【社区投稿】给 NdArray 装上 CUDA 的轮子
Ndarry是Rust编程语言中的一个高性能多维、多类型数组库。它提供了类似 numpy 的多种多维数组的算子。与 Python 相比 Rust 生态缺乏类似 CuPy, Jax 这样利用CUDA 进行加速的开源项目。虽然 Hugging Face 开源的 candle 可以使用 CUDA backend 但是 candle 项瞄准的是大模型的相关应用。本着自己造轮子是最好的学习方法,加上受到 Karpathy llm.c 项目的感召(这个项目是学习如何编写 CUDA kernel 的最好参考之一),我搞了一个 rlib 库给 NdArray 加上一个跑在 CUDA 上的矩阵乘法。ndarray-linalg 库提供的点乘其中一个实现(features)是依赖 openblas 的,对于低维的矩阵性能可以满足需求,但是机器学习,深度学习这些领域遇到的矩阵动辄上千维,openblas 里古老的优化到极致的 Fortran 代码还是敌不过通过并行性开挂的CUDA。
动手之前我参考了 Karpathy 写的 matmul_forward.cu 文件,Karpathy 在里面实现了3种矩阵乘法,纯C代码的 kernel 函数性能明显不如调用CuBlas库和CuBlasLT库的。cublas 库是由NVIDIA提供的一个用于GPU上执行基本线性代数子程序(BLAS)操作的软件库。它是CUDA工具包的一部分,专门针对NVIDIA图形处理单元(GPUs)上的高性能科学计算优化。用 cublas 库另外一个好处就是不需要去通过 blockDim,threadIdx 去计算数据的下标。所以我决定用 cublas 来实现,虽然性能不如 CuBlasLT 但是接口要简单很多。
如何在 RUST 中调用 CUDA?
首先是一个好消息,现在 github 上已经有一个 rust 库 cudarc 封装了 CUDA 的大部分 API 当然包括cublas,甚至它还提供可以把文本编译成 PTX (NVIDIA 的官方解释: a low-levelparallel thread executionvirtual machine and instruction set architecture (ISA). PTX exposes the GPU as a data-parallel computingdevice.)的宏。如果只是直接调用 cudarc 封装好的接口,明显不符合通过造轮子解释如何通过 RUST 调用 CUDA 的目的。这里只好采用和 candle 一样的方案,利用 bindgen_cuda 库将 rust 项目 src 下面包括子目录里面的 .cu 文件全部编译打包成一个静态库,然后通过 FFI 编译连接到 rust 里面。
接下来介绍一下使用 bindgen_cuda 的步骤:
[build-dependencies]
bindgen_cuda = "0.1.5"在项目根目录下面添加 build.rs 文件,加入以下内容:
use std::env;fn main() {let dir = env::var("CARGO_MANIFEST_DIR").unwrap();let builder = bindgen_cuda::Builder::default();builder.build_lib("libcuda.a"); // 将所有.cu 编译打包成一个静态库println!("cargo:rustc-link-search={}", dir); //增加查找库文件libcuda.a的路径println!("cargo:rustc-link-search={}", "/usr/local/cuda/lib64");//增加查找cuda库的路径println!("cargo:rustc-link-lib=static=cuda");//给 ld 增加一个连接参数 -lcuda println!("cargo:rustc-link-lib=cudart");//连接cuda 运行时 libcudart.so println!("cargo:rustc-link-lib=cublas");//连接cublasprintln!("cargo:rustc-link-lib=stdc++");// .cu 其实是C++, NVCC会调用g++进行编译,所以需要C++标准库println!("cargo:rustc-link-lib=cblas");// 这是为了测试 ndarray-linalg 的 dot 函数
}bindgen_cuda 相关的配置和代码完成。接下来就是编译.cu 文件来封装 cublas 提供的矩阵乘法函数cublasSgemm。
cublasSgemm函数的定义如下:
cublasStatus_t cublasSgemm(cublasHandle_t handle,cublasOperation_t transa, cublasOperation_t transb,int m, int n, int k,const float *alpha,const float *A, int lda,const float *B, int ldb,const float *beta,float *C, int ldc)实际上这个函数执行的是 C = alpha * A * B + beta * C,这里只需要进行矩阵乘法所以 alpha = 1.0_f32 beta=0.0_f32。其他参数的说明如下:
handle 是一个结构体的指针,用 cublasCreate(&cublas_handle)这样的方式来创建;
transa 和 transb 表示A,B矩阵是否需要进行转置,NdArray 是行优先的cublas需要列优先,所以A,B都需要转置取值为CUBLAS_OP_T表示要转置,而CUBLAS_OP_N表示不转;
m 是矩阵 A 的行数;
n 是矩阵 B 的列;
k 是矩阵A的列数和矩阵B的行数;
A 矩阵A的指针;
lda A矩阵的前导维度,由于数据在内存里面是连续存储的,ldb表示列优先访问数据步长所以是A的列数(倒置后的行数);
ldb B矩阵的前导维度,这里取B的行数(倒置后的列数);
具体封装的代码在 matmul.cu 中如下:
