【C++】入门(一):命名空间、缺省参数、函数重载
目录
一、关键字
二、命名空间
问题引入(问题代码):
域的问题
1.::域作用限定符 的 用法:
2.域的分类
3.编译器的搜索原则
命名空间的定义
命名空间的使用
举个🌰栗子:
1.作用域限定符指定命名空间名称
2. using 引入命名空间中的成员 即 展开命名空间中某一个
3. usinng namespace 命名空间名称 展开命名空间
三、C++输入、输出
四、缺省参数
概念
全缺省参数
半缺省参数
实践中的应用场景🌰举个例子:
声明和定义分离
回顾 声明 和定义的概念
再来分析上述程序
理解编译与链接的过程
理解函数与文件的关系
五、函数重载
代码示例:
C++是如何支持函数重载的?
函数名修饰
一、关键字
| asm | do | if | return | try | continue |
|---|---|---|---|---|---|
| auto | double | inline | short | typedef | for |
| bool | dynamic_cast | int | signed | typeid | public |
| break | else | long | sizeof | typename | throw |
| case | enum | mutable | static | union | wchar_t |
| catch | explicit | namespace | static_cast | unsigned | default |
| char | extern | operator | switch | virtual | register |
| const | false | private | template | void | true |
| const_cast | float | protected | this | volatile | while |
| delete | goto | reinterpret_cast |
增加的关键字: C++增加了一些关键字来支持面向对象编程(如类、继承、多态等)和模板编程。例如,class,public,protected,private,virtual,friend,template,typename等。这些关键字没有在C语言中。
类型增强:C++增加了一些用于类型安全和方便的关键字,如bool,true,false,using,namespace等。
异常处理:为了支持异常处理,C++引入了try,catch,throw等关键字。
新的转换操作符:C++提供了static_cast,dynamic_cast,const_cast和reinterpret_cast等关键字进行类型转换,这是C语言中所没有的。
增强的存储类说明符:C++引入了mutable和thread_local等存储类说明符。
模板编程:为了支持泛型编程,C++增加了template和typename关键字。
新增运算符:C++还定义了如new,delete等用于动态内存管理的关键字,这些在C中通常通过库函数如malloc和free来实现。
特殊成员函数关键字:C++还有如default和delete等关键字,用于特殊成员函数的声明,这样设计是为了提供更好的控制。
二、命名空间
问题引入(问题代码):
下面代码存在命名冲突 : rand变量 和头文件<stdlib.h>中声明的函数 rand() 名字相同 导致冲突。
#include<stdio.h>
#include<stdlib.h> /*rand*/
int rand = 0;
// C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespaceguan来解决
int main()
{printf("%d\n",rand);return 0;
}域的问题
1.::域作用限定符 的 用法:
限定符左边是哪一个域名 就限定了访问该变量的范围
左边是空 默认是全局域
2.域的分类
-
全局域
-
局部域:如果不用限定符,默认访问局部域 局部优先
-
命名空间域:为了防止命名冲突 eg.全局定义两个同名变量 ,防止重定义,C++提出就用关键字namespace把他们定义在不同命名空间域中。
-
类域
注意:
全局域、局部域既会影响生命周期,也会影响访问。命名空间只影响访问
3.编译器的搜索原则
1️⃣当前局部域 2️⃣全局域 3️⃣如果指定了,直接去指定域搜索
命名空间的定义
正常定义
// 正常的命名空间定义
namespace hhh
{// 命名空间中可以定义变量/函数/类型int rand = 10;int Add(int left, int right){return left + right;}struct Node{struct Node* next;int val;};}嵌套定义
举个栗子🌰:
namespace aaa
{namespace bbb{void Push(){cout<<"zs"<<endl;}}namespace ccc{void Push(){cout<<"yyy"<<endl;}}
}
int main()
{//嵌套定义在命名空间的同名函数 各自调用bit::bbb::Push();bit::ccc::Push();return 0;
}ps:命名空间可以重名,编译器会把他们合并,只要命名空间内部不冲突就可以
命名空间的使用
命名空间到底该如何使用?
举个🌰栗子:
namespace yyy
{//命名空间中定义 变量 / 函数 /类型int a = 0;int b= 1;int Add(int left,int right){return left+right;}struct Node{struct Node* next;int val;};
}1.作用域限定符指定命名空间名称
//指定访问
int main()
{//::作用域限定符printf("%d\n",yyy::a);return 0;
}2. using 引入命名空间中的成员 即 展开命名空间中某一个
//展开一个
using yyy::b;
int main()
{printf("%d\n",yyy::a);//不可以 因为此时只展开了一个成员变量printf("%d\n",b);
}3. usinng namespace 命名空间名称 展开命名空间
展开命名空间 影响的是 域的搜索规则。不展开命名空间,默认情况编译器只会在局部域、全局域搜索。展开命名空间就可以在命名空间里搜索。
//展开全部
using namespace yyy;
int main()
{printf("%d\n",yyy::a);//指定去该命名空间找变量aprintf("%d\n",b)
}注意:
1. 日常练习展开为了方便使用可以展开std,实际工程实践中慎重使用!
2.展开命名空间 不是 等同于引入全局变量!
3.展开命名空间 跟 包含头文件 也有本质区别,包含头文件 在预处理过程中本质是拷贝头文件的内容
三、C++输入、输出
解释Hello world代码
//包含标准输入输出流库
#include<iostream>
// std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
using namespace std;int main(){//cout和cin是全局的流对象,细说分别是ostream和istream类型的对象// <<是流插入运算符,>>是流提取运算符//endl是C++符号,表示endline换行//他们都包含在包含<iostream>头文件中cout<<"Hello world!!!"<<endl;return 0;}说明:使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件 以及按命名空间使用方法使用std。
补充:std命名空间的使用习惯
1.日常练习:直接展开 using namespace std
2.项目开发:std::cout 使用时指定命名空间 + using std::cout 展开常用库对象
