爬虫学习--18.反爬斗争 selenium(3)
操作多窗口与页面切换
-
有时候窗口中有很多子tab页面。这时候肯定是需要进行切换的。selenium提供了一个叫做switch_to.window来进行切换,具体切换到哪个页面,可以从driver.window_handles中找到。
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
import time# 加载驱动
driver = webdriver.Chrome()# 拿到目标url # 这个时候发现同时拿到两个url 不能够打开两个窗口
# 访问百度
driver.get("https://www.baidu.com")
# driver.get("https://www.douban.com")
time.sleep(2)# 访问豆瓣
driver.execute_script("window.open('https://www.douban.com')")
time.sleep(2)# driver.close() # 此时发现百度被关闭了
# 检测当前驱动执行的url
print(driver.current_url)
# # 那这个时候我们操作多窗口防护变了没有了意义 因为我们只能操作第一个百度 那这个时候我就可以切换一下界面
# # 切换界面
driver.switch_to.window(driver.window_handles[1])
# # [1] 0代表的第一个最开始打开的那个 1代表的第二个 -1切换到最新打开的窗口 -2 倒数第二个打开的窗口
print(driver.current_url) # 检测看是否切换到豆瓣的url了
time.sleep(1)
# driver.switch_to.window(driver.window_handles[0])
# time.sleep(1)
# # 检测看是否能对百度进行操作
# driver.find_element(By.ID,"kw").send_keys("python")# 切换iframe
login_iframe = driver.find_element(By.XPATH,'//*[@id="anony-reg-new"]/div/div[1]/iframe')
driver.switch_to.frame(login_iframe)
time.sleep(2)
# 1 切换登录方式 定位到 密码登录(但是在这一步操作之前 要确实是否要切换iframe)
driver.find_element(By.CLASS_NAME,"tab-start").click()
time.sleep(2)
# 2 输入账号和密码
user_input = driver.find_element(By.ID,"username").send_keys("123456789")
time.sleep(2)
pwd_input = driver.find_element(By.ID,"password").send_keys("123456789")
time.sleep(2)
# 3 点击登录豆瓣
# 定位登录按钮点击 我们在定位元素的时候 如果属性出现空格的状态 形如:btn btn-account
# 解决方式 第一种我们选择属性当中的一部分(需要测试)
driver.find_element(By.CLASS_NAME,'btn-account').click()
time.sleep(3)
Selenium执行js语法
有时候selenium提供的方法会出现一些问题,或者执行起来非常麻烦,我们就可以考虑通过selenium执行javascript来实现,使复杂的操作简单化。 selenium执行js脚本的方法:
execute_script(script, *args) 描述:用来执行js语句 参数: script:待执行的js语句,如果有多个js语句,使用英文分号;连接
常见selenium下执行js代码
1 滚动页面:您可以使用 JavaScript 滚动网页以将元素显示在视图中或在页面上移动
driver.execute_script('window.scrollTo(0,document.body.scrollHeight)')2 js点击:
button = driver.find_element(By.CLASS_NAME),'my-button')
driver.execute_script("arguments[0].click();", button)3 等待元素出现:有时候,您需要等待一个元素出现或变为可见状态后再与它进行交互。
您可以使用JavaScript等待元素出现或变为可见状态后再进行交互。
# 等待元素在页面上可见
element = driver.find_element(By.CSS_SELECTOR,'#my-element')
driver.execute_script("""
var wait = setInterval(function() {
if (arguments[0].offsetParent !== null) {
clearInterval(wait);
// 元素现在可见,可以对其进行操作
}
}, 100);
""", element)4 执行自定义JavaScript:使用execute_script方法可以执行您编写的任何自定义 JavaScript 代码,
以完成测试或自动化任务。
driver.execute_script("console.log('Hello, world!');")5 打开多窗口
driver.execute_script("window.open('https://www.douban.com')")
** 这一块的只是示例 不用同学们进行记忆 但是我们可以积累 **
Selenium高级语法
-
page_source (elements源代码)
-
find() (在网页源码中寻找某个字符串是否存在)
-
find_element(By.LINK_TEXT) (根据链接文本获取 一般处理翻页)
-
node.get_attribute (node 代表的是节点名 get_attribute代表的是获取属性名)
-
node.text() (获取节点的文本内容 包含子节点和后代节点)
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
import time# 加载驱动
driver = webdriver.Chrome()# 访问百度
# driver.get('https://www.baidu.com/')"""
1拿到百度的数据结构源码 page_source
这个指的不是网页源代码而是我们前端页面最终渲染的结果也就是我们element中的数据
"""
# html = driver.page_source
# print(html)"""
2 find() 在html源码中查找某个字符是否存在
如果存在则会返回一段数字 如果不存在 不会报错 但是会返回-1
find应用场景 比如翻页爬取
"""
# print(html.find("kw"))
# print(html.find("kwwwwwwwwwwwwwwwwwww"))""" 3 find_element_by_link_text("链接文本")
# driver.get('https://www.gushiwen.cn/')
# time.sleep(3)
# # 根据链接文本内容定位按钮
# driver.find_element(By.LINK_TEXT,'下一页').click() # 点击豆瓣第一页的下一页
# # 画面会跳转到第二页 打印的是第二页的源码
# time.sleep(3)
# print(driver.page_source)"""4 node.get_attribute("属性名") node代表的是你想获取的节点 """
# url = 'https://movie.douban.com/top250'
# driver.get(url)
# a_tag = driver.find_element(By.XPATH,'//div[@class="item"]/div[@class="pic"]/a')
# print(a_tag.get_attribute('href'))""" 5 node.text 获取节点的文本内容 包含子节点和后代节点 """
# driver.get('https://movie.douban.com/top250')
# time.sleep(2)
# div_tag = driver.find_element(By.XPATH,'//div[@class="hd"]')
# print(div_tag.text)
Selenium设置无界面模式
