PV PVC
默写
1 如何将pod创建在指定的Node节点上
node亲和、pod亲和、pod反亲和:
调度策略 匹配标签 操作符
nodeAffinity 主机 In,NotIn,Exists,DoesNotExist,Gt,Lt
podAffinity pod In,NotIn,Exists,DoesNotExist,
podAntiAffinity pod In,NotIn,Exists,DoesNotExist,
调度目标指定主机Pod与指定Pod同一拓扑域Pod与指定Pod不在同一拓扑域
2 污点的种类(在node上设置)
当前 taint effect 支持如下三个选项:
Noschedule:表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上
PreferNoschedule:表示 k8s 将尽量避免将 Pod 调度到具有该污点的 Node 上
NoExecute:表示 k8s 将不会将 pod 调度到具有该污点的 Node 上,同时会将 Node 上已经存在的 pod 驱逐出去
一 挂载存储
容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。
首先,当容器崩溃时,kubelet 会重启它,但是容器中的文件将丢失——容器以干净的状态(镜像最初的状态)重新启动。
其次,在Pod中同时运行多个容器时,这些容器之间通常需要共享文件。Kubernetes 中的Volume抽象就很好的解决了这些问题。Pod中的容器通过Pause容器共享Volume。
(用本地磁盘进行挂载,把本地数据挂载虚拟机中做持久化)
1 emptyDir存储卷
当Pod被分配给节点时,首先创建emptyDir卷,并且只要该Pod在该节点上运行,该卷就会存在。正如卷的名字所述,它最初是空的。
Pod 中的容器可以读取和写入emptyDir卷中的相同文件,尽管该卷可以挂载到每个容器中的相同或不同路径上。当出于任何原因从节点中删除 Pod 时,emptyDir中的数据将被永久删除。
总结:依赖于某一个容器,从一个容器挂载到另一个容器
专业版
vim pod-emptydir.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-emptydirnamespace: defaultlabels: #加两个标签app: myapptier: frontend
spec:containers:- name: myappimage: ikubernetes/myapp:v1 #定义镜像imagePullPolicy: IfNotPresent #拉取策略ports:- name: httpcontainerPort: 80#定义容器挂载内容volumeMounts:#使用的存储卷名称,如果跟下面volume字段name值相同,则表示使用volume的这个存储卷- name: html#挂载至容器中哪个目录mountPath: /usr/share/nginx/html/- name: busyboximage: busybox:latestimagePullPolicy: IfNotPresentvolumeMounts:- name: html#在容器内定义挂载存储名称和挂载路径mountPath: /data/command: ['/bin/sh','-c','while true;do echo $(date) >> /data/index.html;sleep 2;done'] #等待2s就结束
#定义存储卷volumes:#定义存储卷名称 - name: html#定义存储卷类型emptyDir: {}简化版
apiVersion: v1
kind: Pod
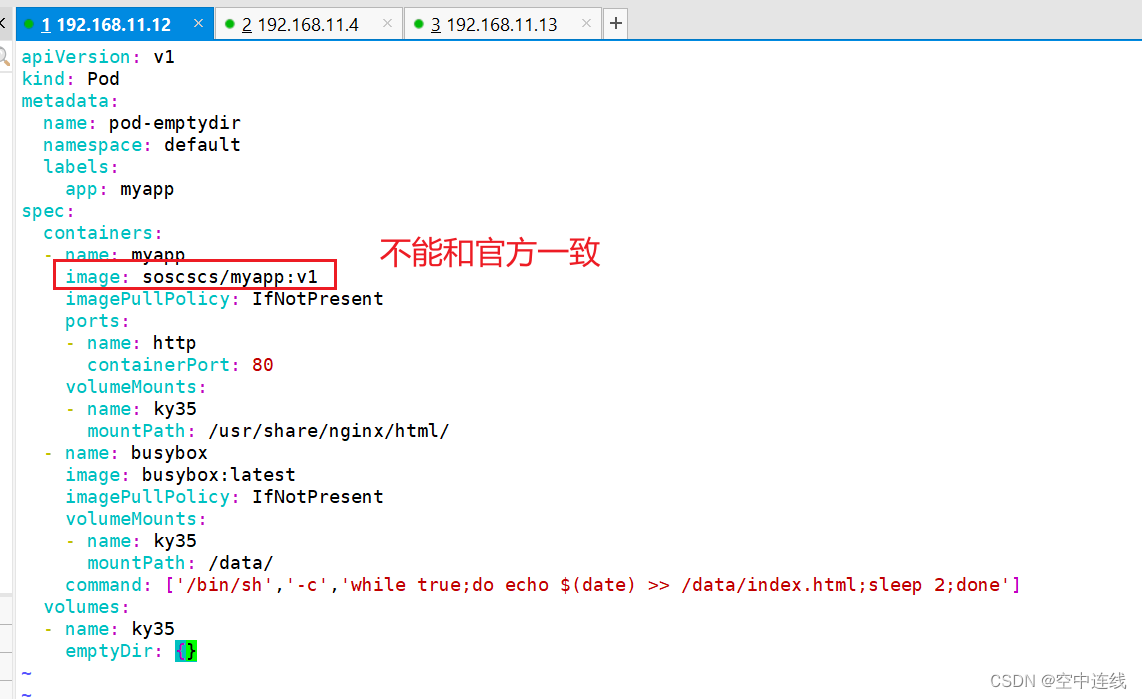
metadata:name: pod-emptydirnamespace: defaultlabels:app: myapp
spec:containers:- name: myappimage: soscscs/myapp:v1imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 80volumeMounts:- name: ky35mountPath: /usr/share/nginx/html/- name: busyboximage: busybox:latestimagePullPolicy: IfNotPresentvolumeMounts:- name: ky35mountPath: /data/command: ['/bin/sh','-c','while true;do echo $(date) >> /data/index.html;sleep 2;done']volumes:- name: ky35emptyDir: {}

kubectl apply -f pod-emptydir.yamlkubectl get pods -o wide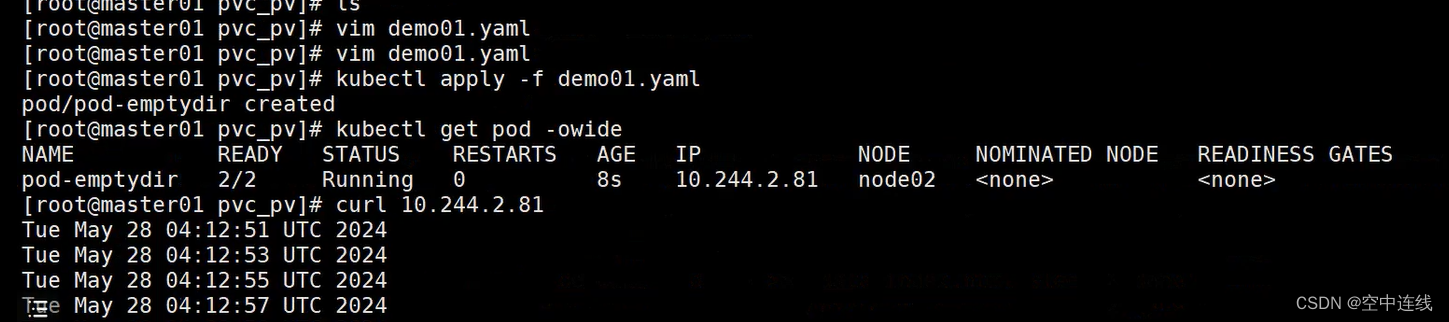
kubectl exec -it pod-emptydir -c busybox sh #进入容器

总结:
emptypir: 可以实现pod中的容器之间共享数据,但是存储卷不能持久化数据,且会随着pod 生命周结束而一起删除
hostpath: 可以实现持久化存储,使用node节点的目录或文件挂载到容器,但是存储空间会受到弄得节点单机限制,node节点故障数据会丢失,pod跨节点不能共享数据
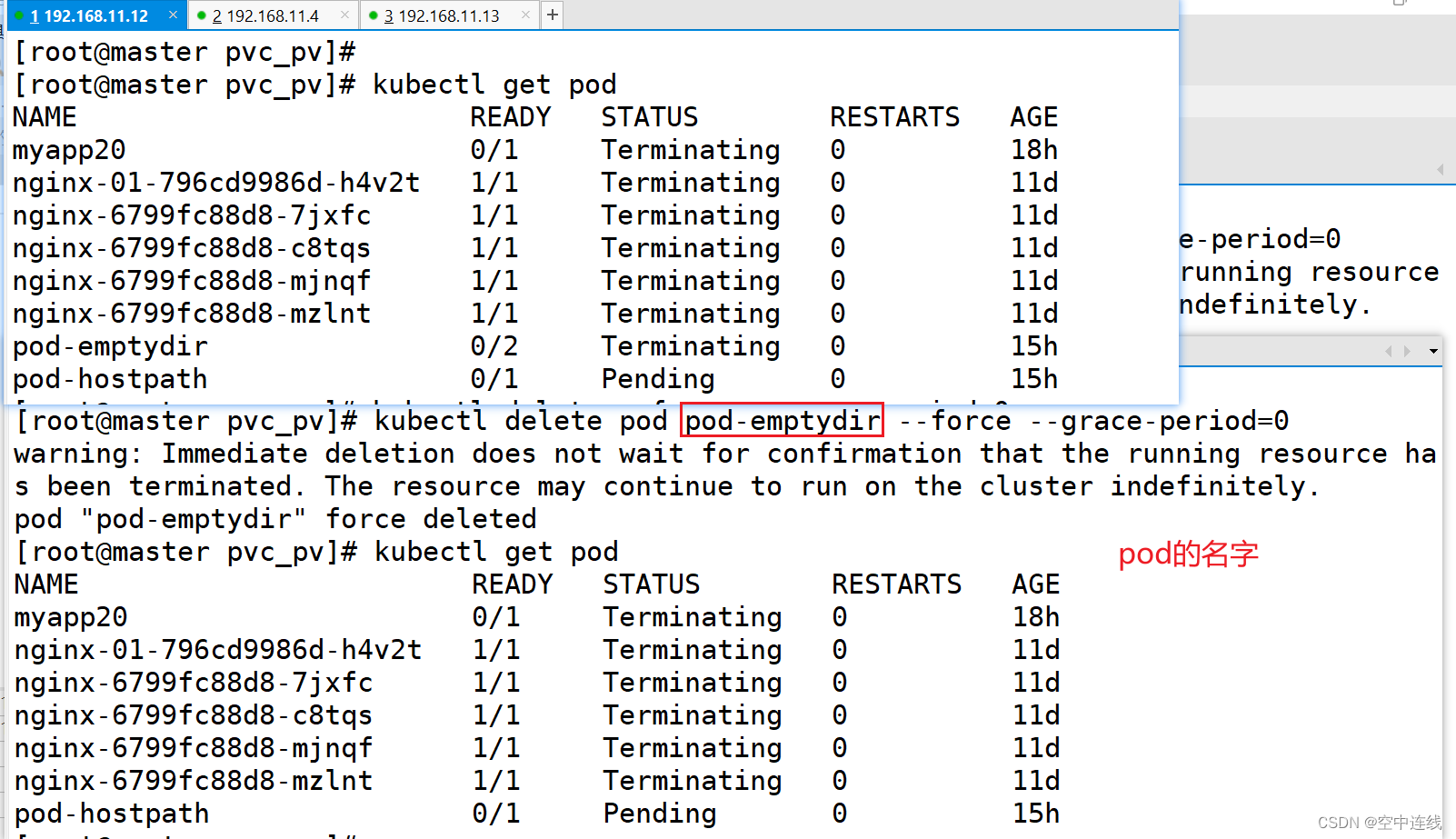
失败总结--强制删除
kubectl delete pod pod-emptydir --force --grace-period=0
2 hostPath存储卷
hostPath卷将 node 节点的文件系统中的文件或目录挂载到集群中。
hostPath可以实现持久存储,但是在node节点故障时,也会导致数据的丢失。
apiVersion: v1
kind: Pod
metadata:name: pod-hostpathnamespace: default
spec:containers:- name: myappimage: soscscs/myapp:v1#定义容器挂载内容volumeMounts:#使用的存储卷名称,如果跟下面volume字段name值相同,则表示使用volume的这个存储卷- name: html#挂载至容器中哪个目录mountPath: /usr/share/nginx/html#读写挂载方式,默认为读写模式falsereadOnly: false#volumes字段定义了paues容器关联的宿主机或分布式文件系统存储卷volumes:#存储卷名称- name: html#路径,为宿主机存储路径hostPath:#在宿主机上目录的路径path: /data/pod/volume1#定义类型,这表示如果宿主机没有此目录则会自动创建type: DirectoryOrCreate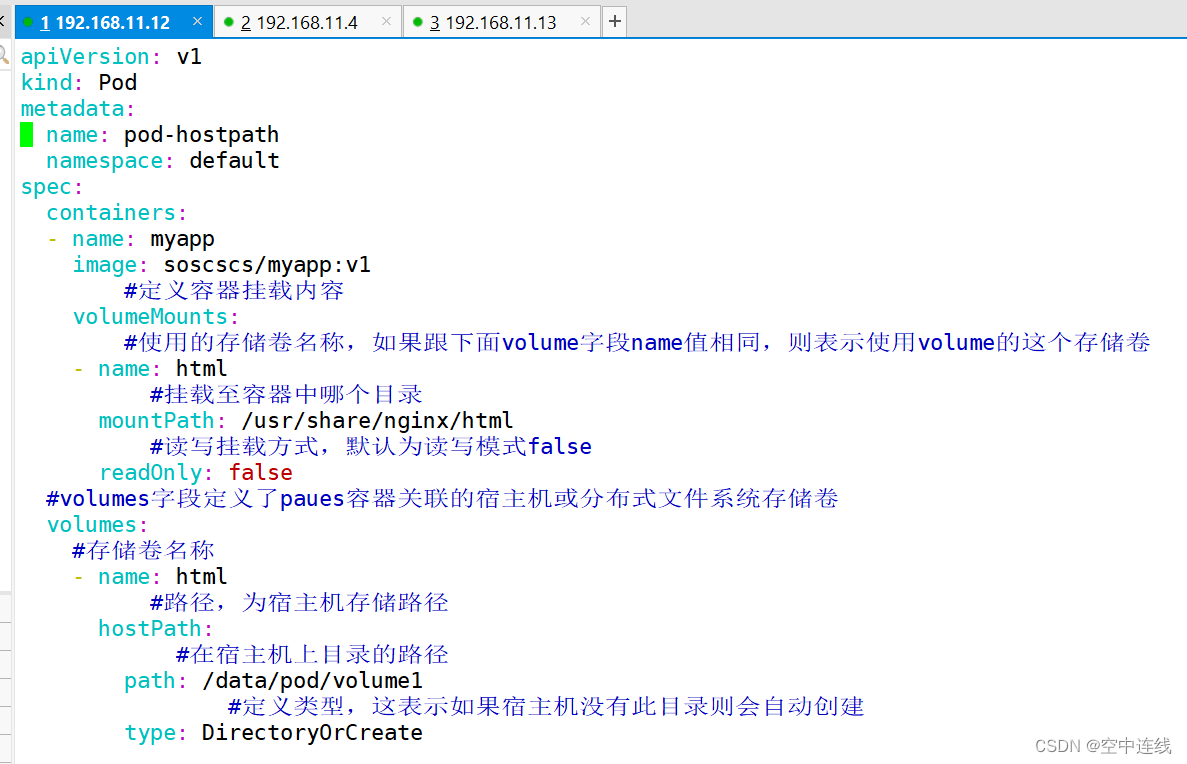

