用户购物性别模型标签(USG)之决策树模型
一、USG模型引入:
首先了解一下,如何通过大数据来确定用户的真实性别,
经常谈论的用户精细化运营,到底是什么?
简单来讲,就是将网站的每个用户标签化,制作一个属于用户自己的网络身份证。然后,运营人员
通过身份证来确定活动的投放人群,圈定人群范围,更为精准的用户培养和管理。
当然,身份证最基本的信息就是姓名,年龄和性别,与现实不同的是,网络上用户填写的资料不一
定完全准确,还需要进行进一步的确认和评估。
确定性别这件事很重要,简单举个栗子,比如店铺想推荐新品的Bra,如果粗糙的
全部投放人群或者投放到不准确性别的人群,那后果可想而知了。
虽然能够通过用户的行为、购买和兴趣数据,了解用户的基本信息,但是仍然不清楚如何建
模?用什么语言建模?
购物性别的区分使用的是机器学习分类算法模型,但是算法也有很多分类,包含逻辑
回归,线性支持向量机,朴素贝叶斯模型和决策树,又该如何选择呢?
使用大数据 Spark MLlib 机器学习库, Java、Scala和Python 三种语言都支持。
其中,决策树的优点较多,主要是其变量处理灵活,不要求相互独立。可处理大维度的数
据,不用预先对模型的特征有所了解。对于表达复杂的非线性模式和特征的相互关系,模型相
对容易理解和解释,所以决定用决策树进行尝试。
核心难点:如何构建树,有三种方式
-
"ID3 算法:信息增益Info_Gain
-
C4.5 算法:信息增量率(比):lnfo Gain Rate
-
CART 算法:Classification And Regression Tree,基尼指数(Gini_Index)
建立在决策树算法之上: 集成融合学习算法 ,效果非常非常好的
-
GBT:梯度提升树算法,构建1棵树,迭代构建的树
-
RF:随机森林,构建N棵树,每个棵树不同,使用所有树预测,综合获取结果
USG:用户购物性别:
1.定义:通过用户购买的产品,确定用户的性别
2.思路:依据商品的名称、商品的颜色和商品的类别等,判断购买者的性别
如何确定USG?
基于用户购买商品确定性别的
用户在购物时,每个商品都有自己的属性,比如名称、颜色、类别等等,往往属于某个性别的用户
a.商品名称
剃须刀 male
口红 female
家用电器 male、female
b.商品颜色
衣服红色/亮色衣服 female
格子衫(黑灰色、杂色) male
中性颜色 male、female
c.商品类别
电子数码产品 male
美容保养 female
U_1001 product_01 male
U_1001 product_02 female
U_1001 product_03 male
U_1001 product_4 male
U_1001 product_05 female
U_1001 product_06 male
基于上面用户购买的物品,打上商品购买的性别,进行计算,最终确定用户购物性别
统计购物商品的个数
total =6
统计购物中男性商品个数
maletotal = 4
占比: maleRate = 4 /6 ≈ 0.666666666
统计购物中女性商品个数
femaletotal = 2
占比: femaleRate = 2/ 6 ≈ 0.333333333333
判断男性商品占比和女商品占比 if(maleRate >=0.6)时,USG = male if(femaleRate >=0.6)时,USG = female
else:USG = 末知
=========上述计算出用户购物性别USG,为什么还需要算法构建模型预测呢?=============
依据上述计算数据,构建分类算法模型以后,直接使用算法模型对用户进行预测即可,不需要在按照规则(经验) 进行分类操作。

业务目标: 精准投放,针对已有产品,寻找某性别偏好的精准人群进行广告投放。
技术目标:对用户购物性别识别:男性,女性,中性。
解决思路:选择一种分类算法,建立Spark模型,对模型进行应用。
线上投放:对得到的数据进行小范围内的测试投放,初期不宜过大扩大投放范围。
效果分析:对投放的用户进行数据分析,评估数据的准确性。若不够完美,则需要
重新建模和测试。
二、标签模型开发:
用户购物性别标签模型类: UsgModel ,继承基类 AbstractModel ,实现标签计算方法doTag 。
订单表:
需要将 订单商品表 中订单号 cordersn 关联到 订单表 中订单号 ordersn ,获取到对应的会员ID: memberid
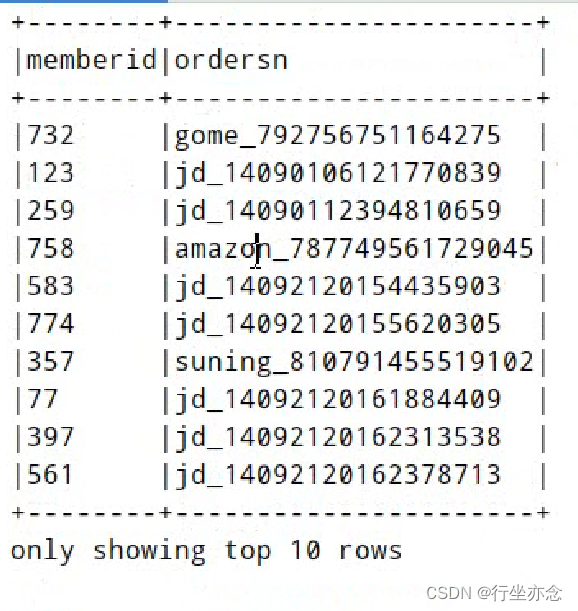
颜色维度表:

商品类别维度表:

读取订单表数据:
val session: SparkSession = businessDF.sparkSessionimport session.implicits._val ordersDF: DataFrame = spark.read.format("hbase").option("zkHosts", "bigdata-cdh01.itcast.cn").option("zkPort", "2181").option("hbaseTable", "tbl_tag_orders").option("family", "detail").option("selectFields", "memberid,ordersn").load()加载颜色维度数据并与ID进行相应的映射:
val colorsDF: DataFrame = {spark.read.format("jdbc").option("driver", "com.mysql.jdbc.Driver").option("url","jdbc:mysql://bigdata-cdh01.itcast.cn:3306/?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC").option("dbtable", "profile_tags.tbl_dim_colors").option("user", "root").option("password", "123456").load()}val colorColumn: Column = {// 声明变量var colorCol: Column = nullcolorsDF.as[(Int, String)].rdd.collectAsMap().foreach{case (colorId, colorName) =>if(null == colorCol){colorCol = when($"ogcolor".equalTo(colorName), colorId)}else{colorCol = colorCol.when($"ogcolor".equalTo(colorName), colorId)}}colorCol = colorCol.otherwise(0).as("color")// 返回colorCol}加载商品维度表数据并将其与对应ID进行映射:
val productsDF: DataFrame = {spark.read.format("jdbc").option("driver", "com.mysql.jdbc.Driver").option("url","jdbc:mysql://bigdata-cdh01.itcast.cn:3306/?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC").option("dbtable", "profile_tags.tbl_dim_products").option("user", "root").option("password", "123456").load()}var productColumn: Column = {// 声明变量var productCol: Column = nullproductsDF.as[(Int, String)].rdd.collectAsMap().foreach{case (productId, productName) =>if(null == productCol){productCol = when($"producttype".equalTo(productName), productId)}else{productCol = productCol.when($"producttype".equalTo(productName), productId)}}productCol = productCol.otherwise(0).as("product")// 返回productCol}根据运营规则标注的部分数据并关联订单数据,颜色维度和商品类别维度数据:
val labelColumn: Column = {when($"ogcolor".equalTo("樱花粉").or($"ogcolor".equalTo("白色")).or($"ogcolor".equalTo("香槟色")).or($"ogcolor".equalTo("香槟金")).or($"productType".equalTo("料理机")).or($"productType".equalTo("挂烫机")).or($"productType".equalTo("吸尘器/除螨仪")), 1) //女.otherwise(0)//男.alias("label")//决策树预测label}val goodsDF: DataFrame = businessDF// 关联订单数据:.join(ordersDF, businessDF("cordersn") === ordersDF("ordersn"))// 选择所需字段,使用when判断函数.select($"memberid".as("userId"), //colorColumn, // 颜色ColorColumnproductColumn, // 产品类别ProductColumn// 依据规则标注商品性别labelColumn)打标签,统计每个用户男女性商品个数占比:
// TODO: 直接使用标注数据,给用户打标签val predictionDF: DataFrame = goodsDF.select($"userId", $"label".as("prediction"))// 4. 按照用户ID分组,统计每个用户购物男性或女性商品个数及占比val genderDF: DataFrame = predictionDF.groupBy($"userId").agg(count($"userId").as("total"), // 某个用户购物商品总数// 判断label为0时,表示为男性商品,设置为1,使用sum函数累加sum(when($"prediction".equalTo(0), 1).otherwise(0)).as("maleTotal"),// 判断label为1时,表示为女性商品,设置为1,使用sum函数累加sum(when($"prediction".equalTo(1), 1).otherwise(0)).as("femaleTotal"))计算标签、计算占比、获取画像标签数据:
// 5.1 获取属性标签:tagRule和tagNameval rulesMap: Map[String, String] = TagTools.convertMap(tagDF)val rulesMapBroadcast: Broadcast[Map[String, String]] = session.sparkContext.broadcast(rulesMap)// 对每个用户,分别计算男性商品和女性商品占比,当占比大于等于0.6时,确定购物性别val gender_tag_udf: UserDefinedFunction = udf((total: Long, maleTotal: Long, femaleTotal: Long) => {// 计算占比val maleRate: Double = maleTotal / total.toDoubleval femaleRate: Double = femaleTotal / total.toDoubleif(maleRate >= 0.6){ // usg = 男性rulesMapBroadcast.value("0")}else if(femaleRate >= 0.6){ // usg =女性rulesMapBroadcast.value("1")}else{ // usg = 中性rulesMapBroadcast.value("-1")}})// 获取画像标签数据val modelDF: DataFrame = genderDF.select($"userId", //gender_tag_udf($"total", $"maleTotal", $"femaleTotal").as("usg"))三、ML Pipeline
在机器学习中,特别是在使用Apache Spark MLlib或Spark ML(Spark的机器学习库)时,ML Pipeline(机器学习流水线)是一个非常重要的概念。ML Pipeline提供了一种将多个机器学习步骤(如特征提取、转换、选择、模型训练和评估等)组合在一起的方式,使得数据处理和模型训练过程更加清晰、模块化和可重用。
DataFrame:数据框,一种数据结构,来源于SparkSQL中,DataFrame=Dataset[Row],存储要训练的和测试的数据集;
Transformer:转换器,一种算法Algorithm,必须实现transform方法。比如:模型 Model就是一个转换器,将输入的数据集DataFrame,转换为预测结果的数据集 DataFrame;
Estimator :估计器或者模型学习器,将数据集DataFrame转换为一个Transformer, 实现 fit() 方法,输入一个 DataFrame并产生一个 Model,即一个Transformer(转换 器);
Pipeline :管道,管道由一系列阶段组成,每个阶段都是 估计器或转换器;
Parameter :参数,无论是转换器Transformer还是模型学习器Estimator都是一个 算法,使用算法的时候必然有参数。
将USG中 构建决策树算法模型 代码修改为 训练Pipeline模型 ,整个管道Pipeline流程示意图如下:
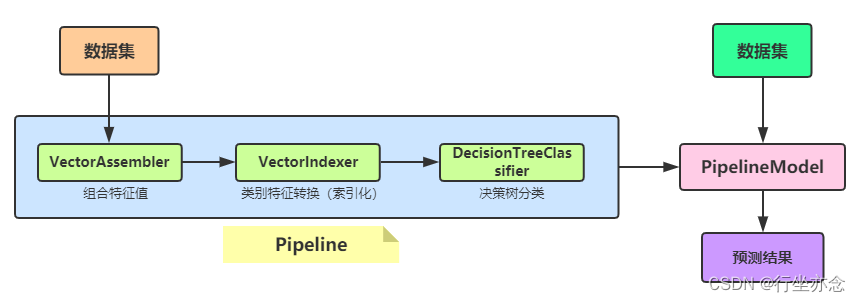
完整代码封装函数 trainPipelineModel如下:
def trainPipelineModel(dataframe: DataFrame): PipelineModel = {// 数据划分为训练数据集和测试数据集val Array(trainingDF, testingDF) = dataframe.randomSplit(Array(0.8, 0.2), seed = 123)// a. 特征向量化val assembler: VectorAssembler = new VectorAssembler().setInputCols(Array("color", "product")).setOutputCol("raw_features")// b. 类别特征进行索引val vectorIndexer: VectorIndexer = new VectorIndexer().setInputCol("raw_features").setOutputCol("features").setMaxCategories(30)// c. 构建决策树分类器val dtc: DecisionTreeClassifier = new DecisionTreeClassifier().setFeaturesCol("features").setLabelCol("label").setPredictionCol("prediction").setImpurity("gini") // 基尼系数.setMaxDepth(5) // 树的深度.setMaxBins(32) // 树的叶子数目// TODO: 构建Pipeline管道对象,组合模型学习器(算法)和转换器(模型)val pipeline: Pipeline = new Pipeline().setStages(Array(assembler, vectorIndexer, dtc))// 训练模型,使用训练数据集val pipelineModel: PipelineModel = pipeline.fit(trainingDF)// f. 模型评估val predictionDF: DataFrame = pipelineModel.transform(testingDF)predictionDF.show(100, truncate = false)println(s"accuracy = ${modelEvaluate(predictionDF, "accuracy")}")// 返回模型pipelineModel}ML Pipeline优缺点分析:
优点:
降低耦合度:将不同的处理逻辑封装成独立的阶段,每个阶段只关注自己的输入和输出,不需要知道其他阶段的细节。这使得添加、删除或修改阶段变得更加容易,且不影响整个流程的运行。
增加灵活性:通过配置化可以实现不同的业务走不同的流程,而不需要修改代码。这能够根据需求变化快速调整流程,提高开发效率和可维护性。
提高性能:可以利用多线程或异步机制来并行执行不同的阶段,从而提高整个流程的吞吐量和响应时间。
提高可读性:通过将复杂的机器学习模型分解为多个阶段,每个阶段负责特定的任务,使得整个模型的结构更加清晰,易于理解和维护。
可测试性强:由于不同的步骤之间相对独立,耦合较低,可以更方便地对每个步骤编写单元测试,从而提高代码质量。缺点:
调试困难:当流水线中的某个阶段出现问题时,可能需要逐个检查每个阶段以确定问题的根源,这可能会增加调试的复杂性和时间成本。
资源消耗:并行执行多个阶段可能会消耗更多的计算资源,包括CPU、内存和存储空间等。
配置和部署:配置和部署一个复杂的ML Pipeline可能需要一定的技术知识和经验,以确保所有组件能够正确协同工作。
注意
对管道调用 fit 方法的效果跟依次对每个评估器调用 fit 方法一样, 都是transform 输入并传递给下个步骤。 管道中最后一个评估器的所有方法,管道都有。例如,如果最后的评估器是一个分类器, Pipeline 可以当做分类器来用。如果最后一个评估器是转换器,管道也一样可以。
四、模型调优
交叉验证(Cross-Validation):
交叉验证(Cross-Validation) 是一种评估机器学习模型性能的方法,特别是当可用的训练数据较少时。这种方法通过重复使用数据来模拟训练集和测试集,从而得到模型性能的一个更可靠估计。以下是交叉验证的基本概念和一些常见的交叉验证策略:
K折交叉验证(K-Fold Cross-Validation):
- 将数据集分为K个大小相等的子集(或尽可能相等)。
- 对于每个子集,都将其视为测试集,而其余K-1个子集则作为训练集。
- 重复此过程K次,每次都使用不同的子集作为测试集。
- 最终,计算K次评估的平均值作为模型性能的估计。

