LORA微调,让大模型更平易近人
技术背景
最近和大模型一起爆火的,还有大模型的微调方法。
这类方法只用很少的数据,就能让大模型在原本表现没那么好的下游任务中“脱颖而出”,成为这个任务的专家。
而其中最火的大模型微调方法,又要属LoRA。
增加数据量和模型的参数量是公认的提升神经网络性能最直接的方法。目前主流的大模型的参数量已扩展至千亿级别,「大模型」越来越大的趋势还将愈演愈烈。
这种趋势带来了多方面的算力挑战。想要微调参数量达千亿级别的大语言模型,不仅训练时间长,还需占用大量高性能的内存资源。
为了让大模型微调的成本「打下来」,微软的研究人员开发了低秩自适应(LoRA)技术。LoRA 的精妙之处在于,它相当于在原有大模型的基础上增加了一个可拆卸的插件,模型主体保持不变。LoRA 随插随用,轻巧方便。
对于高效微调出一个定制版的大语言模型或者大视觉、大多模态模型来说,LoRA 是最为广泛运用的方法之一,同时也是最有效的方法之一。
LoRA微调原理是对预训练模型进行冻结,并在冻结的前提下,向模型中加入额外的网络层,然后只训练这些新增网络层的参数。因为新增参数数量较少,所以finetune的成本显著下降,同时也能获得和全模型微调类似的效果。
LoRA方法的核心思想是,这些大型模型其实是过度参数化的,其中的参数变化可以视为一个低秩矩阵。因此,可以将这个参数矩阵分解成两个较小的矩阵的乘积。在微调过程中,不需要调整整个大型模型的参数,只需要调整低秩矩阵的参数。
有了LoRA这类型的微调方法,可以使得大模型平易近人,可以让更多小公司或个人使用者能简单的在我们自己的数据集中调优模型,微调得到我们期望的输出。
LoRA 简介
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGEMODELS 该文章在ICLR2022中提出,说的是利用低秩适配(low-rankadaptation)的方法,可以在使用大模型适配下游任务时只需要训练少量的参数即可达到一个很好的效果。
由于 GPU 内存的限制,在训练过程中更新模型权重成本高昂。
例如,假设我们有一个 7B 参数的语言模型,用一个权重矩阵 W 表示。在反向传播期间,模型需要学习一个 ΔW 矩阵,旨在更新原始权重,让损失函数值最小。
权重更新如下:W_updated = W + ΔW。
如果权重矩阵 W 包含 7B 个参数,则权重更新矩阵 ΔW 也包含 7B 个参数,计算矩阵 ΔW 非常耗费计算和内存。
由 Edward Hu 等人提出的 LoRA 将权重变化的部分 ΔW 分解为低秩表示。确切地说,它不需要显示计算 ΔW。相反,LoRA 在训练期间学习 ΔW 的分解表示,如下图所示,这就是 LoRA 节省计算资源的奥秘。
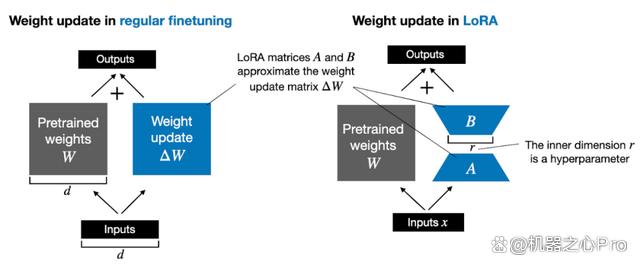
如上所示,ΔW 的分解意味着我们需要用两个较小的 LoRA 矩阵 A 和 B 来表示较大的矩阵 ΔW。如果 A 的行数与 ΔW 相同,B 的列数与 ΔW 相同,我们可以将以上的分解记为 ΔW = AB。(AB 是矩阵 A 和 B 之间的矩阵乘法结果。)
这种方法节省了多少内存呢?还需要取决于秩 r,秩 r 是一个超参数。例如,如果 ΔW 有 10,000 行和 20,000 列,则需存储 200,000,000 个参数。如果我们选择 r=8 的 A 和 B,则 A 有 10,000 行和 8 列,B 有 8 行和 20,000 列,即 10,000×8 + 8×20,000 = 240,000 个参数,比 200,000,000 个参数少约 830 倍。
