elasticsearch7.15实现用户输入自动补全
Elasticsearch Completion Suggester(补全建议)
Elasticsearch7.15安装
官方文档
补全建议器提供了根据输入自动补全/搜索的功能。这是一个导航功能,引导用户在输入时找到相关结果,提高搜索精度。
理想情况下,自动补全功能应该和用户输入一样快,以便为用户提供与已输入内容相关的即时反馈。因此,completion建议器针对速度进行了优化。建议器使用的数据结构支持快速查找,但构建成本很高,并且存储在内存中。
拼音分词插件elasticsearch-analysis-pinyin安装
源码地址:https://gitcode.com/medcl/elasticsearch-analysis-pinyin/overview
-
idea通过git(https://gitcode.com/medcl/elasticsearch-analysis-pinyin.git)导入项目
-
切换到分支7.x
-
修改pom.xml,elasticsearch.version 版本号为7.15.0
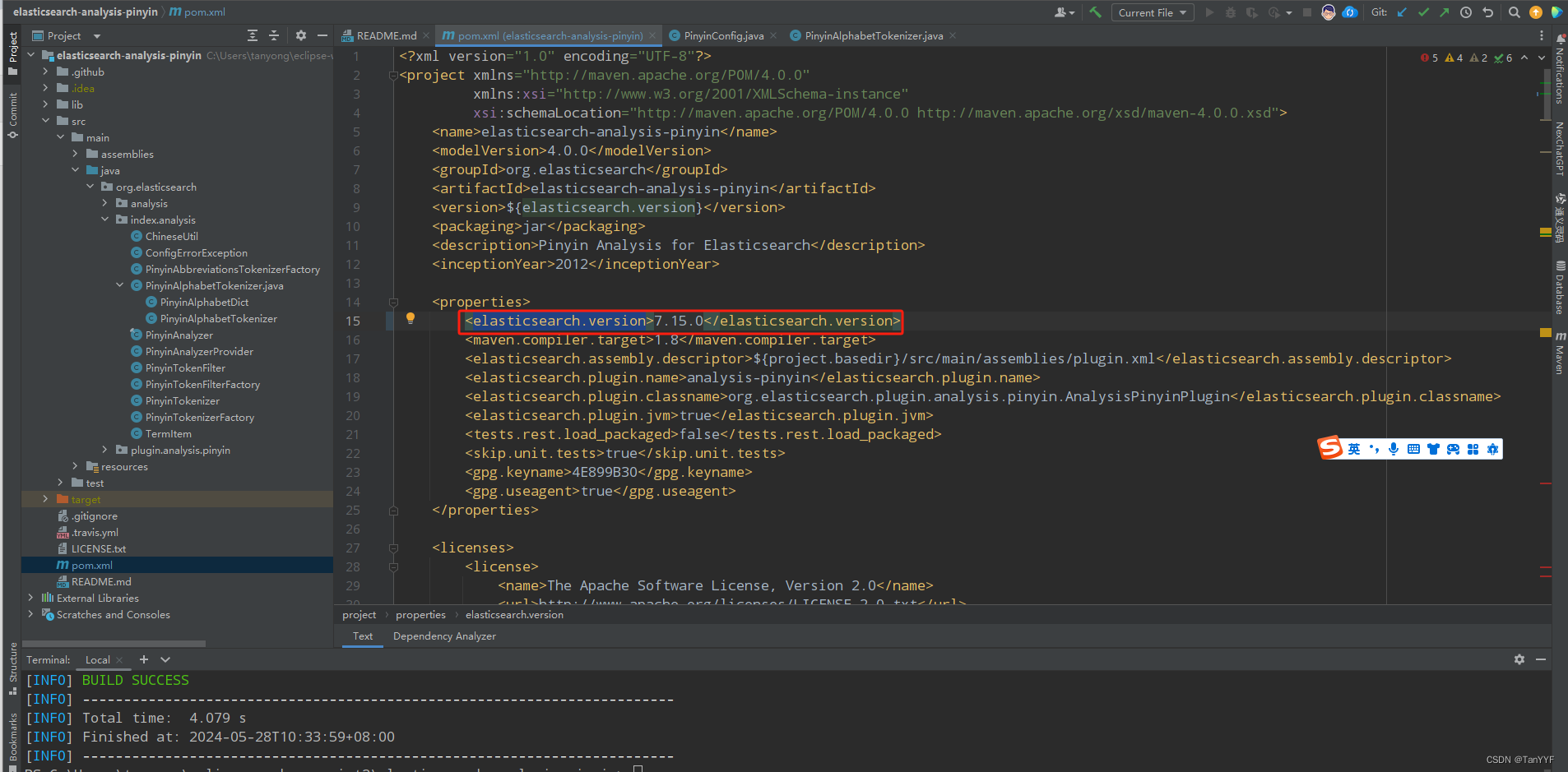
-
执行maven打包命令
mvn clean package "-Dmaven.test.skip=true"执行命令以后生成的插件:
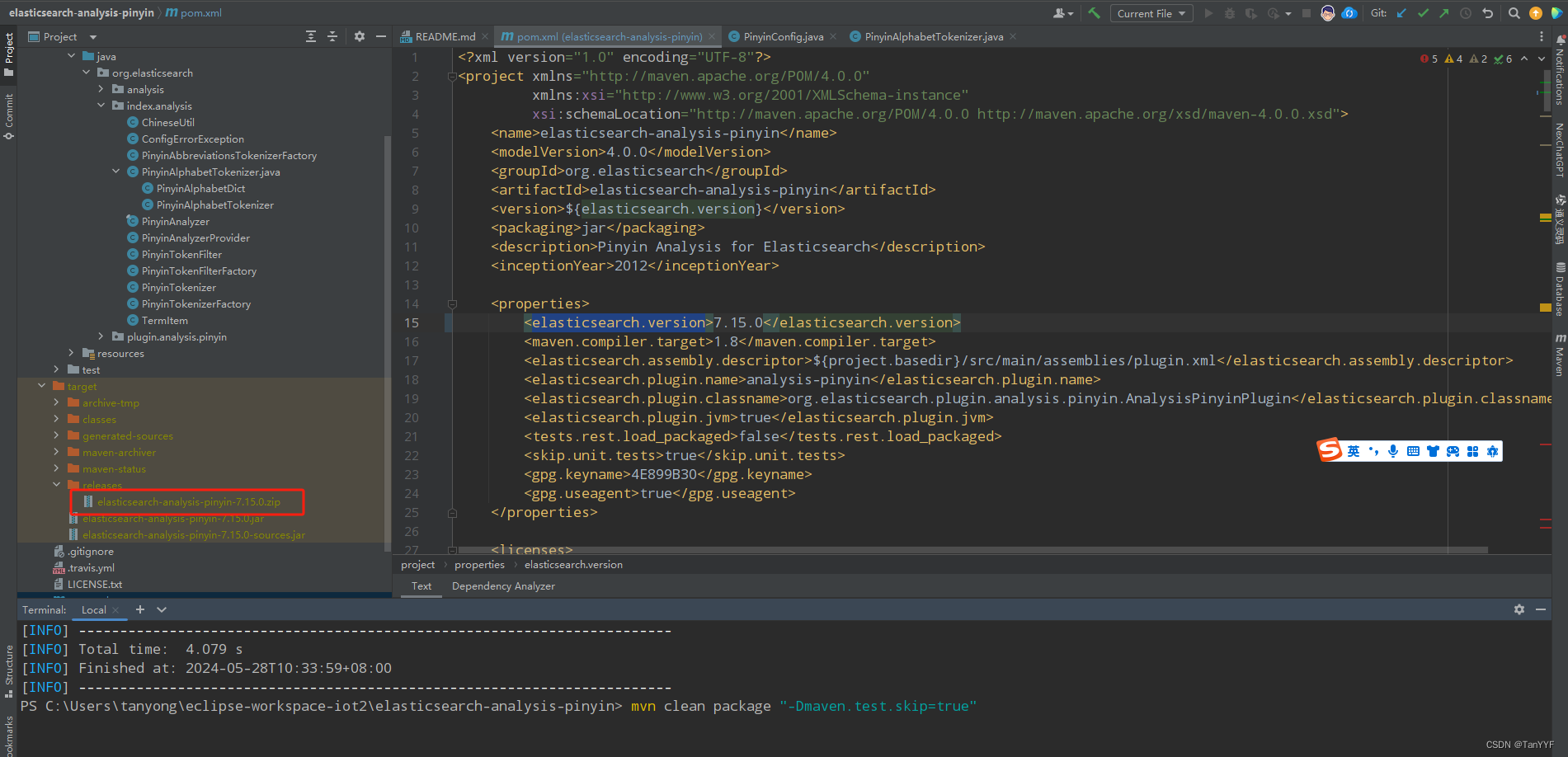
-
将elasticsearch-analysis-pinyin-7.15.0.zip上传到服务器elasticsearch安装目录,修改文件权限为elasticsearch用户权限,笔者的用户是hadoop.
chown hadoop:hadoop elasticsearch-analysis-pinyin-7.15.0.zip -
进入elasticsearch安装目录执行命令安装插件
sh ./bin/elasticsearch-plugin install file:elasticsearch-analysis-pinyin-7.15.0.zip
-
重新启动elasticsearch
# 停止 kill -9 进程id #启动 sh ./bin/elasticsearch -d -
查询插件是否安装成功
GET _cat/plugins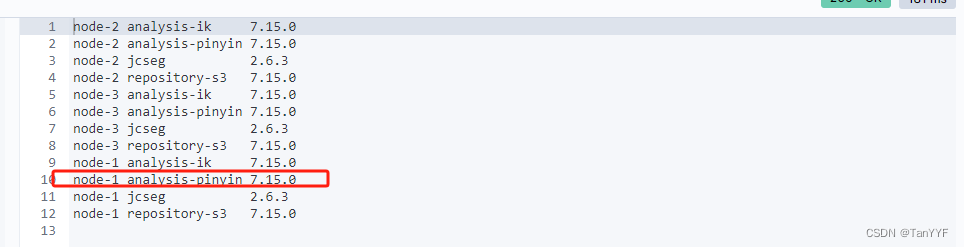
-
拼音插件参数说明
The plugin includes analyzer: pinyin , tokenizer: pinyin and token-filter: pinyin.- keep_first_letter 当启用此选项时, eg: 刘德华>ldh, default: true
- **keep_separate_first_letter ** 当此选项启用时,将单独保留首字母, eg: 刘德华>l,d,h, default: false, NOTE: 由于查询词的频率过高,查询结果可能会过于模糊
- limit_first_letter_length set max length of the first_letter result, default: 16
- keep_full_pinyin when this option enabled, eg: 刘德华> [liu,de,hua], default: true
- keep_joined_full_pinyin when this option enabled, eg: 刘德华> [liudehua], default: false
- keep_none_chinese 结果中保留非中文字母或数字, default: true
- keep_none_chinese_together keep non chinese letter together, default: true, eg: DJ音乐家 -> DJ,yin,yue,jia, when set to false, eg: DJ音乐家 -> D,J,yin,yue,jia, NOTE: keep_none_chinese should be enabled first
- keep_none_chinese_in_first_letter keep non Chinese letters in first letter, eg: 刘德华AT2016->ldhat2016, default: true
- keep_none_chinese_in_joined_full_pinyin keep non Chinese letters in joined full pinyin, eg: 刘德华2016->liudehua2016, default: false
- none_chinese_pinyin_tokenize 如果非汉语字母是拼音,则将其拆分成单独的拼音术语, default: true, eg: liudehuaalibaba13zhuanghan -> liu,de,hua,a,li,ba,ba,13,zhuang,han, NOTE: keep_none_chinese and keep_none_chinese_together should be enabled first
- keep_original 将非中文字母分成单独的拼音词,如果它们是拼音时,此选项启用,将保持原始输入, default: false
- lowercase lowercase non Chinese letters, default: true
- trim_whitespace default: true
- remove_duplicated_term when this option enabled, duplicated term will be removed to save index, eg: de的>de, default: false, NOTE: position related query maybe influenced
