什么时候需要分表分库?
在当今互联网时代,海量数据基本上是每一个成熟产品的共性,特别是在移动互联网产品中,几乎每天都在产生数据,例如,商城的订单表、支付系统的交易明细以及游戏中的战报等等。
对于一个日活用户在百万数量级的商城来说,每天产生的订单数量可能在百万级,特别在一些活动促销期间,甚至上千万。
假设我们基于单表来实现,每天产生上百万的数据量,不到一个月的时间就要承受上亿的数据,这时单表的性能将会严重下降。因为MySQL在InnoDB存储引擎下创建的索引都是基于B+树实现的,所以查询时的I/O次数很大程度取决于树的高度,随着B+树的树高增高,I/O次数增加,查询性能也就越差。
当我们面对一张海量数据的表时,通常有分区、NoSQL存储、分表分库等优化方案。
一 、什么时候要分表分库?
在我看来,能不分表分库就不要分表分库。在单表的情况下,当业务正常时,我们使用单表即可,而当业务出现了性能瓶颈时,我们首先考虑用分区的方式来优化,如果分区优化之后仍然存在后遗症,此时我们再来考虑分表分库。
我们知道,如果在单表单库的情况下,当数据库表的数据量逐渐累积到一定的数量时(5000W行或100G以上),操作数据库的性能会出现明显下降,即使我们使用索引优化或读写库分离,性能依然存在瓶颈。此时,如果每日数据增长量非常大,我们就应该考虑分表,避免单表数据量过大,造成数据库操作性能下降。
二 、如何分表分库?
通常,分表分库分为垂直切分和水平切分两种。
垂直分库是指根据业务来分库,不同的业务使用不同的数据库。例如,订单和消费券在抢购业务中都存在着高并发,如果同时使用一个库,会占用一定的连接数,所以我们可以将数据库分为订单库和促销活动库。
而垂直分表则是指根据一张表中的字段,将一张表划分为两张表,其规则就是将一些不经常使用的字段拆分到另一张表中。例如,一张订单详情表有一百多个字段,显然这张表的字段太多了,一方面不方便我们开发维护,另一方面还可能引起跨页问题。这时我们就可以拆分该表字段,解决上述两个问题。
水平分表则是将表中的某一列作为切分的条件,按照某种规则(Range或Hash取模)来切分为更小的表。
水平分表只是在一个库中,如果存在连接数、I/O读写以及网络吞吐等瓶颈,我们就需要考虑将水平切换的表分布到不同机器的库中,这就是水平分库分表了。
三、 分表分库之后面临的问题
然而,分表分库虽然存在着各种各样的问题,但在一些海量数据、高并发的业务中,分表分库仍是最常用的优化手段。所以,我们应该充分考虑分表分库操作后所面临的一些问题,接下我们就一起看看都有哪些应对之策。
为了更容易理解这些问题,我们将对一个订单表进行分库分表,通过详细的业务来分析这些问题。
假设我们有一张订单表以及一张订单详情表,每天的数据增长量在60W单,平时还会有一些促销类活动,订单增长量在千万单。为了提高系统的并发能力,我们考虑将订单表和订单详情表做分库分表。除了分表,因为用户一般查询的是最近的订单信息,所以热点数据比较集中,我们还可以考虑用表分区来优化单表查询。
通常订单的分库分表要么基于订单号Hash取模实现,要么根据用户 ID Hash 取模实现。订单号Hash取模的好处是数据能均匀分布到各个表中,而缺陷则是一个用户查询所有订单时,需要去多个表中查询。
由于订单表用户查询比较多,此时我们应该考虑使用用户ID字段做Hash取模,对订单表进行水平分表。如果需要考虑高并发时的订单处理能力,我们可以考虑基于用户ID字段Hash取模实现分库分表。这也是大部分公司对订单表分库分表的处理方式。
1.分布式事务问题
在提交订单时,除了创建订单之外,我们还需要扣除相应的库存。而订单表和库存表由于垂直分库,位于不同的库中,这时我们需要通过分布式事务来保证提交订单时的事务完整性。
通常,我们解决分布式事务有两种通用的方式:两阶事务提交(2PC)以及补偿事务提交(TCC)。有关分布式事务的内容,我将在后面的讲解中详细介绍。
2.跨节点JOIN查询问题
用户在查询订单时,我们往往需要通过表连接获取到商品信息,而商品信息表可能在另外一个库中,这就涉及到了跨库JOIN查询。
通常,我们会冗余表或冗余字段来优化跨库JOIN查询。对于一些基础表,例如商品信息表,我们可以在每一个订单分库中复制一张基础表,避免跨库JOIN查询。而对于一两个字段的查询,我们也可以将少量字段冗余在表中,从而避免JOIN查询,也就避免了跨库JOIN查询。
3.跨节点分页查询问题
我们知道,当用户在订单列表中查询所有订单时,可以通过用户ID的Hash值来快速查询到订单信息,而运营人员在后台对订单表进行查询时,则是通过订单付款时间来进行查询的,这些数据都分布在不同的库以及表中,此时就存在一个跨节点分页查询的问题了。
通常一些中间件是通过在每个表中先查询出一定的数据,然后在缓存中排序后,获取到对应的分页数据。这种方式在越往后面的查询,就越消耗性能。
4.全局主键ID问题
在分库分表后,主键将无法使用自增长来实现了,在不同的表中我们需要统一全局主键ID。因此,我们需要单独设计全局主键,避免不同表和库中的主键重复问题。
使用UUID实现全局ID是最方便快捷的方式,即随机生成一个32位16进制数字,这种方式可以保证一个UUID的唯一性,水平扩展能力以及性能都比较高。但使用UUID最大的缺陷就是,它是一个比较长的字符串,连续性差,如果作为主键使用,性能相对来说会比较差。
我们也可以基于Redis分布式锁实现一个递增的主键ID,这种方式可以保证主键是一个整数且有一定的连续性,但分布式锁存在一定的性能消耗。
我们还可以基于Twitter开源的分布式ID生产算法——snowflake解决全局主键ID问题,snowflake是通过分别截取时间、机器标识、顺序计数的位数组成一个long类型的主键ID。这种算法可以满足每秒上万个全局ID生成,不仅性能好,而且低延时。
5.扩容问题
随着用户的订单量增加,根据用户 ID Hash 取模的分表中,数据量也在逐渐累积。此时,我们需要考虑动态增加表,一旦动态增加表了,就会涉及到数据迁移问题。
我们在最开始设计表数据量时,尽量使用2的倍数来设置表数量。当我们需要扩容时,也同样按照2的倍数来扩容,这种方式可以减少数据的迁移量。
四、总结
在业务开发之前,我们首先要根据自己的业务需求来设计表。考虑到一开始的业务发展比较平缓,且开发周期比较短,因此在开发时间比较紧的情况下,我们尽量不要考虑分表分库。但是我们可以将分表分库的业务接口预留,提前考虑后期分表分库的切分规则,把该冗余的字段提前冗余出来,避免后期分表分库的JOIN查询等。
当业务发展比较迅速的时候,我们就要评估分表分库的必要性了。一旦需要分表分库,就要结合业务提前规划切分规则,尽量避免消耗性能的跨表跨库JOIN查询、分页查询以及跨库事务等操作。
相关文章:

什么时候需要分表分库?
在当今互联网时代,海量数据基本上是每一个成熟产品的共性,特别是在移动互联网产品中,几乎每天都在产生数据,例如,商城的订单表、支付系统的交易明细以及游戏中的战报等等。对于一个日活用户在百万数量级的商城来说&…...
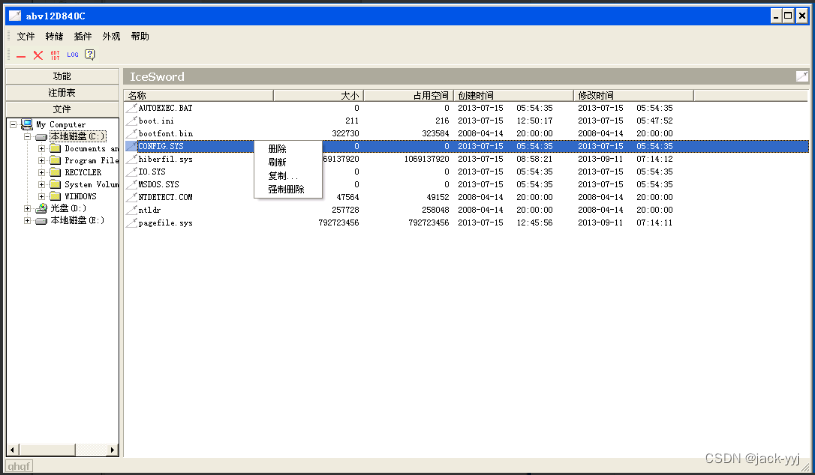
冰刃杀毒工具使用实验(29)
实验目的 (1)学习冰刃的基本功能; (2)掌握冰刃的基本使用方法;预备知识 windows操作系统的基本知识,例如:进程、网络、服务和文件等的了解。 冰刃是一款广受好评的ARK工…...
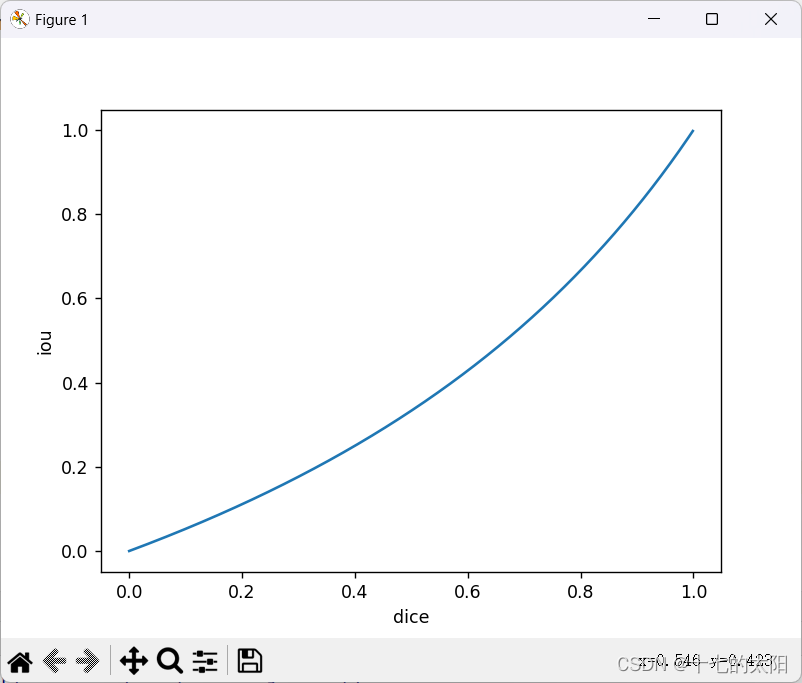
聊聊图像分割的DICE和IOU指标
目录 1. 介绍 2. dice 和 iou 的联系 3. 代码实现 3.1 dice 3.2 iou 3.3 test 3.4 dice 和 iou 的关系曲线 4. 代码 1. 介绍 dice 和 iou 都是衡量两个集合之间相似性的度量 dice计算公式: iou计算公式: iou的集合理解: iou 其实就…...