绝大多数服务器是没有界面的,selenium控制谷歌浏览器也是存在无界面模式的(又称之为无头模式) 开启无界面模式的方法
-
实例化配置对象
options = webdriver.ChromeOptions()
-
配置对象添加开启无界面模式的命令
options.add_argument("--headless")
-
配置对象添加禁用gpu的命令
options.add_argument("--disable-gpu")
-
实例化带有配置对象的driver对象
driver = webdriver.Chrome(chrome_options=options)
from selenium import webdriver
# 创建一个配置对象
options = webdriver.ChromeOptions()
# 开启无界面模式
options.add_argument('--headless')
# 实例化带有配置的driver对象
driver = webdriver.Chrome(options=options)driver.get('http://www.baidu.com/')
html = driver.page_source
print(html)
driver.quit()
Selenium被识别问题解决方案
selenium做爬虫能解决很多反爬问题,但是selenium也有很多特征可以被识别,比如用selenium驱动浏览器后window.navigator.webdriver值是true,而正常运行浏览器该值是未定义的(undefined)
import time
from selenium import webdriver
# 使用chrome开发者模式
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])# 禁用启用Blink运行时的功能
options.add_argument("--disable-blink-features=AutomationControlled")# Selenium执行cdp命令 再次覆盖window.navigator.webdriver的值
driver = webdriver.Chrome(options=options)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.get('https://www.baidu.com/')time.sleep(3)
Selenium综合案例之当当网书籍信息爬取
import csv
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
"""
爬取当当网python爬虫书籍信息并保存到csv文件中
"""class DDspider:
# 初始化方法
def __init__(self):
# 加载驱动
self.driver = webdriver.Chrome()# 发起请求
self.driver.get('http://www.dangdang.com/')# 窗口最大化
# self.driver.maximize_window()# 定位输入框
ipt_tag = self.driver.find_element(By.ID, 'key_S')
ipt_tag.send_keys('python爬虫')
time.sleep(1)# 定位搜索框
serach_ipt = self.driver.find_element(By.CLASS_NAME, 'button')
serach_ipt.click()
time.sleep(1)# 解析目标数据
def Getitem(self):
# 将滚轮拉到底部为的是让全部的source进行加载完全
"""想办法把滚轮拖动到最后"""
# window.scrollTo 拖动滚轮 第一个参数0 表示从起始位置开始拉 第二个参数表示的是整个窗口的高度
self.driver.execute_script(
'window.scrollTo(0,document.body.scrollHeight)' # 这一点属于js代码 不需要死记 但是需要积累
)
time.sleep(1)lilist = self.driver.find_elements(By.XPATH, '//ul[@id="component_59"]/li')
print(len(lilist))# 定义列表用于存放一页中所有书的信息
books = []
for i, item in enumerate(lilist):
try:
# 定义字典用于存放每一本书的信息
book = {}
# 书图
if i == 0:
book['img'] = item.find_element(By.XPATH, './a/img').get_attribute('src')
else:
book['img'] = 'https:' + item.find_element(By.XPATH, './a/img').get_attribute('data-original')# 书名
book['name'] = item.find_element(By.XPATH, './p[@class="name"]/a').get_attribute('title')# 价格
book['price'] = item.find_element(By.XPATH, './p[@class="price"]/span').text# 作者
book['author'] = item.find_element(By.XPATH, './p[@class="search_book_author"]/span[1]').text# 出版时间
book['Publication_time'] = item.find_element(By.XPATH, './/p[@class="search_book_author"]/span[2]').text# 出版社
book['Publishing_house'] = item.find_element(By.XPATH, './/p[@class="search_book_author"]/span[3]').textbooks.append(book)
except Exception as e:
print(e.__class__.__name__)# print(books,len(books))
return books# 翻页函数
def Next_page(self):
alldata = []
while True:
books = self.Getitem()
alldata += books
print(len(alldata),"*" * 50)
if self.driver.page_source.find("next none") == -1:
next_tag = self.driver.find_element(By.XPATH, '//li[@class="next"]/a')
self.driver.execute_script("arguments[0].click();", next_tag)
time.sleep(1)
else:
self.driver.quit()
break
return alldata# 写入数据
def WriteData(self,alldata):
headers = ('img', 'name', 'price', 'author','Publication_time','Publishing_house')
with open('当当.csv', mode='w', encoding='utf-8', newline="")as f:
writer = csv.DictWriter(f, headers)
writer.writeheader() # 写入表头
writer.writerows(alldata)if __name__ == '__main__':
DD = DDspider()
alldata = DD.Next_page()
DD.WriteData(alldata)
相关文章:
)
爬虫学习--18.反爬斗争 selenium(3)
操作多窗口与页面切换 有时候窗口中有很多子tab页面。这时候肯定是需要进行切换的。selenium提供了一个叫做switch_to.window来进行切换,具体切换到哪个页面,可以从driver.window_handles中找到。 from selenium import webdriver from selenium.webdri…...

