LangChain笔记
很好的LLM知识博客:
https://lilianweng.github.io/posts/2023-06-23-agent/
LangChain的prompt hub:
https://smith.langchain.com/hub
一. Q&A
1. Q&A
os.environ["OPENAI_API_KEY"] = “OpenAI的KEY” # 把openai-key放到环境变量里;
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4-0125-preview")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200) # 相邻chunk之间是200字符。(可以指定按照\n还是句号来分割)
splits = text_splitter.split_documents(docs) # 文档切块
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings()) # 使用openai的embedding来对文档做向量化;使用Chroma向量库;
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt") # 从hub上拉取现成的prompt
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
) # 用竖线"|"来串联起各个组件;
2. Chat history

用LangChain封装好的组件,把2个子chain连接在一起。
Query改写的目的:
Q1:"任务分解指的是什么?"
A: "..."
Q2: "它分为哪几步?"
有了Query改写,Q2可被改写为"任务分解分为哪几步?", 进而使用其作为query查询到有用的doc;
2.5 Serving
和FastAPI集成:
from fastapi import FastAPI
from langserve import add_routes# 4. Create chain
chain = prompt_template | model | parser# 4. App definition
app = FastAPI(title="LangChain Server",version="1.0",description="A simple API server using LangChain's Runnable interfaces",
)# 5. Adding chain routeadd_routes(app,chain,path="/chain",
)if __name__ == "__main__":import uvicornuvicorn.run(app, host="localhost", port=8000)3. Streaming
LangChain支持流式输出。
4.1 Wiki
langchain提供现成的Wikipedia数据库;已经向量化完毕封装在类里了。
from langchain_community.retrievers import WikipediaRetriever
wiki = WikipediaRetriever(top_k_results=6, doc_content_chars_max=2000)
4. Citation
让模型给出answer来自于context中docs的哪些片段。
可以在prompt里让模型给出answer的同时,也给出引用doc的id和文字片段。
例如:(注意"VERBATIM", 一字不差的)
You're a helpful AI assistant. Given a user question and some Wikipedia article snippets, \
answer the user question and provide citations. If none of the articles answer the question, just say you don't know.Remember, you must return both an answer and citations. A citation consists of a VERBATIM quote that \
justifies the answer and the ID of the quote article. Return a citation for every quote across all articles \
that justify the answer. Use the following format for your final output:<cited_answer><answer></answer><citations><citation><source_id></source_id><quote></quote></citation><citation><source_id></source_id><quote></quote></citation>...</citations>
</cited_answer>Here are the Wikipedia articles:{context}"""
prompt_3 = ChatPromptTemplate.from_messages([("system", system), ("human", "{question}")]
)所谓的tool,原理可能(我猜)也是tool封装了以上的改prompt方法。
也可以先调LLM给出answer,再调一次LLM给出citation。缺点是调用了2次LLM。
二. structured output
1. LangChain支持一种叫做Pydantic的语法,描述output:
from typing import Optional
from langchain_core.pydantic_v1 import BaseModel, Fieldclass Person(BaseModel):"""Information about a person."""# ^ Doc-string for the entity Person.# This doc-string is sent to the LLM as the description of the schema Person,# and it can help to improve extraction results.# Note that:# 1. Each field is an `optional` -- this allows the model to decline to extract it!# 2. Each field has a `description` -- this description is used by the LLM.# Having a good description can help improve extraction results.name: Optional[str] = Field(default=None, description="The name of the person")hair_color: Optional[str] = Field(default=None, description="The color of the peron's hair if known")height_in_meters: Optional[str] = Field(default=None, description="Height measured in meters")其中,加了"Optional"的,有则输出,无则不输出。
runnable = prompt | llm.with_structured_output(schema=Person)
text = "Alan Smith is 6 feet tall and has blond hair."
runnable.invoke({"text": text})
注意:该llm必须是支持该Pydantic和with_structured_output的模型才行。
输出结果:
Person(name='Alan Smith', hair_color='blond', height_in_meters='1.8288')
2. 提升效果的经验
- Set the model temperature to
0. (只拿最优解) - Improve the prompt. The prompt should be precise and to the point.
- Document the schema: Make sure the schema is documented to provide more information to the LLM.
- Provide reference examples! Diverse examples can help, including examples where nothing should be extracted. (Few shot例子!)
- If you have a lot of examples, use a retriever to retrieve the most relevant examples. (Few shot例子多些更好;正例和负例都要覆盖到,负例是指抽取不到所需字段的情况)
- Benchmark with the best available LLM/Chat Model (e.g., gpt-4, claude-3, etc) -- check with the model provider which one is the latest and greatest! (有的模型连结构化格式都经常输出得不对。。。最好专门用结构化输出来做训练,再用)
- If the schema is very large, try breaking it into multiple smaller schemas, run separate extractions and merge the results. (一次输出的格式,不能太复杂;否则要拆分)
- Make sure that the schema allows the model to REJECT extracting information. If it doesn't, the model will be forced to make up information! (提示模型,可以拒绝输出,不懂不要乱说)
- Add verification/correction steps (ask an LLM to correct or verify the results of the extraction). (用大模型或者代码或者人工来验证正确性,json load失败或不包含必要字段,则说明输出格式错误)
三. Chatbot
1. 有base model和chat model,一定要选用专门为chat做过训练的chat model!
2. 两处query改写:
带知识库检索的,要注意query改写,将类似"那是什么”中的"那"这种代词给替换掉,再去检索。
带memory的,也要query改写。
3. 精简memory的目的:A. 大模型context长度有限;B.删去对话历史中的无关内容,让大模型更聚焦在有用信息上。
memory总结用的prompt:
Distill the above chat messages into a single summary message. Include as many specific details as you can
4. 知识检索,要记得加上“不懂别乱说”:
If the context doesn't contain any relevant information to the question, don't make something up and just say "I don't know"
四. Tools&Agent
1. Agent:大模型来决定,这一步用什么tool(or 直接输出最终结果)以及入参;每一步都把上一步的输出和tool的输出作为历史信息。

