搜索自动补全-elasticsearch实现
1. elasticsearch准备
1.1 拼音分词器
github地址:https://github.com/infinilabs/analysis-pinyin/releases?page=6
必须与elasticsearch的版本相同
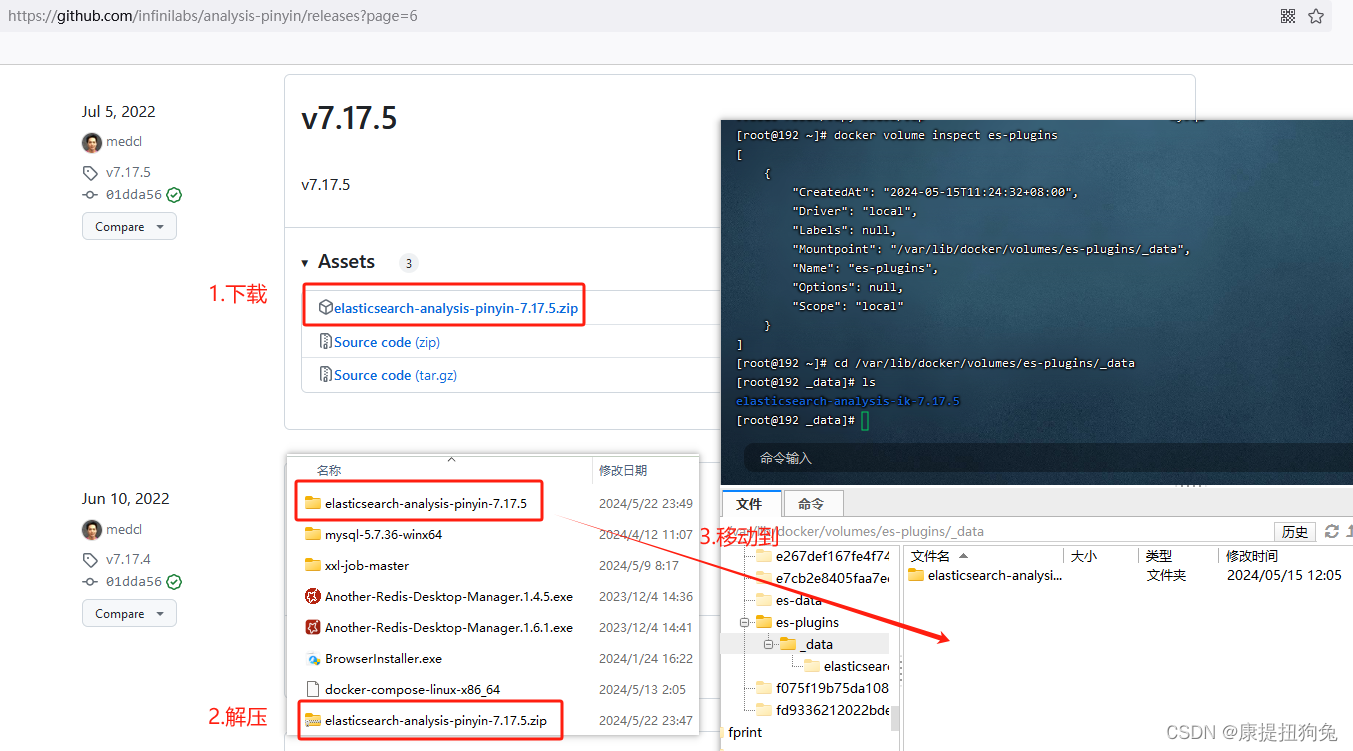 第四步,重启es
第四步,重启es
docker restart es
1.2 定义索引库
PUT /app_info_article
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings":{"properties":{"id":{"type":"long"},"publishTime":{"type":"date"},"layout":{"type":"integer"},"images":{"type":"keyword","index": false},"staticUrl":{"type":"keyword","index": false},"authorId": {"type": "long"},"authorName": {"type": "text"},"title":{"type":"text","analyzer":"text_anlyzer","search_analyzer": "ik_max_word", "copy_to": "all"},"content":{"type":"text","analyzer":"text_anlyzer","search_analyzer": "ik_max_word", "copy_to": "all"},"all":{"type": "text","analyzer": "ik_max_word"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}
1.3 给索引库添加文档
详情参考我的另一篇博客: xxljob分片广播+多线程实现高效定时同步elasticsearch索引库
app_info_article对应的pojo类
@Data
public class SearchArticleVo {// 文章idprivate Long id;// 文章标题private String title;// 文章发布时间private Date publishTime;// 文章布局private Integer layout;// 封面private String images;// 作者idprivate Long authorId;// 作者名词private String authorName;//静态urlprivate String staticUrl;//文章内容private String content;//状态private int enable;//单词自动补全private List<String> suggestion;public void initSuggestion(){suggestion = new ArrayList<String>();suggestion.add(this.title);suggestion.add(this.authorName);}