- ignore_pinyin_offset after 6.0, offset is strictly constrained, overlapped tokens are not allowed, with this parameter, overlapped token will allowed by ignore offset, please note, all position related query or highlight will become incorrect, you should use multi fields and specify different settings for different query purpose. if you need offset, please set it to false. default: true.
创建索引
PUT hot_word
{"settings": {"routing": {"allocation": {"include": {"_tier_preference": "data_content"}}},"number_of_shards": "1","max_result_window": "10000","number_of_replicas": "1","analysis": {"analyzer": {"pinyin_analyzer": {"tokenizer": "my_pinyin"}},"tokenizer": {"my_pinyin": {"type": "pinyin","keep_separate_first_letter": true,"keep_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"lowercase": true,"remove_duplicated_term": true}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_smart"},"suggest": {"type": "completion","analyzer": "pinyin_analyzer","preserve_separators": true,"preserve_position_increments": true,"max_input_length": 50}}}
}
类型completion 参数:
| 参数 | 说明 |
|---|---|
| analyzer | 要使用的索引分析器默认为simple。 |
| search_analyzer | 要使用的搜索分析器,默认值为analyzer。 |
| preserve_separators | 保留分隔符,默认为true。如果禁用,你可以找到一个以Foo Fighters开头的字段,如果你建议使用foof。 |
| preserve_position_increments | 启用位置增量,默认为true如果禁用并使用停用词分析器,你可以得到一个以The Beatles开头的字段,如果你建议使用b。注意:你也可以通过索引两个输入,Beatles和The Beatles来实现这一点,如果你能够丰富数据,则无需更改简单的分析器。 |
| max_input_length | 限制单个输入的长度,默认为50个UTF-16代码点。这个限制只在索引时用于减少每个输入字符串的字符总数,以防止大量输入使底层数据结构膨胀。大多数用例都不受默认值的影响,因为前缀补全的长度很少超过几个字符。 |
添加数据
PUT hot_word/_doc/1?refresh
{"name":"压克力盒","suggest":{"input":["压克力盒"],"weight":10}
}
PUT hot_word/_doc/2?refresh
{"name":"亚克力盒","suggest":{"input":["亚克力盒"],"weight":10}
}
PUT hot_word/_doc/3?refresh
{"name":"刻磨機","suggest":{"input":["刻磨機"],"weight":10}
}
PUT hot_word/_doc/4?refresh
{"name":"刻模机","suggest":{"input":["刻模机"],"weight":10}
}
suggest参数说明:
| 参数 | 说明 | 备注 |
|---|---|---|
| input | 要存储的输入,可以是一个字符串数组,也可以只是一个字符串。该字段是必填字段。 | 此值不能包含以下UTF-16控制字符:\u0000 (null),\u001f (information separator one),\u001f (information separator one) |
| weight | 一个正整数或包含一个正整数的字符串,它定义了权重,允许你对建议进行排序。该字段是可选的。 |
查询
GET hot_word/_search?pretty
{"_source": ["suggest"], "suggest": {"song-suggest": {"prefix": "关键词","completion": {"field": "suggest","size": 10,"skip_duplicates": true}}}
}
参数说明:
- suggest: suggest类型
- song-suggest: suggest名称,自定义命名
- prefix:搜索建议时使用的前缀
- completion: 建议类型
- field:搜索建议的字段名称
- size:返回的建议条数,默认5
- skip_duplicates:是否应该过滤重复的建议(默认为false)。
测试:
-
测试中文输入关键词:亚,亚克、亚克力、亚克力盒,正常返回补全结果:
{"took" : 6,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"suggest" : {"song-suggest" : [{"text" : "亚克力","offset" : 0,"length" : 3,"options" : [{"text" : "亚克力盒","_index" : "hot_word","_type" : "_doc","_id" : "2","_score" : 10.0,"_source" : {"suggest" : {"input" : ["亚克力盒"],"weight" : 10}}},{"text" : "压克力盒","_index" : "hot_word","_type" : "_doc","_id" : "1","_score" : 10.0,"_source" : {"suggest" : {"input" : ["压克力盒"],"weight" : 10}}}]}]} } -
测试拼音输入:ya、yake,yakelihe,yakelihe,正常返回补全结果:
{"took" : 7,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"suggest" : {"song-suggest" : [{"text" : "yakelihe","offset" : 0,"length" : 8,"options" : [{"text" : "亚克力盒","_index" : "hot_word","_type" : "_doc","_id" : "2","_score" : 10.0,"_source" : {"suggest" : {"input" : ["亚克力盒"],"weight" : 10}}},{"text" : "压克力盒","_index" : "hot_word","_type" : "_doc","_id" : "1","_score" : 10.0,"_source" : {"suggest" : {"input" : ["压克力盒"],"weight" : 10}}}]}]} } -
测试拼音首字母输入:y、yk、ykl、yklh,正常返回补全结果。支持首字母补全,pinyin需要设置keep_separate_first_letter为true。
-
测试同音字输入:鸭,鸭课,正常返回补全结果。
-
测试简繁体输入:刻模机,正常返回简繁体补全结果。
模糊查询
completion建议器还支持模糊查询——这意味着即使你在搜索中输入错误,仍然可以得到结果。
GET hot_word/_search?pretty
{"_source": ["suggest"], "suggest": {"song-suggest": {"prefix": "关键词","completion": {"field": "suggest","size": 10,"skip_duplicates": true,"fuzzy": {"fuzziness": 2,"min_length":4,"prefix_length":4,"transpositions": false,"unicode_aware":true}}}}
}
模糊查询fuzzy参数说明:
- fuzziness:作用:决定模糊匹配的程度。默认值为AUTO,意味着根据查询项的长度自动调整模糊匹配的严格程度。也可以手动设置为具体的值,如0(精确匹配)、1(允许一个编辑距离内的匹配)等,或者使用其他特定的字符串值(如"AUTO"、“1”、“2”)。
- transpositions:如果设置为true(默认值),则在计算编辑距离时把字符的交换视为一个变化而不是两个。这对于那些可能因快速打字而产生的常见转置错误(比如"thsi"到"this")非常有用。
- min_length:只有当查询字符串长度达到这个值时,才会返回模糊建议。默认为3,意味着较短的查询可能不会触发模糊匹配,以减少不相关的匹配结果。
- prefix_length:指定了查询字符串中从开始部分的多少个字符必须精确匹配,之后的字符才开始应用模糊匹配算法。默认为1,意味着除了最小长度要求外,所有字符都可能被模糊处理。增加这个值可以提高查询的精确度,尤其是在查询字符串较短时。
- unicode_aware:确定是否在进行模糊匹配计算时考虑Unicode编码。如果设为true,则编辑距离、转置等计算都会基于Unicode码点进行,这使得多语言文本的处理更为准确。但因为涉及到更复杂的计算,所以默认为false以追求更快的性能。
测试输入“亚可爱”,正常返回补全结果:
{"took" : 44,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"suggest" : {"song-suggest" : [{"text" : "亚可爱","offset" : 0,"length" : 3,"options" : [{"text" : "亚克力盒","_index" : "hot_word","_type" : "_doc","_id" : "2","_score" : 40.0,"_source" : {"suggest" : {"input" : ["亚克力盒"],"weight" : 10}}},{"text" : "压克力盒","_index" : "hot_word","_type" : "_doc","_id" : "1","_score" : 40.0,"_source" : {"suggest" : {"input" : ["压克力盒"],"weight" : 10}}}]}]}
}Java实现
easy-es实现:https://www.easy-es.cn/,这个框架建议索引设置为手动,自动索引还不是很稳定
- 添加maven依赖:
<!-- 引入easy-es最新版本的依赖--><dependency><groupId>org.dromara.easy-es</groupId><artifactId>easy-es-boot-starter</artifactId><!--这里Latest Version是指最新版本的依赖,比如2.0.0,可以通过下面的图片获取--><version>v2.0.0</version></dependency><!-- 排除springboot中内置的es依赖,以防和easy-es中的依赖冲突--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><exclusions><exclusion><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId></exclusion><exclusion><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.14.0</version></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.14.0</version></dependency>- java实体关键代码:
/*** 自动补齐字段*/@IndexField(fieldType = FieldType.NESTED, nestedClass = SearchHotWordV2IDX.HotSuggest.class)private SearchHotWordV2IDX.HotSuggest suggest;@Datapublic static class HotSuggest {@IndexField(fieldType = FieldType.INTEGER)private Integer weight;@IndexField(fieldType = FieldType.KEYWORD)private List<String> input;}
- 新增
使用mapper直接调用就可以 - 查询关键代码:
private static final String HOT_KEYWORD_SUGGEST_NAME = "hot-suggest";public List<String> autoComplete(String keyword, Boolean fuzzy) {LambdaEsQueryWrapper<SearchHotWordV2IDX> queryWrapper = new LambdaEsQueryWrapper<SearchHotWordV2IDX>();queryWrapper.select(SearchHotWordV2IDX::getSuggest);String newKeyword = Optional.ofNullable(keyword).map(a -> a.toLowerCase()).map(b -> StrUtil.sub(b, 0, 10)).orElseThrow(RuntimeException::new);// 定义建议构造器SuggestBuilder suggestBuilder = new SuggestBuilder();// 自动补全补齐构造器CompletionSuggestionBuilder completionSuggestionBuilder = new CompletionSuggestionBuilder("suggest").size(20).skipDuplicates(true);if (fuzzy) {// 设置模糊查询FuzzyOptions fuzzyOptions = FuzzyOptions.builder().setFuzziness(2).setFuzzyMinLength(4).setFuzzyPrefixLength(4).build();completionSuggestionBuilder.prefix(newKeyword, fuzzyOptions);} else {completionSuggestionBuilder.prefix(newKeyword);}// 自动补全添加到建议构造器suggestBuilder.addSuggestion(HOT_KEYWORD_SUGGEST_NAME, completionSuggestionBuilder);SearchSourceBuilder searchSourceBuilder = searchHotWordV2EsMapper.getSearchSourceBuilder(queryWrapper);// 建议器添加到searchSourceBuildersearchSourceBuilder.suggest(suggestBuilder);// queryWrapper设置searchSourceBuilderqueryWrapper.setSearchSourceBuilder(searchSourceBuilder);// 查询SearchResponse response = searchHotWordV2EsMapper.search(queryWrapper);Suggest suggest = response.getSuggest();// 获取自动补全结果CompletionSuggestion completionSuggestion = suggest.getSuggestion(HOT_KEYWORD_SUGGEST_NAME);return Optional.ofNullable(completionSuggestion.getOptions()).map(a -> a.stream().map(b -> b.getText().string()).collect(Collectors.toList())).orElse(null);}
相关文章:
elasticsearch7.15实现用户输入自动补全
Elasticsearch Completion Suggester(补全建议) Elasticsearch7.15安装 官方文档 补全建议器提供了根据输入自动补全/搜索的功能。这是一个导航功能,引导用户在输入时找到相关结果,提高搜索精度。 理想情况下,自动补…...

