mongodb在游戏开发领域的优势
1、分布式id
游戏服务器里的大部分数据都是要求全局唯一的,例如玩家id,道具id。之所以有这种要求,是因为运营业务上需要进行合服操作,保证不同服的数据在进行合服之后,也能保证id不冲突。如果采用关系型数据库(例如mysql),常见的分布式id算法有以下方法。
- 分段步长:把long型数字的前N位标记为区服id,剩余的后面所有位用作计算器自增长,并把最大的id进行持久化。
- 雪花算法变种:将雪花算法与游戏区服、系统时间戳、计算器结合起来。
详情可参考: 游戏服务器框架之分布式id生成器
如果选择mongodb,由于其内置一个非常简单高效的分布式id生成算法,可以直接使用。不用业务代码自行设计。
详情可参考: Mongodb分布式id
2、数据库ddl自动化
目前,很多orm框架都不支持自动建表加字段(原生的mybatics,mybatics-plus均不支持,hibernate支持),因为要实现这个功能,需要应用层使用jpa或者其他注解显示表明哪些字段是需要持久化以及对应的类型。
而mongodb。甚至支持在同一个文档里有不同的文档结果。不过这种支持在应用层通常不会这么做,容易造成业务代码混乱。试想一下,把数据库的全部表数据全部打包到单独一个数据表,这种设计绝对是个噩梦。
-
自动创建集合:在 MongoDB 中,当你尝试向尚不存在的集合中插入一个文档时,MongoDB 会自动创建该集合。例如,如果你有一个文档并尝试将其保存到数据库中,而该集合不存在,MongoDB 将自动创建它。
db.mycollection.insertOne({name: "example", value: "data"}) -
自动添加字段:当你插入一个新文档或更新现有文档时,如果文档中包含集合中其他文档不存在的字段,MongoDB 会自动将这些字段添加到文档中。例如:
db.mycollection.updateOne({}, {$set: {newField: "value"}}, {upsert: true})这个命令会为集合中的每个文档添加
newField字段,如果文档中已经存在该字段,则会更新它的值。 -
使用
$set操作符:$set操作符可以用来为文档添加新字段或更新现有字段的值。如果指定的字段不存在,它会被添加。db.mycollection.updateMany({}, {$set: {newField: "defaultValue"}}, {multi: true})
3、嵌套数据处理
使用关系型数据,当我们需要保存用户某一个模块的内容,比如vip数据,我们一般会在Player类加一个嵌套bean,例如叫VipRight。这个嵌套的bean映射到MySQL,可以表示为一个字段。针对一个javabean到一个mysql字段的转换,通常有两种方法。
第一种,同时申明一个bean对象以及这个对象对应的json字符串,类似下面的定义
@Data
public class Player {private String id;private VipRight vipRight;private String vipRightJson;}其中,VipRight又是另外一个javabean,定义如下:
@Data
public class VipRight {private int level;private int exp;
}
当我们从数据库里读取记录时,需要先将json进行反序列化为对应的javabean;当我们写入数据库的时候,则将javabean序列化为json,再持久化到数据库。这种方法写起来非常啰嗦。
另外一种方式,则是通过自定义的orm工具,通过特定的注解,程序自动将json与bean进行转换。例如jforgame-orm工具,就是采用这种方式。
@Data
public class PlayerEnt implements BaseEntity<Long> {@Id@Columnprivate long playerId;/*** 所属账号id*/@Columnprivate long accountId;@Columnprivate String name;@Columnprivate int level;@Column@Convert(converter = JpaObjectConverter.class)private VipRight vipRight;
}如果采用Mongodb,则这种问题不复存在。Mongodb天生支持嵌套文档,springdata mongodb自动会对其进行转换,如下代码:
@Data
@Document("player")
public class Player {@Idprivate String id;@Fieldprivate VipRight vipRight;}4、对嵌套bean数据的查询
