微调Llama3实现在线搜索引擎和RAG检索增强生成功能
视频中所出现的代码 Tavily Search+RAG
微调Llama3实现在线搜索引擎和RAG检索增强生成功能!打造自己的perplexity和GPTs!用PDF实现本地知识库_哔哩哔哩_bilibili
一.准备工作
1.安装环境
conda create --name unsloth_env python=3.10
conda activate unsloth_envconda install pytorch-cuda=12.1 pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformerspip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"pip install --no-deps trl peft accelerate bitsandbytes2.微调代码(要先登录一下)
huggingface-cli login
点击提示的网页获取token(注意要选择可写的)
#dataset https://huggingface.co/datasets/shibing624/alpaca-zh/viewerfrom unsloth import FastLanguageModel
import torchfrom trl import SFTTrainer
from transformers import TrainingArgumentsmax_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.# 4bit pre quantized models we support for 4x faster downloading + no OOMs.
fourbit_models = ["unsloth/mistral-7b-bnb-4bit","unsloth/mistral-7b-instruct-v0.2-bnb-4bit","unsloth/llama-2-7b-bnb-4bit","unsloth/gemma-7b-bnb-4bit","unsloth/gemma-7b-it-bnb-4bit", # Instruct version of Gemma 7b"unsloth/gemma-2b-bnb-4bit","unsloth/gemma-2b-it-bnb-4bit", # Instruct version of Gemma 2b"unsloth/llama-3-8b-bnb-4bit", # [NEW] 15 Trillion token Llama-3
] # More models at https://huggingface.co/unslothmodel, tokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/llama-3-8b-bnb-4bit",max_seq_length = max_seq_length,dtype = dtype,load_in_4bit = load_in_4bit,# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)model = FastLanguageModel.get_peft_model(model,r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128target_modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],lora_alpha = 16,lora_dropout = 0, # Supports any, but = 0 is optimizedbias = "none", # Supports any, but = "none" is optimized# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long contextrandom_state = 3407,use_rslora = False, # We support rank stabilized LoRAloftq_config = None, # And LoftQ
)alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.### Instruction:
{}### Input:
{}### Response:
{}"""EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):instructions = examples["instruction"]inputs = examples["input"]outputs = examples["output"]texts = []for instruction, input, output in zip(instructions, inputs, outputs):# Must add EOS_TOKEN, otherwise your generation will go on forever!text = alpaca_prompt.format(instruction, input, output) + EOS_TOKENtexts.append(text)return { "text" : texts, }
passfrom datasets import load_dataset#file_path = "/home/Ubuntu/alpaca_gpt4_data_zh.json"#dataset = load_dataset("json", data_files={"train": file_path}, split="train")dataset = load_dataset("yahma/alpaca-cleaned", split = "train")dataset = dataset.map(formatting_prompts_func, batched = True,)trainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset,dataset_text_field = "text",max_seq_length = max_seq_length,dataset_num_proc = 2,packing = False, # Can make training 5x faster for short sequences.args = TrainingArguments(per_device_train_batch_size = 2,gradient_accumulation_steps = 4,warmup_steps = 5,max_steps = 60,learning_rate = 2e-4,fp16 = not torch.cuda.is_bf16_supported(),bf16 = torch.cuda.is_bf16_supported(),logging_steps = 1,optim = "adamw_8bit",weight_decay = 0.01,lr_scheduler_type = "linear",seed = 3407,output_dir = "outputs",),
)trainer_stats = trainer.train()model.save_pretrained_gguf("llama3", tokenizer, quantization_method = "q4_k_m")
model.save_pretrained_gguf("llama3", tokenizer, quantization_method = "q8_0")
model.save_pretrained_gguf("llama3", tokenizer, quantization_method = "f16")#to hugging face
model.push_to_hub_gguf("leo009/llama3", tokenizer, quantization_method = "q4_k_m")