// 使用C语言接口声明一个矩阵乘法函数,这允许这个函数可以被其他C程序调用。
extern "C" void matmul_cublas(float *out,const float *a, const float *b,int m, int n, int k)
{// 定义标量alpha和beta,这在矩阵乘法中作为系数使用:C = alpha*A*B + beta*C。const float alpha = 1.0f;const float beta = 0.0f;// 声明指向GPU内存中矩阵的指针。float *a_mat, *b_mat, *out_mat;// 在GPU上分配内存空间,为矩阵A和B以及输出矩阵out_mat。cudaCheck(cudaMalloc(&a_mat, m * k * sizeof(float)));cudaCheck(cudaMalloc(&b_mat, n * k * sizeof(float)));cudaCheck(cudaMalloc(&out_mat, m * n * sizeof(float)));// 将矩阵A和B的数据从主机复制到分配的GPU内存。cudaCheck(cudaMemcpy(a_mat, a, m * k * sizeof(float), cudaMemcpyHostToDevice));cudaCheck(cudaMemcpy(b_mat, b, n * k * sizeof(float), cudaMemcpyHostToDevice));// 调用cuBLAS库函数cublasSgemm执行单精度的矩阵乘法。// 注意:CUBLAS_OP_T表示传递给cuBLAS的矩阵在GPU中是转置的。cublasCheck(cublasSgemm(cublas_handle, CUBLAS_OP_T, CUBLAS_OP_T, m, n, k, &alpha, a_mat, k, b_mat, n, &beta, out_mat, m));// 将结果从GPU内存复制回主机内存。cudaCheck(cudaMemcpy(out, out_mat, m * n * sizeof(float), cudaMemcpyDeviceToHost));// 清理,在GPU上分配的内存空间。if (a_mat)cudaCheck(cudaFree(a_mat));if (b_mat)cudaCheck(cudaFree(b_mat));if (out_mat)cudaCheck(cudaFree(out_mat));
}在这段代码中,使用了一些辅助宏cudaCheck和cublasCheck来检查 CUDA 和 cuBLAS 调用是否成功。这些宏来自 Karpathy llm.c 项目的 common.h。
对应的 RUST 的代码如下:
// Extern block defining functions implemented in foreign code (e.g. C/C++ using CUDA).
extern "C" {fn matmul_cublas(out: *mut c_float,a: *const c_float,b: *const c_float,m: size_t,n: size_t,k: size_t,);fn _init_cublas();fn _destory_cublas();
}// Function to perform matrix multiplication using the cuBLAS library.
pub fn matmul<D1: Dimension, D2: Dimension, D3: Dimension>(out: &mut ArrayBase<OwnedRepr<f32>, D1>,a: &ArrayBase<ViewRepr<&f32>, D2>,b: &ArrayBase<ViewRepr<&f32>, D3>,
) {let out_ptr = out.as_mut_ptr();let a_ptr = a.as_ptr();let b_ptr = b.as_ptr();let (m, n, k) = get_shape(a, b);unsafe {_init_cublas();matmul_cublas(out_ptr, a_ptr, b_ptr, m, n, k); // Calling the foreign CUDA function._destory_cublas();}
}其中 _init_cublas() 和 _destory_cublas() 分别用于调用 cublasCreate 和 cublasDestroy 。我把handle 实现成了 singleton,还加上了一个计数器防止多次 free() 导致的内存错误。
接下来通过定义一个 trait 来给 NdArray 数组加上 cuda_dot 的方法。
// A trait that defines a CUDA-based dot product between arrays.
pub trait CudaDot<Rhs> {type Output;// The method signature for performing the dot product using CUDA.fn cuda_dot(&self, rhs: &Rhs) -> Self::Output;
}// Implementation of CudaDot for 1D owned representation arrays.
impl CudaDot<ArrayBase<OwnedRepr<f32>, Ix1>> for ArrayBase<OwnedRepr<f32>, Ix1> {type Output = ArrayBase<OwnedRepr<f32>, Ix1>;// Performs dot product on 1D arrays using CUDA and returns the result as a 1-element array.fn cuda_dot(&self, rhs: &ArrayBase<OwnedRepr<f32>, Ix1>) -> Self::Output {let mut out = Array::from_elem(1, 0.0_f32);matmul(&mut out, &self.view(), &rhs.t());return out;}
