生信算法7 - 核酸序列Fasta和蛋白PDB文件读写与检索
python 3.9实现以下算法。
1. 简单的写文件和读文件
# 写
file1 = open('count.txt','w')
file1.write('this is a test')
file1.close()# 读
file2 = open('my_file')
print(file2.read())2. 将列表内容写入文本文件
# 生成100-500数字列表
data = [i * 100 for i in range(1, 6)]
print(data)context = []
for value in data:# 将内容追加至context列表context.append(str(value) + '\n')# 写入文件
open('results.txt', 'w').writelines(out)# 文件内容
# 100
# 200
# 300
# 400
# 500
3. 将NCBI Genbank文件转换为fasta文件
Genbank包含了所有已知的核酸和蛋白质序列,以及发表的期刊及生物学注释等信息。
AY810830.gb文件下载:
https://www.ncbi.nlm.nih.gov/nuccore/AY810830
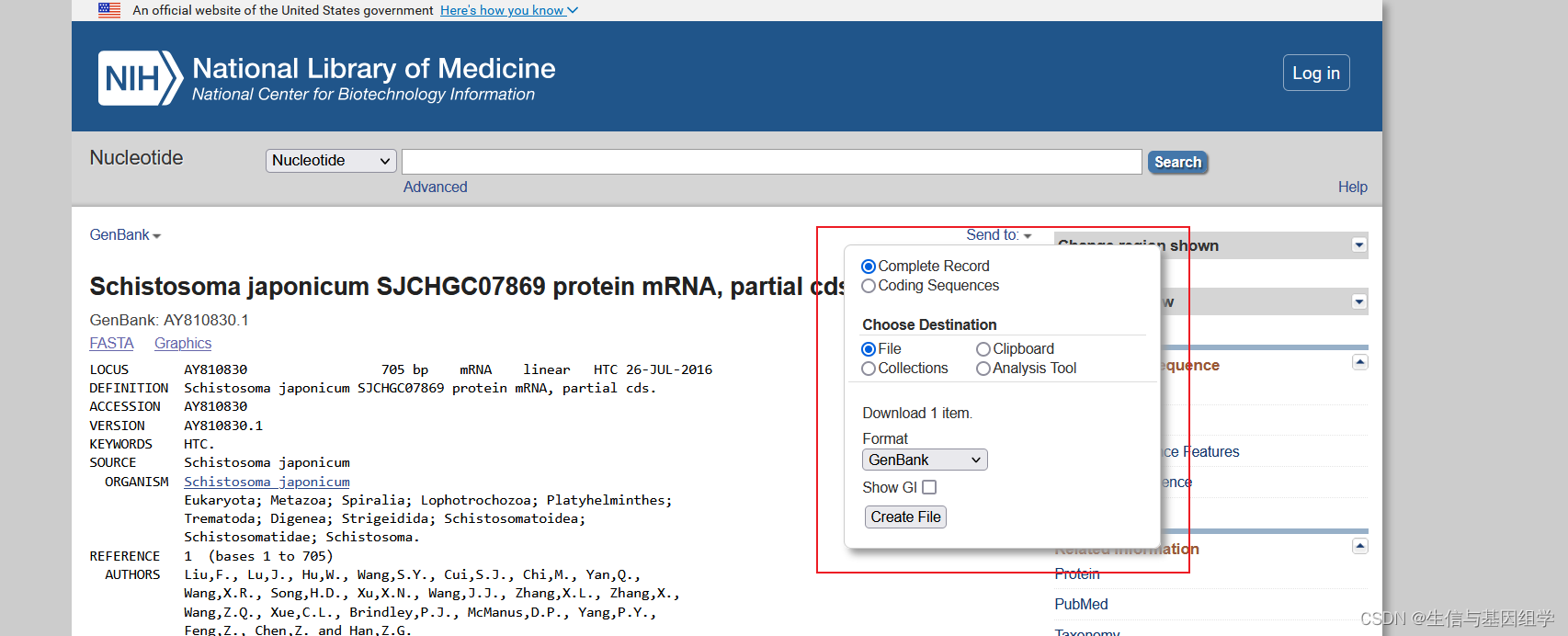
genbank_file = open("AY810830.gb")
fasta_file = open("AY810830.fasta","w")flag = False
# 遍历文件每行
for line in genbank_file:# 写入ACCESSION编号if line.startswith('ACCESSION'):accession = line.split()[1].strip()fasta_file.write('>' + accession + '\n')# 存在ORIGIN,则存在fasta序列if line.startswith('ORIGIN'):flag = Trueelif flag:fields = line.split()if fields != []:print(seq)# fasta序列seq = ''.join(fields[1:])fasta_file.write(seq.upper() + '\n')genbank_file.close()
fasta_file.close()4. 提取fasta序列header信息
fasta_file = open('AY810830.fasta','r')
out_file = open('AY810830.header','w')for line in fasta_file:# > 开头为fasta序列header信息if line.startswith('>'):out_file.write(line)out_file.close()5. 转换RNA fasta序列为氨基酸序列
# 定义密码子表字典
codon_table = {'GCU':'A', 'GCC':'A', 'GCA':'A', 'GCG':'A', 'CGU':'R', 'CGC':'R', 'CGA':'R', 'CGG':'R', 'AGA':'R', 'AGG':'R', 'UCU':'S', 'UCC':'S','UCA':'S', 'UCG':'S', 'AGU':'S', 'AGC':'S', 'AUU':'I', 'AUC':'I','AUA':'I', 'UUA':'L', 'UUG':'L', 'CUU':'L', 'CUC':'L', 'CUA':'L','CUG':'L', 'GGU':'G', 'GGC':'G', 'GGA':'G', 'GGG':'G', 'GUU':'V','GUC':'V', 'GUA':'V', 'GUG':'V', 'ACU':'T', 'ACC':'T', 'ACA':'T','ACG':'T', 'CCU':'P', 'CCC':'P', 'CCA':'P', 'CCG':'P', 'AAU':'N','AAC':'N', 'GAU':'D', 'GAC':'D', 'UGU':'C', 'UGC':'C', 'CAA':'Q','CAG':'Q', 'GAA':'E', 'GAG':'E', 'CAU':'H', 'CAC':'H', 'AAA':'K','AAG':'K', 'UUU':'F', 'UUC':'F', 'UAU':'Y', 'UAC':'Y', 'AUG':'M','UGG':'W','UAG':'STOP', 'UGA':'STOP', 'UAA':'STOP'}# 读取RNA fasta文件
rna = ''
for line in open('A06662-RNA.fasta'):# 过滤>开头行if not line.startswith('>'): # 拼接序列并去除末尾\nrna = rna + line.strip()# 三个不同阅读框,转换为蛋白序列
for frame in range(3):# 0,1,2protein_seq = '' print('Reading frame ' + str(frame + 1))for i in range(frame, len(rna), 3):codon = rna[i:(i + 3)]if codon in codon_table:# 判断是否为终止密码子if codon_table[codon] == 'STOP':# *符号表示终止密码子protein_seq = protein_seq + '*'else: # 不是终止密码子则添加转换后的氨基酸名称至protein_seqprotein_seq = protein_seq + codon_table[codon]else:# 处理非密码子表里的RNA序列,以-符号表示protein_seq = protein_seq + '-' # 每行48个氨基酸打印protein_seqi = 0while i < len(protein_seq):print(protein_seq[i:i + 48])i = i + 48