当然,A 和 B 无法捕捉到 ΔW 涵盖的所有信息,但这是 LoRA 的设计所决定的。在使用 LoRA 时,我们假设模型 W 是一个具有全秩的大矩阵,以收集预训练数据集中的所有知识。当我们微调 LLM 时,不需要更新所有权重,只需要更新比 ΔW 更少的权重来捕捉核心信息,低秩更新就是这么通过 AB 矩阵实现的。
LoRA是怎么去微调适配下游任务的?
流程很简单,LoRA利用对应下游任务的数据,只通过训练新加部分参数来适配下游任务。
而当训练好新的参数后,利用重参的方式,将新参数和老的模型参数合并,这样既能在新任务上到达fine-tune整个模型的效果,又不会在推断的时候增加推断的耗时。
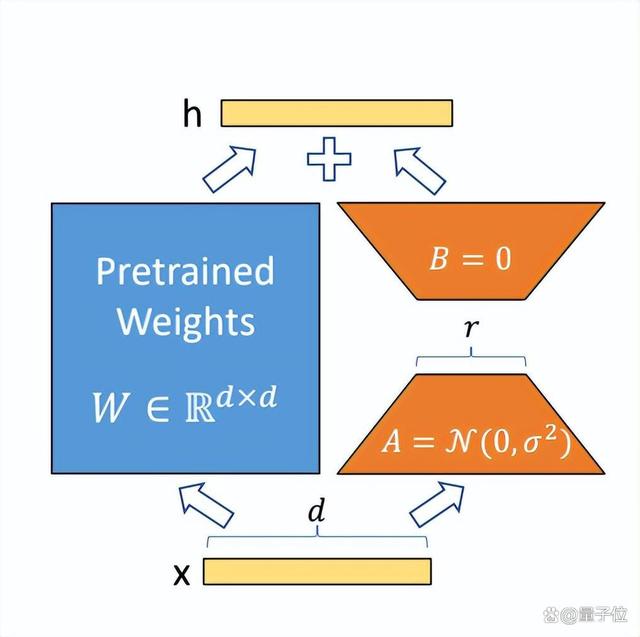
图中蓝色部分为预训练好的模型参数,LoRA在预训练好的模型结构旁边加入了A和B两个结构,这两个结构的参数分别初始化为高斯分布和0,那么在训练刚开始时附加的参数就是0。
A的输入维度和B的输出维度分别与原始模型的输入输出维度相同,而A的输出维度和B的输入维度是一个远小于原始模型输入输出维度的值,这也就是low-rank的体现(有点类似Resnet的结构),这样做就可以极大地减少待训练的参数了。
在训练时只更新A、B的参数,预训练好的模型参数是固定不变的。在推断时可以利用重参数(reparametrization)思想,将AB与W合并,这样就不会在推断时引入额外的计算了。
而且对于不同的下游任务,只需要在预训练模型基础上重新训练AB就可以了,这样也能加快大模型的训练节奏。
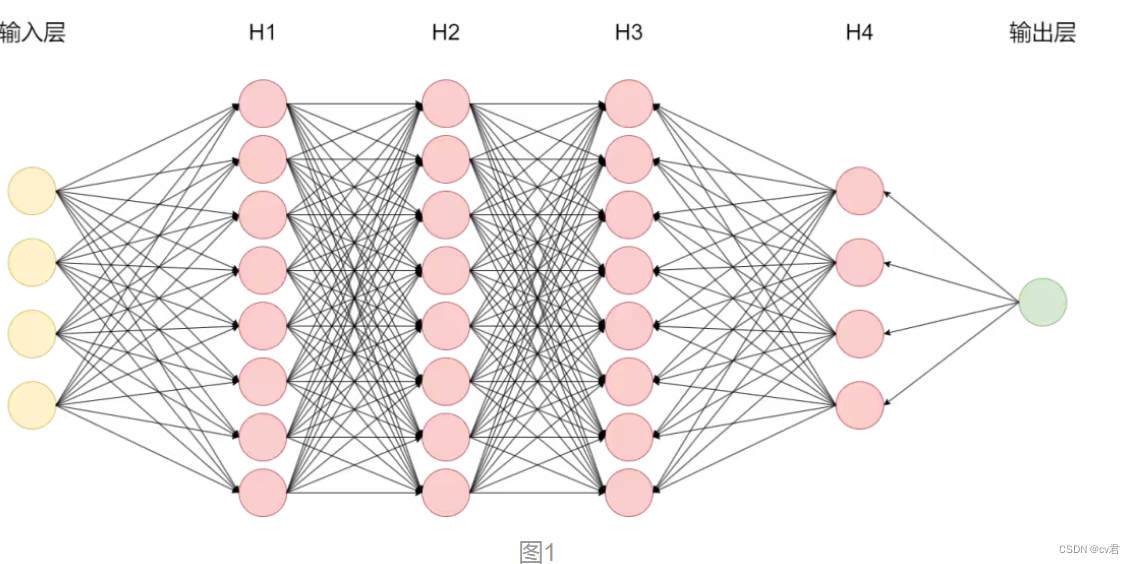
之前在基地的ChatGPT分享中提到过LLM的工作原理是根据输入文本通过模型神经网络中各个节点来预测下一个字,以自回归生成的方式完成回答。
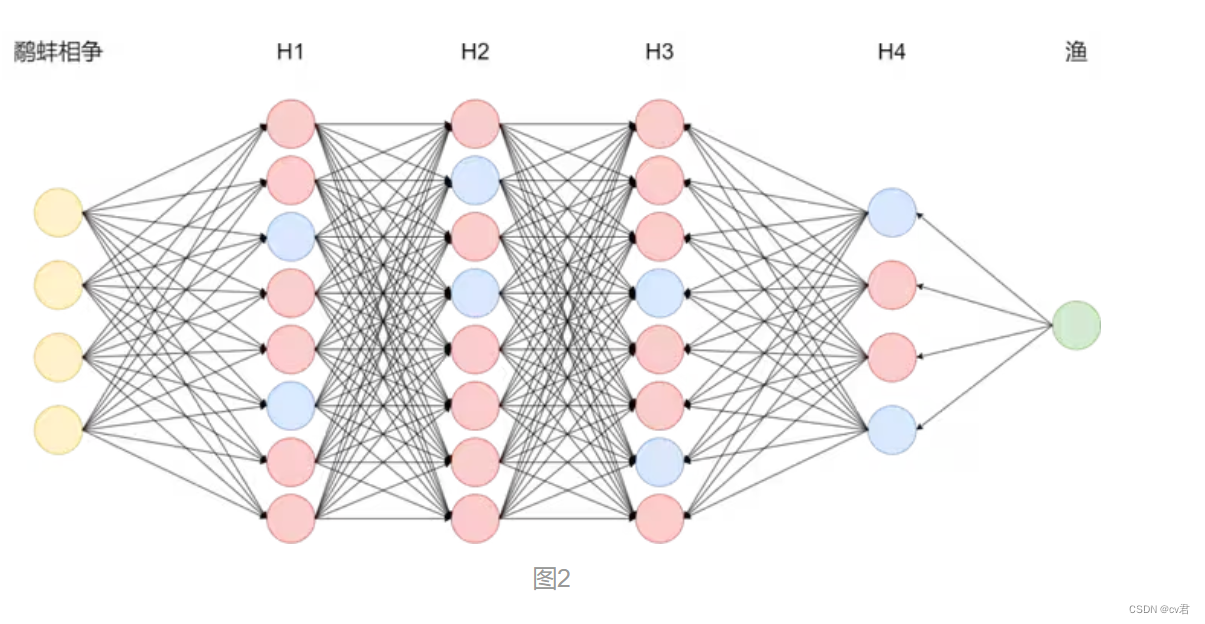
实际上,模型在整个自回归生成过程中决定最终答案的神经网络节点只占总节点的极少一部分。如图1所示为多级反馈神经网络,以输入鹬蚌相争为例,真正参与运算的节点如下图2蓝色节点所示,实际LLM的节点数有数亿之多,我们称之为参数量。 作者:神州数码云基地
神经网络包含许多稠密层,执行矩阵乘法运算。这些层中的权重矩阵通常具有满秩。LLM具有较低的“内在维度”,即使在随机投影到较小子空间时,它们仍然可以有效地学习。
假设权重的更新在适应过程中也具有较低的“内在秩”。对于一个预训练的权重矩阵W0 ∈ Rd×k,我们通过低秩分解W0 + ∆W = W0 + BA来表示其更新,其中B ∈ Rd×r,A ∈ Rr×k,且秩r ≤ min(d,k)。在训练过程中,W0被冻结,不接收梯度更新,而A和B包含可训练参数。需要注意的是,W0和∆W = BA都与相同的输入进行乘法运算,它们各自的输出向量在坐标上求和。前向传播公式如下:h = W0x + ∆Wx = W0x + BAx
在图3中我们对A使用随机高斯随机分布初始化,对B使用零初始化,因此在训练开始时∆W = BA为零。然后,通过αr对∆Wx进行缩放,其中α是r中的一个常数。在使用Adam优化时,适当地缩放初始化,调整α的过程与调整学习率大致相同。因此,只需将α设置为我们尝试的第一个r,并且不对其进行调整。这种缩放有助于在改变r时减少重新调整超参数的需求。
LoRa微调ChatGLM-6B
有时候我们想让模型帮我们完成一些特定任务或改变模型说话的方式和自我认知。作为定制化交付中心的一员,我需要让“他”加入我们。先看一下模型原本的输出。