model.push_to_hub_gguf("leo009/llama3", tokenizer, quantization_method = "q8_0")
model.push_to_hub_gguf("leo009/llama3", tokenizer, quantization_method = "f16")
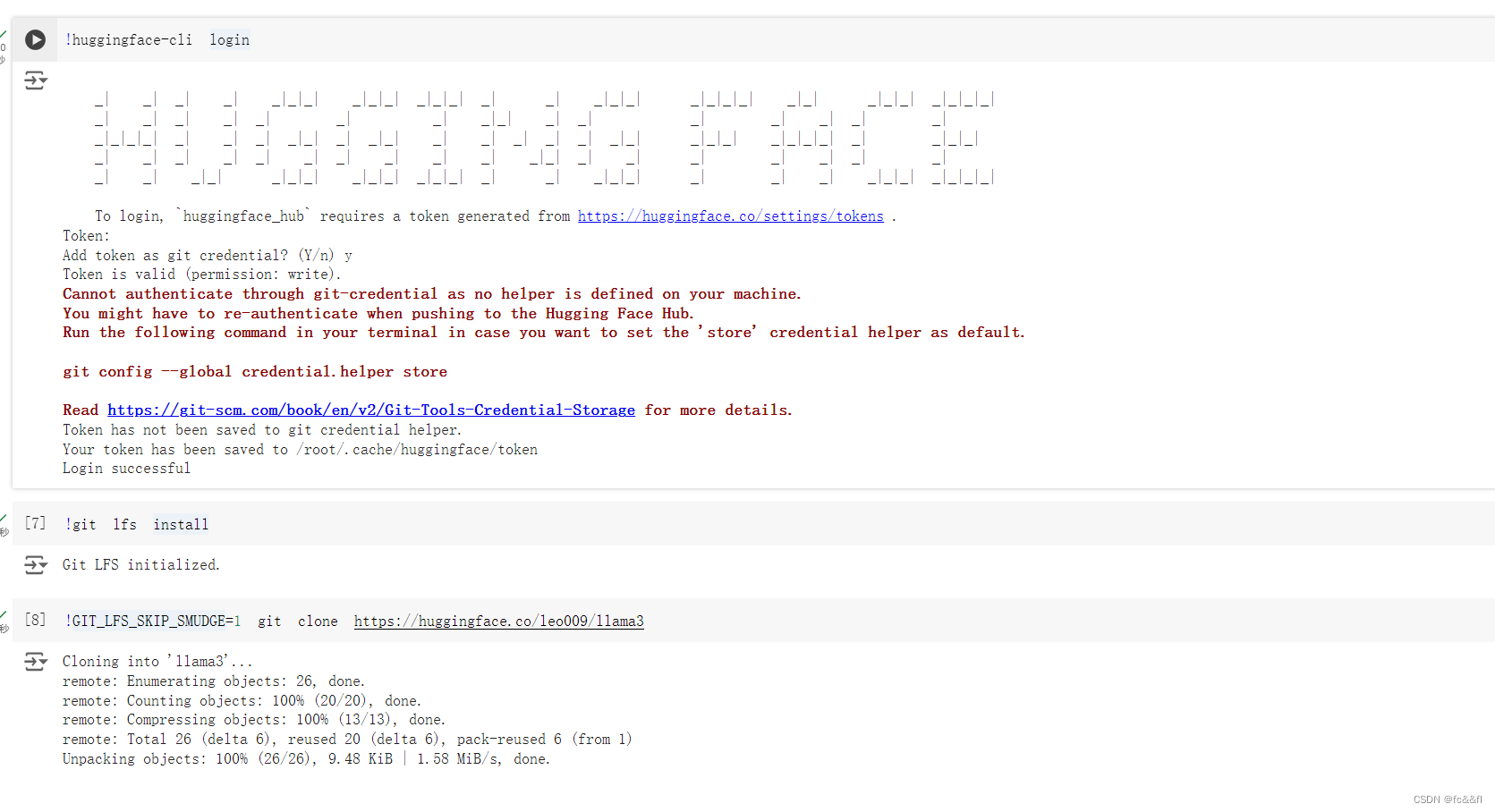
3.我们选择将hugging face上微调好的模型下载下来(https://huggingface.co/leo009/llama3/tree/main)
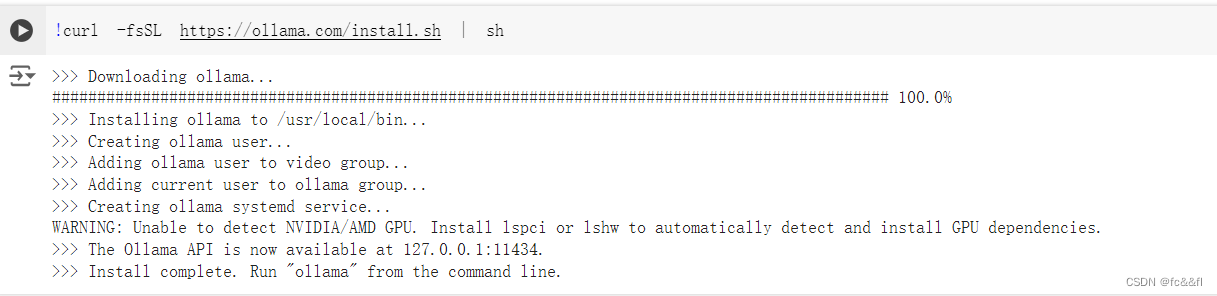
4.模型导入ollama
下载ollama
导入ollama
FROM ./downloads/mistrallite.Q4_K_M.gguf
ollama create example -f Modelfile二.实现在线搜索
1.获取Tavily AI API
Tavily AI
export TAVILY_API_KEY=tvly-xxxxxxxxxxx2.安装对应的python库
install tavily-python
pip install phidata
pip install ollam
3.运行app.py
#app.py
import warnings# Suppress only the specific NotOpenSSLWarning
warnings.filterwarnings("ignore", message="urllib3 v2 only supports OpenSSL 1.1.1+")from phi.assistant import Assistant
from phi.llm.ollama import OllamaTools
from phi.tools.tavily import TavilyTools# 创建一个Assistant实例,配置其使用OllamaTools中的llama3模型,并整合Tavily工具
assistant = Assistant(llm=OllamaTools(model="mymodel3"), # 使用OllamaTools的llama3模型tools=[TavilyTools()],show_tool_calls=True, # 设置为True以展示工具调用信息
)# 使用助手实例输出请求的响应,并以Markdown格式展示结果
assistant.print_response("Search tavily for 'GPT-5'", markdown=True)
三.实现RAG
1.git clone https://github.com/phidatahq/phidata.git
2.phidata---->cookbook---->llms--->ollama--->rag里面 有示例和教程
修改assigant.py中的14行代码,将llama3改为自己微调好的模型
另外需要注意的是!!!
要将自己的模型名称加入到app.py里面的数组里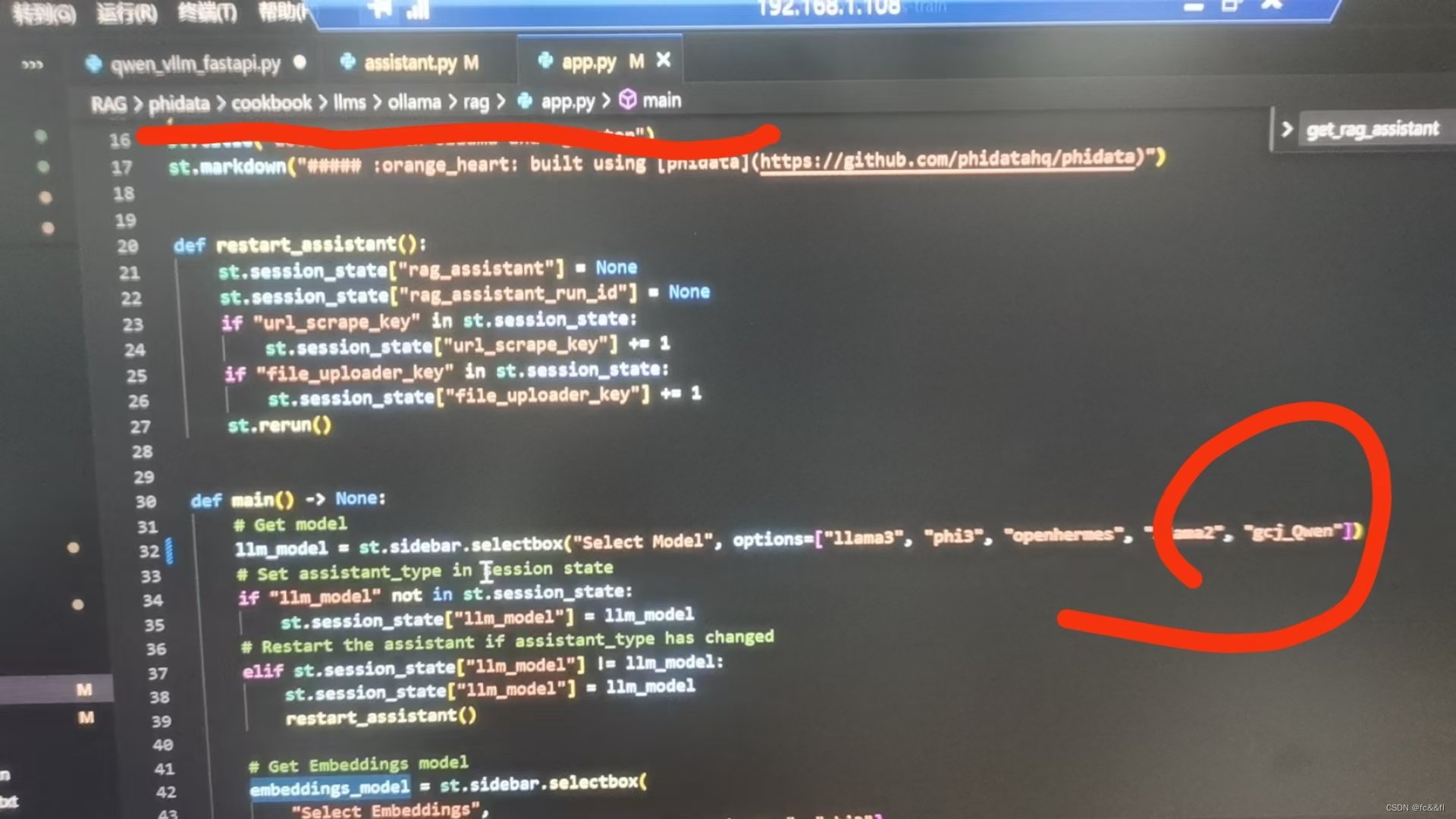
streamlit run /home/cxh/phidata/cookbook/llms/ollama/rag/assistant.py
相关文章:
微调Llama3实现在线搜索引擎和RAG检索增强生成功能
视频中所出现的代码 Tavily SearchRAG 微调Llama3实现在线搜索引擎和RAG检索增强生成功能!打造自己的perplexity和GPTs!用PDF实现本地知识库_哔哩哔哩_bilibili 一.准备工作 1.安装环境 conda create --name unsloth_env python3.10 conda activate …...
【软件工程】【23.04】p1
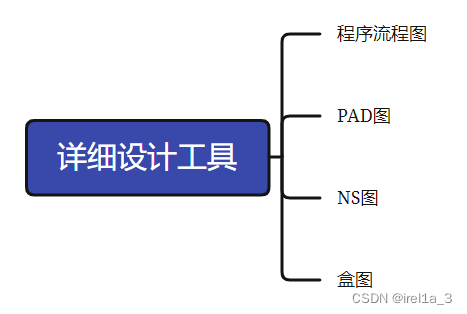
关键字: 软件模型、提炼、加工表达工具、通信内聚、访问依赖、边界类交互分析、RUP核心工作流、首先测试数据流、软件验证过程、CMMI过程域分类工程类; 软件工程目的、功能需求是需求的主体、结构化方法、耦合、详细设计工具、类、类图、RUP采用用例技…...

