【强化学习05】从Q学习到深度Q学习
深度Q学习(Deep Q-Learning, DQN)是将深度学习与Q学习结合起来的一种强化学习方法,利用神经网络来近似Q值函数,解决传统Q学习在大规模或连续状态空间中的局限性。下面详细解释DQN的机理。
背景知识
Q学习
Q学习是一种值函数法,它通过学习Q值(状态-动作值)来评估在某个状态下执行某个动作的长期回报。Q学习更新Q值的核心公式为:
Q ( s , a ) ← Q ( s , a ) + α [ r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) ] Q(s, a) \leftarrow Q(s, a) + \alpha \left[ r + \gamma \max_{a'} Q(s', a') - Q(s, a) \right] Q(s,a)←Q(s,a)+α[r+γmaxa′Q(s′,a′)−Q(s,a)]
其中:
- s s s和 a a a分别是当前状态和动作。
- r r r是即时奖励。
- s ′ s' s′是执行动作 a a a后的下一个状态。
- α \alpha α是学习率。
- γ \gamma γ是折现因子。
深度神经网络
深度神经网络(DNN)是一种多层神经网络,能够从大量数据中学习复杂的特征表示。DNN在图像识别、自然语言处理等领域表现优异。
深度Q学习(DQN)
DQN的核心思想是使用深度神经网络来近似Q值函数,即用神经网络参数 θ \theta θ表示Q值函数 Q ( s , a ; θ ) Q(s, a; \theta) Q(s,a;θ)。
关键组件
-
经验回放(Experience Replay)
- 存储代理在环境中经历的每一个转换(状态,动作,奖励,下一个状态)到一个固定大小的经验池中。
- 从经验池中随机抽取小批量(mini-batch)样本进行训练,打破样本间的相关性,提高训练的稳定性。
-
目标网络(Target Network)
- 使用两个神经网络:一个是当前Q网络(Q-Network),另一个是目标Q网络(Target Q-Network)。
- 目标Q网络的参数 θ − \theta^- θ−定期复制当前Q网络的参数 θ \theta θ,减少训练的不稳定性。
DQN算法步骤
-
初始化:
- 初始化经验回放池 D D D。
- 初始化Q网络参数 θ \theta θ。
- 初始化目标Q网络参数 θ − = θ \theta^- = \theta θ−=θ。
-
重复以下步骤直到收敛:
-
环境交互:
- 根据当前策略(例如 ε-greedy 策略)在状态 s s s下选择动作 a a a。
- 执行动作 a a a,观察即时奖励 r r r和下一个状态 s ′ s' s′。
- 将转换 ( s , a , r , s ′ ) (s, a, r, s') (s,a,r,s′)存储到经验回放池 D D D中。
-
经验回放:
- 从经验池中随机抽取一个小批量样本 ( s i , a i , r i , s i ′ ) (s_i, a_i, r_i, s'_i) (si,ai,ri,si′)。
- 计算目标Q值 y i y_i yi:
y i = { r i if s i ′ is terminal r i + γ max a ′ Q ( s i ′ , a ′ ; θ − ) otherwise y_i = \begin{cases} r_i & \text{if$s'_i$is terminal} \\ r_i + \gamma \max_{a'} Q(s'_i, a'; \theta^-) & \text{otherwise} \end{cases} yi={riri+γmaxa′Q(si′,a′;θ−)ifsi′is terminalotherwise - 通过最小化均方误差(MSE)损失函数更新Q网络参数 θ \theta θ:
L ( θ ) = E ( s i , a i , r i , s i ′ ) ∼ D [ ( y i − Q ( s i , a i ; θ ) ) 2 ] L(\theta) = \mathbb{E}_{(s_i, a_i, r_i, s'_i) \sim D} \left[ \left( y_i - Q(s_i, a_i; \theta) \right)^2 \right] L(θ)=E(si,ai,ri,si′)∼D[(yi−Q(si,ai;θ))2]
