hadoop学习之MapReduce案例:输出每个班级中的成绩前三名的学生
hadoop学习之MapReduce案例:输出每个班级中的成绩前三名的学生
所要处理的数据案例:
1500100001 施笑槐,22,女,文科六班,406
1500100002 吕金鹏,24,男,文科六班,440
1500100003 单乐蕊,22,女,理科六班,359
1500100004 葛德曜,24,男,理科三班,421
1500100005 宣谷芹,22,女,理科五班,395
1500100006 边昂雄,21,男,理科二班,314
...
1.Map端
package com.shujia.mr.top3;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*TODO在编写代码之前需要先定义数据的处理逻辑对于各班级中的学生总分进行排序,要求取出各班级中总分前三名学生MapTask阶段:① 读取ReduceJoin的处理结果,并对数据进行提取② 按照学生的班级信息,对班级作为Key,整行数据作为Value写出到 ReduceTask 端ReduceTask阶段:① 接收到整个班级中的所有学生信息并将该数据存放在迭代器中*/public class Top3Mapper extends Mapper<LongWritable, Text, Text, Stu> {/*** 直接将学生对象发送到Reduce端进行操作* ① 对于Stu学生自定义学生类,作为输出类型,需要将当前类进行序列化操作 implement Writable 接口* ② 同时需要在自定义类中保证 类是具有无参构造的* 运行时会出现:* java.lang.RuntimeException: java.lang.NoSuchMethodException: com.shujia.mr.top3.Stu.<init>()* 从日志上可以看到调用了 Stu.<init>() 指定的就是无参构造* 从逻辑上:* 在Mapper端 构建了Stu对象 => 通过调用其 write 对其进行了序列化操作* 在Reducer端 需要对其进行反序列化 => 通过无参构造创建自身的空参对象 => 调用readFields方法进行 反序列化* 将数据赋予给当前的空参对象属性*/@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Stu>.Context context) throws IOException, InterruptedException {// 1500100009 沈德昌,21,男,理科一班,251 => 表示读取到的数据String[] split = value.toString().split("\t");if (split.length == 2) {String otherInfo = split[1];String[] columns = otherInfo.split(",");if (columns.length == 5) {String clazz = columns[3];Stu stu = new Stu(split[0], columns[0], Integer.valueOf(columns[1]), columns[2], columns[3], Integer.valueOf(columns[4]));context.write(new Text(clazz), stu);}}}
}
2.Reduce端
package com.shujia.mr.top3;import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;/*TODO ReduceTask阶段*/
public class Top3Reducer extends Reducer<Text, Stu, Text, NullWritable> {/*** 对一个班级中所有的学生成绩进行排序 =>* 1.将数据存储在一个容器中* 2.对容器中数据进行排序操作* 对排序的结果进行取前三** @param key 表示班级信息* @param values 一个班级中所有的学生对象* @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void reduce(Text key, Iterable<Stu> values, Reducer<Text, Stu, Text, NullWritable>.Context context) throws IOException, InterruptedException {/*TODO 当程序执行到Reducer端时,需要对Values中的数据进行遍历,获取每一个学生对象但是在添加过程中,ArrayList中所有的对象信息都变成一样的。表示当前 ArrayList存储的对象为1个,每次添加的引用信息都是指向一个对象地址如何解决?每次获取到对象后,对其进行克隆一份(重新创建一个对象进行存储)*/ArrayList<Stu> stus = new ArrayList<>();for (Stu stu : values) {// 排序方案2:需要对Stu进行序列化//TODO 每次获取到对象后,对其进行克隆一份(重新创建一个对象进行存储)Stu stu1 = new Stu(stu.id, stu.name, stu.age, stu.gender, stu.clazz, stu.score);stus.add(stu1);}// 进行排序操作,将stus集合传入函数进行排序Collections.sort(stus,// 设定排序规则new Comparator<Stu>() {/*CSDN:return 0:不交换位置,不排序return 1:交换位置return -1:不交换位置return o1-o2:升序排列return o2-o1:降序排列*/@Overridepublic int compare(Stu o1, Stu o2) {int compareScore = o1.score - o2.score;// 保证成绩序列是降序排序,若成绩相同,则按照学号进行字典排序返回数值,最后进行字典 升序排序//String中的compareTo方法:用字符串1跟字符串2作比较,如果字符串1的字典顺序在字符串2前面(较小),则返回一个负数。// 若在后面,则返回一个正数。若两个字符串的字典顺序相同,则返回0。return -compareScore > 0 ? 1 : (compareScore == 0 ? o1.id.compareTo(o2.id) : -1);}});// 对排序的结果进行遍历for (int i = 0; i < 3; i++) {context.write(new Text(stus.get(i).toString()+","+(i+1)),NullWritable.get());}}