}
核心代码
@XxlJob("syncIndex")public void syncIndex() {//1、获取任务传入的参数 {"minSize":100,"size":10}String jobParam = XxlJobHelper.getJobParam();Map<String,Integer> jobData = JSON.parseObject(jobParam,Map.class);int minSize = jobData.get("minSize"); //分片处理的最小总数据条数int size = jobData.get("size"); //分页查询的每页条数 小分页//2、查询需要处理的总数据量 total=IArticleClient.searchTotal()Long total = articleClient.searchTotal();//3、判断当前分片是否属于第1片,不属于,则需要判断总数量是否大于指定的数据量[minSize],大于,则执行任务处理,小于或等于,则直接结束任务int cn = XxlJobHelper.getShardIndex(); //当前节点的下标if(total<=minSize && cn!=0){//结束return;}//4、执行任务 [index-范围] 大的分片分页处理//4.1:节点个数int n = XxlJobHelper.getShardTotal();//4.2:当前节点处理的数据量int count = (int) (total % n==0? total/n : (total/n)+1);//4.3:确定当前节点处理的数据范围//从下标为index的数据开始处理 limit #{index},#{count}int indexStart = cn*count;int indexEnd = cn*count+count-1; //最大的范围的最后一个数据的下标//5.小的分页查询和批量处理int index =indexStart; //第1页的indexSystem.out.println("分片个数是【"+n+"】,当前分片下标【"+cn+"】,处理的数据下标范围【"+indexStart+"-"+indexEnd+"】");do {//=============================================小分页================================//5.1:分页查询//5.2:将数据导入ESpush(index,size,indexEnd);//5.3:是否要查询下一页 index+sizeindex = index+size;}while (index<=indexEnd);}/*** 数据批量导入* @param index* @param size* @param indexEnd* @throws IOException*/public void push(int index,int