-
更新目标网络:
- 每隔固定的步数,将Q网络参数复制到目标网络:
θ − = θ \theta^- = \theta θ−=θ
- 每隔固定的步数,将Q网络参数复制到目标网络:
-
深度Q学习与时序差分
在深度Q学习(DQN)中,时序差分方法用于更新Q值,而Q值是通过神经网络进行近似的。时序差分在DQN中的应用体现在以下几个方面:
目标Q值的计算
在传统的Q学习中,Q值的更新依赖于贝尔曼方程,通过TD误差进行更新:
δ = r + γ max a ′ Q ( s ′ , a ′ ) − Q ( s , a ) \delta = r + \gamma \max_{a'} Q(s', a') - Q(s, a) δ=r+γmaxa′Q(s′,a′)−Q(s,a)
在DQN中,这一思想被保留并应用于神经网络的训练中。我们使用目标网络来计算目标Q值,这样可以更稳定地进行更新。
TD误差在DQN中的具体实现
-
经验回放(Experience Replay):
- 从经验池中随机抽取一小批样本 ( s i , a i , r i , s i ′ ) (s_i, a_i, r_i, s'_i) (si,ai,ri,si′)。
-
计算目标Q值(Target Q-Value):
- 对于每个样本,计算目标Q值 y i y_i yi:
y i = { r i if s i ′ is terminal r i + γ max a ′ Q ( s i ′ , a ′ ; θ − ) otherwise y_i = \begin{cases} r_i & \text{if$s'_i$is terminal} \\ r_i + \gamma \max_{a'} Q(s'_i, a'; \theta^-) & \text{otherwise} \end{cases} yi={riri+γmaxa′Q(si′,a′;θ−)ifsi′is terminalotherwise - 这里, θ − \theta^- θ−是目标网络的参数, θ \theta θ是当前Q网络的参数。
- 对于每个样本,计算目标Q值 y i y_i yi:
-
计算TD误差(TD Error):
- TD误差 δ \delta δ由以下公式计算:
δ i = y i − Q ( s i , a i ; θ ) \delta_i = y_i - Q(s_i, a_i; \theta) δi=yi−Q(si,ai;θ)
- TD误差 δ \delta δ由以下公式计算:
-
更新Q网络参数:
- 通过最小化损失函数 L ( θ ) L(\theta) L(θ)来更新Q网络的参数 θ \theta θ:
L ( θ ) = E ( s i , a i , r i , s i ′ ) ∼ D [ ( y i − Q ( s i , a i ; θ ) ) 2 ] L(\theta) = \mathbb{E}_{(s_i, a_i, r_i, s'_i) \sim D} \left[ \left( y_i - Q(s_i, a_i; \theta) \right)^2 \right] L(θ)=E(si,ai,ri,si′)∼D[(yi−Q(si,ai;θ))2] - 这实际上是在最小化TD误差的平方和。
- 通过最小化损失函数 L ( θ ) L(\theta) L(θ)来更新Q网络的参数 θ \theta θ:
优势和挑战
优势
- 处理高维状态空间:DQN利用神经网络能够处理高维度和复杂状态空间。
- 减少样本相关性:经验回放池通过随机抽取样本打破了数据的时间相关性。
- 稳定性:目标网络通过减少训练目标的频繁变化提高了训练的稳定性。
挑战
- 超参数调优:DQN需要仔细调优超参数(如学习率、折现因子、经验池大小等)。
- 训练时间:训练神经网络需要大量的计算资源和时间。
- 探索效率:在复杂环境中,ε-greedy策略可能导致探索效率低下。
总结
深度Q学习(DQN)通过结合深度神经网络和Q学习,能够在复杂和高维度的状态空间中进行有效的强化学习。关键技术包括经验回放和目标网络,这些技术显著提高了训练的稳定性和效率。尽管面临一些挑战,但DQN在许多强化学习任务中表现出色,特别是在游戏和模拟环境中。
相关文章:

【强化学习05】从Q学习到深度Q学习
深度Q学习(Deep Q-Learning, DQN)是将深度学习与Q学习结合起来的一种强化学习方法,利用神经网络来近似Q值函数,解决传统Q学习在大规模或连续状态空间中的局限性。下面详细解释DQN的机理。 背景知识 Q学习 Q学习是一种值函数法&…...

FPGA实现多路并行dds
目录 基本原理 verilog代码 仿真结果 基本原理 多路并行dds,传统DDS的局限性在于输出频率有限。根据奈奎斯特采样定理,单路DDS的输出频率应小于系统时钟频率的一半。但是在很多地方,要使采样率保持一致,所以,为了…...
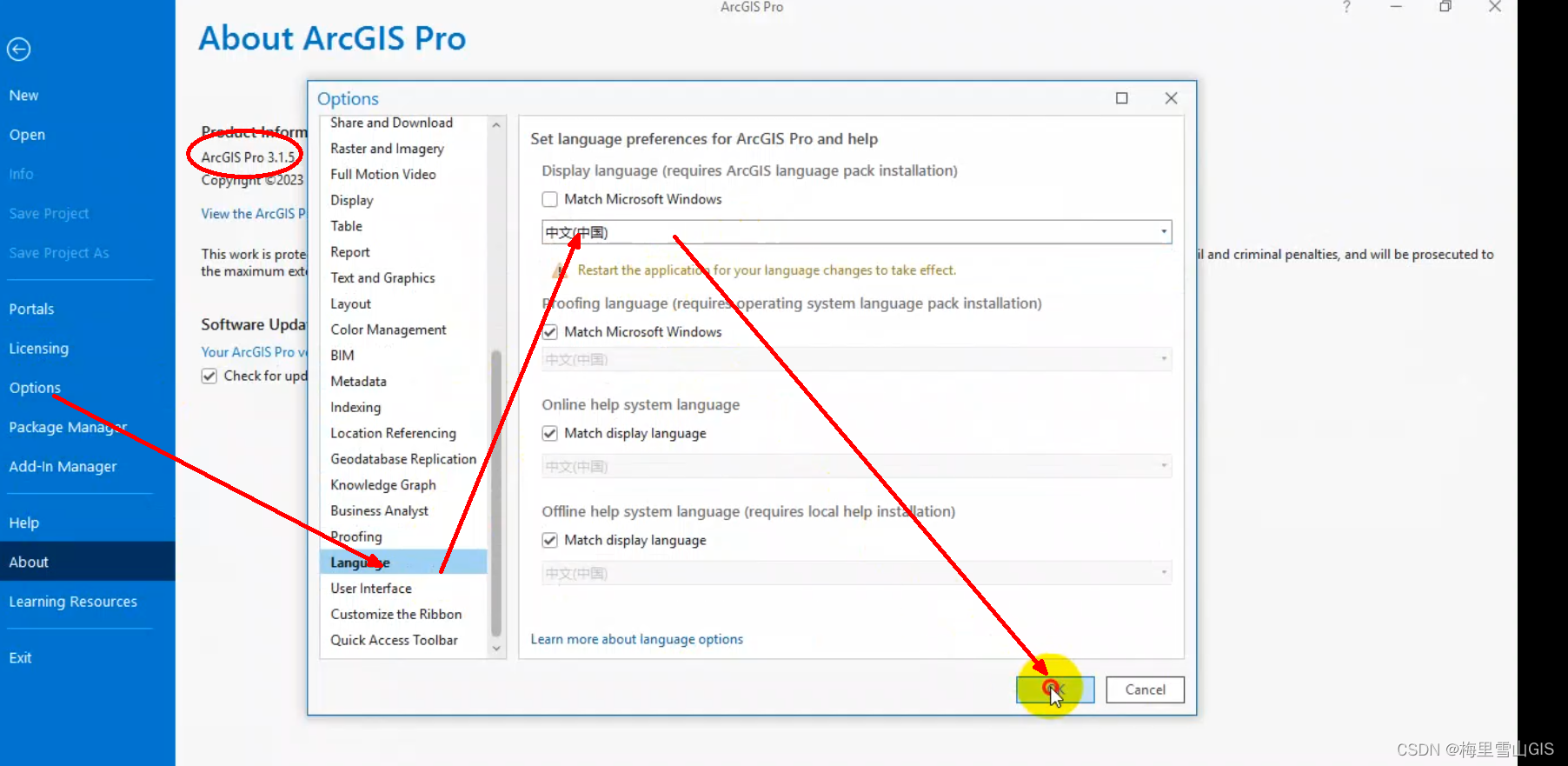
ArcgisPro3.1.5安装手册
ArcgisPro3.1.5安装手册 一、目录介绍: 二、安装教程: (1)安装顺序:最先安装运行环境(runtime6.0.5),接着安装install里面的文件,最后复制path里面的文件替换到软件bin文件夹下即可。 (2)具体安装步骤ÿ…...

三大主流框架
Web前端开发领域中,三大主流框架通常指的是: React:由Facebook开发的一个用于构建用户界面的JavaScript库。React以其组件化、声明式编程和虚拟DOM等特点而广受欢迎,能够高效地更新和渲染大型应用。 Vue.js:由尤雨溪创…...