6. 将fasta序列转换为字典
P62258氨基酸序列下载:
https://www.ncbi.nlm.nih.gov/protein/P62258
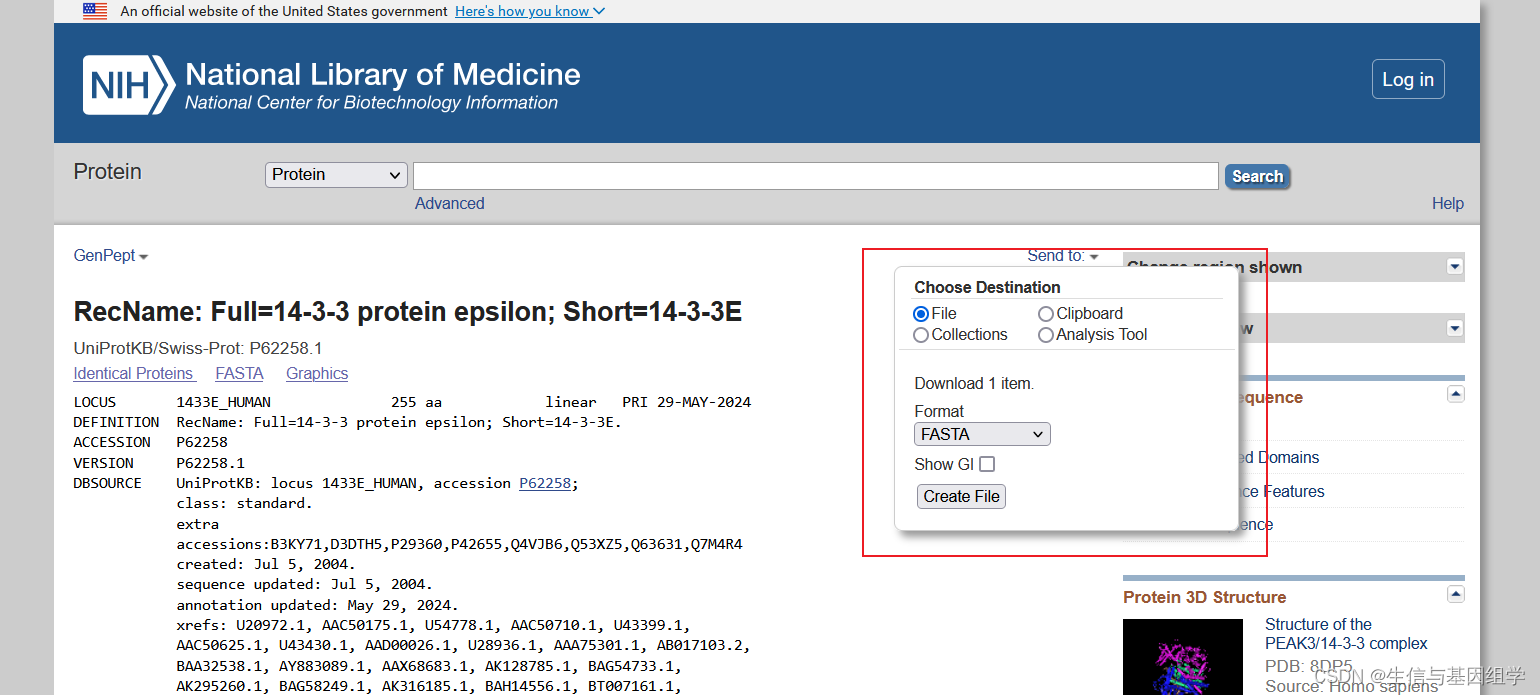
sequences = {}
ac = ''
seq = ''# 遍历fasta文件
for line in open("P62258.fasta"):# header信息保存至字典if line.startswith('>') and seq != '':sequences[ac] = seqseq = ''# >开头则获取蛋白序列编号, 否则添加氨基酸序列至seq变量if line.startswith('>'):ac = line.split('|')[1]else:seq = seq + line.strip()sequences[ac] = seq# 打印全部key
print(sequences.keys())# 打印指定Key字典氨基酸序列
print(sequences['P62258.1'])![sequences['P62258.1']](https://img-blog.csdnimg.cn/direct/ca9dafbf7b0143398876ad43351599c6.png)
7. 从pdb文件提取氨基酸序列
PDB数据库是一个数据中心,主要包含:原子坐标,蛋白质结构的其他信息和除蛋白以外生物大分子的信息。pdb文件可以从该数据下载。
牛β-胰蛋白酶 pdb文件下载:
https://www.rcsb.org/structure/1TLD
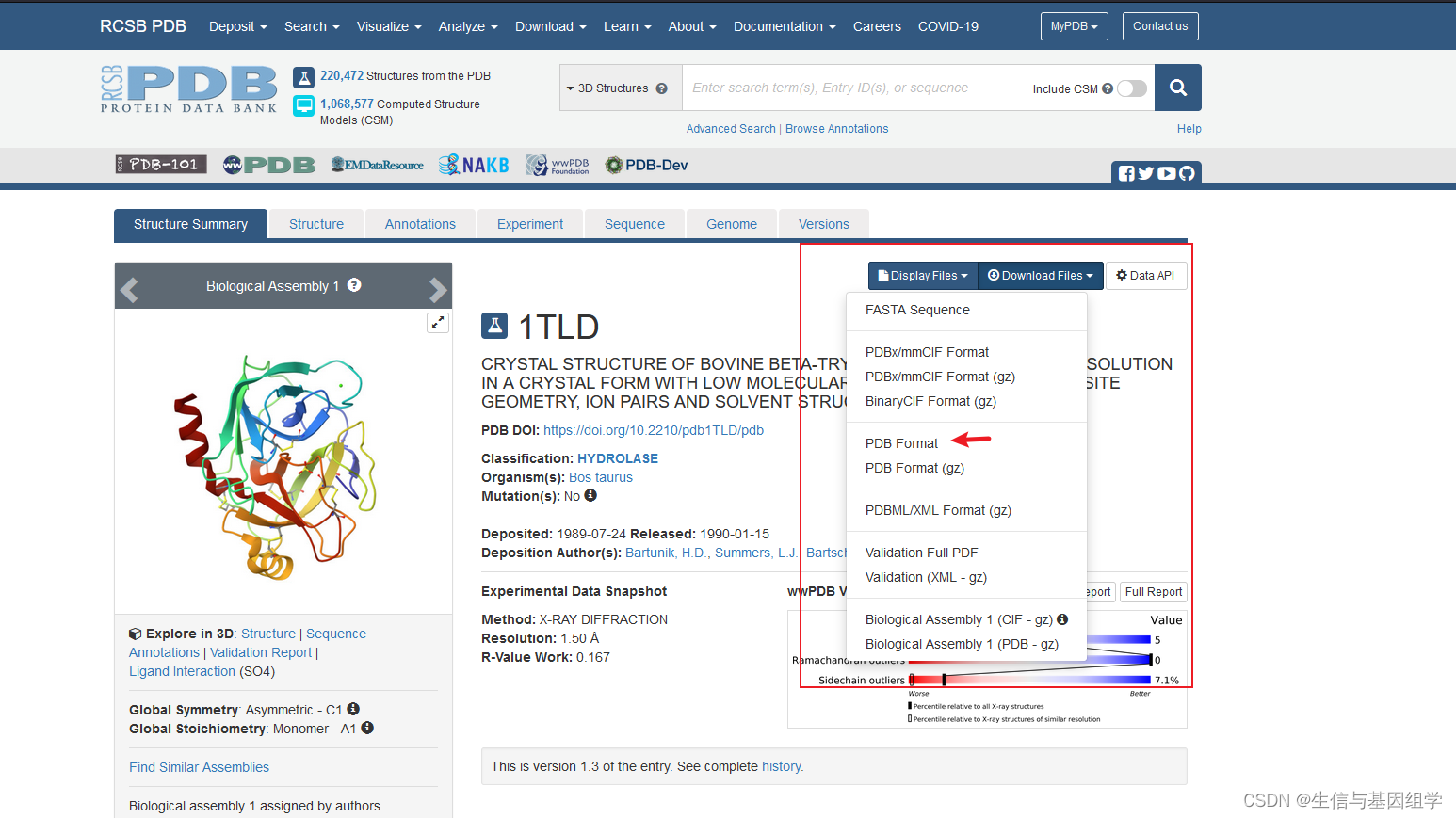
# 氨基酸简写字典
aa_codes = {'ALA':'A', 'CYS':'C', 'ASP':'D', 'GLU':'E','PHE':'F', 'GLY':'G', 'HIS':'H', 'LYS':'K','ILE':'I', 'LEU':'L', 'MET':'M', 'ASN':'N','PRO':'P', 'GLN':'Q', 'ARG':'R', 'SER':'S','THR':'T', 'VAL':'V', 'TYR':'Y', 'TRP':'W'}seq = ''
# 遍历.pdb文件
for line in open("1tld.pdb"):# SEQRES开头行为氨基酸序列if line.startswith("SEQRES"):line_split = line.split()print(line_split)# 拼接氨基酸序列for aa_code in line_split[4:]:seq = seq + aa_codes[aa_code]# 打印拼接结果, 每行63个氨基酸
i = 0
print(">1tld")
while i < len(seq):print(seq[i:(i + 64)])i = i + 64
pdb文件SEQRES:
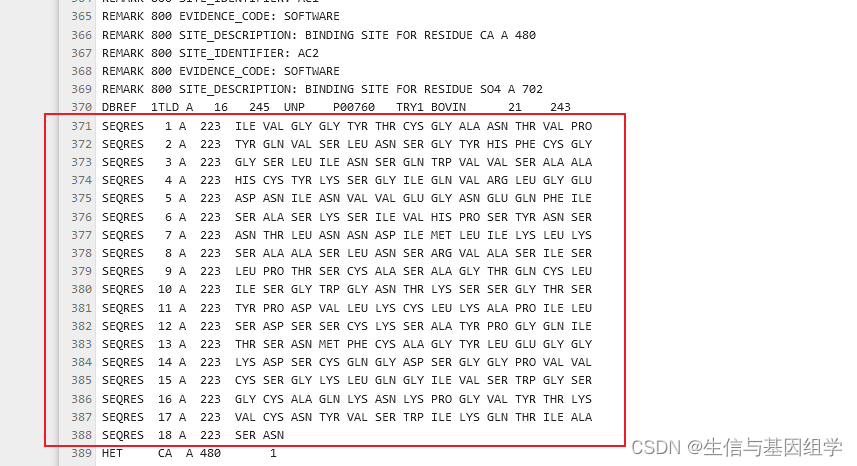
seq打印结果:

生信算法文章推荐
生信算法1 - DNA测序算法实践之序列操作
生信算法2 - DNA测序算法实践之序列统计
生信算法3 - 基于k-mer算法获取序列比对索引
生信算法4 - 获取overlap序列索引和序列的算法
生信算法5 - 序列比对之全局比对算法
生信算法6 - 比对reads碱基数量统计及百分比统计
相关文章:
生信算法7 - 核酸序列Fasta和蛋白PDB文件读写与检索
python 3.9实现以下算法。 1. 简单的写文件和读文件 # 写 file1 open(count.txt,w) file1.write(this is a test) file1.close()# 读 file2 open(my_file) print(file2.read())2. 将列表内容写入文本文件 # 生成100-500数字列表 data [i * 100 for i in range(1, 6)] pri…...

【Python】Python异步编程
Python 异步编程 异步编程 异步编程是一种编程范式,通过非阻塞的方式执行任务,允许程序在等待某些操作(如I/O操作、网络请求、数据库查询等)完成时,继续执行其他任务。这与同步编程(或阻塞编程)…...
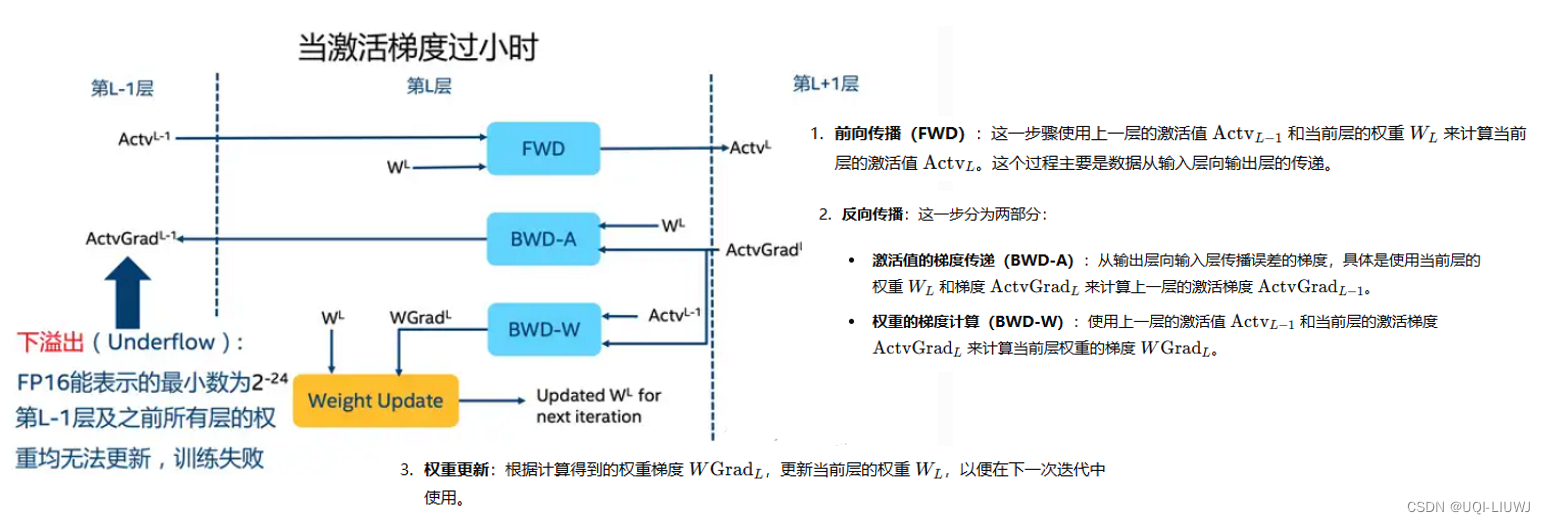
pytorch笔记:自动混合精度(AMP)
1 理论部分 1.1 FP16 VS FP32 FP32具有八个指数位和23个小数位,而FP16具有五个指数位和十个小数位Tensor内核支持混合精度数学,即输入为半精度(FP16),输出为全精度(FP32) 1.1.1 使用FP16的优缺…...