Flutter 中的 ColoredBox 小部件:全面指南
Flutter 中的 ColoredBox 小部件:全面指南 在 Flutter 的世界中,ColoredBox 是一个用于填充颜色的简单而强大的小部件。它是一个不透明的矩形,可以用来创建颜色块,作为布局的占位符,或者简单地改变某个区域的背景色。…...

【LeetCode 随笔】面试经典 150 题【中等+困难】持续更新中。。。
文章目录 12.【中等】整数转罗马数字151.【中等】反转字符串中的单词6.【中等】Z 字形变换68.【困难】文本左右对齐167.【中等】两数之和 II - 输入有序数组 🌈你好呀!我是 山顶风景独好 💝欢迎来到我的博客,很高兴能够在这里和您…...

SwiftUI中AppStorage的介绍使用
在Swift中,AppStorage是SwiftUI中引入的一个属性包装器,在这之前我们要存储一些轻量级的数据采用UserDefaults进行存取。而AppStorage用于从UserDefaults中读取值,当值改变时,它会自动重新调用视图的body属性。也就是说࿰…...
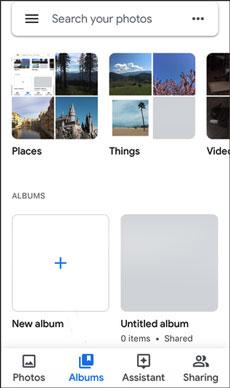
iCloud 照片到 Android 指南:帮助您快速将照片从 iCloud 传输到安卓手机
概括 iOS 和 Android 之间的传输是一个复杂的老问题。将 iCloud 照片传输到 Android 似乎是不可能的。放心。现在的高科技已经解决了这个问题。尽管 Apple 和 Android 不提供传输工具,但您仍然有其他有用的选项。这篇文章与您分享了 5 个技巧。因此,…...

