自动化您的任务——crewAI 初学者教程

今天,我写这篇文章是为了分享您开始使用一个非常流行的多智能体框架所需了解的所有信息:crewAI。 我将在这里或那里跳过一些内容,使本教程成为一个精炼的教程,概述帮助您入门的关键概念和要点
今天,我写这篇文章是为了分享您开始使用一个非常流行的多智能体框架所需了解的所有信息:crewAI。 我将在这里或那里跳过一些内容,使本教程成为一个精炼的教程,概述帮助您入门的关键概念和要点。
什么是crewAI?
crewAI 是由 João Moura 创建的框架。 它旨在建立一个人工智能代理团队,共同完成任务。 它建立在LangChain之上,并提供直观易用的API。
为什么我需要AI代理?
假设您是一名博主,花费大量时间研究和撰写内容。 您能否自动化该过程并节省无数时间?
或者,您可能是 SEO 专家,并且浪费时间生成和解释报告。 有没有办法自动执行此操作,以便您可以专注于 SEO 的战略方面?
这两个问题的答案都是:是的,有。
在婴儿期,代理由于其效率和速度而有潜力取代人类在现实世界中完成的许多流程。
核心crewAI组件
我们将讨论crewAI 最重要的组成部分。 以下是我们将要介绍的内容的细分:
- Agents
- Tasks
- Tools
- Crews (and Processes)
现在,如果我将以上几点放在一个句子中来解释它们是如何联系在一起的,那么这句话将是这样的:
Crews, made up of Agents perform Tasks using Tools by following Processes. *
无法将内存组件放入该句子中 - 如果可以,请在评论中分享!
认识 crewAI
假设您是一位博主(像我一样),希望优化您的促销后流程。 为了简单起见,我们假设这是一个 3 步过程,如下所示:
- 获取博客上的最新帖子。
- 根据该帖子写一条推文。
- 根据帖子撰写新闻通讯电子邮件。
现在我将向您展示crewAI 如何帮助我在几秒钟内(而不是通常需要几分钟或几小时)实现上述目标。
crewAI 中的代理
代理一起工作,每个代理使用一种或多种工具为团队做出贡献,以解决共同的目标。
如果我们回到我们的示例,我们将需要创建两个代理。 第一个将从我的博客中提取最新帖子,然后第二个将使用该内容将其转换为 Twitter(或 X)帖子和时事通讯电子邮件。
好吧,太酷了 - 让我们看看第一个代理在 Python 中是什么样子的:
from crewai import Agent...extractor = Agent(role='Content Retriever',goal='Given a URL you will retrieve the content.',backstory='''As an expert at retrieving complete and accurateinformation, you are responsible for presenting the content of webpagesthat will be used to create engaging content for twitter and a newsletter.''',verbose=True
)第二个:
writer = Agent(role='Content Writer',goal='You are responsible to transforming long text into engaging content ready for promotion on different channels.',backstory="""You are an excellent communications specialist, known for yourexceptional skill of transforming complex subject into easy tounderstand stories that attract people.""",verbose=True
)- role 属性指定代理的功能。
- goal 属性指定代理必须实现的目标。
- backstory 属性为代理的身份和行为添加了上下文。
代理属性
要创建代理,您通常需要使用所需的属性初始化 Agent 类的实例。 这是一个包含所有属性的概念示例:
# Example: Creating an agent with all attributes
from crewai import Agentagent = Agent(role='Data Analyst',goal='Extract actionable insights',backstory="""You're a data analyst at a large company.You're responsible for analyzing data and providing insightsto the business.You're currently working on a project to analyze theperformance of our marketing campaigns.""",tools=[my_tool1, my_tool2], # Optional, defaults to an empty listllm=my_llm, # Optionalfunction_calling_llm=my_llm, # Optionalmax_iter=15, # Optionalmax_rpm=None, # Optionalverbose=True, # Optionalallow_delegation=True, # Optionalstep_callback=my_intermediate_step_callback, # Optionalcache=True # Optional