在 node01 节点上创建挂载目录
mkdir -p /data/pod/volume1
echo 'node01.kgc.com' > /data/pod/volume1/index.html
在 node02 节点上创建挂载目录
mkdir -p /data/pod/volume1
echo 'node02.kgc.com' > /data/pod/volume1/index.html
在master上检测一下:curl
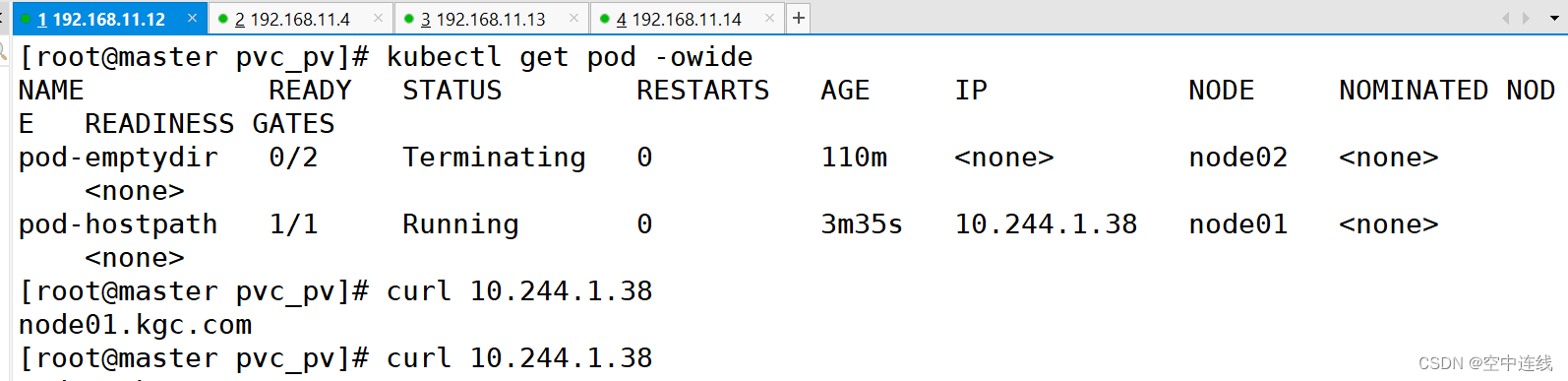
注意:若启动不run 就重启一下
创建 Pod 资源
vim pod-hostpath.yaml
apiVersion: v1
kind: Pod
metadata:name: pod-hostpathnamespace: default
spec:containers:- name: myappimage: ikubernetes/myapp:v1#定义容器挂载内容volumeMounts:#使用的存储卷名称,如果跟下面volume字段name值相同,则表示使用volume的这个存储卷- name: html#挂载至容器中哪个目录mountPath: /usr/share/nginx/html#读写挂载方式,默认为读写模式falsereadOnly: false #代表了可读可查都可以进行#volumes字段定义了paues容器关联的宿主机或分布式文件系统存储卷volumes:#存储卷名称- name: html#路径,为宿主机存储路径hostPath:#在宿主机上目录的路径path: /data/pod/volume1#定义类型,这表示如果宿主机没有此目录则会自动创建type: DirectoryOrCreatekubectl apply -f pod-hostpath.yaml
访问测试
kubectl get pods -o wide
3 nfs共享存储卷
注意:只是共享存储,没有存储能力
NAS存储设备 + NFS 才能共享出去
GFS--自动搭 ceph---第三方 NAS---第三方
云端存储:oss s3 SLB LB CDN AWS
① 在stor01节点上安装nfs,并配置nfs服务
在stor01节点上安装nfs,并配置nfs服务
mkdir /data/volumes -p
chmod 777 /data/volumes
vim /etc/exports
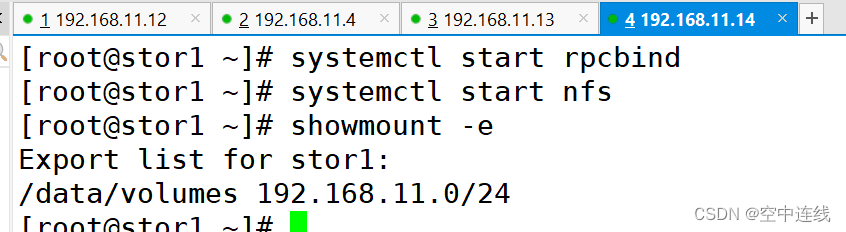
/data/volumes 192.168.10.0/24(rw,no_root_squash)systemctl start rpcbind
systemctl start nfsshowmount -e
Export list for stor01:
/data/volumes 192.168.10.0/24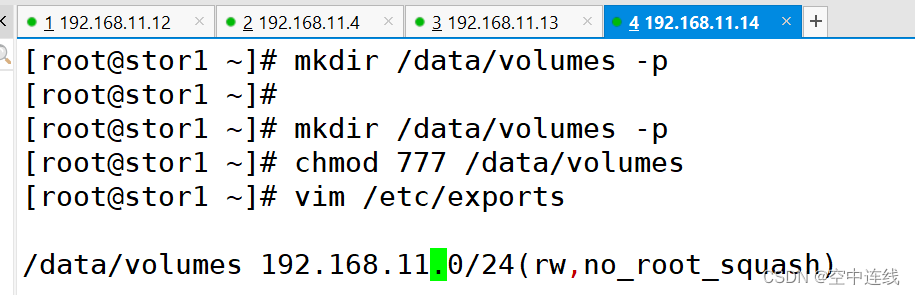
做映射
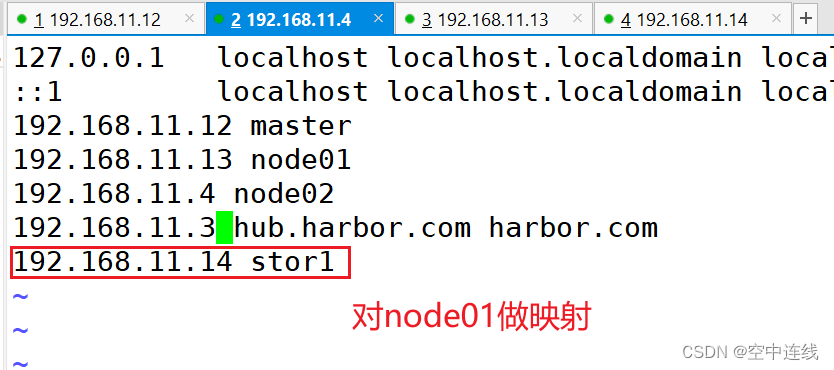
② master节点操作
kind: Pod
vim pod-nfs-vol.yaml
apiVersion: v1
metadata:name: pod-vol-nfsnamespace: default
spec:containers:- name: myappimage: ikubernetes/myapp:v1volumeMounts:- name: htmlmountPath: /usr/share/nginx/htmlvolumes:- name: htmlnfs:path: /data/volumesserver: stor01
apiVersion: v1
kind: Pod
metadata:name: pod-nfsnamespace: default
spec:containers:- name: myappimage: soscscs/myapp:v1volumeMounts:- name: ky35mountPath: /usr/share/nginx/htmlvolumes:- name: ky35nfs:path: /data/volumesserver: 192.168.11.14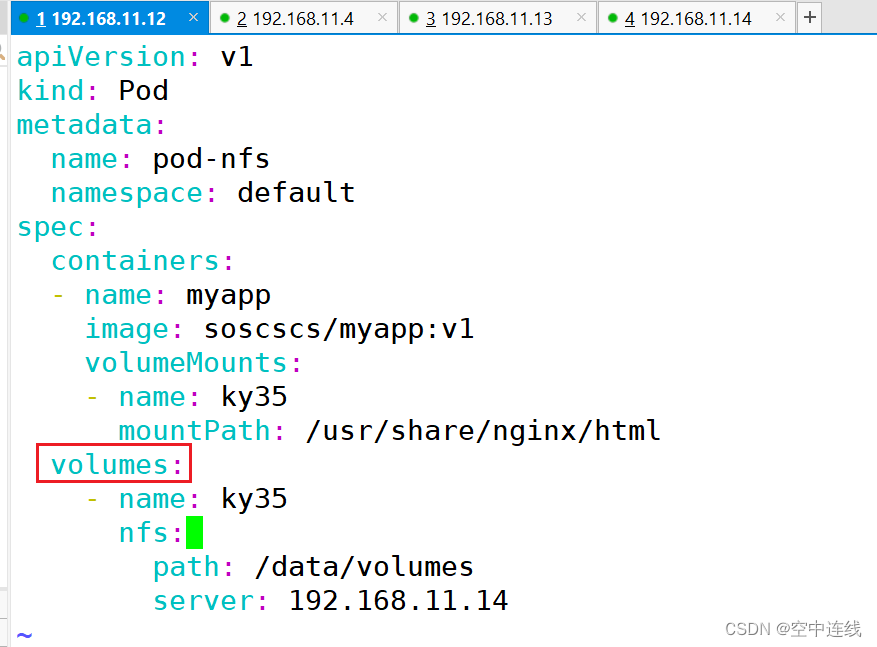
kubectl apply -f pod-nfs-vol.yaml
kubectl get pods -o wide