五、总结:
在USG模型中,ML Pipeline(机器学习流水线)为使用决策树算法构建和评估模型提供了一个系统化的流程,确保了整个模型开发过程的一致性和可重复性。交叉验证通过将数据集划分为不同的子集,并轮流使用这些子集进行训练和测试,为模型提供了更为准确和可靠的性能评估。这有助于我们发现并避免过拟合,调整模型参数以达到最佳性能,以及在不同算法和特征集合中选择最佳模型。
相关文章:
用户购物性别模型标签(USG)之决策树模型
一、USG模型引入: 首先了解一下,如何通过大数据来确定用户的真实性别, 经常谈论的用户精细化运营,到底是什么? 简单来讲,就是将网站的每个用户标签化,制作一个属于用户自己的网络身份证。然后,运营人员 通…...

Mock的用法
1. 引入unittest包,再从包里引用mock类 import unittest from unittest import Mock 2. mock的作用,做挡板或者用来做一些单元测试过程中复杂的数据的模拟 demo Demo() #把mock的值赋值给demo的get()方法,这样在调用这个方法时࿰…...
内网-win1
一、概述 1、工作组:将不同的计算机按功能(或部门)分别列入不同的工作组 (1)、查看(windows) 查看当前系统中所有用户组:打开命令行--》net localgroup查看组中用户:打开命令行 --》net localgroup 后接组名查看用户…...
2023年09月真题C语言软件编程等级考试三级(含详细解析答案))
中国电子学会(CEIT)2023年09月真题C语言软件编程等级考试三级(含详细解析答案)
中国电子学会(CEIT)考评中心历届真题(含解析答案) C语言软件编程等级考试三级 2023年09月 编程题五道 总分:100分一、谁是你的潜在朋友(20分) "臭味相投"一这是我们描述朋友时喜欢用的词汇。两个人是朋友通常意味着他们存在着 许多共同的兴趣。然而作为…...
golang线程池ants-四种使用方法
目录 1、ants介绍 2、使用方式汇总 3、各种使用方式详解 3.1 默认池 3.2 普通模式 3.3 带参函数 3.4 多池多协程 4、总结 1、ants介绍 众所周知,goroutine相比于线程来说,更加轻量、资源占用更少、无线程上下文切换等优势,但是也不能…...