接下来我将使用LoRa微调将“他”变成定制化交付中心的一员。具体的LoRa微调及微调源码请前往Confluence查看LoRa高效参数微调准备数据集我们要准备的数据集是具有针对性的,例如你是谁?你叫什么?谁是你的设计者?等等有关目标身份的问题,答案则按照我们的需求进行设计,这里列举一个例子

设置参数进行微调
CUDA_VISIBLE_DEVICES=0 python ../src/train_sft.py \--do_train \--dataset self \--dataset_dir ../data \--finetuning_type lora \--output_dir path_to_sft_checkpoint \--overwrite_cache \--per_device_train_batch_size 4 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 5e-5 \--num_train_epochs 3.0 \--plot_loss \--fp16 影响模型训练效果的参数主要有下面几个 lora_rank(int,optional): LoRA 微调中的秩大小。这里并不是越大越好,对于小型数据集如果r=1就可以达到很不错的效果,即便增加r得到的结果也没有太大差别。 lora_alpha(float,optional): LoRA 微调中的缩放系数。 lora_dropout(float,optional): LoRA 微调中的 Dropout 系数。 learning_rate(float,optional): AdamW 优化器的初始学习率。如果设置过大会出现loss值无法收敛或过拟合现象即过度适应训练集而丧失泛化能力,对非训练集中的数据失去原本的计算能力。 num_train_epochs(float,optional): 训练轮数,如果loss值没有收敛到理想值可以增加训练轮数或适当降低学习率。
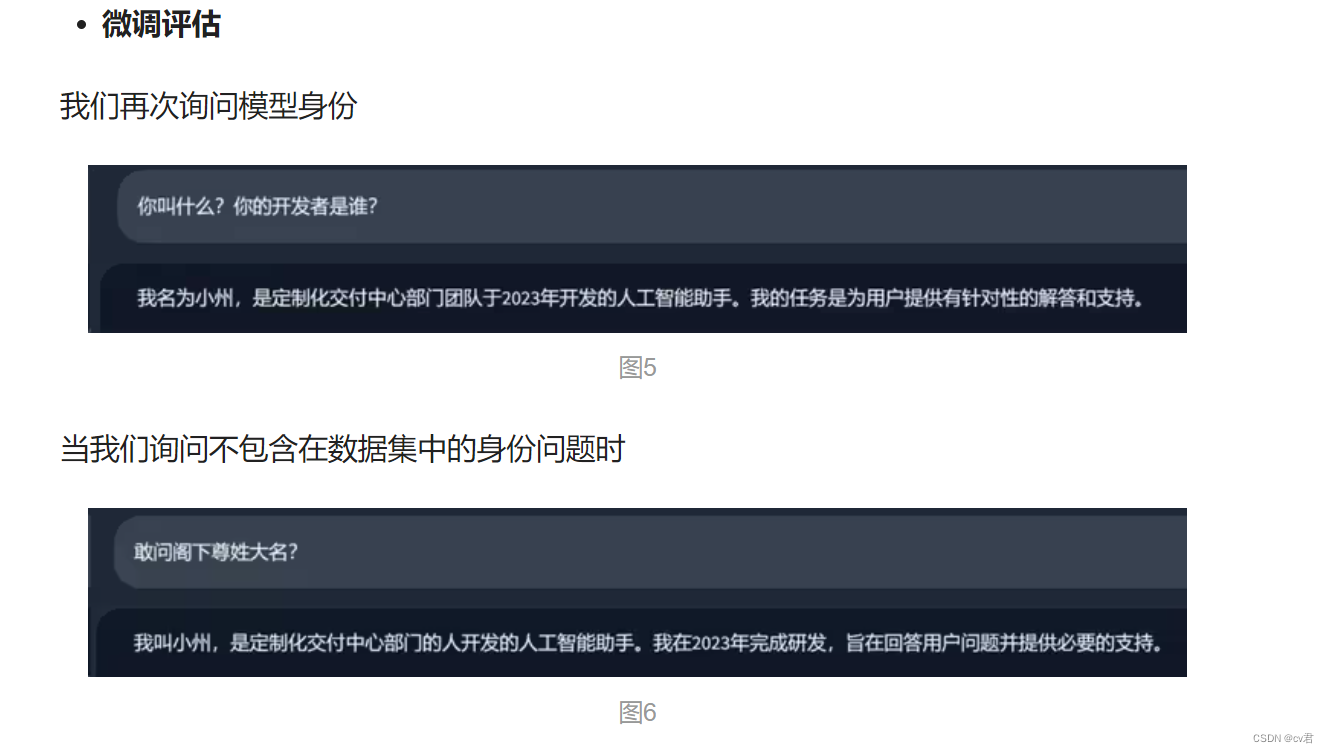
很好,我们得到了理想的回答,这说明“小州”的人设已经建立成功了,换句话说,图二中蓝色节点(身份信息)的权重已经改变了,之后任何关于身份的问题都会是以“小州”的人设进行回答。
LoRA使用
HuggingFace的PEFT(Parameter-Efficient Fine-Tuning)中提供了模型微调加速的方法,参数高效微调(PEFT)方法能够使预先训练好的语言模型(PLMs)有效地适应各种下游应用,而不需要对模型的所有参数进行微调。
对大规模的PLM进行微调往往成本过高,在这方面,PEFT方法只对少数(额外的)模型参数进行微调,基本思想在于仅微调少量 (额外) 模型参数,同时冻结预训练 LLM 的大部分参数,从而大大降低了计算和存储成本,这也克服了灾难性遗忘的问题,这是在 LLM 的全参数微调期间观察到的一种现象PEFT 方法也显示出在低数据状态下比微调更好,可以更好地泛化到域外场景。
例如,使用PEFT-lora进行加速微调的效果如下,从中我们可以看到该方案的优势: 
## 1、引入组件并设置参数
from transformers import AutoModelForSeq2SeqLM
from peft import get_peft_config, get_peft_model, get_peft_model_state_dict, LoraConfig, TaskType
import torch
from datasets import load_dataset
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
from transformers import AutoTokenizer
from torch.utils.data import DataLoader
from transformers import default_data_collator, get_linear_schedule_with_warmup
from tqdm import tqdm
## 2、搭建模型
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
## 3、加载数据
dataset = load_dataset("financial_phrasebank", "sentences_allagree")
dataset = dataset["train"].train_test_split(test_size=0.1)
dataset["validation"] = dataset["test"]
del dataset["test"]
classes = dataset["train"].features["label"].names
dataset = dataset.map(lambda x: {"text_label": [classes[label] for label in x["label"]]},batched=True,num_proc=1,
)
## 4、训练数据预处理
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
def preprocess_function(examples):inputs = examples[text_column]targets = examples[label_column]model_inputs = tokenizer(inputs, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt")labels = tokenizer(targets, max_length=3, padding="max_length", truncation=True, return_tensors="pt")labels = labels["input_ids"]labels[labels == tokenizer.pad_token_id] = -100model_inputs["labels"] = labelsreturn model_inputs
processed_datasets = dataset.map(preprocess_function,batched=True,num_proc=1,remove_columns=dataset["train"].column_names,load_from_cache_file=False,desc="Running tokenizer on dataset",
)
train_dataset = processed_datasets["train"]
eval_dataset = processed_datasets["validation"]
train_dataloader = DataLoader(train_dataset, shuffle=True, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=default_data_collator, batch_size=batch_size, pin_memory=True)