)这就是创建代理所需了解的全部内容。 现在让我们分配任务。
crewAI 中的任务
任务是代理所做的事情。 任务至少由描述、预期输出以及对将执行该任务的代理的引用组成。
在我们的例子中,我们需要执行以下任务:
任务 1:从博客中获取内容
任务 2:根据内容撰写推文
任务3:根据内容撰写新闻通讯
任务 1 和 writer 代理将负责处理,并且由于代理可以执行多个任务,因此我们将把任务 2 和 3 分配给我们的 extractor。
我们将从任务 1 开始:fetch
from crewai import Task...fetch = Task(description=f'''Given a URL, retrieve the content of the webpage.It is important that you do not miss any information.Make sure that:- The content does not include html, css, or javascript.- The content is complete and accurate.- You do not include headers, footers, or sidebars.''',agent=extractor, expected_output='''Title: [The title of the article]Author: [The author of the article]Date: [The date the article was published]Content: [The content of the article]'''
)任务 2 如下所示:
twitterize = Task(description='''Given a long text, transform it into engaging content ready for promotion on Twitter.Make sure that:- The content is engaging and informative.- The content is less than 280 characters.- The content includes relevant hashtags - Limit to one.''',agent=writer,expected_output='''Title: [Engaging catchy title for the tweet]Content: [Engaging content for the tweet]'''
)最后,任务3与twitterize比较相似。 您可以自己创建它,或者您可以在本文底部免费获取源代码。
嗯不错! 现在您知道什么是任务以及它们如何工作。下一个:工具。
有关可用任务参数和选项的完整列表
任务属性
| 属性 | 描述 |
|---|---|
| Description | 清晰、简洁地说明任务的内容。 |
| Agent | 负责任务的代理,直接分配或由机组人员的进程分配。 |
| Expected Output | 任务完成情况的详细描述。 |
| Tools(可选) | 代理可以用来执行任务的功能或能力。 |
| Async Execution(可选) | 如果设置,任务将异步执行,无需等待完成即可继续进行。 |
| Context (可选) | 指定其输出用作该任务上下文的任务。 |
| Config(可选) | 执行任务的代理的其他配置详细信息,允许进一步定制。 |
| Output JSON (可选) | 输出 JSON 对象,需要 OpenAI 客户端。 只能设置一种输出格式。 |
| Output Pydantic (可选) | 输出 Pydantic 模型对象,需要 OpenAI 客户端。 只能设置一种输出格式。 |
| Output File (可选) | 将任务输出保存到文件中。 如果与输出 JSON 或输出 Pydantic 一起使用,指定如何保存输出。 |
| Callback(可选) | 一个 Python 可调用函数,在完成后使用任务的输出执行。 |
| Human Input (可选) | 指示任务最后是否需要人工反馈,这对于需要人工监督的任务很有用。 |
使用工具创建任务
import os
os.environ["OPENAI_API_KEY"] = "Your Key"
os.environ["SERPER_API_KEY"] = "Your Key" # serper.dev API keyfrom crewai import Agent, Task, Crew
from crewai_tools import SerperDevToolresearch_agent = Agent(role='Researcher',goal='Find and summarize the latest AI news',backstory="""You're a researcher at a large company.You're responsible for analyzing data and providing insightsto the business.""",verbose=True
