Kafka Java API
1、增加依赖
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>1.0.0</version> </dependency>
2、三个案例
案例1:生产数据
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;public class Demo1KafkaProducer {public static void main(String[] args) {Properties properties = new Properties();//指定broker列表properties.setProperty("bootstrap.servers", "master:9092,node2:9092,node2:9092");//指定key和value的数据格式properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");//创建生产者KafkaProducer<String, String> producer = new KafkaProducer<>(properties);//生产数据producer.send(new ProducerRecord<>("words","java"));producer.flush();//关闭连接producer.close();}
}案例2: 文件生产数据到kafka(读取)
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;public class Demo2FileToKaFka {public static void main(String[] args) throws Exception{Properties properties = new Properties();//指定broker列表properties.setProperty("bootstrap.servers", "master:9092,node2:9092,node2:9092");//指定key和value的数据格式properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");//创建生产者KafkaProducer<String, String> producer = new KafkaProducer<>(properties);//读取文件BufferedReader bs = new BufferedReader(new FileReader("flink/data/student.csv"));String line;while ((line=bs.readLine())!=null){//生产数据 如果指定分区默认为轮循添加数据producer.send(new ProducerRecord<>("students",line));producer.flush();}//关闭连接bs.close();producer.close();}
}创建控制台消费者消费数据
kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic bigdata