【C++】:vector容器的底层模拟实现迭代器失效隐藏的浅拷贝
目录 💡前言一,构造函数1 . 强制编译器生成默认构造2 . 拷贝构造3. 用迭代器区间初始化4. 用n个val值构造5. initializer_list 的构造 二,析构函数三,关于迭代器四,有关数据个数与容量五,交换函数swap六&am…...
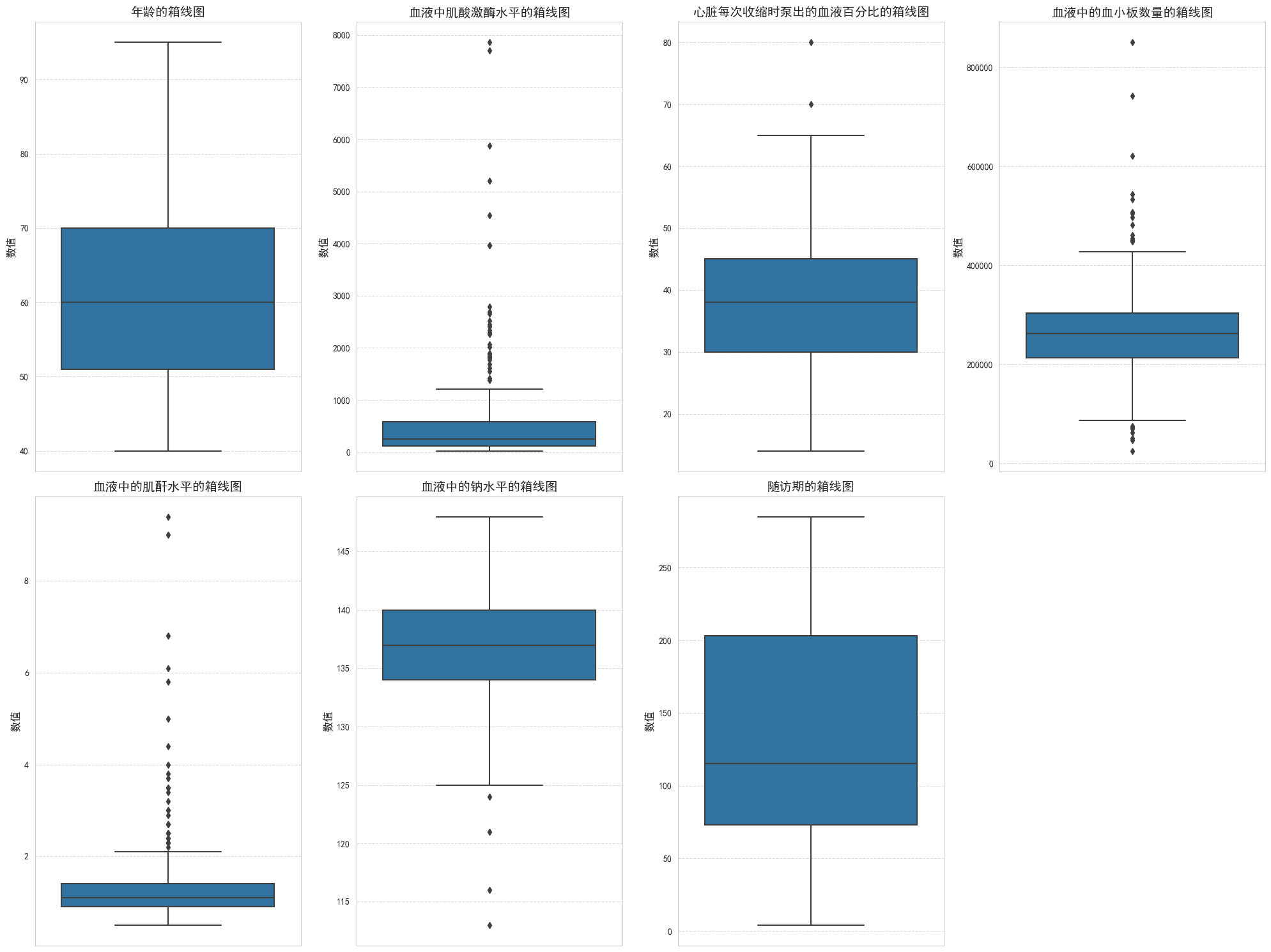
必看项目|多维度揭示心力衰竭患者生存关键因素(生存分析、统计检验、随机森林)
1.项目背景 心力衰竭是一种严重的公共卫生问题,影响着全球数百万人的生活质量和寿命,心力衰竭的病因复杂多样,既有个体生理因素的影响,也受到环境和社会因素的制约,个体的生活方式、饮食结构和医疗状况在很大程度上决定了其心力衰竭的风险。在现代社会,随着生活水平的提…...