掌握正则表达式的力量:全方位解析PCRE的基础与进阶技能
Perl 兼容正则表达式(PCRE)是 Perl scripting language 中所使用的正则表达式语法标准。这些正则表达式在 Linux 命令行工具(如 grep -P)及其他编程语言和工具中也有广泛应用。以下是一些基础和进阶特性,帮你掌握和使用…...

FastFM库,一款强大神奇的Python系统分析预测的工具
FastFM库概述 在机器学习领域,Factorization Machines(FM)是处理稀疏数据集中特征间交互的重要工具.Python的fastFM库提供了高效的实现,特别适合用于推荐系统、评分预测等任务.本文将全面介绍fastFM的安装、特性、基本和高级功能,并结合实际应用场景展示…...

R语言绘图 --- 饼状图(Biorplot 开发日志 --- 2)
「写在前面」 在科研数据分析中我们会重复地绘制一些图形,如果代码管理不当经常就会忘记之前绘图的代码。于是我计划开发一个 R 包(Biorplot),用来管理自己 R 语言绘图的代码。本系列文章用于记录 Biorplot 包开发日志。 相关链接…...

用于日常任务的实用 Python 脚本
Python 是一种多功能编程语言,以其简单易读而闻名。它广泛应用于从 Web 开发到数据分析等各个领域。Python 脚本,它们可以通过自动执行常见任务来使您的生活更轻松。 用于日常任务的实用 Python 脚本 1. 使用 Pandas 进行数据分析2. 使用 BeautifulSoup …...

