AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.05.01-2024.05.10
文章目录~
- 1.Pseudo-Prompt Generating in Pre-trained Vision-Language Models for Multi-Label Medical Image Classification
- 2.VLSM-Adapter: Finetuning Vision-Language Segmentation Efficiently with Lightweight Blocks
- 3.Memory-Space Visual Prompting for Efficient Vision-Language Fine-Tuning
- 4.THRONE: An Object-based Hallucination Benchmark for the Free-form Generations of Large Vision-Language Models
- 5.Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
- 6.Knowledge-aware Text-Image Retrieval for Remote Sensing Images
- 7.Adapting Dual-encoder Vision-language Models for Paraphrased Retrieval
- 8.Research on Image Recognition Technology Based on Multimodal Deep Learning
- 9.Source-Free Domain Adaptation Guided by Vision and Vision-Language Pre-Training
- 10.ImageInWords: Unlocking Hyper-Detailed Image Descriptions
- 11.Generalizing CLIP to Unseen Domain via Text-Guided Diverse Novel Feature Synthesis
- 12.What matters when building vision-language models?
- 13.Learning Object States from Actions via Large Language Models
- 14.Few Shot Class Incremental Learning using Vision-Language models
- 15.CLIPArTT: Light-weight Adaptation of CLIP to New Domains at Test Time
1.Pseudo-Prompt Generating in Pre-trained Vision-Language Models for Multi-Label Medical Image Classification
标题:在预训练的视觉语言模型中生成伪提示,用于多标签医学图像分类
author:Yaoqin Ye, Junjie Zhang, Hongwei Shi
date Time:2024-05-10
paper pdf:http://arxiv.org/pdf/2405.06468v1
摘要:
医学图像识别任务因存在多种不同的病理指征而明显复杂化,这给未见标签的多标签分类带来了独特的挑战。这种复杂性凸显了对采用多标签零点学习的计算机辅助诊断方法的需求。预训练视觉语言模型(VLMs)的最新进展展示了医疗图像零镜头分类的显著能力。然而,这些方法在利用来自更广泛图像数据集的大量预训练知识方面存在局限性,而且通常依赖于放射科专家的手动提示构建。通过自动调整提示过程,提示学习技术已成为使 VLM 适应下游任务的有效方法。然而,现有的基于 CoOp 的策略在对未见类别执行特定类别提示方面存在不足,从而限制了在细粒度场景中的通用性。为了克服这些限制,我们从自然语言处理(NLP)中的文本生成中汲取灵感,引入了一种新颖的提示生成方法。我们的方法被命名为伪提示生成(PsPG),它利用了多模态特征的先验知识。PsPG 采用基于 RNN 的解码器,可自动生成符合类别的嵌入向量,即伪提示。在各种多标签胸片数据集上进行的比较评估证实,我们的方法优于领先的医学视觉语言和多标签即时学习方法。源代码见 https://github.com/fallingnight/PsPG
2.VLSM-Adapter: Finetuning Vision-Language Segmentation Efficiently with Lightweight Blocks
标题:VLSM 适配器:利用轻量级块高效微调视觉语言分割
author:Manish Dhakal, Rabin Adhikari, Safal Thapaliya, Bishesh Khanal
publish:12 pages, 5 figures, 2 tables
date Time:2024-05-10
paper pdf:http://arxiv.org/pdf/2405.06196v1
摘要:
利用大规模开放域图像和文本对训练的基础视觉语言模型(VLM)最近被用于开发视觉语言分割模型(VLSM),该模型可在推理过程中提供文本提示,以指导图像分割。如果能为医学图像建立稳健而强大的 VLSM,就能帮助医疗专业人员完成许多临床任务,因为在这些任务中,他们必须花费大量时间来划分感兴趣的目标结构。由于注释医学图像数据集较少,用于医学图像的 VLSM 需要对基础 VLM 或在开放域自然图像数据集上预训练的 VLSM 进行微调;这种微调耗费资源且成本高昂,因为它通常需要更新全部或大部分预训练参数。最近,有人在 VLM 中提出了称为适配器的轻量级模块,它可以冻结预训练模型,只在微调期间训练适配器,从而大大减少了所需的计算资源。我们介绍了一种新型适配器–VLSM-Adapter,它可以使用变压器编码器对预训练的视觉语言分割模型进行微调。我们在广泛使用的基于 CLIP 的分割模型中进行的实验表明,只需 300 万个可训练参数,VLSM-Adapter 就能超越最先进的技术,并与端到端微调的上限相当。源代码可在以下网址获取:https://github.com/naamiinepal/vlsm-adapter。
3.Memory-Space Visual Prompting for Efficient Vision-Language Fine-Tuning
标题:记忆空间视觉提示,实现高效的视觉语言微调
author:Shibo Jie, Yehui Tang, Ning Ding, Zhi-Hong Deng, Kai Han, Yunhe Wang
publish:Accepted to ICML2024
date Time:2024-05-09
paper pdf:http://arxiv.org/pdf/2405.05615v1
摘要:
目前,高效构建大型视觉语言(VL)模型的解决方案分为两步:将预训练视觉编码器的输出投射到预训练语言模型的输入空间,作为视觉提示;然后通过端到端参数高效微调(PEFT)将模型转移到下游 VL 任务中。然而,这种模式仍然效率低下,因为它大大增加了语言模型的输入长度。在本文中,与将视觉提示整合到输入中不同,我们将视觉提示视为额外的知识,有助于语言模型处理与视觉信息相关的任务。我们发现语言模型的前馈网络(FFN)具有 "键值记忆 "的作用,受此启发,我们引入了一种称为记忆空间视觉提示(MemVP)的新方法,将视觉提示与前馈网络的权重连接起来,以注入视觉知识。各种 VL 任务和语言模型的实验结果表明,MemVP 显著减少了微调 VL 模型的训练时间和推理延迟,其性能超过了以前的 PEFT 方法。代码:https://github.com/JieShibo/MemVP