2. LangChain支持自定义tool:
from langchain_core.tools import tool@tool
def multiply(first_int: int, second_int: int) -> int:"""Multiply two integers together."""return first_int * second_int注释很有用,告诉大模型该tool是干什么用的。
3. tool调用失败后的策略:
A. 给一个兜底LLM(GPT4等能力更强的模型),第一个模型失败后,调兜底模型再试。
B. 把tool入参和报错信息,放到prompt里,再调用一次(大模型很听话)。
"The last tool call raised an exception. Try calling the tool again with corrected arguments. Do not repeat mistakes."
五. query & analysis
1. 如果知识库是结构化/半结构化数据,可以把query输入大模型得到更合适的搜索query,例如{"query":"XXX", "publish_year":"2024"}
2. 一个复杂query,输入LLM,得到若干简单query;使用简单query查询知识库得到结果,合在一起,回答复杂query
帮助LLM理解如何去分解得到简单query? 答:给几个few-shot-examples;
3. "需要搜索则输出query,不需要搜索则直接输出回答"
4. 多个知识库:根据生成的query里的“库”字段,只查询相应的库;没必要所有库都查询;
相关文章:
LangChain笔记
很好的LLM知识博客: https://lilianweng.github.io/posts/2023-06-23-agent/ LangChain的prompt hub: https://smith.langchain.com/hub 一. Q&A 1. Q&A os.environ["OPENAI_API_KEY"] “OpenAI的KEY” # 把openai-key放到环境变量里&…...