使用hash分区的方式改写该案例:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;import java.io.BufferedReader;
import java.io.FileReader;
import java.util.Properties;public class Dem3FileToKafkaWithHash {public static void main(String[] args) throws Exception {Properties properties = new Properties();//指定broker列表properties.setProperty("bootstrap.servers", "master:9092,node2:9092,node2:9092");//指定key和value的数据格式properties.setProperty("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.setProperty("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");//创建生产者KafkaProducer<String, String> producer = new KafkaProducer<>(properties);//读取文件FileReader fileReader = new FileReader("flink/data/student.csv");BufferedReader bufferedReader = new BufferedReader(fileReader);String line;while ((line = bufferedReader.readLine()) != null) {String clazz = line.split(",")[4];//hash分区int partition = Math.abs(clazz.hashCode()) % 3;//生产数据//kafka-topics.sh --create --zookeeper master:2181,node1:2181,node2:2181/kafka --replication-factor 2 --partitions 3 --topic students_hash_partition//指定分区生产数据producer.send(new ProducerRecord<>("students_hash_partition", partition, null, line));producer.flush();}//关闭连接fileReader.close();bufferedReader.close();producer.close();}
}案例3:消费kafka中的数据
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.util.ArrayList;
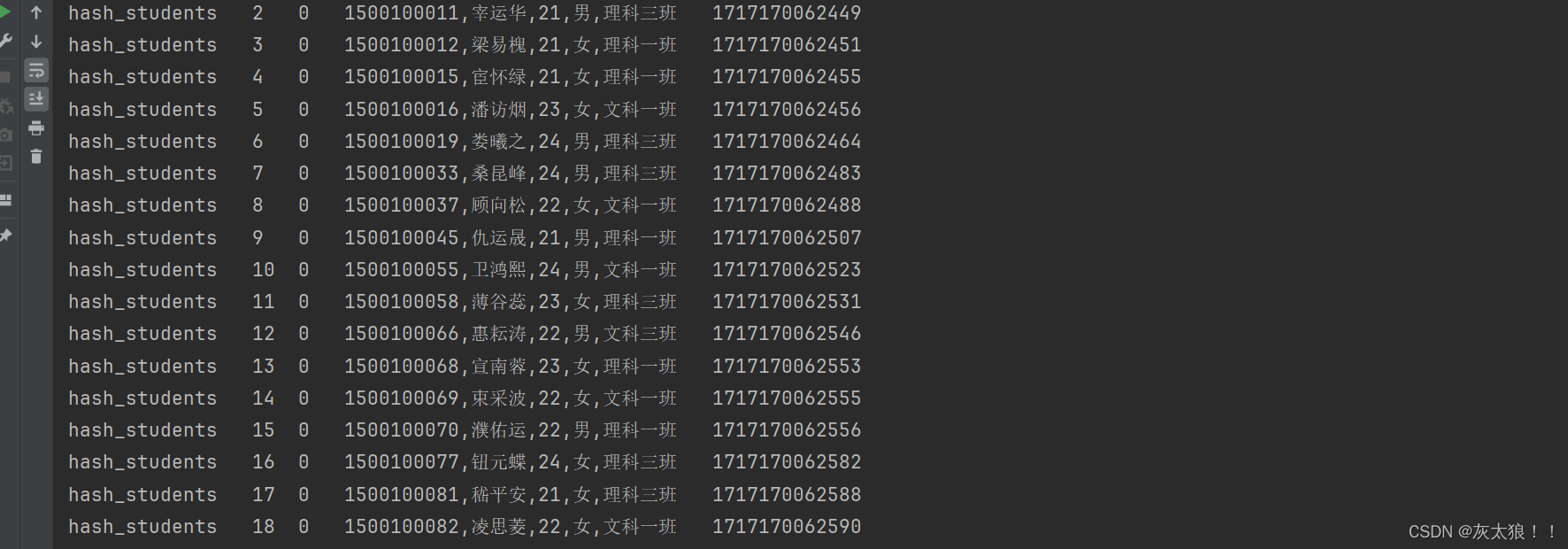
import java.util.Properties;public class Demo4Consumer {public static void main(String[] args) {Properties properties = new Properties();//指定kafka集群列表properties.setProperty("bootstrap.servers", "master:9092,node2:9092,node2:9092");//指定key和value的数据格式properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");/** earliest* 