深度学习知识与心得
目录
深度学习简介
传统机器学习
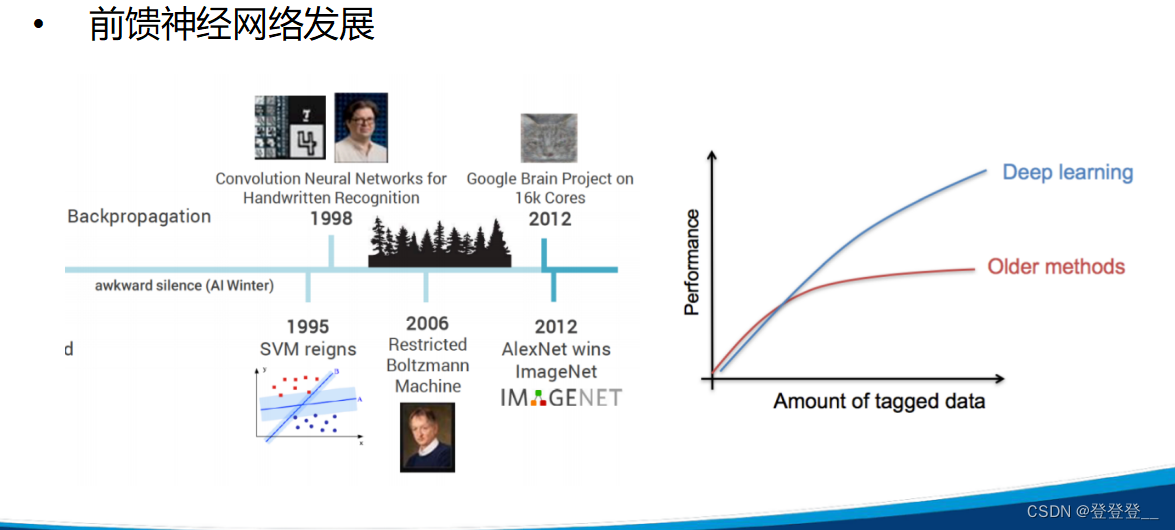
深度学习发展
感知机
前馈神经网络
前馈神经网络(BP网络)
深度学习框架讲解
深度学习框架
TensorFlow
一个简单的线性函数拟合过程
卷积神经网络CNN(计算机视觉)
自然语言处理NLP
Word Embedding
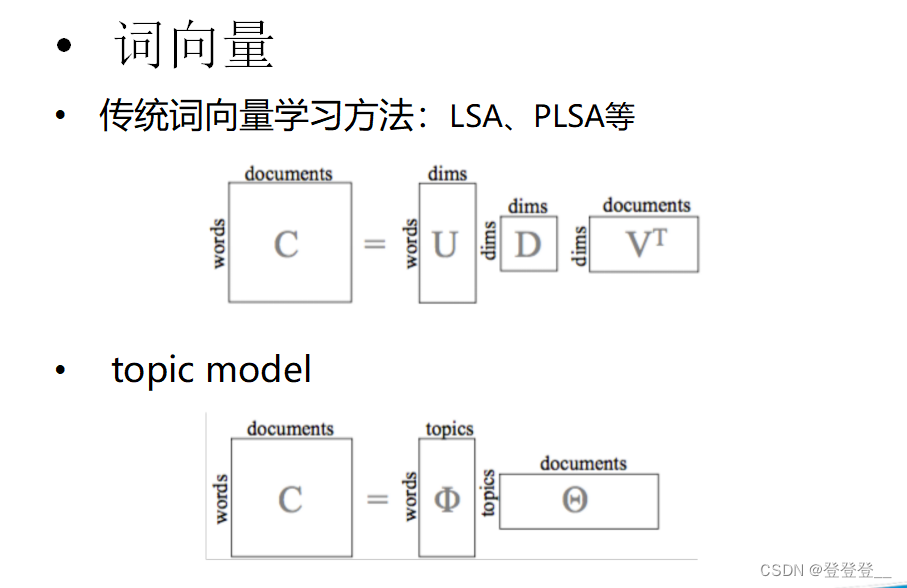
词向量
词向量学习方法:LSA、PLSA
词向量训练
词向量应用
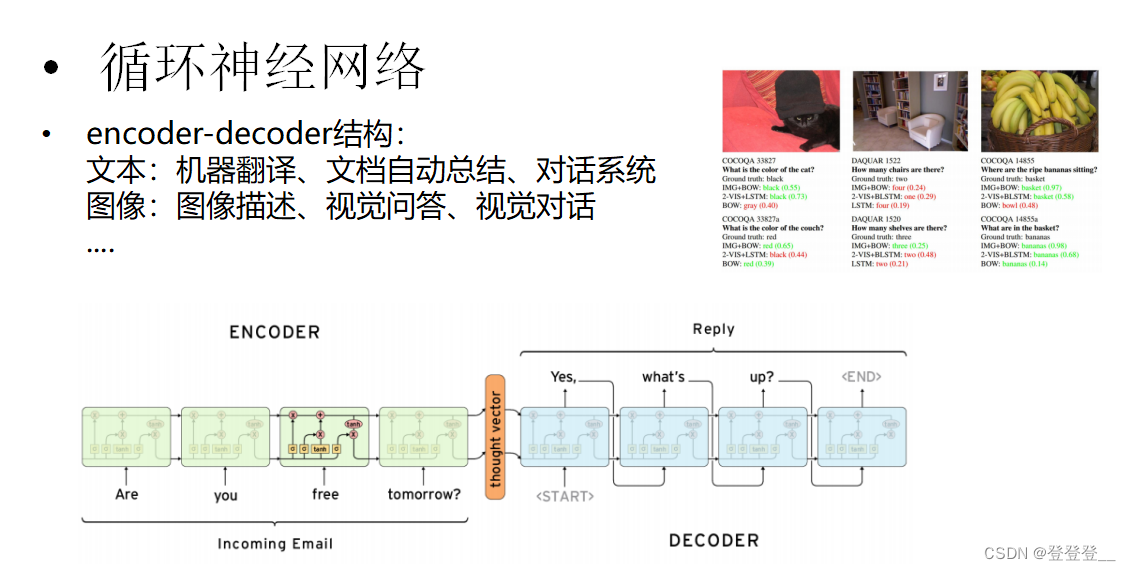
循环神经网络RNN(语义理解)
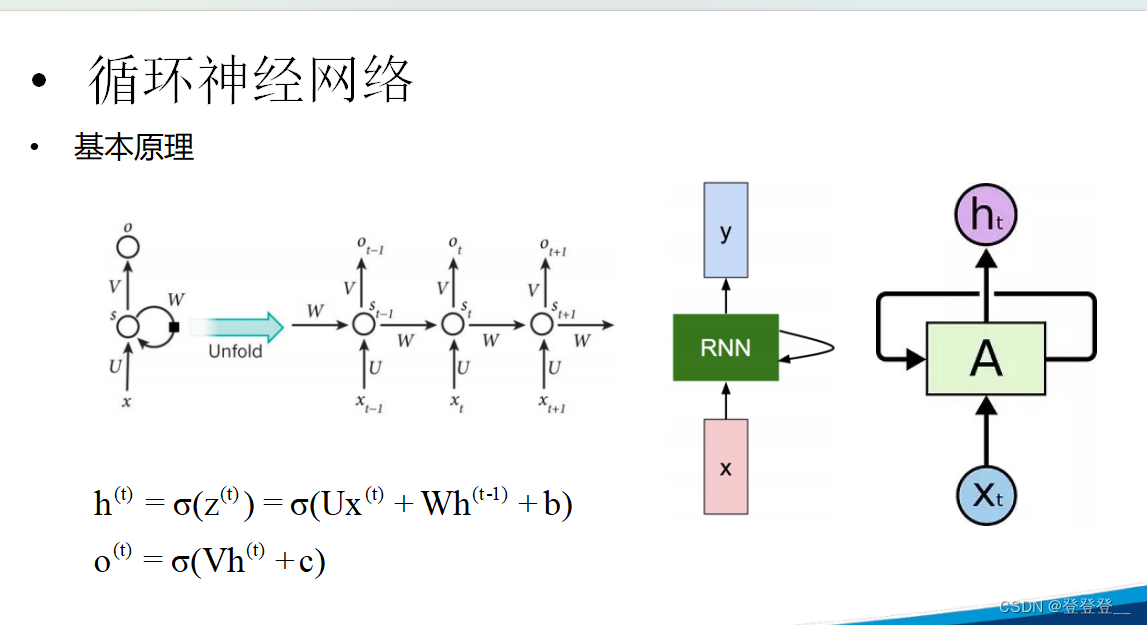
基本原理
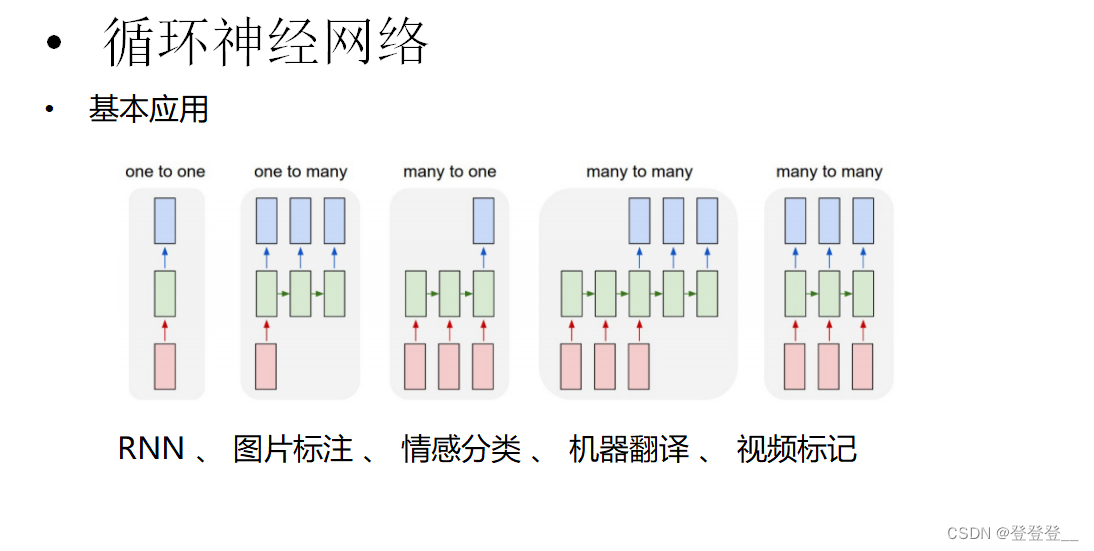
基本应用
RNN的缺陷
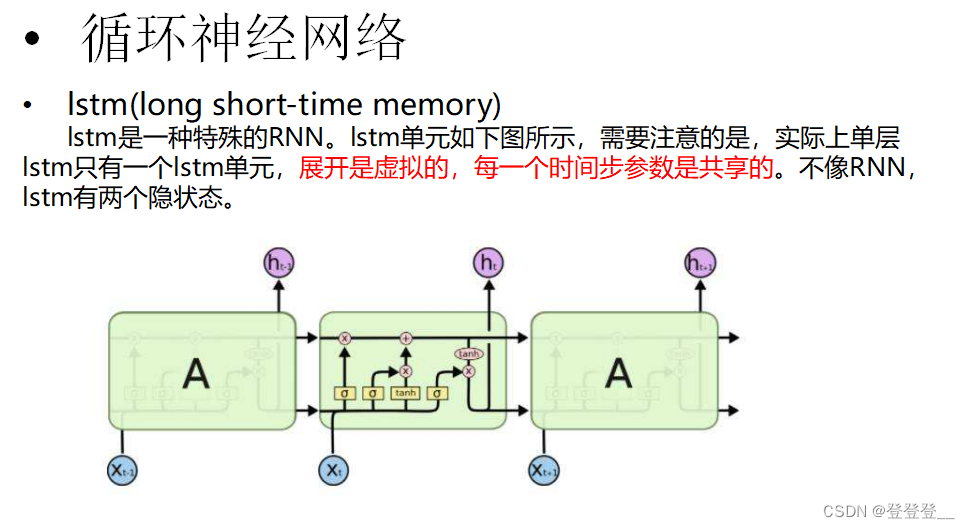
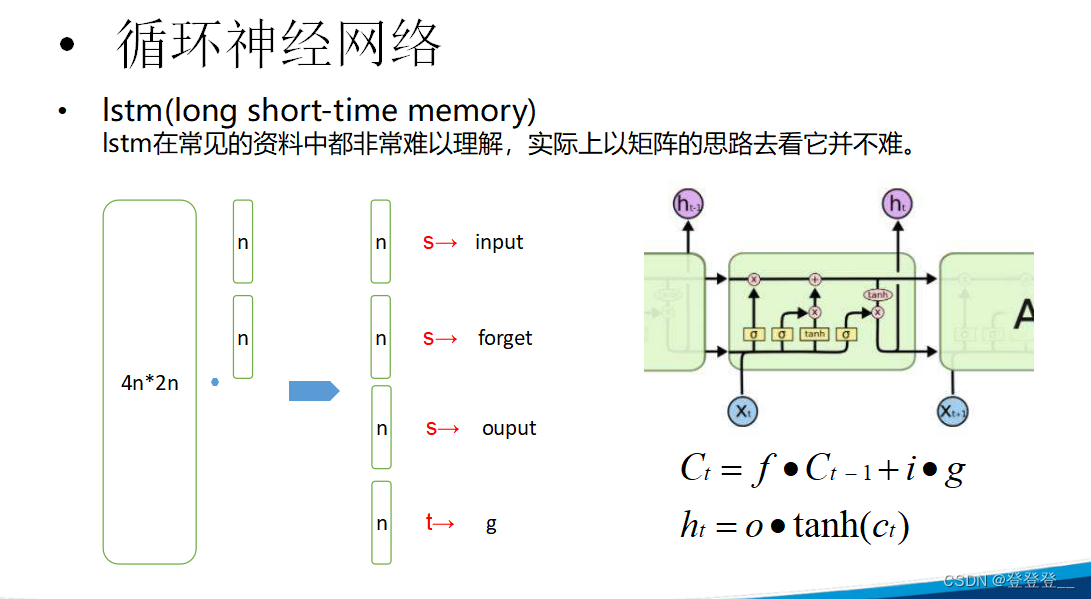
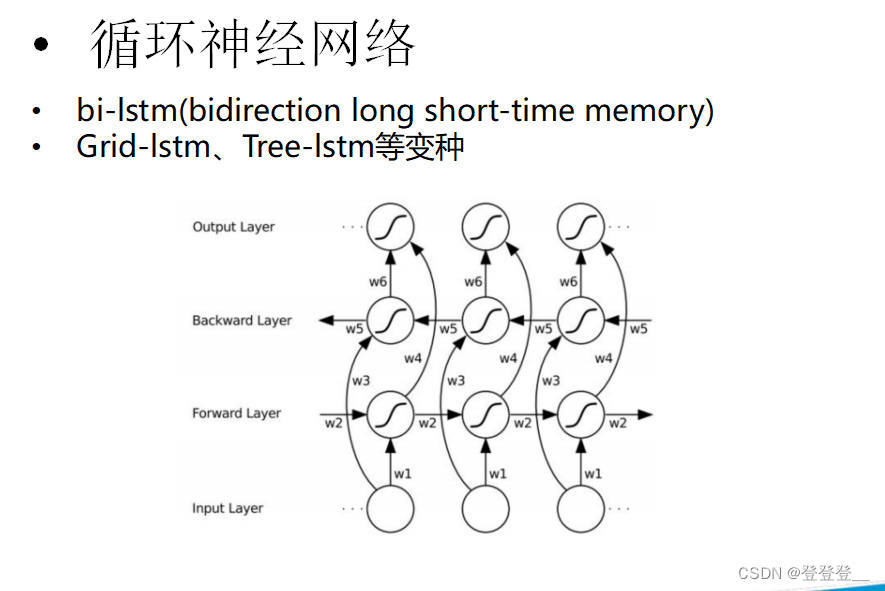
LSTM (特殊的RNN)
练习_聊天机器人实战
深度学习(Deep Learning,简称DL)是机器学习(Machine Learning,简称ML)领域中的一个重要研究方向。它被引入机器学习领域,目的是使机器能够更接近于实现人工智能(Artificial Intelligence,简称AI)的原始目标。深度学习通过学习样本数据的内在规律和表示层次,实现对诸如文字、图像和声音等数据的解释,并提升机器的分析学习能力。
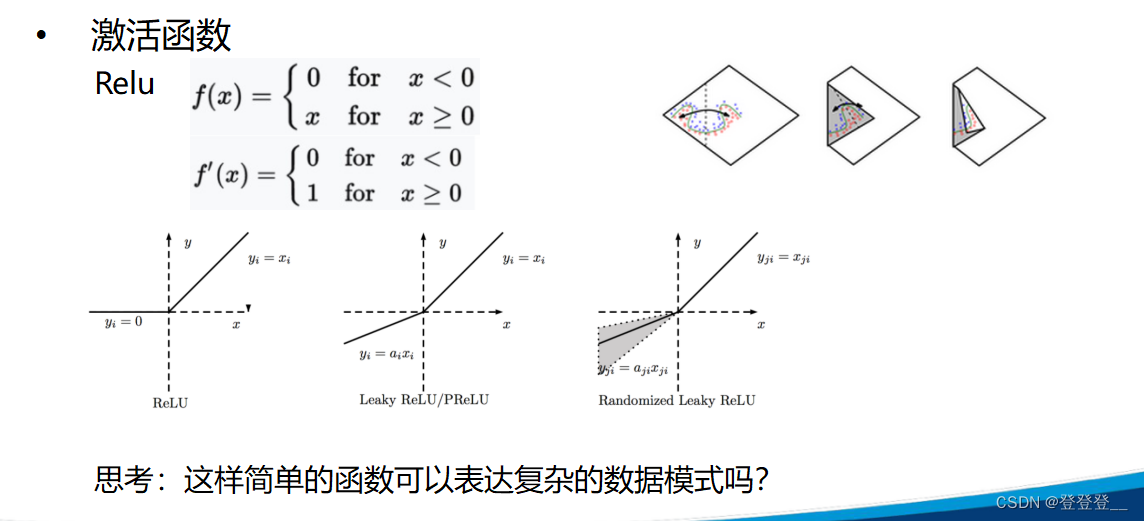