C++ 输入输出 自动识别变量类型
-
示例代码:
#include <iostream> using namespace std; int main() {int a;double b;char c;// 可以自动识别变量的类型cin>>a;cin>>b>>c;cout<<a<<endl;cout<<b<<" "<<c<<endl;return 0; }-
说明
-
cin>>a;这行代码从标准输入流(键盘)中接受一个整数,并将其存储在变量a中。cin会根据提供的变量类型自动解释输入数据。cin>>b>>c;这行代码首先从标准输入流中接收一个双精度浮点数,并将其存储在变量b中,然后接收一个字符并存储在c中。
四、缺省参数
-
概念
声明或定义函数时为函数的参数指定缺省值。缺省值就是给形参设置一个默认值。调用函数时,如果没有指定实参,则使用参数的默认值。
缺省值必须是 常量或者全局变量。一般使用常量。
void Func(int a = 0) {cout<<a<<endl; } int main() {Func(); //没有传参 使用参数默认值 Func(10); //传参时 使用指定的实参return 0; } -
全缺省参数
void Func(int a = 10, int b = 20, int c = 30) {cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl; } 调用Func()时,可以这样给参数int main() {Func(1,2,3);Func(1,2);Func(1);Func();//注意:不可以跳越传值//Func(,1,2);return 0; } -
半缺省参数
注意:只能从右往左连续给缺省值,这样调用保证传的实参顺序不存在歧义
void Func(int a, int b = 20, int c = 30) {cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl; } //调用 同样不能跳越给 int main() {Func(1,2,3);Func(1,2);Func(1); }
实践中的应用场景🌰举个例子:
struct Stack
{int* a;int size;int capacity;//...
};
//StackInit()改造为半缺省函数 使得可以适用更多的需要开辟空间的场景
void StackInit(struct Stack* ps,int n=4)
{ps->a=(int*)malloc(sizeof(int)*n);
}
int main()
{struct Stack st1;//缺省参数 使得函数可以适应不同场景 // 1、确定要插入100个数据StackInit(&st1, 100); // call StackInit(?)
// 2、只插入10个数据struct Stack st2;StackInit(&st2, 10); // call StackInit(?)
// 3、不知道要插入多少个 //这时就可以使用函数定义里提供的 参数缺省值 //不知道插入多少个 可以先初始化四个空间struct Stack st3;StackInit(&st3);
return 0;
}-
声明和定义分离
回顾 声明 和定义的概念
-
函数声明:告诉编译器函数的名称、返回类型以及参数列表(类型、顺序和数量),但不涉及函数的具体实现。函数声明经常出现在头文件(
.h)中 -
函数定义:提供了函数的实际实现,它包括函数的主体,即函数被调用时将执行的具体代码。函数定义包含了函数声明的所有信息,并加上了函数体
//Stack.h 声明 struct Stack {int* a;int size;int capacity;//... }; void StackInit(struct Stack* ps,int n=4);//*注意 必须在声明中给出缺省值 void StackPush(struct Stack* ps,int x); //Stack.cpp 定义 void StackInit(struct Stack* ps,int n)//*注意声明和定义中缺省值不能同时给 {ps->a=(int*)malloc(sizeof(int)*n); } void StackPush(struct Stack* ps , int x) {} //Test.cpp #include"Stack.h" int main() {struct Stack st1;// 1、确定要插入100个数据StackInit(&st1, 100); // call StackInit(?)//此时包含了头文件,Test.cpp只有函数声明 用这个函数的名字找到该函数的地址 编译阶段会检查调用该函数是否存在匹配的函数,经过检查 匹配// 2、只插入10个数据struct Stack st2;StackInit(&st2, 10); // call StackInit(?)// 3、不知道要插入多少个 struct Stack st3;StackInit(&st3);return 0; }但是试想一下,1️⃣如果缺省值只在函数定义中给出,编译阶段 无法用这个函数的名字找到该函数的匹配 ,因为调用传参跟函数声明并不匹配。另一种情况,2️⃣如果在函数的声明和定义中都指定了缺省参数编译器也可能不确定应该使用哪个版本的默认值为了避免这种情况,C++标准规定了缺省参数应当只在一个地方指定:
-
如果函数声明在头文件中进行,那么就在头文件中的声明处指定缺省参数;
-
如果函数没有在头文件中声明(例如,完全在一个
.cpp文件内定义),那么就在函数定义处指定缺省参数
综上,
1️⃣在项目中,声明和定义应当分离,缺省值一定要在函数声明中给出!因为,编译阶段只有函数声明,从而保证编译阶段是没有问题的。
2️⃣声明和定义分离,导致编译阶段无法找到函数的定义,没有函数的地址。
-
-
再来分析上述程序
-
理解编译与链接的过程
1️⃣预处理阶段 :展开头文件、宏替换、条件编译、删除注释
对于每个
.c文件,编译过程从预处理开始。预处理器会处理以#开头的指令,例如#include "stack.h"会将stack.h中的内容文本上粘贴到stack.c和test.c文件中,这样stack.c和test.c就可以看到这些函数声明了2️⃣编译:检查语法➡️生成汇编代码
编译器接着编译每个.c源文件,将它们转换成目标代码(通常是机器代码的一种中间形态,称为目标文件,扩展名为.o或.obj)。此时,编译器确保源代码符合语法规则,对每个源文件进行类型检查,确保所有函数调用都符合其声明,但还不解决跨文件的函数引用问题。例如,stack.c被编译成stack.o,test.c被编译成test.o
3️⃣汇编:汇编代码➡️二进制机器码
4️⃣链接:合并、有些地方要用函数名去其他文件找函数地址
一旦所有的源文件被编译成目标文件,链接器(linker)负责将这些目标文件以及必要的库文件链接成一个单一的可执行文件。在链接过程中,如果test.c(对应的是test.o)调用了stack.c中(对应的是stack.o)的函数,链接器负责“修补”这些调用,使得test.o中的调用可以正确地连接到stack.o中定义的函数上,链接器确保所有外部引用都能正确解析到它们所引用的实体。
-
理解函数与文件的关系
-
在stack.h中声明的函数,让其他源文件知道这些函数的存在、它们的参数以及返回值类型。stack.h扮演了接口的角色。
-
stack.c提供了stack.h中声明的函数的具体实现。test.c作为使用这些函数的客户端代码,通过#include "stack.h"能够调用这些函数。
-
编译过程中,test.c和stack.c分别被编译成中间的目标文件。这些目标文件中的函数调用尚未解析到具体的地址
-
在链接过程,链接器解析这些调用,使得从test.o中的调用可以正确地定位到stack.o中的函数定义,从而生成一个完整的可执行文件,所有的函数调用都被正确地解析和连接,这个地址修正的过程也叫做重定位
-
-

