Streamsets-JDBC模式使用更新时间字段数据同步
StreamSets的开源地址:https://github.com/streamsets/datacollector-oss
Streamsets官网地址:https://streamsets.com/
Streamsets文档地址:https://docs.streamsets.com/portal/datacollector/3.16.x/help/index.html
我又来写Streamsets了,各种原因好久没研究Cassandra了。
本次分享主要介绍Streamsets的JDBC模式、为什么使用时间字段同步数据、遇到的问题和解决方案。
解决方案并不是最完美但也是基于当前条件下最优解,如有疑问,欢迎热烈讨论。
提供的脚本毫无保留,可直接使用。
Streamsets在3.22.2之后就闭源了,更高阶的特性已包装为平台产品。
结合周边讨论和网上的资料来看,Streamsets的活跃度不高,在网上搜的资料太少啦,又随着项目闭源,活跃度更低了,归其原因我分析Streamsets是一个大而全的数据同步工具,整合了市面上基本所有的数据源,但是每个公司不可能用到里面所有的数据源,真正能用到大部分数据源的公司,规模肯定大到不会依赖这种外部的工具,自己手写同步的自由度和效率要更好。
Streamsets对于我们的优势在于开箱即用,相比于手搓代码来实现业务细节,Streamsets将数据同步的每个阶段独立开来,将业务变动最大的数据清洗部分以处理器的形式开放出来,数据的转换和转换的实时配置并生效,直观的监控指标。
版本为Streamsets的3.16.0的离线版本,部署到内网时的最新版本为3.16.0,所以方案和问题的解决方案均以3.16.0为基础。
JDBC模式介绍:
JDBC模式的增量模式只支持新增的数据和不需要修改的数据,且官方建议的offsetColumn为PrimaryKey,如:ID。
Incremental mode
When the JDBC Query Consumer performs an incremental query, it uses the initial offset as the offset value in the first SQL query. As the origin completes processing the results of the first query, it saves the last offset value that it processes. Then it waits the specified query interval before performing a subsequent query.
When the origin performs a subsequent query, it returns data based on the last-saved offset. You can reset the origin to use the initial offset value.
Use incremental mode for append-only tables or when you do not need to capture changes to older rows. By default, JDBC Query Consumer uses incremental mode.
SELECT * FROM <table_name> WHERE <primaryKey> > ${OFFSET} ORDER BY <primaryKey>
这样支持的场景为不断的增量数据,无法捕获数据的更新。
但是正常的业务系统一般不存在只新增不更新的场景。
全量同步模式每次加载所有的数据,当表的数据量较大时,同步所需的时间和延迟不能接受。
修改为通过update_time来捕获数据变化:
SELECT * FROM user WHERE update_time > ${OFFSET} ORDER BY update_time
在配置管道时将OffsetColumn指定为update_time,业务系统使用mybatis-plus在数据新增和更新时补充创建时间和更新时间。数据库的时间精度为秒。
使用update_time的好处是对于开发者和运维人员可读性更好,在进行历史数据的同步和数据对接时更方便。
该方案看似非常合理,业务侧只要控制好update_time的逻辑,每次数据变化时update_time是不断滚动向前的,滚动查询不断的进行数据同步。
但是too young too simple。
按照Streamsets的处理逻辑,在两种场景下会丢数据。
分别是当单次同步的数据量超过maxBatchSize时,概率性丢数据和并发写入数据库时概率性丢数据。
这两种丢数据的场景是不可控的,时间不可控,完全看运气。但是不确定往往是最可怕的。
为什么会丢数据?
第一种场景:单次同步的数据量超过maxBatchSize
Offset的更新逻辑和jdbc-protolib源码中的逻辑:
origin会当根据sql查询的数据读取不超过配置的maxBatchSize的数量,并将最新的update_time赋值给offset。
// com.streamsets.pipeline.stage.origin.jdbc.JdbcSource.java
public String produce(String lastSourceOffset, int maxBatchSize, BatchMaker batchMaker) {// ...try (Connection connection = dataSource.getConnection()) {if (null == resultSet || resultSet.isClosed()) {// 执行查询sql语句resultSet = statement.executeQuery(preparedQuery);}// 超过maxBatchSize的数据不发送到下一阶段,留到下次操作时处理。while (continueReading(rowCount, batchSize) && (haveNext = resultSet.next())) {final Record record = processRow(resultSet, rowCount);if (null != record) {// 记录下数据batchMaker.addRecord(record);}// 更新offsetif (isIncrementalMode) {nextSourceOffset = resultSet.getString(offsetColumn);} else {nextSourceOffset = initialOffset;}// 后续收尾工作}}return nextSourceOffset;}
结合Streamsets的Offset的更新逻辑和jdbc-protolib源码中的逻辑,当一秒内出现多条数据时,会因为精度问题导致数据丢失。
第二种场景:数据并发写入数据库时。
业务侧代码使用mybatis-plus作为ORM来处理数据的读写,当有大数据量写入数据时,如:Excel导入或高并发的数据写入。
mybatis-plus的内置处理逻辑为分批次提交,每次提交1000,所以单个线程写入的qps为1000。
以Excel导入为例,如果批量保存方法没有加@Transaction注解,会大大增加数据丢失的概率。
原因为结合mybatis的处理+没加@Transaction注解导致1000个insert语句一次性发给数据库,这1000条sql语句是以非事务的方式执行,每条数据都是一个完整的事务,执行完毕自动提交,立即可见。
这时当Streamsets触发查询操作时,时机恰好出现在一秒内的前半段,而一秒内的后半段还在数据写入,导致后半段的数据丢失。