还是以上边的例子,如果程序需要在启服的时候捞取vip等级前50的数据作为排行榜,如果采用mysql的话,由于mysql查询不支持json子查询,我们不得不在player类增加一个冗余字段,额外保存vip等级,例如下面的代码。在更新的时候需要两个位置一起更新,非常麻烦。
@Data
public class Player {private String id;private VipRight vipRight;private String vipRightJson;//冗余vip等级字段private int vipLevel;}
采用mongodb的话,由于其支持嵌套子查询,直接一个子bean搞定,在springdata mongodb里,插入与查询只需如下代码:
PlayerRepository bean = SpringContext.getBean(PlayerRepository.class);Player demo = new Player();VipRight vipRight = new VipRight();vipRight.setExp(111);vipRight.setLevel(100);demo.setVipRight(vipRight);bean.insert(demo);List<Player> byVipRight = bean.findByVipRight(100);System.out.println(byVipRight.size());其中,嵌套文档查询需要用自定义的行为
import org.springframework.data.mongodb.repository.MongoRepository;
import org.springframework.data.mongodb.repository.Query;
import org.springframework.stereotype.Repository;
import org.tea.editor.domain.Player;import java.util.List;@Repository
public interface PlayerRepository extends MongoRepository<Player, String> {@Query("{'vipRight.level':?0}")List<Player> findByVipRight(int level);
}
如果使用mongosh查询的话,查询语句如下:
db.player.find({"vipRight.level":100})
//输出结果
[{_id: ObjectId('664ac4453b9f7f0308a03f2a'),vipRight: { level: 100, exp: 111 },_class: 'org.jforgame.Player'}
]5、水平拓展
水平扩展意味着单个游戏服务器能够存储更多的玩家,例如大世界架构的服务器,需要存储大容量的游戏数据。然而,目前流行的手游,或者小游戏,大部分基于“滚服模式”,本身也不要求数据库存储大量的游戏数据,而是将游戏拆分成一个一个相对独立,较小容量的区服。因此,水平扩展对于大部分游戏架构的吸引力不强。
MongoDB 水平扩展:
MongoDB 支持通过分片集群实现数据的水平扩展。分片是一种将数据分布到多个服务器或集群上的技术,通过将数据分成多个片段并存储在多个服务器上,MongoDB 能够提高数据库的存储容量和吞吐量。分片集群包含两个主要概念:
- 分片:将数据分割成多个片段,每个片段存储在集群中的一台服务器上。
- 副本集:副本集是分片集群中的一种数据冗余技术,通过在多个服务器上保存同一份数据的副本来确保数据的可靠性和可用性。
分片集群的优点包括:
- 读写水平扩展:MongoDB 可以将读写负载分布到集群中的不同分片上,提高吞吐量,并在高并发情况下保持高性能。
- 数据冗余和可用性:副本集提供数据冗余和可用性保障,即使某个服务器发生故障,也能快速切换到其他可用服务器上。
MySQL 水平扩展:
MySQL 的水平扩展能力相对有限,通常需要通过分库分表的方式来实现。水平拆分是通过某种策略将数据分片存储,每片数据分散到不同的MySQL表或库,达到分布式的效果。MySQL的水平扩展主要包括:
- 表分区:MySQL 支持表分区,这是一种简单的水平拆分,用户需要在建表时加上分区参数,对应用是透明的无需修改代码。
- 读写分离:通过主从复制,可以实现读写分离,提高数据库的读取性能。
- 分库分表:通过将数据分布到不同的MySQL实例,实现水平扩展。
MySQL 水平扩展的策略可能涉及:
- 垂直拆分:根据数据库内数据表的相关性进行拆分。
- 水平拆分:通过某种策略将数据分片存储,每片数据分散到不同的MySQL表或库。
水平扩展策略的选择需要考虑数据的增长模式、访问模式、分片关联性问题以及分片扩容问题。每种策略都有其优缺点,需要根据具体的业务需求和场景来决定最合适的扩展方案。
相关文章:

mongodb在游戏开发领域的优势
1、分布式id 游戏服务器里的大部分数据都是要求全局唯一的,例如玩家id,道具id。之所以有这种要求,是因为运营业务上需要进行合服操作,保证不同服的数据在进行合服之后,也能保证id不冲突。如果采用关系型数据库&#x…...

大数据Scala教程从入门到精通第十篇:Scala在IDEA中编写Hello World代码的简单说明
一:代码展示 object Main {def main(args: Array[String]): Unit {//SCALA中可以不写;//绿色的小三角达标的是这个类中有一个MAIN方法代表是可以执行的。//ctrl shift f10可以直接运行println("Hello world!")//Java中的类库我们可以直接使用System.o…...

【SPSS】基于因子分析法对水果茶调查问卷进行分析
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
ElasticSearch学习篇12_《检索技术核心20讲》基础篇
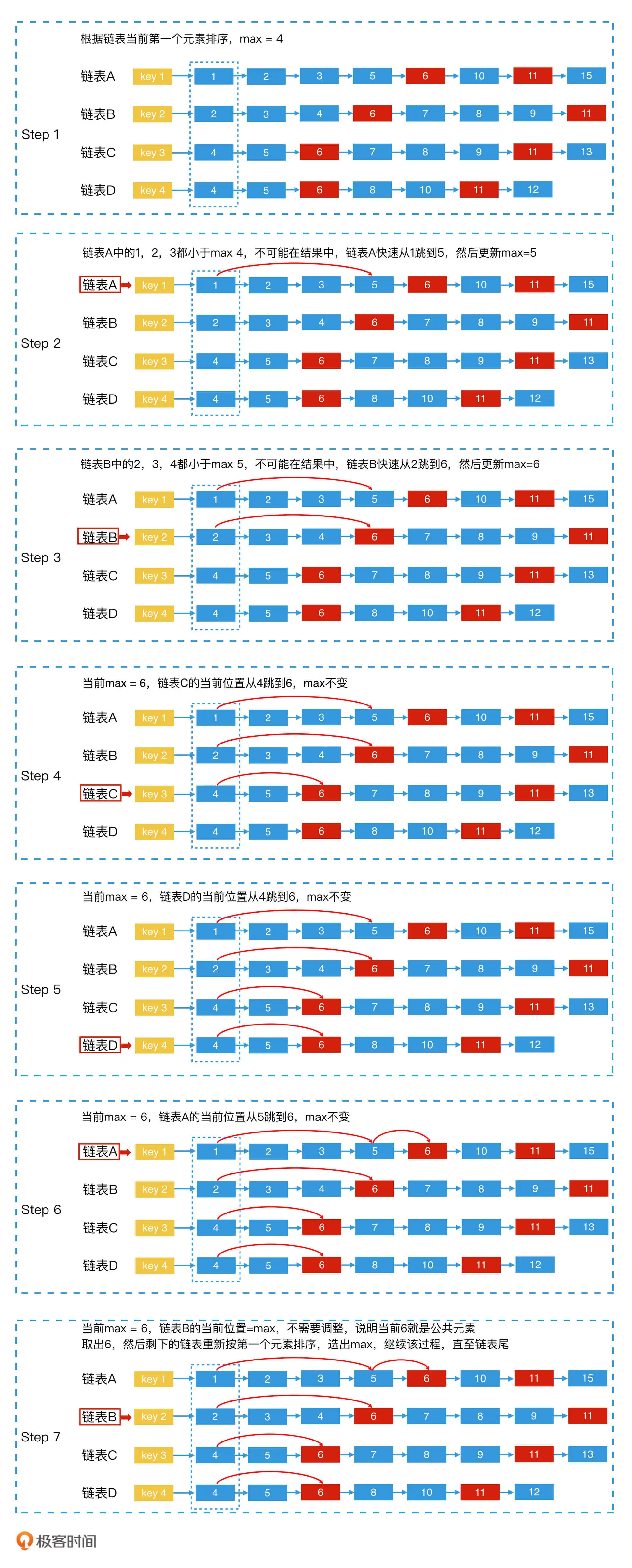
背景 学习极客实践课程《检索技术核心20讲》https://time.geekbang.org/column/article/215243 课程分为基础篇、进阶篇、系统案例篇 主要记录企业课程学习过程课程大纲关键点,以文档形式记录笔记。 内容 检索技术:它是更底层的通用技术,…...
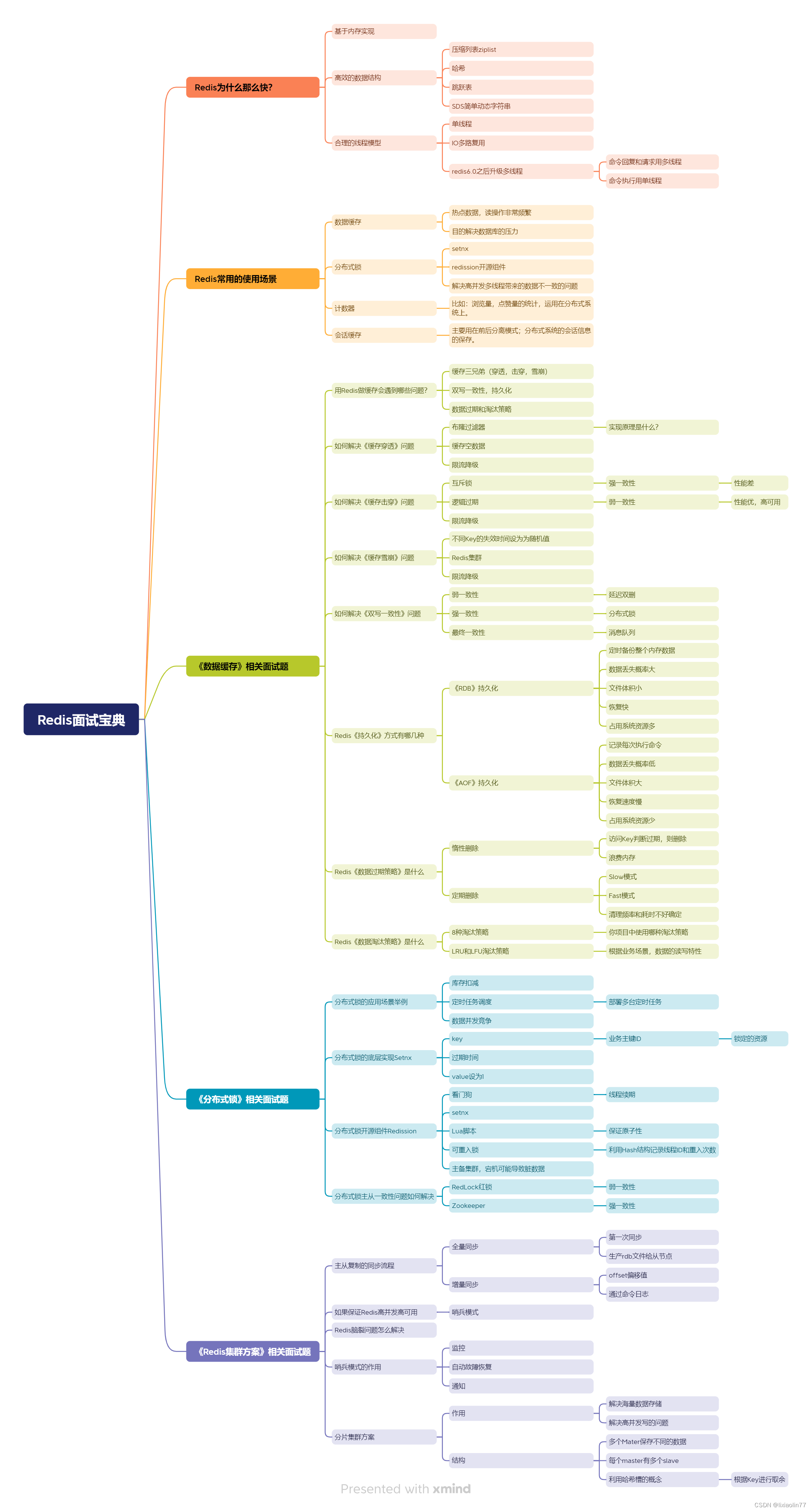
Reids高频面试题汇总总结