## 5、设定优化器和正则项
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
lr_scheduler = get_linear_schedule_with_warmup(optimizer=optimizer,num_warmup_steps=0,num_training_steps=(len(train_dataloader) * num_epochs),
)
## 6、训练与评估
model = model.to(device)
for epoch in range(num_epochs):model.train()total_loss = 0for step, batch in enumerate(tqdm(train_dataloader)):batch = {k: v.to(device) for k, v in batch.items()}outputs = model(**batch)loss = outputs.losstotal_loss += loss.detach().float()loss.backward()optimizer.step()lr_scheduler.step()optimizer.zero_grad()
model.eval()eval_loss = 0eval_preds = []for step, batch in enumerate(tqdm(eval_dataloader)):batch = {k: v.to(device) for k, v in batch.items()}with torch.no_grad():outputs = model(**batch)loss = outputs.losseval_loss += loss.detach().float()eval_preds.extend(tokenizer.batch_decode(torch.argmax(outputs.logits, -1).detach().cpu().numpy(), skip_special_tokens=True))eval_epoch_loss = eval_loss / len(eval_dataloader)eval_ppl = torch.exp(eval_epoch_loss)train_epoch_loss = total_loss / len(train_dataloader)train_ppl = torch.exp(train_epoch_loss)print(f"{epoch=}: {train_ppl=} {train_epoch_loss=} {eval_ppl=} {eval_epoch_loss=}")
## 7、模型保存
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
model.save_pretrained(peft_model_id)
## 8、模型推理预测
from peft import PeftModel, PeftConfig
peft_model_id = f"{model_name_or_path}_{peft_config.peft_type}_{peft_config.task_type}"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)model = PeftModel.from_pretrained(model, peft_model_id)
model.eval()
inputs = tokenizer(dataset["validation"][text_column][i], return_tensors="pt")
print(dataset["validation"][text_column][i])
print(inputs)
with torch.no_grad():outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=10)print(outputs)print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True))
提问
LoRA 的权重可以组合吗?
答案是肯定的。在训练期间,我们将 LoRA 权重和预训练权重分开,并在每次前向传播时加入。
假设在现实世界中,存在一个具有多组 LoRA 权重的应用程序,每组权重对应着一个应用的用户,那么单独储存这些权重,用来节省磁盘空间是很有意义的。同时,在训练后也可以合并预训练权重与 LoRA 权重,以创建一个单一模型。这样,我们就不必在每次前向传递中应用 LoRA 权重。
weight += (lora_B @ lora_A) * scaling
我们可以采用如上所示的方法更新权重,并保存合并的权重。
同样,我们可以继续添加很多个 LoRA 权重集:
weight += (lora_B_set1 @ lora_A_set1) * scaling_set1weight += (lora_B_set2 @ lora_A_set2) * scaling_set2weight += (lora_B_set3 @ lora_A_set3) * scaling_set3...
我还没有做实验来评估这种方法,但通过 Lit-GPT 中提供的 scripts/merge_lora.py 脚本已经可以实现。
脚本链接:https://github.com/Lightning-AI/lit-gpt/blob/main/scripts/merge_lora.py
-
如果要结合 LoRA,确保它在所有层上应用,而不仅仅是 Key 和 Value 矩阵中,这样才能最大限度地提升模型的性能。
-
调整 LoRA rank 和选择合适的 α 值至关重要。提供一个小技巧,试试把 α 值设置成 rank 值的两倍。
-
14GB RAM 的单个 GPU 能够在几个小时内高效地微调参数规模达 70 亿的大模型。对于静态数据集,想要让 LLM 强化成「全能选手」,在所有基线任务中都表现优异是不可能完成的。想要解决这个问题需要多样化的数据源,或者使用 LoRA 以外的技术。
LoRA可以用于视觉任务吗?
可以的,经常结合stable diffusion等大模型进行微调,在aigc中经常使用,下期我们深入分析lora和lora该如何进行优化。
总结
针对LLM的主流微调方式有P-Tuning、Freeze、LoRa、instruct等等。由于LoRa的并行低秩矩阵几乎没有推理延迟被广泛应用于transformers模型微调,另一个原因是ROI过低,对LLM的FineTune所需要的计算资源不是普通开发者或中小型企业愿意承担的。而LoRa将训练参数减少到原模型的千万分之一的级别使得在普通计算资源下也可以实现FineTune。
相关文章:
LORA微调,让大模型更平易近人
技术背景 最近和大模型一起爆火的,还有大模型的微调方法。 这类方法只用很少的数据,就能让大模型在原本表现没那么好的下游任务中“脱颖而出”,成为这个任务的专家。 而其中最火的大模型微调方法,又要属LoRA。 增加数据量和模…...