)search_tool = SerperDevTool()task = Task(description='Find and summarize the latest AI news',expected_output='A bullet list summary of the top 5 most important AI news',agent=research_agent,tools=[search_tool]
)crew = Crew(agents=[research_agent],tasks=[task],verbose=2
)result = crew.kickoff()
print(result)crewAI工具
正如您所看到的,我们的提取器代理的任务是从给定的 URL 中提取信息。 但如何呢?
提示:通过使用工具。
在crewAI中,您可以通过三种方式使用工具:
- 自定义工具:您自己编写的工具,本质上是一个 Python 函数。
- 内置工具:crewAI 附带了许多内置工具。
- LangChain工具:由于crewAI是建立在LangChain之上的,因此您也将获得LangChain的所有好东西。
对于我们的示例,有很多现有工具可以帮助我们从博客中提取信息。 此类工具之一是内置于crewAI 中的ScrapeWebsiteTool。 所以在这种情况下,我们不需要自己构建。
要使用它,我们只需将它传递到提取器使用的工具列表中,如下所示:
from crewai_tools import ScrapeWebsiteToolsite_url = 'https://www.gettingstarted.ai/crewai-beginners-tutorial
scrape_tool = ScrapeWebsiteTool(url=site_url)extractor = Agent(...tools=[scrape_tool] # <----...
)确保使用 pip 安装可选工具包:
pip install crewai[tools]太酷了 - 我们快完成了,这意味着您快成为超级巨星了!
crewAI crews
现在我们已经定义了任务、工具和代理。 我们必须将它们全部分组,以便它们一起工作。 这就是我们定义工作人员的地方,但在此之前 - 让我解释一下特工如何一起工作。
crew 流程
现在您知道船员是由特工组成的。 但这些代理必须知道如何相互交谈,比如由哪一个发起对话。 在crewAI 中,有两个受支持的流程,第三个流程即将推出。 目前的流程是:
- 顺序:一项接着一项任务,有秩序地进行。
- 分层:经理将协调对话流程。
由于我们的任务可以按顺序完成,因此我们将采用顺序流程。
我们开始做吧:
from crewai import Crew...crew = Crew(agents=[extractor, writer],tasks=[fetch, twitterize, newsletterize],Process=Process.sequential
)这就是全部,非常简单,不是吗?
最后,我们调用 kickoff() 方法来设置一切:
result = crew.kickoff()print("#### USAGE ####")
print (crew.usage_metrics) # <-- Optionalprint("#### RESULT ####")
print(result)快速仅供参考:usage_metrics 函数返回一个很好的执行摘要,如下所示: Crew use {'total_tokens': 65002, 'prompt_tokens': 55305, 'completion_tokens': 9697, 'successful_requests': 67}
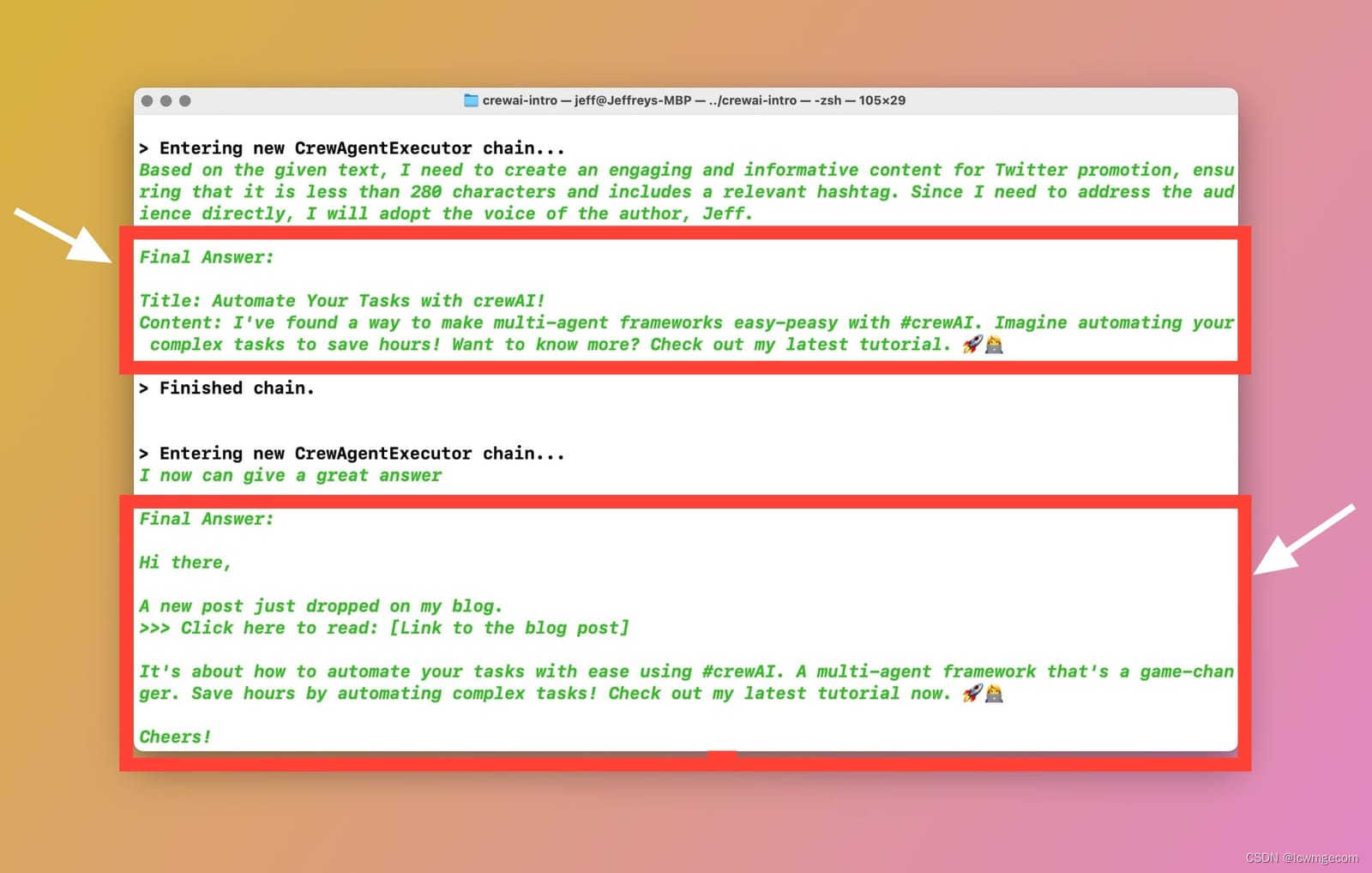
结论和想法
老实说,crewAI 的美妙之处无疑在于其简单的结构。 您可以添加另一个代理,负责在 Twitter 上发布消息并向您的订阅者发送电子邮件。
您可以通过利用工具来完成此操作,可以使用现有工具,也可以创建自己的与第三方 API 的集成。
现在,如果您正在使用 OpenAI 或其他付费 LLM 服务,我建议您密切关注计费仪表板,因为代理往往会消耗大量代币,例如,本教程中的工作人员运行一次的成本约为 0.90 美元。
Agent 会取代人类团队吗? 是的,也不是?
是的,如果您或您的公司能够以更少的成本更快地取得成果,您会不会这么做吗?
相关文章:
自动化您的任务——crewAI 初学者教程
今天,我写这篇文章是为了分享您开始使用一个非常流行的多智能体框架所需了解的所有信息:crewAI。 我将在这里或那里跳过一些内容,使本教程成为一个精炼的教程,概述帮助您入门的关键概念和要点 今天,我写这篇文章是为了…...
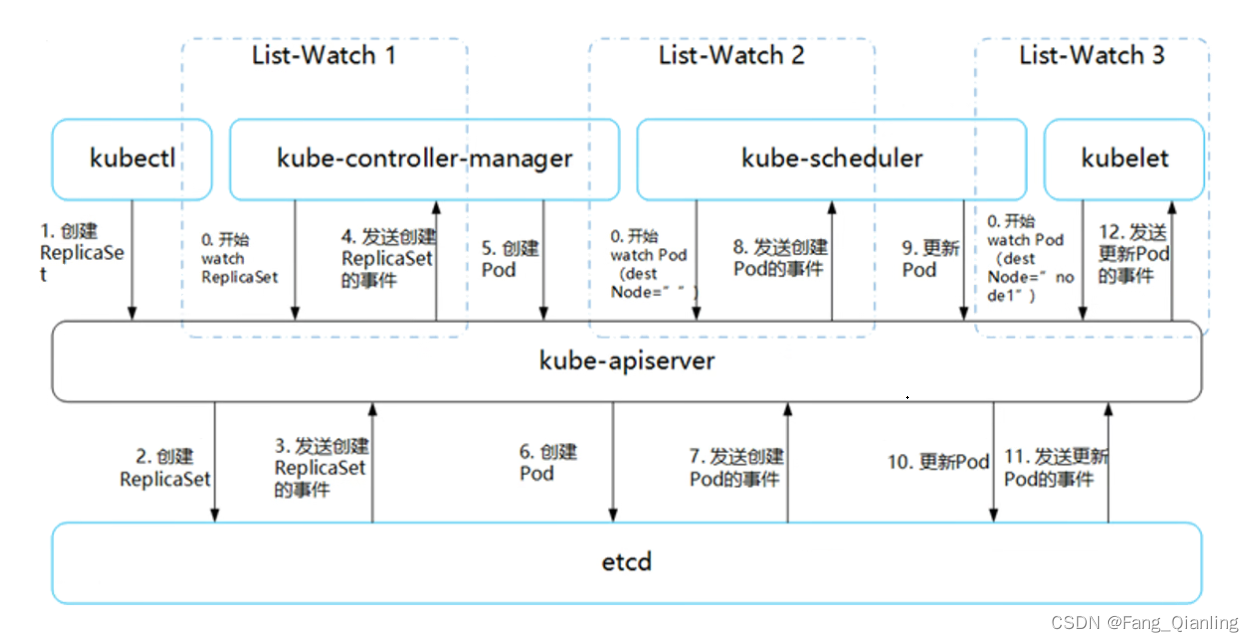
K8s集群中的Pod调度约束亲和性与反亲和性
前言 在 K8s 集群管理中,Pod 的调度约束——亲和性(Affinity)与反亲和性(Anti-Affinity)这两种机制允许管理员精细控制 Pod 在集群内的分布方式,以适应多样化的业务需求和运维策略。本篇将介绍 K8s 集群中…...