一、Redis基础 Redis是什么? Redis是一个开源的内存数据存储系统,它可以用作数据库、缓存和消息中间件。Redis支持多种数据结构,如字符串、哈希表、列表、集合、有序集合等,并提供了丰富的操作命令来操作这些数据结构。Redis的主要特点是什么? 高性能:Redis将数据存储在内…...
19 - grace数据处理 - 补充 - 地下水储量计算过程分解 - 冰后回弹(GIA)改正
19 - grace数据处理 - 补充 - 地下水储量计算过程分解 - 冰后回弹(GIA)改正 0 引言1 gia数据处理过程0 引言 由水量平衡方程可以将地下水储量的计算过程分解为3个部分,第一部分计算陆地水储量变化、第二部分计算地表水储量变化、第三部分计算冰后回弹改正、第四部分计算地下…...
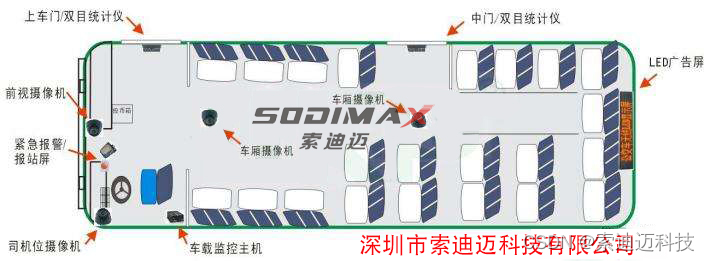
车载客流统计设备:双目3D还原智能统计算法的应用与优势
随着城市交通的日益繁忙和公共交通系统的不断完善,对公交车等交通工具的客流统计和分析变得越来越重要。传统的客流统计方法往往存在效率低下、精度不足等问题,难以满足现代城市交通管理的需求。而基于双目3D还原智能统计算法的车载客流统计设备…...
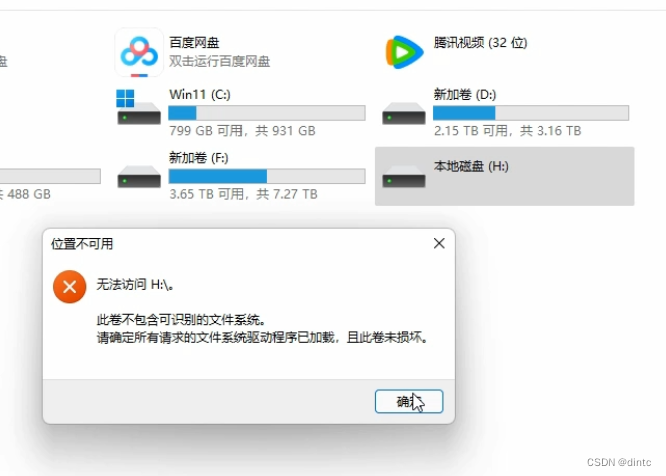
U盘无法打开?数据恢复与预防措施全解析
在日常生活和工作中,U盘已成为我们存储和传输数据的重要工具。然而,有时我们会遇到U盘无法打开的情况,这无疑给我们带来了诸多不便。本文将深入探讨U盘打不开的现象、原因及解决方案,并分享如何预防此类问题的发生。 一、U盘无法访…...