如何评价GPT-4o?
GPT-4o是OpenAI为聊天机器人ChatGPT发布的一款新语言模型,其名称中的“o”代表Omni,即全能的意思,凸显了其多功能的特性。这款模型在多个方面都有着显著的优势和进步。 首先,GPT-4o具有极强的多模态能力,它能够接受文本…...

算能BM1684+FPGA+AI+Camera推理边缘计算盒
搭载算丰智算芯片BM1684,是面向AI推理的边缘计算盒。高效适配市场上所有AI算法,实现视频结构化、人脸识别、行为分析、状态监测等应用,为智慧城市、智慧交通、智慧能源、智慧金融、智慧电信、智慧工业等领域进行AI赋能。 产品规格 处理器芯片…...
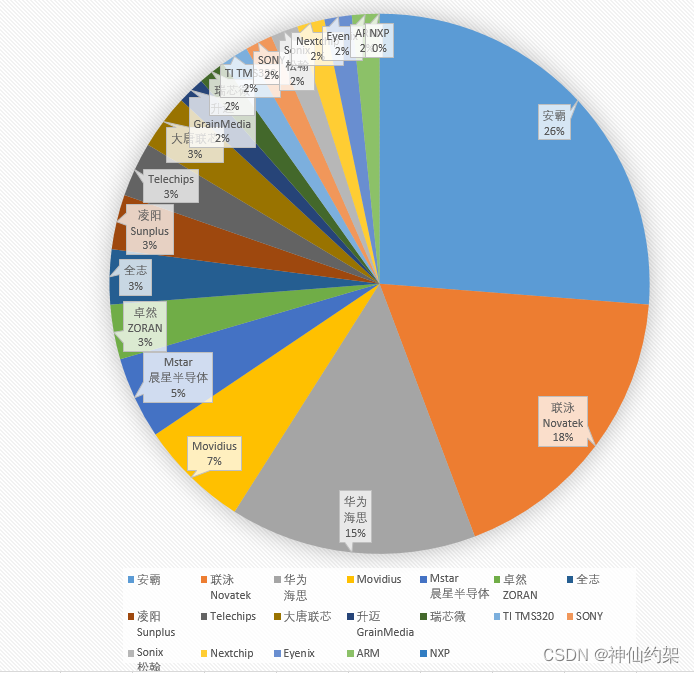
不同厂商SOC芯片在视频记录仪领域的应用
不同SoC公司芯片在不同产品上的应用信息: 大唐半导体 芯片型号: LC1860C (主控) LC1160 (PMU)产品应用: 红米2A (399元)大疆晓Spark技术规格: 28nm工艺,4个ARM Cortex-A7处理器,1.5GHz主频,2核MaliT628 GPU,1300万像…...
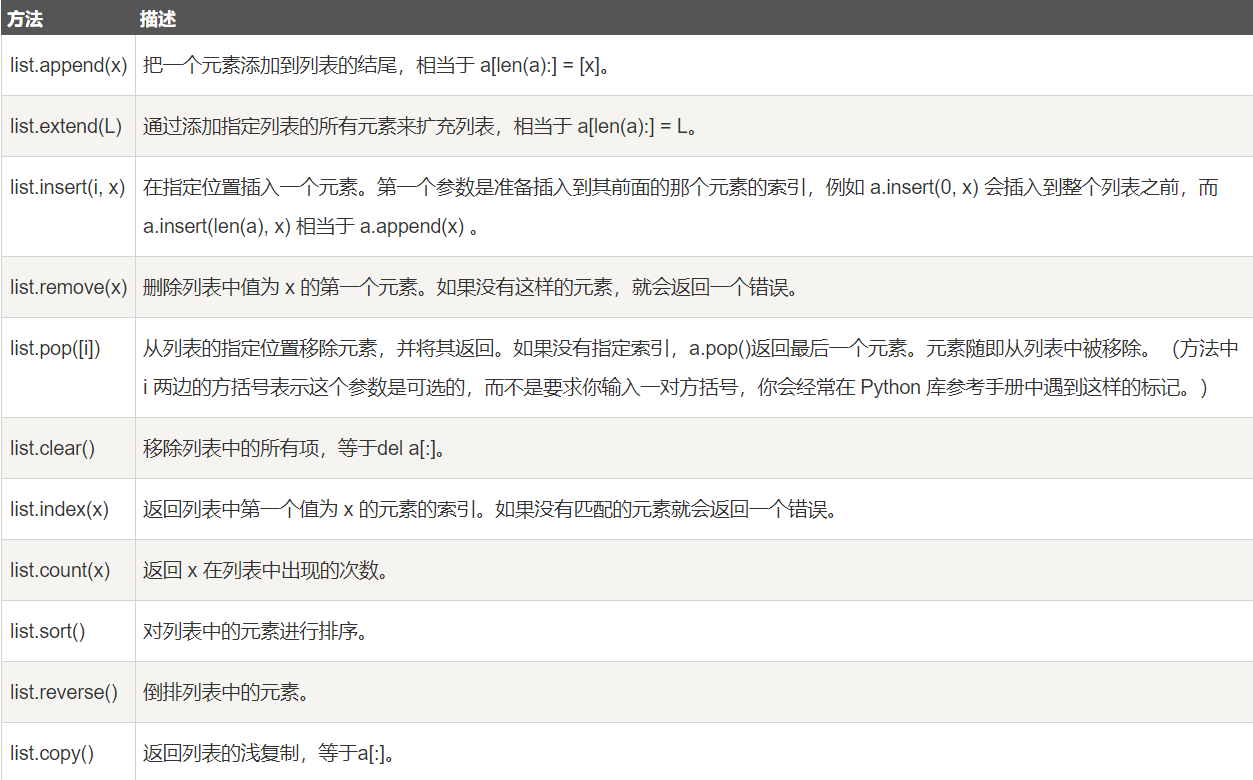
【Python入门学习笔记】Python3超详细的入门学习笔记,非常详细(适合小白入门学习)
Python3基础 想要获取pdf或markdown格式的笔记文件点击以下链接获取 Python入门学习笔记点击我获取 1,Python3 基础语法 1-1 编码 默认情况下,Python 3 源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串。 当然你也可以为源码文件指…...

