10-28 02:30:00 |
+---------------------+注意:
要使用命名时区,如“MET”或“欧洲/阿姆斯特丹”,必须正确设置时区表。
有关说明,请参阅“MySQL Server时区支持”。
您可以看到,当转换到“MET”时区时,两个不同的UTC值是相同的。对于给定的TIMESTAMP列查询,这种现象可能会导致不同的结果,这取决于优化器是否使用索引来执行查询。
假设查询使用WHERE子句从前面显示的表中选择值,以在ts列中搜索单个特定值,例如用户提供的时间戳文字:
SELECT ts FROM tstable
WHERE ts = 'literal';进一步假设查询在以下条件下执行:
会话时区不是UTC,而是夏令时。例如
SET time_zone = 'MET';由于夏令时的变化,存储在TIMESTAMP列中的唯一UTC值在会话时区中不是唯一的。(前面显示的示例说明了这种情况是如何发生的。)
查询指定一个搜索值,该搜索值在会话时区中输入DST的小时内。
在这些条件下,WHERE子句中的比较对于无索引查找和索引查找以不同的方式发生,并导致不同的结果:
如果没有索引或优化器无法使用索引,则会在会话时区中进行比较。优化器执行表扫描,检索每个ts列的值,将其从UTC转换为会话时区,并将其与搜索值(也在会话时区中进行解释)进行比较:
mysql> SELECT ts FROM tstableWHERE ts = '2018-10-28 02:30:00'; +---------------------+ | ts | +---------------------+ | 2018-10-28 02:30:00 | | 2018-10-28 02:30:00 | +---------------------+由于存储的ts值被转换为会话时区,因此查询可能返回两个时间戳值,这两个值与UTC值不同,但在会话时区中相等:一个值出现在时钟更改时的夏令时偏移之前,另一个值发生在夏令时偏移之后。
如果有可用的索引,则以UTC进行比较。优化器执行索引扫描,首先将搜索值从会话时区转换为UTC,然后将结果与UTC索引条目进行比较:
mysql> ALTER TABLE tstable ADD INDEX (ts); mysql> SELECT ts FROM tstableWHERE ts = '2018-10-28 02:30:00'; +---------------------+ | ts | +---------------------+ | 2018-10-28 02:30:00 | +---------------------+在这种情况下,(转换的)搜索值仅与索引条目匹配,并且由于不同存储的UTC值的索引条目也是不同的,因此搜索值只能与其中一个匹配。
由于非索引查找和索引查找的优化器操作不同,查询在每种情况下都会产生不同的结果。无索引查找的结果返回会话时区中匹配的所有值。索引查找无法执行以下操作:
它是在存储引擎中执行的,存储引擎只知道UTC值。
对于映射到同一UTC值的两个不同会话时区值,索引查找仅匹配相应的UTC索引条目,并且仅返回一行。
在前面的讨论中,存储在tstable中的数据集恰好由不同的UTC值组成。在这种情况下,所示形式的所有使用索引的查询最多匹配一个索引条目。
如果索引不是UNIQUE,则表(和索引)可能存储给定UTC值的多个实例。例如,ts列可能包含UTC值“2018-10-28 00:30:00”的多个实例。在这种情况下,使用查询的索引将返回它们中的每一个(在结果集中转换为MET值“2018-10-28 02:30:00”)。的确,使用索引的查询将转换后的搜索值与UTC索引条目中的单个值匹配,而不是与转换为会话时区中搜索值的多个UTC值匹配。
如果返回会话时区中匹配的所有ts值很重要,则解决方法是通过IGNORE index提示禁止使用索引:
mysql> SELECT ts FROM tstableIGNORE INDEX (ts)WHERE ts = '2018-10-28 02:30:00';
+---------------------+
| ts |
+---------------------+
| 2018-10-28 02:30:00 |
| 2018-10-28 02:30:00 |
+---------------------+对于两个方向的时区转换,同样缺乏一对一映射的情况也发生在其他上下文中,例如使用FROM_UNIXTIME()和UNIX_TIMESTAMP()函数执行的转换。参见第14.7节“日期和时间函数”。
相关文章:
)
【MySQL精通之路】索引优化(2)
目录 1 MySQL如何使用索引 2 主键优化 3 空间索引优化 4 外键优化 5 列索引 6 多列索引 7 验证索引使用情况 8 InnoDB和MyISAM索引统计集合 9 B树索引与哈希索引的比较 9.1 B-树索引特征 9.2 哈希索引特征 10 索引扩展的使用 11 优化器使用生成的列索引 12 不可见…...
:数组处理、计算属性与函数、class与Style绑定)
VUE3 学习笔记(5):数组处理、计算属性与函数、class与Style绑定
数组监测处理方法 VUE 提供了关于数组处理的直接方法,但并非全部都是可以处理的 如下可以直接处理: .push --向数组中增加 .pop --从数组中最后减去一个元素 .shift --从数组中第一个减去一个元素 .unshift --在数组中的头部添加一个元素 .splice --自定…...
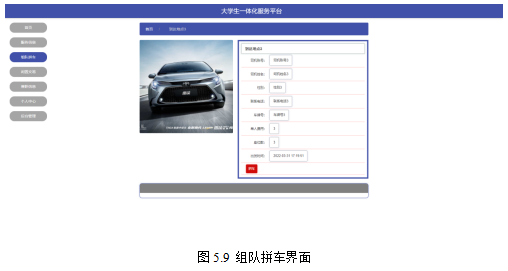
基于springboot实现大学生一体化服务平台系统项目【项目源码+论文说明】
基于springboot实现大学生一体化服务平台系统演示 摘要 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统大学生综…...

