【机器学习】洞悉数据奥秘:决策树算法在机器学习中的魅力
在机器学习的分类和回归问题中,决策树是一种广泛使用的算法。决策树模型因其直观性、易于理解和实现,以及处理分类和数值特征的能力而备受欢迎。本文将解释决策树算法的概念、原理、应用、优化方法以及未来的发展方向。
🚀时空传送门
- 🔍什么是决策树算法
- 📕决策树算法原理
- 🌹决策树算法参数
- 🚆决策树算法的应用及代码示例
- 💖决策树算法的优化
- 🍀决策树算法的未来发展
🔍什么是决策树算法
决策树算法是一种监督学习算法,用于分类和回归问题。它采用树状结构表示决策过程,其中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶节点代表一个类别(分类问题)或值(回归问题)。决策树的主要优点是直观易懂、易于解释,并且不需要对数据进行复杂的预处理。
📕决策树算法原理

决策树算法通过递归地选择最优特征进行划分数据集,并生成相应的决策规则。常见的决策树算法有ID3、C4.5和CART等。这里以CART(分类与回归树)算法为例进行解释。
CART算法的核心是“基尼不纯度”(Gini Impurity)或“平方误差”(Squared Error)作为划分标准。对于分类问题,CART选择基尼不纯度最小的特征进行划分;对于回归问题,则选择平方误差最小的特征进行划分。
算法流程大致如下:
- 从根节点开始,选择最优特征进行划分。
- 对该特征的每个可能取值,将数据集划分为若干个子集,并创建相应的子节点。
- 对每个子节点递归地执行步骤1和2,直到满足停止条件(如子节点包含的样本数过少、所有样本属于同一类别等)。
- 生成决策树。
🌹决策树算法参数

在实际应用中,我们可能需要调整一些参数来优化模型的性能。以下是一些常用的参数:
- criterion: 划分准则,可以是’gini’(基尼指数)或’entropy’(信息增益)。
- max_depth: 决策树的最大深度。
- min_samples_split: 划分内部节点所需的最小样本数。
- min_samples_leaf: 叶节点所需的最小样本数。
- max_features: 考虑用于划分节点的最大特征数。
- random_state: 随机数生成器的种子,用于控制特征的随机选择。
通过调整这些参数,我们可以控制决策树的复杂性和泛化能力,从而优化模型的性能。
🚆决策树算法的应用及代码示例

🚗医疗诊断中的应用
在医疗诊断中,决策树算法可以用于辅助医生根据患者的症状和体征进行疾病的分类和预测。例如,医生可以使用包含患者年龄、性别、病史、症状等特征的数据集来训练一个决策树模型,然后使用该模型对新患者的疾病进行分类预测。
以鸢尾花数据集(Iris dataset)为例,使用scikit-learn库中的决策树分类器:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score # 加载数据
iris = load_iris()
X = iris.data
y = iris.target # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 创建决策树分类器
clf = DecisionTreeClassifier() # 训练模型
clf.fit(X_train, y_train) # 预测测试集
y_pred = clf.predict(X_test) # 计算准确率
print("Accuracy:", accuracy_score(y_test, y_pred))
🚲回归问题
以波士顿房价数据集(Boston Housing dataset)为例,使用scikit-learn库中的决策树回归器:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error # 加载数据
boston = load_boston()
X = boston.data
y = boston.target # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 创建决策树回归器
reg = DecisionTreeRegressor() # 训练模型
reg.fit(X_train, y_train) # 预测测试集
y_pred = reg.predict(X_test) # 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
💴金融风险评估中的应用