五、函数重载
C语言不允许同名函数
C++允许同名函数。要求:函数名相同,参数不同,构成 函数重载
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似但数据类型不同的问题。
代码示例:
#include<iostream>using namespace std;// 1、参数类型不同
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}
double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}// 2、参数个数不同
void f()
{cout << "f()" << endl;
}
void f(int a)
{cout << "f(int a)" << endl;
}// 3、参数类型顺序不同
void f(int a, char b)
{cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{cout << "f(char b, int a)" << endl;
}
int main()
{Add(10, 20);Add(10.1, 20.2);f();f(10);f(10, 'a');f('a', 10);return 0;
}C语言不支持重载 链接时,直接用函数名去找地址,有同名函数的情况则区分不开。
-
C++是如何支持函数重载的?
通过函数名修饰实现的,只要函数参数不同,函数名就会被修饰成不同。然后直接用修饰好的名字,去找该函数的地址。
-
函数名修饰
名字修饰是编译器自动进行的一种处理过程,它将C++源代码中的函数名和变量名转换成包含更多信息的唯一标识符。这些信息通常包括函数的参数类型、参数数量等,甚至可能包括所属的类名(对于类成员函数),通过这种方式,每个重载的函数都会被赋予一个独一无二的名字,确保链接器在最后链接程序的时候能够区分它们
-
Linux下g++的修饰规则简单易懂,下面我们使 用了g++演示了这个修饰后的名字。 通过下面我们可以看出gcc的函数修饰后名字不变。而g++的函数修饰后变成【_Z+函数长度 +函数名+类型首字母】。
-
采用C语言编译器编译后结果