通用代码生成器应用场景三,遗留项目反向工程
通用代码生成器应用场景三,遗留项目反向工程 如果您有一个遗留项目,要重新开发,或者源代码遗失,或者需要重新开发,但是希望复用原来的数据,并加快开发。 如果您的项目是通用代码生成器生成的,…...
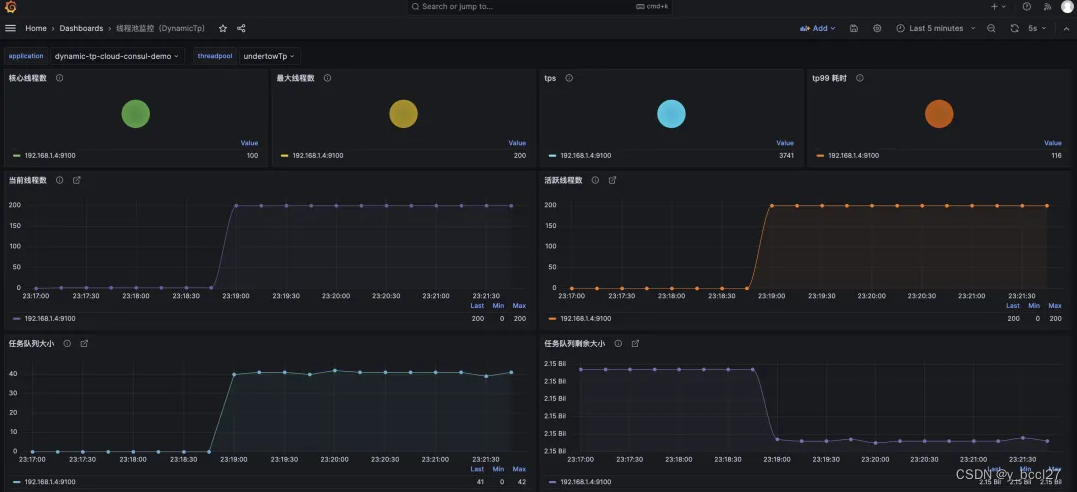
轻量级动态可监控线程池 - DynamicTp
一、背景介绍 使用线程池ThreadPoolExecutor的过程中你是否有以下痛点呢? 代码中创建了一个 ThreadPoolExecutor,但是不知道那几个核心参数设置多少比较合适凭经验设置参数值,上线后发现需要调整,改代码重新发布服务,…...
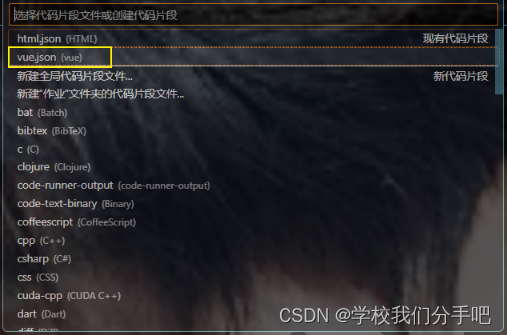
对于vsc中的vue命令 vue.json
打开vsc 然后在左下角有一个设置 2.点击用户代码片段 3.输入 vue.json回车 将此代码粘贴 (我的不一定都适合) { "vue2 template": { "prefix": "v2", "body": [ "<template>", " <…...
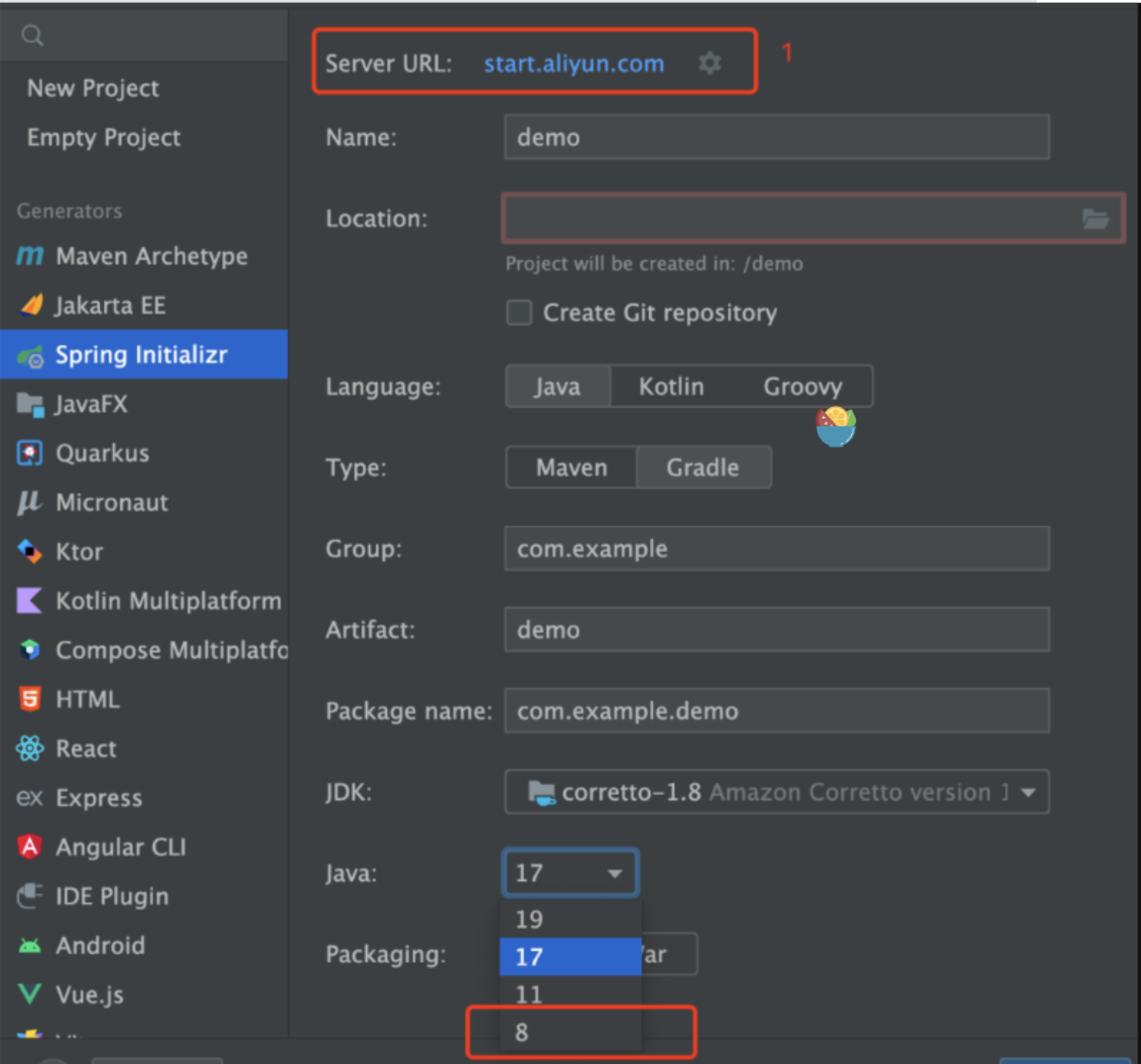
Spring Boot 官方不再支持 Spring Boot 的 2.x 版本!新idea如何创建java8项目
idea现在只能创建最少jdk17 使用 IDEA 内置的 Spring Initializr 创建 Spring Boot 新项目时,没有 Java 8 的选项了,只剩下了 > 17 的版本 是因为 Spring Boot 官方不再支持 Spring Boot 的 2.x 版本了,之后全力维护 3.x;而 …...