R语言ggplot2包绘制世界地图
数据和代码获取:请查看主页个人信息!!! 1. 数据读取与处理 首先,从CSV文件中读取数据,并计算各国每日收入的平均签证成本。 library(tidyverse) df <- read_csv("df.csv") %>% group_…...
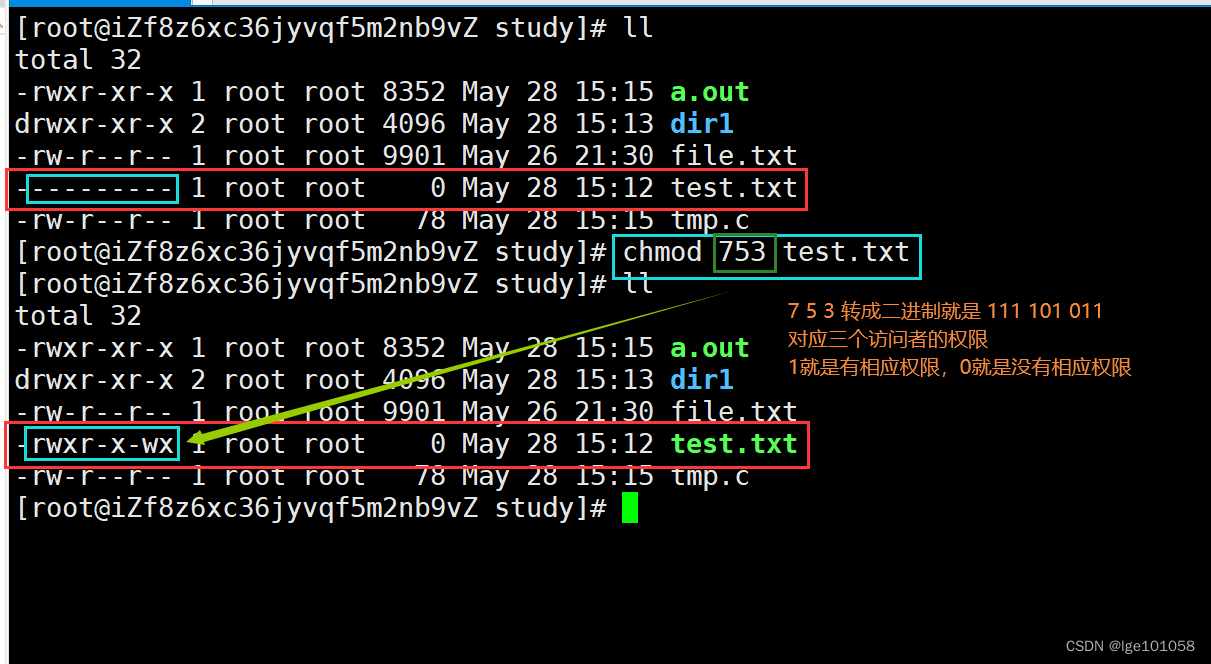
【Linux】Linux的权限_1
文章目录 三、权限1. shell外壳2. Linux的用户3. Linux权限管理文件访问者的分类文件类型和访问权限 未完待续 三、权限 1. shell外壳 为什么要使用shell外壳 由于用户不擅长直接与操作系统直接接触和操作系统的易用程度、安全性考虑,用户不能直接访问操作系统。 什…...

日语_远程办公常用日语单词
基本词汇 リモートワーク(Rimōto Wāku):远程工作テレワーク(Terewāku):远程工作(Telework)在宅勤務(ざいたくきんむ,Zaitaku Kinmu)ÿ…...