惠海 H6902B 升压恒流芯片 太阳能 风扇灯 应急灯 支持3.7V 5V 7.4V
惠海H6902B升压恒流驱动芯片是一款专为LED照明应用设计的驱动方案。该芯片具有多项产品特征,能够满足多种LED照明需求。 适用于多种电压输入范围(2.7V-80V)并具备效率(达95%以上)和工作频率(1MHzÿ…...
体验SmartEDA的高效与便捷,电子设计从未如此简单
SmartEDA:革新电子设计,让高效与便捷触手可及 在快节奏的现代生活中,科技日新月异,各行各业都在寻求更高效、更便捷的解决方案。对于电子设计行业而言,SmartEDA的出现,无疑是一场革命性的变革。它以其高效…...

LangChain笔记
很好的LLM知识博客: https://lilianweng.github.io/posts/2023-06-23-agent/ LangChain的prompt hub: https://smith.langchain.com/hub 一. Q&A 1. Q&A os.environ["OPENAI_API_KEY"] “OpenAI的KEY” # 把openai-key放到环境变量里&…...

金融序列的布朗运动
https://zhuanlan.zhihu.com/p/659164160 python金融衍生品定价系列之一 —— 布朗运动与伊藤公式 导语:网络上和书本上关于期权定价相关的内容已经较为丰富,但将理论和python代码结合起来讲的却很少,这也是python金融衍生品定价系列的写作初衷,在用python实现相关模型的同…...

利用ChatGPT辅助数学建模竞赛:理清思路、解题技巧与实战经验
导言 数学建模竞赛是许多学生在学术领域追求卓越的重要途径之一。然而,竞赛题目的复杂性常常让人望而生畏。在这样的情况下,利用人工智能工具,如ChatGPT,可以极大地辅助我们快速理清思路、解题技巧与实战经验。本文将探讨如何利用ChatGPT在数学建模竞赛中取得更好的成绩,…...

Java基础——Optional
Optional 类主要解决的问题是臭名昭著的空指针异常NPE(NullPointerException) 在 Java 8 之前,任何访问对象方法或属性的调用都可能导致 NullPointerException: String isocode user.getAddress().getCountry().getIsocode().to…...

Mask R-CNN实战
一、源码和数据集的准备 获取git开源项目代码 https://github.com/matterport/Mask_RCNN 一下载2.1的前三个文件,和2.0的第一个h5文件,coco.h5是预训练权重,也放入源码 项目文件结构如下: samples/logs:训练模型保存的位置 配置…...