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费* latest 默认* 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产认值生的该分区下的数据* none* topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常**/properties.setProperty("auto.offset.reset", "earliest");//指定消费者组,一条数据在一个组内只消费一次properties.setProperty("group.id", "java_kafka_group1");//创建消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);//订阅topicArrayList<String> topics = new ArrayList<>();topics.add("hash_students");consumer.subscribe(topics);//死循环拉取数据,使数据全部拉取完毕while (true) {//拉取数据 默认只会拉取500条数据ConsumerRecords<String, String> consumerRecords = consumer.poll(1000);//解析数据for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {String topic = consumerRecord.topic(); //主题long offset = consumerRecord.offset(); //偏移量int partition = consumerRecord.partition(); //分区String value = consumerRecord.value(); //数据long timestamp = consumerRecord.timestamp(); //处理时间System.out.println(topic + "\t" + offset + "\t" + partition + "\t" + value + "\t" + timestamp);}}}
}
相关文章:
Kafka Java API
1、增加依赖 <dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>1.0.0</version> </dependency>2、三个案例 案例1:生产数据 import org.apache.kafka.clients.p…...

pushd: not found
解决方法: pushd 比 cd 命令更高效的切换命令,非默认,可在脚本开头添加: #! /bin/bash ubuntu 编译时出现/bin/sh: 1: pushd: not found的问题-CSDN博客...
【第十三节】C++控制台版本坦克大战小游戏
目录 一、游戏简介 1.1 游戏概述 1.2 知识点应用 1.3 实现功能 1.4 开发环境 二、项目设计 2.1 类的设计 2.2 各类功能 三、程序运行截图 3.1 游戏主菜单 3.2 游戏进行中 3.3 双人作战 3.4 编辑地图 一、游戏简介 1.1 游戏概述 本项目是一款基于C语言开发的控制台…...
酷得单片机方案 2.4G儿童遥控漂移车
电子方案开发定制,我们是专业的 东莞酷得智能单片机方案之2.4G遥控玩具童车具有以下比较有特色的特点: 1、内置充电电池:这款小车配备了可充电的电池,无需频繁更换电池,既环保又方便。充电方式可能为USB充电或者专用…...

【为什么 Google Chrome 打开网页有时极慢?尤其是国内网站,如知网等】
要通过知网搜一点资料,发现怎么都打不开。而且B站,知乎这些速度也变慢了!已经检查过确定不是网络的问题。 清空了记录,清空了已接受Cookie,清空了缓存内容……没用!!! 不断搜索&am…...