}
3.main方法
package com.shujia.mr.top3;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import java.io.FileNotFoundException;
import java.io.IOException;public class Top3 {/*TODO:将项目打包到Hadoop中进行执行。*/public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {// TODO MapReduce程序入口中的固定写法// TODO 1.获取Job对象 并设置相关Job任务的名称及入口类Configuration conf = new Configuration();Job job = Job.getInstance(conf, "Top3");// 设置当前main方法所在的入口类job.setJarByClass(Top3.class);// TODO 2.设置自定义的Mapper和Reducer类job.setMapperClass(Top3Mapper.class);job.setReducerClass(Top3Reducer.class);// TODO 3.设置Mapper的KeyValue输出类 和 Reducer的输出类 (最终输出)job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Stu.class);job.setOutputKeyClass(Text.class);/*NullWritable是Writable的一个特殊类,实现方法为空实现,不从数据流中读数据,也不写入数据,只充当占位符,如在MapReduce中,如果你不需要使用键或值,你就可以将键或值声明为NullWritable,NullWritable是一个不可变的单实例类型。*/job.setOutputValueClass(NullWritable.class);// TODO 4.设置数据的输入和输出路径// 本地路径FileSystem fileSystem = FileSystem.get(job.getConfiguration());Path outPath = new Path("hadoop/out/new_top3");
// Path outPath = new Path("/data/hadoop/out/new_top3");Path inpath = new Path("hadoop/out/reducejoin");
// Path inpath = new Path("/data/hadoop/out/reducejoin");if (!fileSystem.exists(inpath)) {throw new FileNotFoundException(inpath+"不存在");}TextInputFormat.addInputPath(job,inpath);if (fileSystem.exists(outPath)) {System.out.println("路径存在,开始删除");fileSystem.delete(outPath,true);}TextOutputFormat.setOutputPath(job,outPath);// TODO 5.提交任务开始执行job.waitForCompletion(true);}
}
4.创建的学生类
package com.shujia.mr.top3;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.io.Serializable;public class Stu implements Writable {String id;String name;int age;String gender;String clazz;int score;/*TODO 使用Hadoop序列化的问题:java.lang.RuntimeException: java.lang.NoSuchMethodException: com.shujia.mr.top3.Stu.<init>()*///TODO 需要给定无参构造方法(序列化需要)public Stu() {}public Stu(String id, String name, int age, String gender, String clazz, int score) {this.id = id;this.name = name;this.age = age;this.gender = gender;this.clazz = clazz;this.score = score;}@Overridepublic String toString() {return id +", " + name +", " + age +", " + gender +", " + clazz +", " + score;}// TODO 自定义类要重写下列方法才能进行序列化/*对于Write方法中是对当前的对象进行序列化操作*/@Overridepublic void write(DataOutput out) throws IOException {out.writeUTF(id);out.writeUTF(name);out.writeInt(age);out.writeUTF(gender);out.writeUTF(clazz);out.writeInt(score);}/*readFields方法中是对当前对象进行反序列化操作*/@Overridepublic void readFields(DataInput in) throws IOException {this.id = in.readUTF(); // 将0101数据反序列化数据并保存到当前属性中this.name = in.readUTF();this.age = in.readInt();this.gender = in.readUTF();this.clazz = in.readUTF();this.score = in.readInt();}
}
相关文章:

hadoop学习之MapReduce案例:输出每个班级中的成绩前三名的学生
hadoop学习之MapReduce案例:输出每个班级中的成绩前三名的学生 所要处理的数据案例: 1500100001 施笑槐,22,女,文科六班,406 1500100002 吕金鹏,24,男,文科六班,440 1500100003 单乐蕊,22,女,理科六班,359 1500100004 葛德曜,24,男,理科三班,421 15001…...

【亲测,安卓版】快速将网页网址打包成安卓app,一键将网页打包成app,免安装纯绿色版本,快速将网页网址打包成安卓apk
背景:部分客户需求将自己网站打包成app,供用户在浏览器安装使用、 网页网址快速生成app 准备材料操作流程第一步:打开HBuilder X新建项目第二步创建Wap2App项目第三步修改App图标第四步发布app第五步查看apk 准备材料 1.需要打包的网页 2.ap…...

学习thinkphp的循环标签
1.FOREACH标签 foreach标签的用法和PHP语法非常接近,用于循环输出数组或者对象的属性,用法如下: $list User::all(); View::assign(list,$list); 模板文件中可以这样输出 {foreach $list as $key>$vo } {$vo.id}:{$vo.name} {/foreac…...

根据标签名递归读取xml字符串中element
工具类: /*** 根据标签名递归读取xml字符串中element* 例:* String xml * "<req>\n" * "<tag1></tag1>\n" * "<tag2>\n" * " <tag4></tag4>\n" * "</tag2>\n&…...

Ovid医学库文献如何在家查找下载
今天讲的数据库是一个知名医学库——Ovid Ovid隶属于威科集团的健康出版事业集团,与LWW、Adis等公司属于姊妹公司。Ovid数据库在医学外文文献数据库方面占据绝对地位,目前已有包涵人文、科技等多领域数据库300个,其中80多个是生物医学数据库…...

在已创建的git工程中添加.gitignore
有些代码创建git时,为了方便将所有文件都加入了git管理,但实际有些库的Makefile文件和编译目录的文件不需要加入管理,否则每次提交或编译后,git diff将看到非常多的冗余信息。而我们修改的核心代码都淹没在这些大量无用的信息里面…...

MR混合现实情景实训教学系统在临床医学课堂上的应用
MR混合现实情景实训教学系统在临床医学课堂上的应用可以带来许多积极的影响,具体表现在以下几个方面: 1. 增强教学的真实感和互动性:MR混合现实技术能够创建出高度逼真的模拟临床环境,使学生能够身临其境地体验临床实践。这种技术…...

就说说开一家公司的流程和成本
本人在进互联网公司和外企前,也和一位老板合作做,在一家小微公司里做过技术负责人,所以也了解开办一家公司的流程以及公司运作的成本。 通过本文大家其实能看到创业的难度。具体来讲,开办并维持着一家公司,其实需要操…...

【前端】面试八股文——数组扁平化的实现
【前端】面试八股文——数组扁平化的实现 数组扁平化是指将一个多维数组转换为一维数组。在前端开发中,处理这样的数组结构是很常见的需求。本文将详细介绍几种实现数组扁平化的方法,以帮助读者更好地理解和应用这些技术。 1. 使用 Array.prototype.fl…...

2005-2022年各省全体居民人均可支配收入数据(无缺失)
2005-2022年各省全体居民人均可支配收入数据(无缺失) 1、时间:2005-2022年 2、来源:国家统计局、统计年鉴 3、指标:全体居民人均可支配收入 4、范围:31省 5、缺失情况:无缺失 6、指标解释…...

JVM调优,何时调优,怎么调优,面试的时候调优
一般Java面试的时候,面试官都喜欢问一个面试题,就是JVM调优的面试题,相信超过99%的小伙伴都没有过JVM调优的经历。说实话,我以前也没有相关的调优经验,也非常喜欢百度,这个问题到底想问什么,应该…...
)
朗之万动力学(Langevin dynamics)
朗之万动力学(Langevin dynamics) 是一种模拟经典粒子运动的方法,常用于物理、化学和材料科学等领域。它是由法国物理学家保罗朗之万(Paul Langevin)于1908年提出的,用于描述布朗运动,即微小粒…...
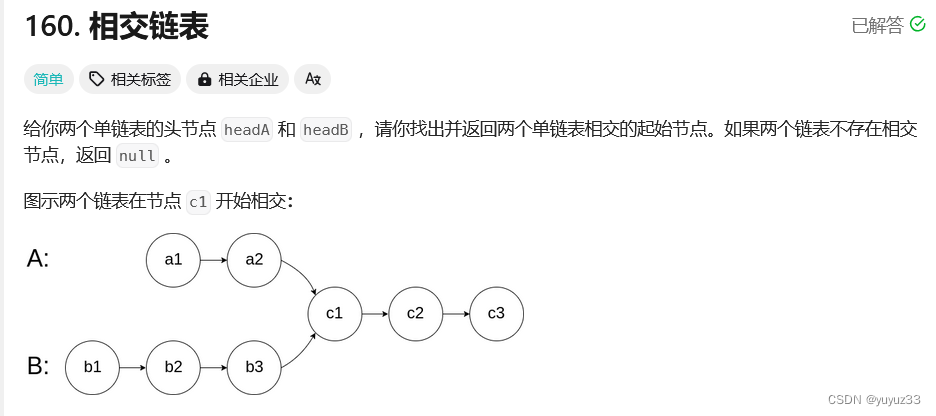
双指针技巧,链表
双指针链表 虚拟头节点双指针,都要用虚拟1头节点 合并两个有序链表 设置双指针,都指向虚拟头节点 ListNode list1 代表的是头节点 class Solution {public ListNode mergeTwoLists(ListNode list1, ListNode list2) {ListNode dummynew ListNode(-1…...