kafka之consumer参数auto.offset.reset
Kafka的auto.offset.reset 参数是用于指定消费者在启动时如何处理偏移量(offset)的。这个参数有三个主要的取值:earliest、latest和none。 earliest: 当各分区下有已提交的offset时,从提交的offset开始消费;…...
回答篇二:测试开发高频面试题目
引用之前文章:测试开发高频面试题目 本篇文章是回答篇(持续更新中) 1. 在测试开发中使用哪些自动化测试工具和框架?介绍一下你对其中一个工具或框架的经验。 a. 测试中经常是用的自动化测试工具和框架有Selenium、Pytest、Postman…...
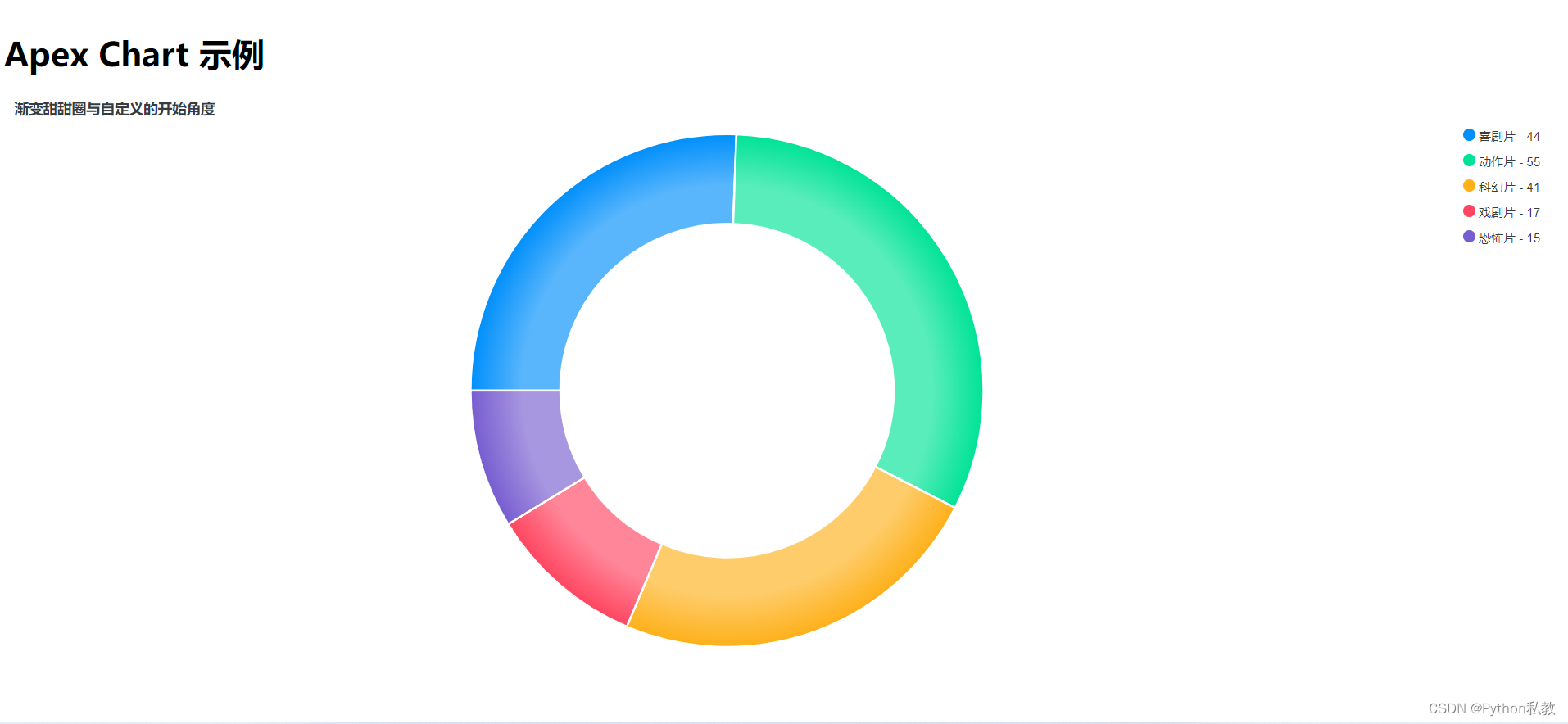
React18 apexcharts数据可视化之甜甜圈图
03 甜甜圈图 apexcharts数据可视化之甜甜圈图。 有完整配套的Python后端代码。 本教程主要会介绍如下图形绘制方式: 基本甜甜圈图个性图案的甜甜圈图渐变色的甜甜圈图 面包圈 import ApexChart from react-apexcharts;export function DonutUpdate() {// 数据…...