解决方案:
如果你拿到的是Streamsets的安装包,那第一种场景无法通过配置和升级的方式解决,因为使用的方式和增量模式的设计初衷不符。
有一份折中方案,但不保熟:
1.能力范围内update_time的精度越细越好,越细会有一定的性能损耗,但丢数据的概率大大降低。
2.评估每次同步的数据量大小,maxBatchSize的大小要大于单次同步的数据量。注意内存大小,小心OOM,(插一句:oracle的批量更新会存在连接泄露,需注意。如果有源码顺手改之。)
可以下载一份Streamsets的源码,改之。
代码如下:
// com.streamsets.pipeline.stage.origin.jdbc.JdbcSource.java
public String produce(String lastSourceOffset, int maxBatchSize, BatchMaker batchMaker) {// ...try (Connection connection = dataSource.getConnection()) {if (null == resultSet || resultSet.isClosed()) {// 执行查询sql语句resultSet = statement.executeQuery(preparedQuery);}while ((haveNext = resultSet.next())) {if(continueReading(rowCount, batchSize)){final Record record = processRow(resultSet, rowCount);if (null != record) {// 记录下数据batchMaker.addRecord(record);}// 更新offsetif (isIncrementalMode) {nextSourceOffset = resultSet.getString(offsetColumn);} else {nextSourceOffset = initialOffset;}} else {// 当超过maxBatchSize时,继续查找最后一秒的数据。if(!nextSourceOffset.equals(initialOffset) && nextSourceOffset.equals(resultSet.getString(offsetColumn))){if(null != record) batchMaker.addRecord(record);}// 后续收尾工作}}return nextSourceOffset;}
第二种场景出现的原因是在同一秒内同时出现写入和查询操作,查询时无法取出应取出的数据。
解决的思路为错峰,通过配置手段将查询动作和写入动作错开。
// oracle
select * from user where update_time < TO_TIMESTAMP('${offset}','yyyy-MM-dd HH24:mi:ss.ff') and update_time < SYSDATE - INTERVAL '1' SECOND order by update_time;
// mysql
select * from user where update_time < '${offset}' and update_time < DATE_SUB(now(), INTERVAL 1 SECOND) order by update_time;
// dm
select * from user where update_time < TO_TIMESTAMP('${offset}','yyyy-MM-dd HH24:mi:ss.ff') and update_time < CURRENT_TIMESTAMP- INTERVAL '1' SECOND order by update_time;
// kingbase
select * from user where update_time < '${offset}' and update_time < current_timestamp - INTERVAL '1' SECOND order by update_time;
需要特别注意:因为数据库中存储的时间有可能为业务服务的时间,要保证数据库和业务服务的时区和时间要保持一致。
通道示意图:
新版Streamsets的布局,我的不长这样。
源:无特殊配置
Jython处理器:根据源传过来的数据查询目标表,对数据进行标记。
流选择器:根据数据的标记分发数据,标记为insert的走新增通道,标记为update的走修改通道。
目标:一个配置为INSERT,另一个配置为UPDATE。
Jython脚本:
import java.sql.DriverManager as DriverManager
import java.lang.Class as Class
import timeurl = "jdbc:mysql://localhost:3306/db?autoReconnect=true&useSSL=false&characterEncoding=utf8"
Class.forName("com.mysql.jdbc.Driver")
username = "root"
password = "passwd"
batch_size = 1000primary_key = "id"
table_name = "t_target"
ids = []
db_ids = set()
records = sdc.records
conn = None
stmt = None
rs = None
if len(records) != 0:try:conn = DriverManager.getConnection(url,username,password)if conn is not None:stmt = conn.createStatement()start_time = time.time()for record in records:id = record.value[primary_key]ids.append(id)num_batches = len(ids) // batch_size + (1 if len(ids) % batch_size != 0 else 0)for i in range(num_batches):start_index = i * batch_sizeend_index = min((i+1) * batch_size,len(ids))batch_ids = ids[start_index,end_index]sql = "select ' + primary_key + ' from " + table_name + " where '+ primary_key +' in ('"for j,id in enumerate(batch_ids):if j != 0:sql += "','"sql += str(id)sql += "')"rs = stmt.executeQuery(sql)while rs.next():id = rs.getString(primary_key)db_ids.add(id)end_time = time.time()sdc.log.info('from '+ table_name + 'query:' + str(len(ids)) + 'rows cost:'+str(end_time - start_time) + 's')for record in records:id = record.value[primary_key]if id in db_ids:record.value['insert_or_update'] = 'update'else:record.value['insert_or_update'] = 'insert'sdc.output.write(record)except Exception as e:raise RuntimeError(e)finally:if rs:rs.close()if stmt:stmt.close()if conn:conn.close()
else:sdc.log.trace('no more data')
结语:
截止到此,也算一套完整的解决方案。拷贝之后可直接食用。
后面有时间会分享一些定位时发现的问题和小技巧。
- 国产化数据库达梦和人大金仓的适配。
- 国产化服务器加密环境的打包和部署方案。
- 为Streamsets减负,轻量化安装包。
- JDBC模式的性能优化小技巧。
- 穿插一些Streamsets组件的实现原理。
- Streamsets CDC模式的配置。
- 手写一份Streamsets的Stage,用以支撑国产化的需求
相关文章:
Streamsets-JDBC模式使用更新时间字段数据同步
StreamSets的开源地址:https://github.com/streamsets/datacollector-oss Streamsets官网地址:https://streamsets.com/ Streamsets文档地址:https://docs.streamsets.com/portal/datacollector/3.16.x/help/index.html 我又来写Streamsets了…...
Nodejs-- 网络编程
网络编程 构建tcp服务 TCP tcp全名为传输控制协议。再osi模型中属于传输层协议。 tcp是面向连接的协议,在传输之前需要形成三次握手形成会话 只有会话形成了,服务端和客户端才能想发送数据,在创建会话的过程中,服务端和客户…...
context 举例 - Form 表单)
React@16.x(14)context 举例 - Form 表单
目录 1,目标2,实现2.1,index.js2.2,context.js2.2,Form.Input2.3,Form.Button 3,使用 1,目标 上篇文章说到,context 上下文一般用于第3方组件库,因为使用场景…...