鸿蒙 DevEcoStudio:发布进度条通知
使用notificationManager及wantAgent实现功能import notificationManager from ohos.notificationManager import wantAgent from ohos.app.ability.wantAgent Entry Component struct Index {State message: string 发布进度条通知progressValue: number0async publicDownloa…...

web前端之vue动态访问静态资源、静态资源的动态访问、打包、public、import、URL、Vite
MENU 静态资源与打包规则动态访问静态资源直接导入将静态资存放在public目录中动态导入URL构造函数结束语实践与坑附文 静态资源与打包规则 介绍 Vite脚手架在打包代码的时候,会把源代码里对于静态资源的访问路径转换为打包后静态资源文件的路径。主要的区别是文件指…...
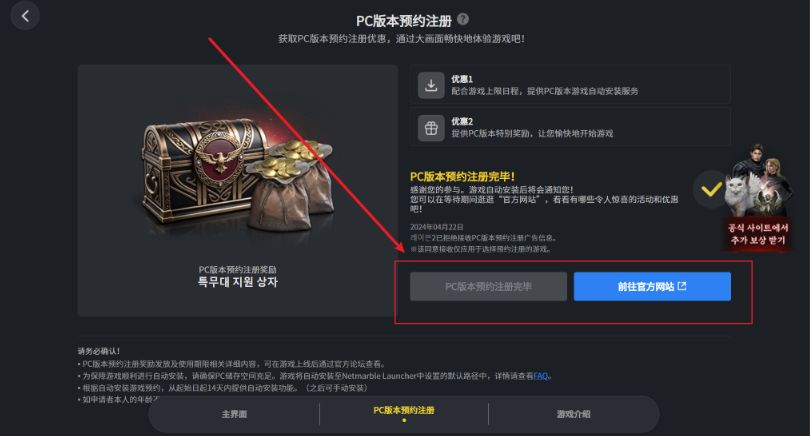
Raven2掠夺者2渡鸦2角色创建、游戏预下载、账号怎么注册教程
《渡鸦2》(Raven 2)是由韩国开发的一款大型多人在线角色扮演游戏(MMORPG)类型的手游,作为前作《Raven》的续集,继承并发展了其黑暗奇幻世界观,同时在游戏设计和内容上进行了大量创新。游戏预计于…...
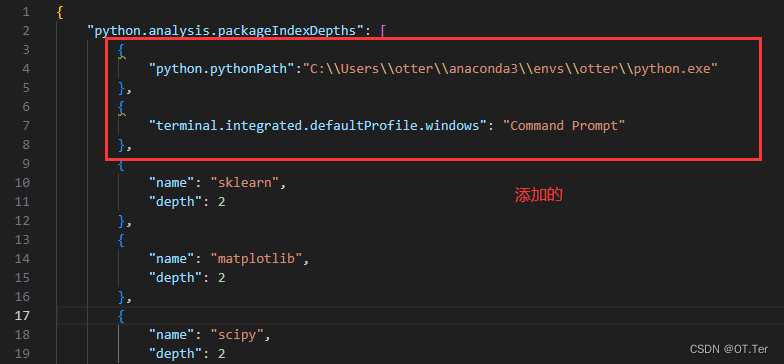
Window VScode配置Conda教程(成功版)
VScode配置Conda 参考博文:https://blog.csdn.net/qq_51831335/article/details/126757014Anaconda安装(注意勾选自动配置环境变量!) 官网:https://www.anaconda.com/download/success VScode配置 python插件安装安装 …...