如何通过OpenHarmony的音频模块实现录音变速功能?
简介 OpenAtom OpenHarmony(以下简称“OpenHarmony”)是由开放原子开源基金会孵化及运营的开源项目,是面向全场景、全连接、全智能时代的智能物联网操作系统。 多媒体子系统是OpenHarmony系统中的核心子系统,为系统提供了相机、…...

探索 Rust 语言的精髓:深入 Rust 标准库
探索 Rust 语言的精髓:深入 Rust 标准库 Rust,这门现代编程语言以其内存安全、并发性和性能优势而闻名。它不仅在系统编程领域展现出强大的能力,也越来越多地被应用于WebAssembly、嵌入式系统、分布式服务等众多领域。Rust 的成功࿰…...
Log360:护航安全,远离暗网风险
暗网有时候就像是一个神秘的地下世界,是互联网的隐蔽角落,没有任何规则。这是一个被盗数据交易、网络犯罪分子策划下一步攻击的地方。但仅仅因为它黑暗,不意味着你要对潜在的威胁视而不见。 暗网 这就是ManageEngine Log360的用武之地&…...

react使用antd警告:Warning: findDOMNode is deprecated in StrictMode.
警告信息: Warning: findDOMNode is deprecated in StrictMode. findDOMNode was passed an instance of DOMWrap which is inside StrictMode. Instead, add a ref directly to the element you want to reference. Learn more about using refs safely here: htt…...