知识点总结
1、Uboot的流程调用: 1.1、cmd_process函数是怎么被调用到的: cmd_process在common/command.c 1.2、uboot阶段断电,后续起不来,可能要换线去使用,也许和电源线有关 2、git 相关使用 2.1 .gitignore相关的使用 1、…...

Python并发与异步编程
Python的并发与异步编程是两个不同的概念,但它们经常一起使用,以提高程序的性能和响应能力。以下是对这两个概念的详细讲解: 并发编程 (Concurrency) 并发编程是指在程序中同时执行多个任务的能力。Python提供了几种实现并发的机制ÿ…...
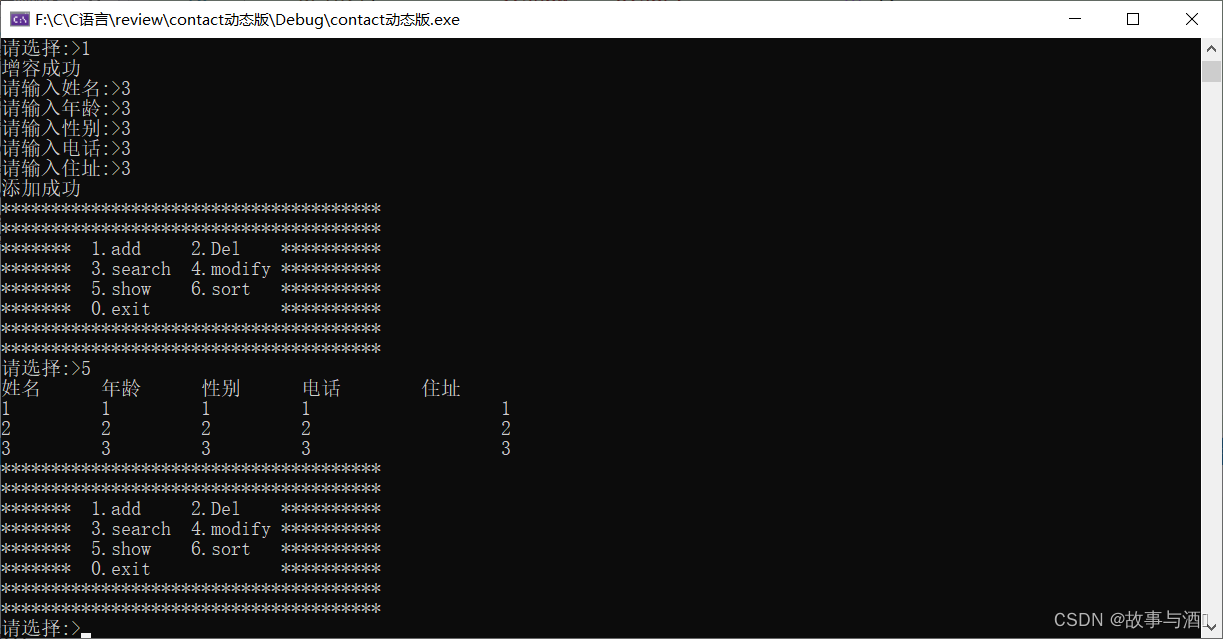
动态内存管理—C语言通讯录