③ 在nfs服务器上创建index.html
cd /data/volumes
vim index.html
<h1> nfs stor01</h1>
④ master节点操作
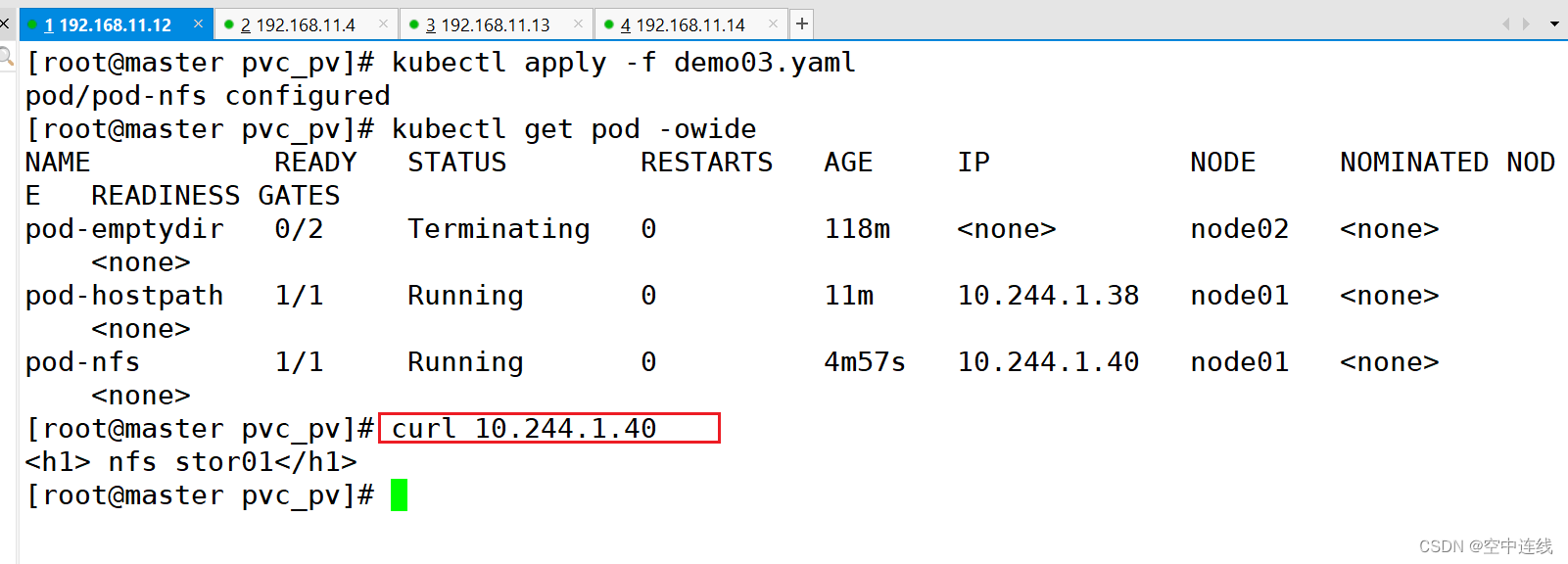 ⑤ 删除nfs相关pod,再重新创建,可以得到数据的持久化存储
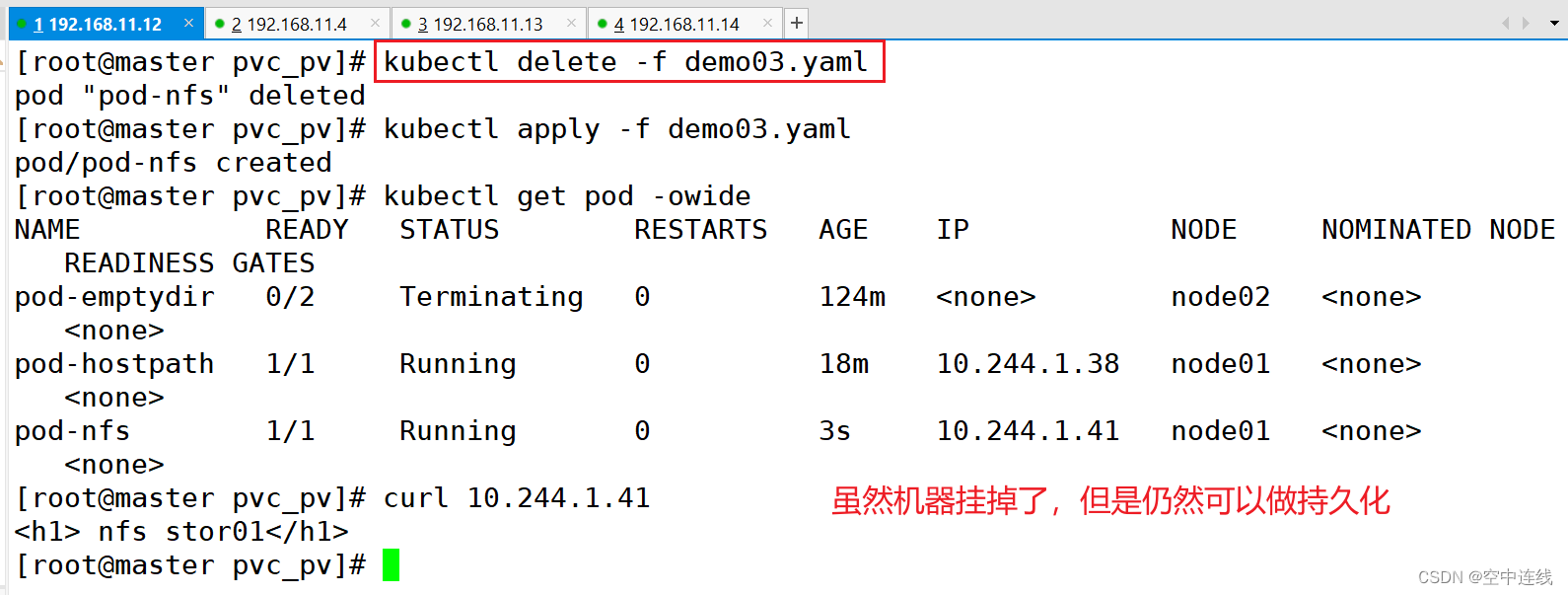
⑤ 删除nfs相关pod,再重新创建,可以得到数据的持久化存储
kubectl delete -f demo03.yaml
kubectl delete -f pod-nfs-vol.yaml
失败总结