FastAPI - 数据库操作5
先安装mysql驱动程序 pipenv install pymysql安装数据库ORM库SQLAlchemy pipenv install SQLAlchemy修改文件main.py文件内容 设置数据库连接 # -*- coding:utf-8 –*- from fastapi import FastAPIfrom sqlalchemy import create_engineHOST 192.168.123.228 PORT 3306 …...

HTML静态网页成品作业(HTML+CSS)—— 冶金工程专业展望与介绍介绍网页(2个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有2个页面。 二、作品演示 三、代…...
Flutter基础 -- Dart 语言 -- 注释函数表达式
目录 1. 注释 1.1 单行注释 1.2 多行注释 1.3 文档注释 2. 函数 2.1 定义 2.2 可选参数 2.3 可选参数 默认值 2.4 命名参数 默认值 2.5 函数内定义 2.6 Funcation 返回函数对象 2.7 匿名函数 2.8 作用域 3. 操作符 3.1 操作符表 3.2 算术操作符 3.3 相等相关的…...
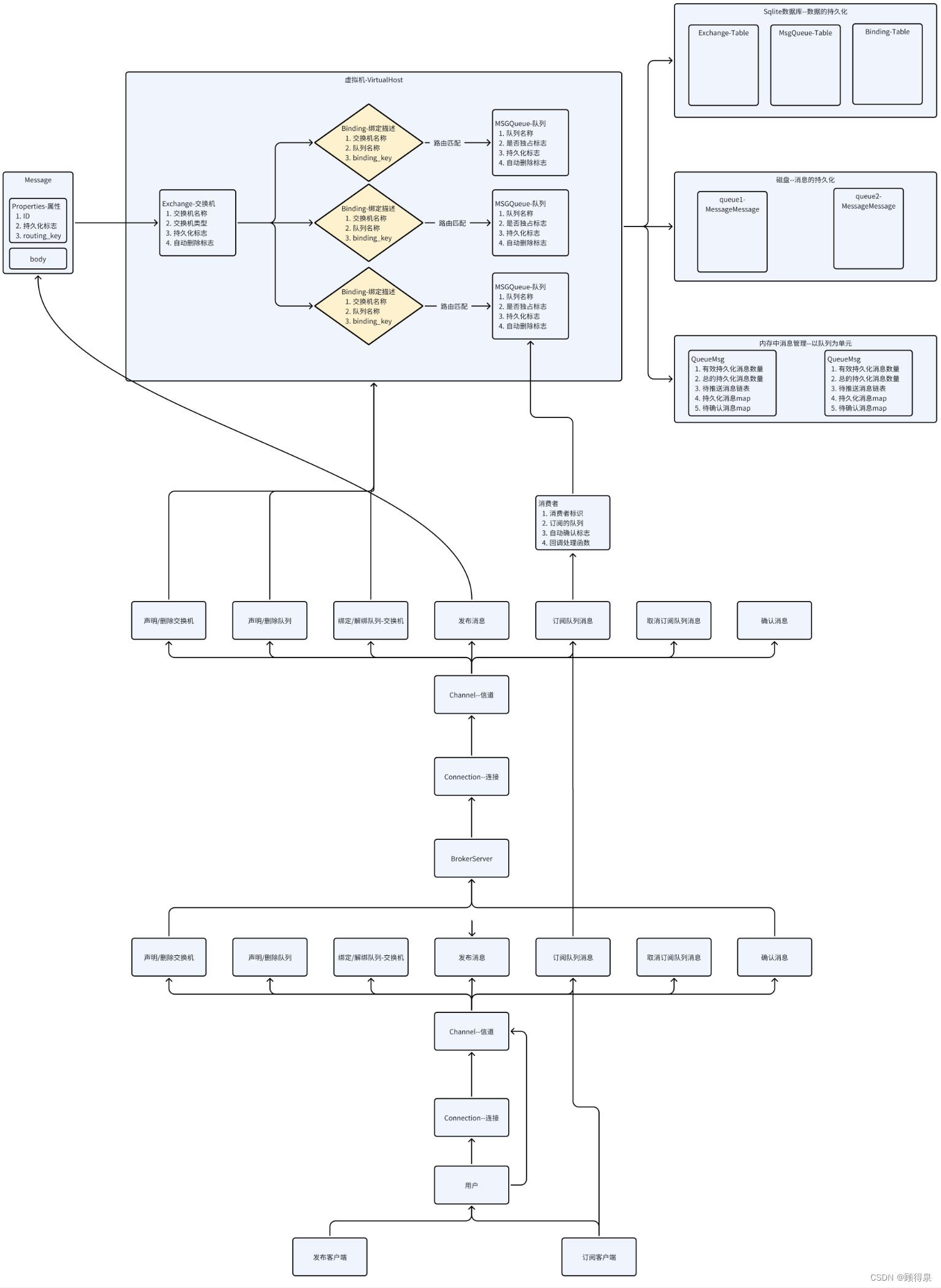
“仿RabbitMQ实现消息队列”---整体架构与模块说明
顾得泉:个人主页 个人专栏:《Linux操作系统》 《C从入门到精通》 《LeedCode刷题》 键盘敲烂,年薪百万! 一、概念性框架理解 我们主要实现的内容: 1.Broker服务器:消息队列服务器(服务端&…...