结论:在linux下,采用gcc编译完成后,函数名字的修饰没有发生改变。
-
采用C++编译器编译后结果
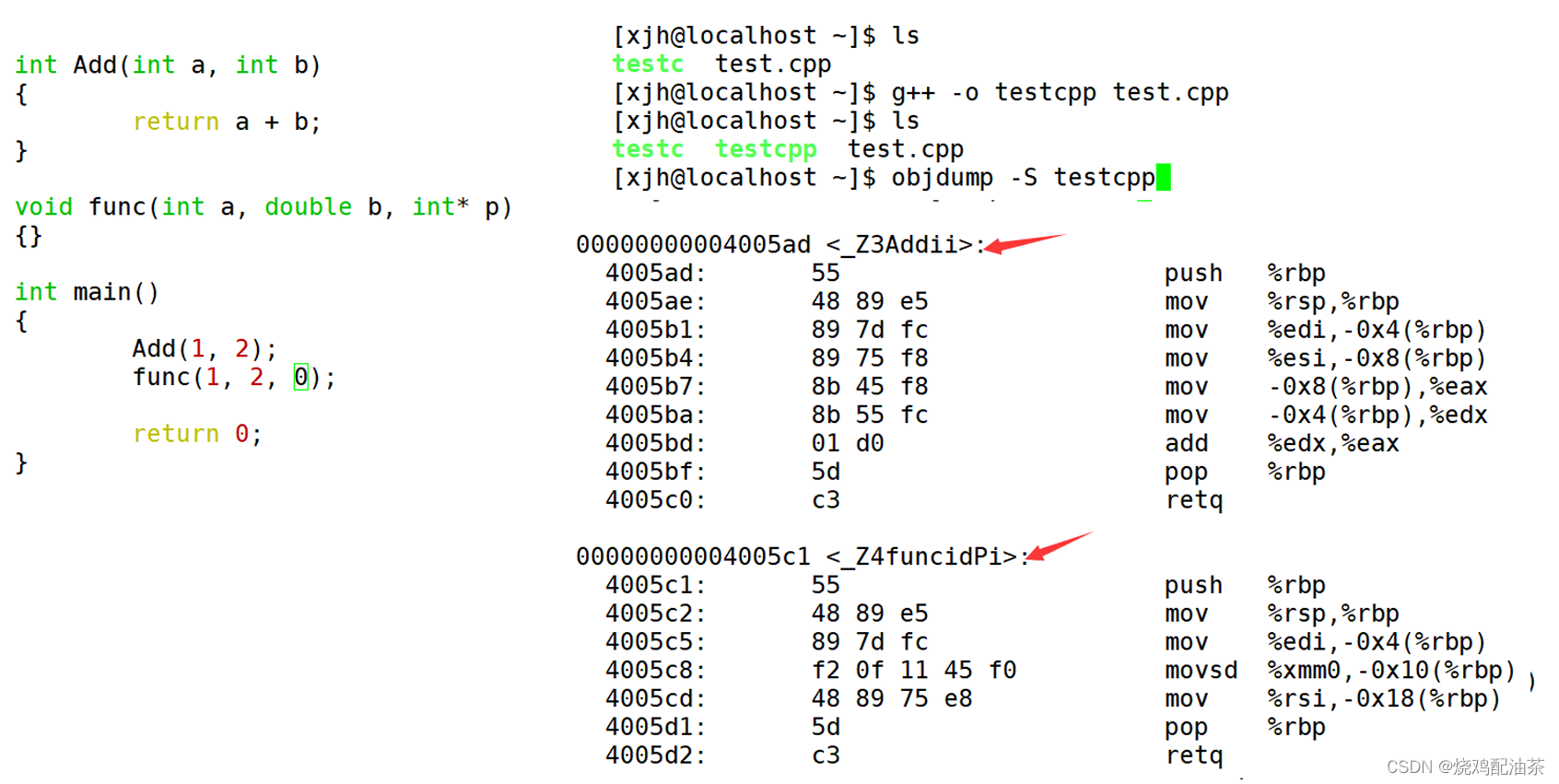
结论:在linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改后的名字中。
通过以上这里就理解了C语言没办法支持重载,因为同名函数没办法区分。而C++是通过函数修 饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载。
相关文章:
【C++】入门(一):命名空间、缺省参数、函数重载
目录 一、关键字 二、命名空间 问题引入(问题代码): 域的问题 1.::域作用限定符 的 用法: 2.域的分类 3.编译器的搜索原则 命名空间的定义 命名空间的使用 举个🌰栗子: 1.作用域限定符指定命名空间名称 2. using 引入…...