Flutter开发效率提升1000%,Flutter Quick教程之对组件进行拖拽与接收
1,首先,所有可以选择的组件,都在左边的组件面板里。从里面点击任何一个,按住左键,向右边的手机面板上进行拖拽即可。 2,拖拽后,我们要选择一个接收组件。什么时候可以接收组件,就是当…...
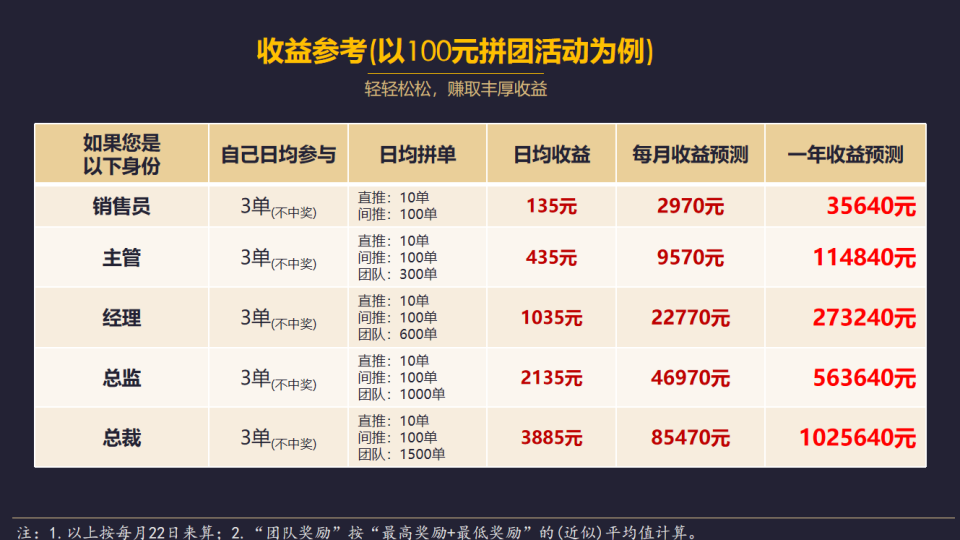
揭秘小程序商城的团购奇迹:独特模式引领盈利新纪元
在数字经济的新纪元里,你是否对那些不张扬却充满潜力的商业模式心生好奇?今天,我要为你揭示一种别出心裁的商业模式,它以其独特的魅力,不仅迅速吸引了大量用户的目光,更在短短一个月内创造了超过600万的惊人…...
ssm_mysql_高校自习室预约系统(源码)
博主介绍:✌程序员徐师兄、8年大厂程序员经历。全网粉丝15w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...