size,int indexEnd) {pool.execute(()->{System.out.println("当前线程处理的分页数据是【index="+index+",size="+(index+size>indexEnd? indexEnd-index+1 : size)+"】");//1)查询数据库数据List<SearchArticleVo> searchArticleVos = articleClient.searchPage(index, index+size>indexEnd? indexEnd-index+1 : size); //size可能越界// 第1页 index=0// indexEnd=6// 第2页 index=5// indexEnd-index+=2//2)创建BulkRequest - 刷新策略BulkRequest bulkRequest = new BulkRequest()//刷新策略-立即刷新.setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE);for (SearchArticleVo searchArticleVo : searchArticleVos) {//A:创建XxxRequestsearchArticleVo.initSuggestion();IndexRequest indexRequest = new IndexRequest("app_info_article")//B:向XxxRequest封装DSL语句数据.id(searchArticleVo.getId().toString()).source(com.alibaba.fastjson.JSON.toJSONString(searchArticleVo), XContentType.JSON);//3)将XxxRequest添加到BulkRequestbulkRequest.add(indexRequest);}//4)使用RestHighLevelClient将BulkRequest添加到索引库if(searchArticleVos!=null && searchArticleVos.size()>0){try {restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();}}});}
在xxl-job任务调度平台执行一次该任务,文档就被添加进去了
如图
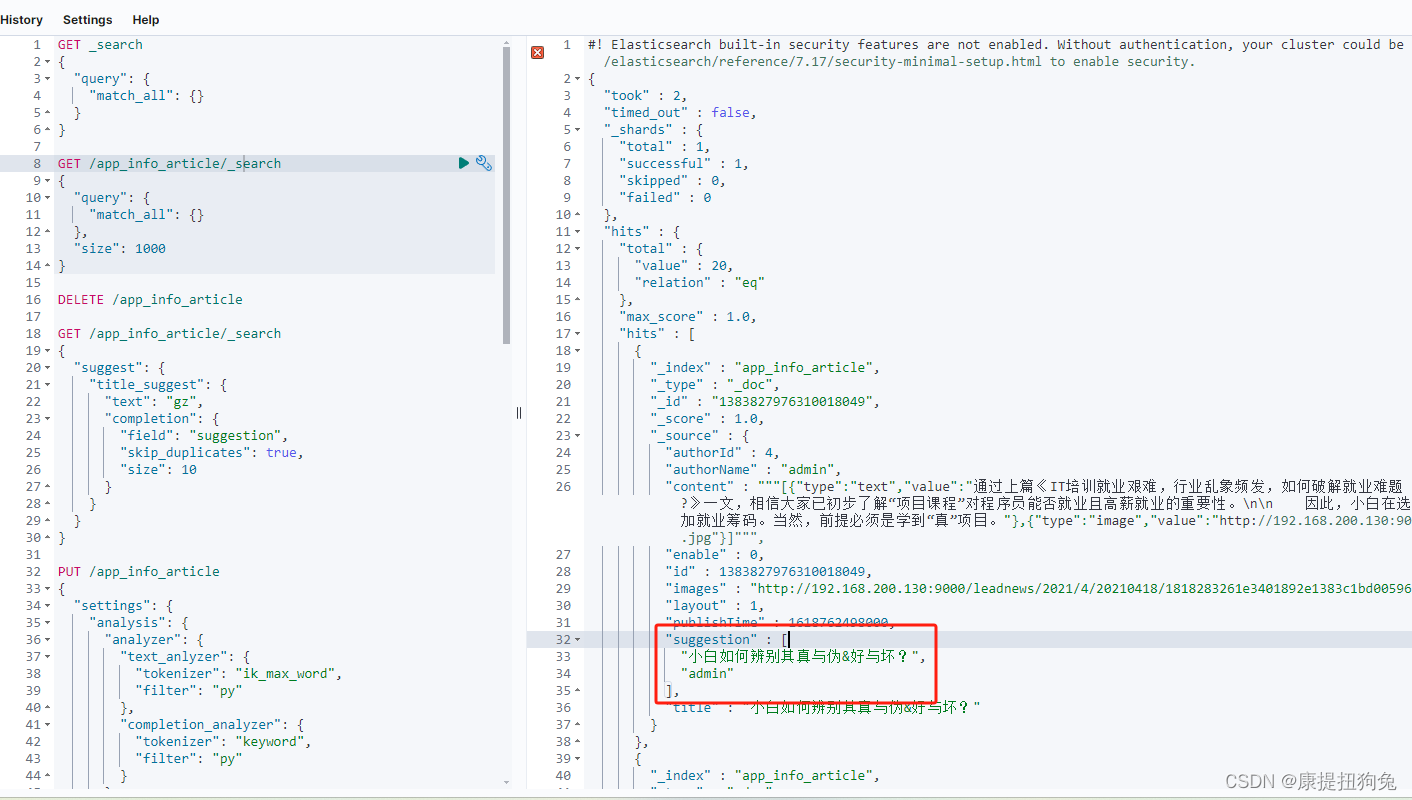
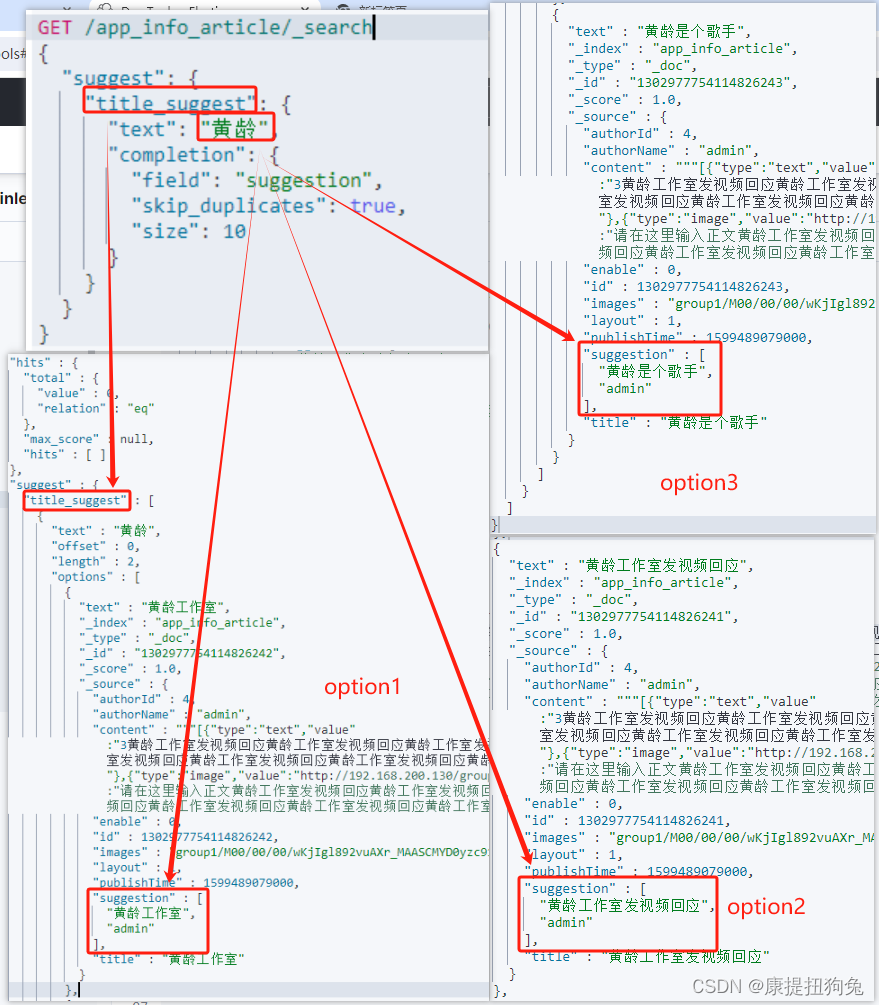
1.4 自动补全查询
// 自动补全查询
GET /test/_search
{"suggest": {"title_suggest": { //设置这个自动查询操作的名称"text": "java", // 关键字"completion": {"field": "suggestion", // 补全查询的字段名"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
示例1.