LabVIEW全自动样品处理系统有哪些优势?
基于LabVIEW的全自动样品处理系统在现代科研和工业应用中展现出显著的优势,其在数据采集、分析和控制方面的性能使其成为提高效率和精度的理想选择。以下是该系统的详细优势: 高效自动化 LabVIEW的图形化编程语言极大地简化了自动化流程的开发。用户可…...

shell脚本操作http请求的返回值——shell处理json格式数据
日常工作中,我们经常会遇到http请求会返回大量格式固定的数据,而我们只需要其中的一部分,那么怎么提取我们想要的字段呢。 这里会介绍一种用shell脚本处理http请求返回,或者处理json格式数据的方式。 这里我们用到了 jq这个强大的…...

leetcode力扣 300. 最长递增子序列 II
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。 示例 1&#…...

C++_vector简单源码剖析:vector模拟实现
文章目录 🚀1.迭代器🚀2.构造函数与析构函数⚡️2.1 默认构造函数vector()⚡️2.2 vector(int n, const T& value T())⚡️内置类型也有构造函数 ⚡️2.3 赋值重载operator⚡️2.4 通用迭代器拷贝⚡️2.5 vector(initializer_list<T> il)⚡️…...

第3章 数据链路层
王道学习 考纲内容 (一)数据链路层的功能 (二)组帧 (三)差错控制 检错编码;纠错编码 (四)流量控制与可靠传输机制 流量控制、可靠传输与滑动窗口…...

使用OrangePi KunPeng Pro部署AI模型
目录 一、OrangePi Kunpeng Pro简介二、环境搭建三、模型运行环境搭建(1)下载Ollama用于启动并运行大型语言模型(2)配置ollama系统服务(3)启动ollama服务(4)启动ollama(5)查看ollama运行状态四、模型部署(1)部署1.8b的qwen(2)部署2b的gemma(3)部署3.8的phi3(4)部署4b的qwen(5)部…...