在金融风险评估中,决策树算法可以帮助银行、保险公司等金融机构根据客户的信用历史、收入、负债等信息评估其信用风险等级。通过构建决策树模型,金融机构可以更加准确地预测客户的违约概率,从而制定更加合理的贷款政策或保险费率。
示例代码(使用scikit-learn库)
假设我们有一个包含客户信用信息和信用风险等级的数据集financial_risk_data.csv,其中包含了客户的年龄、收入、负债、信用历史等特征以及信用风险等级标签。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report # 加载数据
data = pd.read_csv('financial_risk_data.csv')
X = data.drop('RiskLevel', axis=1) # 特征
y = data['RiskLevel'] # 标签 # 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 创建决策树分类器
clf = DecisionTreeClassifier(random_state=42) # 训练模型
clf.fit(X_train, y_train) # 预测测试集
y_pred = clf.predict(X_test) # 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}") # 计算分类报告
report = classification_report(y_test, y_pred)
print(f"Classification Report:\n{report}") # 导出模型以便使用
# 例如,可以将模型保存为PMML或pickle文件
# import pickle
# with open('financial_risk_model.pkl', 'wb') as f:
# pickle.dump(clf, f)
💖决策树算法的优化
虽然决策树算法简单有效,但仍然存在一些局限性,如过拟合、对噪声数据敏感等。为了克服这些问题,可以采取以下优化方法:
- 预剪枝(Pre-pruning):在决策树生成过程中,提前停止树的生长,防止过拟合。
- 后剪枝(Post-pruning):先生成完整的决策树,然后自底向上进行剪枝,去除不必要的子树。
- 特征选择:使用更合适的特征选择方法,如基于信息增益、增益比或基尼指数等进行特征选择。
- 集成方法:如随机森林(Random Forests)和梯度提升决策树(Gradient Boosting Decision Trees),通过集成多个决策树来提高模型的性能。
🍀决策树算法的未来发展

随着数据量的不断增长和计算能力的提升,决策树算法将继续发展并在更多领域得到应用。未来的研究方向可能包括:
- 与深度学习结合:将决策树与深度学习技术相结合,构建更加复杂和强大的模型。
- 可解释性增强:在保持模型性能的同时,提高模型的可解释性,使其更加适用于需要高解释性的领域。
- 处理大规模数据:优化算法以适应大规模数据集的训练和推理,提高计算效率。
总之,决策树算法作为一种简单而有效的机器学习算法,将在未来的发展中继续发挥重要作用。
相关文章:
【机器学习】洞悉数据奥秘:决策树算法在机器学习中的魅力
在机器学习的分类和回归问题中,决策树是一种广泛使用的算法。决策树模型因其直观性、易于理解和实现,以及处理分类和数值特征的能力而备受欢迎。本文将解释决策树算法的概念、原理、应用、优化方法以及未来的发展方向。 🚀时空传送门 &#x…...
redis(17):什么是布隆过滤器?如何实现布隆过滤器?
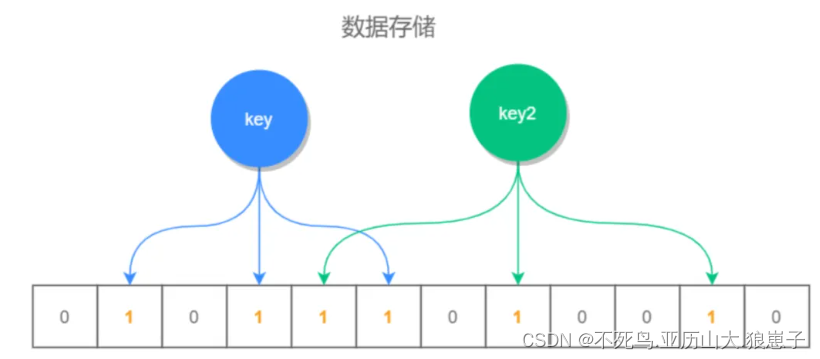
1 布隆过滤器介绍 布隆过滤器(Bloom Filter)是一种空间效率极高的概率型数据结构,用于判断一个元素是否在一个集合中。它基于位数组和多个哈希函数的原理,可以高效地进行元素的查询,而且占用的空间相对较小,如下图所示: 根据 key 值计算出它的存储位置,然后将此位置标…...
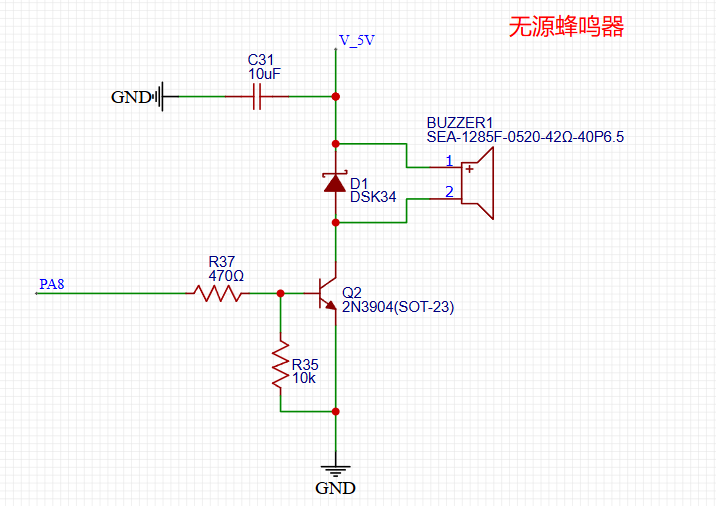
STM32自己从零开始实操03:输出部分原理图
一、继电器电路 1.1指路 延续使用 JZC-33F-012-ZS3 继电器,设计出以小电流撬动大电流的继电器电路。 (提示)电路需要包含:三极管开关电路、续流二极管、滤波电容、指示灯、输出部分。 1.2数据手册重要信息提炼 联系排列&…...