springboot如何快速接入minio对象存储
1.在项目中添加 Minio 的依赖,在使用 Minio 之前,需要在项目中添加 Minio 的依赖。可以在 Maven 的 pom.xml 文件中添加以下依赖: <dependency><groupId>io.minio</groupId><artifactId>minio</artifactId>&l…...

第六届“智能设计+运维”国产工业软件研讨会暨2024年天洑软件用户大会圆满召开
2024年5月23-24日,第六届“智能设计运维”国产工业软件研讨会暨2024年天洑软件用户大会在南京举办。来自国产工业软件研发企业、制造业企业、高校、科研院所的业内大咖,能源动力、船舶海事、车辆运载、航空航天、新能源汽车、动力电池、消费电子、石油石…...
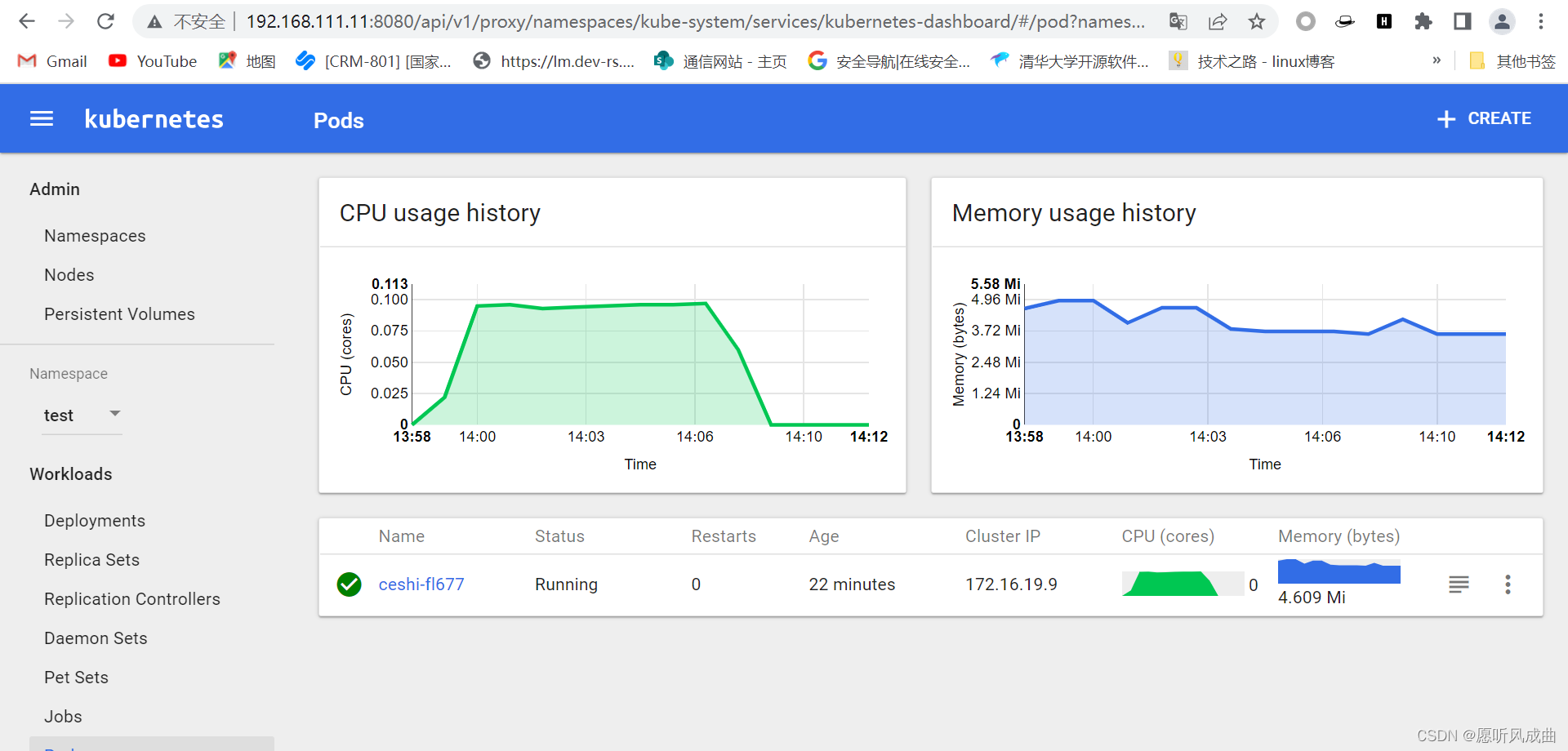