十几款基于ChatGPT的免费神器,每个都是王炸!
十几款基于ChatGPT的免费神器,每个都是王炸! 1、ChatGPT ChatGPT非常强大,但注册需要魔法和国外的手机号,大部分人都没法使用。还好有一些基于API开发的体验版,我收集了一些可以直接使用的站点分享给大家,…...

devicemotion 或者 deviceorientation在window.addEventListener 事件中不生效,没有输出内容
问题:devicemotion 或者 deviceorientation 在window.addEventListener 事件中不生效,没有输出内容 原因: 1、必须在Https协议下才可使用 2、必须用户手动点击click事件中调用 ,进行权限申请 源码: <!DOCTYPE h…...

java单元测试如何断言异常
在junit单元测试中,我们可以使用 org.junit.Assert.assertThrows 包下的 assertThrows() 方法 这个方法返回了一个泛型的异常 public static <T extends Throwable> assertThrows(Class<T> expectedType, Executable executable) 假设我们有以下…...

C语言| n的阶乘相加
逻辑性较强,建议记住。 分析思路: 假如n4:m m * i; sum sum m; 1)当i1时,m1, sum1。 2)当i2时,m12, sum112。 3)当i3时,m123, sum112123。 4)当i4时&…...

cwiseMax、cwiseMin函数
一、cwiseMax含义 cwiseMax是Eigen库中的一个函数,用于求两个矩阵或向量的逐元素最大值。它的作用类似于std::max函数,但是可以同时处理多个元素,且支持矩阵和向量。 举例: 例如,对于两个向量a和b,cwiseMax…...
【thinkphp问题栏】tp5.1重写URL,取消路径上的index.php
在Apache运行thinkphp5.1时,发现系统默认生成的.htaccess不生效。 首先先查看怎么修改伪静态 1、修改Apache的配置文件 在Apache的安装目录下,打开config/httpd.conf。 搜索rewrite.so,将前面的#删掉,表示开启URL重写功能 2、…...