Unity中将图片做成Prefab的步骤
Unity中将图片做成Prefab的步骤 在Unity中,将一张图片做成Prefab是一个常见的操作。Prefab是Unity中的一种资源类型,可以让你预先定义一个游戏对象,然后在场景中多次实例化它。以下是详细的步骤: 步骤一:准备图片资源…...

Web前端三大主流框架:React、Vue和Angular
在当前的Web开发领域,前端框架的选择对于项目的成功至关重要。作为一名资深的IT技术员,我对前端技术的发展和行业趋势保持着持续的关注。本文将介绍当前Web前端三大主流框架:React、Vue和Angular,并分析它们各自的优势。 React&a…...
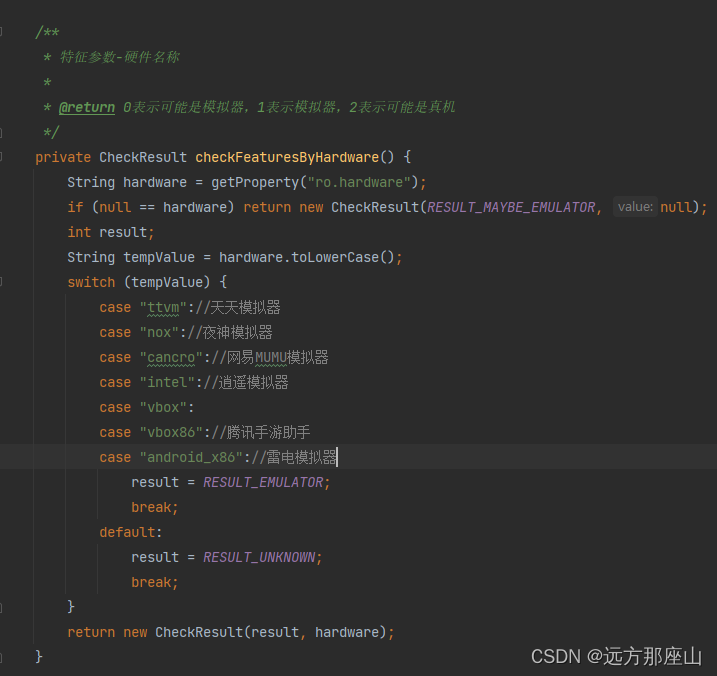
安全风险 - 检测设备是否为模拟器
在很多安全机构的检测中,关于模拟器的运行环境一般也会做监听处理,有的可能允许执行但是会提示用户,有的可能直接禁止在模拟器上运行我方APP 如何判断当前 app 是运行在Android真机,还是运行在模拟器? 可能做 Framework 的朋友思…...