4.THRONE: An Object-based Hallucination Benchmark for the Free-form Generations of Large Vision-Language Models
标题:THRONE:基于物体的幻觉基准,用于自由生成大型视觉语言模型
author:Prannay Kaul, Zhizhong Li, Hao Yang, Yonatan Dukler, Ashwin Swaminathan, C. J. Taylor, Stefano Soatto
publish:In CVPR 2024
date Time:2024-05-08
paper pdf:http://arxiv.org/pdf/2405.05256v1
摘要:
在大型视觉语言模型(LVLM)中减少幻觉仍然是一个未决问题。最近的基准并没有解决开放式自由回答中的幻觉问题,我们称之为 “第一类幻觉”。相反,它们关注的是对非常具体的问题格式做出反应的幻觉–通常是关于特定对象或属性的多项选择反应–我们称之为 “第二类幻觉”。此外,此类基准通常需要外部 API 调用模型,而这些模型可能会发生变化。在实践中,我们发现减少第二类幻觉并不会导致第一类幻觉的减少,相反,这两种形式的幻觉往往互不相关。为了解决这个问题,我们提出了 THRONE,这是一个基于对象的新型自动框架,用于定量评估 LVLM 自由形式输出中的 I 型幻觉。我们使用公共语言模型(LMs)来识别 LVLM 反应中的幻觉,并计算相关指标。通过使用公共数据集对大量最新的 LVLM 进行评估,我们发现现有指标的改进并不会导致 I 型幻听的减少,而且现有的 I 型幻听测量基准并不完整。最后,我们提供了一种简单有效的数据增强方法,以减少第一类和第二类幻觉,并以此作为强有力的基准。
5.Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
标题:用于零镜头异常检测的双图像增强型 CLIP
author:Zhaoxiang Zhang, Hanqiu Deng, Jinan Bao, Xingyu Li
date Time:2024-05-08
paper pdf:http://arxiv.org/pdf/2405.04782v1
摘要:
图像异常检测一直是计算机视觉领域的一项挑战性任务。视觉语言模型的出现,特别是基于 CLIP 框架的兴起,为零镜头异常检测开辟了新的途径。最近的研究通过将图像与正常和提示性描述对齐,探索了 CLIP 的使用。然而,完全依赖文本指导往往无法达到预期效果,这凸显了额外视觉参考的重要性。在这项工作中,我们利用视觉语言联合评分系统,引入了一种双图像增强 CLIP 方法。我们的方法处理成对的图像,利用每张图像作为另一张图像的视觉参考,从而用视觉语境丰富推理过程。这种双图像策略显著提高了异常分类和定位性能。此外,我们还利用测试时间适应模块加强了我们的模型,该模块结合合成异常来完善定位能力。我们的方法极大地挖掘了视觉语言联合异常检测的潜力,并在各种数据集上展示了与当前 SOTA 方法相当的性能。
6.Knowledge-aware Text-Image Retrieval for Remote Sensing Images
标题:遥感图像的知识感知文本图像检索
author:Li Mi, Xianjie Dai, Javiera Castillo-Navarro, Devis Tuia
publish:Under review
date Time:2024-05-06
paper pdf:http://arxiv.org/pdf/2405.03373v1
摘要:
在大型地球观测档案中进行基于图像的检索具有挑战性,因为人们需要仅以查询图像为向导,在数以千计的候选匹配图像中进行导航。通过使用文本作为视觉查询的辅助信息,检索系统提高了可用性,但同时也面临着困难,因为视觉信号的多样性无法仅通过简短的标题来概括。因此,作为一项基于匹配的任务,跨模态文本-图像检索往往会受到文本和图像之间信息不对称的影响。为解决这一难题,我们提出了一种针对遥感图像的知识感知文本图像检索(KTIR)方法。通过从外部知识图谱中挖掘相关信息,KTIR 丰富了搜索查询中可用的文本范围,缓解了文本与图像之间的信息差距,从而实现更好的匹配。此外,通过整合特定领域的知识,KTIR 还增强了预训练视觉语言模型对遥感应用的适应性。在三个常用的遥感文本-图像检索基准上进行的实验结果表明,所提出的知识感知方法能带来多样且一致的检索结果,优于最先进的检索方法。
7.Adapting Dual-encoder Vision-language Models for Paraphrased Retrieval
标题:调整双编码器视觉语言模型,实现转述式检索
author:Jiacheng Cheng, Hijung Valentina Shin, Nuno Vasconcelos, Bryan Russell, Fabian Caba Heilbron
date Time:2024-05-06
paper pdf:http://arxiv.org/pdf/2405.03190v1
摘要:
近年来,双编码器视觉语言模型(\eg CLIP)取得了显著的文本到图像检索性能。然而,我们发现这些模型通常会导致一对解析查询的检索结果大相径庭。这种行为可能会降低检索系统的可预测性,并导致用户产生挫败感。在这项工作中,我们考虑了转述文本到图像检索的任务,其中一个模型的目标是在给出一对转述查询的情况下返回相似的结果。首先,我们收集了一个转述图像描述的数据集,以方便对这项任务进行定量评估。然后,我们假设,现有双编码器模型的不良行为是由于其文本塔造成的,而文本塔是根据图像-句子对进行训练的,缺乏捕捉转述查询之间语义相似性的能力。为了改善这一问题,我们研究了从在大型文本语料库中预先训练的语言模型开始训练双编码器模型的多种策略。与 CLIP 和 OpenCLIP 等公开的双编码器模型相比,采用我们的最佳适应策略训练的模型在保持类似的零点分类和检索准确率的同时,还能显著提高转述查询的排序相似度。
8.Research on Image Recognition Technology Based on Multimodal Deep Learning
标题:基于多模态深度学习的图像识别技术研究
author:Jinyin Wang, Xingchen Li, Yixuan Jin, Yihao Zhong, Keke Zhang, Chang Zhou
date Time:2024-05-06
paper pdf:http://arxiv.org/pdf/2405.03091v1
摘要:
本项目研究利用深度神经网络的人类多模态行为识别算法。根据不同模态信息的特点,使用不同的深度神经网络来适应不同模态的视频信息。通过对各种深度神经网络的整合,该算法成功地识别了多种模态的行为。在本项目中,使用了微软 Kinect 开发的多个摄像头,在获取常规图像的基础上收集相应的骨点数据。通过这种方式,可以提取图像中的运动特征。最终,通过这两种方法辨别出的行为特征将被综合起来,以促进行为的精确识别和分类。我们使用 MSR3D 数据集对所建议算法的性能进行了评估。实验结果表明,识别行为的准确率始终保持在较高水平,这表明该算法在各种场景下都是可靠的。此外,测试还表明,该算法大大提高了在视频片段中检测行人行为的准确性。