05.k8s弹性伸缩
5.k8s弹性伸缩 k8s弹性伸缩,需要附加插件heapster监控 弹性伸缩:随着业务访问量的大小,k8s系统中的pod比较弹性,会自动增加或者减少pod数量; 5.1 安装heapster监控 1:上传并导入镜像,打标签 ls *.tar.gz for n in ls *.tar.gz…...
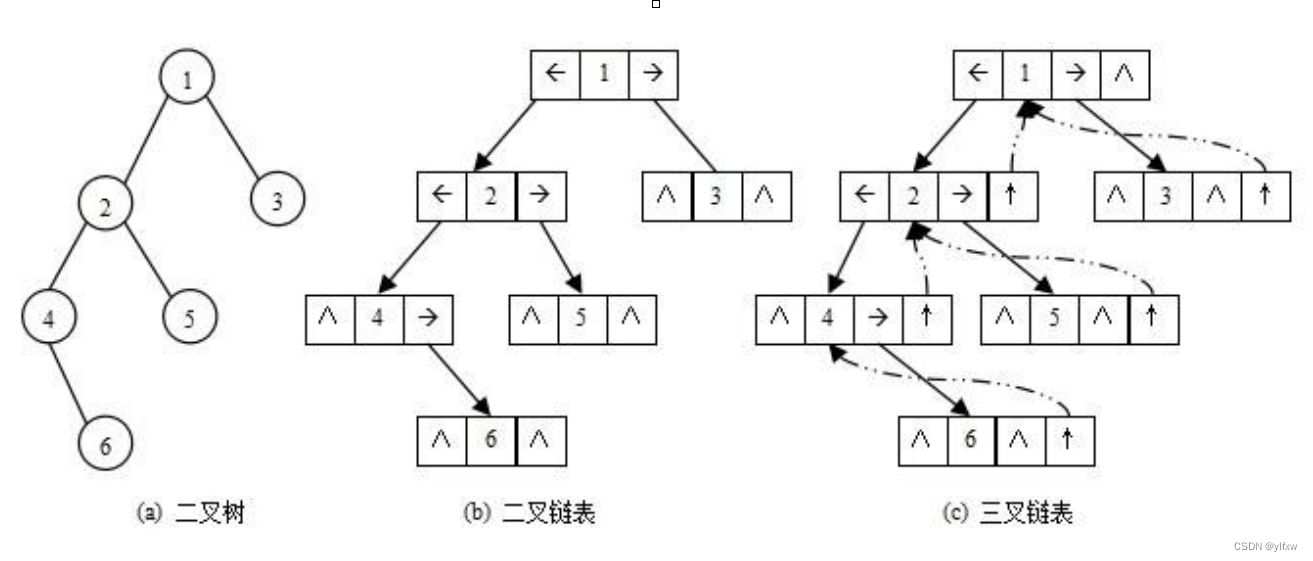
【数据结构】详解二叉树
文章目录 1.树的结构及概念1.1树的概念1.2树的相关结构概念1.3树的表示1.4树在实际中的应用 2.二叉树的结构及概念2.1二叉树的概念2.2特殊的二叉树2.2.1满二叉树2.2.2完全二叉树 2.3 二叉树的性质2.4二叉树的存储结构2.4.1顺序结构2.4.2链表结构 1.树的结构及概念 1.1树的概念…...