MTK 平台项目security boot 开启/关闭 及 系统签名流程
以 https://online.mediatek.com/FAQ#/SW/FAQ26691 为基础做如下记录以做备忘: How to Enable/Disable Secure Boot for Security 3.0: 1、 How to Enable Path Enable Preloader /vendor/mediatek/proprietary/bootable/bootloader/preloader/custom/{…...
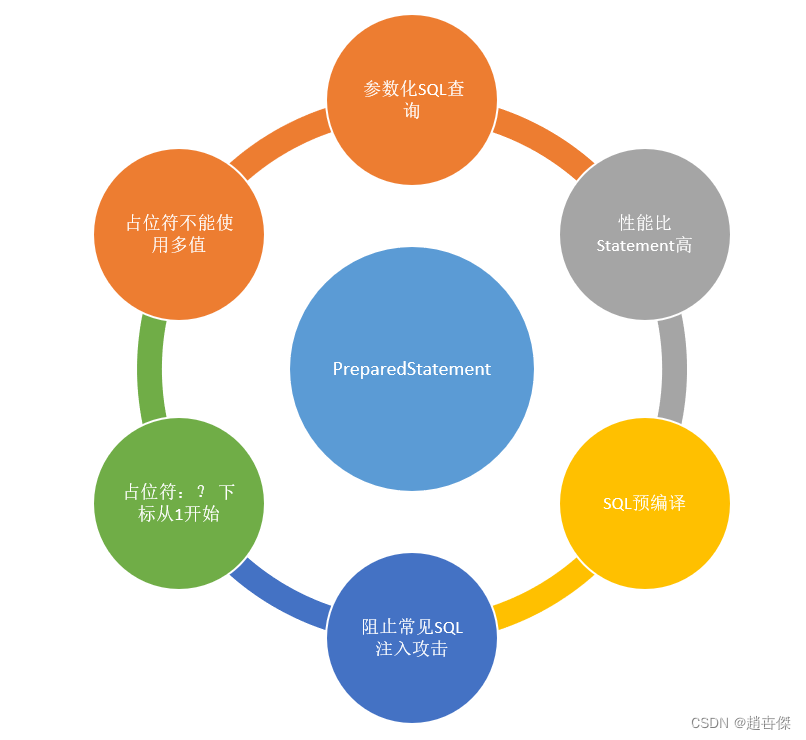
JDBC连接MySQL
目录 1.数据库编程的必备条件 2.Java的数据库编程JDBC 3.JDBC的工作原理 4.第三方库connector的下载和导包 5.JDBC的使用 使用步骤 (1)创建数据源对象DataSource (2)给对象设置必要的属性 (3)和数据…...
【Qt】【模型视图架构】 在项目视图中启用拖放
文章目录 1. 在便捷类中启用拖放2. 在模型/视图类中启用拖放 模型/视图框架支持Qt的拖放应用。 列表、表格和树中的项目可以在视图中被拖拽,数据作为MIME编码的数据被导入和导出。标准视图可以自动支持内部的拖放。 默认视图的拖放功能并没有被启用,如果…...
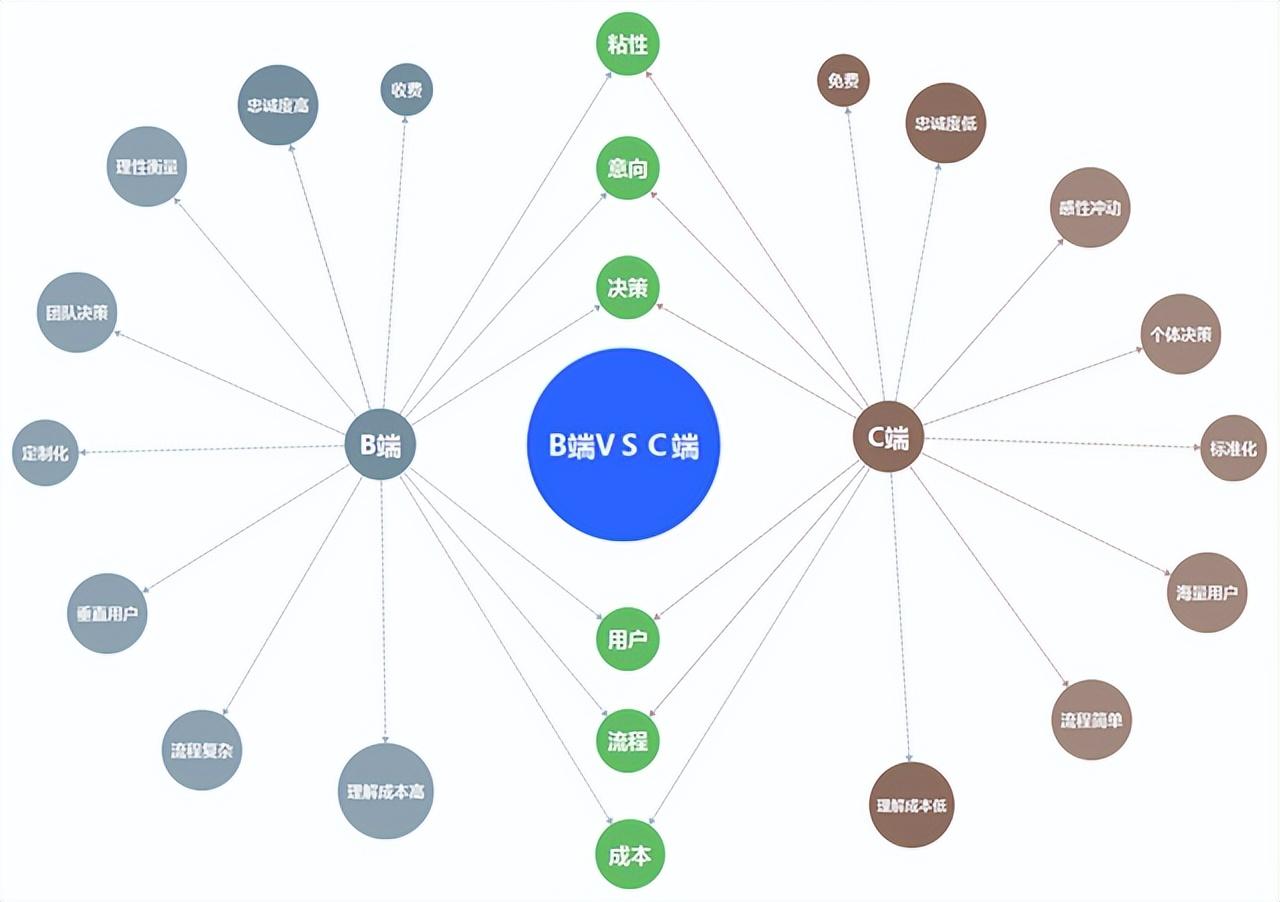
B端产品无爆款,说有的都是忽悠和外行!
前言:网上经常有人讲运营,把C端那一套硬搬到B端,讲的自我陶醉,稍微有点常识的人就知道不能这么玩。 一、什么是B端和C端 B端(Business-to-Business)是指面向企业客户的市场和产品。B端产品或服务主要是为…...