centos安装Redis
在CentOS上安装Redis的步骤如下: 使用yum安装依赖库: sudo yum install -y gcc make 下载Redis源码: wget http://download.redis.io/releases/redis-6.0.9.tar.gz 解压Redis源码: tar xzf redis-6.0.9.tar.gz 编译Redis&…...

继承与多态2
2.5(杨.丹尼尔梁英文第11版P537:*13.12)(几何对象的面积求和)写一个方法,将数组中所有几何对象的面积求和。 方法签名是: 公共静态双求和区域(几何对象【】a) 编写一个测试程序&…...

在RT-Thread下为MPU手搓以太网MAC驱动-3
文章目录 MAC驱动支持不同的PHY芯片关于对PHY设备抽象的改进RT-Thread下PHY设备抽象接口的改进关于对PHY设备抽象的改进 这是个人驱动开发过程中做的一些记录,仅代表个人意见和理解,不喜勿喷 MAC驱动需要支持不同的PHY芯片 MAC驱动支持不同的PHY芯片 关…...

Cocos Creator 2D物理引擎的使用详解
前言 Cocos Creator是一款优秀的游戏开发工具,它提供了强大的2D物理引擎,帮助开发者轻松实现游戏中的物理效果。在本文中,我们将详细介绍Cocos Creator中2D物理引擎的使用方法,并通过代码实现来演示其具体应用。 对惹࿰…...
618局外人抖音:别人挤压商家“拼价格”,它默默联合商家“抢用户”?
文|新熔财经 作者|宏一 “618”来临之际,各电商平台和短视频平台早已打响了“促销大战”。不过,今年各大平台都更积极适应新的消费形式,调整了“大促动作”。 比如淘宝、京东带头取消了沿用十年之久的预售机制&…...

【Unity AR开发插件】五、运行示例程序
专栏 本专栏将介绍如何使用这个支持热更的AR开发插件,快速地开发AR应用。 链接: Unity开发AR系列 热更数据制作:制作热更数据-AR图片识别场景 插件简介 通过热更技术实现动态地加载AR场景,简化了AR开发流程,让用户可…...

JavaScript className 类名属性操作
在JavaScript中,可以通过className属性来操作HTML元素的类名。 添加类名:可以使用element.className "className"来添加一个类名到元素中。 var element document.getElementById("myElement"); element.className " newC…...

做场外个股期权怎么询价
做场外个股期权怎么询价?没有具体的哪家做市商是询价是最低的,个人投资者需要通过机构通道方询价进行对比,各券商的报价由询价机构方提供给到投资者,可以参考不同券商的报价进行比对,再决定是否进行投资。本文来自&…...

Databend 开源周报第 146 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 支持 Expressio…...

Android12.0 SIM卡语言自适应
文章目录 需求语言设定Settings中语言切换流程检测到SIM卡,更新系统语言最终修改 需求 要求系统语言跟随SIM卡的语言变化。 语言设定 (1)系统预置语言, 即在makefile中指定的语言 (2)重启, 如果未插卡, 则系统语言为预置的语言 (3)重启插入SIM卡开机, 会自适应为…...

滴滴一季度营收同比增长14.9%至491亿元 经调整EBITA盈利9亿元
【头部财经】5月29日,滴滴在其官网发布2024年一季度业绩报告。一季度滴滴实现总收入491亿元,同比增长14.9%;经调整EBITA(非公认会计准则口径)盈利9亿元。其中,中国出行一季度实现收入445亿元,同…...

C语言 指针——指针变量的定义、初始化及解引用
目录 指针 内存如何编址? 如何对变量进行寻址? 用什么类型的变量来存放变量的地址? 如何显示变量的地址?编辑 使用未初始化的指针会怎样? NULL是什么? 如何访问指针变量指向的存储单元中的数据? 指针变量的…...