SpringMVC 数据映射VC
从 view 层发送请求到Controller,在Controller中获取参数: 在不输入值时会报400,参数错误 在不输入值时num默认为null 没有找到对应标签名称叫nums的,输入任何值时都报400 设置required默认值为false,即使表单没有nums…...
Clickhouse Bitmap 类型操作总结—— Clickhouse 基础篇(四)
文章目录 创建 Bitmap 对象Bitmap 转换为整数数组计算总数(去重)值指定start, end 索引生成子 Bitmap指定 start 索引和数量限制生成子 Bitmap指定偏移量生成子 Bitmap是否包含指定元素两个 Bitmap 是否存在相同元素一个是否为另一个 Bitmap 的子集求最小…...

202474读书笔记|《我自我的田渠归来》——愿你拥有向上的力量,一切的好事都应该有权利发生
202474读书笔记|《我自我的田渠归来》——愿你拥有向上的力量 《我自我的田渠归来》作者张晓风,被称为华语散文温柔的一支笔,她的短文很有味道,角度奇特,温柔慈悲而敏锐。 很幸运遇到了这本书,以她的感受重新认识一些事…...
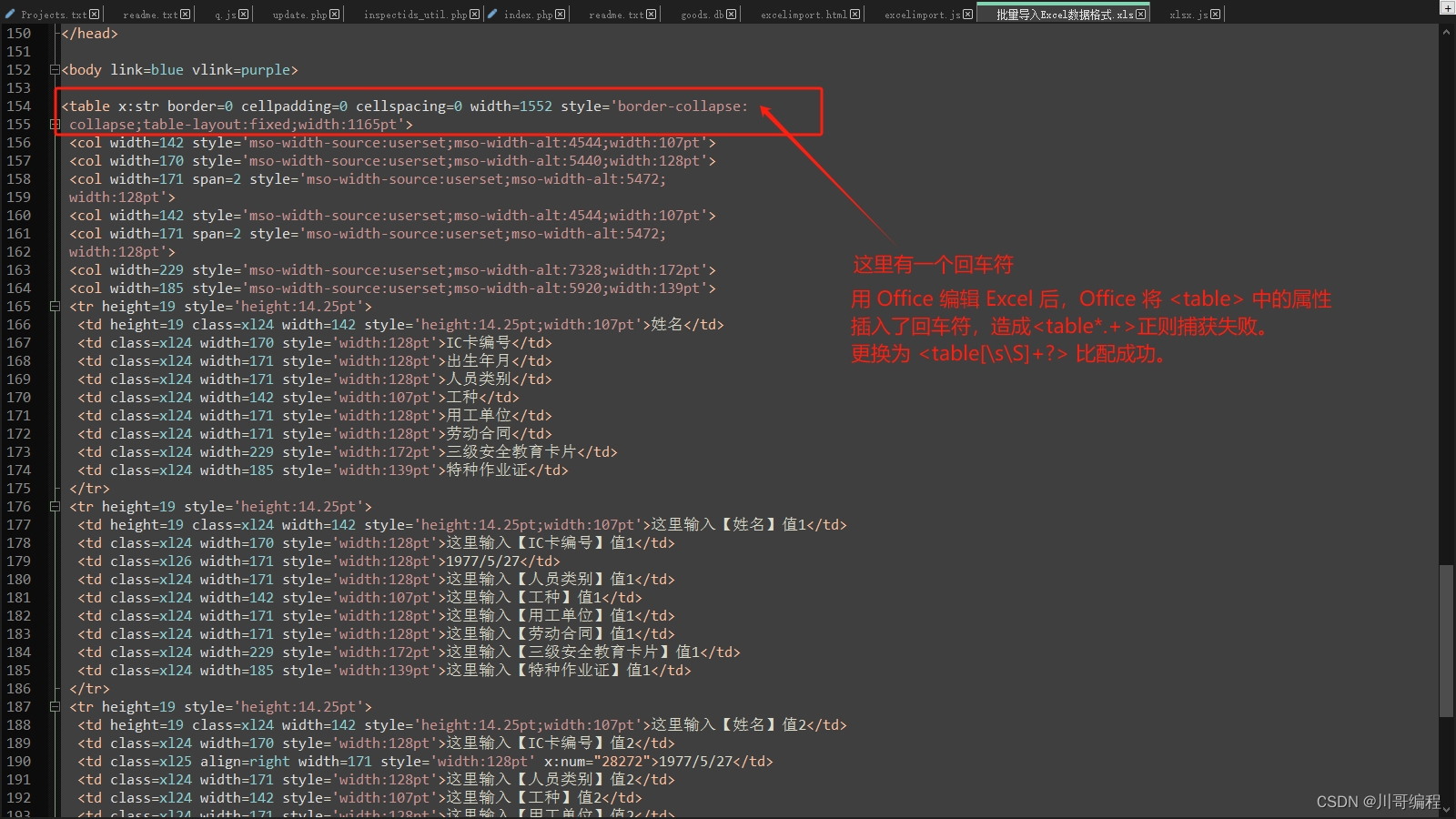
SheetJS V0.17.5 导入 Excel 异常修复 Invalid HTML:could not find<table>
导入 Excel 提示错误:Invalid HTML:could not find<table> 检查源代码 发现 table 属性有回车符 Overview: https://docs.sheetjs.com/docs/ Source: https://git.sheetjs.com/sheetjs/sheetjs/issues The public-facing websites of SheetJS: sheetjs.com…...
重学java51.Collections集合工具类、泛型
"我已不在地坛,地坛在我" —— 《想念地坛》 24.5.28 一、Collections集合工具类 1.概述:集合工具类 2.特点: a.构造私有 b.方法都是静态的 3.使用:类名直接调用 4.方法: static <T> boolean addAll(collection<? super T>c,T... el…...
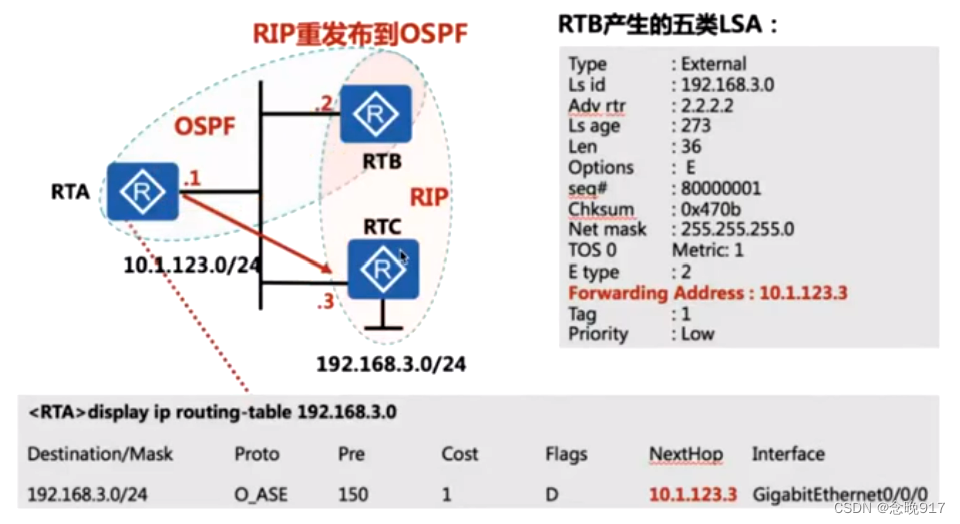
OSPF扩展知识2
FA-转发地址 正常 OSPF 区域收到的 5 类 LSA 不存在 FA 值; 产生 FA 的条件: 1、5类LSA ----假设 R2为 ASBR,90/0 口工作的 OSPF 中,g0/1 口工作在非 ospf 协议或不同 ospf 进程中;若 g0/1 也同时宣告在和 g0/0 相同的 OSPF 进程…...