腾讯云的身份证核验,找不到这个类
文件上传功能在许多Web应用程序中是非常常见的需求之一。然而,由于文件上传存在安全风险,保护用户上传的文件的安全性,以及防止黑客利用上传功能进行攻击是非常重要的。在本文中,我们将讨论一些常见的安全漏洞,并提供一…...

vue3 vue-draggable-next 实现拖拽穿梭框效果
一、vue3 vue-draggable-next 实现拖拽穿梭框效果 <template> <div> <h2>列表 1</h2> <draggable v-model"list1" group"items" tag"transition-group" end"onDragEnd"> <div v-for"(item…...
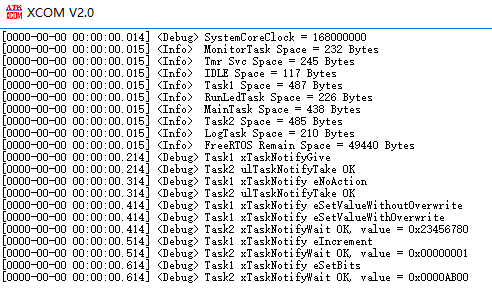
FreeRTOS【16】直达任务通知使用
1.开发背景 直达任务通知,FreeRTOS 的线程任务提供的接口,可以用作线程唤醒,或者是传递数据,因为是基于线程本身的操作,是轻量级,速度响应更快,适合小内存芯片使用。 事实上本人使用得比较少&am…...
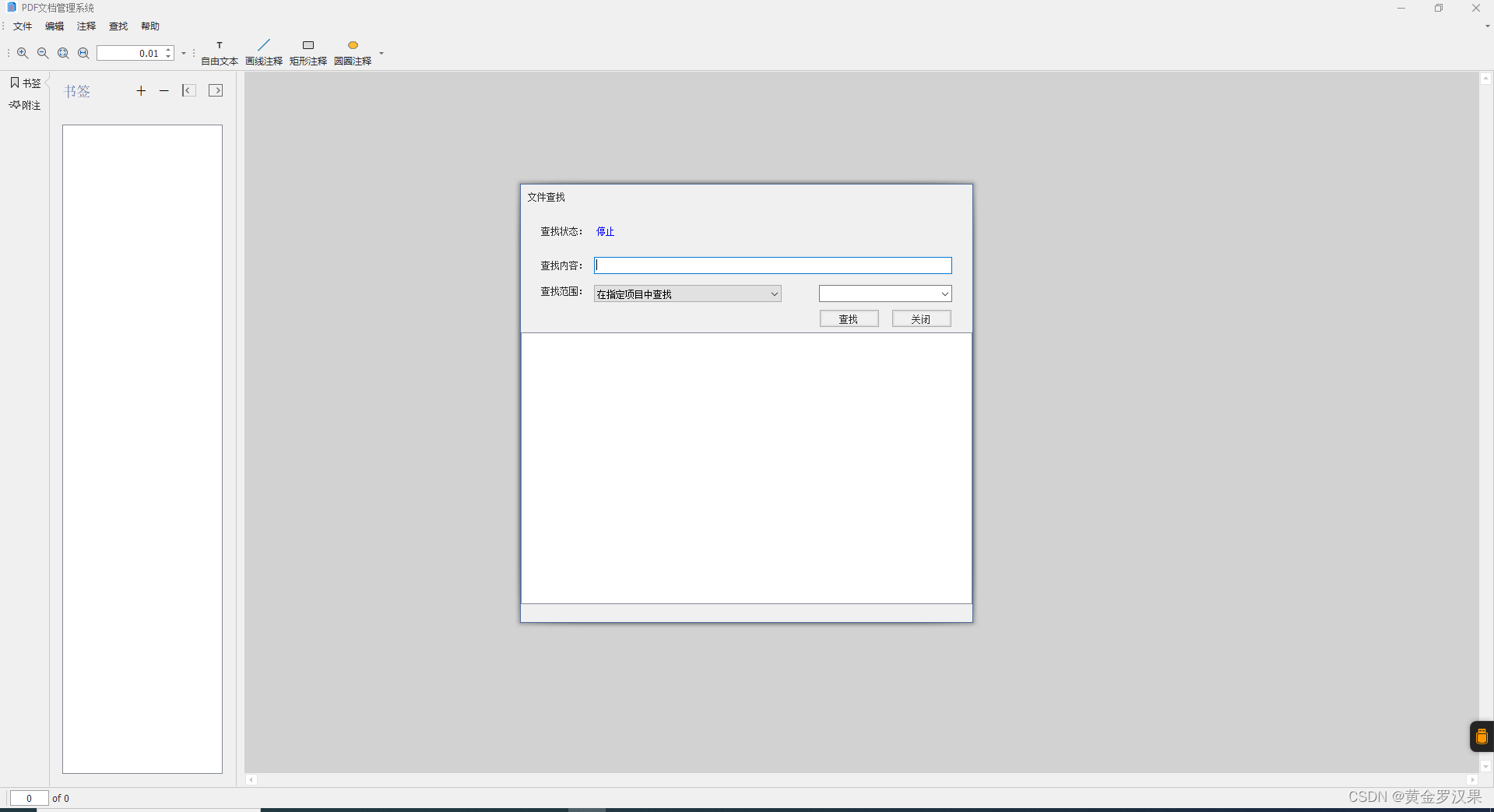
关于软件<PDF文档管理系统V1.0>的介绍
<PDF文档管理系统V1.0>(下载地址在最下面)是我在2023年发布的<知识辅助系统>的改善以及重新开发版本,软件在重新开发提供了<知识辅助系统>的所有功能的基础上,添加了一些新的功能。软件尽量提供简单、实用的功能…...