软件设计师教程(十)计算机系统知识-结构化开发
软件设计师教程 软件设计师教程(一)计算机系统知识-计算机系统基础知识 软件设计师教程(二)计算机系统知识-计算机体系结构 软件设计师教程(三)计算机系统知识-计算机体系结构 软件设计师教程(…...
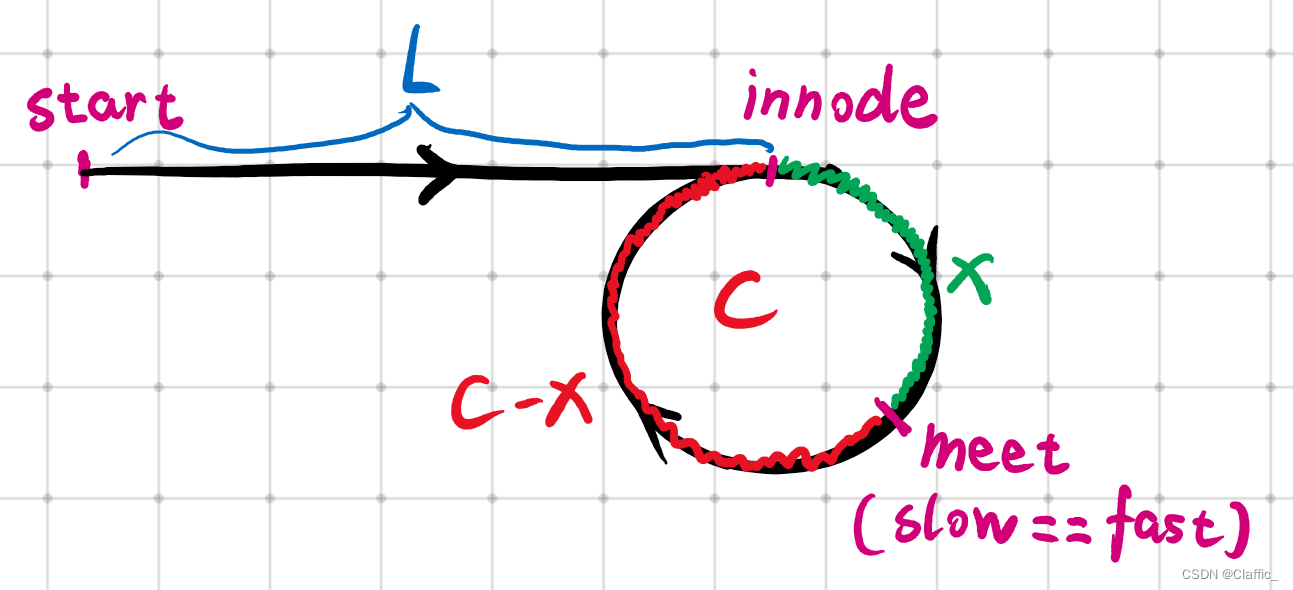
链表OJ之 快慢指针法总结
欢迎来到 Claffic 的博客 💞💞💞 前言: 快慢指针指的是每次指针移动的步长,是解决链表相关的题目的一大利器,下面我将以例题的形式讲解快慢指针法。 目录 一. 链表的中间结点 思路: 代码实…...