apollo版本更新简要概述
apollo版本更新简要概述 Apollo 里程碑版本9.0重要更新Apollo 开源平台 9.0 的主要新特征如下:基于包管理的 PnC 扩展开发范式基于包管理的感知扩展开发范式全新打造的 Dreamview Plus 开发者工具感知模型全面升级,支持增量训练 版本8.0版本6.0 Apollo 里…...

基于心电疾病分类的深度学习模型部署应用于OrangePi Kunpeng Pro开发板
一、开发板资源介绍 该板具有4核心64位的处理器和8TOPS的AI算力,让我们验证一下,在该板上跑深度学习模型的效果如何? 二、配网及远程SSH登录访问系统 在通过microusb连接串口进入开发板调试,在命令行终端执行以下命令 1&#…...

vue中axios的使用
1.get请求 axios.get(http://127.0.0.1:2333/show_course, {params: {param: choice} }) .then((response) > {this.list response.data; }) .catch((error) > {console.error(error); }); 2.post请求:当需要向服务器提交数据以创建新资源时使用。例如&…...

Spark SQL【Java API】
前言 之前对 Spark SQL 的影响一直停留在 DSL 语法上面,感觉可以用 SQL 表达的,没有必要用 Java/Scala 去写,但是面试一段时间后,发现不少公司还是在用 SparkSQL 的,京东也在使用 Spark On Hive 而不是我以为的 Hive O…...
文心智能体平台丨创建你的四六级学习小助手
引言 在人工智能飞速发展的今天,我们迎来了文心智能体平台。该平台集成了最先进的人工智能技术,旨在为用户提供个性化、高效的学习辅助服务。今天,我们将向大家介绍如何利用文心智能体平台,创建一个专属于你的四六级学习小助手。…...
)
js全国省市区JSON数据(全)
AreaJson 就是全国省市区的具体数据信息,下面我自定义了一些方法,获取数据用的,不需要的可以删掉,只拿JSON内的数据即可 const AreaJson [{"name": "北京市","city": [{"name": "…...

轻量级 C Logger
目录 一、描述 二、实现效果 三、使用案例 四、内存检测 一、描述 最近实现一个 WS 服务器,内部需要一个日志打印记录服务器程序的运行过程,故自己实现了一个轻量级的 logger,主要包含如下特征: 可输出 debug、info、warn、er…...

哪里能下载到合适的衣柜3D模型素材?
室内设计师在进行家居设计时,衣柜3D模型素材是非常重要的工具。那么,哪里能下载到合适的衣柜3D模型素材呢? 一、建e网: ①建e网是一个专注于3D模型素材分享的平台,上面可以找到大量的衣柜3D模型。 ②该网站提供的模型种类丰富&am…...