分享一个 ASP.NET Web Api 上传和读取 Excel的方案
前言 许多业务场景下需要处理和分析大量的数据,而 Excel 是业务人员常用的数据表格工具,因此,将 Excel 表格中内容上传并读取到网站,是一个很常见的功能,目前有许多成熟的开源或者商业的第三方库,比如 NPO…...
)
【算法实战】每日一题:将某个序列中内的每个元素都设为相同的值的最短次数(差分数组解法,附概念理解以及实战操作)
题目 将某个序列中内的每个元素都设为相同的值的最短次数 1.差分数组(后面的减去前面的值存储的位置可以理解为中间) 差分数组用于处理序列中的区间更新和查询问题。它存储序列中相邻元素之间的差值,而不是直接存储每个元素的值 怎么对某…...
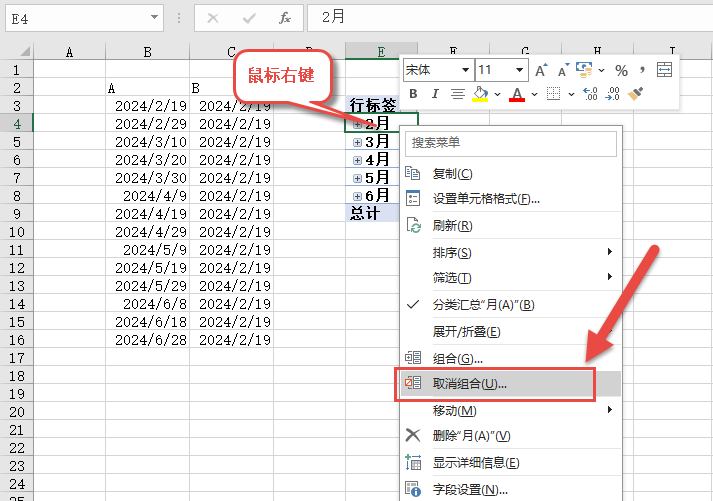
EXCEL数据透视图中的日期字段,怎样自动分出年、季度、月的功能?
在excel里,这个果然是有个设置的地方,修改后就好了。 点击文件选项卡,选项,在高级里,将图示选项的勾选给取消,然后再创建数据透视表或透视图,日期就不会自动组合了: 这个选项只对新…...