7-Zip是什么呢
1. 简介 7-Zip 是一个功能强大、免费开源的文件压缩和解压缩工具,适用于个人用户和企业用户,可以在多种操作系统上进行使用,并且支持广泛的压缩格式和高级功能。 2. 特点与优势 开源免费:7-Zip 是免费的开源软件,可…...

Satellite Stereo Pipeline学习
1.在Anaconda某个环境中安装s2p pip install s2p 2.在Ubuntu系统中安装s2p源代码 git clone https://github.com/centreborelli/s2p.git --recursive cd s2p pip install -e ".[test]" 3.在s2p中进行make all处理 中间会有很多情况,基本上哪个包出问题…...

linux-gpio
在Linux shell中测试GPIO通信,通常需要使用GPIO的设备文件,这些文件通常位于/sys/class/gpio目录下。要使用特定的GPIO引脚,比如GPIO92,你需要执行以下步骤: 导出GPIO引脚:首先,需要确保GPIO92已…...

C# 代码配置的艺术
文章目录 1、代码配置的定义及其在软件工程中的作用2、C# 代码配置的基本概念和工具3、代码配置的实践步骤4、实现代码配置使用属性(Properties)使用配置文件(Config Files)使用依赖注入(Dependency Injection…...

268 基于matlab的模拟双滑块连杆机构运动
基于matlab的模拟双滑块连杆机构运动,并绘制运动动画,连杆轨迹可视化输出,并输出杆件质心轨迹、角速度、速度变化曲线。可定义杆长、滑块速度,滑块初始位置等参数。程序已调通,可直接运行。 268 双滑块连杆机构运动 连…...

进口铝合金电动隔膜泵
进口铝合金电动隔膜泵是一种高效、可靠的工业泵,其特点、性能与应用广泛,以下是对其的详细分析: 特点 材质与结构: 采用铝合金材料制造,具有良好的耐腐蚀性和轻量化特点。铝合金材质使得泵体结构紧凑、轻便ÿ…...
G4 - 可控手势生成 CGAN
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目录 代码总结与心得 代码 关于CGAN的原理上节已经讲过,这次主要是编写代码加载上节训练后的模型来进行指定条件的生成 图像的生成其实只需要使用…...