挂载存储
emptypir :可以实现Pod中的容器之间共享数据,但是存储卷不能持久化数据,且会随着pod 生命周结束而一起删除
hostpath:可以实现持久化存储,使用node节点的目录或文件挂载到容器,但是存储空间会受到弄得节点单机限制,node节点故障数据会丢失,poa跨节点不能共享数据
nfs:可以实现持久化存储,使用nfs将存储设别空间挂载到容器中,pod可以跨node节点共享数据
二 PVC 和 PV
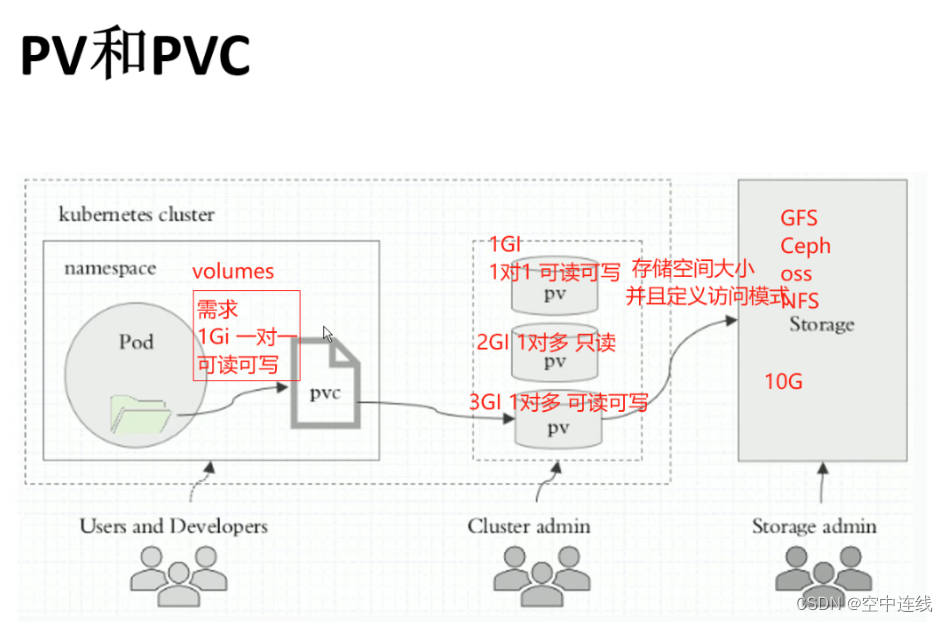
PV 全称叫做 Persistent Volume,持久化存储卷。它是用来描述或者说用来定义一个存储卷的,这个通常都是由运维工程师来定义。
PVC 的全称是 Persistent Volume Claim,是持久化存储的请求。它是用来描述希望使用什么样的或者说是满足什么条件的 PV 存储。
PVC 的使用逻辑:在 Pod 中定义一个存储卷(该存储卷类型为 PVC),定义的时候直接指定大小,PVC 必须与对应的 PV 建立关系,PVC 会根据配置的定义去 PV 申请,而 PV 是由存储空间创建出来的。PV 和 PVC 是 Kubernetes 抽象出来的一种存储资源。
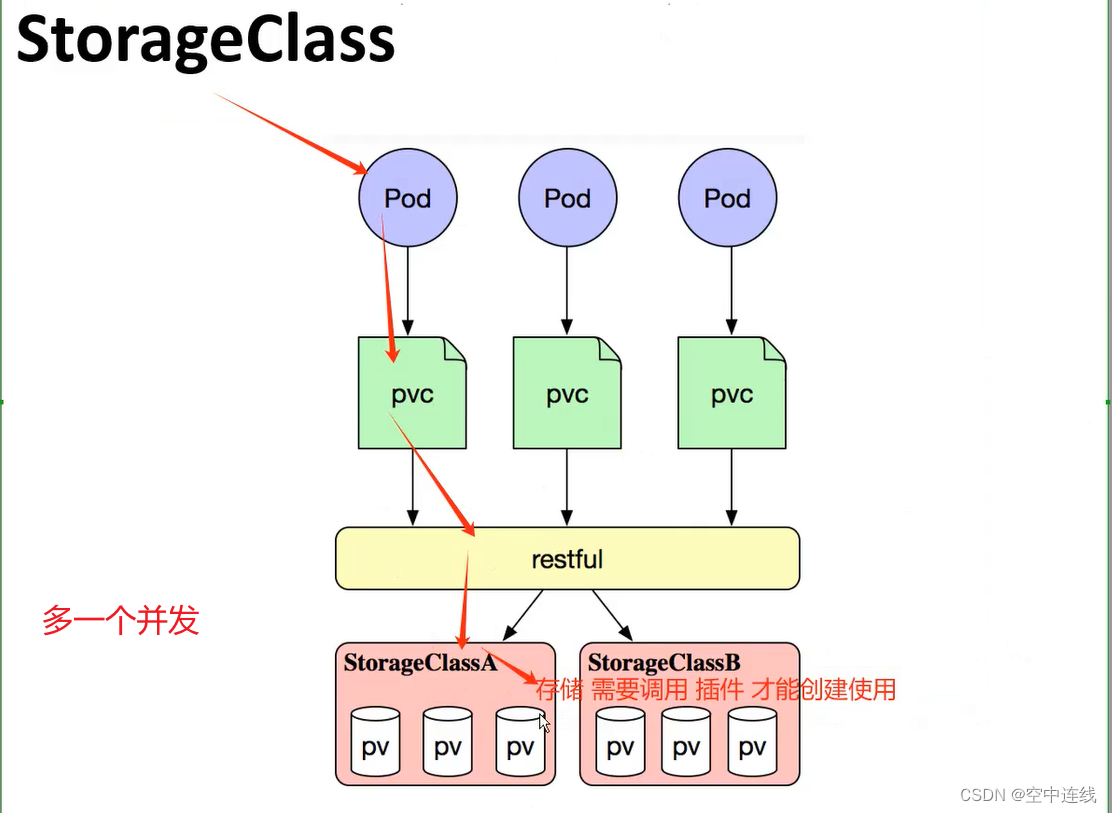
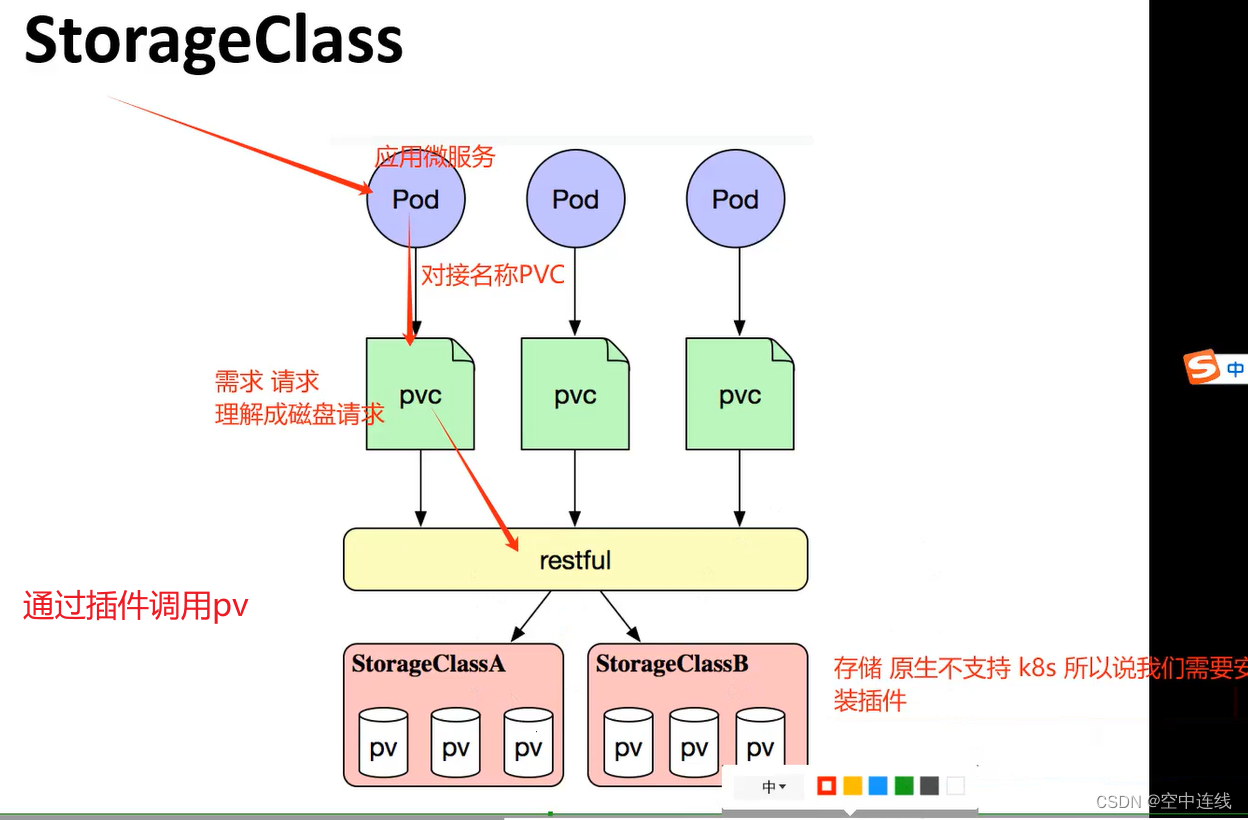
上面介绍的PV和PVC模式是需要运维人员先创建好PV,然后开发人员定义好PVC进行一对一的Bond,但是如果PVC请求成千上万,那么就需要创建成千上万的PV,对于运维人员来说维护成本很高,Kubernetes提供一种自动创建PV的机制,叫StorageClass,它的作用就是创建PV的模板。
创建 StorageClass 需要定义 PV 的属性,比如存储类型、大小等;另外创建这种 PV 需要用到的存储插件,比如 Ceph 等。 有了这两部分信息,Kubernetes 就能够根据用户提交的 PVC,找到对应的 StorageClass,然后 Kubernetes 就会调用 StorageClass 声明的存储插件,自动创建需要的 PV 并进行绑定。
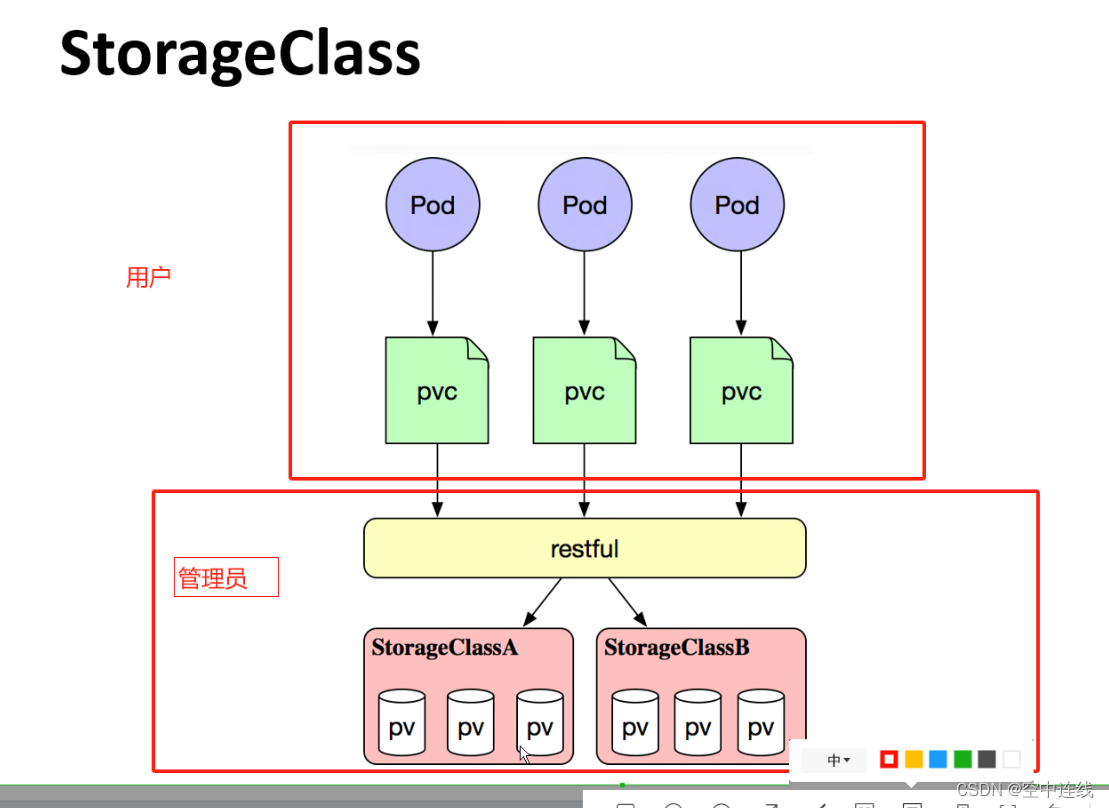
- 存储: 存储工程师运维
- PV: k8s 管理员运维
- PVC: 用户维护
PV是集群中的资源。 PVC是对这些资源的请求,也是对资源的索引检查。
1 PV和PVC之间的相互作用遵循这个生命周期:
Provisioning(配置)---> Binding(绑定)---> Using(使用)---> Releasing(释放) ---> Recycling(回收)
Provisioning:即 PV 的创建,可以直接创建 PV(静态方式),也可以使用 StorageClass 动态 创建
Binding:将 PV 分配给 PVC
Using:Pod 通过 PVC 使用该 Volume,并可以通过准入控制StorageProtection(1.9及以前版本 为PVCProtection) 阻止删除正在使用的 PVC
Releasing:Pod 释放 Volume 并删除 PVC
Reclaiming:回收 PV,可以保留 PV 以便下次使用,也可以直接从云存储中删除
2 根据这 5 个阶段,PV 的状态有以下 4 种:
- Available(可用):表示可用状态,还未被任何 PVC 绑定
- Bound(已绑定):表示 PV 已经绑定到 PVC
- Released(已释放):表示 PVC 被删掉,但是资源尚未被集群回收
- Failed(失败):表示该 PV 的自动回收失败
3 一个PV从创建到销毁的具体流程如下:
1 一个PV创建完后状态会变成Available,等待被PVC绑定。
2 一旦被PVC邦定,PV的状态会变成Bound,就可以被定义了相应PVC的Pod使用。
3 Pod使用完后会释放PV,PV的状态变成Released。
4 变成Released的PV会根据定义的回收策略做相应的回收工作。有三种回收策略,Retain、Delete和Recycle。
Retain就是保留现场,K8S集群什么也不做,等待用户手动去处理PV里的数据,处理完后,再手 动删除PV。
Delete策略,K8S会自动删除该PV及里面的数据。
Recycle方式,K8S会将PV里的数据删除,然后把PV的状态变成Available,又可以被新的PVC绑 定使用。
三 回收策略
kubectl explain pv #查看pv的定义方式
FIELDS:apiVersion: v1kind: PersistentVolumemetadata: #由于 PV 是集群级别的资源,即 PV 可以跨 namespace 使用,所以 PV 的 metadata 中不用配置 namespacename: speckubectl explain pv.spec #查看pv定义的规格
spce:nfs:(定义存储类型)path:(定义挂载卷路径)server:(定义服(定义访问模型,务器名称)accessModes:有以下三种访问模型,以列表的方式存在,也就是说可以定义多个访问模式) * * *- ReadWriteOnce #(RWO)存储可读可写,但只支持被单个 Pod 挂载- ReadOnlyMany #(ROX)存储可以以只读的方式被多个 Pod 挂载- ReadWriteMany #(RWX)存储可以以读写的方式被多个 Pod 共享 注:官网
#nfs 支持全部三种;iSCSI 不支持 ReadWriteMany(iSCSI 就是在 IP 网络上运行 SCSI 协议的一种网络存储技术);HostPath 不支持 ReadOnlyMany 和 ReadWriteMany。capacity:(定义存储能力,一般用于设置存储空间)storage: 2Gi (指定大小)storageClassName: (自定义存储类名称,此配置用于绑定具有相同类别的PVC和PV)persistentVolumeReclaimPolicy: Retain #回收策略(Retain/Delete/Recycle) * * *
#Retain(保留):当删除与之绑定的PVC时候,这个PV被标记为released(PVC与PV解绑但还没有执行回收策略)且之前的数据依然保存在该PV上,但是该PV不可用,需要手动来处理这些数据并删除该PV。
#Delete(删除):删除与PV相连的后端存储资源(只有 AWS EBS, GCE PD, Azure Disk 和 Cinder 支持)
#Recycle(回收):删除数据,效果相当于执行了 rm -rf /thevolume/* (只有 NFS 和 HostPath 支持)kubectl explain pvc #查看PVC的定义方式
KIND: PersistentVolumeClaim
VERSION: v1
FIELDS:apiVersion <string>kind <string> metadata <Object>spec <Object>nfs 支持全部三种
iSCSI 不支持 ReadWriteMany(iSCSI 就是在 IP 网络上运行 SCSI 协议的一种网络存储技术);HostPath 不支持 ReadOnlyMany 和 ReadWriteMany。
capacity: (定义存储能力,一般用于设置存储空间)
storage: 2Gi (指定大小)
storageClassName: (自定义存储类名称,此配置用于绑定具有相同类别的PVC和PV)
persistentVolumeReclaimPolicy: Retain #回收策略(Retain/Delete/Recycle)
Retain(保留):当删除与之绑定的PVC时候,这个PV被标记为released(PVC与PV解绑但还没有执行回收策略)且之前的数据依然保存在该PV上,但是该PV不可用,需要手动来处理这些数据并删除该PV。
Delete(删除):删除与PV相连的后端存储资源(只有 AWS EBS, GCE PD, Azure Disk 和 Cinder 支持)
Recycle(回收):删除数据,效果相当于执行了 rm -rf /thevolume/* (只有 NFS 和 HostPath 支持)
PV和PVC中的spec关键字段要匹配
比如存储(storage)大小、访问模式(accessModes)、存储类名称(storageClassName)
kubectl explain pvc.spec
spec:accessModes: (定义访问模式,必须是PV的访问模式的子集)resources:requests:storage: (定义申请资源的大小)storageClassName: (定义存储类名称,此配置用于绑定具有相同类别的PVC和PV)四 NFS使用PV和PVC---静态
只能创建一些简单的,
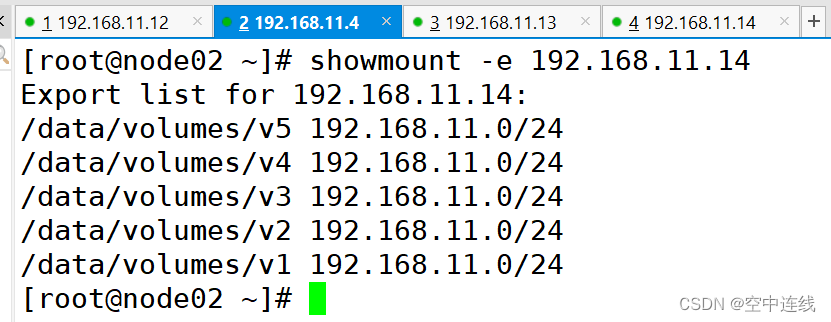
1 配置nfs存储
mkdir v{1,2,3,4,5}
vim /etc/exports
/data/volumes/v1 192.168.10.0/24(rw,no_root_squash)
/data/volumes/v2 192.168.10.0/24(rw,no_root_squash)
/data/volumes/v3 192.168.10.0/24(rw,no_root_squash)
/data/volumes/v4 192.168.10.0/24(rw,no_root_squash)
/data/volumes/v5 192.168.10.0/24(rw,no_root_squash)exportfs -arv
showmount -e