深入分析 Android Activity (四)
文章目录 深入分析 Android Activity (四)1. Activity 的生命周期详解1.1 onCreate1.2 onStart1.3 onResume1.4 onPause1.5 onStop1.6 onDestroy1.7 onRestart 2. Activity 状态的保存与恢复2.1 保存状态2.2 恢复状态 3. Activity 的启动优化3.1 延迟初始化3.2 使用 ViewStub3.…...
Java实现顺序表
Java顺序表 前言一、线性表介绍常见线性表总结图解 二、顺序表概念顺序表的分类顺序表的实现throw具体代码 三、顺序表会出现的问题 前言 推荐一个网站给想要了解或者学习人工智能知识的读者,这个网站里内容讲解通俗易懂且风趣幽默,对我帮助很大。我想与…...

刷题笔记1:如何科学的限制数字溢出问题
LCR 192. 把字符串转换成整数 (atoi) - 力扣(LeetCode) 我们以力扣的此题目为例,简述在诸如大数运算等问题中如何限制数字溢出问题。 先来直接看看自己的处理方式: class Solution { public:int myAtoi(string str) {int pcur0;…...

社区供稿丨GPT-4o 对实时互动与 RTC 的影响
以下文章来源于共识粉碎机 ,作者AI芋圆子 前面的话: GPT-4o 发布当周,我们的社区伙伴「共识粉碎机」就主办了一场主题为「GPT-4o 对实时互动与 RTC 的影响」讨论会。涉及的话题包括: GPT-4o 如何降低延迟(VAD 模块可…...
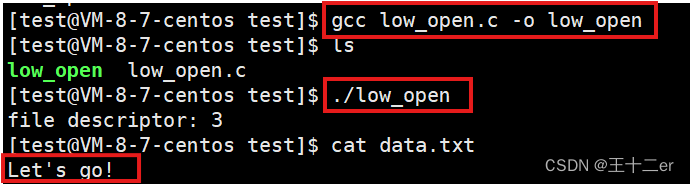
基于Linux的文件操作(socket操作)
基于Linux的文件操作(socket操作) 1. 文件描述符基本概念文件描述符的定义:标准文件描述符:文件描述符的分配: 2. 文件描述符操作打开文件读取文件中的数据 在linux中,socket也被认为是文件的一种ÿ…...
)
C++面试题记录(网络)
TCP与UDP区别 1. TCP面向连接,UDP无连接,所以UDP数据传输效率更高 2.UDP可以支持一对一、一对多、多对一、多对多通信,TCP只能一对一 3. TCP需要在端系统维护连接状态,包括缓存,序号,确认号,…...