示例2.
2. 代码流程
2.1 核心业务代码
AssociateController
@RestController
@RequestMapping(value = "/api/v1/associate")
public class AssociateController {@Autowiredprivate AssociateService associateService;/**** 单词自动补全*/@PostMapping(value = "/search")public ResponseResult search(@RequestBody UserSearchDto dto) throws IOException {return associateService.search(dto);}
}
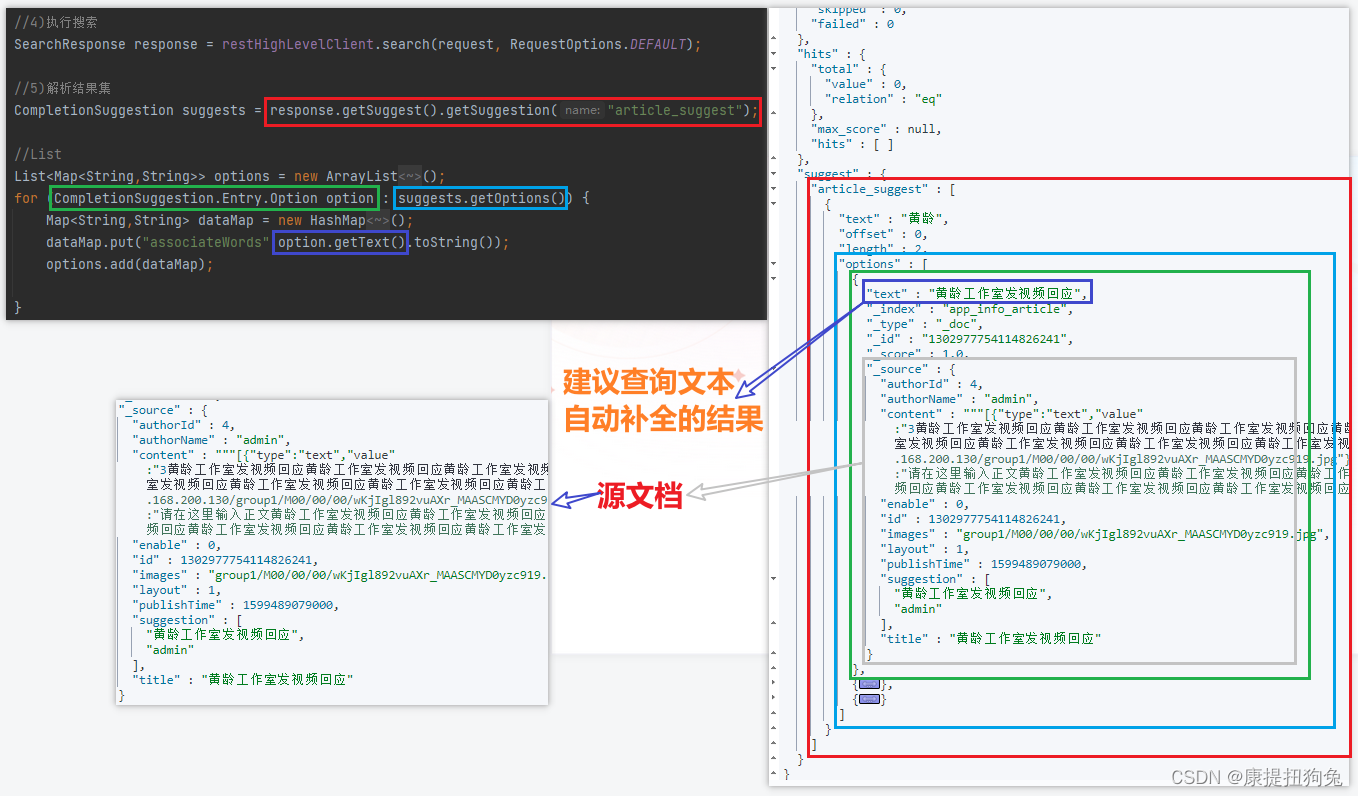
核心search方法
@Autowiredprivate RestHighLevelClient restHighLevelClient;/**** 单词自动补全* @param dto* @return*/@Overridepublic ResponseResult search(UserSearchDto dto) throws IOException {//1)新建一个SearchRequestSearchRequest request = new SearchRequest("app_info_article");//2)创建一个单词自动补全配置 Suggest,给它取个别名request.source().suggest(new SuggestBuilder().addSuggestion(//给它取个别名"article_suggest",SuggestBuilders//指定查询的字段.completionSuggestion("suggestion")//去重.skipDuplicates(true)//搜索的前缀.prefix(dto.getSearchWords()).size(10)));//4)执行搜索SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);//5)解析结果集CompletionSuggestion suggests = response.getSuggest().getSuggestion("article_suggest");//ListList<Map<String,String>> options = new ArrayList<Map<String,String>>();for (CompletionSuggestion.Entry.Option option : suggests.getOptions()) {Map<String,String> dataMap = new HashMap<String,String>();dataMap.put("associateWords",option.getText().toString());options.add(dataMap);}return ResponseResult.okResult(options);}
结果集解析