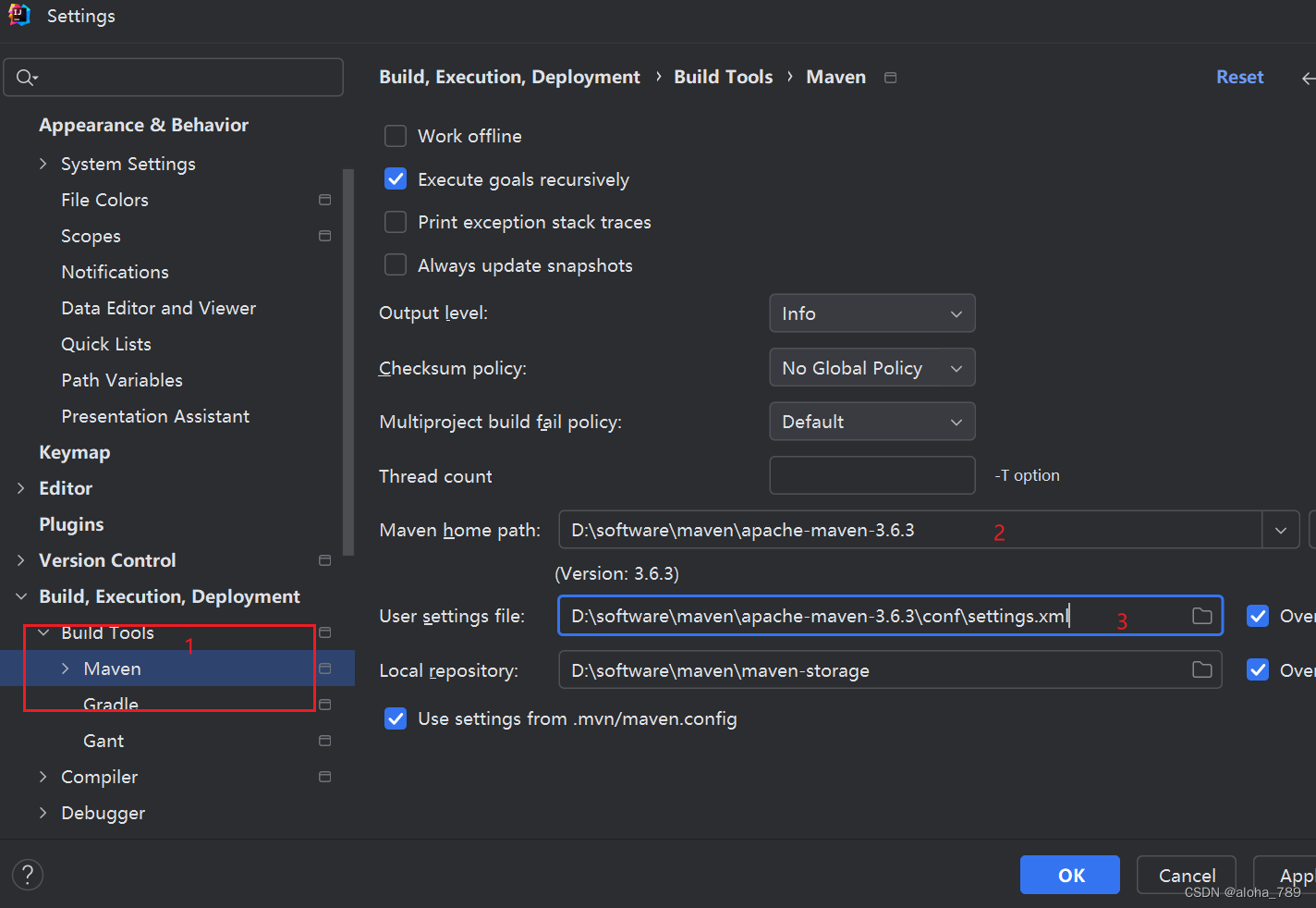
maven的下载以及配置的详细教程(附网盘下载地址)
文章目录 下载配置IDEA内部使用配置 下载 1.百度网盘下载 链接: https://pan.baidu.com/s/1LD9wOMFalLL49XUscU4qnQ?pwd1234 提取码: 1234 2.解压即可 配置 1.打开安装文件下conf下的settings.xml文件,我的如下 2.修改配置信息(目的是为了修改本地…...

Unity3D 主城角色动画控制与消息触发详解
前言 在游戏开发中,角色动画控制和消息触发是非常重要的一部分,它可以让游戏更加生动和互动。本文将详细介绍如何在Unity3D中实现主城角色动画控制与消息触发。 对惹,这里有一个游戏开发交流小组,大家可以点击进来一起交流一下开…...