金融序列的布朗运动
https://zhuanlan.zhihu.com/p/659164160 python金融衍生品定价系列之一 —— 布朗运动与伊藤公式 导语:网络上和书本上关于期权定价相关的内容已经较为丰富,但将理论和python代码结合起来讲的却很少,这也是python金融衍生品定价系列的写作初衷,在用python实现相关模型的同…...

利用ChatGPT辅助数学建模竞赛:理清思路、解题技巧与实战经验
导言 数学建模竞赛是许多学生在学术领域追求卓越的重要途径之一。然而,竞赛题目的复杂性常常让人望而生畏。在这样的情况下,利用人工智能工具,如ChatGPT,可以极大地辅助我们快速理清思路、解题技巧与实战经验。本文将探讨如何利用ChatGPT在数学建模竞赛中取得更好的成绩,…...

Java基础——Optional
Optional 类主要解决的问题是臭名昭著的空指针异常NPE(NullPointerException) 在 Java 8 之前,任何访问对象方法或属性的调用都可能导致 NullPointerException: String isocode user.getAddress().getCountry().getIsocode().to…...

Mask R-CNN实战
一、源码和数据集的准备 获取git开源项目代码 https://github.com/matterport/Mask_RCNN 一下载2.1的前三个文件,和2.0的第一个h5文件,coco.h5是预训练权重,也放入源码 项目文件结构如下: samples/logs:训练模型保存的位置 配置…...

02--SpringBoot自动装配原理
1、自动配置类读取原理 SpringBootApplication应用标注在某个类上,说明这个类是SpringBoot的主配置类,SpringBoot的项目需要运行这个类的main方法来启动SpringBoot应用的服务; 1.1 源码分析 Target(ElementType.TYPE) Retention(Retention…...

【加密与解密(第四版)】第十二章笔记
第十二章 注入技术 12.1 DLL注入方法 在通常情况下,程序加载 DLL的时机主要有以下3个:一是在进程创建阶段加载输入表中的DLL,即俗称的“静态输人”;二是通过调用 LoadLibrary(Ex)主动加载,称为“动态加载”;三是由于系…...