9.Source-Free Domain Adaptation Guided by Vision and Vision-Language Pre-Training
标题:由视觉和视觉语言预训练引导的无源领域自适应
author:Wenyu Zhang, Li Shen, Chuan-Sheng Foo
publish:Extension of ICCV paper arXiv:2212.07585, submitted to IJCV
date Time:2024-05-05
paper pdf:http://arxiv.org/pdf/2405.02954v1
摘要:
无源域适配(SFDA)旨在将在完全标记的源域上训练的源模型适配到相关但无标记的目标域上。虽然源模型是获取目标伪标签的关键途径,但生成的伪标签可能会表现出源偏差。在传统的 SFDA 管道中,一个大数据(如 ImageNet)预训练特征提取器被用于在源训练开始时初始化源模型,随后被丢弃。尽管预训练特征提取器具有对泛化非常重要的各种特征,但在源训练过程中,它可能会过度适应源数据分布,从而遗忘相关的目标领域知识。与其丢弃这些宝贵的知识,我们不如引入一个综合框架,将预训练网络纳入目标适应过程。所提出的框架非常灵活,允许我们将现代预训练网络插入适应过程,以利用其更强的表征学习能力。在适配方面,我们提出了协同学习算法(Co-learn algorithm),通过源模型和预训练特征提取器协同提高目标伪标签质量。最近,视觉语言模型 CLIP 在零镜头图像识别方面取得了成功,在此基础上,我们提出了一种扩展算法 Co-learn++,以进一步纳入 CLIP 的零镜头分类决策。我们在 3 个基准数据集上进行了评估,其中包括更具挑战性的场景,如开放集、部分集和开放部分 SFDA。实验结果表明,我们提出的策略提高了适应性能,并能与现有的 SFDA 方法成功整合。
10.ImageInWords: Unlocking Hyper-Detailed Image Descriptions
标题:ImageInWords:解锁超详细图像描述
author:Roopal Garg, Andrea Burns, Burcu Karagol Ayan, Yonatan Bitton, Ceslee Montgomery, Yasumasa Onoe, Andrew Bunner, Ranjay Krishna, Jason Baldridge, Radu Soricut
publish:Webpage (https://google.github.io/imageinwords), GitHub
(https://github.com/google/imageinwords), HuggingFace
(https://huggingface.co/datasets/google/imageinwords)
date Time:2024-05-05
paper pdf:http://arxiv.org/pdf/2405.02793v1
摘要:
尽管 "一图胜千言 "的谚语由来已久,但为训练视觉语言模型创建准确、超详细的图像描述仍然充满挑战。目前的数据集通常是网络抓取的描述,这些描述简短、颗粒度低,而且往往包含与视觉内容无关的细节。因此,在这些数据上训练出来的模型会产生大量信息缺失、视觉不一致和幻觉的描述。为了解决这些问题,我们引入了 ImageInWords (IIW),这是一个经过精心设计的人环注释框架,用于策划超详细的图像描述,以及由此产生的新数据集。我们通过对数据集质量及其微调效用的评估,验证了该框架的可读性、全面性、特异性、幻觉和人类相似性。与最近发布的数据集(+66%)和 GPT-4V 输出(+48%)相比,我们的数据集在这些方面都有明显改善。此外,在相同的人类评估维度上,使用 IIW 数据对模型进行微调的结果比之前的研究结果提高了 31%。根据微调后的模型,我们还对文本到图像生成和视觉语言推理进行了评估。根据自动和人工指标的判断,我们模型的描述可以生成最接近原图的图像。我们还发现我们的模型能生成更丰富的合成描述,在 ARO、SVO-Probes 和 Winoground 数据集上比最佳基准高出 6%。
11.Generalizing CLIP to Unseen Domain via Text-Guided Diverse Novel Feature Synthesis
标题:通过文本引导的多样化新特征合成将 CLIP 推广到未知领域
author:Siyuan Yan, Cheng Luo, Zhen Yu, Zongyuan Ge
publish:24 pages
date Time:2024-05-04
paper pdf:http://arxiv.org/pdf/2405.02586v1
摘要:
像 CLIP 这样的视觉语言基础模型已经显示出令人印象深刻的零点泛化能力,但在下游数据集上进行微调可能会导致过度拟合,并丧失对未知领域的泛化能力。虽然可以从新的感兴趣的领域收集额外的数据,但由于在获取注释数据方面存在挑战,这种方法往往不切实际。为了解决这个问题,我们提出了一种即插即用的特征增强方法,称为 LDFS(Language-Guided Diverse Feature Synthesis),用于合成新的领域特征并改进现有的 CLIP 微调策略。LDFS 有三大贡献:1) 为了合成新的领域特征并促进多样性,我们提出了一种基于文本引导特征增强损失的实例条件特征增强策略。2) 为了在增强后保持特征质量,我们引入了一个成对正则器,以保持 CLIP 特征空间内增强特征的一致性。3) 我们建议使用随机文本特征增强来缩小模态差距,进一步促进文本引导的特征合成过程。广泛的实验表明,LDFS 在提高 CLIP 在未见领域的泛化能力方面具有优势,而无需收集这些领域的数据。代码将公开发布。
12.What matters when building vision-language models?
标题:建立视觉语言模型时,什么最重要?
author:Hugo Laurençon, Léo Tronchon, Matthieu Cord, Victor Sanh
date Time:2024-05-03
paper pdf:http://arxiv.org/pdf/2405.02246v1
摘要:
随着大型语言模型和视觉转换器的改进,人们对视觉语言模型(VLM)的兴趣与日俱增。尽管有关这一主题的文献很多,但我们注意到,有关视觉语言模型设计的关键决策往往缺乏依据。我们认为,这些没有依据的决定阻碍了该领域的进步,因为我们很难确定哪些选择能提高模型性能。为了解决这个问题,我们围绕预训练模型、架构选择、数据和训练方法进行了大量实验。我们的研究成果包括 Idefics2 的开发,这是一个拥有 80 亿个参数的高效基础 VLM。在各种多模态基准测试中,Idefics2 的性能在同类规模模型中处于领先水平,通常可与四倍于其规模的模型相媲美。我们发布了该模型(基础模型、指导模型和聊天模型)以及为训练该模型而创建的数据集。
13.Learning Object States from Actions via Large Language Models
标题:通过大型语言模型从行动中学习对象状态
author:Masatoshi Tateno, Takuma Yagi, Ryosuke Furuta, Yoichi Sato
publish:19 pages of main content, 24 pages of supplementary material
date Time:2024-05-02