【设计模式深度剖析】【1】【行为型】【模板方法模式】| 以烹饪过程为例加深理解
👈️上一篇:结构型设计模式对比 文章目录 模板方法模式定义英文原话直译如何理解呢? 2个角色类图代码示例 应用优点缺点使用场景 示例解析:以烹饪过程为例类图代码示例 模板方法模式 模板方法模式(Template Method Pattern&…...

JAVA:异步任务处理类CompletableFuture让性能提升一倍
一、前言 CompletableFuture 是 Java 8 引入的一个功能强大的类,用于异步编程。它表示一个可能尚未完成的计算的结果,你可以对其添加回调函数来在计算完成时执行某些操作。在 Spring Boot 应用中,CompletableFuture 可以用于提高应用的响应性…...
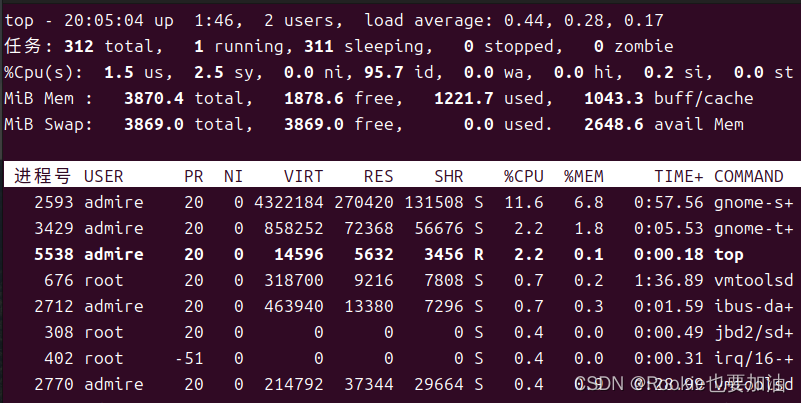
10Linux 进程管理学习笔记
Linux 进程管理 目录 文章目录 Linux 进程管理一.进程1.显示当前进程状态(ps)进程树(pstree)1.1实时显示进程信息(top)顶部概览信息:CPU 状态:内存状态:进程信息表头:进程列表:1.2(htop) 2.终止进程(kill)2.1通过名称…...