C++STL详解(五)——list的介绍与使用
文章目录list的介绍list的使用list的定义方法list迭代器失效问题list插入和删除inserteraselist迭代器的使用begin,end 和 rbegin,rendlist元素访问front 和 backlist容量控制与数据清理resizeclearlist操作函数spliceremove 和 remove_ifuniquemergerev…...
进程和进程的调度
今天,为大家带来进程和进程的调度的学习 1.认识计算机 2.什么是操作系统 3.什么是进程 4.进程管理 5.进程的属性 6.进程的调度 7.进程调度的过程 8.内存分配 1.认识计算机 计算机的组成有五大部分 1.CPU(是计算机的大脑,负责逻辑运算和控制) 2.内存 3.外存 4.输入…...
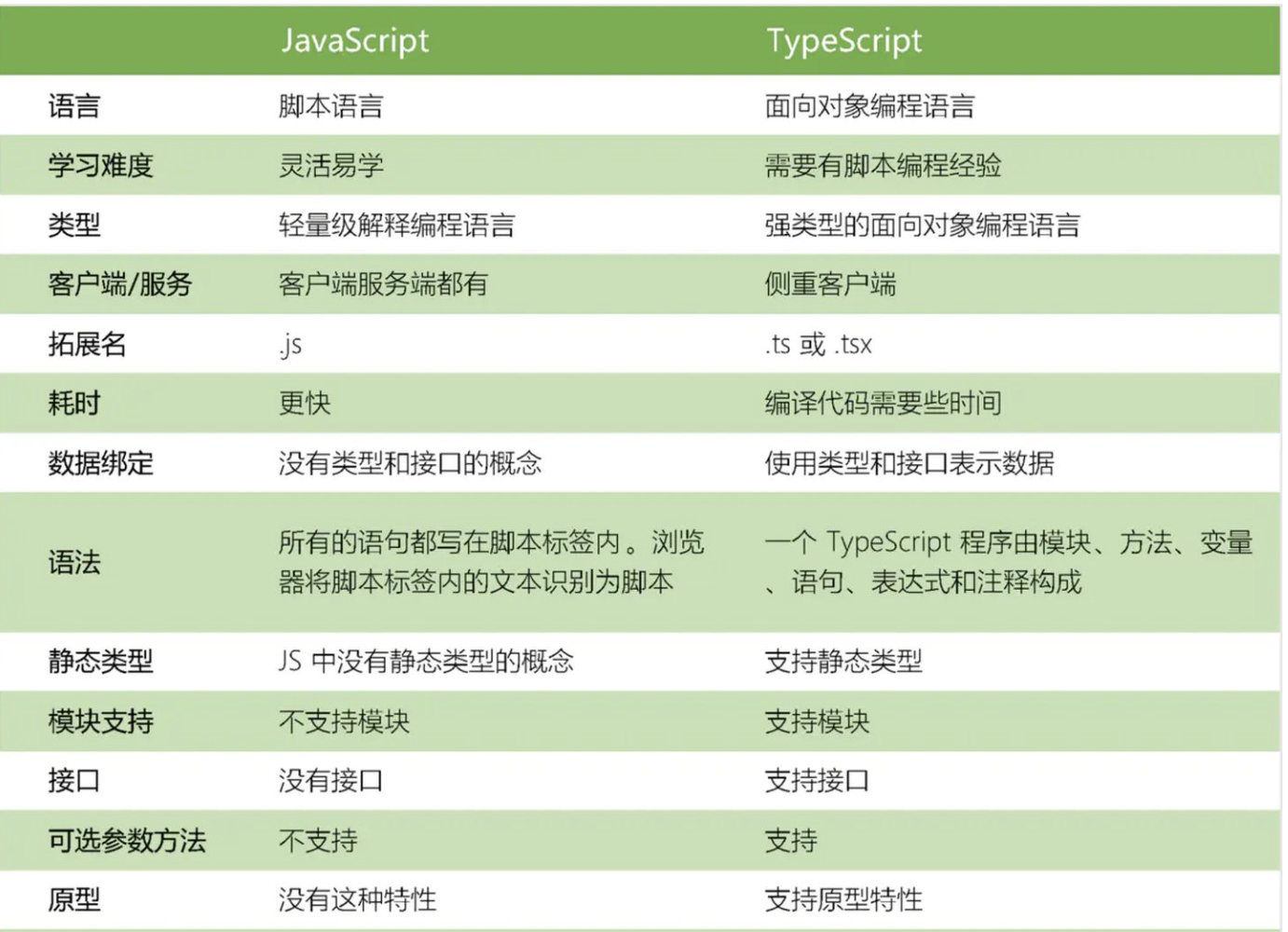
TypeScript 深度剖析:TypeScript 的理解?与 JavaScript 的区别?
一、是什么 TypeScript 是 JavaScript 的类型的超集,支持ES6语法,支持面向对象编程的概念,如类、接口、继承、泛型等 超集,不得不说另外一个概念,子集,怎么理解这两个呢,举个例子,如…...