paper pdf:http://arxiv.org/pdf/2405.01090v1
摘要:
在视频中对物体状态进行时间定位,对于理解动作和物体之外的人类活动至关重要。由于物体状态本身的模糊性和多样性,这项任务一直缺乏训练数据。为了避免详尽的注释,从教学视频中转录的旁白中学习是很有意义的。然而,与动作相比,旁白中对物体状态的描述较少,因此效果较差。在这项工作中,我们建议使用大型语言模型(LLM)从旁白中包含的动作信息中提取对象状态信息。我们发现,大型语言模型包含了关于动作及其产生的对象状态之间关系的世界知识,并能从过去的动作序列中推断出对象状态的存在。所提出的基于 LLM 的框架具有灵活性,可以针对任意类别生成可信的伪对象状态标签。我们使用新收集的多对象状态转换(MOST)数据集对我们的方法进行了评估,该数据集包含 60 个对象状态类别的密集时间注释。我们通过生成的伪标签训练出的模型与强大的零镜头视觉语言模型相比,在 mAP 方面有了 29% 以上的显著提高,这表明了通过 LLM 从动作中明确提取物体状态信息的有效性。
14.Few Shot Class Incremental Learning using Vision-Language models
标题:利用视觉-语言模型进行少数几次类增量学习
author:Anurag Kumar, Chinmay Bharti, Saikat Dutta, Srikrishna Karanam, Biplab Banerjee
publish:under review at Pattern Recognition Letters
date Time:2024-05-02
paper pdf:http://arxiv.org/pdf/2405.01040v1
摘要:
深度学习领域的最新进展表明,在各种有监督的计算机视觉任务中,深度学习的显著性能可与人类能力相媲美。然而,在模型训练之前拥有涵盖所有类别的大量训练数据池这一普遍假设往往与现实世界中的场景不同,在现实世界中,新类别的数据可用性有限是常态。如何将样本较少的新类别无缝集成到训练数据中就成了难题,这就要求模型能够在不影响基础类别性能的前提下巧妙地适应这些新增类别。为了解决这一迫切问题,研究界在少量类增量学习(FSCIL)领域推出了几种解决方案。 在本研究中,我们介绍了一种利用语言正则和子空间正则的创新 FSCIL 框架。在基础训练过程中,语言正则器有助于纳入从视觉语言模型中提取的语义信息。在增量训练过程中,子空间正则器有助于促进模型获取基础类固有的图像和文本语义之间的细微联系。我们提出的框架不仅能让模型利用有限的数据接受新的类别,还能确保在基础类别上保持性能。为了证明我们的方法的有效性,我们在三个不同的 FSCIL 基准上进行了全面的实验,我们的框架在这些基准上取得了最先进的性能。
15.CLIPArTT: Light-weight Adaptation of CLIP to New Domains at Test Time
标题:CLIPArTT:CLIP 在测试时轻量级适应新领域
author:Gustavo Adolfo Vargas Hakim, David Osowiechi, Mehrdad Noori, Milad Cheraghalikhani, Ali Bahri, Moslem Yazdanpanah, Ismail Ben Ayed, Christian Desrosiers
date Time:2024-05-01
paper pdf:http://arxiv.org/pdf/2405.00754v1
摘要:
以 CLIP 为代表的预训练视觉语言模型(VLMs)在零镜头分类任务中表现出了显著的适应性,无需额外训练。然而,当领域发生变化时,它们的性能就会下降。在本研究中,我们介绍了 CLIP 测试时间适应(CLIPArTT),这是一种针对 CLIP 的完全测试时间适应(TTA)方法,包括在推理过程中自动构建文本提示,以用作文本监督。我们的方法采用了独特的微创文本提示调整过程,将多个预测类别汇总到一个新的文本提示中,作为伪标签,以转导方式对输入进行重新分类。此外,我们还率先在 VLM 领域实现了 TTA 基准(如 TENT)的标准化。我们的研究结果表明,不需要额外的转换或新的可训练模块,CLIPArTT 就能在 CIFAR-10 等非损坏数据集、CIFAR-10-C 和 CIFAR-10.1 等损坏数据集以及 VisDA-C 等合成数据集中动态提高性能。这项研究强调了通过新颖的测试时间策略提高 VLM 适应性的潜力,为在不同数据集和环境中实现稳健性能提供了启示。代码见: https://github.com/dosowiechi/CLIPArTT.git
相关文章:
:2024.05.01-2024.05.10)
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.05.01-2024.05.10
文章目录~ 1.Pseudo-Prompt Generating in Pre-trained Vision-Language Models for Multi-Label Medical Image Classification2.VLSM-Adapter: Finetuning Vision-Language Segmentation Efficiently with Lightweight Blocks3.Memory-Space Visual Prompting for Efficient …...
)
Python 点云生成高程模型图(DSM)
点云生成高程模型图 一、什么是DSM?二、python代码三、结果可视化一、什么是DSM? DSM(Digital Surface Model)是一种数字高程模型,通常用于描述地表地形的数字化表示。它是由一系列离散的高程数据点组成的三维地形模型,其中每个点都具有其相应的高程值。 DSM主要用于…...
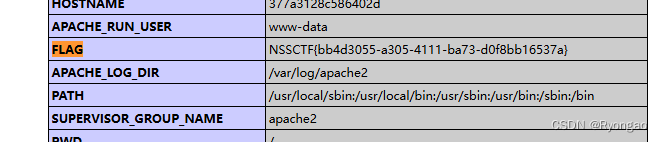
[第五空间 2021]WebFTP
题目是WebFTP 通过标签可以看出git泄露(git泄露是指开发人员利用git进行版本控制) 通过网上了解WebFTP的源码账号admin 密码admin888 进去之后正常思路是我们利用/.git 在githack里面进行复现 查看log看看有没有flag 但是经过我们查询之后不是这样子 通过一段时间摸索在phpinf…...
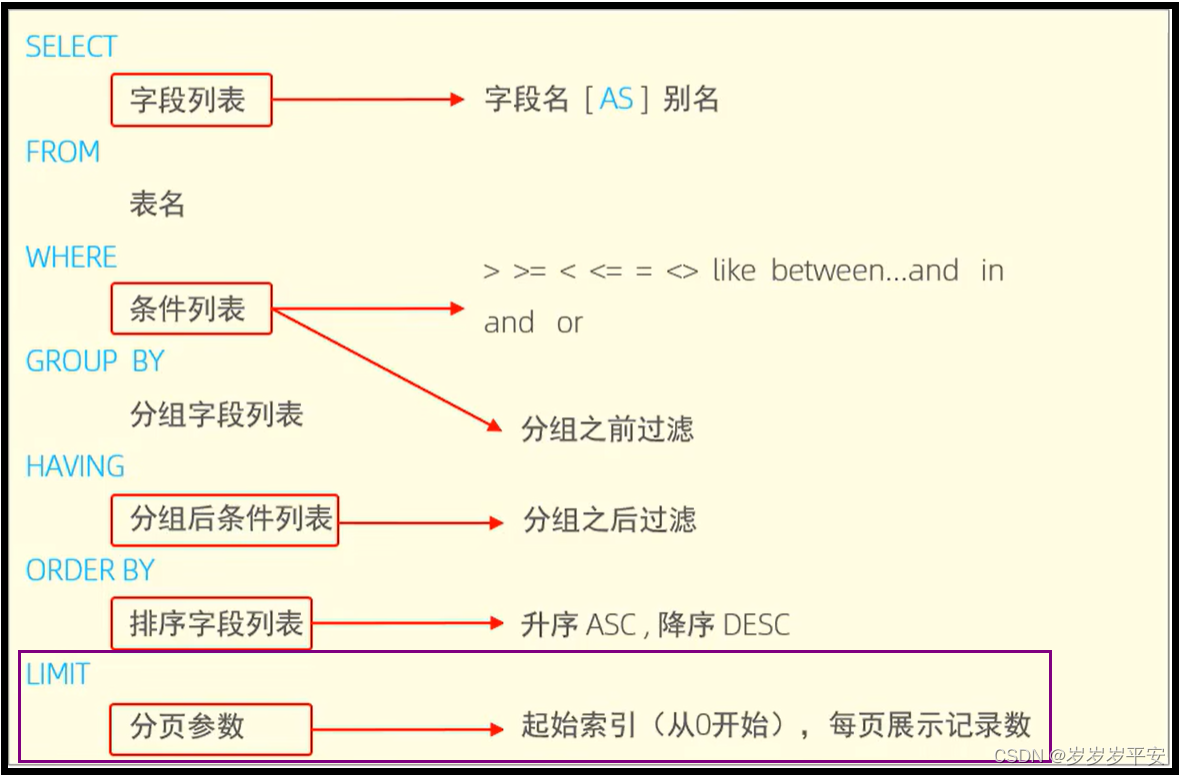
SQL—DQL(数据查询语言)之小结
一、引言 在前面我们已经学习完了所有的关于DQL(数据查询语言)的基础语法块部分,现在对DQL语句所涉及的语法,以及需要注意的事项做一个简单的总结。 二、DQL语句 1、基础查询 注意: 基础查询的语法是:SELE…...
找回xmind文件办法:一切意外均可找回(误删/重启关机等)
我周三编辑完,周四下午评审完用例忘记保存 结果到了快乐星期五,由于是周五我太开心了...早上到公司后觉得电脑卡,直接点了重启啥都没保存啊啊啊啊啊 准备上传测试用例时才想起来我的用例找不见了!!!&…...
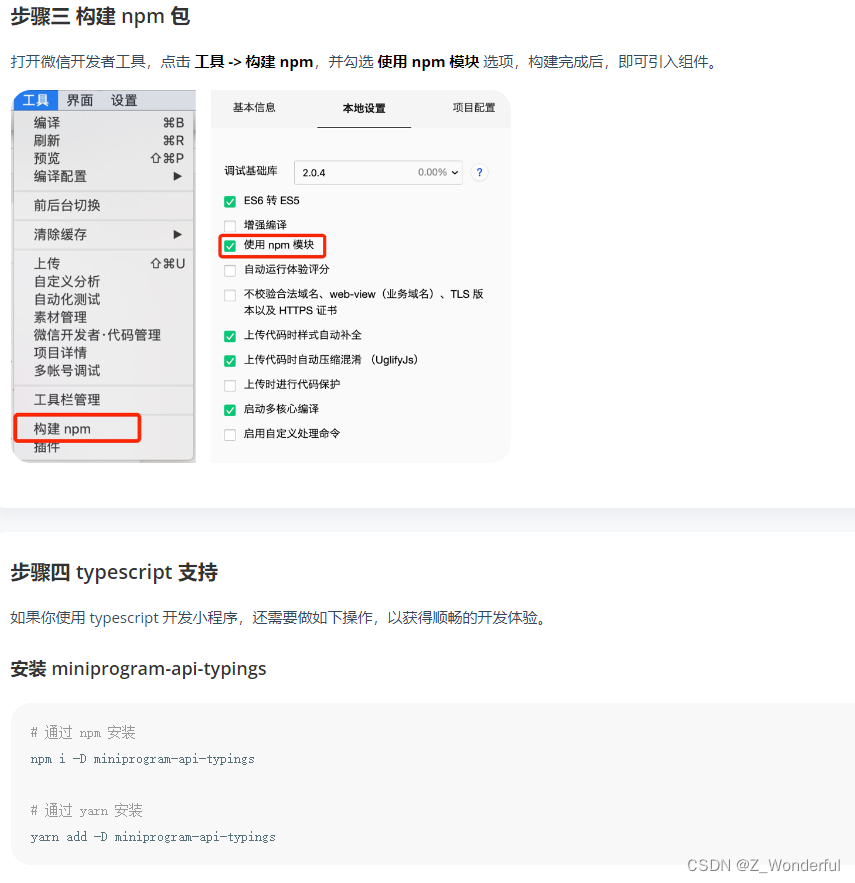
微信小程序 npm构建+vant-weaap安装
微信小程序:工具-npm构建 报错 解决: 1、新建miniprogram文件后,直接进入到miniprogram目录,再次执行下面两个命令,然后再构建npm成功 npm init -y npm install express(Node js后端Express开发ÿ…...