深度学习的核心原理主要包括神经网络、反向传播算法、激活函数、损失函数和优化算法等。神经网络是深度学习的基本结构,它由输入层、隐藏层和输出层组成,通过权重和偏置连接各层,逐层传递信息并进行处理。反向传播算法则用于在训练过程中更新网络参数,优化网络性能。激活函数和损失函数则分别用于增加网络的非线性能力和衡量网络输出与真实标签之间的差异。优化算法则用于在训练过程中最小化损失函数,更新网络参数。
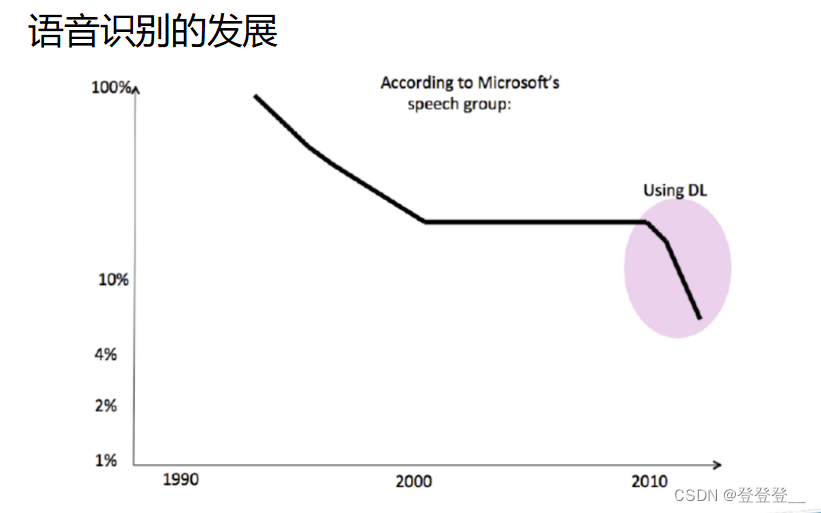
深度学习在众多领域都有广泛的应用,如计算机视觉及图像识别、自然语言处理、语音识别及生成、推荐系统、游戏开发、医学影像识别、金融风控、智能制造、购物领域以及基因组学等。这些应用不仅展示了深度学习的强大能力,也推动了相关领域的进步和发展。
在未来,深度学习将继续朝着跨学科融合、多模态融合、自动化模型设计、持续优化算法、边缘计算的应用以及可解释性和可靠性等方向发展。这些发展将进一步推动深度学习技术的进步,拓宽其应用领域,并提升其在各种复杂任务中的性能。
需要注意的是,深度学习虽然取得了显著的成果,但仍然存在一些挑战和限制,如数据需求量大、模型复杂度高、计算资源消耗大等问题。因此,在实际应用中,需要根据具体任务和场景来选择合适的深度学习方法和模型,并进行合理的优化和调整。

深度学习简介
传统机器学习
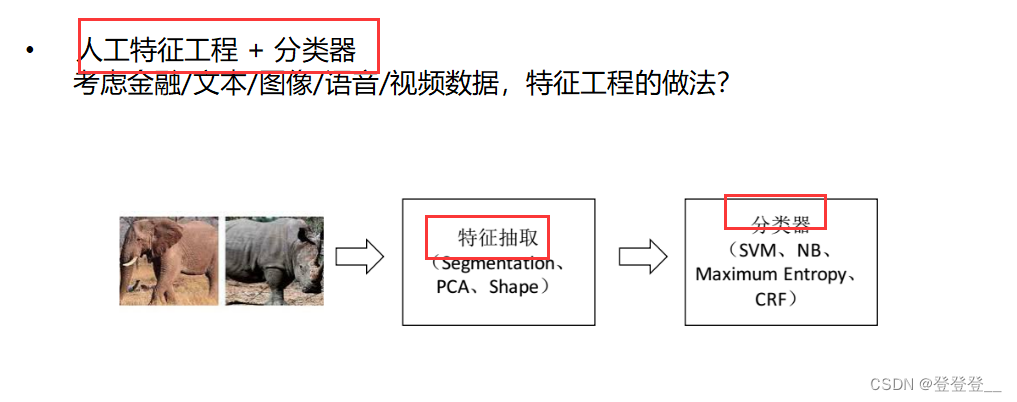

深度学习发展
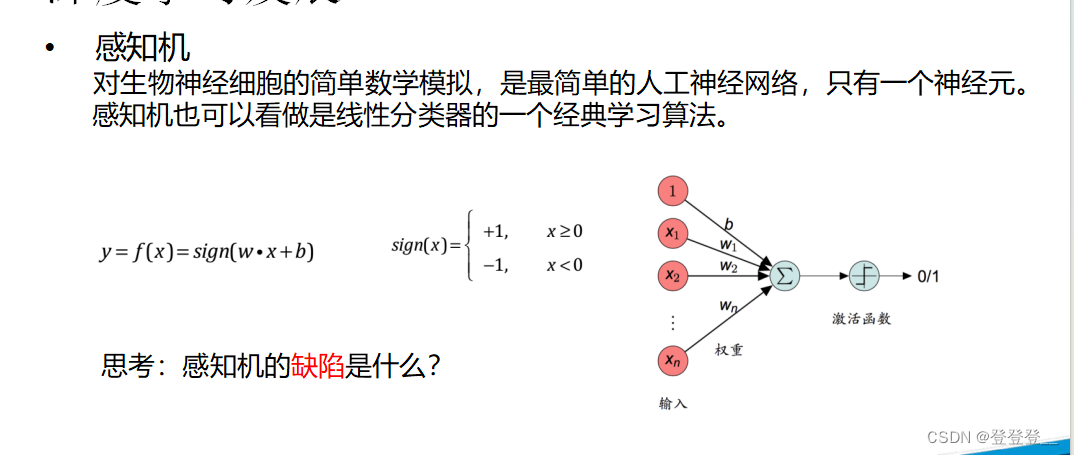
感知机
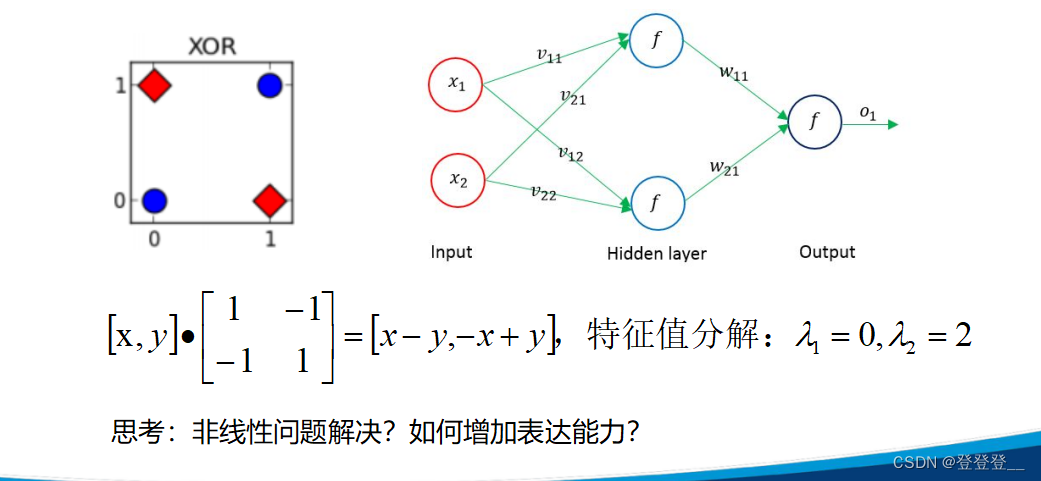
非线性问题解决不能用线性变换
前馈神经网络
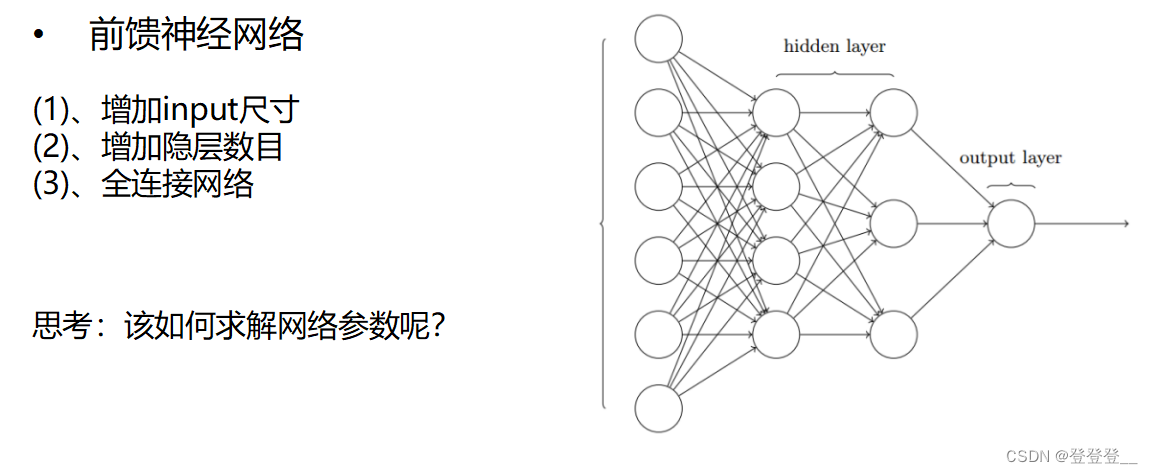
前馈神经网络(BP网络)
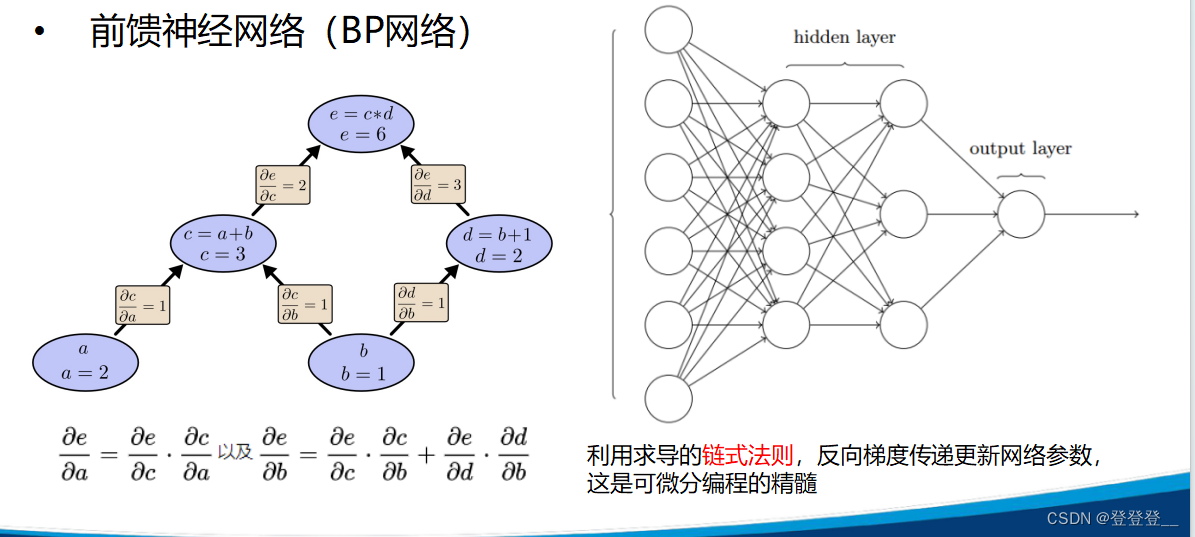

可以通过多调几次参数和多跑几次模型