}// Implementation of CudaDot for multiplying a 1D array with a 2D array.
impl CudaDot<ArrayBase<OwnedRepr<f32>, Ix2>> for ArrayBase<OwnedRepr<f32>, Ix1> {type Output = ArrayBase<OwnedRepr<f32>, Ix1>;// Performs multiplication of a 1D array with a 2D array.fn cuda_dot(&self, rhs: &ArrayBase<OwnedRepr<f32>, Ix2>) -> Self::Output {let mut out = Array::from_elem(1, 0.0_f32);matmul(&mut out, &self.view(), &rhs.view());return out;}
}// Implementation of CudaDot for multiplying a 2D array with a 1D array.
impl CudaDot<ArrayBase<OwnedRepr<f32>, Ix1>> for ArrayBase<OwnedRepr<f32>, Ix2> {type Output = ArrayBase<OwnedRepr<f32>, Ix1>;// Performs multiplication of a 2D array with a 1D array.fn cuda_dot(&self, rhs: &ArrayBase<OwnedRepr<f32>, Ix1>) -> Self::Output {let mut out = Array::from_elem(1, 0.0_f32);matmul(&mut out, &rhs.view(), &self.view());return out;}
}// Implementation of CudaDot for 2D arrays.
impl CudaDot<ArrayBase<OwnedRepr<f32>, Ix2>> for ArrayBase<OwnedRepr<f32>, Ix2> {type Output = ArrayBase<OwnedRepr<f32>, Ix2>;// Performs dot product on two 2D arrays using CUDA and returns a new 2D array.fn cuda_dot(&self, rhs: &ArrayBase<OwnedRepr<f32>, Ix2>) -> Self::Output {let (m, n, _) = get_shape(&self.view(), &rhs.view());let mut out = Array::from_elem((n, m), 0.0_f32);matmul(&mut out, &self.view(), &rhs.view());return out;}
}这里实现了 1D, 2D 矩阵之间的点乘。trait 是 rust 非常棒的特性,无需继承,组合等等就可以给已有库增加新的功能。trait 确实是 Rust 类型系统的基石,使得代码更模块化、灵活且易于维护。
核心代码就全部介绍完了。既然是为了利用 CUDA 的异构并行计算能力,当然需要对比一下 cuda_dot 与 NdArray-linalg 库提供的 dot 的性能。
对比测试的代码如下:
fn dot_with_ndarry() {let a = Array::from_elem((H_SIZE, H_SIZE), 1.0_f32);let b = Array::from_elem((H_SIZE, V_SIZE), 1.0_f32);let start = Instant::now();for _ in 0..100 {let _ = a.dot(&b);}println!("ndarray dot elapsed: {:.2?}", start.elapsed());}fn dot_with_cuda() {let a = Array::from_elem((H_SIZE, H_SIZE), 1.0_f32);let b = Array::from_elem((H_SIZE, V_SIZE), 1.0_f32);let start = Instant::now();for _ in 0..100 {let _ = a.cuda_dot(&b);}println!("matmul elapsed: {:.2?}", start.elapsed());}在低维度情况下,NdArray-linalg 性能比 cuda_dot, 但是维度以上去cuda_dot的优势就很明显了。下面是具体测试的数据。
硬件环境:微软 Azure 提供的带一张 Nvidia A10 显卡,36 核 CPU的云主机 (感谢微软的慷慨)。
软件:
g++ (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
rustc 1.77.2 (25ef9e3d8 2024-04-09)
cuda_12.1
Nvidia Driver Version: 535.154.05
Rows(H_SIZE) Columns(V_SIZE) ndarra-linalg cuda_dot -------------- ----------------- --------------- ---------- 64 64 2.27ms 9.89ms 128 80 11.37ms 10.66ms 768 128 438.01ms 57.86ms 2048 1000 22800ms 323.30ms从测试可以看出,在高维度矩阵乘法场景下 cublas 体现出了巨大的优势。
全部的代码在:https://github.com/Lyn-liyuan/ndarray-cuda-matmul
相关文章:

【社区投稿】给 NdArray 装上 CUDA 的轮子
Ndarry是Rust编程语言中的一个高性能多维、多类型数组库。它提供了类似 numpy 的多种多维数组的算子。与 Python 相比 Rust 生态缺乏类似 CuPy, Jax 这样利用CUDA 进行加速的开源项目。虽然 Hugging Face 开源的 candle 可以使用 CUDA backend 但是 candle 项瞄准的是大模型的相…...
)
Linux|Linux常用命令合集(一)
想记录一下个人会用到的一些linux命令,持续更新中… chmod\chown 之前如果文件权限不足,直接就是 chmod 777 filename/dirname ,这并不是一个好习惯。 r(读权限):值为4w(写权限)&a…...

RTPS协议之Behavior Module
目录 交互要求基本要求RTPS Writer 行为RTPS Reader行为 RTPS协议的实现与Reader匹配的Writer的行为涉及到的类型RTPS Writer实现RTPS WriterRTPS StatelessWriterRTPS ReaderLocatorRTPS StatefulWriterRTPS ReaderProxyRTPS ChangeForReader RTPS StatelessWriter BehaviorBe…...
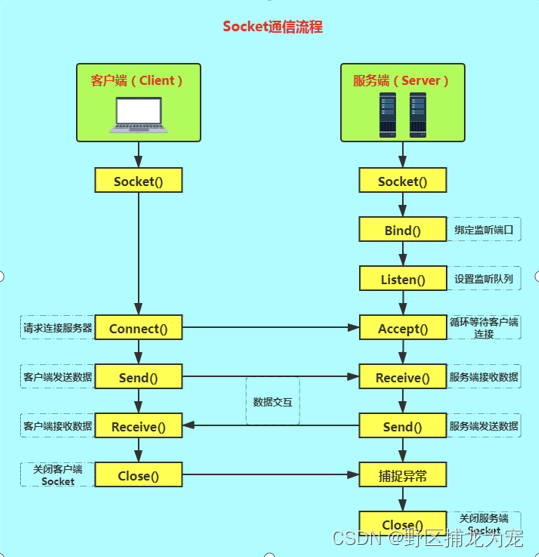
Socket网络通讯入门(一)
提示:能力有限,不足以及错误之处还请指出! 文章目录 前言一、 计算机网络 OSI、TCP/IP、五层协议 体系结构1.OSI七层模型每层的作用2.TCP/IP协议分成3.五层协议体系结构 二、Socket服务端和客户端 简单通信1.服务端代码2.客户端 总结 前言 简…...