【LeetCode 63】 不同路径 II
1. 题目 2. 分析 这道题比较典型,跟最小路径和 是同样的思想。比较简单。 3. 代码 class Solution:def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:row len(obstacleGrid)col len(obstacleGrid[-1]) dp [[0] *(col) f…...
OpenAI助手API接入-问答对自动生成
支持GPT-3.5-Turbo, GPT-4o, GPT-4-Turbo import json import openai from pathlib import Path import os client openai.OpenAI(base_urlbase_url, api_keyapi_key) file client.files.create( fileopen("H3.pdf", "rb"), purposeassistants ) …...
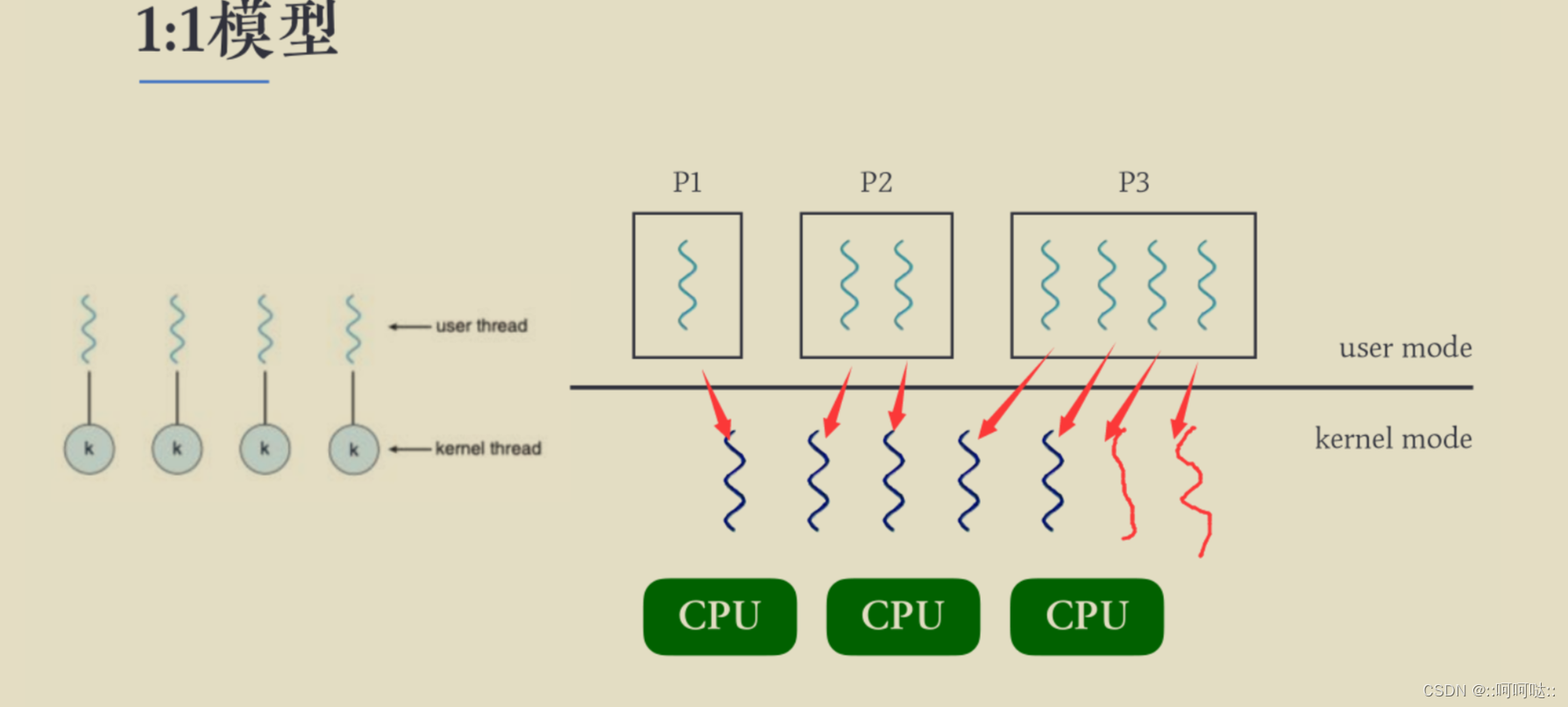
9. C++通过epoll+fork的方式实现高性能网络服务器
epollfork 实现高性能网络服务器 一般在服务器上,CPU是多核的,上述epoll实现方式只使用了其中的一个核,造成了资源的大量浪费。因此我们可以将epoll和fork结合来实现更高性能的网络服务器。 创建子进程函数–fork( ) 要了解线程我们先来了解…...