2.2 测试
请求url:http://127.0.0.1:8801/app/search/api/v1/associate/search/
其中/app/search为nginx和gateway处理过
-
测试1
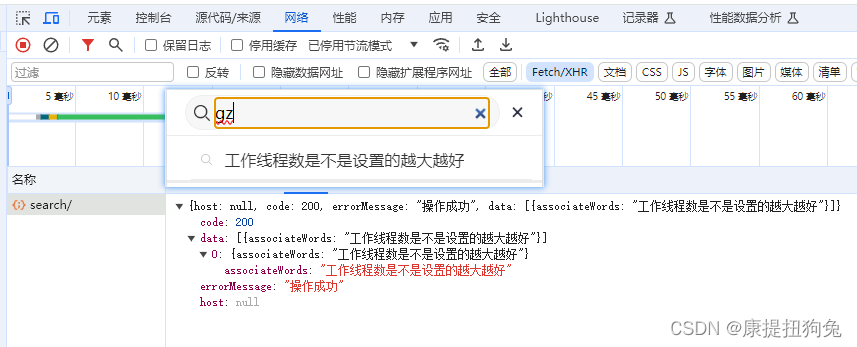
-
测试2
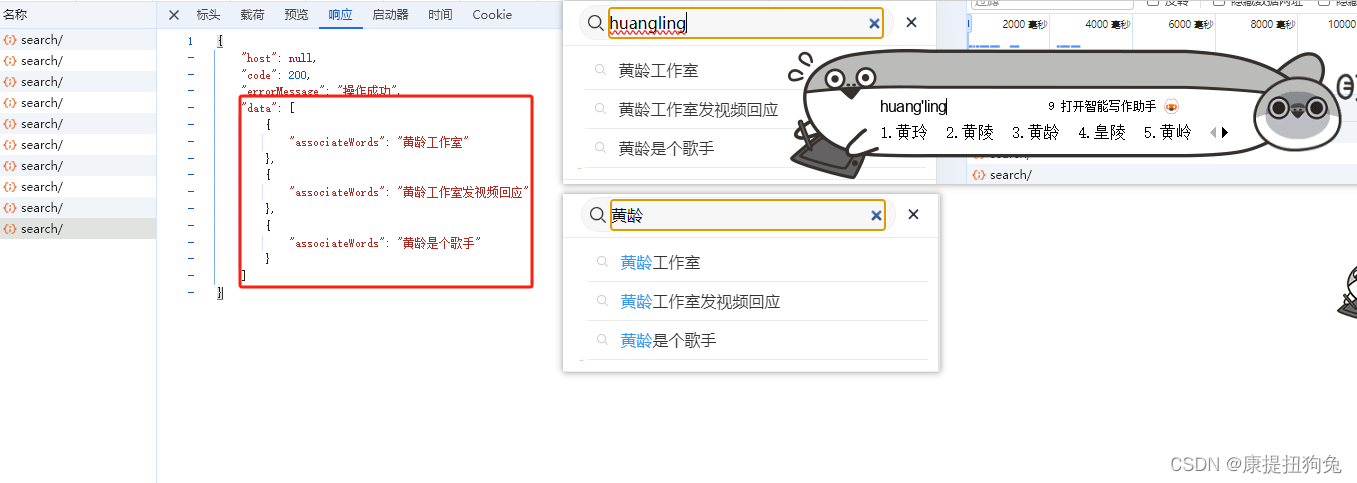
ps:联想词中的蓝色高亮是前端处理的。 -
测试3
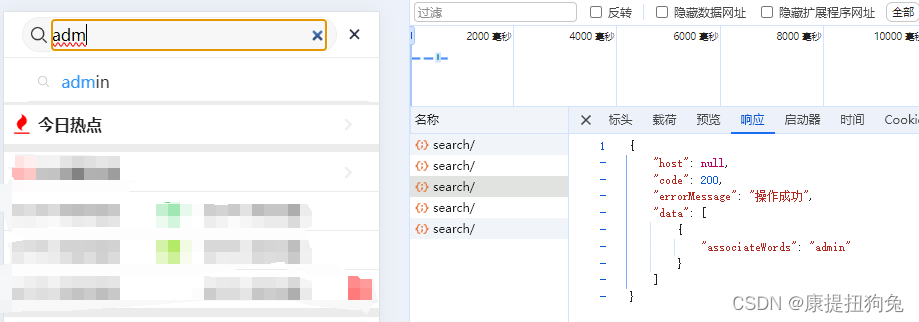
相关文章:
搜索自动补全-elasticsearch实现
1. elasticsearch准备 1.1 拼音分词器 github地址:https://github.com/infinilabs/analysis-pinyin/releases?page6 必须与elasticsearch的版本相同 第四步,重启es docker restart es1.2 定义索引库 PUT /app_info_article {"settings": …...