高并发幂等计数器【面试真题】
高并发幂等计数器【面试真题】 前言版权推荐高并发幂等计数器题目初想 最后 前言 2023-8-30 12:07:45 公开发布于 2024-5-22 00:09:47 以下内容源自《【面试真题】》 仅供学习交流使用 版权 禁止其他平台发布时删除以下此话 本文首次发布于CSDN平台 作者是CSDN日星月云 博…...
设计软件有哪些?建模和造型工具篇(3),渲染100邀请码1a12
这次我们接着介绍建模工具。 1、FloorGenerator FloorGenerator是由CG-Source开发的3ds Max插件,用于快速创建各种类型的地板和瓷砖。该插件提供了丰富的地板样式和布局选项,用户可以根据需要轻松创建木质地板、石板地板、砖瓦地板等不同风格的地面。F…...
无人机+EasyDSS互联网视频平台:构建秸秆焚烧监控的“天眼”系统
一、方案背景 在每年的夏收时节,秸秆禁烧成为各地政府面临的一项重要任务。随着夏收季节的结束,大量农作物秸秆的处理问题逐渐凸显。一方面农作物种植面积辽阔,禁烧区域面积较大,监管巡逻人员的数量有限,无法全面顾及…...
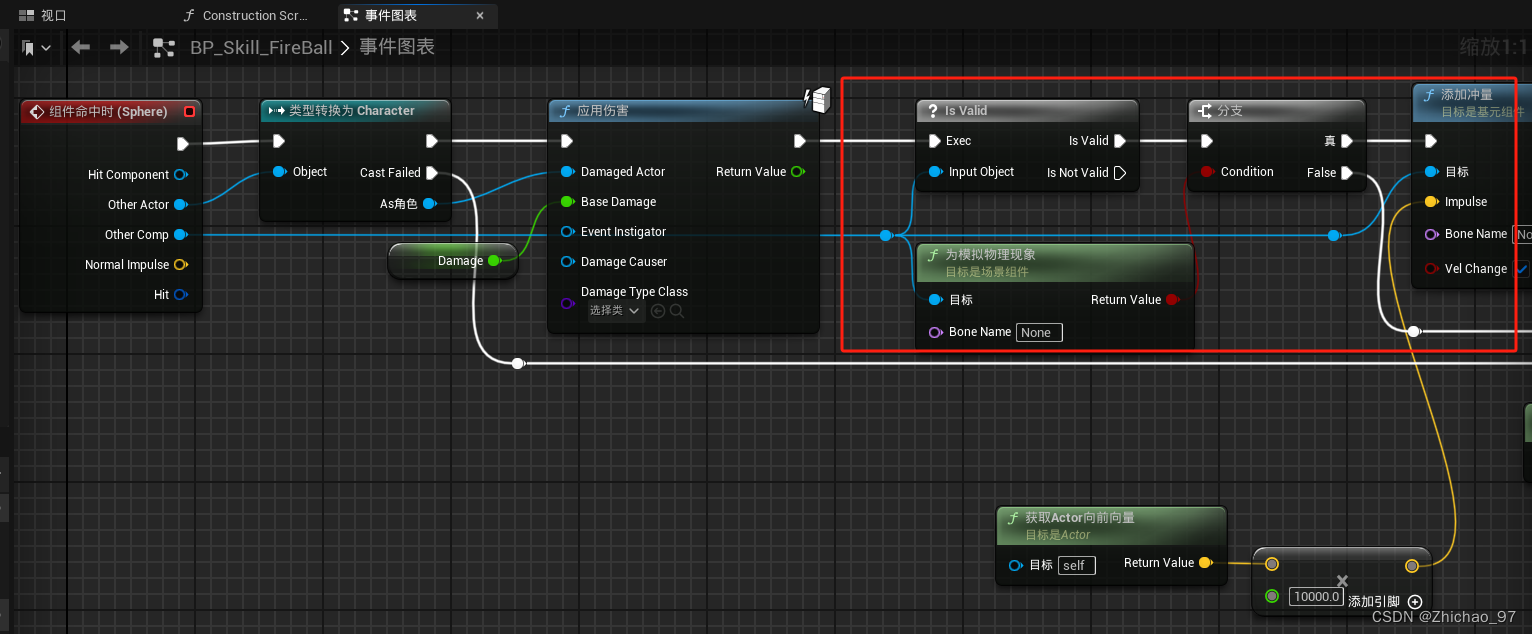
【UE5.1 角色练习】06-角色发射火球-part2
目录 效果 步骤 一、火球生命周期 二、添加可被伤害的NPC 三、添加冲量 在上一篇(【UE5.1 角色练习】06-角色发射火球-part1)基础上继续实现角色发射火球相关功能 效果 步骤 一、火球生命周期 为了防止火球没有命中任何物体而一直移动下去&#…...

多系统集成的项目周期为何普遍较长?
在现代企业的运营中,各种信息系统的集成已成为提升效率和竞争力的关键。然而,当工厂的ERP系统需要与MES、SRM、WMS、CRM等其他系统集成时,项目周期往往长达一年以上,这不仅耗费时间、人力和财力,还可能影响企业的正常运…...

【LaTex】11 ACM参考文献顺序引用 - 解决 ACM-Reference-Format 顺序不符合论文实际引用顺序的问题
【LaTex】11 ACM参考文献顺序引用 写在最前面解决 ACM-Reference-Format 顺序不符合论文实际引用顺序的问题问题描述问题原因如何解决问题解决方案1(更简单)解决方案2(更自由) 小结 🌈你好呀!我是 是Yu欸 …...

selenium 学习笔记(一)
pip的安装 新建一个txt curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py 把上面的代码复制进去后,把后缀名改为.bat然后双击运行 当前目录会出现一个这个文件 然后在命令行pyhon get-pip.py等它下好就可以了selenium安装 需要安装到工程目…...