YoloV8改进策略:卷积篇|基于PConv的二次创新|附结构图|性能和精度得到大幅度提高(独家原创)
摘要 在PConv的基础上做了二次创新,创新后的模型不仅在精度和速度上有了质的提升,还可以支持Stride为2的降采样。 改进方法简单高效,需要发论文的同学不要错过! 论文指导 PConv在论文中的描述 论文: 下面我们展示了可以通过利用特征图的冗余来进一步优化成本。如图3所…...

图论(从数据结构的三要素出发)
文章目录 逻辑结构物理结构邻接矩阵定义性能分析性质存在的问题 邻接表定义性能分析存在的问题 十字链表(有向图)定义性能分析 邻接多重表(无向图)定义性能分析 数据的操作图的基本操作图的遍历广度优先遍历(BFS)算法思想和实现性能分析深度优先最小生成…...

spark相关知识
1.Spark的特点 Spark的设计遵循“一个软件栈满足不同应用场景”的理念,逐渐形成了一套完整的生态系统,既能够提供内存计算框架,也可以支持SQL即席查询、实时流式计算、机器学习和图计算等。 运行速度快,易使用,强大的技…...

K8S认证|CKA题库+答案| 12. 查看Pod日志
目录 12、查看Pod日志 CKA v1.29.0模拟系统 下载试用 题目: 开始操作: 1)、切换集群 2)、提取错误日志 3)、验证提取结果 12、查看Pod日志 CKA v1.29.0模拟系统 下载试用 题目: 您必须在以下C…...
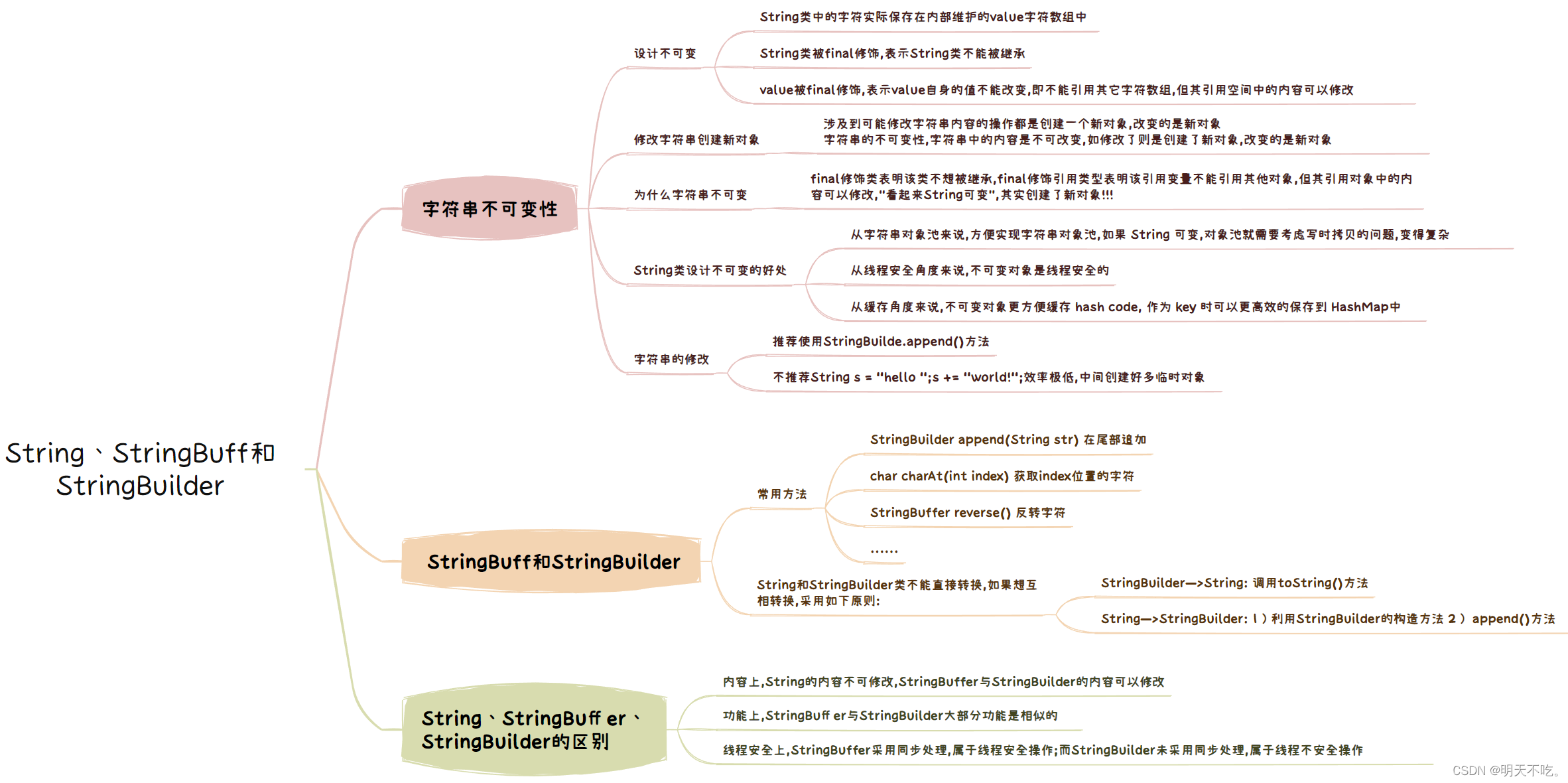
【Java SE】 String、StringBuff和StringBuilder
🥰🥰🥰来都来了,不妨点个关注叭! 👉博客主页:欢迎各位大佬!👈 文章目录 1. 字符串不可变性1.1 设计不可变1.2 修改字符串创建新对象1.3 为什么字符串不可变1.4 String类设计不可变的…...