官方文档:https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/configure-persistent-volume-storage/#create-a-persistentvolume

2 定义PV
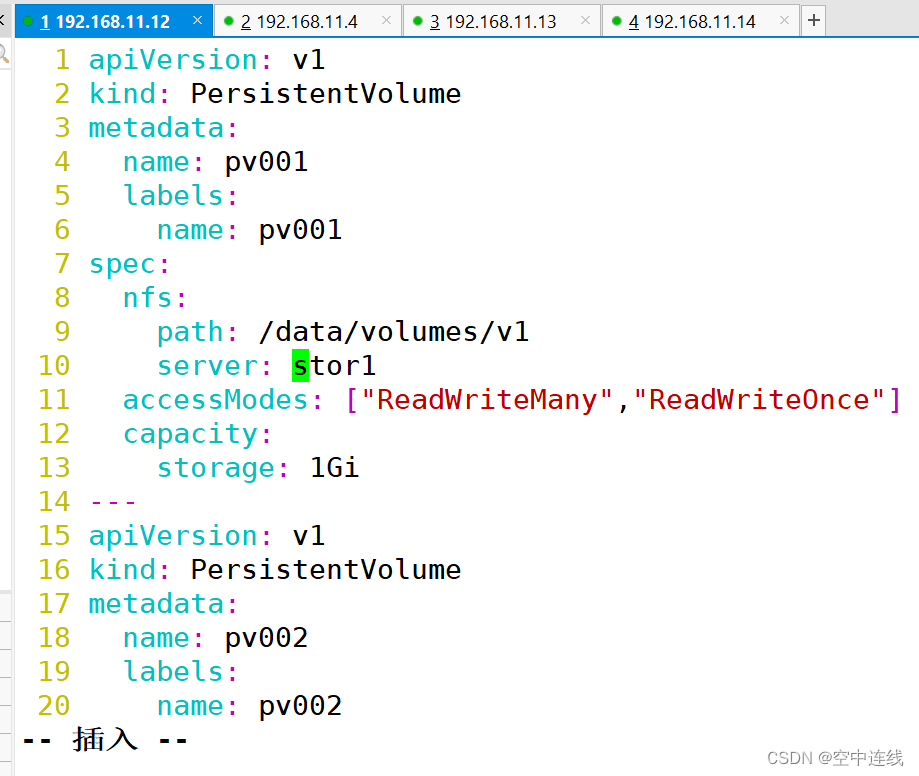
这里定义5个PV,并且定义挂载的路径以及访问模式,还有PV划分的大小。
vim pv-demo.yaml
apiVersion: v1
kind: PersistentVolume
metadata:name: pv001labels:name: pv001
spec:nfs:path: /data/volumes/v1server:stor01 accessModes: ["ReadWriteMany","ReadWriteOnce"]capacity:storage: 1Gi
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv002labels:name: pv002
spec:nfs:path: /data/volumes/v2server: stor01accessModes: ["ReadWriteOnce"]capacity:storage: 2Gi
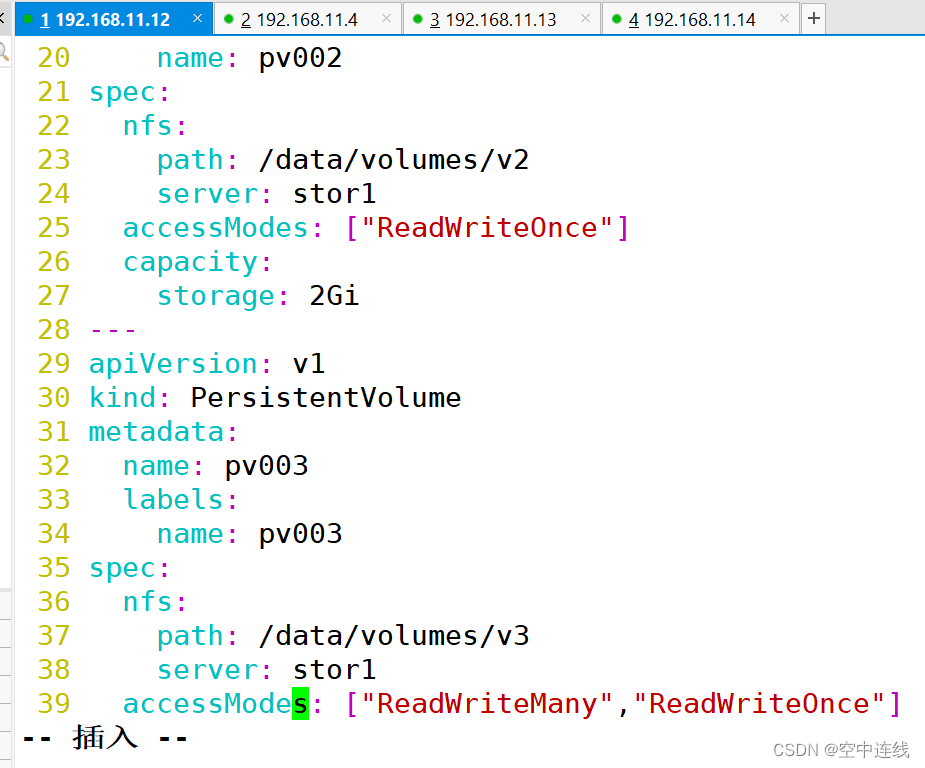
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv003labels:name: pv003
spec:nfs:path: /data/volumes/v3server: stor01accessModes: ["ReadWriteMany","ReadWriteOnce"]capacity:storage: 2Gi
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv004labels:name: pv004
spec:nfs:path: /data/volumes/v4server: stor01accessModes: ["ReadWriteMany","ReadWriteOnce"]capacity:storage: 4Gi
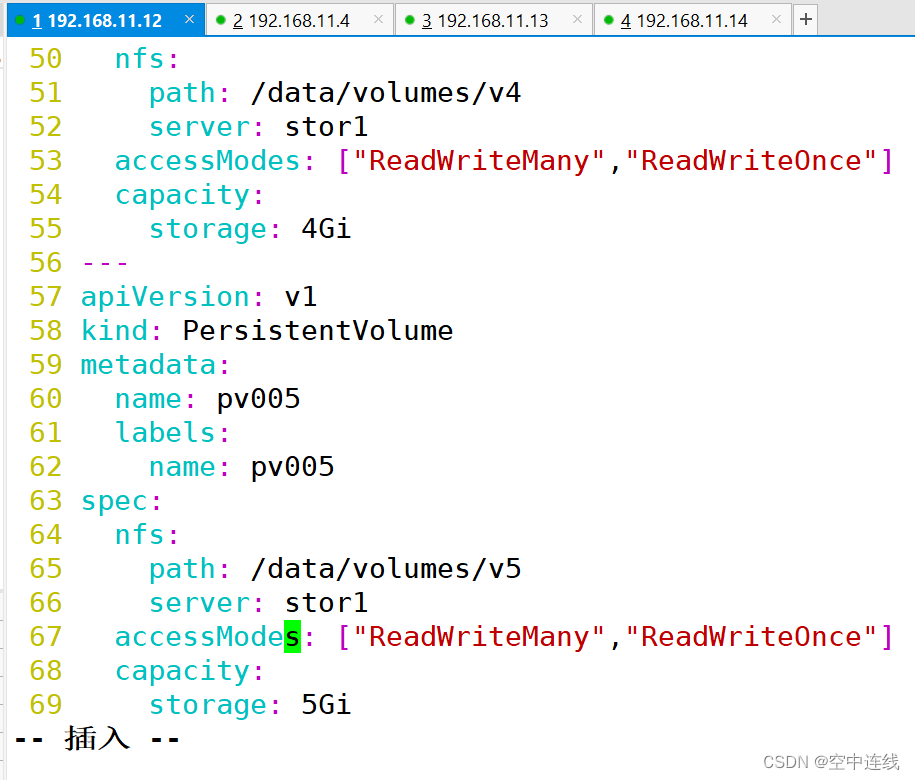
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv005labels:name: pv005
spec:nfs:path: /data/volumes/v5server: stor01accessModes: ["ReadWriteMany","ReadWriteOnce"]capacity:storage: 5Gi