连接远程的kafka【linux】
# 连接远程的kafka【linux】 前言版权推荐连接远程的kafka【linux】一、开放防火墙端口二、本地测试是否能访问端口三、远程kafka配置四、开启远程kakfa五、本地测试能否连接远程六、SpringBoot测试连接 遇到的问题最后 前言 2024-5-14 18:45:48 以下内容源自《【linux】》 仅…...
简单的 Cython 示例
1, pyx文件 fibonacci.pyx def fibonacci_old(n):if n < 0:return 0elif n 1:return 1else:return fibonacci_old(n-1) fibonacci_old(n-2) 2,setup.py setup.py from setuptools import setup from Cython.Build import cythonizesetup(ext_mod…...

Laravel时间处理类Carbon
时间和日期处理是非常常见的任务。Carbon 是一个功能强大的 PHP 扩展包,它为我们提供了许多方便的方法来处理日期和时间。在 Laravel 中,你无需单独安装 Carbon,因为 Laravel 默认已经包含了它。如果你正在使用 Laravel,那么你已经…...

2024年5月软考架构题目回忆分享
十年架构两茫茫 ,Redis , UML 夜来幽梦忽还乡 , 大数据, Lambda 选择题 1.需求分析和架构设计面临这两个不同对象,一个是问题空间,一个是解空间 这是英文题,总共五个题目,只记得这么多 2. …...

香橙派 AIpro开发板初上手
一、香橙派 AIpro开箱 最近拿到了香橙派 AIpro(OrangePi AIpro),下面就是里面的板子和相关的配件。包含主板、散热组件、电源适配器、双C口电源线、32GB SD卡。我手上的这个是8G LPDDR4X运存的版本。 OrangePi AIpro开发板是一款由香橙派与华…...

如何使用DotNet-MetaData识别.NET恶意软件源码文件元数据
关于DotNet-MetaData DotNet-MetaData是一款针对.NET恶意软件的安全分析工具,该工具专为蓝队研究人员设计,可以帮助广大研究人员轻松识别.NET恶意软件二进制源代码文件中的元数据。 工具架构 当前版本的DotNet-MetaData主要由以下两个部分组成…...

LeetCode---栈与队列
232. 用栈实现队列 请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(push、pop、peek、empty): 实现 MyQueue 类: void push(int x) 将元素 x 推到队列的末尾int pop() 从队列的开头移除并返回元素int pee…...

【教程】利用API接口添加本站同款【每日新闻早早报】-每天自动更新,不占用文章数量
本次分享的是给网站添加一个每日早报的文章,可以看到本站置顶上面还有一个日更的日报,这是利用ALAPI的接口完成的!利用接口有利也有弊,因为每次用户访问网站的时候就会增加一次API接口请求,导致文章的请求会因为请求量…...

僵尸进程,孤儿进程,守护进程
【一】僵尸进程 1.僵尸进程是指完成自己的任务之后,没有被父进程回收资源,占用系统资源,对计算机有害,应该避免 """ 所有的子进程在运行结束之后都会变成僵尸进程(死了没死透)还保留着pid和一些运行过程的中的记录便于主进程查看(短时间…...
Nuxt3 中使用 ESLint
# 快速安装 使用该命令安装的同时会给依赖、内置模块同时更新 npx nuxi module add eslint安装完毕后,nuxt.config.ts 文件 和 package.json 文件 会新增代码段: # nuxt.config.ts modules: ["nuxt/eslint" ] # package.json "devDep…...
【Jmeter】性能测试之压测脚本生成,也可以录制接口自动化测试场景
准备工作-10分中药录制HTTPS脚本,需配置证书 准备工作-10分中药 以https://www.baidu.com/这个地址为录制脚本的示例。 录制脚本前的准备工作当然是得先把Jmeter下载安装好、JDK环境配置好、打开Jmeter.bat,打开cmd,输入ipconfig,…...
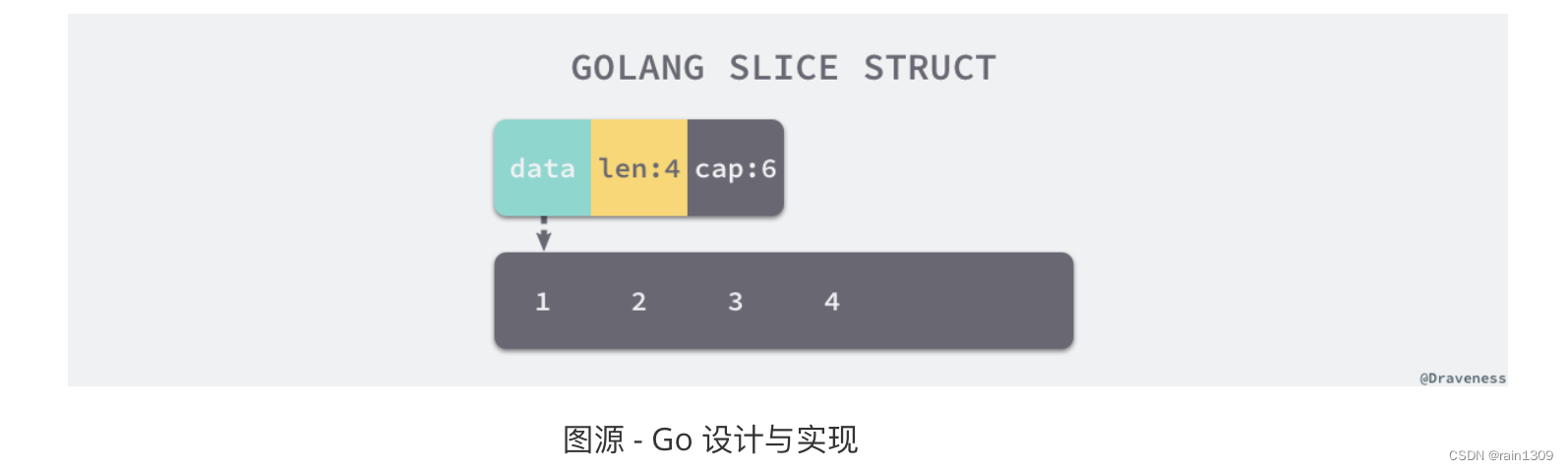
Go 编程技巧:零拷贝字符串与切片转换的高效秘籍
前言 在深入探讨Go语言中字符串与切片类型转换的高效方法之前,让我们先思考一个关键问题:如何在不进行内存拷贝的情况下,实现这两种数据类型之间的无缝转换?本文将详细解析Go语言中字符串(字符类型)和切…...