【Mac】XMind for mac(XMind思维导图)v24.04.10311软件介绍和安装教程
软件介绍 XMind for Mac是一款功能强大的思维导图软件。它具有以下主要特点: 1.多样化的思维导图功能:XMind for Mac提供了丰富的思维导图编辑功能,用户可以创建各种类型的思维导图,包括组织结构图、逻辑图、时间轴图等…...

使用 Django ORM 进行数据库操作
文章目录 创建Django项目和应用定义模型查询数据更新和删除数据总结与进阶聚合和注解跨模型查询原始SQL查询 Django是一个流行的Web应用程序框架,它提供了一个强大且易于使用的对象关系映射(ORM)工具,用于与数据库进行交互。在本文…...
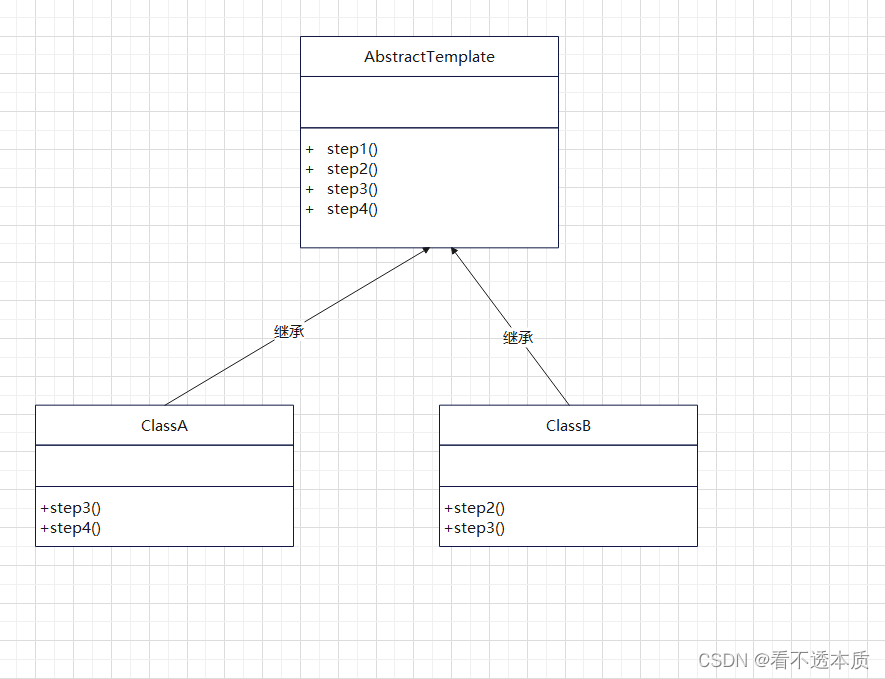
行为型设计模式之模板模式
文章目录 概述原理结构图实现 小结 概述 模板方法模式(template method pattern)原始定义是:在操作中定义算法的框架,将一些步骤推迟到子类中。模板方法让子类在不改变算法结构的情况下重新定义算法的某些步骤。 模板方法中的算法可以理解为广义上的业…...