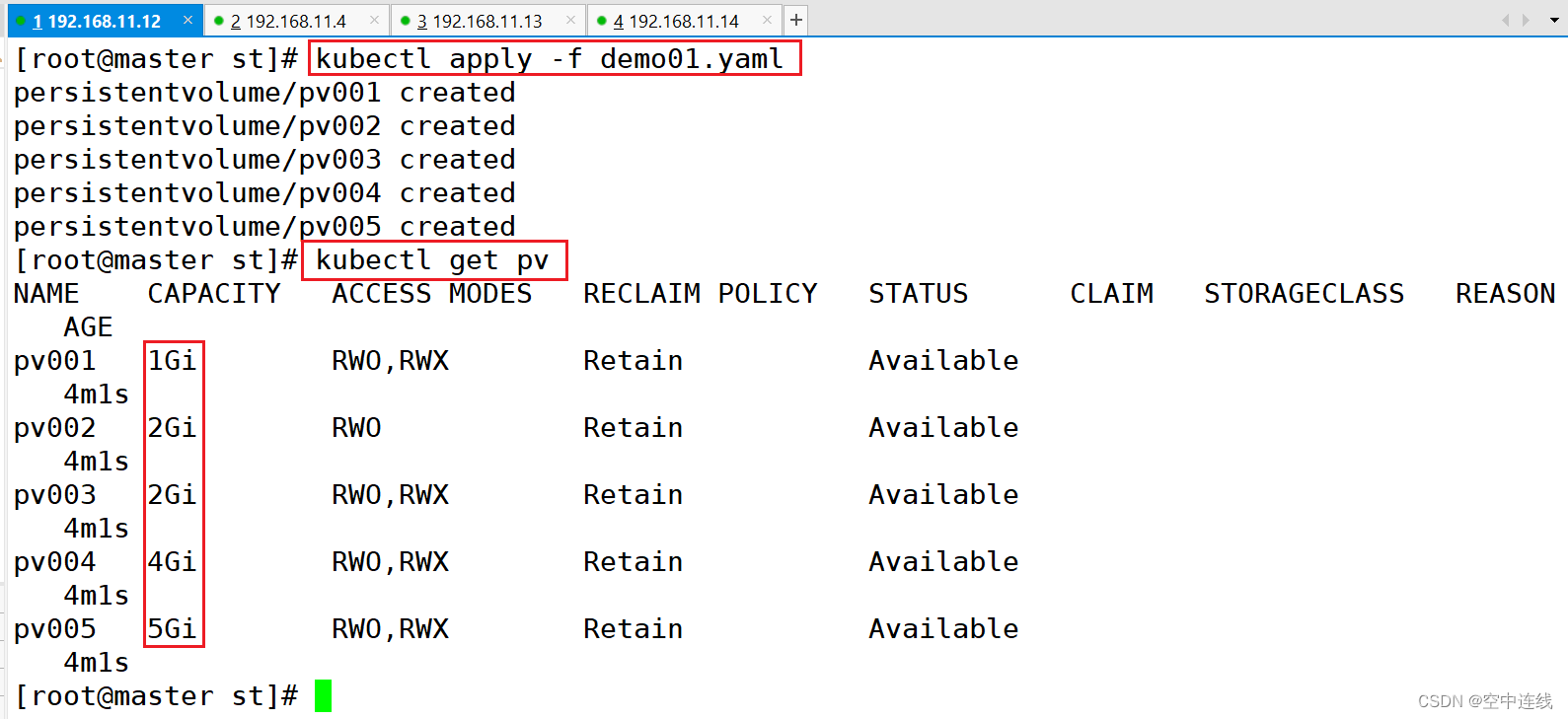
3 定义PVC
这里定义了pvc的访问模式为多路读写,该访问模式必须在前面pv定义的访问模式之中。定义PVC申请的大小为2Gi,此时PVC会自动去匹配多路读写且大小为2Gi的PV,匹配成功获取PVC的状态即为Bound
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: mypvcnamespace: default
spec:accessModes: ["ReadWriteMany"]resources:requests:storage: 2Gi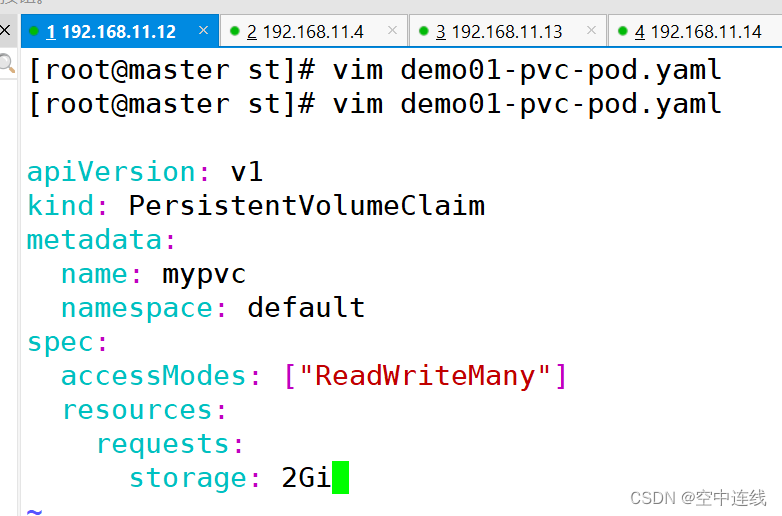
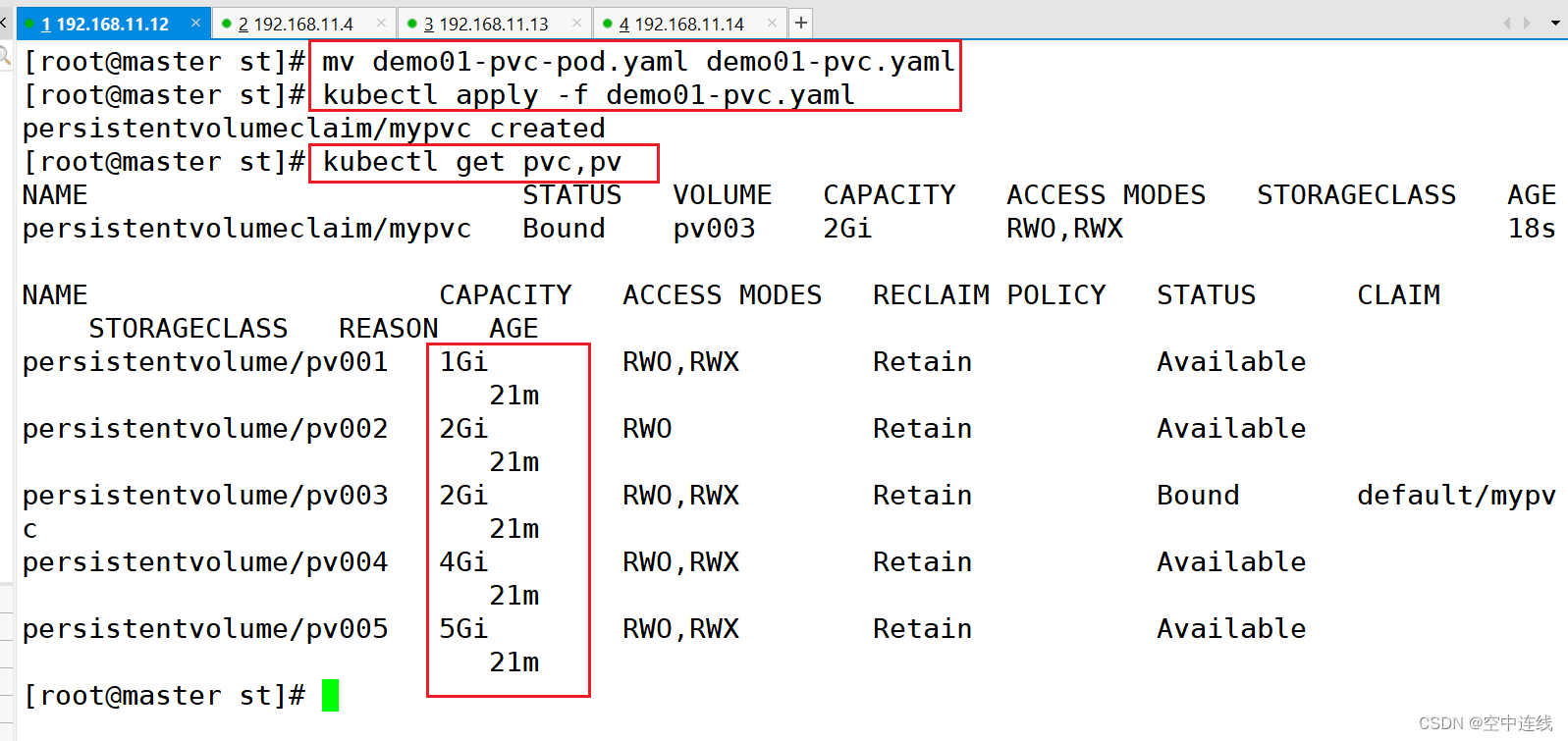
apiVersion: v1
kind: Pod
metadata:name: pod-vol-pvcnamespace: default
spec:containers:- name: myappimage: ikubernetes/myapp:v1volumeMounts:- name: htmlmountPath: /usr/share/nginx/htmlvolumes:- name: htmlpersistentVolumeClaim:claimName: mypvc
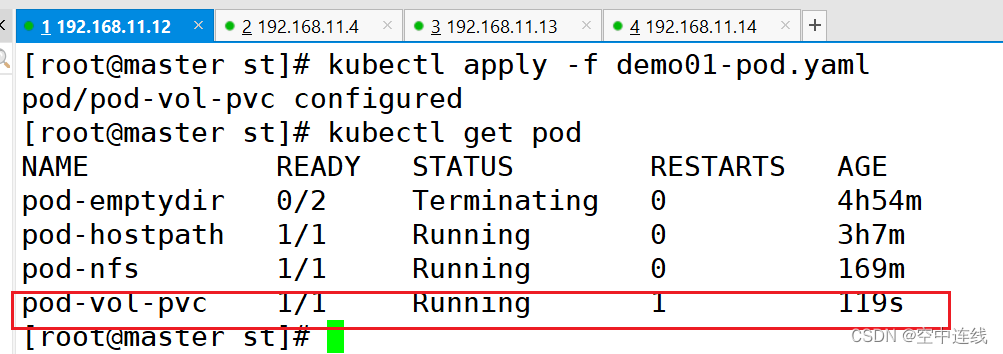
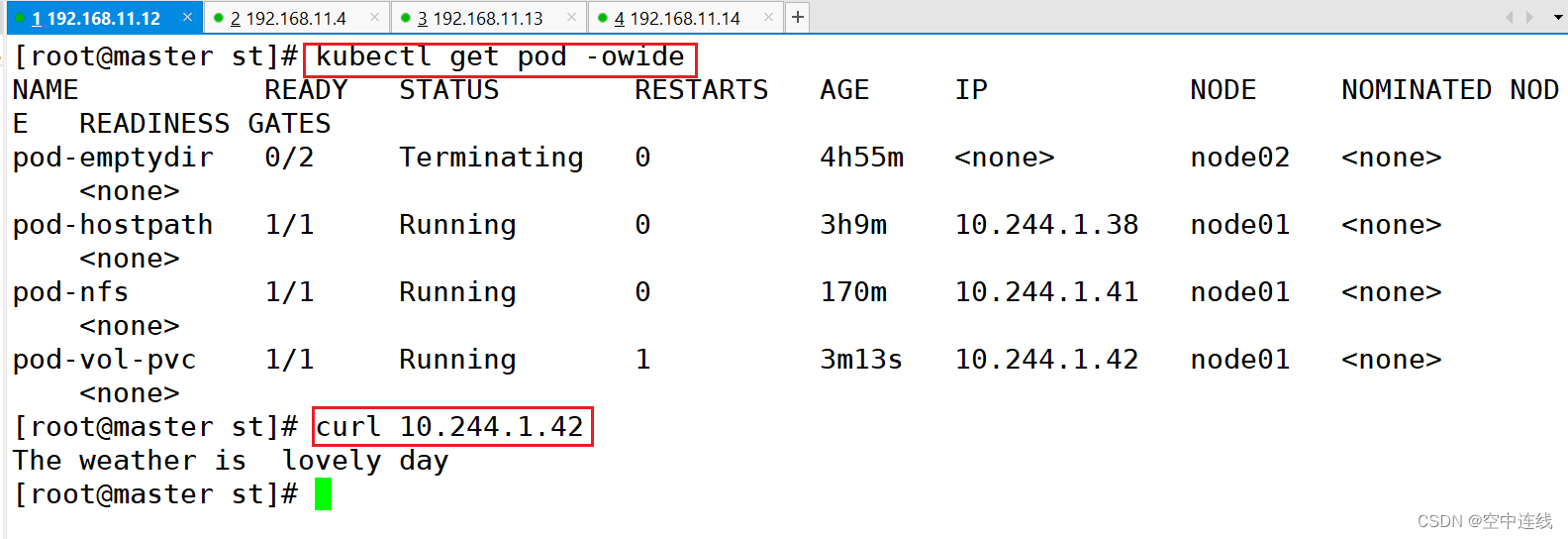
4 测试访问
在存储服务器上创建index.html,并写入数据,通过访问Pod进行查看,可以获取到相应的页面。
cd /data/volumes/v3/
echo "welcome to use pv3" > index.html