美颜SDK关键技术讲解——人脸识别与人脸美化
拍摄,自从智能手机普及之后就已经不再是小众爱好,使用手机拍摄记录生活几乎成了人们的日常。在巨量的需求下,美颜工具、美颜SDK已经被广泛应用于各大视频拍摄平台。虽然经常听到美颜SDK,但是大多数人并不了解它,下文小…...
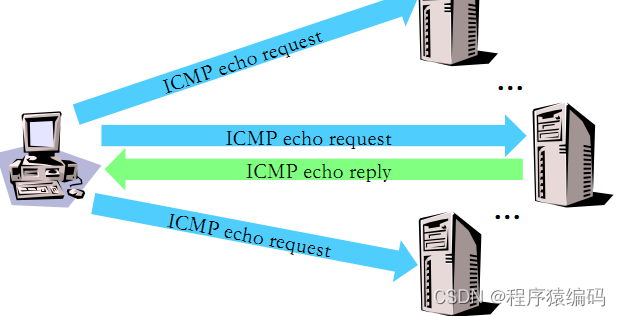
Linux下C/C++ 网络扫描(主机扫描技术)
主机扫描是网络扫描的基础,通过对目标网络中主机IP地址的扫描,从一堆主机中扫描出存活的主机,然后以他们为目标进行后续的攻击。一般会借助于ICMP、TCP、UDP等协议的工作机制,检查打开的进程,开放的端口号等等。 主机…...

无法将“vue-cli-service”项识别为 cmdlet、函数、脚本文件或不是内部命令的原因和解决方案
经常有小伙伴问我说,为什么我们在开发vue项目的时候,需要在package.json的script对象中,去设置命令启动项目,而不是直接的通过"vue-cli-service serve"命令去把项目跑起来。带着这些疑问,小生在此总结了以下…...

逆流程 场景下 处理状态机变化的方案
背景: 针对某些业务场景下,存在逆流程。 比如场景的场景 正向流程如,发起某项申请->对某项申请进行审批。(审批为通过/驳回)。这样这个工作流程就算到最终态。 常见的状态机如, 申请未提交࿰…...