目录 一,动态内存函数的介绍 1.1 malloc和free 1.2 calloc 1.3 realloc 1.4C/C程序的内存开辟 二,通讯录管理系统 动态内存函数的介绍 malloc free calloc realloc 一,动态内存函数的介绍 1.1 malloc和free void* malloc (…...
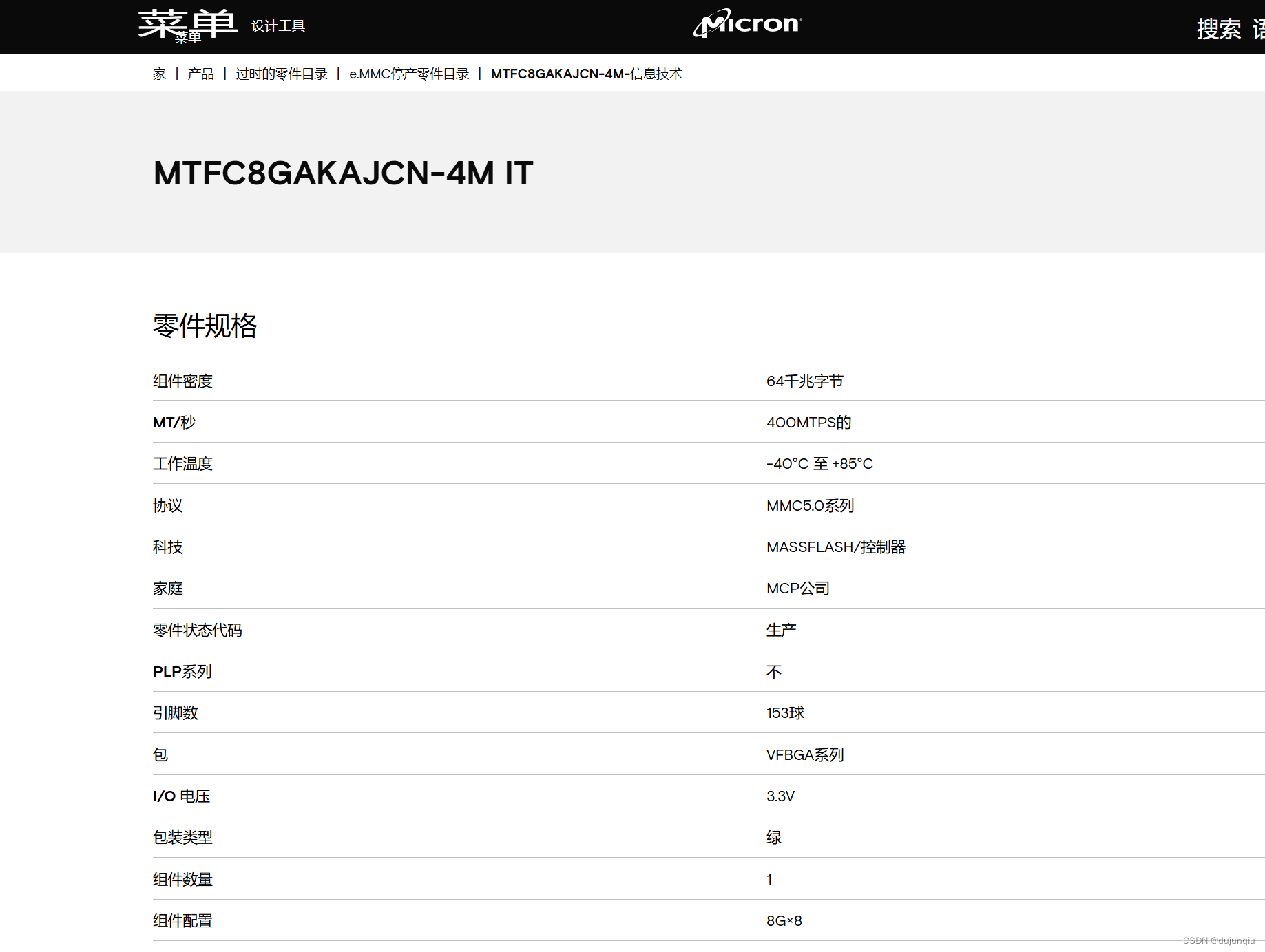
美光EMMC芯片丝印型号查询 8LK17/D9PSK, OXA17/JY997
问题说明 最近在使用美光EMMC的时候,发现通过芯片丝印查询不到 芯片的规格说明书; 经过查阅资料,发现美光的EMMC芯片 “由于空间限制,FBGA 封装组件具有与部件号不同的缩写部件标记”,需要通过官网查询丝印的FBGA cod…...