缓冲字符流
BufferedReader/BufferedWriter增加了缓存机制,大大提高了读写文本文件的效率。 字符输入缓冲流 BufferedReader是针对字符输入流的缓冲流对象,提供了更方便的按行读取的方法:readLine();在使用字符流读取文本文件时,我们可以使…...
Django中使用Celery和APScheduler实现定时任务
在之前的文章我们已经学习了Celery和APScheduler的基本使用,下面让我们来了解一下如何在Django中使用Celery和APScheduler Celery 1.前提工作 python 3.7 pip install celery pip install eventlet #5.0版本以下 pip install importlib-metadata4.8.3(…...

Kivy.uix.textinput
一个小小的输入框,纵上下数页文档已不能全不概括,当去源码慢慢寻找,才知道其中作用,才能运用灵活。 Text Input — Kivy 2.3.0 documentation # -*- encoding: utf-8 -*-Text Input .. versionadded:: 1.0.4.. image:: images/te…...

基于IoTDB 平台的学习和研究
Apache IoTDB(物联网数据库)是一个针对物联网领域的高性能原生数据库,适用于数据管理和分析,并可在边缘计算和云端部署。由于它轻量级的架构、高性能和丰富的功能集,以及与Apache Hadoop、Spark和Flink的深度集成&…...

nessus plugins目录为空的问题
想要避免这种问题,可以将nessus服务设置为手动,并且先停止nessus服务。 批处理脚本: 下面的/~/Nessus/plugin_feed_info.inc替换成你配置好的 plugin_feed_info.inc 所在的路径 service nessusd stop; cp /~/Nessus/plugin_feed_info.inc …...
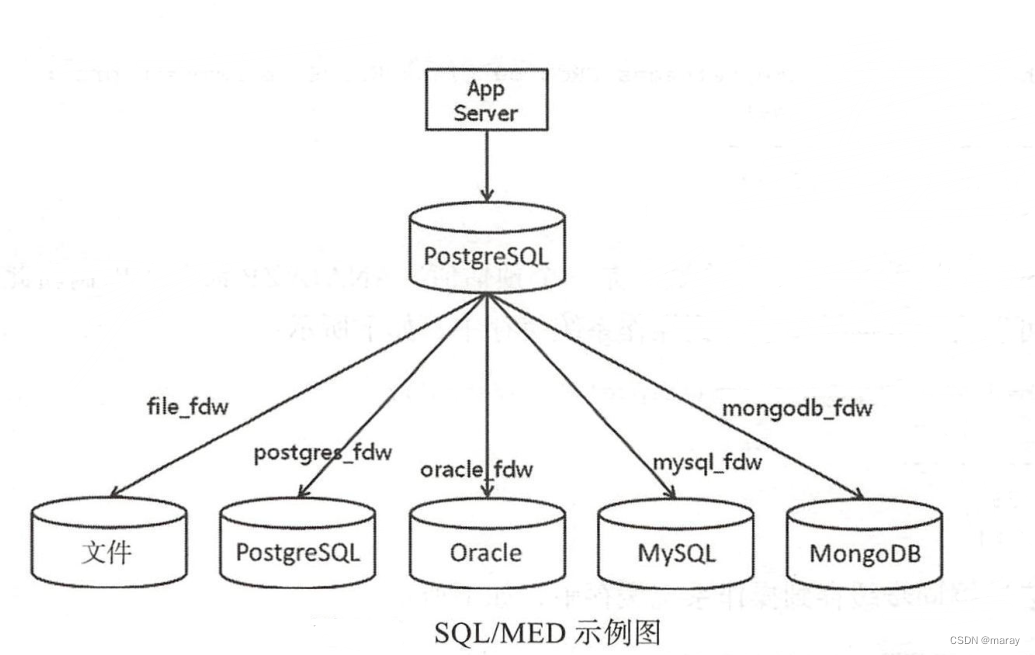
FDW(Foreign Data Wrapper)
在上一篇博客里,最末尾提到了 FDW。pg 实现了数百个 fdw 插件,用于访问外部数据。 FDW 到底是什么呢? 标准 FDW(Foreign Data Wrapper)遵循了 SQL/MED 标准,标准全称:ISO/IEC 9075-9 Managem…...