计算机毕业设计 | SpringBoot+vue仓库管理系统(附源码)
1,绪论 1.1 项目背景 随着电子计算机技术和信息网络技术的发明和应用,使着人类社会从工业经济时代向知识经济时代发展。在这个知识经济时代里,仓库管理系统将会成为企业生产以及运作不可缺少的管理工具。这个仓库管理系统是由:一…...

【Python】解决Python报错:TypeError: can only concatenate str (not “int“) to str
🧑 博主简介:阿里巴巴嵌入式技术专家,深耕嵌入式人工智能领域,具备多年的嵌入式硬件产品研发管理经验。 📒 博客介绍:分享嵌入式开发领域的相关知识、经验、思考和感悟,欢迎关注。提供嵌入式方向…...

大数据技术分享 | Kylin入门系列:基础介绍篇
Kylin入门教程 在大数据时代,如何高效地处理和分析海量数据成为了企业面临的挑战之一。Apache Kylin作为一个开源的分布式分析引擎,提供了Hadoop之上的SQL查询接口及多维分析(OLAP)能力,使得对超大规模数据集的分析变…...

程序猿转型做项目经理一定要注意这 5 个坑
前言 国内的信息系统项目经理,很多都是从技术骨干转型的,我就是这样一路走过来的,这样有很多好处,比如技术过硬容易服众、熟悉开发流程更容易把控项目进度和质量、开发过程中碰到难题时更好组织攻坚等等,但是所谓成也…...

GA/T 1400视图库实战:从零部署Easy1400平台到设备级联全流程解析
1. 初识GA/T 1400与Easy1400平台 第一次接触GA/T 1400标准时,我完全被各种专业术语绕晕了。简单来说,这是一套专门针对视频监控领域的行业标准,规定了视频图像信息在采集、传输、存储等环节的技术要求。而Easy1400就是基于这个标准开发的一套…...

打破平台壁垒:Windows上安装APK文件的完整解决方案
打破平台壁垒:Windows上安装APK文件的完整解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过在Windows电脑上直接运行安卓应用ÿ…...

DownKyi完全指南:三步解锁B站8K视频下载的终极方案
DownKyi完全指南:三步解锁B站8K视频下载的终极方案 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等ÿ…...

开源机械爪控制库:从PID算法到ROS集成的全栈开发指南
1. 项目概述:一个开源的机械爪设计与控制库最近在机器人硬件开发的圈子里,开源项目“MeyerZhou/openclaw”引起了不少创客和机器人爱好者的注意。简单来说,这是一个专注于机械爪(或称机械手、夹爪)设计与控制的代码库和…...

dotai:将AI大模型无缝集成到Shell终端的智能助手工具
1. 项目概述:当AI遇上你的终端如果你是一个重度命令行用户,每天在终端里敲击着ls、cd、git commit这些命令,有没有那么一瞬间,希望有个助手能帮你自动补全、解释命令,甚至直接帮你写出复杂的管道操作?dotai…...

基于MCP协议构建AI数据连接器:从原理到SQL查询服务器实践
1. 项目概述:一个连接AI与数据源的“翻译官”最近在折腾AI应用开发,特别是想让大语言模型(LLM)能直接、安全地访问我自己的数据库、API或者文件系统时,遇到了一个普遍难题:怎么让AI理解并操作这些外部数据源…...

探索下一代命令行界面:OpenCLI 架构设计与插件化实践
1. 项目概述:一个面向未来的命令行界面原型最近在开源社区里,我注意到一个名为sys-fairy-eve/nightly-mvp-2026-03-19-opencli的项目。这个标题信息量不小,它不像一个成熟的产品,更像是一个开发过程中的里程碑快照。sys-fairy-eve…...

如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南
如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南 【免费下载链接】wedecode 全自动化,微信小程序 wxapkg 包 源代码还原工具, 线上代码安全审计,支持 Windows, Macos, Linux 项目地址: https://gitcode.com/gh…...

AI全栈开发实战:基于Cursor的智能代码生成与架构设计
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI代码编辑器有关,并且涉及全栈应用开发。但它的价值远不止于此。作为一个在前…...

医院内外部人员管理系统
基于计算机视觉技术的医院人员综合管理解决方案,整合人脸识别考勤与行人流量监控两大核心能力,实现内部员工身份验证、自动打卡签到,以及公共区域人流量实时统计与可视化分析,提升医院管理效率与安全保障水平。 [📺 系…...