win32-鼠标消息、键盘消息、计时器消息、菜单资源
承接前文: win32窗口编程windows 开发基础win32-注册窗口类、创建窗口win32-显示窗口、消息循环、消息队列 本文目录 键盘消息键盘消息的分类WM_CHAR 字符消息 鼠标消息鼠标消息附带信息 定时器消息 WM_TIMER创建销毁定时器 菜单资源资源相关菜单资源使用命令消息的…...

springboot项目部署到linux服务器
springboot后端 修改前 修改后 vue前端 修改前 将地址中的 localhost改为 ip 重新生成war包 war上传到linux的tomcat的webapps下 其他环境配置和macOS大差不差 Tomcat安装使用与部署Web项目的三种方法_tomcat部署web项目-CSDN博客...

MagicLens:新一代图像搜索技术和产品形态
MagicLens:Self-Supervised Image Retrieval with Open-Ended Instructions MagicLens: 自监督图像检索与开放式指令 作者:Kai Zhang, Yi Luan, Hexiang Hu, Kenton Lee, Siyuan Qiao, Wenhu …...
[9] CUDA性能测量与错误处理
CUDA性能测量与错误处理 讨论如何通过CUDA事件来测量它的性能如何通过CUDA代码进行调试 1.测量CUDA程序的性能 1.1 CUDA事件 CPU端的计时器可能无法给出正确的内核执行时间CUDA事件等于是在你的CUDA应用运行的特定时刻被记录的时间戳,通过使用CUDA事件API&#…...

Java学习四
Random 随机数 数组 静态初始化数组 数组在计算机中的基本原理 数组的访问 什么是遍历 数组的动态初始化 动态初始化数组元素默认值规则 Java内存分配介绍 数组在计算机中的执行原理 使用数组时常见的一个问题 案例求数组元素最大值 public class Test1 {public static void ma…...

Vue 父组件使用refs来直接访问和修改子组件的属性或调用子组件的方法
步骤 1: 在子组件中定义要被修改的属性或方法 首先,在子组件中定义你想要父组件能够修改或调用的属性或方法。例如,我们有一个名为MyChildComponent的子组件,它有一个名为childData的数据属性和一个名为updateData的方法。 // 子组件 MyChi…...

范罗士、希喂、安德迈爆款宠物空气净化器哪款好?深度对比测评
作为一名深受养猫过敏困扰的铲屎官,我经常提醒新手铲屎官重视家里的空气环境。宠物的浮毛和皮屑不仅会引发过敏,还可能传播细菌和病毒。很多人以为普通空气净化器能解决问题,但这些产品并未针对宠物家庭的特殊需求。经过多次研究和测试&#…...

SAP OBYC自动记账 详解
在MM模块的许多操作都能实现在FI模块自动过账,如PO收货、发票验证、工单发料、向生产车间发料等等。不用说,一定需要在IMG中进行配置才可以实现自动处理。但SAP实现的这种自动配置的机制是怎样的呢?其实也并不复杂,让我们先以一种最简单的情况来了解实现原理和实现流程,然…...

《NoSQL数据库技术与应用》 MongoDB副本集
《NoSQL数据库技术与应用》 教学设计 课程名称:NoSQL数据库技术与应用 授课年级: 20xx年级 授课学期: 20xx学年第一学期 教师姓名: 某某老师 2020年5月6日 课题 名称 第4章 MongoDB副本集 计划学时 8课时 内容 分析 独立模式可…...