Nginx-04-Docker Nginx
Docker Nginx 实战 HTTP 服务 Nginx 的最大作用,就是搭建一个 Web Server。 有了容器,只要一行命令,服务器就架设好了,完全不用配置。 运行官方 image $ docker container run \-d \-p 8080:80 \--rm \--name mynginx \nginx…...

Rust一维Vec垂直方向拼接、水平方向拼接,多个二维Vec垂直方向拼接
1.在Rust中,拼接二维Vec通常意味着将多个一维Vec组合成一个二维Vec。假设你想要将多个Vec<T>拼接成一个Vec<Vec<T>>,你可以使用迭代器方法来实现。 下面是一个示例,演示如何将多个一维Vec拼接成一个二维Vec: …...

低代码与人工智能:改变软件开发的未来
引言 在当今快速发展的科技时代,软件开发行业也在不断地创新和演进。其中,低代码开发和人工智能技术是两个备受关注的领域,低代码开发通过简化开发流程和降低编码难度,使得软件开发变得更加高效和便捷,而人工智能技术…...

第三方软件检测机构要具备哪些资质要求?专业测试报告如何申请?
第三方软件检测机构是独立于软件开发商和用户之外的公正机构,负责对软件进行全面的检测和评估。其独立性保证了评测结果的客观性和公正性,有效避免了软件开发商对自身产品的主观偏见和误导。 要成为一家合格的第三方软件检测机构,需要具备一…...

快团团帮卖团长怎么对供货大团长进行评分?
都说帮卖“躺赚”? 一旦遇团不淑,惨遭不靠谱团长挖坑,售后拖延、发货慢、产品瑕疵…… 加上顾客夺命连环催,双面夹击,夹缝生存。供货团长靠不靠谱太重要了! 快团团供货团长评分系统上线! 帮卖团…...
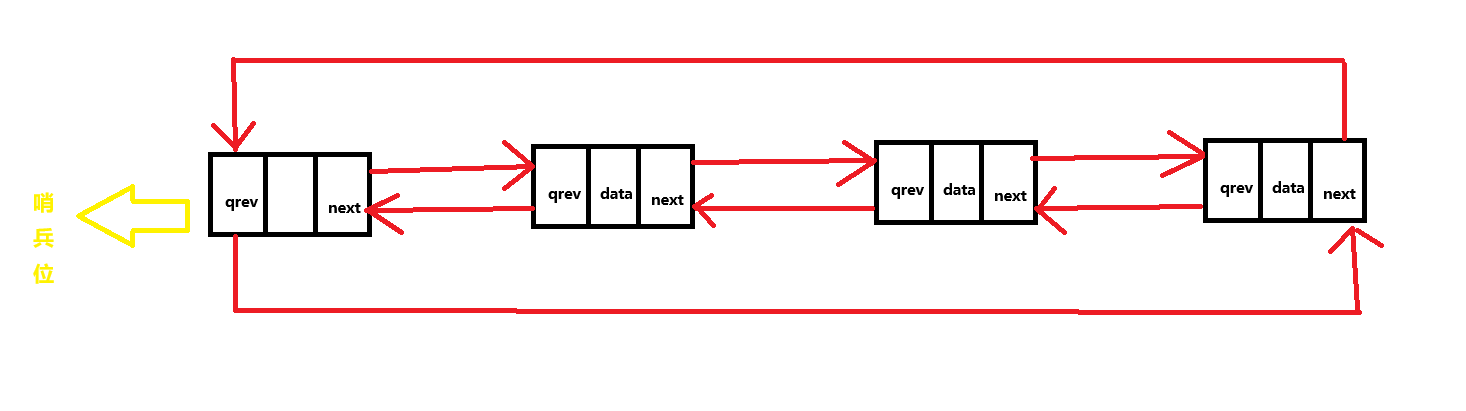
双向带头链表实现
目录 一. 逻辑结构图解 1. 节点中存储的值 2.逻辑实现 二. 各种功能实现 1. 创建节点函数 2. 初始化哨兵位 3. 尾插 4. 头插 5. 尾删 6. 头删 7. 打印链表值 8. 查找数据,返回节点地址 9. 指定地址后插入节点 10. 删除指定地址节点 11. 销毁链表 三.…...