数据库技术基础
数据库技术基础 导航 文章目录 数据库技术基础导航一、基础概念数据库系统数据库管理系统DBMS分类数据库技术的发展数据库体系结构 二、数据模型数据模型基本概念 三、数据库的控制功能事务概述SOL中事务定义语句日志文件故障种类两个操作Undo/Redo事务故障的恢复系统故障的恢…...

这些项目,我当初但凡参与一个,现在也不至于还是个程序员
10年前,我刚开始干开发不久,我觉得这真是一个有前景的职业,我觉得我的未来会无限广阔,我觉得再过几年,我一定工资不菲。于是我开始像很多大佬说的那样,开始制定职业规划,并且坚决执行。但过去这…...

ch2应用层--计算机网络期末复习
2.1应用层协议原理 网络应用程序位于应用层 开发网络应用程序: 写出能够在不同的端系统上通过网络彼此通信的程序 2.1.1网络应用程序体系结构分类: 客户机/服务器结构 服务器: 总是打开(always-on)具有固定的、众所周知的IP地址 主机群集常被用于创建强大的虚拟服务器 客…...

Red Hat Enterprise Linux (RHEL) 8.10 发布 - 红帽企业 Linux 8 完美终结版
Red Hat Enterprise Linux (RHEL) 8.10 (x86_64, aarch64) - 红帽企业 Linux 红帽企业 Linux 8 完美终结版 请访问原文链接:Red Hat Enterprise Linux (RHEL) 8.10 (x86_64, aarch64) - 红帽企业 Linux,查看最新版。原创作品,转载请保留出处…...
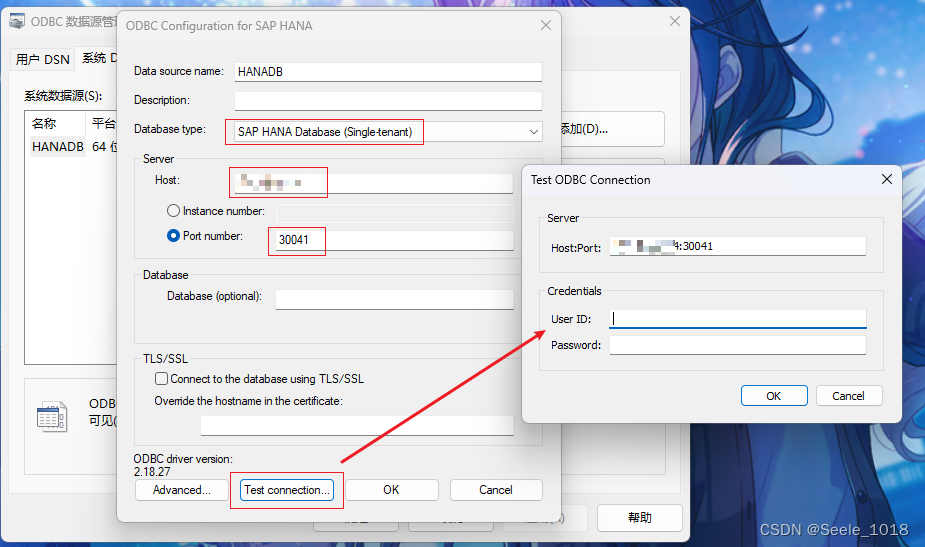
.NET 直连SAP HANA数据库
前言 上个项目碰到的需求,IT部门要求直连SAP的HANA数据库,以只读的权限读取SAP部门开发的CDS视图,是个有点复杂的工程,需要从成品一直往前追溯到原材料的产地,和交货单、工单、采购订单有相当程度上的关联 IT部门要求…...