第十五课,海龟画图:抬笔与落笔函数、画曲线函数
一,turtle.penup()和turtle.pendown():抬起与落下画笔函数 当使用上节课学习的这个turtle.forward():画笔前进函数时,画笔会朝着当前方向在画布上留下一条指定(像素)长度的直线,但你可能发现&a…...

【机器学习】让大模型变得更聪明
文章目录 前言1. 理解大模型的局限性1.1 理解力的挑战1.2 泛化能力的挑战1.3 适应性的挑战 2. 算法创新:提高模型学习和推理能力2.1 自监督学习2.2 强化学习2.3 联邦学习 3. 数据质量与多样性:增强模型的泛化能力3.1 高质量数据的获取3.2 数据多样性的重…...

5.26机器人基础-DH参数 正解
1.建立DH坐标系 1.确定Zi轴(关节轴) 2.确定基础坐标系 3.确定Xi方向(垂直于zi和zi1的平面) 4.完全确定各个坐标系 例子: 坐标系的布局是由个人决定的,可以有不同的选择 标准坐标系布局: …...
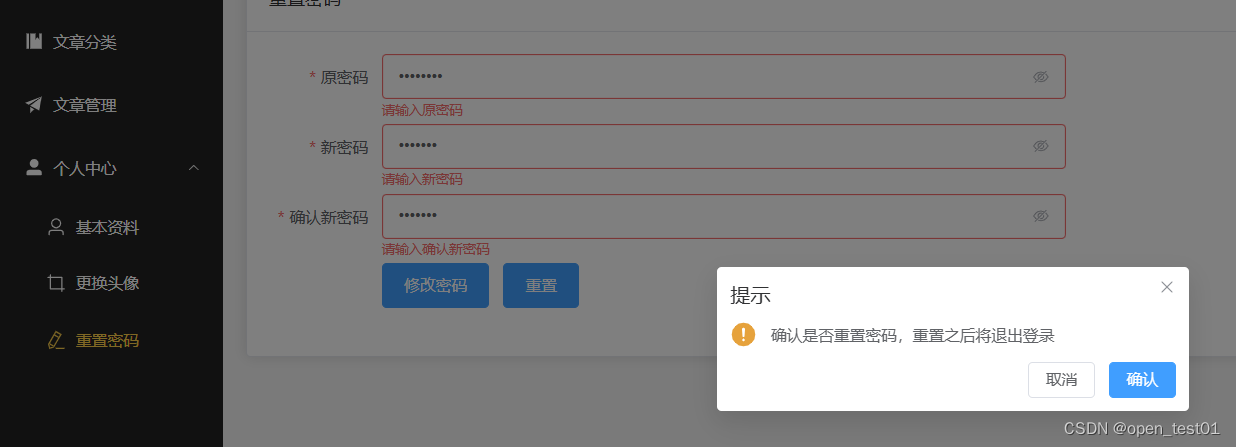
Vue3项目练习详细步骤(第五部分:用户模块的功能)
顶部导航栏个人信息显示 接口文档 接口请求与绑定 导航栏下拉菜单功能 路由实现 退出登录和路由跳转实现 基本资料修改 页面结构 接口文档 接口请求与绑定 修改头像 页面结构 头像回显 头像上传 接口文档 重置密码 页面结构 接口文档 接口请求与绑定 顶部导航…...

测试onlyoffice在线预览文件功能
HTML示例代码 <!DOCTYPE html> <html lang"zh"><head><meta charset"UTF-8"><title>测试onlyoffice在线预览文件功能</title><script type"text/javascript" src"http://onlyoffice服务器ip:端口/…...

Day57 每日温度 + 下一个更大元素Ⅰ
739 每日温度 题目链接:739.每日温度 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,…...
)
nuxt3 api如何透传(不引第3方库)
背景: nuxt做为一个vue的服务端渲染框架,本身就具备服务端的功能,理论上可以完整做一个系统功能,包括对数据库等等操作,但更合理的做法是nuxt应该定位只做服务端渲染的事情,更偏向ui层面,而非数据curd,业务逻辑,权限等等偏向服务端的逻辑。本身基于vue的服务端渲染已…...
list常用接口模拟实现
文章目录 一、模拟list类的框架二、函数接口实现1、迭代器接口2、常用删除、插入接口3、常用其他的一些函数接口4、默认成员函数 一、模拟list类的框架 1、使用带哨兵的双向链表实现。 2、链表结点: // List的结点类 template<class T> struct ListNode {Li…...
 —— Stylelint(v16.6.1):CSS/SCSS 代码质量工具)
前端工程化工具系列(三) —— Stylelint(v16.6.1):CSS/SCSS 代码质量工具
Stylelint 是 CSS/SCSS 代码的静态分析工具,用于检查代码中的错误和样式违规。 1. 环境要求 v16 以上的 Stylelint,支持 Node.js 的版本为 v18.12.0。 在命令行中输入以下内容来查看当前系统中 node 的版本。 node -vNode.js 推荐使用 v18.20.3 或者 …...

crossover mac好用吗 CrossOver Mac怎么下载 Mac用crossover损害电脑吗
CrossOver 是一款可以让Mac用户能够自由运行和游戏windows游戏软件的虚拟机类应用,虽然能够虚拟windows但是却并不是一款虚拟机,也不需要重启系统或者启动虚拟机,类似于一种能够让mac系统直接运行windows软件的插件。它以其出色的跨平台兼容性…...

PHP模块pdo_sqlite.so: undefined symbol: sqlite3_column_table_name
安装 php-sqlite3 之后,执行php -m 命令有警告,如下 PHP Warning: PHP Startup: Unable to load dynamic library pdo_sqlite (tried: /usr/lib64/php/modules/pdo_sqlite (/usr/lib64/php/modules/pdo_sqlite: cannot open shared object file: No su…...
卷积神经网络-奥特曼识别
数据集 四种奥特曼图片_数据集-飞桨AI Studio星河社区 (baidu.com) 中间的隐藏层 已经使用参数的空间 Conv2D卷积层 ReLU激活层 MaxPool2D最大池化层 AdaptiveAvgPool2D自适应的平均池化 Linear全链接层 Dropout放置过拟合,随机丢弃神经元 -----------------…...
VB.net进行CAD二次开发(四)
netload不能弹出对话框,参考文献2 参考文献1说明了自定义菜单的问题,用的是cad的系统命令 只要加载了dll,自定义的命令与cad的命令同等地位。 这时,可以将自定义菜单的系统命令替换为自定义命令。 <CommandMethod("Add…...