NLP是自然语言处理(Natural Language Processing)的缩写,是人工智能和语言学领域的交叉学科。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系,但又有重要的区别。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。因而它是计算机科学的一部分


深度学习框架讲解
深度学习框架
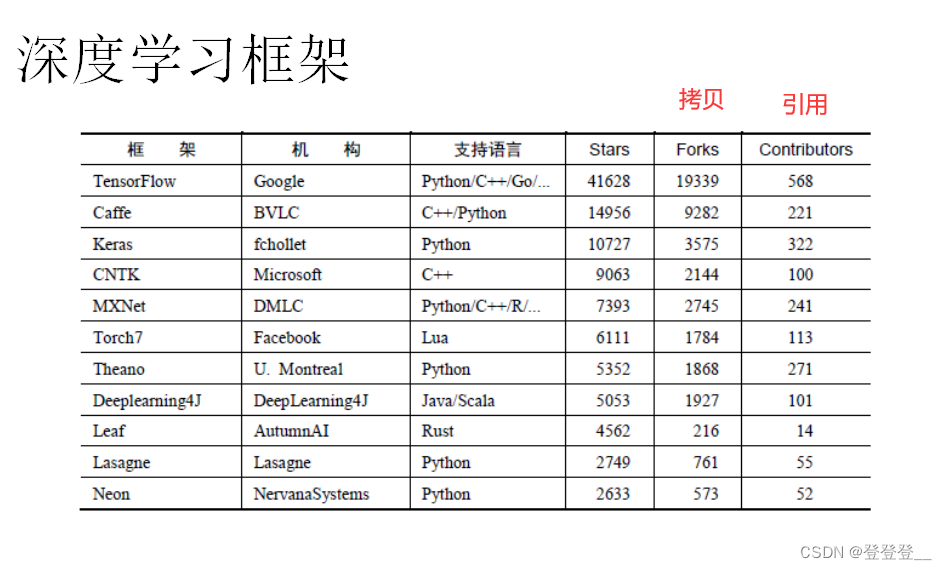
TensorFlow

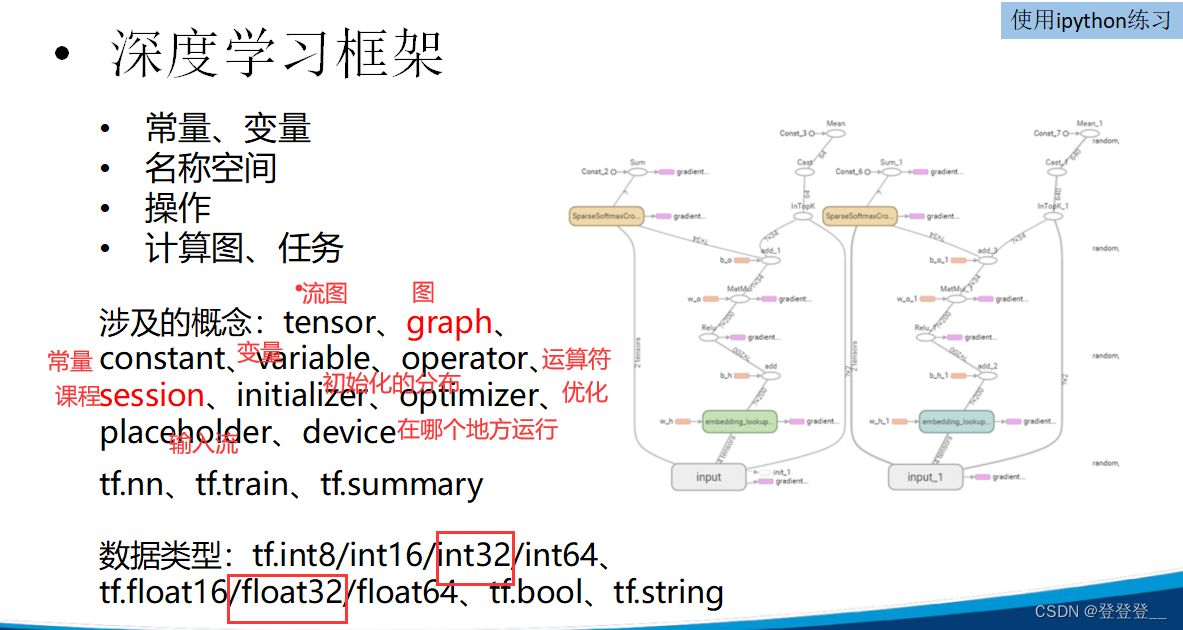
一个简单的线性函数拟合过程

下面是代码的解释:
- 导入TensorFlow库。
import tensorflow as tf
- 创建两个
tf.Variable对象x和y,并分别初始化为[1, 2, 3]和[4, 5, 6]。x = tf.Variable([1, 2, 3], dtype=tf.float32) y = tf.Variable([4, 5, 6], dtype=tf.float32)
- 计算
x和y的逐元素乘积,并求和得到z。z = tf.reduce_sum(x * y)
- 使用
tf.Session来初始化变量并计算z的值。with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # 初始化所有全局变量 z_value = sess.run(z) # 执行计算图,得到z的值 print(z_value) # 打印结果在
with tf.Session() as sess:的上下文中,首先使用sess.run(tf.global_variables_initializer())来初始化所有全局变量(即x和y)。然后,使用sess.run(z)来执行计算图并获取z的值。最后,将z的值打印出来。运行这段代码将输出:
32这是因为
(1*4) + (2*5) + (3*6) = 4 + 10 + 18 = 32。


卷积神经网络CNN(计算机视觉)
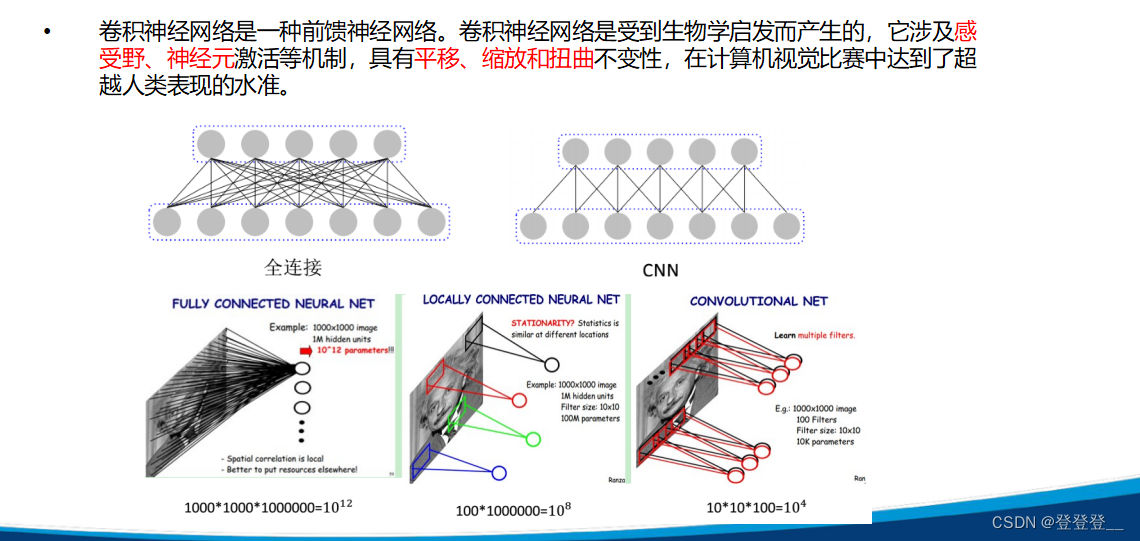
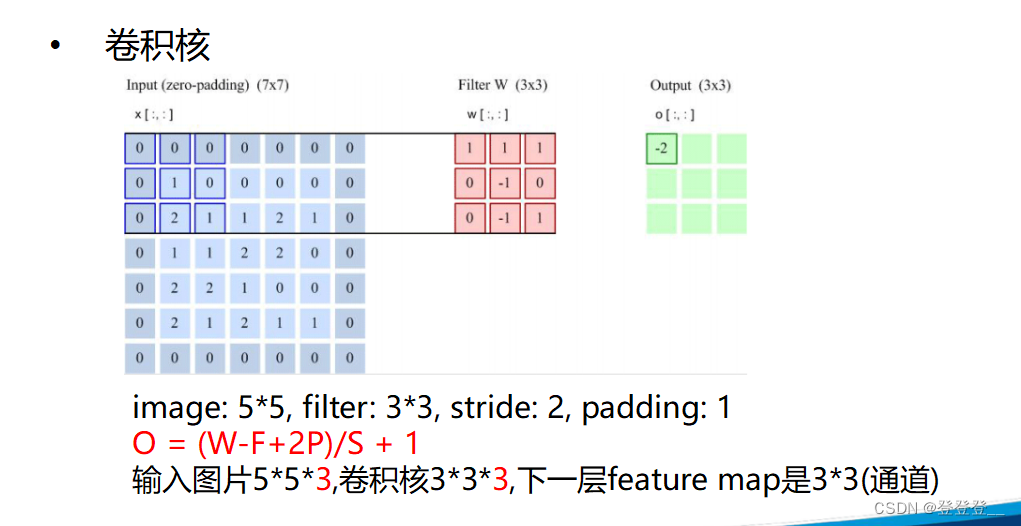
卷积神经网络(Convolutional Neural Networks,简称CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习领域的代表算法之一。卷积神经网络具有表征学习的能力,能够按其阶层结构对输入信息进行平移不变分类,因此也被称为“平移不变人工神经网络”。
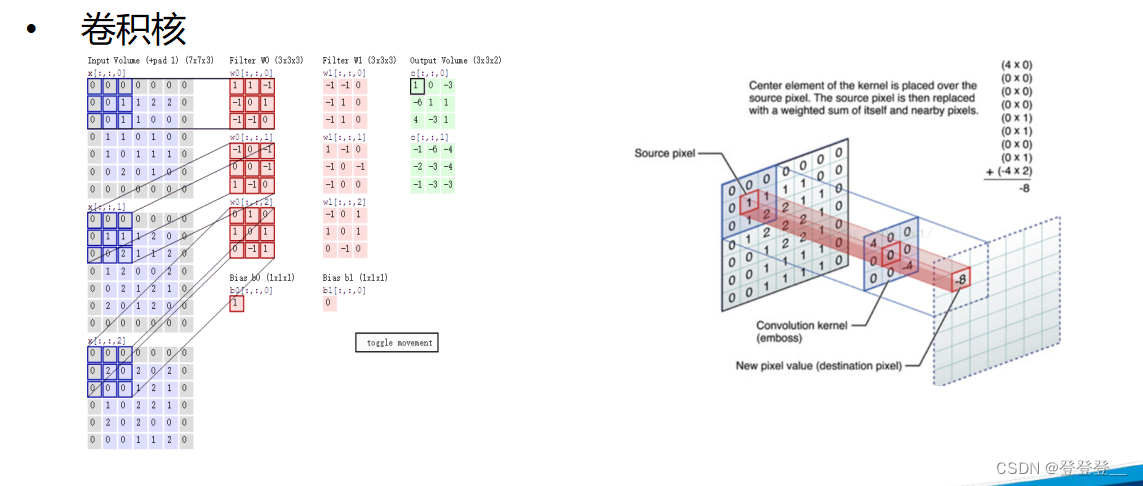
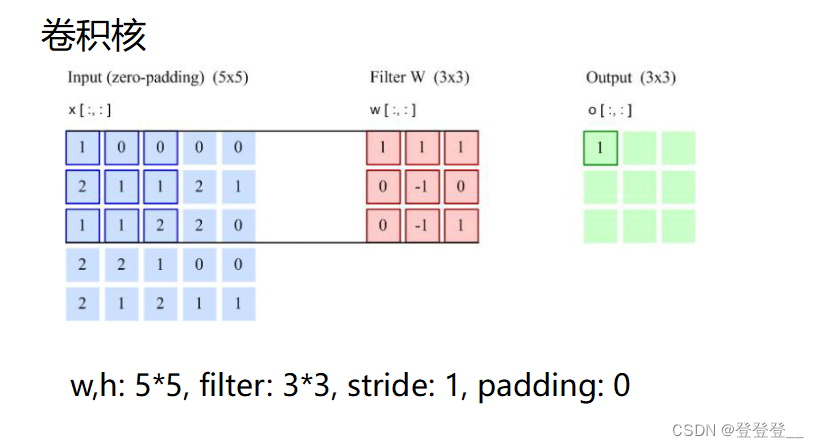
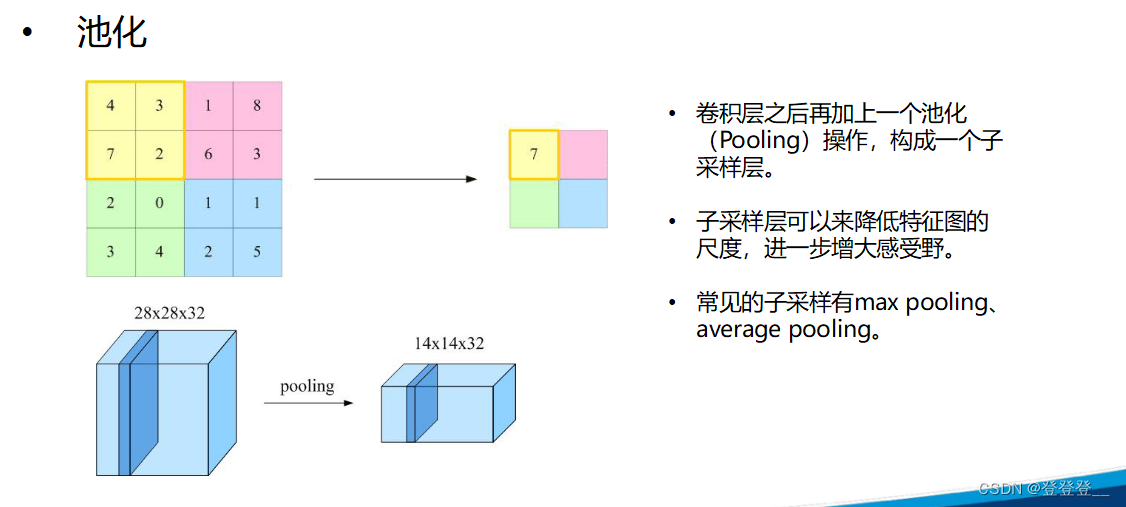
卷积神经网络的基本结构包括输入层、卷积层、池化层、全连接层和输出层。其中,卷积层通过卷积操作提取特征,每个卷积层通常包含多个卷积核,每个卷积核对输入数据进行卷积运算,得到一个特征图。池化层则通过降采样来减少特征图的尺寸,增强模型的鲁棒性和特征提取能力。全连接层将特征映射到一个高维特征空间中,再通过softmax函数进行分类或回归。
卷积神经网络的核心特点是权值共享和局部连接。权值共享是指在卷积层中,同一个卷积核在不同位置上的权值是相同的,这可以大大减少模型参数,提高模型泛化能力。局部连接是指在卷积层中,每个卷积核只与输入数据的一部分进行卷积运算,而不是与整个输入数据进行卷积运算,这样可以提取出局部特征,增强模型的特征提取能力。
卷积神经网络在图像、视频、语音等信号数据的分类和识别任务中如表现出色,图像识别、分类、人脸识别、物体识别、交通标志识别等领域。近年来,卷积神经网络也在自然语言处理任务中展现出有效性。