02--SpringBoot自动装配原理
1、自动配置类读取原理 SpringBootApplication应用标注在某个类上,说明这个类是SpringBoot的主配置类,SpringBoot的项目需要运行这个类的main方法来启动SpringBoot应用的服务; 1.1 源码分析 Target(ElementType.TYPE) Retention(Retention…...

【加密与解密(第四版)】第十二章笔记
第十二章 注入技术 12.1 DLL注入方法 在通常情况下,程序加载 DLL的时机主要有以下3个:一是在进程创建阶段加载输入表中的DLL,即俗称的“静态输人”;二是通过调用 LoadLibrary(Ex)主动加载,称为“动态加载”;三是由于系…...

高并发幂等计数器【面试真题】
高并发幂等计数器【面试真题】 前言版权推荐高并发幂等计数器题目初想 最后 前言 2023-8-30 12:07:45 公开发布于 2024-5-22 00:09:47 以下内容源自《【面试真题】》 仅供学习交流使用 版权 禁止其他平台发布时删除以下此话 本文首次发布于CSDN平台 作者是CSDN日星月云 博…...
设计软件有哪些?建模和造型工具篇(3),渲染100邀请码1a12
这次我们接着介绍建模工具。 1、FloorGenerator FloorGenerator是由CG-Source开发的3ds Max插件,用于快速创建各种类型的地板和瓷砖。该插件提供了丰富的地板样式和布局选项,用户可以根据需要轻松创建木质地板、石板地板、砖瓦地板等不同风格的地面。F…...
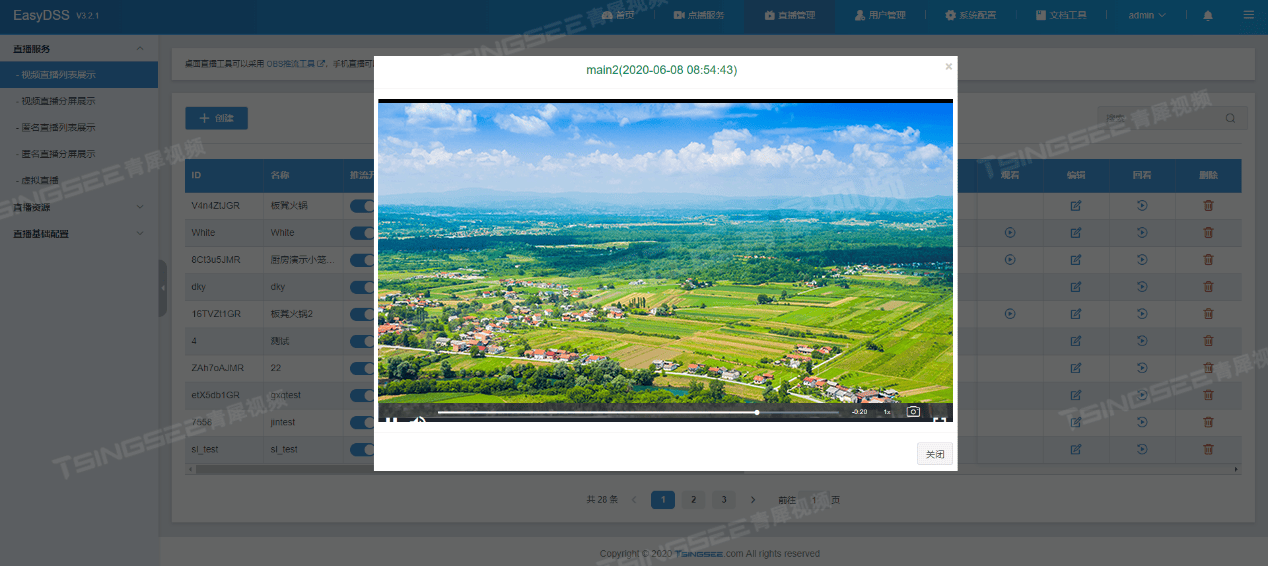
无人机+EasyDSS互联网视频平台:构建秸秆焚烧监控的“天眼”系统
一、方案背景 在每年的夏收时节,秸秆禁烧成为各地政府面临的一项重要任务。随着夏收季节的结束,大量农作物秸秆的处理问题逐渐凸显。一方面农作物种植面积辽阔,禁烧区域面积较大,监管巡逻人员的数量有限,无法全面顾及…...
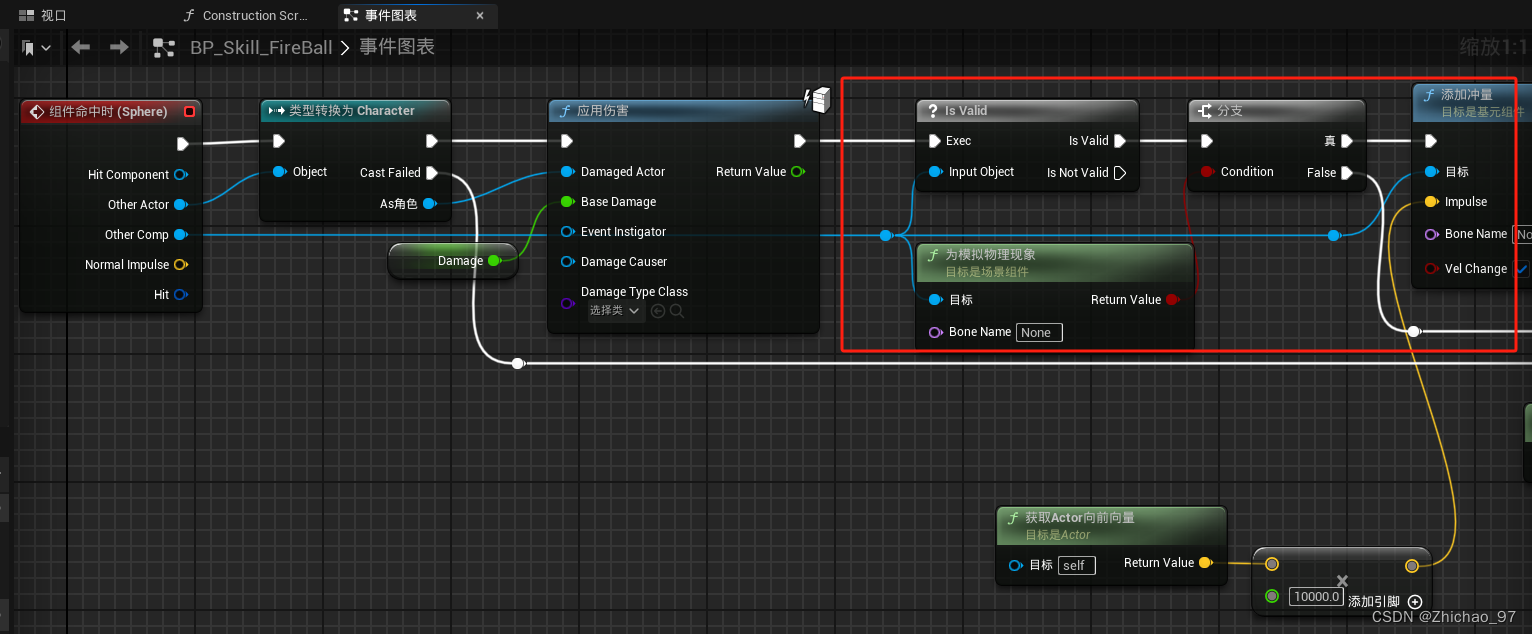
【UE5.1 角色练习】06-角色发射火球-part2
目录 效果 步骤 一、火球生命周期 二、添加可被伤害的NPC 三、添加冲量 在上一篇(【UE5.1 角色练习】06-角色发射火球-part1)基础上继续实现角色发射火球相关功能 效果 步骤 一、火球生命周期 为了防止火球没有命中任何物体而一直移动下去&#…...

多系统集成的项目周期为何普遍较长?
在现代企业的运营中,各种信息系统的集成已成为提升效率和竞争力的关键。然而,当工厂的ERP系统需要与MES、SRM、WMS、CRM等其他系统集成时,项目周期往往长达一年以上,这不仅耗费时间、人力和财力,还可能影响企业的正常运…...