MapDB:轻量级、高性能的Java嵌入式数据库引擎
MapDB:轻量级、高性能的Java嵌入式数据库引擎 在今天的软件开发中,嵌入式数据库因其轻便、高效和易于集成而备受欢迎。对于Java开发者来说,MapDB无疑是一个值得关注的选项。MapDB是一个纯Java编写的嵌入式数据库引擎,它提供了高性…...

Rye: 一个革新的Python包管理工具
文章目录 Rye: 一个革新的Python包管理工具Rye的诞生背景Rye的核心特性Rye的安装与使用Rye的优势与挑战Rye的未来展望结语 Rye: 一个革新的Python包管理工具 在Python生态系统中,包管理一直是一个复杂且令人头疼的问题。随着Python社区的不断发展,出现了…...

如何在C#代码中判断当前C#的版本和dotnet版本
代码如下: using System.Reflection; using System.Runtime.InteropServices;var csharpVersion typeof(string).Assembly.GetCustomAttributes(typeof(AssemblyFileVersionAttribute), false).OfType<AssemblyFileVersionAttribute>().FirstOrDefault()?.…...
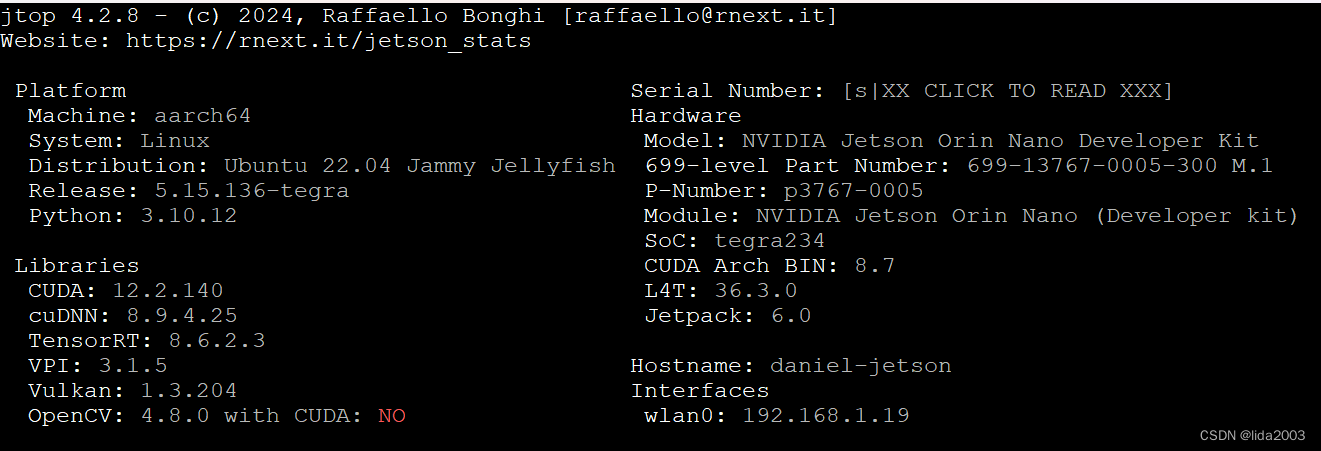
Linux 36.3@Jetson Orin Nano之系统安装
Linux 36.3Jetson Orin Nano之系统安装 1. 源由2. 命令行烧录Step 1:下载Linux 36.3安装程序Step 2:下载Linux 36.3根文件系统Step 3:解压Linux 36.3安装程序Step 4:解压Linux 36.3根文件系统Step 5:安装应用程序Step …...
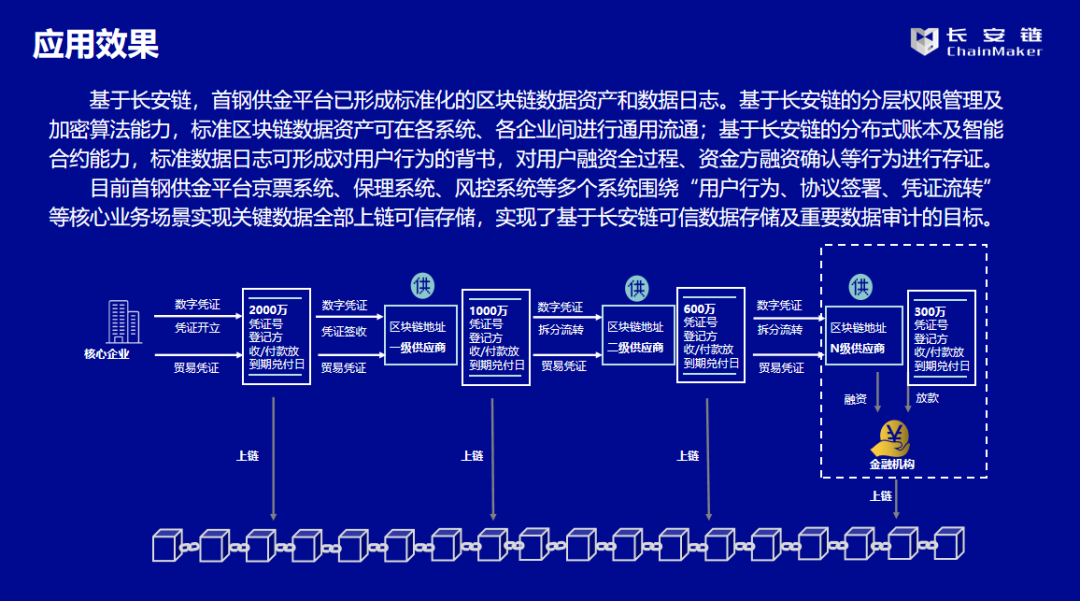
案例实践 | 基于长安链的首钢供应链金融科技服务平台
案例名称-首钢供应链金融科技服务平台 ■ 建设单位 首惠产业金融服务集团有限公司 ■ 用户群体 核心企业、资金方(多为银行)等合作方 ■ 应用成效 三大业务场景,共计关联29个业务节点,覆盖京票项目全部关键业务 案例背景…...
—Vue3.4新特性揭秘:defineModel重塑v-model,拥抱高效双向数据流!)
Vue3实战笔记(55)—Vue3.4新特性揭秘:defineModel重塑v-model,拥抱高效双向数据流!
文章目录 前言defineModel() 基本用法总结 前言 v-model 可以在组件上使用以实现双向绑定。 从 Vue 3.4 开始,推荐的实现方式是使用 defineModel() 宏 defineModel() 基本用法 定义defineModel(): <!-- Child.vue --> <script setup> con…...