使用 DuckDuckGo API 实现多种搜索功能
在日常生活中,我经常使用搜索引擎来查找信息,如谷歌和百度。然而,当我想通过 API 来实现这一功能时,会发现这些搜索引擎并没有提供足够的免费 API 服务。如果有这样的免费 API, 就能定时获取“关注实体”的相关内容,并…...
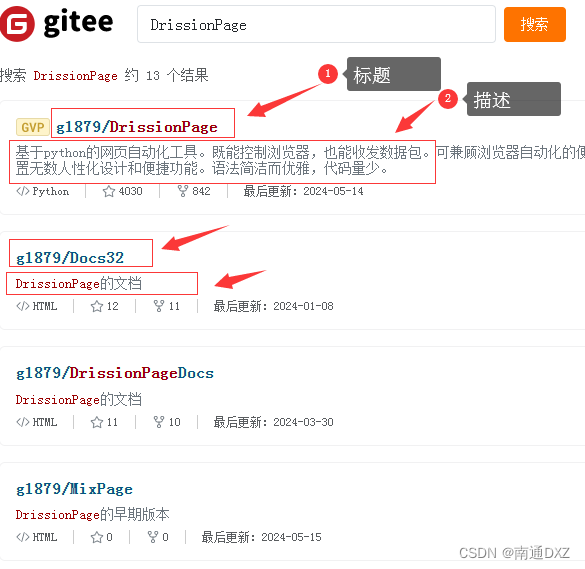
【DrissionPage爬虫库 1】两种模式分别爬取Gitee开源项目
文章目录 DrissionPage爬虫库简介1. 浏览器操控模式(类似于游戏中的后台模拟鼠标键盘)2. 数据包收发模式(类似于游戏中的协议封包) 实战中学习需求:爬取Gitee开源项目的标题与描述解决方案1:用数据包方式获…...

leetcode 115.不同的子序列
思路:LCS类dp 这道题的思考思路其实就是把以两个字符串结尾作为状态方程。 dp[i][j]的意义就是在s字符串在以s[i]结尾的字符串的情况下,所能匹配出t字符串以t[j]结尾的字符串个数。 本质上其实是一个LCS类的状态方程,只不过是意义不一样了…...

二叉树的顺序实现-堆
一、什么是堆 在数据结构中,堆(Heap)是一种特殊的树形数据结构,用数组存储,通常被用来实现优先队列。 堆具有以下特点: 堆是一棵完全二叉树(Complete Binary Tree),即…...

【Maven】Maven主要知识点目录整理
1. Maven的基本概念 作者相关文章链接: 1、【Maven】简介_下载安装-CSDN博客 定义:Maven是Apache的一个开源项目,是Java开发环境中用于管理和构建项目,以及维护依赖关系的强大软件项目管理工具。作用:简化了项目依赖…...
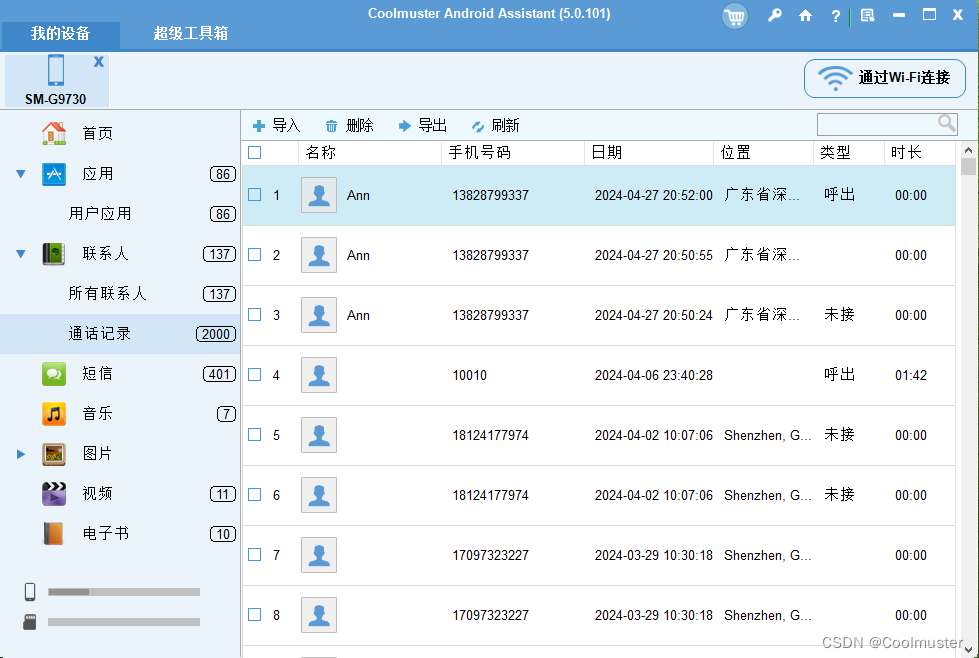
Coolmuster Android Assistant: 手机数据管理的全能助手
在数字化时代,智能手机不仅是通讯工具,更是个人数据的中心。随着数据量的不断增加,如何有效管理和保护这些数据成为了一个重要议题。Coolmuster Android Assistant应运而生,它是一款专为安卓用户设计的综合数据管理软件࿰…...