【剧前爆米花--爪哇岛寻宝】Java实现无头单向非循环链表和无头双向链表与相关题目
作者:困了电视剧 专栏:《数据结构--Java》 文章分布:这是关于数据结构链表的文章,包含了自己的无头单向非循环链表和无头双向链表实现简单实现,和相关题目,想对你有所帮助。 目录 无头单向非循环链表实现 …...
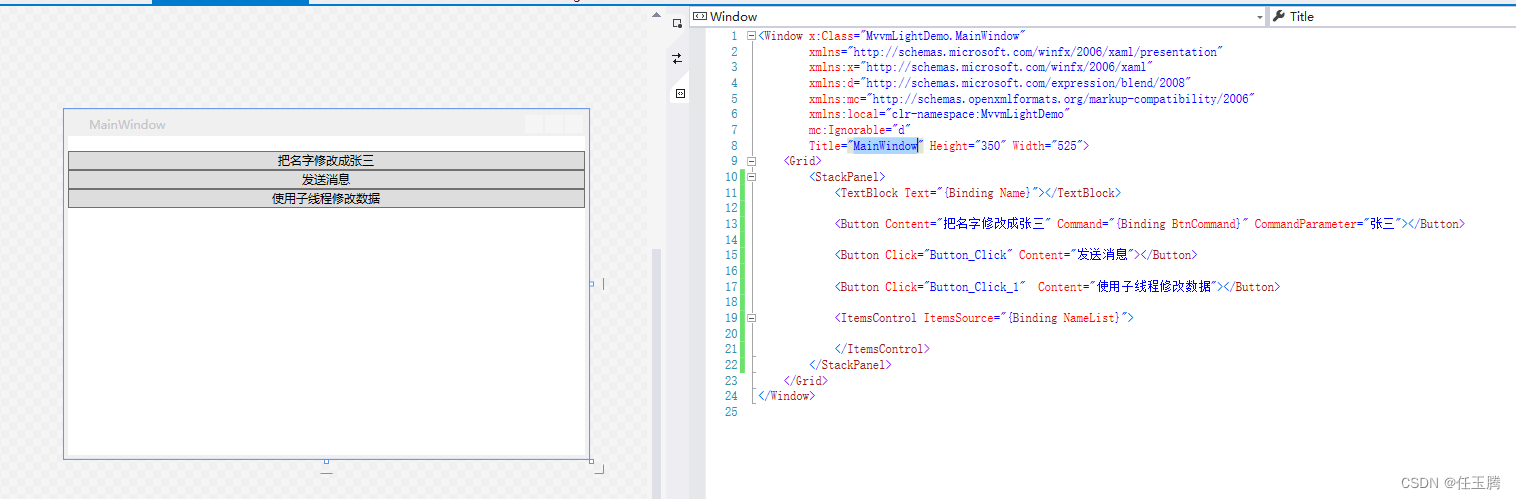
学习MvvmLight工具
最近学习了一下MvvmLight,觉得有些功能还是挺有特色的,所以记录一下 首先新建也给WPF程序 然后在Nuget里面安装MvvmLightLib 包,安装上面那个也可以,但是安装上面那个会自动在代码里面添加一些MvvmLight的demo ,安装M…...

基于BiLSTM+CRF医学病例命名实体识别项目
研究背景 为通过项目实战增加对命名实体识别的认识,本文找到中科院软件所刘焕勇老师在github上的开源项目,中文电子病例命名实体识别项目MedicalNamedEntityRecognition。对其进行详细解读。 原项目地址:https://github.com/liuhuanyong/Med…...

05 C语言数据类型
05 C语言数据类型 1、数据类型 编程语言对数据类型分为两派:一种认为要注重,一种认为可以忽视。 C语言类型 1、整数 : char < short < int < long < long long ,bool 2、浮点数:float < double < long doub…...

C++11:右值引用和移动语义
文章目录1. 左值和右值表达式1.1 概念1.2 左值和右值2. 左值引用和右值引用2.1 相互引用2.2 示例代码2.3 左值引用使用场景缺点2.4 右值引用和移动语义小结2.5 移动赋值2.6 右值引用的其他使用场景右值引用版本的插入函数3. 完美转发3.1 万能引用3.2 如何实现完美转发3.3 完美转…...

tcpdump网络抓包工具
tcpdump 是一个强大的网络抓包工具,在分析服务之间调用时非常有用。可以将网络中传送的数据包抓取下来进行分析。tcpdump 提供灵活的抓取策略,支持针对网络层、协议、主机、网络或端口的过滤,并提供 and、or、not 等逻辑语句来去掉不想要的信…...