产品经理-需求分析(三)
1. 需求分析 从业务的需要出发,确定业务目的和目标,将业务需求转为产品需求 1.1 业务需求 业务需求 业务动机 业务目标 就是最根本的动机和目标成果,通过这个需求解决特定的问题 1.2 产品需求 产品需求 解决方案 产品结构 产品流程…...
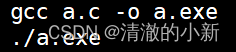
Linux 编译器gcc/g++使用
gcc/g同理 编译器运行过程 1. 预处理(进行宏替换) gcc -E a.c -o a.i 预处理后还是c语言 -E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面 告诉gcc,从现在开始进行程序的翻译,将预处理工作做完停下 2. 编译&#x…...
)
adam优化器计算过程(tensorflow)
一、adam原理 原理 应用 优点 缺点 二、手动实现 一步一步计算 三、使用tensorflow api实现 api使用 四、一个具体的深度学习的例子...

【数据结构与算法 | 链表篇】力扣876
1. 力扣876 : 链表的中间节点 (1). 题 给你单链表的头结点 head ,请你找出并返回链表的中间结点。 如果有两个中间结点,则返回第二个中间结点。 示例 1: 输入:head [1,2,3,4,5] 输出:[3,4,5] 解释:链表…...

kubeadm引导欧拉系统高可用的K8S1.28.X
文章目录 一. 核心组件架构二. 有状态与无状态应用三. 资源对象3.1 规约与状态3.2 资源的分类-元数据,集群,命名空间3.2.1 元数据3.2.2 集群资源 3.3 命名空间级3.3.1 pod3.3.2 pod-副本集3.3.3 pod-控制器 四. Kubeadm安装k8s集群4.1 初始操作4.2 ~~所有节点安装Docker&#x…...

【信息学奥赛】字典的键和值对换
【信息学奥赛】字典的键和值对换 💖The Begin💖点点关注,收藏不迷路💖 输入一个字典,要求将该字典的键和值对换。(注意,字典中有键的值是重复的) 输入: 一行࿰…...

使用Django框架搭建Web应用
文章目录 简介安装Django创建一个Django项目创建一个Django应用编写视图配置URL运行开发服务器总结与拓展数据库集成管理后台表单处理模板引擎安全性 简介 Django 是一款基于 Python 语言的开源 Web 应用框架,采用了 MVC(模型-视图-控制器)设…...