Docker Swarm - 删除 worker 节点
1、前提:集群环境已经运行 在manager节点上执行: # 查看节点信息 >>> docker node lsID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION jr06s8pbrclkrxt7jpy7wae8t * iZ2ze78653g2…...
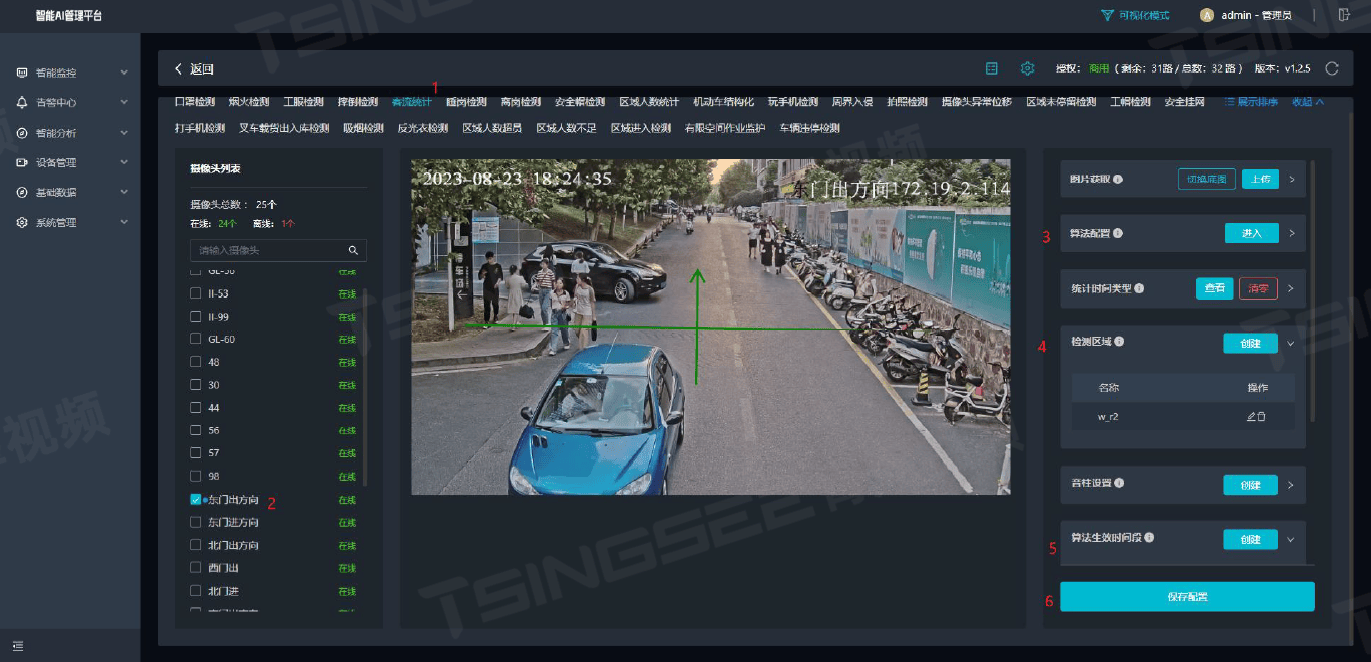
AI视频智能分析技术赋能营业厅:智慧化管理与效率新突破
一、方案背景 随着信息技术的快速发展,图像和视频分析技术已广泛应用于各行各业,特别是在营业厅场景中,该技术能够有效提升服务质量、优化客户体验,并提高安全保障水平。TSINGSEE青犀智慧营业厅视频管理方案旨在探讨视频监控和视…...
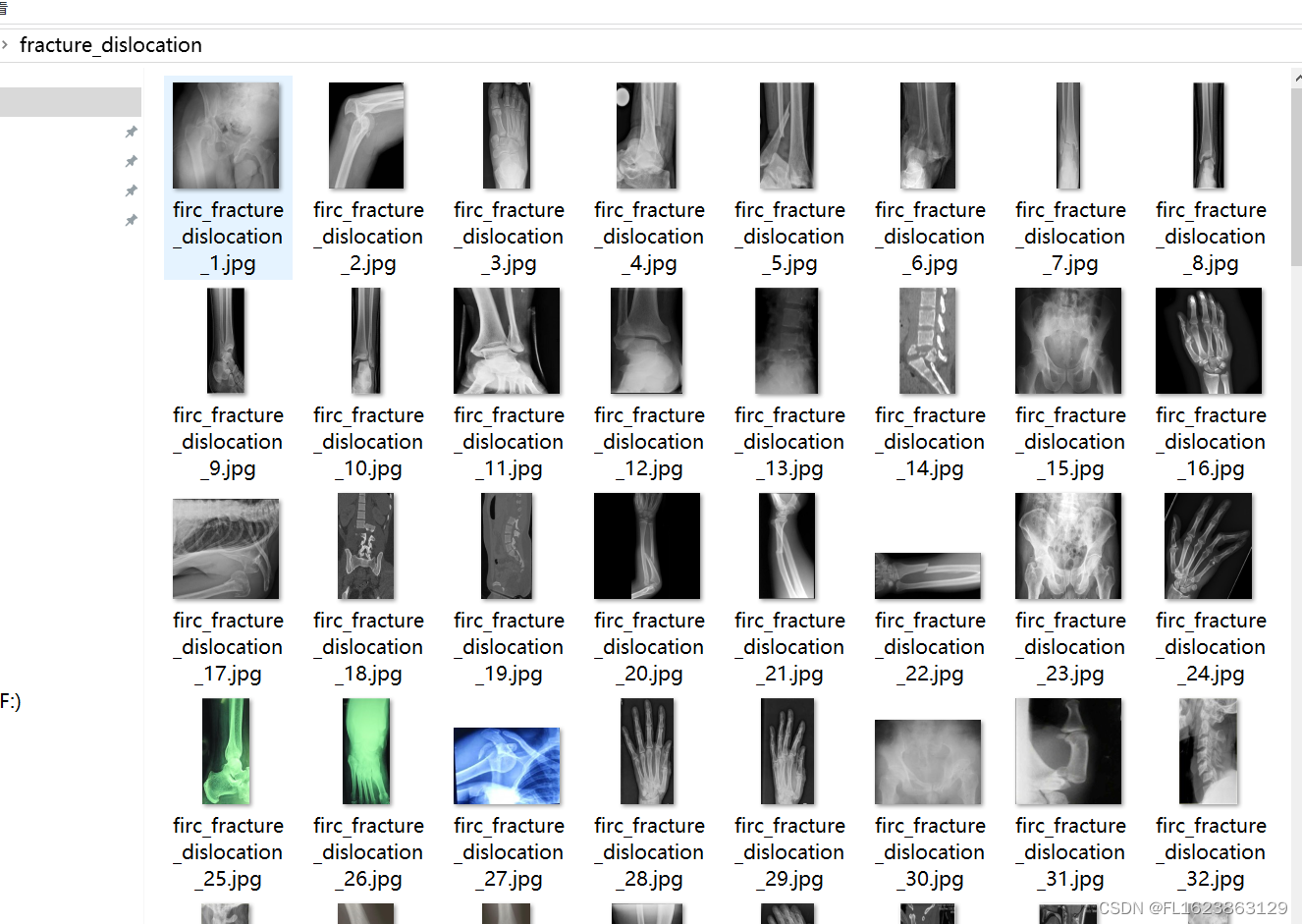
骨折分类数据集1129张10类别
数据集类型:图像分类用,不可用于目标检测无标注文件 数据集格式:仅仅包含jpg图片,每个类别文件夹下面存放着对应图片 图片数量(jpg文件个数):1129 分类类别数:10 类别名称:["avulsion_fracture",…...