MaxCompute SQL中的所有保留字与关键字如下
– MaxCompute SQL中的所有保留字与关键字如下 注意 命名表、列或分区时,不要使用保留字与关键字,否则可能会报错。 保留字不区分大小写。 在对表、列或是分区命名时如若使用关键字,需给关键字加符号进行转义,否则会报错。 % &am…...
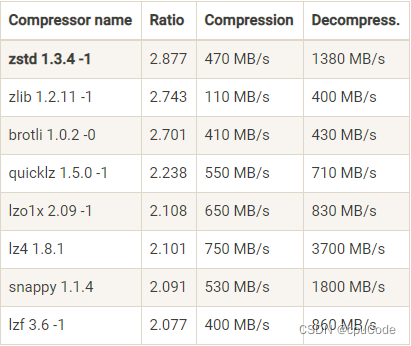
Kafka 压缩算法
压缩 (compression) : 用时间换空间的思想 用较小的 CPU 开销获得磁盘少占用或网络 I/O 少传输 Kafka 消息分两层: 消息日志组成 : n 个消息集合消息集合 (message set) 组成 : n 条日志项 (record item)日志项封装了消息 (message)Kafka 在消息集合层上进行写入…...
操作系统)
Linux(9)操作系统
linux 之 操作系统冯若依曼体系体系结构理解数据流动操作系统什么是操作系统??理解操作系统的调用系统调用的接口:冯若依曼体系 体系结构 要理解进程首先就需要了解操作系统!!! 五大组件: ○…...

关于【进程池阻塞 + 子进程未回收问题】
续接上文:进程间通信(二):实现一个高可用的进程池-CSDN博客 目录 一、先看现象:两个核心问题 二、核心原因:文件描述符泄漏(管道读端没关干净) 1. 管道的核心规则回顾 2. 后果&a…...

数字记忆策展:WeChatMsg与数据主权时代的个人记忆管理
数字记忆策展:WeChatMsg与数据主权时代的个人记忆管理 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

跨设备滚动优化:Scroll Reverser让macOS操作效率提升80%的效率工具
跨设备滚动优化:Scroll Reverser让macOS操作效率提升80%的效率工具 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 在当今多设备办公环境中,Mac用户常常面…...

Windows 11下xray安装全流程:从下载到配置证书的保姆级教程
Windows 11安全工具配置全指南:从零开始搭建本地测试环境 在数字化生活日益普及的今天,个人电脑安全越来越受到重视。对于技术爱好者而言,了解和使用专业安全工具不仅能提升自身防护能力,也是学习网络安全知识的重要途径。本文将详…...

彻底清理C盘自带软件方法:2026最新版强力卸载预装软件工具教程
电脑用着用着C盘就满了,开机小助手总提醒“磁盘空间不足”。点进控制面板一看,全是买电脑时自带的那些从未用过的软件,想卸载又怕卸不干净,甚至担心把系统搞崩溃。其实,彻底清理这些自带软件有章可循,关键是…...

快速集成A2A Agent
面我们提到可以将MCP服务也封装为一个Tool(AIFunction)让Agent调用,这里A2A Agent也是一样的道理。 这样做的好处是:让MAF中的Agent像调用本地函数一样调用远程A2A Agent 或 MCP Server。 下面的代码展示了在MAF中将A2A Card转换…...

AI 模型量化精度与推理速度平衡
AI模型量化精度与推理速度平衡:智能时代的效率与质量博弈 在人工智能技术快速发展的今天,AI模型的部署效率成为关键挑战。模型量化技术通过降低计算精度来提升推理速度,但如何在精度损失与速度提升之间找到平衡,成为开发者关注的…...

视频抠像技术全解析:基于MatAnyone的动态场景处理与多目标分离方案
视频抠像技术全解析:基于MatAnyone的动态场景处理与多目标分离方案 【免费下载链接】MatAnyone MatAnyone: Stable Video Matting with Consistent Memory Propagation 项目地址: https://gitcode.com/gh_mirrors/ma/MatAnyone 视频抠像技术在影视制作、直播…...

Comsol 仿真纳米孔超表面的手性响应:探索微观世界的光学奥秘
comsol仿真纳米孔超表面的手性响应在光学领域,超表面以其独特的亚波长结构展现出对光的卓越操控能力,而手性超表面更是其中的璀璨明珠,能够对不同旋向的圆偏振光产生特异响应。今天咱们就来聊聊如何用 Comsol 对纳米孔超表面的手性响应进行仿…...