AI自动化办公:批量将Excel表格英文内容翻译为中文
有一个50列的表格,里面都是英文,要翻译成中文: 在ChatGPT中输入提示词: 你是一个开发AI大模型应用的Python编程专家,要完成以下任务的Python脚本: 打开Excel文件:"F:\AI自媒体内容\AI行业…...
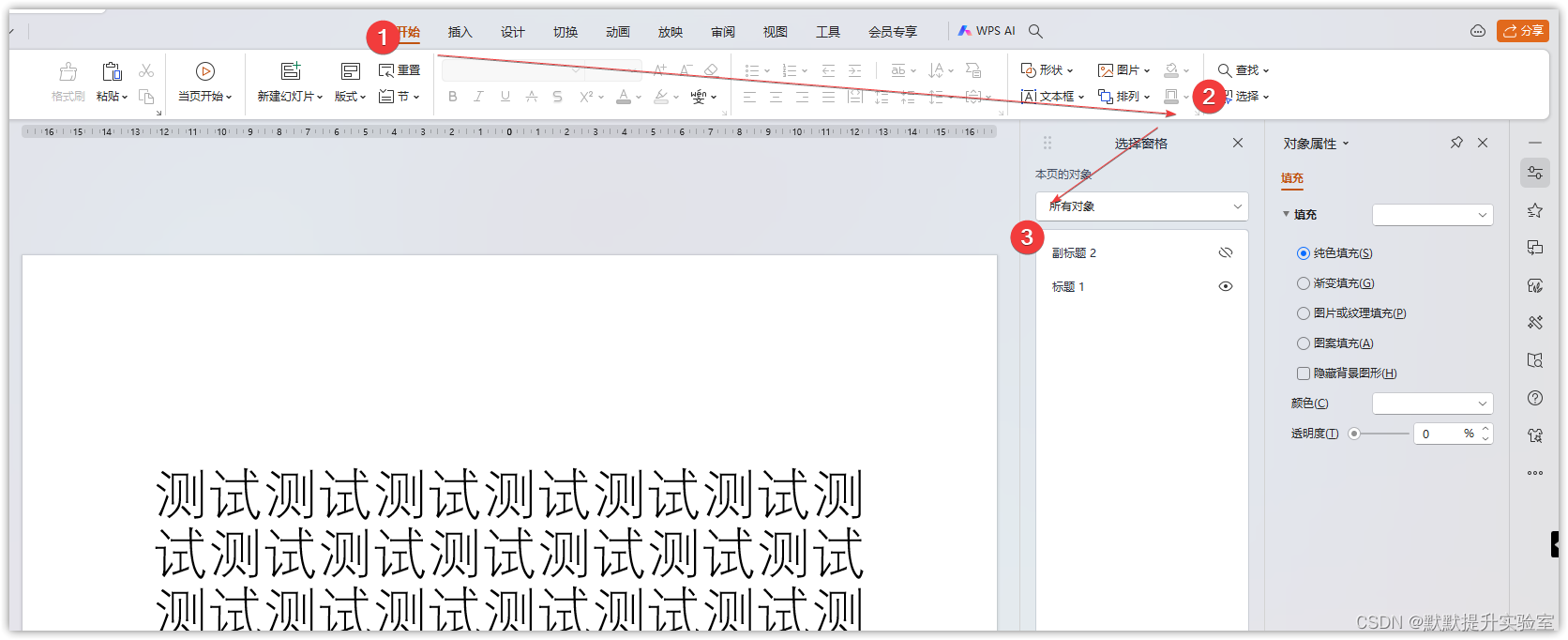
PPT 隐藏开启对象图层
目录预览 一、问题描述二、解决方案三、参考链接 一、问题描述 制作PPT的时候,有时候需要在一张PPT放置多个依次出现的内容,然后设置对应的动画,要是需要对某个内容进行修改的话,就会很不方便,这个时候就需要使用&…...
PHP火狼大灌篮游戏源码微信+手机wap源码带控制
使用此接口可以实现支付宝、QQ钱包、微信支付与财付通的即时到账,免签约,无需企业认证。PHP易支付源码,免签约不需要企业的支付平台源码,彩虹第三四方在线支付系统源码,易支付token合作者商户申请源码,app和网页都可以…...
)
推荐几首听无数遍也听不腻的好歌(1)
1.Wannabe (Spice Girls Cover) 这首歌是Why Mona创作的首红眼特效的歌,唱的像牙痛的唱不清楚,但配上超级劲爆的旋律及节奏,简直好听到爆 2.Down For Life (Reset) 这首HSHK创作的纯音乐,虽然旋律一直重复一个调,但…...
【全开源】Java短剧系统微信小程序+H5+微信公众号+APP 源码
打造属于你的精彩短视频平台 一、引言:为何选择短剧系统小程序? 在当今数字化时代,短视频已经成为人们日常生活中不可或缺的一部分。而短剧系统小程序源码,作为构建短视频平台的强大工具,为广大开发者提供了快速搭建…...
基于Springboot驾校预约平台小程序的设计与实现(源码+数据库+文档)
一.项目介绍 系统角色:管理员、教练、学员 小程序(仅限于学员注册、登录): 查看管理员发布的公告信息 查看管理员发布的驾校信息 查看所有教练信息、预约(需教练审核)、评论、收藏喜欢的教练 查看管理员发布的考试信息、预约考试(需管理…...

python列表基本运算
列表基本运算 成员运算符 in 老师你在上课喊人回答问题的时候,就犯了难。想点的人名字已经脱口而出了,但发现这位同学没来。 可不,今天的课就来了 8 个人: students [林黛玉, 薛宝钗, 贾元春, 妙玉, 贾惜春, 王熙凤, 秦可卿,…...
用法详解 | 构建多层感知机 | nn.Module的作用 | nn.Sequential的作用)
Pytorch实用教程:pytorch中nn.Linear()用法详解 | 构建多层感知机 | nn.Module的作用 | nn.Sequential的作用
文章目录 1. nn.Linear()用法构造函数参数示例使用场景2. 构建多层感知机步骤代码示例注意事项3. 继承自nn.Module的作用是什么?1. 组织网络结构2. 参数管理3. 模型保存和加载4. 设备管理不继承 `nn.Module` 的后果...