音视频开发—FFmpeg 音频重采样详解
音频重采样(audio resampling)是指改变音频信号的采样率的过程。采样率(sample rate)是指每秒钟采集的音频样本数,通常以赫兹(Hz)或每秒样本数(samples per second)表示。…...

统计本地端口占用情况
要查看MongoDB是否正在备份,可以通过以下几种方法: 查看MongoDB的进程列表: 使用命令ps -ef | grep mongo,这将列出所有正在运行的MongoDB进程。在输出的列表中,你可以查看是否有与备份相关的进程或任务正在运行。 查…...
-查询优化(9)-外部联接优化)
【MySQL精通之路】SQL优化(1)-查询优化(9)-外部联接优化
主博客: 【MySQL精通之路】SQL优化(1)-查询优化-CSDN博客 上一篇: 【MySQL精通之路】SQL优化(1)-查询优化(8)-嵌套联接优化-CSDN博客 下一篇: 【MySQL精通之路】SQL优化(1)-查询优化(10)-外部联接简化-CSDN博客 外部联接包括LEFT JOIN和…...

Python应用开发——30天学习Streamlit Python包进行APP的构建(1)
关于 #30天学Streamlit #30天学Streamlit 是一个旨在帮助你学习构建 Streamlit 应用的编程挑战。 你将学会: 如何搭建一个编程环境用于构建 Streamlit 应用构建你的第一个 Streamlit 应用学习所有好玩的、能用在 Streamlit 应用里的输入输出组件🗓️ 天 1 设置本地开发环境…...
轻兔推荐 —— 一个好用的软件服务推荐平台
给大家推荐一个好用的的软件服务推荐平台:轻兔推荐 网站界面简洁大方,没有太多杂七杂八的功能和页面,有明暗主题色可以选择,默认为亮色,可在网站上方手动切换。 每工作日都会推荐一款软件,有时会加更&…...
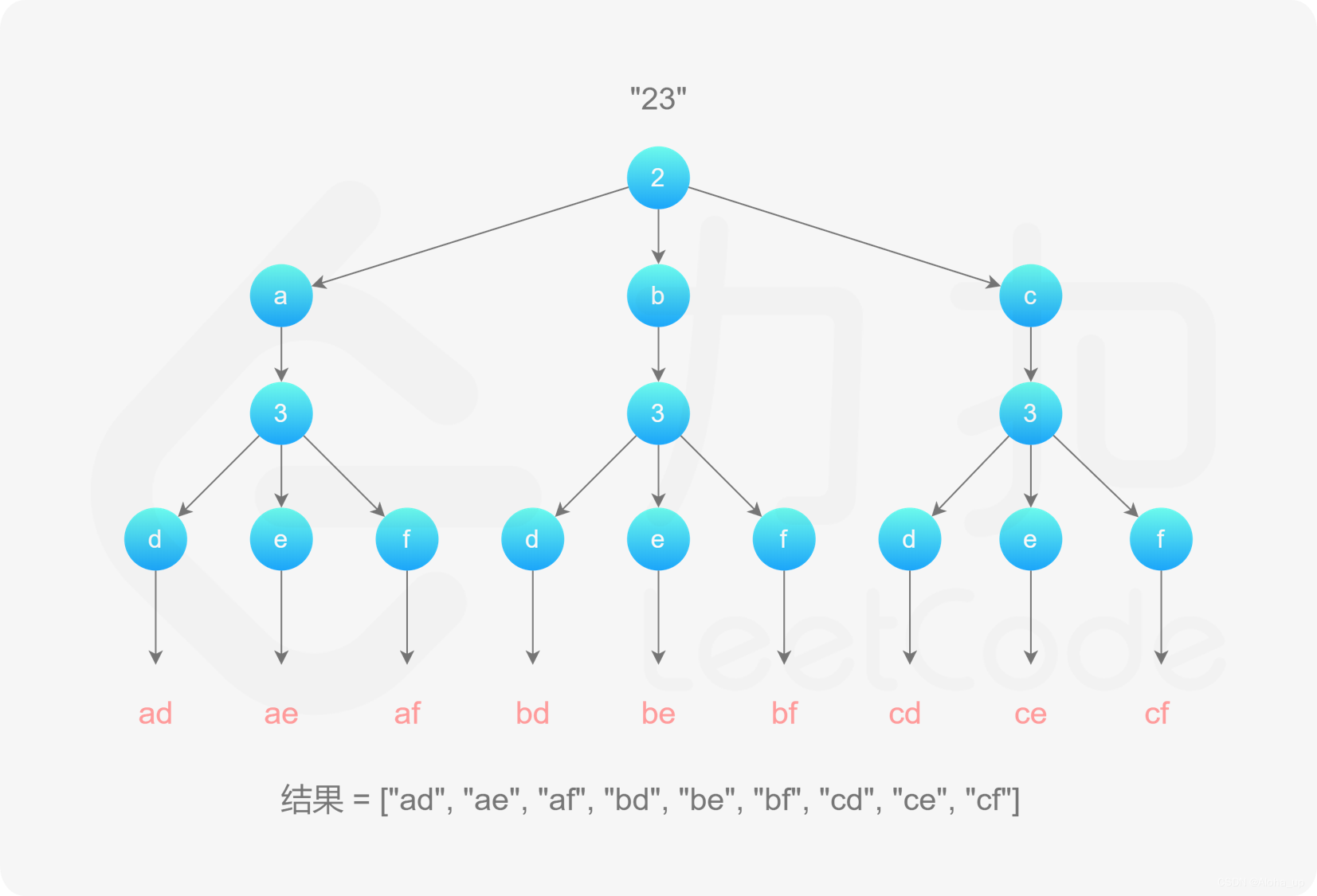
LeetCode hot100-57-G
17. 电话号码的字母组合 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。不会,放IDEA里执行了一下大概理解了流程 …...