【Endnote】如何在word界面加载Endnote
如何在word界面加载Endnote 方法1:方法2:从word入手方法3:从CWYW入手参考 已下载EndNote,但Word中没有显示EndNote,应如何加载显示呢? 方法1: 使用EndNote的Configure EndNote.exe 。 具体步骤为&#x…...
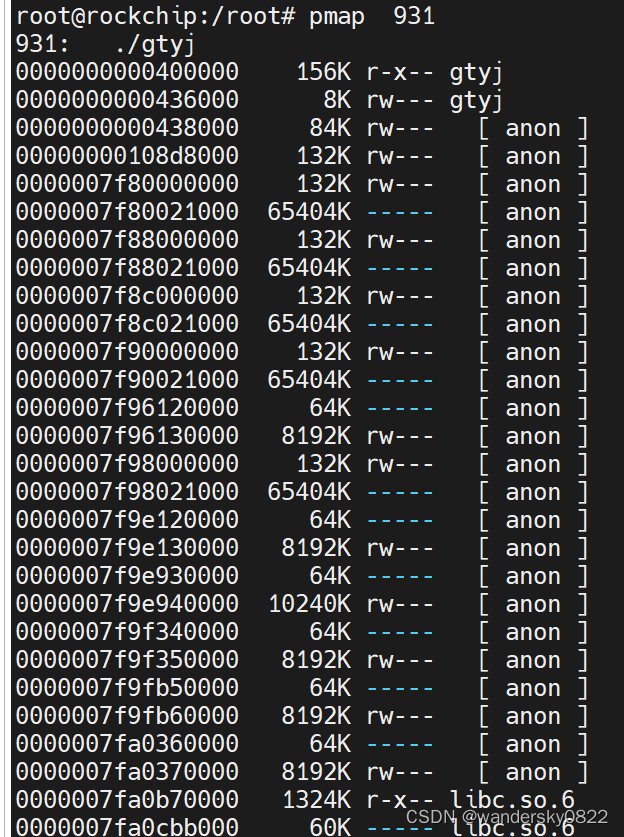
优化CPU占用率及内存占用2
在标准化无线通信板时,关注过程序占用ram的问题,当时 发现每一个线程都会分配8M栈空间,这次换rk3568后,偶尔看了下RAM占用,吓了一跳,不但每个线程有8M栈空间,几乎每个线程都占用了64MB的一个RAM…...
C语言(字符和字符串函数)2
Hi~!这里是奋斗的小羊,很荣幸各位能阅读我的文章,诚请评论指点,欢迎欢迎~~ 💥个人主页:小羊在奋斗 💥所属专栏:C语言 本系列文章为个人学习笔记,在这里撰写成文一…...

【数据结构与算法 | 栈篇】力扣20,150
1. 力扣20 : 有效的符号 (1). 题 给定一个只包括 (,),{,},[,] 的字符串 s ,判断字符串是否有效。 有效字符串需满足: 左括号必须用相同类型的右括号闭合。左括号必须以正确的顺序闭合。每个…...