万用表档位介绍与测量
万用表档位介绍与测量一:万用表档位介绍二:表笔的连接三:电阻测量(Ω)四:电流测量注意事项:1、测电流一定是串联,绝对不能直接把表笔搭在电源两极!一搭就烧表、炸保险。2…...

Servlet 容器 vs Spring 容器 超详细对比
目录 一、先搞懂两个容器本质 1. Servlet 容器(Web 容器) 2. Spring 容器(IoC 容器) 二、核心相同点 三、核心不同点(重点) 四、最直白通俗理解 五、Web 项目完整启动顺序(必背面试题) 容器层级关系 六、请求处理流程差异 1. 原生 Servlet 模式(只有 Servle…...

别再让治具压坏你的板子!手把手教你用TSK-64应力测试仪搞定ICT/FCT应力管控
从应力失控到精准管控:TSK-64测试仪在ICT/FCT产线的实战指南 当产线突然出现批量PCBA功能异常时,多数工程师的第一反应是检查焊接质量或元器件性能,却往往忽略了治具施加的机械应力这个"隐形杀手"。某汽车电子制造商曾因FCT治具压力…...

LiveSplit深度解析:构建专业级速度跑计时系统的核心技术架构
LiveSplit深度解析:构建专业级速度跑计时系统的核心技术架构 【免费下载链接】LiveSplit A sleek, highly customizable timer for speedrunners. 项目地址: https://gitcode.com/gh_mirrors/li/LiveSplit LiveSplit是一款为速度跑者设计的专业级计时软件&am…...

XXMI启动器:一站式二次元游戏模组管理终极指南,轻松管理热门游戏模组
XXMI启动器:一站式二次元游戏模组管理终极指南,轻松管理热门游戏模组 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher XXMI启动器是一款功能强大的开源游戏…...

如何在5分钟内免费安装DeepL Chrome翻译插件:终极指南
如何在5分钟内免费安装DeepL Chrome翻译插件:终极指南 【免费下载链接】deepl-chrome-extension A DeepL Translator Chrome extension 项目地址: https://gitcode.com/gh_mirrors/de/deepl-chrome-extension 你是否厌倦了生硬的机器翻译?想要在浏…...

SpringbootWeb【入门】+Mysql【安装】
今天这个是很重要的先从认识spring开始后面认识springboot 这是www.spring.io官网 这就是创说中的spring全家桶 打开idea创建一个Sringboot工程出来 这就创建好了 现在开始装Mysql【安装】 MySQL :: Download MySQL Community Serverhttps://dev.mysql.com/downloads/m…...

如何在GTA5在线模式中保护自己?YimMenu安全增强菜单完整指南
如何在GTA5在线模式中保护自己?YimMenu安全增强菜单完整指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/y…...

UVa 259 Software Allocation
题目分析 一个计算中心有 101010 台不同的计算机(编号 000 至 999),每台计算机在同一时间只能运行一个应用程序。有 262626 种应用程序,名称分别为 A\texttt{A}A 至 Z\texttt{Z}Z。每天会有用户提交应用程序,同一个应用…...

【更新 v 2.7.5 版本】桌面版 Open Claw 本地一键部署指南
✨ 核心亮点 零代码门槛|全程可视化|无需手动配环境|内置所有依赖|28 万 Tokens 额度 🔗 下载地址 https://xiake.yun/api/download/package/16?promoCodeIV8E496E2F7A 📝 前言 开源圈热门的「数字员…...