如何利用unicloud阿里云云函数实现文件包括图片或文件上传,unicloud云函数写法一览
这里以一个单文件上传为例子,多图多文件同理,循环单图处理逻辑即可。 背景 前端vue上传图片文件(base64格式)到服务器,并获取返回的服务器资源存储路径 传入参数 { ”queryStringParameters“:{ "file":&qu…...

Django序列化器中is_valid和validate
今天上班的时候分配了一个任务,是修复前端的一个提示优化,如下图所示: 按照以往的经验我以为可以直接在validate上进行校验,如何抛出一个异常即可 ,例如: class CcmSerializer(serializers.ModelSerialize…...

关于Golang中自定义包的简单使用-Go Mod
1. go env 查看 GO111MODULE 是否为 on,不是修改成on go env -w GO111MODULEon 2 .自定义包的目录格式 3. test.go 内容 package calc func Add(x, y int) int { // 首字母大写表示公有方法return x y }func Sub(x, y int) int {return x - y } 4.生成calc目…...
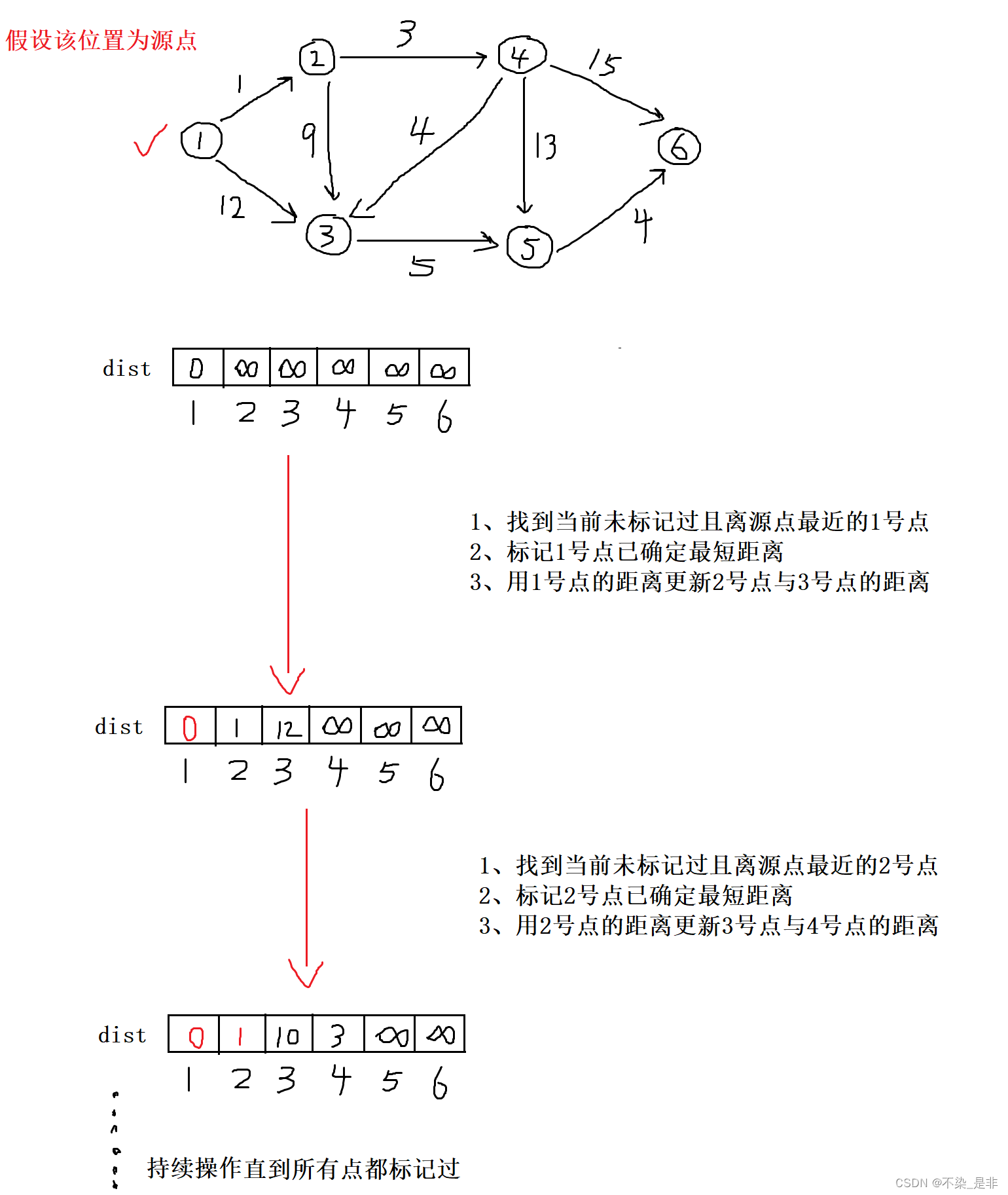
Dijkstra求最短路篇二(全网最详细讲解两种方法,适合小白)(python,其他语言也适用)
前言: Dijkstra算法博客讲解分为两篇讲解,这两篇博客对所有有难点的问题都会讲解,小白也能很好理解。看完这两篇博客后保证收获满满。 第一篇博客讲解朴素Dijkstra算法Dijkstra求最短路篇一(全网最详细讲解两种方法,适合小白)(p…...