Flutter 中的 DropdownButtonFormField 小部件:全面指南
Flutter 中的 DropdownButtonFormField 小部件:全面指南 在Flutter中,DropdownButtonFormField是一个特殊的表单字段小部件,它结合了下拉选择框(DropdownButton)和表单字段(FormField)的功能。…...
原理与工程实践:从分治算法到信号处理应用)
快速傅里叶变换(FFT)原理与工程实践:从分治算法到信号处理应用
1. 从时域到频域:为什么我们需要FFT?如果你曾经处理过音频信号、图像数据,或者调试过通信系统,那你一定对“频谱”这个概念不陌生。我们生活的世界是时间的函数,声音随着时间起伏,图像像素在空间上排列&…...

阿伐曲泊帕常见副作用头痛及疲劳的临床特征与管理
头痛与疲劳是阿伐曲泊帕治疗慢性肝病相关血小板减少症时患者报告频率最高的两项非肝脏系统不良反应。两项副作用虽极少直接危及生命,却实实在在地侵蚀着患者的日常功能与长期治疗依从性。ADAPT-1与ADAPT-2两项三期临床试验的完整安全性数据,为这两项副作…...

颈椎健康互助平台
颈椎健康互助平台选题背景分析随着信息技术的飞速发展和现代社会工作、生活方式的深刻变革,颈椎健康问题已从一个单纯的医学议题,演变为一个影响广泛、亟待社会协同解决的公共健康挑战。颈椎健康互助平台的选题,正是在这一宏观背景下应运而生…...

Agent工程2026:从提示词堆砌到生产级智能体的完整跃迁路径
如果你今天还在用"给LLM加几个工具调用"来描述你的Agent,那我们需要认真谈谈了。 2026年的AI工程现实是:绝大多数Agent项目死在了从Demo到生产的路上。不是因为模型不够强,而是因为工程没跟上。本文会系统梳理Agent工程化的核心路…...

2026年数字人拍摄新方式:一条视频能省多少时间
2026年数字人拍摄新方式:一条视频能省多少时间 【导语】 做视频最耗时间的是什么?不是拍摄那几分钟,而是前期的准备工作。但现在有一种新方式,可以让你完全不用拍摄真人,一条视频从准备到成片,最快只要7分钟…...

手把手教你:在ARM架构服务器上源码编译PyTorch 1.8.1并适配华为昇腾NPU
在ARM架构服务器上源码编译PyTorch 1.8.1并适配华为昇腾NPU实战指南 当AI开发遇上国产化硬件浪潮,越来越多的团队开始尝试在ARM架构服务器上部署深度学习框架。本文将带你深入探索在华为鲲鹏等ARM服务器上从零开始编译PyTorch 1.8.1,并最终对接昇腾NPU加…...

CLup使用:一键创建Doris存算一体集群
通过 CLup 数据库管理平台的可视化界面,一键自动化部署 Apache Doris 存算一体集群,自动完成环境检查、配置初始化、节点部署与集群注册,无需手动执行复杂的 FE/BE 配置与启动命令,大幅降低部署门槛。CLup安装部署请看:…...

CANN/asc-devkit SIMD排序函数文档
Sort 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/cann/…...
的结构、功能及医学应用研究进展)
白介素-5(IL-5)的结构、功能及医学应用研究进展
摘要白介素-5(Interleukin-5,IL-5)是一种由Th2细胞、嗜酸性粒细胞祖细胞等免疫细胞分泌的多功能细胞因子,在调节免疫反应、尤其是嗜酸性粒细胞(Eosinophil, EOS)的分化、存活及功能活化中发挥核心作用。自1…...

大模型应用开发指南:从入门到实践,收藏这份从Demo到生产落地的完整攻略
本文分享了AI应用开发中从Demo到生产落地的完整实践,涵盖技术选型、架构设计、核心算法优化及部署经验。通过LangGraph、RAGFlow和Langfuse等工具,解决上下文超限、Prompt管理混乱等问题,最终实现准确率提升25%的工业级AI系统。适合程序员和小…...