node依赖安装的bug汇总
1.npm仓库 首先要获取npm仓库的地址: registryhttp://11.11.111.1:1111/abcdefg/adsfadsf 类似这种的地址 然后设置npm仓库: npm config set registryhttp://11.11.111.1:1111/abcdefg/adsfadsf (地址要带等号) 接着安装依赖: npm i…...
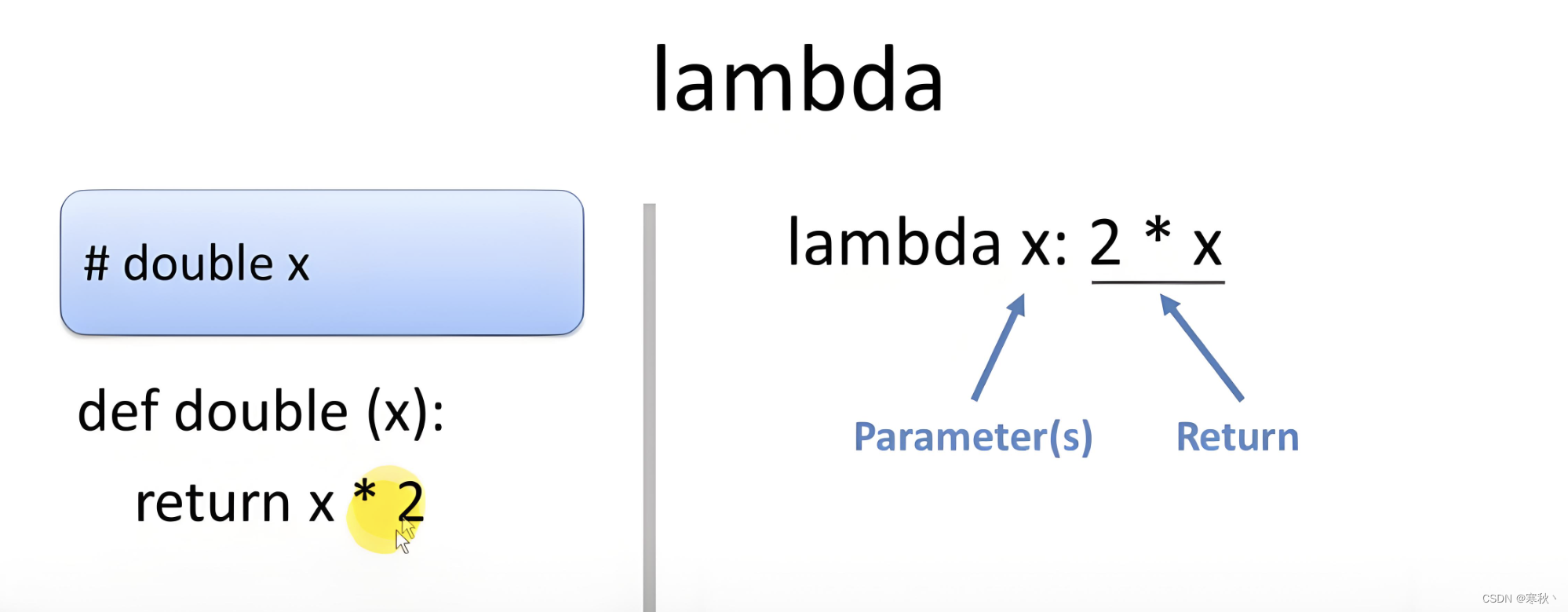
Python中的 Lambda 函数
大家好,在 Python 编程的世界里,有一种功能强大却不常被提及的工具,它就是 Lambda 函数。这种匿名函数在 Python 中拥有着令人惊叹的灵活性和简洁性,却常常被许多开发者忽视或者只是将其当作一种附加功能。Lambda 函数的引入&…...

服务器遭遇黑洞后如何快速恢复与防范
在互联网世界中,“黑洞"一词常用于描述一种网络安全措施,即当服务器遭遇大规模DDoS攻击,为了保护网络基础设施和其他用户免受影响,网络服务商会暂时将受到攻击的IP地址流量导向一个"空洞”,使其不再响应任何…...

GPT-4o有点坑
GPT-4o有点坑 0. 前言1. GPT-4o简介2. GPT-4o带来的好处2.1 可以上传图片和文件2.2 更丰富的功能以及插件 3. "坑"的地方3.1 使用时间短3.2 GPT-4o变懒了 4. 总结 0. 前言 原本不想对GPT-4o的内容来进行评论的,但是看了相关的评论一直在说:技…...