硅基量子比特稳健控制方案解析与优化
1. 半导体自旋量子比特的稳健量子控制方案解析在硅基量子计算领域,半导体自旋量子比特因其与现有半导体工艺的兼容性和相对较长的相干时间,被视为实现大规模量子计算的有力候选者。然而,量子比特间的持续耦合(always-on couplings…...

别再傻傻分不清!RV、RVV、RVVP这些电工字母到底啥意思?一张图帮你搞定家庭布线选线
家庭电工实战指南:RV/RVV/RVVP线材选型与避坑手册 刚打开装修材料清单时,那些密密麻麻的字母组合让人瞬间头大——RV、RVV、RVVP、AVVR...这些看似天书的代号,直接决定了你家插座能否承载大功率电器、智能窗帘会不会信号中断,甚至…...

HalloWing M0开发板:从Arduino到CircuitPython的嵌入式创意实践
1. 项目概述:为什么选择HalloWing M0作为你的创意引擎如果你和我一样,喜欢捣鼓些能发光、发声甚至能感知互动的电子小玩意儿,但又对那些密密麻麻的接线和复杂的底层寄存器配置感到头疼,那么Adafruit HalloWing M0开发板很可能就是…...

终极指南:如何快速调试LZ4错误日志——结构化错误信息与调试等级详解
终极指南:如何快速调试LZ4错误日志——结构化错误信息与调试等级详解 【免费下载链接】lz4 Extremely Fast Compression algorithm 项目地址: https://gitcode.com/GitHub_Trending/lz/lz4 LZ4作为一款Extremely Fast Compression algorithm,在高…...

终极Navicat无限重置教程:3种方法解决Mac版14天试用限制
终极Navicat无限重置教程:3种方法解决Mac版14天试用限制 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 还在为Na…...

排列检验的色彩力量
原文:towardsdatascience.com/the-colorful-power-of-permutation-tests-38f0490ebfba https://github.com/OpenDocCN/towardsdatascience-blog-zh-2024/raw/master/docs/img/4ce3dd25bad50a2c1f85e5463faedb76.png 由作者创作的鸢尾花,通过 Midjourney…...

3分钟免费转换:PNG/JPG图片如何无损转为SVG矢量图?
3分钟免费转换:PNG/JPG图片如何无损转为SVG矢量图? 【免费下载链接】vectorizer Potrace based multi-colored raster to vector tracer. Inputs PNG/JPG returns SVG 项目地址: https://gitcode.com/gh_mirrors/ve/vectorizer vectorizer是一款基…...

Midjourney V6啤酒标签设计实战:3步生成高转化率精酿包装,附可复用Prompt模板
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6啤酒标签设计实战:3步生成高转化率精酿包装,附可复用Prompt模板 精准定义品牌视觉语义 Midjourney V6 对文本理解显著增强,需将抽象品牌调性转化为可解…...

Overture开源框架:快速部署生产级大语言模型API服务
1. 项目概述:一个开箱即用的开源AI应用框架最近在折腾AI应用开发的朋友,估计都绕不开一个核心问题:如何快速、稳定地把一个大语言模型(LLM)的能力,封装成一个能对外提供服务的API,并且这个服务还…...

ViT模型压缩与加速技术:边缘计算部署实践
1. ViT模型压缩与加速技术概述视觉Transformer(ViT)模型近年来在计算机视觉领域取得了突破性进展,通过将图像分割为补丁序列并应用自注意力机制,实现了超越传统卷积神经网络(CNN)的性能表现。然而ÿ…...