03-树3 Tree Traversals Again(浙大数据结构PTA习题)
03-树3 Tree Traversals Again 分数 25 作者 陈越 An inorder binary tree traversal can be implemented in a non-recursive way with a stack. For example, suppose that when a 6-node binary tree (with the keys numbered from 1 to 6) is traversed, th…...

Java项目对接redis,客户端是选Redisson、Lettuce还是Jedis?
JAVA项目对接redis,客户端是选Redisson、Lettuce还是Jedis? 一、客户端简介1. Jedis介绍2. Lettuce介绍3. Redisson介绍 二、横向对比三、选型说明 在实际的项目开发中,对于一个需要对接Redis的项目来说,就面临着选择合适的Redis客…...
)
别再乱装CUDA了!用Anaconda为你的3060 Ti一键搞定PyTorch GPU环境(含CUDA 11.3实战)
3060 Ti显卡玩家的PyTorch环境配置指南:用Anaconda避开CUDA版本地狱 在深度学习领域,GPU加速已经成为提升模型训练效率的标配。然而,对于许多刚入门的开发者来说,配置PyTorch的GPU支持往往成为第一道门槛——尤其是当涉及到CUDA版…...

从零到一:Android Studio集成Uniapp离线SDK打包实战
1. 环境准备:工具选择与版本匹配 第一次接触Uniapp离线打包时,最让我头疼的就是工具版本匹配问题。记得去年接手一个混合开发项目时,因为HBuilderX和SDK版本不兼容,整整浪费了两天时间排查问题。为了避免大家重蹈覆辙,…...

轻量级爬虫框架slacrawl:基于规则驱动的模块化数据采集实践
1. 项目概述:一个轻量级、模块化的网页爬虫框架最近在做一个需要从多个网站定时抓取结构化数据的小项目,找了一圈现成的工具,要么太重(像Scrapy,学起来成本高),要么太死板(很多脚本只…...

百度网盘直链解析工具:突破下载限速的Python解决方案
百度网盘直链解析工具:突破下载限速的Python解决方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾经为百度网盘的下载速度而烦恼?作为国内最…...

Steam Achievement Manager完整指南:快速解决游戏成就难题的终极工具
Steam Achievement Manager完整指南:快速解决游戏成就难题的终极工具 【免费下载链接】SteamAchievementManager A manager for game achievements in Steam. 项目地址: https://gitcode.com/gh_mirrors/st/SteamAchievementManager 核心关键词:S…...

终极指南:如何在Mac上免费快速导出微信聊天记录
终极指南:如何在Mac上免费快速导出微信聊天记录 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾因误删重要微信聊天记录而焦虑?或需要查找…...
)
从XTR文件看GNSS数据质量:如何利用Anubis报告优化你的测量方案(以GPS/BDS/Galileo为例)
从XTR文件解码GNSS数据质量:实战分析与优化策略 在GNSS测量领域,数据质量直接决定了最终定位结果的可靠性。XTR文件作为Anubis软件生成的质量报告,包含了大量反映GNSS观测质量的指标参数。对于有经验的工程师而言,这些数字不仅仅是…...

立体孪生全域可视,实现仓储人货动线全周期透明管控
立体孪生全域可视,实现仓储人货动线全周期透明管控副标题:动态三维实时还原库区人员、物资、车辆立体态势,运用库区无感定位、跨货架跨镜长距跟踪、身体指纹在岗确权,出入库、巡检、值守、调度全程透明可追溯一、方案总览现代规模…...

Kubernetes部署Valheim游戏服务器:云原生技术赋能游戏运维实践
1. 项目概述:当维京英灵殿遇上容器编排如果你和我一样,既沉迷于《英灵神殿》(Valheim)里与好友共建家园、挑战上古巨兽的乐趣,又恰好是一名整天和Kubernetes(k8s)打交道的开发者或运维ÿ…...

免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧
免费开源鼠标连点器终极指南:5分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...