【机器学习】探索未来科技的前沿:人工智能、机器学习与大模型
文章目录 引言一、人工智能:从概念到现实1.1 人工智能的定义1.2 人工智能的发展历史1.3 人工智能的分类1.4 人工智能的应用 二、机器学习:人工智能的核心技术2.1 机器学习的定义2.2 机器学习的分类2.3 机器学习的实现原理2.4 机器学习的应用2.5 机器学习…...
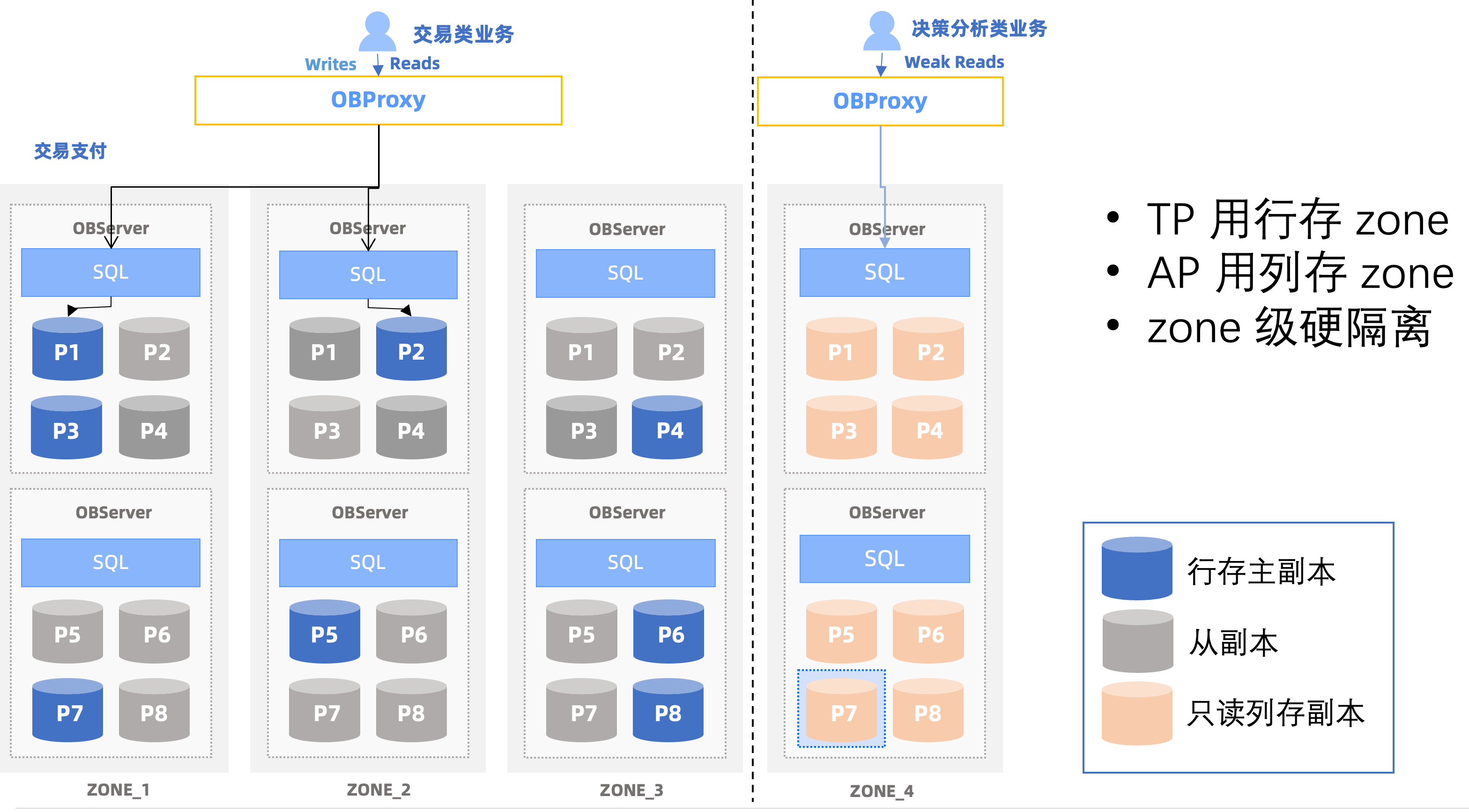
OceanBase 4.3.0 列存引擎解读:OLAP场景的入门券
近期,OceanBase 发布了4.3.0版本,该版本成功实现了行存与列存存储的一体化,并同时推出了基于列存的全新向量化引擎和代价评估模型。通过强化这些能力,OceanBase V4.3.0 显著提高了处理宽表的效率,增强了在AP࿰…...
算法每日一题(python,2024.05.25) day.7
题目来源(力扣. - 力扣(LeetCode),简单) 解题思路: 难点:加一时可能出现9使得位数进一,而当特殊情况,即全部为9时,数组所在长度会变长一。 从末尾开始判断&…...