HTML <from>表单
定义:<form>元素定义了一个表单,用户可以在表单中输入数据,这些数据可以被提交到服务器。 属性: action:指定表单提交时的目标URL(服务器端脚本的地址)。 method:定义提交表…...
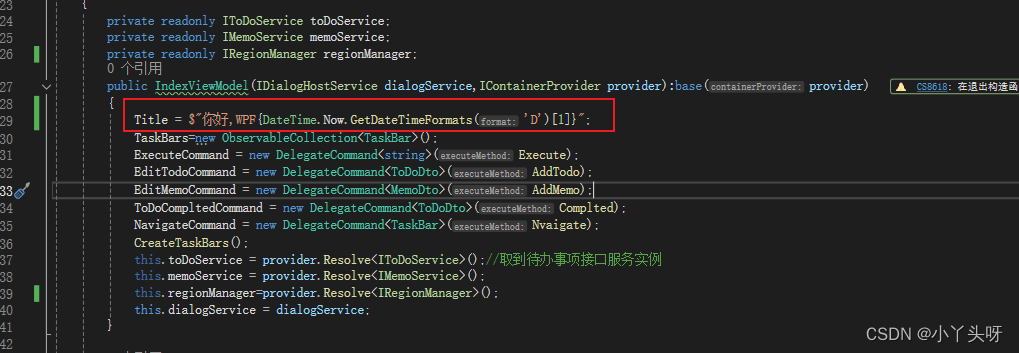
Wpf 使用 Prism 实战开发Day28
首页汇总方块点击导航功能 点击首页汇总方块的时候,跳转到对应的数据页面 step1: 在IndexViewModel 中,给TaskBar 里面Target 属性,赋上要跳转的页面 step2: 创建导航事件命令和方法实现 step3: 实现导航的逻辑。通过取到 IRegionManager 的…...

HC32F460的Bootloader避坑指南:Flash分区、中断向量表重定位和跳转的那些坑
HC32F460 Bootloader实战避坑手册:从Flash配置到中断处理的深度解析 当你在深夜调试HC32F460的Bootloader时,突然发现程序在跳转后莫名跑飞,或者中断死活不响应——这种崩溃感我太熟悉了。本文将带你直击五个最容易被忽视却至关重要的技术细节…...

AI教材写作新趋势,低查重助力高效教材编写!
编写痛点与AI解法 整理教材的知识点简直就是一项“精细的工作”,其难点在于如何保持平衡与衔接性!要么令人担忧的是核心知识点的遗漏,要么把握不好难度的层次——小学教材往往深奥,让学生难以理解;高中教材却又过于浅…...

Apache Spark 第 11 章:Delta Lake 与 Lakehouse
第十一章深入拆解 Delta Lake 与 Lakehouse 架构,这是现代数据工程的核心组件。从传统数据湖的痛点出发,逐层剖析 Delta Lake 的实现原理。 第一张:为什么需要 Delta Lake。三大痛点和 Delta Lake 的解法一目了然。接下来看最核心的实现机制—…...

SeqGPT-560M智能客服问答系统部署指南
SeqGPT-560M智能客服问答系统部署指南 1. 引言 想象一下这样的场景:你的电商平台每天收到上千条客户咨询,从"这个衣服有货吗"到"怎么申请退货",问题五花八门。传统客服需要一个个手动回复,效率低下还容易出…...

告别手动更新!用Python+Pandas快速解析通达信tnf文件,构建本地股票代码库
用PythonPandas高效解析通达信TNF文件:打造自动化股票代码库 每次手动更新股票代码库时,那些重复性操作总让我想起学生时代抄写课文的场景——机械、耗时且容易出错。作为量化研究员,我们真正需要的是把时间花在策略优化上,而不是…...

Alpamayo-R1-10B实战案例:自动驾驶算法工程师日常调试VLA模型工作流
Alpamayo-R1-10B实战案例:自动驾驶算法工程师日常调试VLA模型工作流 1. 项目概述 Alpamayo-R1-10B是专为自动驾驶研发设计的开源视觉-语言-动作(VLA)模型,基于100亿参数架构构建。这套工具链包含AlpaSim模拟器和Physical AI AV数据集,旨在通…...

从手动压枪到智能辅助:探索罗技鼠标宏在PUBG中的进化之路
从手动压枪到智能辅助:探索罗技鼠标宏在PUBG中的进化之路 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 当你在绝地求生的激烈对枪中…...

基于Kubernetes Operator的MySQL InnoDB Cluster自动化部署实践
1. MySQL InnoDB Cluster与Kubernetes Operator基础 MySQL InnoDB Cluster是MySQL官方提供的高可用数据库解决方案,它基于MySQL Group Replication技术构建,能够实现多节点数据同步和自动故障转移。想象一下,这就像是一个由多个数据库实例组…...

Qwen3.5-2B部署实操:CentOS 7兼容性处理与依赖库降级方案
Qwen3.5-2B部署实操:CentOS 7兼容性处理与依赖库降级方案 1. 模型简介 Qwen3.5-2B是阿里云推出的轻量化多模态基础模型,属于Qwen3.5系列的小参数版本(20亿参数)。该模型主打低功耗、低门槛部署特性,特别适配端侧和边…...

动态透视报表 + 查询接口 + Excel导出
动态透视报表 查询接口 Excel导出 ✅ 动态行维度(产品 / 型号 / 项目 任意组合)✅ 动态列维度(月份)✅ a / f 子表头✅ SQL 透视(适合 GaussDB)✅ 查询接口 EasyExcel 导出接口✅ 可复用报表引擎 整体…...