详解 Spark 的运行架构
一、核心组件 1. Driver Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作主要负责: 将用户程序转化为作业 (job)在 Executor 之间调度任务 (task)跟踪 Executor 的执行情况通过 UI 展示查询运行情况 2. Exec…...
盲盒小程序开发,为市场带来的新机遇
近年来,盲盒市场一直处于热门行业中,发展非常快速。在互联网的支持下,也衍生出了线上盲盒小程序,实现了线上线下双发展的态势。 盲盒小程序作为一种新的盲盒购物方式,受到了盲盒消费者的喜爱,为盲盒行业的…...

无人机飞控实战:四元数微分方程在PX4中的实现与调参技巧
无人机飞控实战:四元数微分方程在PX4中的实现与调参技巧 当无人机在复杂环境中执行高速机动时,传统欧拉角描述姿态会出现万向节锁死现象。去年调试一台行业级六旋翼时,就曾遇到俯仰角接近90时控制器突然发散的情况——这正是欧拉角奇异点的典…...

intv_ai_mk11作品分享:会议纪要提炼、政策白话解读、技术术语通俗化实例
intv_ai_mk11作品分享:会议纪要提炼、政策白话解读、技术术语通俗化实例 1. 模型简介与核心能力 intv_ai_mk11是一款基于Llama架构的中等规模文本生成模型,特别擅长处理各类文本转换和解释任务。这个开箱即用的解决方案已经完成本地部署,用…...

Ostrakon-VL扫描终端实战:识别冷柜温度计读数并判断是否符合标准
Ostrakon-VL扫描终端实战:识别冷柜温度计读数并判断是否符合标准 1. 项目背景与价值 在零售和餐饮行业中,冷链管理是确保食品安全的关键环节。传统的人工检查冷柜温度方式存在效率低、易出错等问题。Ostrakon-VL扫描终端通过创新的像素风格界面和强大的…...

HunyuanVideo-Foley高算力适配:RTX4090D显存利用率优化至92%实测
HunyuanVideo-Foley高算力适配:RTX4090D显存利用率优化至92%实测 1. 镜像概述与核心优势 HunyuanVideo-Foley私有部署镜像专为视频与音效生成任务深度优化,基于RTX 4090D 24GB显存硬件平台打造。经过CUDA 12.4与驱动550.90.07的针对性调优,…...

双向DC/DC全钒液流蓄电池充放电储能matlab/simulink仿真模型,采用双闭环控制...
双向DC/DC全钒液流蓄电池充放电储能matlab/simulink仿真模型,采用双闭环控制,充放电电流和电压均可控,直流母线端电压可控,电流为负则充电,电流为正则放电,可以控制电流实现充放电。 (1…...

自动驾驶小白必看:航向角、偏航角、前轮转角到底有什么区别?
自动驾驶入门:航向角、偏航角与前轮转角的本质差异与应用解析 刚接触自动驾驶技术时,最让人困惑的莫过于那些描述车辆方向的专业术语——航向角、偏航角、前轮转角,它们看起来相似却又各有所指。理解这些概念不仅是掌握车辆控制的基础&#…...

猫抓插件深度解析:浏览器资源嗅探的终极实战指南
猫抓插件深度解析:浏览器资源嗅探的终极实战指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓插件是一款功能强大的开源浏览器扩…...

Dan Koe: 如果你有多重兴趣,请不要浪费接下来的2-3年
本文整理自 Dan Koe 原文。Dan Koe 是 YouTube、X 等平台拥有数百万粉丝的个人成长领域创作者,以"一人公司"理念、深度内容创作和高效 AI 工作流著称。你是否曾因为无法只专注一件事而感到自责? 你学设计,又想学编程;读…...

Phi-4-mini-reasoning开源大模型教程:免配置镜像+128K长文本推理实战
Phi-4-mini-reasoning开源大模型教程:免配置镜像128K长文本推理实战 1. 模型简介 Phi-4-mini-reasoning是一个轻量级开源大语言模型,专注于高质量推理任务。作为Phi-4模型家族成员,它具备以下核心特点: 推理能力突出࿱…...

Java微服务在Istio中出现“偶发503 no healthy upstream”?7分钟定位Sidecar健康检查盲区与Liveness Probe冲突真相
第一章:Java微服务在Istio中偶发503问题的现象与影响在基于Istio构建的服务网格环境中,Java微服务(尤其是采用Spring Cloud Kubernetes或原生Spring Boot Istio Sidecar部署模式)频繁出现偶发性HTTP 503 Service Unavailable响应…...