【正在线上召开】2024机器智能与数字化应用国际会议(MIDA2024),免费参会
【ACM出版】2024机器智能与数字化应用国际会议(MIDA2024) 2024 International Conference on Machine Intelligence and Digital Applications 【支持单位】 宁波财经学院 法国上阿尔萨斯大学 【大会主席】 Ljiljana Trajkovic 加拿大西蒙菲莎大…...

ESP32-S2物联网实战:IPv6配置与Adafruit IO双向通信
1. 项目概述与核心价值如果你手头有一块ESP32-S2开发板,并且已经厌倦了仅仅让它连上Wi-Fi、点个灯,想让它真正“活”起来,成为一个能融入现代互联网、能与云端自由对话的智能节点,那么这篇文章就是为你准备的。我们将深入两个在物…...

ViGEmBus终极指南:Windows游戏控制器模拟驱动完全解析
ViGEmBus终极指南:Windows游戏控制器模拟驱动完全解析 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus ViGEmBus是一款运行在Windows内核模式的驱…...

智慧树自动刷课神器Autovisor:3分钟极速上手的完整指南
智慧树自动刷课神器Autovisor:3分钟极速上手的完整指南 【免费下载链接】Autovisor 2025智慧树刷课脚本 基于Python Playwright的自动化程序 [有免安装版] 项目地址: https://gitcode.com/gh_mirrors/au/Autovisor 还在为智慧树平台的繁琐操作而烦恼吗&#…...

Token工厂:从“卖流量”到“卖Token”:中国移动砸百亿建Token生态,三大运营商的AI战争升级,阿里,百度,华为,字节跟进
5月9日,2026移动云大会上,中国移动市场经营部总经理邱宝华扔出一个新概念——"Token运营体系"。未来3-5年,中国移动将投入百亿级Token生态资源,建设千亿级算力基础设施,携手共创万亿级AI产业价值。"百亿…...

3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南
3分钟上手RePKG:轻松提取Wallpaper Engine壁纸资源的终极指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经遇到过这样的困扰?在Wallpaper Engi…...

从零解析开源API网关fiGate:架构设计与生产实践
1. 项目概述:从零解析一个开源API网关最近在梳理团队内部微服务治理方案时,我又重新审视了市面上各类API网关的实现。除了大家耳熟能详的Kong、APISIX、Tyk这些“明星产品”,其实在GitHub的海洋里,还藏着不少设计精巧、思路独特的…...

RTX 5090功耗600W:高功耗显卡的系统级挑战与实战装机指南
1. 项目概述:从一则功耗新闻到显卡生态的深度解构最近,一则关于英伟达下一代旗舰显卡RTX 5090功耗可能高达600W的消息,在硬件圈和AI计算领域激起了不小的波澜。对于普通玩家而言,这或许只是一个“电老虎”又升级了的谈资ÿ…...

基于BLE信号强度的寻物游戏:用CircuitPython实现无线接近探测
1. 项目概述:一个用蓝牙信号“捉迷藏”的硬件游戏几年前我第一次接触Adafruit的Circuit Playground系列开发板时,就被它那种“开箱即玩”的理念吸引了。它把LED、按钮、传感器都集成在一块板子上,让你不用焊接就能快速验证想法。后来出的Circ…...

5分钟快速上手:PlantUML Editor - 告别拖拽,用代码绘制专业UML图表
5分钟快速上手:PlantUML Editor - 告别拖拽,用代码绘制专业UML图表 【免费下载链接】plantuml-editor PlantUML online demo client 项目地址: https://gitcode.com/gh_mirrors/pl/plantuml-editor 还在为绘制复杂的UML图表而烦恼吗?你…...

陕西省ICPC省赛总结
个人反思 我个人感觉还是练的少,学的不够系统。具体反应到题上,表现在看到题没有思路,并且也不知道这道题用到什么算法思想,导致拿的书和本子几乎用不上。其次是思考不够深入,我的队友都能进行深入的思考,但…...