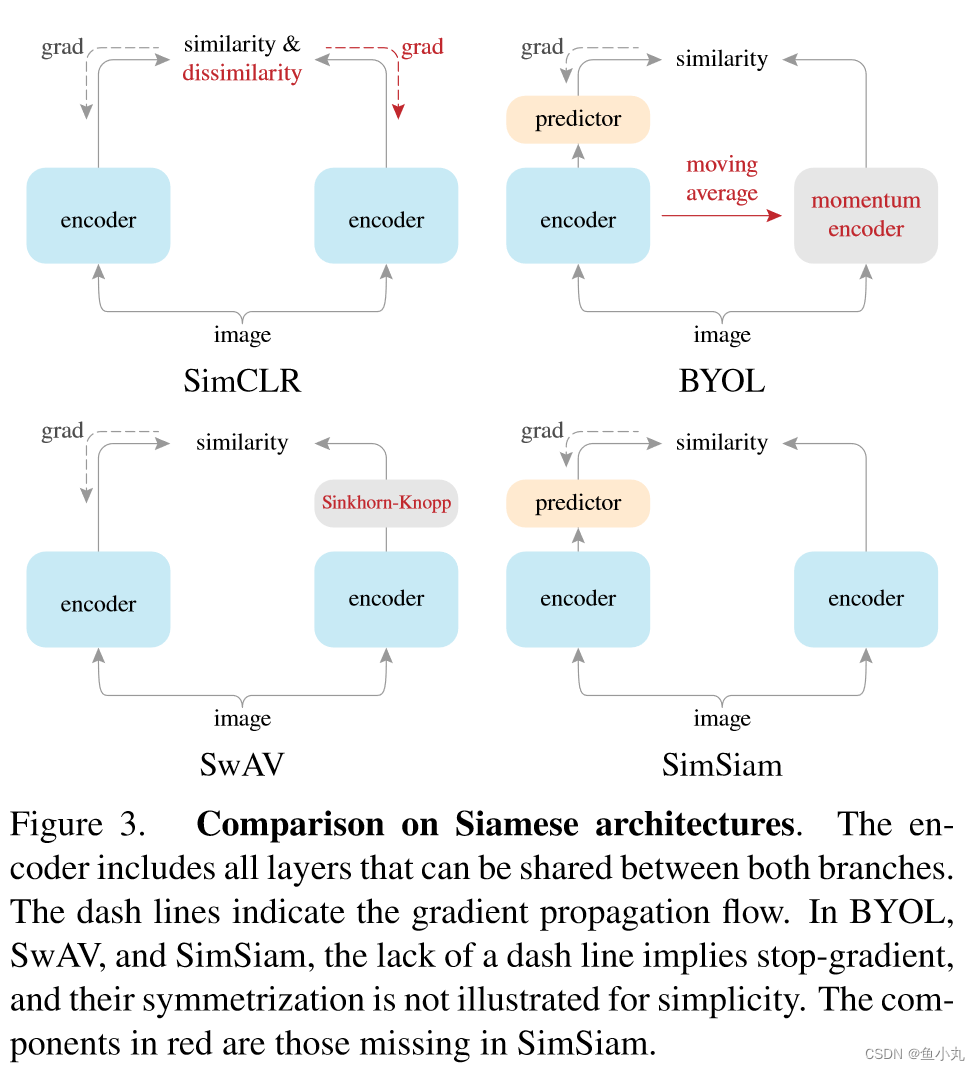
一些关于深度聚类以及部分对比学习的论文阅读笔记
目录 资料SwAV问题方法方法的创新点为什么有效有什么可以借鉴的地方聚类Multi-crop 代码 PCL代码 Feature Alignment and Uniformity for Test Time Adaptation代码 SimSiam 资料 深度聚类算法研究综述(很赞,从聚类方法和深度学习方法两个方面进行了总结࿰…...
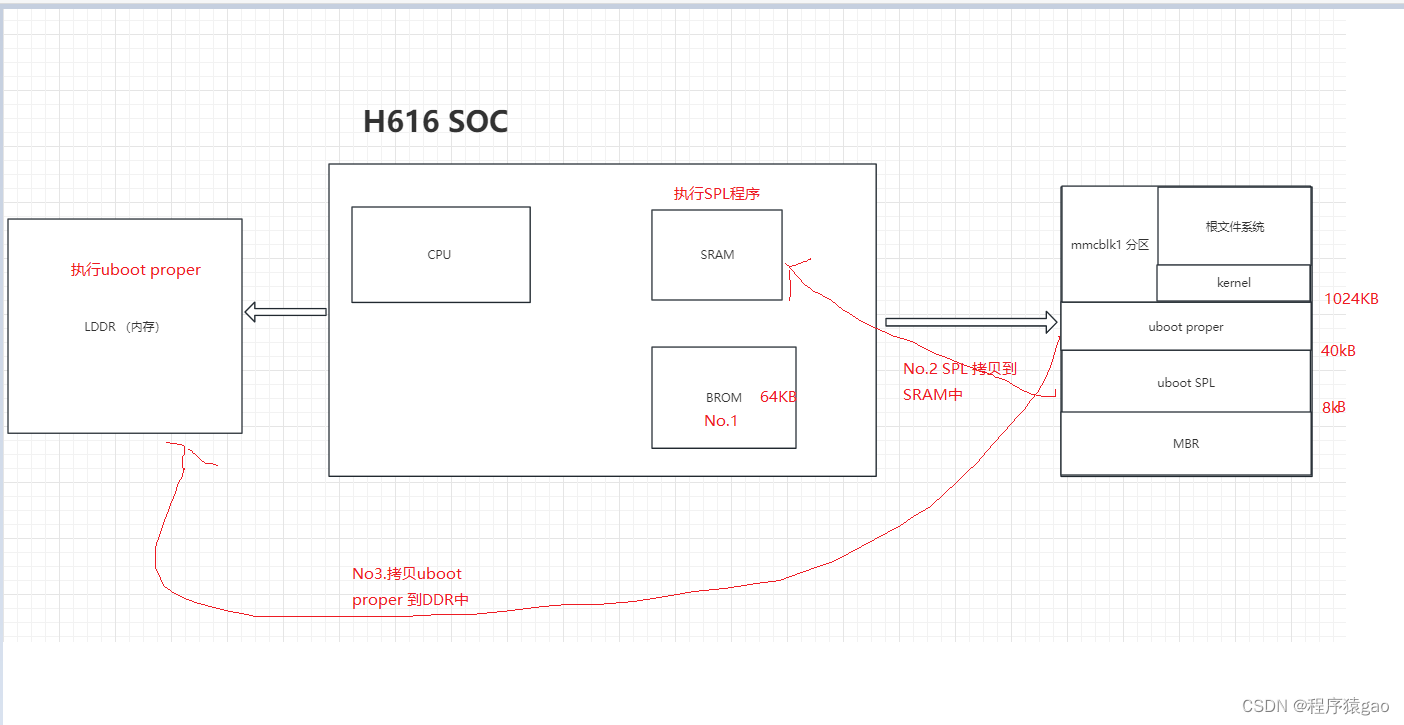
【ARM-Linux篇】u-boot编译
一、u-boot简介 uboot是一种通用的引导加载程序,它可以用于多种嵌入式系统,支持多种操作系统,如Linux, Android,NetBSD等。uboot的主要作用是将操作系统内核从存储设备(如Flash, SD卡等)加载到内存中,并执…...