3步轻松月入过万,APP广告新模式大揭秘!
万万没想到:用这个APP广告模式,月入过万竟然如此简单! 在移动应用开发的世界里,变现一直是一道难题。 许多APP开发者和产品经理为了提高收益、增强用户黏性,不断尝试各种策略。 然而,很多时候,…...

java项目之智能家居系统源码(springboot+vue+mysql)
风定落花生,歌声逐流水,大家好我是风歌,混迹在java圈的辛苦码农。今天要和大家聊的是一款基于springboot的智能家居系统。项目源码以及部署相关请联系风歌,文末附上联系信息 。 项目简介: 基于Springboot的智能家居系…...

前端 JS 经典:读取文件原始内容
前言:有些时候在工程化开发中,我们需要读取文件里面的原始内容,比如,你有一个文件,后缀名为 .myfile,你需要拿到这个文件里的内容,该怎么处理呢。 在 vue2 中,因为 vue2 使用 vue-c…...

c++ 动态链接器audit c++如何使用ld_audit监控so加载过程
Oracle监听端口被占用导致TNS-12541错误,需检查并更换端口(如1522),同步更新listener.ora、tnsnames.ora及JDBC连接串,重启监听;EM Express需单独配置HTTP端口;Windows下还需手动开放防火墙新端…...

基于CRICKIT与CPX的交互式电子展板:从传感器到执行器的完整原型开发指南
1. 项目概述:打造一个会“思考”和“反应”的电子展板如果你对Arduino或树莓派这类微控制器项目感兴趣,但又觉得从零开始连接电机、灯带、传感器,还要处理复杂的电源和信号问题,过程太过繁琐和容易出错,那么这个项目可…...

churrera-cli:Go语言开发的Git仓库批量克隆与自动化管理工具
1. 项目概述:一个为开发者“挤奶油”的命令行工具如果你是一名经常与GitHub、GitLab等代码托管平台打交道的开发者,那么你一定对“克隆仓库”这个动作再熟悉不过了。每天,我们可能都需要从不同的地方拉取代码库,无论是为了学习、复…...
开源清理工具OpenClearn:透明可控的数字垃圾管理方案
1. 项目概述:一个开源的“清洁工”如何重塑你的数字生活如果你和我一样,是个在数字世界里摸爬滚打了十几年的老鸟,那你电脑里肯定也有一堆“数字垃圾”。这些垃圾不是指那些过时的文件,而是那些你明明已经删除了,但操作…...

全栈代码资源聚合库:开发者如何高效利用开源代码示例提升工程能力
1. 项目概述:一个面向开发者的全栈代码资源聚合库最近在GitHub上看到一个挺有意思的项目,叫wuwangzhang1216/claude-code-source-all-in-one。光看这个名字,你大概能猜到这是个什么——没错,这是一个围绕“代码”和“源代码”做文…...

Allegro铺铜避坑指南:从十字花焊盘到孤铜删除,新手必知的10个实用技巧
Allegro铺铜避坑指南:从十字花焊盘到孤铜删除,新手必知的10个实用技巧 第一次在Allegro中铺铜时,那种手足无措的感觉我至今记忆犹新。面对密密麻麻的参数选项和看似简单的操作背后隐藏的各种"坑",即使是完成了布局布线的…...

2026企业数字化必看:实在Agent订单数据处理智能助理实战及ERP自动录入教程
进入2026年,全球企业级自动化市场已完成从“流程驱动”向“智能体(Agent)驱动”的范式转移。根据Gartner与IDC在2025年底发布的联合报告显示,超过85%的500强企业已在其核心业务流程中部署了具备自主决策能力的数字员工。在这一背景…...

BilibiliDown:专业级B站视频下载工具,高效构建个人媒体库
BilibiliDown:专业级B站视频下载工具,高效构建个人媒体库 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.co…...

三步快速解锁网盘高速下载:LinkSwift直链解析终极指南
三步快速解锁网盘高速下载:LinkSwift直链解析终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

HarmonyOS 6 CalendarPickerDialog 日历选择弹窗使用文档
文章目录完整代码功能概述代码结构说明核心参数详解1. 基础参数2. DateRange 结构说明3. 示例禁用区间配置说明总结完整代码 Entry Component struct CalendarPickerDialogExample {private selectedDate: Date new Date(2025-08-05);private disabledDateRange: DateRange[]…...