【LaTex】11 ACM参考文献顺序引用 - 解决 ACM-Reference-Format 顺序不符合论文实际引用顺序的问题
【LaTex】11 ACM参考文献顺序引用 写在最前面解决 ACM-Reference-Format 顺序不符合论文实际引用顺序的问题问题描述问题原因如何解决问题解决方案1(更简单)解决方案2(更自由) 小结 🌈你好呀!我是 是Yu欸 …...

selenium 学习笔记(一)
pip的安装 新建一个txt curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py 把上面的代码复制进去后,把后缀名改为.bat然后双击运行 当前目录会出现一个这个文件 然后在命令行pyhon get-pip.py等它下好就可以了selenium安装 需要安装到工程目…...

Nginx-04-Docker Nginx
Docker Nginx 实战 HTTP 服务 Nginx 的最大作用,就是搭建一个 Web Server。 有了容器,只要一行命令,服务器就架设好了,完全不用配置。 运行官方 image $ docker container run \-d \-p 8080:80 \--rm \--name mynginx \nginx…...

如何告别模组管理噩梦:XXMI启动器的3个革命性解决方案
如何告别模组管理噩梦:XXMI启动器的3个革命性解决方案 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 你是否曾经为管理多个游戏的模组而感到头疼?每个游…...

TMS320VC5502PGF300:TI TMS320C55x系列定点DSP,300MHz,176-LQFP封装
TMS320VC5502PGF300:C55x低功耗DSP的300MHz经典音频处理方案在语音识别、音频编解码和通信基带处理等实时信号处理应用中,处理器的能效比(单位功耗下的算力)往往是系统设计的核心约束。高性能处理器虽然算力强劲,但较高…...

告别混淆!一文讲透 Flink State Backend 与 Checkpoint Storage
一、引言在 Flink 1.13 版本之前,StateBackend 接口是一个“大杂烩”,它同时负责两件事:状态的本地访问与存储(Task 运行时状态存在哪?内存还是 RocksDB?)Checkpoint 数据的持久化(做…...

Windows和Office激活终极指南:KMS_VL_ALL_AIO一键解决方案
Windows和Office激活终极指南:KMS_VL_ALL_AIO一键解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows和Office的激活问题烦恼吗?每次重装系统都要重新…...
2026)
郑州市科技局:科技成果汇编(第01册)2026
这份文档是郑州市科学技术局 2026 年发布的第 1 期科技成果汇编,共收录112 项优质科技成果,覆盖装备制造、环境治理、新材料、电子信息、新能源与节能、生物医药、粮油食品、其他八大核心领域,由郑州大学、华北水利水电大学、河南工业大学等高…...

长期使用Token Plan套餐在Taotoken平台带来的月度成本控制感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Token Plan套餐在Taotoken平台带来的月度成本控制感受 作为一名需要频繁调用大模型API进行项目开发的工程师,成…...

Chrome-Charset:3步彻底解决网页乱码问题,告别天书般的浏览体验![特殊字符]
Chrome-Charset:3步彻底解决网页乱码问题,告别天书般的浏览体验!🚀 【免费下载链接】Chrome-Charset An extension used to modify the page default encoding for Chromium 55 based browsers. 项目地址: https://gitcode.com/…...

如何快速在Windows上安装安卓应用?APK Installer的终极免费解决方案
如何快速在Windows上安装安卓应用?APK Installer的终极免费解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想在Windows电脑上运行安卓应用…...

HarmonyOS APP<<古今职鉴定>>开源教程第20篇:农历日期与节日计算
本篇学习农历算法,实现年俗内容的日期驱动图:农历日期与节日计算 的关键流程与实现要点。 学习目标 完成本篇后,你将能够: ✅ 理解农历算法原理✅ 实现公历转农历✅ 计算传统节日✅ 实现年俗日期匹配 预计学习时间 约 90 分钟…...

[全网首发]百万短剧CMS系统_支持全网网盘转存拉新
内容目录一、详细介绍二、效果展示1.部分代码2.效果图展示三、学习资料下载一、详细介绍 爱搜索正版管理系统安装教程 --------------------------------- 搭建要求环境如下 --------------------------------- 宝塔 --------------------------------- PHP7.2 Nginx 1.26.3 M…...