Lombok一文通
1、Lombok简介 作为java的忠实粉丝,但也不得不承认,java是一门比较啰嗦的语言,很多代码的编写远不如其他静态语言方便,更别说跟脚本语言比较了。 因此,lombok应运而生。 Lombok是一种工具库,它提供了一组…...

Seq2Seq模型:详述其发展历程、深远影响与结构深度剖析
Seq2Seq(Sequence-to-Sequence)模型是一种深度学习架构,专为处理从一个输入序列到一个输出序列的映射任务设计。这种模型最初应用于机器翻译任务,但因其灵活性和有效性,现已被广泛应用于自然语言处理(NLP&a…...
公网如何访问内网?
公网和内网已经成为我们生活中不可或缺的存在。由于内网的安全性考虑,公网无法直接访问内网资源。如何实现公网访问内网呢?本文将介绍一种名为【天联】的私有通道技术,通过安全加密,保障数据传输的安全性。 【天联】私有通道技术 …...

luceda ipkiss实战:利用MZI Lattice Filter实现可调谐波分复用器
1. MZI晶格滤波器基础与可调谐波分复用原理 马赫曾德干涉仪(MZI)晶格结构是集成光子学中最经典的多功能器件之一。我第一次接触这种结构时,就被它优雅的对称性和强大的可重构性所吸引。本质上,它通过级联多个MZI单元形成周期性结构…...

基于MCP协议构建Azure DevOps智能助手:连接AI与开发运维的实践指南
1. 项目概述:一个连接开发与运维的智能“翻译官”如果你和我一样,长期在Azure DevOps的流水线、看板和代码仓库里打转,同时又对新兴的AI编程助手(比如Claude、Cursor)爱不释手,那你肯定遇到过这样的困境&am…...

Midjourney v7艺术风格跃迁路径:从基础写实到超现实叙事的5阶能力模型,含GPT-4o协同提示链模板
更多请点击: https://intelliparadigm.com 第一章:Midjourney v7艺术风格跃迁路径总览 Midjourney v7 并非简单迭代,而是以扩散模型架构重构与多模态风格理解为内核的范式跃迁。其核心突破在于引入「语义风格锚点(Semantic Style…...

零基础新手会议记录,选购避坑指南 可直接上手
日常工作学习中,不少人会遇到会议纪要整理、访谈录音处理、讲座笔记记录的难题,手动整理耗时费力还易出错。本文评测了市面上主流录音转写工具,整理了新手避坑指南和实用选择建议,零基础也能快速上手。综合实测后,听脑…...
)
从零开始:用PX4的uORB消息机制,手把手教你实现模块间通信(附代码示例)
从零构建PX4模块通信:uORB消息机制实战指南 在PX4飞控生态中,模块间通信如同无人机的神经系统,而uORB(微对象请求代理)正是这个系统的核心传输介质。当开发者尝试为飞控添加激光雷达或自定义IMU时,往往会遇…...
)
告别手动抢红包!用Kotlin写一个Android微信红包监听助手(附完整代码)
用Kotlin构建Android微信红包自动化工具:从原理到避坑指南 春节聚会时,你是否曾因低头抢红包错过亲友的精彩对话?工作群里的手气红包总在分神时一闪而过?作为一名Android开发者,其实可以用技术优雅解决这些烦恼。本文…...

突破性模组管理革命:RimSort如何解决RimWorld玩家的三大核心痛点
突破性模组管理革命:RimSort如何解决RimWorld玩家的三大核心痛点 【免费下载链接】RimSort RimSort is an open source mod manager for the video game RimWorld. There is support for Linux, Mac, and Windows, built from the ground up to be a reliable, comm…...

Swift集成飞书生态:使用feishu-swift SDK实现高效开发
1. 项目概述:一个连接飞书与Swift生态的桥梁最近在折腾一个内部工具,需要把iOS App里的某些数据自动同步到飞书文档里,方便团队协作查看。一开始想用飞书官方API直接写,但发现Swift这边原生的HTTP请求和JSON处理起来有点啰嗦&…...

开源破产法律实务知识库:构建结构化办案指南与协作平台
1. 项目概述:一个破产法律实务的开源知识库最近在整理过往的破产案件卷宗时,我一直在思考一个问题:如何将那些零散、重复但又至关重要的法律文书、办案流程和实务要点,系统地沉淀下来,形成一套可以随时查阅、迭代更新的…...
)
RFSoC开发避坑指南:手把手教你理解并配置RF数据转换器的核心结构体(以XRFdc为例)
RFSoC开发实战:深度解析XRFdc结构体配置与避坑策略 第一次打开xrfdc.h头文件时,面对密密麻麻的结构体定义,我的鼠标滚轮不由自主地滑动了三分钟才看完所有内容。作为曾经在RFSoC项目上踩过无数坑的开发者,我完全理解那种面对数十个…...