大泽动力车载柴油发电机的特点和优势有哪些
大泽动力车载柴油发电机具有一系列显著的特点和优势,以下是对其的详细介绍: 低噪音性能:大泽动力车载柴油发电机具备明显的低噪音性能,其噪音限值在距离机组7米处测得为70dB(A),这为用户提供了一个相对安静的工作环境…...
基于 IP 的 DDOS 攻击实验
一、介绍 基于IP的分布式拒绝服务(Distributed Denial of Service, DDoS)攻击是一种利用大量受控设备(通常是僵尸网络)向目标系统发送大量请求或数据包,以耗尽目标系统的资源,导致其无法正常提供服务的攻击…...

GPT-4o如何重塑AI未来!
如何评价GPT-4o? 简介:最近,GPT-4o横空出世。对GPT-4o这一人工智能技术进行评价,包括版本间的对比分析、GPT-4o的技术能力以及个人感受等。 GPT-4o似乎是一个针对GPT-4模型进行优化的版本,它在性能、准确性、资源效率以及安全和…...

window本地域名映射修改
位置 C:\Windows\System32\drivers\etc 文件名 hosts 修改方法 复制一份到桌面 修改桌面的文件 # 前面为ip 后面为域名,域名-》ip的映射 127.0.0.1 link.com最后将修改后的文件保存,复制到C:\Windows\System32\drivers\etc替换...

【退役之重学】为什么要加入多级缓存
一、为什么 加入多级缓存是为了提高数据访问的效率和性能 二、怎么做 在多级访问系统中,数据首先会被存储在速度最快的 L1 缓存中,如果数据在 L1 缓存中未命中,则会继续在 L2 缓存 和 L3 缓存中查找,如果在所有缓存中都未命中&…...
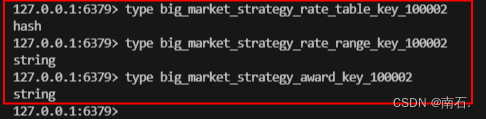
Redis常用命令大全
目录 1、五大数据类型的基本命令 1.1 字符串 1.2 列表 1.3 哈希 1.4 集合 1.5 有序集合 2、与key相关 2.1 查看redis数据的类型 2.2 查看当前redis库中的所有key命令 3、除了五大数据类型外常见命令 3.1 键操作 3.2 服务器操作 3.3 连接操作 3.4 发布/订阅 3.5 事…...