 五 搭建 StorageClass + NFS,实现 NFS 的动态 PV 创建
五 搭建 StorageClass + NFS,实现 NFS 的动态 PV 创建
成千上万就需要用动态资源去创建
Kubernetes 本身支持的动态 PV 创建不包括 NFS,所以需要使用外部存储卷插件分配PV。
https://kubernetes.io/zh/docs/concepts/storage/storage-classes/
卷插件称为 Provisioner(存储分配器),
NFS 使用的是 nfs-client,这个外部PV。Provisioner:用于指定 Volume 插件的类型,包括内置插件(如 kubernetes.io/aws-ebs)和外部插件(如 exte卷插件会使用已经配置好的 NFS 服务器自动创建 rnal-storage 提供的 ceph.com/cephfs)。
1 在stor01节点上安装nfs,并配置nfs服务
mkdir /opt/k8s
chmod 777 /opt/k8s/vim /etc/exports
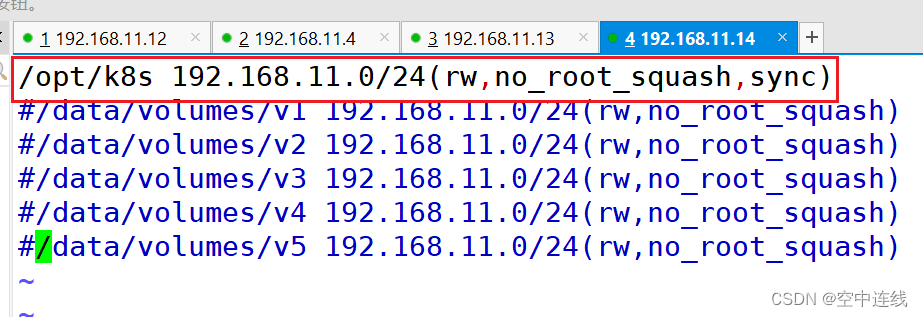
/opt/k8s 192.168.10.0/24(rw,no_root_squash,sync)systemctl restart nfs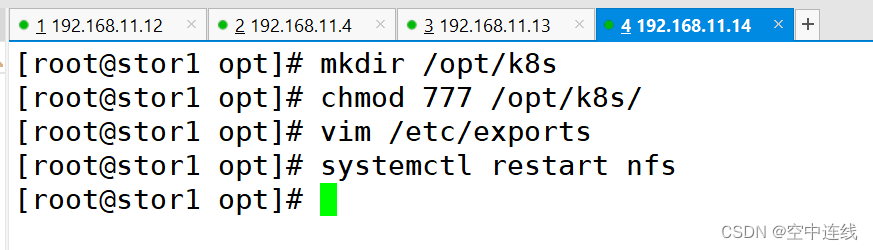
2 创建 Service Account,
用来管理 NFS Provisioner 在 k8s 集群中运行的权限,设置 nfs-client 对 PV,PVC,StorageClass 等的规则
vim nfs-client-rbac.yaml
创建 Service Account 账户,用来管理 NFS Provisioner 在 k8s 集群中运行的权限
apiVersion: v1
kind: ServiceAccount
metadata:name: nfs-client-provisioner
---
#创建集群角色
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: nfs-client-provisioner-clusterrole
rules:- apiGroups: [""]resources: ["persistentvolumes"]verbs: ["get", "list", "watch", "create", "delete"]- apiGroups: [""]resources: ["persistentvolumeclaims"]verbs: ["get", "list", "watch", "update"]- apiGroups: ["storage.k8s.io"]resources: ["storageclasses"]verbs: ["get", "list", "watch"]- apiGroups: [""]resources: ["events"]verbs: ["list", "watch", "create", "update", "patch"]- apiGroups: [""]resources: ["endpoints"]verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]
---
#集群角色绑定
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: nfs-client-provisioner-clusterrolebinding
subjects:
- kind: ServiceAccountname: nfs-client-provisionernamespace: default
roleRef:kind: ClusterRolename: nfs-client-provisioner-clusterroleapiGroup: rbac.authorization.k8s.io
3 使用 Deployment 来创建 NFS Provisioner
NFS Provisione(即 nfs-client),有两个功能:一个是在 NFS 共享目录下创建挂载点(volume),另一个则是将 PV 与 NFS 的挂载点建立关联。
#由于 1.20 版本启用了 selfLink,所以 k8s 1.20+ 版本通过 nfs provisioner 动态生成pv会报错,解决方法如下:
vim /etc/kubernetes/manifests/kube-apiserver.yaml
spec:containers:- command:- kube-apiserver- --feature-gates=RemoveSelfLink=false #添加这一行- --advertise-address=192.168.10.19
......kubectl apply -f /etc/kubernetes/manifests/kube-apiserver.yaml
kubectl delete pods kube-apiserver -n kube-system
kubectl get pods -n kube-system | grep apiserver

4 创建 NFS Provisioner
vim nfs-client-provisioner.yaml
kind: Deployment
apiVersion: apps/v1
metadata:name: nfs-client-provisioner
spec:replicas: 1selector:matchLabels:app: nfs-client-provisionerstrategy:type: Recreatetemplate:metadata:labels:app: nfs-client-provisionerspec:serviceAccountName: nfs-client-provisioner #指定Service Account账户containers:- name: nfs-client-provisionerimage: quay.io/external_storage/nfs-client-provisioner:latestimagePullPolicy: IfNotPresentvolumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAMEvalue: nfs-storage #配置provisioner的Name,确保该名称与StorageClass资源中的provisioner名称保持一致- name: NFS_SERVERvalue: stor01 #配置绑定的nfs服务器- name: NFS_PATHvalue: /opt/k8s #配置绑定的nfs服务器目录volumes: #申明nfs数据卷- name: nfs-client-rootnfs:server: stor01path: /opt/k8s
5 创建 PVC 和 Pod 测试
vim test-pvc-pod.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: test-nfs-pvc
spec:accessModes:- ReadWriteManystorageClassName: nfs-client-provisioner #关联StorageClass对象resources:requests:storage: 1Gi
---
apiVersion: v1
kind: Pod
metadata:name: test-storageclass-pod
spec:containers:- name: busyboximage: busybox:latestimagePullPolicy: IfNotPresentcommand:- "/bin/sh"- "-c"args:- "sleep 3600"volumeMounts:- name: nfs-pvcmountPath: /mntrestartPolicy: Nevervolumes:- name: nfs-pvcpersistentVolumeClaim:claimName: test-nfs-pvc #与PVC名称保持一致
PVC 通过 StorageClass 自动申请到空间
kubectl get pvc
查看 NFS 服务器上是否生成对应的目录,自动创建的 PV 会以 ${namespace}-${pvcName}-${pvName} 的目录格式放到 NFS 服务器上
ls /opt/k8s/
default-test-nfs-pvc-pvc-11670f39-782d-41b8-a842-eabe1859a456//进入 Pod 在挂载目录 /mnt 下写一个文件,然后查看 NFS 服务器上是否存在该文件
kubectl exec -it test-storageclass-pod sh
/ # cd /mnt/
/mnt # echo 'this is test file' > test.txt//发现 NFS 服务器上存在,说明验证成功
cat /opt/k8s/test.txt
相关文章:
PV PVC
默写 1 如何将pod创建在指定的Node节点上 node亲和、pod亲和、pod反亲和: 调度策略 匹配标签 操作符 nodeAffinity 主机 In,NotIn,Exists,DoesNotExist,Gt,Lt podAffinity …...

深入理解Nginx配置文件:全面指南
Nginx 是一个高性能的 HTTP 服务器和反向代理服务器,也是一个电子邮件(IMAP/POP3)代理服务器。由于其高效性和灵活性,Nginx 被广泛应用于各种 web 服务中。本文将详细介绍 Nginx 配置文件的结构和主要配置项,帮助你深入…...

【传知代码】自监督高效图像去噪(论文复现)
前言:在数字化时代,图像已成为我们生活、工作和学习的重要组成部分。然而,随着图像获取方式的多样化,图像质量问题也逐渐凸显出来。噪声,作为影响图像质量的关键因素之一,不仅会降低图像的视觉效果…...

linnux上安装php zip(ZipArchive)、libzip扩展
安装顺序: 安装zip(ZipArchive),需要先安装libzip扩展 安装libzip,需要先安装cmake 按照cmake、libzip、zip的先后顺序安装 下面的命令都是Linux命令 1、安装cmake 确认是否已安装 cmake --version cmake官网 未安装…...

油封制品中各种橡胶材料的差异
在机械系统中,油封起着关键的作用,其主要功能是防止润滑剂泄漏和污染物进入。油封的性能很大程度上取决于所用的橡胶材料。不同的橡胶化合物各有其独特的特性、优点和应用场景。本文将详细探讨油封制品中各种橡胶材料的差异,重点分析其特性、…...
梳理清楚的echarts地图下钻和标点信息组件
效果图 说明 默认数据没有就是全国地图, $bus.off("onresize")是地图容器变化刷新地图适配的,可以你们自己写 getEchartsFontSize是适配字体大小的,getEchartsFontSize(0.12) 12 mapScatter是base64图片就是图上那个标点的底图 Ge…...

【busybox记录】【shell指令】readlink
目录 内容来源: 【GUN】【readlink】指令介绍 【busybox】【readlink】指令介绍 【linux】【readlink】指令介绍 使用示例: 打印符号链接或规范文件名的值 - 默认输出 打印符号链接或规范文件名的值 - 打印规范文件的全路径 打印符号链接或规范文…...
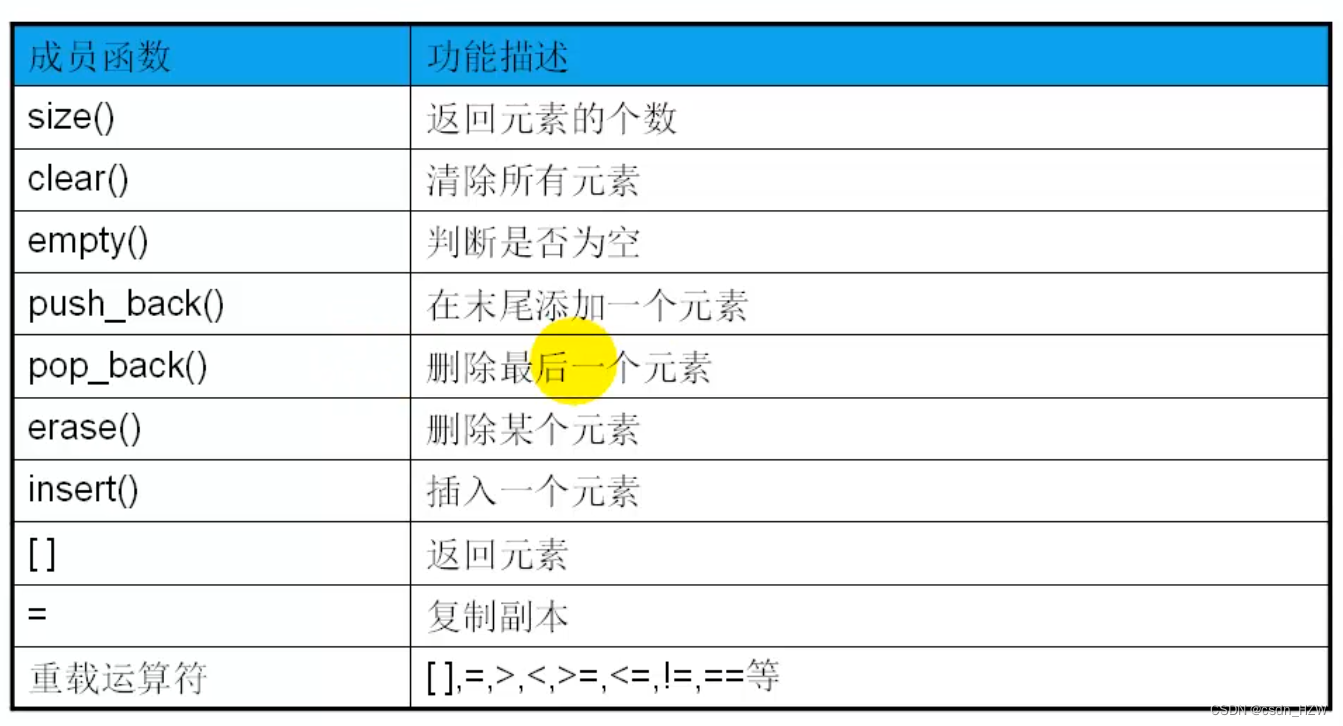
C++之vector
1、标准库的vector类型 2、vector对象的初始化 3、vector常用成员函数 #include <vector> #include <algorithm> #include <iostream> using namespace std;typedef vector<int> INTVEC;// 普通方法 //void showVec(const INTVEC& vec) // 这边如…...