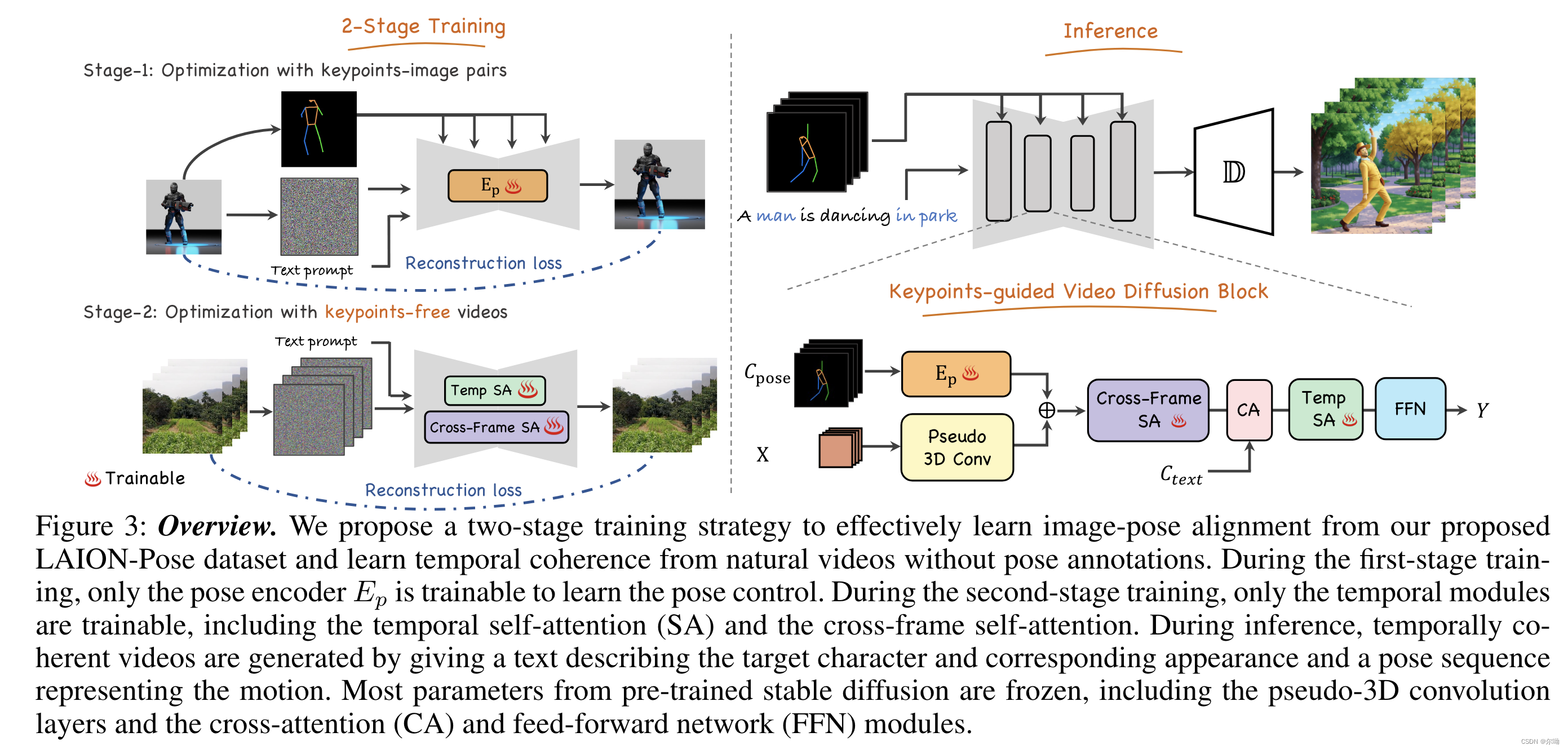
Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos
清华深&港科&深先进&Tencent AAAI24https://github.com/mayuelala/FollowYourPose 问题引入 本文的任务是根据文本来生成高质量的角色视频,并且可以通过pose来控制任务的姿势;当前缺少video-pose caption数据集,所以提出一个两…...
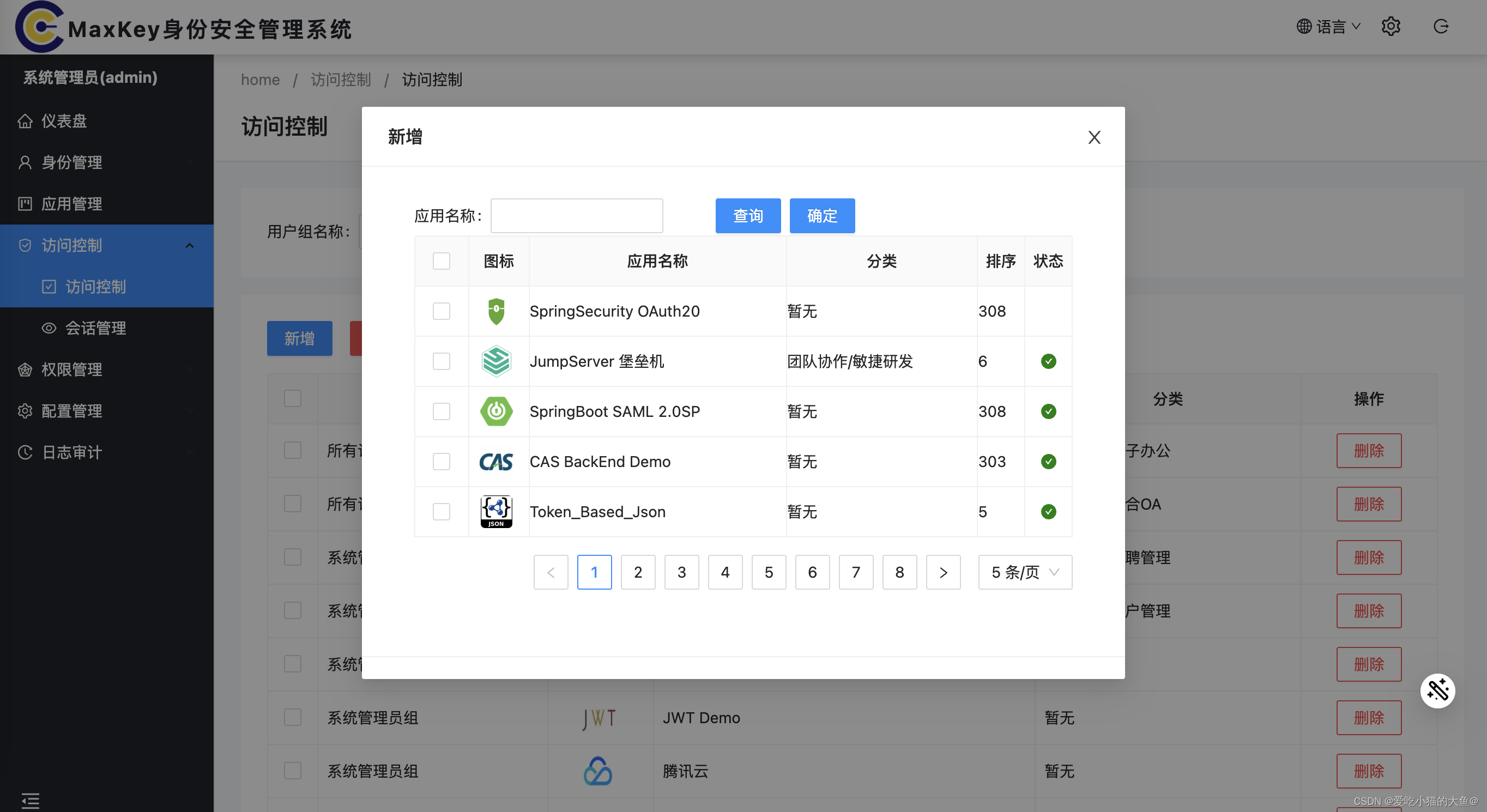
记录一次开源 MaxKey 安装部署
官方文档:https://www.maxkey.top/doc/docs/intro/ 开源代码:https://toscode.mulanos.cn/dromara/MaxKey 发行版:https://toscode.mulanos.cn/dromara/MaxKey/releases 一、准备工作 yum install -y yum-utils yum-config-manager --add-r…...