我用Mybatis的方式封装了OLAP查询!
背景 相信做数据平台的朋友对OLAP并不陌生,主流的OLAP引擎有Clickhouse,Impala,Starrocks…以及公司二开的OLAP平台,本次要说的OLAP属于最后一种。 最近在做一个BI项目,业务背景很简单,就是一个数据展示平…...

基于Adafruit IO与振动传感器的智能洗衣机提醒器DIY教程
1. 项目概述:告别遗忘,让洗衣机“开口说话”你有没有过这样的经历?把衣服塞进洗衣机,按下启动键,然后转头就去忙别的事情,等再想起来时,已经是好几个小时甚至第二天,湿漉漉的衣服在滚…...

Coding爆发打破「AI泡沫论」,MiniMax能否卡位下一个Google?
【Coding爆发打破「AI泡沫论」】 Coding的爆发,彻底断绝了「AI泡沫论」,这已成为共识。阿里财报显示MaaS ARR超过80亿元,年底还有望再涨三倍以上,意味着只有投入没有回报的周期已过去,能开始盈利,大小玩家都…...
)
保姆级教程:用PyTorch在MuJoCo的Ant-v2环境跑通PPO算法(附完整代码)
从零实现PPO算法:MuJoCo Ant-v2环境实战指南 在强化学习领域,让一个虚拟蚂蚁学会行走是经典的基准测试任务。本文将带你用PyTorch框架,在MuJoCo的Ant-v2环境中完整实现PPO算法。不同于理论讲解,我们聚焦于可运行的代码实现和实际…...

星露谷物语SMAPI模组加载器:5分钟快速上手指南与完整使用教程
星露谷物语SMAPI模组加载器:5分钟快速上手指南与完整使用教程 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 你是否曾经因为星露谷物语模组安装复杂、冲突不断而感到困扰?今…...

CherryUSB嵌入式USB协议栈终极指南:从入门到精通
CherryUSB嵌入式USB协议栈终极指南:从入门到精通 【免费下载链接】CherryUSB CherryUSB is a tiny and beautiful, high performance and portable USB host and device stack for embedded system with USB IP 项目地址: https://gitcode.com/gh_mirrors/ch/Cher…...

ChatGPT-PerfectUI:开源前端界面部署与核心功能解析
1. 项目概述:一个为ChatGPT打造的“完美”前端界面如果你和我一样,是ChatGPT的重度用户,每天都要和它进行大量的对话,那么你肯定对官方那个略显简陋的Web界面有过一些“怨念”。功能切换不够直观、对话管理略显笨拙、界面风格万年…...
)
别再手动绕田了!用Python+Google Earth Pro搞定农田边界KML文件(附完整代码)
零成本农田边界数字化:Python与Google Earth Pro实战指南 在农业自动化领域,获取精确的农田边界数据是路径规划的第一步。传统方法依赖RTK设备或无人机测绘,成本高昂且操作复杂。本文将介绍一种无需专业硬件的解决方案,仅需一台普…...
)
ArcGIS实战:手把手教你拼接与裁剪全国10米建筑高度栅格数据(以武汉为例)
ArcGIS实战:全国10米建筑高度栅格数据的精准处理与武汉应用 引言:高精度建筑数据的价值与挑战 城市规划师李明最近在武汉某旧城改造项目中遇到了棘手问题——传统30米分辨率的建筑高度数据无法准确反映老城区复杂的建筑形态差异。当他尝试获取更高精度的…...

手把手教你用MPU6050和nRF52832做手环计步:避开数据读取卡死的坑
手把手教你用MPU6050和nRF52832实现稳定计步:从硬件调试到算法优化全攻略 在可穿戴设备开发中,计步功能看似基础却暗藏玄机。许多开发者在使用MPU6050加速度传感器搭配nRF52832主控时,都会遇到一个令人头疼的问题——系统运行一段时间后莫名卡…...

5分钟快速上手:用Tinke免费工具轻松解包修改NDS游戏资源
5分钟快速上手:用Tinke免费工具轻松解包修改NDS游戏资源 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 你是否曾经想过深入探索任天堂DS游戏的神秘世界?想要提取那些精美…...