Java面试题-Tomcat初级面试题
Tomcat是什么?请简述它的主要功能。 Tomcat是一个开源的Web应用服务器,由Apache软件基金会开发。它是一个实现了Java Servlet和JavaServer Pages(JSP)技术的容器,用于处理客户端的请求并返回响应。Tomcat的主要功能如…...

红队内网攻防渗透:内网渗透之windows内网权限提升技术:数据库篇
红队内网攻防渗透 1. 内网权限提升技术1.1 数据库权限提升技术1.1.1 数据库提权流程1.1.1.1 先获取到数据库用户密码1.1.1.2 利用数据库提权工具进行连接1.1.1.3 利用建立代理解决不支持外联1.1.1.4 利用数据库提权的条件及技术1.1.2 Web到Win-数据库提权-MSSQL1.1.3 Web到Win-…...

rust嵌入式开发之总结
我们用rust开发的新版产品刚刚交付,已经在海上安装测试完毕并顺利投产。终于松了口气,同时也有时间和精力来做个全面的总结了。 这个产品,目前差不多有三版: 第一个版本是用crt-thread写的,投产后出了一个内存泄露的…...

【制作100个unity游戏之27】使用unity复刻经典游戏《植物大战僵尸》,制作属于自己的植物大战僵尸随机版和杂交版6(附带项目源码)
最终效果 系列导航 文章目录 最终效果系列导航前言方法一、使用excel配置表excel转txt文本读取txt数据按配置信息生成僵尸 方法二、使用ScriptableObject 配置关卡信息源码结束语 前言 本节主要是推荐两种实现配置关卡信息,并按表生成僵尸和关卡波次 方法一、使用…...

回溯算法指组合总和
题目: 找出所有相加之和为 n 的 k 个数的组合,且满足下列条件: 只使用数字1到9每个数字 最多使用一次 返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。 思路: 这种问题…...

java-stream转换map key重复报错解决小记
解决key重复问题 在用stream转成map过程中会有key重复的隐患,如果数据没重复还好,如果重复了会提示 java.lang.IllegalStateException: Duplicate key 8753444332651at java.util.stream.Collectors.lambda$throwingMerger$0(Collectors.java:133)at ja…...

终极指南:如何免费快速上手Method Draw在线SVG编辑器
终极指南:如何免费快速上手Method Draw在线SVG编辑器 【免费下载链接】Method-Draw Method Draw, the SVG Editor for Method of Action 项目地址: https://gitcode.com/gh_mirrors/me/Method-Draw 如果你正在寻找一款简单高效的在线SVG编辑器,那…...

独立开发者如何利用 Taotoken 的 Token Plan 套餐以更优成本启动 AI 项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 的 Token Plan 套餐以更优成本启动 AI 项目 对于独立开发者或小型工作室而言,在项目启动…...
:文档加载与文本分块技术)
工业级大模型学习之路021:LangChain零基础入门教程(第四篇):文档加载与文本分块技术
一、文档处理是 RAG 系统的基石1.1 为什么文档处理决定了 RAG 系统的上限?RAG 系统的核心逻辑是 **"检索相关文档片段 → 喂给大模型生成回答"**,整个流程的质量完全依赖于文档处理环节:如果文档解析失败,再好的检索和生…...

Unity C#方法设计实战:从参数传递到跨脚本调用
1. 这不是语法课,是写代码时每天要面对的“沟通现场”刚带完一批Unity新手做小项目,有个现象特别明显:很多人能背出“方法就是函数”“参数分值传递和引用传递”,但一到实际写代码就卡壳——比如想让角色跳跃时播放音效࿰…...
)
new一个指针再被智能指针接管和直接调用make_unique有什么区别? (接上篇的未完待续)
上篇代码有错误,在本篇幅更正#include <iostream> #include <memory> #include <vector> #include <utility> #include <cstddef> #include <type_traits> //std::enable_if_t<!std::is_array<T>::value, int&…...

嵌入式开发硬件生态构建:MIPI屏、UVC摄像头与4G模块的选型与集成实战
1. 项目概述:一次面向嵌入式开发者的硬件生态补全最近,我们团队负责的睿擎派(一个基于瑞芯微RK3566/RK3588等主流芯片的嵌入式开发板品牌)项目,迎来了一次重要的硬件配件更新。这次上新不是简单的“换个壳”࿰…...

3000+戴森球计划工厂蓝图终极指南:从新手到大师的完全解决方案
3000戴森球计划工厂蓝图终极指南:从新手到大师的完全解决方案 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 还在为戴森球计划中复杂的工厂布局而头疼吗&#…...

WebPageTest:企业级分布式网页性能检测架构与优化实践
WebPageTest:企业级分布式网页性能检测架构与优化实践 【免费下载链接】WebPageTest Official repository for WebPageTest 项目地址: https://gitcode.com/gh_mirrors/we/WebPageTest WebPageTest作为全球领先的开源网页性能检测平台,为技术决策…...

Chrome画中画扩展终极指南:一键实现多任务视频播放
Chrome画中画扩展终极指南:一键实现多任务视频播放 【免费下载链接】picture-in-picture-chrome-extension 项目地址: https://gitcode.com/gh_mirrors/pi/picture-in-picture-chrome-extension Chrome画中画扩展是一款基于原生Picture-in-Picture API开发的…...

【Appium 系列】第20节-测试项目结构设计 — 从脚本到工程
对应代码:配套代码/test/ 完整目录结构说明:本节讲解如何组织一个中大型 Appium 测试项目,从目录结构到文件职责,从脚本到工程的演进。这节讲什么测试项目从小到大会经历三个阶段:阶段 1:脚本阶段test_logi…...