k8s基础命令
#查看pod kubectl get pod -n 命名空间 或者 kubectl get pod -n 命名控江 -o wide 例如: kubectl get pod -n databank-dev #查看deployment控制器 kubectl get deploy -n 命名空间 kubectl get deploy -n databank-dev #查看命名控制(namespace&am…...

【云原生_K8S系列】认识 Kubernetes
在当今数字化转型的浪潮中,企业对于构建高效、灵活的软件架构有了更高的期望。而在这个迅速变化的环境中,容器化技术如雨后春笋般涌现,为解决传统部署和管理软件所带来的挑战提供了一种全新的解决方案。在众多容器编排工具中,Kube…...
性能猛兽:OrangePi Kunpeng Pro评测!
1.引言 随着物联网和嵌入式系统的不断发展,对于性能强大、资源消耗低的单板计算机的需求也日益增加。在这个快节奏的技术时代,单板计算机已成为各种应用场景中不可或缺的组成部分,从家庭娱乐到工业自动化,再到科学研究࿰…...

六一儿童节创意项目:教你用HTML5和CSS3制作可爱的雪糕动画
六一儿童节快到了,这是一个充满童趣和欢乐的日子。为了给孩子们增添一份节日惊喜,我们决定用HTML5和CSS3制作一个生动有趣的雪糕动画。通过这个项目,不仅能提升你的前端技能,还能带给孩子们一份特别的节日礼物。无论你是前端开发新…...

日用百货元宇宙 以科技创新培育产业新质生产力
当前,我国乳品工业的科技创新进入深水区,不仅对科技的需求加大,还具有跨学科、多领域交叉的显著特征,在引领我国乳制品行业现代化产业体系建设过程中,不断催生新产业、新模式、新动能,面向行业未来的新质生…...

云服务器购买之后到部署项目的流程
1.通过账号密码登录百度智能云控制台; 2.进入对应的服务器‘云服务器BBC’ 找到’实例‘即找到对应的服务器列表; 此时通过本地电脑 1.cmd命令提示符 PING 服务器公网地址不通; 2.通过本地电脑进行远程桌面连接不通 原因:没有关联安全组,或者…...

六自由度并联无人机自适应起降平台设计——从构型选型到运动学仿真全流程
六自由度并联无人机自适应起降平台设计——从构型选型到运动学仿真全流程 摘要 随着无人机物流配送、海上作业、灾害救援等场景的快速发展,无人机在动态环境下的安全起降成为制约其大规模应用的瓶颈问题。传统的固定起降平台无法适应舰船摇摆、车辆运动等动态条件,而串联机…...
)
告别BMC踩坑:手把手教你用U盘给IBM/Lenovo x3650 M5装系统(含JRE报错解决方案)
企业级服务器系统部署实战:IBM/Lenovo x3650 M5的U盘安装全指南 当面对一台崭新的IBM/Lenovo x3650 M5服务器时,许多IT运维人员都会遇到系统部署的挑战。虽然官方文档通常推荐通过BMC/IMM远程管理接口进行安装,但现实操作中,Java…...

CW32F003与CW32F030国产MCU深度对比:从选型到项目实战全解析
1. 项目概述与核心价值最近在整理手头的开发板,翻出了两块来自武汉芯源的CW32F003和CW32F030。这两款芯片和对应的开发板,在国产MCU的入门级市场里,算得上是“老朋友”了,尤其是对于成本敏感、需要快速验证方案的工程师和学生来说…...
)
Keil5编译报错‘Target not created’?别急着重装,先试试这几招(附常见原因排查清单)
Keil5编译报错‘Target not created’的深度排查指南 当Keil5编译时出现"Target not created"的提示,很多开发者第一反应是重装软件。但实际上,这个报错背后可能隐藏着多种原因,盲目重装不仅浪费时间,还可能掩盖真正的问…...

深入解析TRC-20代币:从技术原理到生态布局,一篇文章讲透
深入解析TRC-20代币:从技术原理到生态布局,一篇文章讲透 引言 在波场(TRON)生态中,TRC-20 代币标准扮演着至关重要的角色,它不仅是承载如USDT等巨量稳定币的基石,更是连接DeFi、GameFi和NFT等…...

Perplexity谚语查询功能实测报告:7类典型误用场景+5步精准调优法,错过即降效40%
更多请点击: https://kaifayun.com 第一章:Perplexity谚语查询功能的核心价值与适用边界 Perplexity 的谚语查询功能并非通用语言模型的简单问答接口,而是一个面向文化语义深度解析的专用能力模块。它依托高质量结构化谚语知识图谱与上下文感…...

DeepSeek LeetCode 2509.查询树中环的长度 C语言实现
题目分析这道题的关键在于理解完全二叉树的编号规律:节点 val 的父节点是 val / 2(整数除法)。当在两个节点间添加一条边时,形成的环长度等于两节点到其最近公共祖先(LCA)的路径边数之和,再加 1…...

魔百盒CM311-1s刷机后体验:安卓9.0固件到底香不香?附5621DS无线实测
魔百盒CM311-1s刷机实战:安卓9.0系统深度评测与无线性能揭秘 当手中的魔百盒CM311-1s遇上安卓9.0系统,这场硬件与软件的碰撞会擦出怎样的火花?作为一款搭载S905L3B芯片的电视盒子,其原生系统往往受限于运营商定制化限制࿰…...

3个步骤快速定位Windows热键占用者:Hotkey Detective完整实战指南
3个步骤快速定位Windows热键占用者:Hotkey Detective完整实战指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective …...

ESP32-S2开发入门:用VSCode远程连接WSL,打造丝滑的嵌入式开发工作流
ESP32-S2开发环境优化:VSCode与WSL的高效协作方案 嵌入式开发工程师常面临跨平台协作的挑战——既需要Linux环境的强大工具链,又依赖Windows的图形界面友好性。本文将揭示如何通过VSCode远程连接WSL,构建一个无缝衔接的ESP32-S2开发环境&…...