HttpSecurity 是如何组装过滤器链的
有小伙伴们问到这个问题,简单写篇文章和大伙聊一下。 一 SecurityFilterChain 首先大伙都知道,Spring Security 里边的一堆功能都是通过 Filter 来实现的,无论是认证、RememberMe Login、会话管理、CSRF 处理等等,各种功能都是通…...
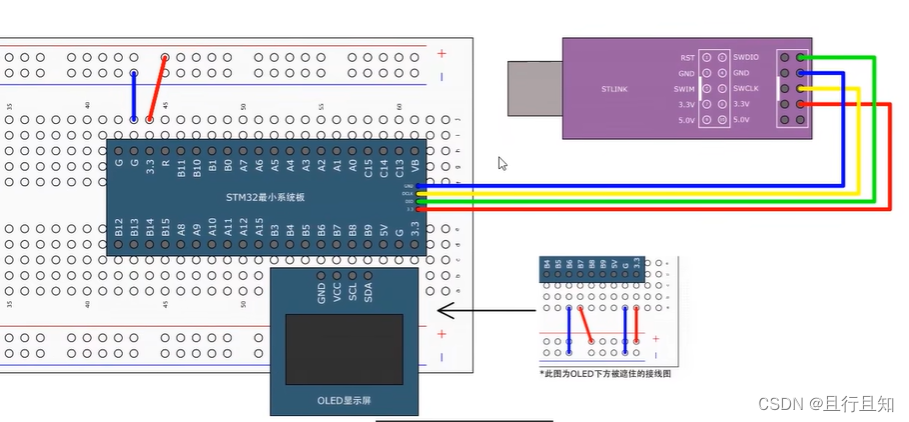
STM32 入门教程(江科大教材)#笔记2
3-4按键控制LED /** LED.c**/ #include "stm32f10x.h" // Device headervoid LED_Init(void) {/*开启时钟*/RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA, ENABLE); //开启GPIOA的时钟/*GPIO初始化*/GPIO_InitTypeDef GPIO_InitStructure;GPIO_I…...
与往返时间(RTT)出发:构建实时音视频通信的网络质量评估体系)
从抖动(Jitter)与往返时间(RTT)出发:构建实时音视频通信的网络质量评估体系
1. 实时音视频通信的网络质量挑战 当你参加视频会议时突然画面卡成PPT,或者直播连麦时对方声音忽大忽小,这些糟糕体验的背后往往是网络质量问题在作祟。实时音视频通信对网络环境极为敏感,就像在钢丝上骑自行车——任何微小的颠簸都可能导致严…...
)
NotebookLM化学辅助实战手册(附ACS期刊PDF解析模板+分子式自动标注插件)
更多请点击: https://kaifayun.com 第一章:NotebookLM化学研究辅助概述 NotebookLM 是 Google 推出的基于人工智能的文档理解与知识协作工具,专为研究者设计,支持对 PDF、TXT 等格式的科学文献进行语义索引、跨文档推理与可追溯问…...

Docker化部署KingbaseES V9:从镜像导入到开发版License激活实战
1. 为什么选择Docker部署KingbaseES V9? 在开发测试环境中,传统数据库安装方式往往需要耗费大量时间在环境配置和依赖解决上。我去年参与的一个政务云项目就遇到过这种情况:团队花了三天时间在不同操作系统的测试机上反复折腾依赖库ÿ…...

拆个汽车配件里的压电陶瓷片,用示波器和面包板实测它的‘发电’与‘震动’能力
从废弃汽车配件到电子实验神器:压电陶瓷片的深度拆解与实战应用 引言:压电陶瓷的奇妙世界 在电子爱好者的眼中,垃圾堆可能是最有趣的"宝藏库"。那些被丢弃的汽车配件、旧家电和电子设备中,往往藏着令人惊喜的元器件。其…...

高维光谱数据分析研究与光谱型纳米流式检测系统数据采集处理软件的开发与化学生物学应用【附代码】
✨ 长期致力于光谱型纳米流式检测技术、光谱解耦算法、降维算法、免疫分型、细菌自发荧光研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于泊松回归…...

CircuitFusion:多模态AI在集成电路设计中的革命性应用
1. 集成电路设计的多模态革命:CircuitFusion技术解析在AI芯片设计领域,一个令人头疼的现实是:随着芯片复杂度呈指数级增长,传统设计流程已难以应对。以7nm工艺节点为例,单个芯片可能包含数十亿个晶体管,设计…...

如何快速构建高质量双语学习材料:Lingtrain Aligner文本对齐工具完全指南
如何快速构建高质量双语学习材料:Lingtrain Aligner文本对齐工具完全指南 【免费下载链接】lingtrain-aligner Lingtrain Aligner — ML powered library for the accurate texts alignment. 项目地址: https://gitcode.com/gh_mirrors/li/lingtrain-aligner …...

2025最新 SpringCloud 教程,Seat-原理-四种事务模式,总结,笔记72,笔记73
2025最新 SpringCloud 教程,Seat-原理-四种事务模式,总结,笔记72,笔记73 一、参考资料 Seat-原理-四种事务模式 🔗 总结 🔗 二、笔记总结...

别再只用MD5了!聊聊Java中MessageDigest的SHA-256、SHA-3等算法选择与实战避坑
别再只用MD5了!Java哈希算法安全升级实战指南 哈希算法在现代应用开发中扮演着数据指纹的角色,但很多Java开发者仍然停留在MD5/SHA-1的舒适区。当数据库泄露事件频发、算力攻击成本不断降低时,选择正确的哈希算法已经不再是简单的技术选型问题…...

Windows Node.js版本管理实战:NVM-Windows配置与部署解决方案
Windows Node.js版本管理实战:NVM-Windows配置与部署解决方案 【免费下载链接】nvm-windows A node.js version management utility for Windows. Ironically written in Go. 项目地址: https://gitcode.com/gh_mirrors/nv/nvm-windows NVM-Windows是Windows…...