C++ | Leetcode C++题解之第123题买卖股票的最佳时机III
题目: 题解: class Solution { public:int maxProfit(vector<int>& prices) {int n prices.size();int buy1 -prices[0], sell1 0;int buy2 -prices[0], sell2 0;for (int i 1; i < n; i) {buy1 max(buy1, -prices[i]);sell1 max(…...
)
【故障诊断】DSCNN-HA-TL:融合Swin窗口注意力和全局注意力机制的变工况轴承故障诊断(迁移学习/小样本)
在工业旋转机械中,滚动轴承是最关键、也最容易发生故障的部件之一。然而,变工况、故障样本稀缺、跨域泛化能力差三大难题,长期制约着故障诊断模型的落地效果。 近期,来自河北工程大学、天津大学等机构的研究团队提出了一种全新的…...

如何在不同终端里面使用claude code并使用不同模型
在使用 Claude Code 开发项目时,我们可能会遇到这样的需求:一个终端使用速度更快、成本更低的模型处理日常代码修改,另一个终端使用推理能力更强的模型处理复杂问题。比如:一个终端用 deepseek-v4-pro[1m],另一个终端用…...

ENSP实战:从Console到AAA,详解交换机安全登录的进阶配置
1. 从零开始:认识交换机登录安全的基本面 第一次接触企业级交换机时,很多新手都会被各种登录方式搞得晕头转向。我刚开始做网络运维时,就曾经因为没设置好登录认证,导致测试环境的交换机被隔壁团队的同事误操作重启。今天我们就从…...

ARM Cortex-A9 MPCore多核处理器架构与优化实践
1. ARM Cortex-A9 MPCore硬件架构概述ARM Cortex-A9 MPCore是一款广泛应用于嵌入式系统的高性能多核处理器。作为ARMv7-A架构的代表性产品,它在工业控制、汽车电子和消费电子等领域有着广泛应用。这款处理器最显著的特点是支持1-4个核心的对称多处理(SMP)配置&#…...

Cadence Allegro PCB设计效率提升:自定义快捷键配置全攻略
1. 项目概述:为什么我们需要自定义快捷键?如果你是一名电子工程师,或者正在使用Cadence Allegro进行PCB设计,那么“效率”这个词对你来说一定不陌生。每天,我们都要在Allegro的复杂菜单和工具栏中穿梭,点击…...

基于LLM的AI新闻智能体:自动化信息采集与周报生成实战
1. 项目概述:一个能自动追踪AI新闻的智能体 最近在GitHub上看到一个挺有意思的项目,叫 ai-news-weekly-agent 。光看名字,你大概能猜到它是个和AI新闻相关的自动化工具。没错,它的核心目标就是扮演一个“AI新闻周刊编辑”的角色…...

开源硬件自动化测试平台:OpenClaw Grand Central 架构与实战
1. 项目概述:一个面向开源硬件与自动化测试的“中央枢纽”最近在折腾一些开源硬件项目,特别是涉及到多设备、多协议联动的自动化测试时,经常被一个老大难问题困扰:如何高效、统一地管理和调度那些五花八门的设备?从树莓…...

不想做程序员了,听说网络安全前景好,现在转行还来得及吗?
不想做程序员了,听说网络安全前景好,现在转行还来得及吗? 我去年四月份被裁员,找了两个月工作,面试寥寥无几,就算有也都是外包,而且外包也没面试通过。我经历了挫败,迷茫࿰…...
)
别光训练模型了!用YOLOv5+OpenCV做个实时手势控制小游戏(Python源码分享)
用YOLOv5OpenCV打造手势控制游戏:从模型部署到交互设计实战 当计算机视觉遇上游戏设计,会碰撞出怎样的火花?本文将带你跨越AI模型部署与交互开发的鸿沟,用不到200行Python代码实现一个可通过手势控制的"太空侵略者"风格…...
)
终极指南:如何快速将AIO Sandbox与主流AI框架集成(LangChain、OpenAI Assistant等)
终极指南:如何快速将AIO Sandbox与主流AI框架集成(LangChain、OpenAI Assistant等) 【免费下载链接】sandbox All-in-One Sandbox for AI Agents that combines Browser, Shell, File, MCP and VSCode Server in a single Docker container. …...