基于Vue uni-app的自定义列表表格信息展示组件
摘要:随着软件技术的不断发展,前端开发面临着越来越多的挑战。特别是在业务场景复杂多变的情况下,如何提高开发效率和降低维护成本成为了关键。本文旨在探讨组件化开发在前端应用中的重要性,并以Vue uni-app自定义列表表格为例&am…...

wordpress数据迁移---没有验证
迁移 WordPress 完整数据(文章、页面、媒体、主题、插件、设置、评论、用户),核心是 备份旧站文件 数据库 → 新服务器配置环境 → 上传文件 导入数据库 → 修改配置 替换域名 / URL → 测试。下面分 插件一键迁移(新手推荐&am…...

多任务学习调参新思路:如何让模型自己决定分类和回归任务谁更重要?
多任务学习中的自适应权重分配:让模型学会动态平衡分类与回归任务 想象一下,你正在训练一个自动驾驶系统,它需要同时完成车辆检测(分类任务)和深度估计(回归任务)。传统方法中,你需要…...

三菱FX2N与士林变频器MODBUS通讯实战指南
1. 硬件连接:从零搭建通讯桥梁 第一次接触三菱FX2N和士林变频器的MODBUS通讯时,最让我头疼的就是硬件接线。别看只是几根线,接错了轻则通讯失败,重则烧毁端口。这里分享几个实操中容易踩的坑: 变频器端接线要点&#x…...

探索固定翼无人机编队控制:从高效协同到PX4-Autopilot落地实践
探索固定翼无人机编队控制:从高效协同到PX4-Autopilot落地实践 【免费下载链接】PX4-Autopilot PX4 Autopilot Software 项目地址: https://gitcode.com/gh_mirrors/px/PX4-Autopilot PX4-Autopilot作为开源无人机飞控系统的核心框架,通过模块化设…...

突破安卓HTTPS抓包困境:Xposed+JustTrustMe框架实战指南
1. 为什么HTTPS抓包在安卓上这么难? 最近几年做安全测试的朋友应该深有体会,安卓应用的HTTPS抓包越来越难搞了。我刚开始接触这块时也踩了不少坑,明明在浏览器里能轻松抓到的HTTPS请求,到了APP里就死活抓不到。后来才发现…...

为什么你的Ubuntu实时内核编译失败了?PREEMPT_RT补丁的5个关键配置解析
为什么你的Ubuntu实时内核编译失败了?PREEMPT_RT补丁的5个关键配置解析 在工业自动化、机器人控制和金融交易等对延迟敏感的领域,毫秒级的响应差异可能直接影响系统可靠性。许多开发者选择Ubuntu搭配PREEMPT_RT补丁构建实时系统,却在编译阶段…...

突破语言壁垒:FigmaCN开源插件让设计界面全中文呈现
突破语言壁垒:FigmaCN开源插件让设计界面全中文呈现 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 作为一名设计师,你是否也曾在使用Figma时因全英文界面而频繁…...

3款高效AI答题工具助力B站硬核会员试炼
3款高效AI答题工具助力B站硬核会员试炼 【免费下载链接】bili-hardcore bilibili 硬核会员 AI 自动答题脚本,直接调用 B 站 API,非 OCR 实现 项目地址: https://gitcode.com/gh_mirrors/bi/bili-hardcore B站硬核会员试炼要求用户在100道专业题目…...
)
项目7-5 单表数据记录查询—— 任务7.6.6 查询结果不重复、7.6.7 范围查询、7.6.8 字符匹配查询(二)
项目7-4 单表数据记录查询—— 任务7.6.6 查询结果不重复、7.6.7 范围查询、7.6.8 字符匹配查询(二) 一、教学目标【2分钟】 **二、课程导入【4分钟】** **三、核心内容讲解** **【第一部分:概念讲解】用大白话理解三个关键字** **【第二部分:实操演示】** **四、课堂小结与…...

新手福音:借助快马AI生成代码,轻松入门天天直播应用开发
作为一个刚入门前端开发的新手,想尝试直播类应用开发时,面对复杂的技术栈和交互逻辑常常无从下手。最近我发现用InsCode(快马)平台可以快速生成可运行的学习项目,就以"天天直播"为例记录下我的实践过程。 项目结构设计 整个直播页面…...