探索旅行的优惠之选,千益畅行旅游卡让旅程更省心省力!
在旅行的道路上,一张旅游卡往往能为您带来意想不到的便利与优惠。那么,对于千益畅行旅游卡,您是否好奇如何轻松拥有它呢? 首先,千益畅行旅游卡作为旅行者的贴心伴侣,为您提供了多样化的获取渠道。您可以通…...
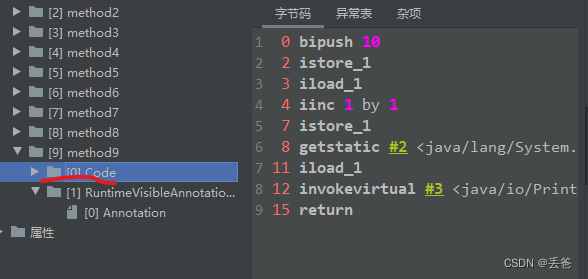
JVM学习-彻底搞懂Java自增++
从字节码角度分析i和i的区别 public void method6() {int i 10;i; //在局部变量表上直接加1}public void method7() {int i 10;i; //字节码同i}public void method8() {int i 10;int a i; //通过下图可以看出先将局部变量表中的值push到操作数栈,然…...
【全开源】民宿酒店预订管理系统(ThinkPHP+uniapp+uView)
民宿酒店预订管理系统 特色功能: 客户管理:该功能可以帮助民宿管理者更加有效地管理客户信息,包括客户的姓名、电话、地址、身份证号码等,并可以在客户的订单中了解客户的消费情况,从而更好地满足客户的需求ÿ…...

Kafka-UI:3分钟快速上手,轻松管理你的Apache Kafka集群
Kafka-UI:3分钟快速上手,轻松管理你的Apache Kafka集群 【免费下载链接】kafka-ui Open-Source Web UI for managing Apache Kafka clusters 项目地址: https://gitcode.com/gh_mirrors/kaf/kafka-ui 你是否曾经为管理Apache Kafka集群而头疼&…...

BBDown实用指南:高效下载B站视频的完整解决方案
BBDown实用指南:高效下载B站视频的完整解决方案 【免费下载链接】BBDown Bilibili Downloader. 一个命令行式哔哩哔哩下载器. 项目地址: https://gitcode.com/gh_mirrors/bb/BBDown BBDown是一个功能强大的命令行式哔哩哔哩视频下载器,专为技术爱…...

Awesome-Dify-Workflow:重新定义AI工作流编排的模块化解决方案
Awesome-Dify-Workflow:重新定义AI工作流编排的模块化解决方案 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/Aweso…...

利用Taotoken模型广场为不同任务选择合适大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同任务选择合适大模型 在实际开发工作中,我们常常面临多种任务需求:有时需要模型…...

Bee 蜂群效应智能体架构
第一章 绪论 1.1 研究背景与问题提出 在通用人工智能(AGI)发展的演进脉络中,传统单体大模型的“规模即智能”范式正面临算力瓶颈、泛化能力受限以及系统脆弱性等多重挑战。这种中心化架构在面对动态、开放的复杂环境时,其自适应与持续学习能力显得尤为不足。在此背景下,…...
——限时开放下载)
DeepSeek+GCP生产就绪 checklist(含IAM最小权限矩阵、VPC Service Controls白名单、审计日志留存合规项)——限时开放下载
更多请点击: https://kaifayun.com 第一章:DeepSeekGCP生产就绪部署全景概览 DeepSeek大模型在Google Cloud Platform(GCP)上的生产就绪部署,需兼顾模型服务化、弹性扩缩容、可观测性、安全合规与成本优化五大核心维度…...

避坑指南:DolphinScheduler Docker部署后,MySQL数据源连不上的几种常见原因及排查
DolphinScheduler Docker部署MySQL数据源连接问题深度排查手册 当你兴冲冲地部署完DolphinScheduler的Docker版本,准备配置MySQL数据源时,突然遭遇"连接失败"的红色警告——这种挫败感我太熟悉了。去年我们团队迁移数据平台时就连续踩了三个坑…...

钠金属负极自校正技术:复合纸基底设计原理与工程实践
1. 项目概述:从“火中取栗”到“驯服烈马”的钠金属负极革新在电池研发领域,金属钠负极一直被视为下一代高能量密度电池的“圣杯”,其理论比容量高达1166 mAh/g,是石墨负极的近三倍,且钠资源储量丰富、成本低廉。然而&…...

CANN hcomm通道获取API
HcclChannelAcquire 【免费下载链接】hcomm HCOMM(Huawei Communication)是HCCL的通信基础库,提供通信域以及通信资源的管理能力。 项目地址: https://gitcode.com/cann/hcomm 产品支持情况 Ascend 950PR/Ascend 950DT:支…...
Pixelle-Video:如何让AI为您的声音创作注入灵魂?
Pixelle-Video:如何让AI为您的声音创作注入灵魂? 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 在AI视频创作的…...