【简单介绍下idm有那些优势】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...
MyBatis系统学习 - 使用Mybatis完成查询单条,多条数据,模糊查询,动态设置表名,获取自增主键
上篇博客我们围绕Mybatis链接数据库进行了相关概述,并对Mybatis的配置文件进行详细的描述,本篇博客也是建立在上篇博客之上进行的,在上面博客搭建的框架基础上,我们对MyBatis实现简单的增删改查操作进行重点概述,在MyB…...

Generative Action Description Prompts for Skeleton-based Action Recognition
标题:基于骨架的动作识别的生成动作描述提示 源文链接:https://openaccess.thecvf.com/content/ICCV2023/papers/Xiang_Generative_Action_Description_Prompts_for_Skeleton-based_Action_Recognition_ICCV_2023_paper.pdfhttps://openaccess.thecvf.c…...
代码实践 -深度学习基础-02线性回归基础版)
动手学深度学习(Pytorch版)代码实践 -深度学习基础-02线性回归基础版
02线性回归基础版 主要内容 数据生成:使用线性模型 ( y X*w b ) 加上噪声生成人造数据集。数据读取:通过小批量读取数据集来实现批量梯度下降,打乱数据顺序并逐批返回特征和标签。模型参数初始化:随机初始化权重和偏置&#x…...
信息学奥赛初赛天天练-15-阅读程序-深入解析二进制原码、反码、补码,位运算技巧,以及lowbit的神奇应用
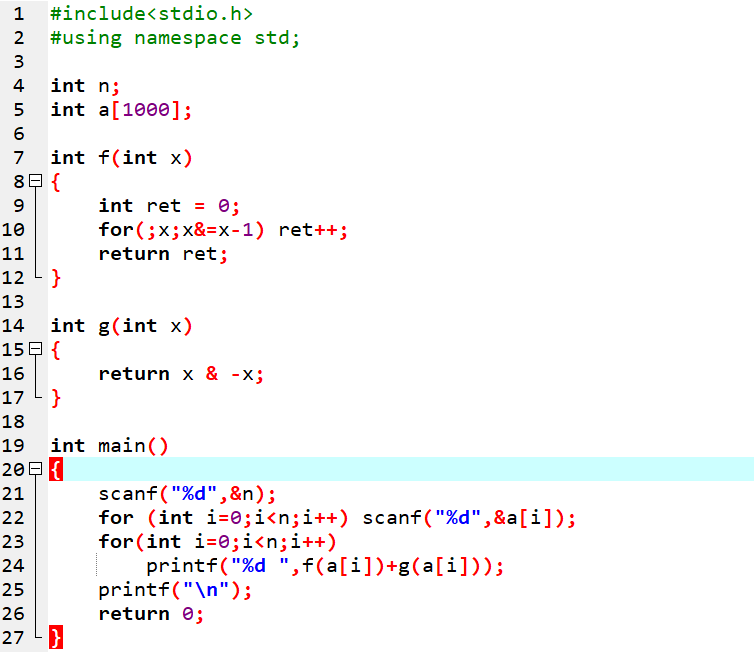
更多资源请关注纽扣编程微信公众号 1 2021 CSP-J 阅读程序1 阅读程序(程序输入不超过数组或字符串定义的范围;判断题正确填 √,错误填;除特 殊说明外,判断题 1.5 分,选择题 3 分) 源码 #in…...

期权具体怎么交易详细的操作流程?
期权就是股票,唯一区别标的物上证指数,会看大盘吧,交易两个方向认购做多,认沽做空,双向t0交易,期权具体交易流程可以理解选择方向多和空,选开仓的合约,买入开仓和平仓没了࿰…...
系统架构设计师【第3章】: 信息系统基础知识 (核心总结)
文章目录 3.1 信息系统概述3.1.1 信息系统的定义3.1.2 信息系统的发展3.1.3 信息系统的分类3.1.4 信息系统的生命周期3.1.5 信息系统建设原则3.1.6 信息系统开发方法 3.2 业务处理系统(TPS)3.2.1 业务处理系统的概念3.2.2 业务处理系统的功能 …...
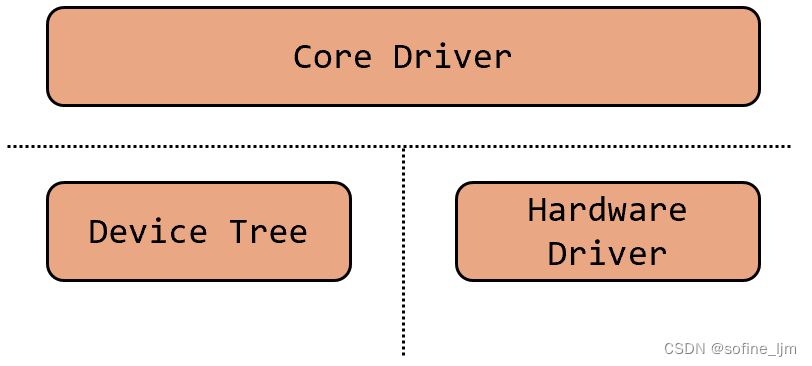
Linux 驱动设备匹配过程
一、Linux 驱动-总线-设备模型 1、驱动分层 Linux内核需要兼容多个平台,不同平台的寄存器设计不同导致操作方法不同,故内核提出分层思想,抽象出与硬件无关的软件层作为核心层来管理下层驱动,各厂商根据自己的硬件编写驱动…...

游戏子弹类python设计与实现详解
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、引言 二、子弹类设计思路 1. 属性定义 2. 方法设计 三、子弹类实现详解 1. 定义子弹…...
——列表)
Python基础学习笔记(六)——列表
目录 一、一维列表的介绍和创建二、序列的基本操作1. 索引的查询与返回2. 切片3. 序列加 三、元素的增删改1. 添加元素2. 删除元素3. 更改元素 四、排序五、列表生成式 一、一维列表的介绍和创建 列表(list),也称数组,是一种有序、…...

帝国CMS跳过选择会员类型直接注册方法
国CMS因允许多用户组注册,所以在注册页面会有一个选择注册用户组的界面,即使网站只用了一个用户组也会出现。 如果想去掉这个页面,直接进入注册页面,那么可按以下办法修改 打开 e/class/user.php 文件 查找: $chan…...
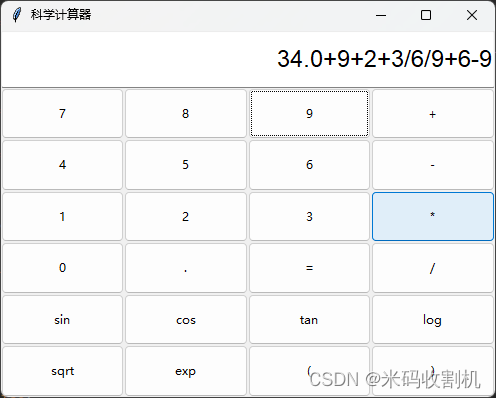
【python】python tkinter 计算器GUI版本(模仿windows计算器 源码)【独一无二】
👉博__主👈:米码收割机 👉技__能👈:C/Python语言 👉公众号👈:测试开发自动化【获取源码商业合作】 👉荣__誉👈:阿里云博客专家博主、5…...

Gradio界面定制化:为DAMO-YOLO WebUI添加导出检测结果CSV功能
Gradio界面定制化:为DAMO-YOLO WebUI添加导出检测结果CSV功能 1. 项目背景与需求 如果你用过那个基于DAMO-YOLO的手机检测WebUI,可能会发现一个问题:检测结果只能看,不能存。 每次上传图片,系统会告诉你检测到了几个…...

从CPU指令到C++代码:拆解 std::atomic fetch_add 在 x86 和 ARM 平台上的底层实现与性能差异
从CPU指令到C代码:拆解 std::atomic fetch_add 在 x86 和 ARM 平台上的底层实现与性能差异 在现代高性能并发编程中,原子操作是构建无锁数据结构和线程安全代码的基石。std::atomic 的 fetch_add 操作看似简单,但其底层实现却因硬件架构差异而…...
)
从数据集到GUI应用:手把手教你用YOLOv11训练自己的手势识别模型(保姆级教程)
从数据集到GUI应用:手把手教你用YOLOv11训练自己的手势识别模型(保姆级教程) 在计算机视觉领域,手势识别技术正逐渐从实验室走向实际应用。无论是智能家居控制、虚拟现实交互,还是无障碍通信系统,准确快速的…...

OpenClaw数据可视化:GLM-4.7-Flash分析结果自动图表生成
OpenClaw数据可视化:GLM-4.7-Flash分析结果自动图表生成 1. 为什么需要自动化数据可视化 作为一名经常需要处理数据的开发者,我发现自己80%的时间都花在了数据清洗和图表调整上。每次分析新数据集时,都要重复这些步骤:写Python脚…...

从ONNX到MLU:基于MagicMind的GFPGANv1.4超分模型部署与性能调优实战
1. 环境准备与模型转换 寒武纪MLU平台上的AI模型部署需要从基础环境搭建开始。我最近在MLU370-M8卡上部署GFPGANv1.4超分模型时,发现选择合适的Docker镜像是第一步关键。官方推荐的pytorch:v24.10镜像已经预装了torch2.4.0和torchmlu1.23.1,这省去了大量…...

探索Rufus全新应用场景:为老旧设备注入Windows 11新生命
探索Rufus全新应用场景:为老旧设备注入Windows 11新生命 【免费下载链接】rufus The Reliable USB Formatting Utility 项目地址: https://gitcode.com/GitHub_Trending/ru/rufus 还在为Windows 11严格的硬件要求而烦恼吗?你的旧电脑完全可以运行…...

终极go2rtc流媒体解决方案:3分钟搭建多协议摄像头管理系统
终极go2rtc流媒体解决方案:3分钟搭建多协议摄像头管理系统 【免费下载链接】go2rtc Ultimate camera streaming application with support RTSP, RTMP, HTTP-FLV, WebRTC, MSE, HLS, MP4, MJPEG, HomeKit, FFmpeg, etc. 项目地址: https://gitcode.com/GitHub_Tre…...

【同态加密实战】从Paillier到BFV:算法原理与编码艺术深度解析
1. 同态加密:数据隐私保护的魔法钥匙 想象一下,你有一把能锁住数据的魔法钥匙——即使数据被锁在箱子里,别人依然可以对箱子里的数据进行计算,而无需打开箱子看到原始内容。这就是同态加密的神奇之处。作为密码学领域的"圣杯…...

TypeScript——模块解析
模块解析1、相对模块导入2、非相对模块导入3、模块解析策略4、模块解析策略之Classic4.1、解析相对模块导入4.2、解析非相对模块导入5、模块解析策略之Node5.1、解析相对模块导入5.2、解析非相对模块导入6、--baseUrl6.1、设置--baseUrl6.2、解析--baseUrl7、paths7.1、设置pat…...

LyricsX深度解析:macOS平台终极歌词解决方案的技术实现与高级应用
LyricsX深度解析:macOS平台终极歌词解决方案的技术实现与高级应用 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX LyricsX是一款专为macOS设计的终极歌词应用,通过…...