Flutter开发指南
Flutter开发指南(Android 开发角度) 与Android 的对比 1.Android 的View 与Flutter 的对应关系: a.在android 中,view 是屏幕显示的基础,比如 button,文本,列表,输入框都是 view。…...
SpringCloud学习笔记万字整理(无广版在博客)
在此感谢黑马程序员的SpringCloud课程 所有笔记、生活分享首发于个人博客 想要获得最佳的阅读体验(无广告且清爽),请访问本篇笔记 认识微服务 随着互联网行业的发展,对服务的要求也越来越高,服务架构也从单体架构逐渐…...
c++(七)
c(七) 内联函数内联函数的特点为什么要有内联函数内联函数是如何工作的呢 类型转换异常处理智能指针单例模式懒汉模式饿汉模式 VS中数据库的相关配置 内联函数 修饰类的成员函数,关键字:inline inline 返回值类型 函数名(参数列…...

SQL语言
SQL语言 导航 文章目录 SQL语言导航一、SQL概述SQL 二、数据库定义SQL 数据类型 三、数据操作视图更新 四、SQL的授权五、存储过程六、嵌入式SQL主语言与数据库通信 七、动态SQL 一、SQL概述 SQL 支持三级模式结构 视图->外模式 基本表->模式 存储文件->内模式 二…...

【PPT】修改新建文本框默认字体
【PPT】修改新建文本框默认字体...

TortoiseGit重置与还原功能详解:除了‘后悔药’,还能当‘时光机’和‘后悔药解药’?
TortoiseGit重置与还原功能深度解析:从版本控制到历史重构的艺术 在代码开发的漫长旅途中,每个开发者都曾有过"如果当时..."的瞬间。与大多数版本控制系统不同,Git提供的不仅是一个简单的"撤销"按钮,而是一套…...

MASA全家桶汉化包:三步搞定Minecraft模组界面中文化的终极指南
MASA全家桶汉化包:三步搞定Minecraft模组界面中文化的终极指南 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为Masa Mods复杂的英文界面而烦恼吗?MASA全家…...

基于小波变换与渐进式特征金字塔网络的高效目标检测方法 —— 以电网巡检为例
点击蓝字关注我们关注并星标从此不迷路计算机视觉研究院公众号ID|计算机视觉研究院学习群|扫码在主页获取加入方式https://pmc.ncbi.nlm.nih.gov/articles/PMC12923819/pdf/41598_2026_Article_37017.pdf计算机视觉研究院专栏Column of Computer Vision …...

当AI开始检测自身缺陷:测试工具失控的风险与应对
在软件测试领域,AI正从辅助工具向核心角色转变。2026年的测试场景中,AI不仅能自动生成测试用例、自我修复失效选择器,还能以人眼精度完成视觉回归检测。这些能力让测试工程师从繁琐的重复劳动中解放出来,将精力聚焦于业务逻辑与边…...

百度网盘SVIP破解插件:macOS用户突破下载限速的终极指南
百度网盘SVIP破解插件:macOS用户突破下载限速的终极指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 百度网盘SVIP破解插件(…...
别再只调XGBoost参数了!试试阿里PAI这篇AAAI 2024新作AMFormer,用Transformer做表格数据效果真香
突破表格数据建模瓶颈:AMFormer如何用算术特征交互重塑深度学习方法 在金融风控、医疗诊断和推荐系统等实际业务场景中,结构化表格数据始终占据着核心地位。传统树模型如XGBoost和LightGBM凭借对特征缺失和噪声的鲁棒性,长期统治着这一领域。…...

5分钟掌握:如何在Blender中快速安装和使用VRM插件终极指南
5分钟掌握:如何在Blender中快速安装和使用VRM插件终极指南 【免费下载链接】VRM-Addon-for-Blender VRM Importer, Exporter and Utilities for Blender 2.93 to 5.1 项目地址: https://gitcode.com/gh_mirrors/vr/VRM-Addon-for-Blender 想在Blender中轻松处…...

Unity游戏接入TapTap登录,从后台配置到打包上线的完整避坑指南
Unity游戏接入TapTap登录的全流程避坑指南:从配置到上线的实战经验 在独立游戏开发领域,TapTap平台凭借其庞大的用户基础和便捷的登录系统,已成为许多开发者的首选接入方案。然而,从后台配置到最终打包上线的完整流程中࿰…...

从零到一:基于HappyBase的HBase Python应用实战指南
1. 环境准备与基础配置 第一次接触HBase和HappyBase时,环境配置往往是最让人头疼的部分。记得我刚开始搭建环境时,花了整整两天时间才把所有服务调通。为了让各位少走弯路,我把这些年积累的经验都整理在这里。 首先需要明确的是,…...

如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南
如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tre…...