from PIL import Image
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets('./MNIST_data', one_hot=True)# 定义图
x = tf.placeholder(tf.float32, shape=[None, 784])
y_ = tf.placeholder(tf.float32, shape=[None, 10])x_image = tf.reshape(x, [-1, 28, 28, 1])W_conv1 = tf.Variable(tf.truncated_normal([5, 5, 1, 32], stddev=0.1))
b_conv1 = tf.constant(0.1, shape=[32])h_conv1 = tf.nn.relu(tf.nn.conv2d(x_image, W_conv1, strides=[1, 1, 1, 1], padding='SAME') + b_conv1)
h_pool1 = tf.nn.max_pool(h_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')W_conv2 = tf.Variable(tf.truncated_normal([5, 5, 32, 64], stddev=0.1))
b_conv2 = tf.constant(0.1, shape=[64])h_conv2 = tf.nn.relu(tf.nn.conv2d(h_pool1, W_conv2, strides=[1, 1, 1, 1], padding='SAME') + b_conv2)
h_pool2 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')W_fc1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1024], stddev=0.1))
b_fc1 = tf.constant(0.1, shape=[1024])h_pool2 = tf.reshape(h_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2, W_fc1) + b_fc1)keep_prob = tf.placeholder(tf.float32)
h_fc1 = tf.nn.dropout(h_fc1, keep_prob)W_fc2 = tf.Variable(tf.truncated_normal([1024, 10], stddev=0.1))
b_fc2 = tf.constant(0.1, shape=[10])y_conv = tf.matmul(h_fc1, W_fc2) + b_fc2
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
prediction = tf.argmax(y_conv, 1)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))saver = tf.train.Saver() # defaults to saving all variables
process_train = Falsewith tf.Session() as sess:if process_train:sess.run(tf.global_variables_initializer())for i in range(20000):batch = mnist.train.next_batch(100)_, train_accuracy = sess.run([train_step, accuracy],feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})if i % 100 == 0:print("step %d, training accuracy %g" % (i, train_accuracy))# 保存模型参数,注意把这里改为自己的路径saver.save(sess, './mnist_model/model.ckpt')print("test accuracy %g" % accuracy.eval(feed_dict={x: mnist.test.images,y_: mnist.test.labels, keep_prob: 1.0}))else:saver.restore(sess, "./mnist_model/model.ckpt")pred_file = "./3.png"img_content = Image.open(pred_file)img_content = img_content.resize([28, 28])pred_content = img_content.convert("1")pred_pixel = list(pred_content.getdata()) # get pixel valuespred_pixel = [(255 - x) * 1.0 / 255.0 for x in pred_pixel]pred_num = sess.run(prediction, feed_dict={x: [pred_pixel], keep_prob: 1.0})print('recognize result:')print(pred_num)
自然语言处理NLP
Word Embedding
Word Embedding,即“词嵌入”或“单词嵌入”,是自然语言处理(NLP)中的一组语言建模和特征学习技术的统称,其中词语或短语从词汇表被映射为实数的向量。这些向量通常会捕获词语之间的某种语义或句法关系,从而实现对词汇表中单词的数值化表示。
Word Embedding的主要目标是找到一个低维空间,将每个词从高维空间(词汇表)映射到这个低维空间,并使得语义上相似的词在这个低维空间中的距离较近。这样的映射可以帮助机器学习模型更好地理解和处理文本数据。
Word Embedding的几种常见方法包括:
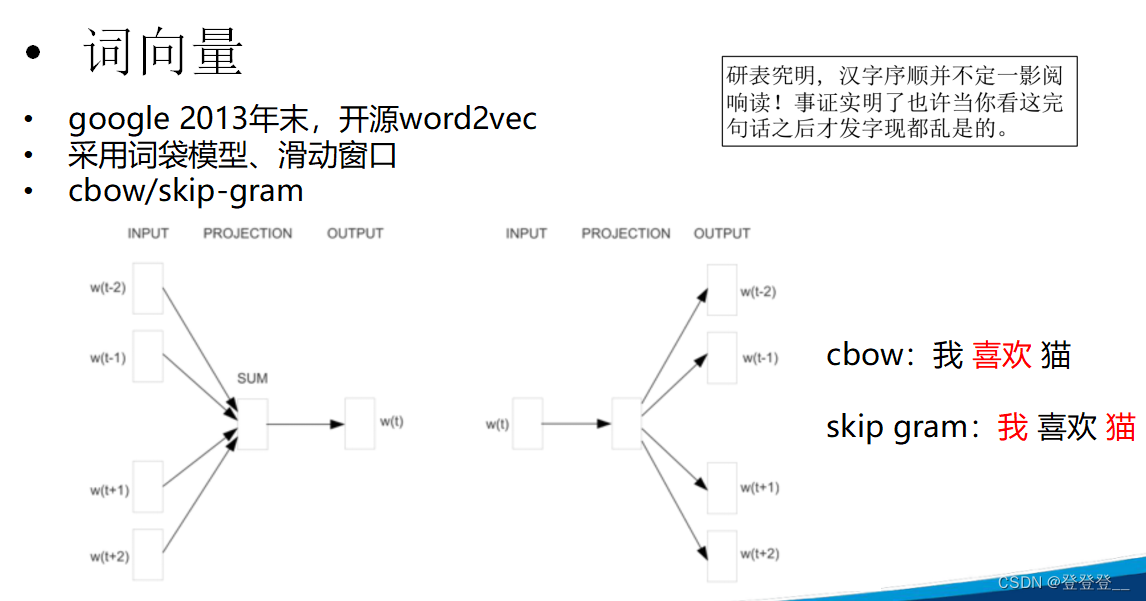
Word2Vec:由Google的研究人员开发,包括Skip-gram和CBOW两种模型。Word2Vec通过训练神经网络来学习词向量,使得具有相似上下文的词具有相似的向量表示。
GloVe:全局向量表示法,基于词语的共现统计信息来生成词向量。它结合了局部上下文窗口方法和全局统计信息,以捕获词的语义关系。
FastText:扩展了Word2Vec,不仅考虑词本身,还考虑词的n-gram信息,以更好地处理未登录词和形态变化。
BERT(Bidirectional Encoder Representations from Transformers):基于Transformer的预训练模型,通过大量的无监督文本数据训练,可以生成上下文相关的词嵌入。BERT的出现极大地推动了NLP领域的发展,尤其是在各种NLP任务中取得了显著的性能提升。
Word Embedding在自然语言处理的许多任务中都发挥了重要作用,如文本分类、情感分析、命名实体识别、问答系统等。通过使用这些预训练的词嵌入,模型可以更好地捕获文本的语义信息,从而提高性能。
词向量





词向量学习方法:LSA、PLSA
LSA,全称Latent Semantic Analysis,中文译为潜在语义分析,是一种基于向量空间模型的文本表示方法。它通过分析文本集合中词语的共现关系,挖掘出词语之间的潜在语义结构,并将文本表示为低维的向量空间中的点,从而实现对文本的高效表示和相似度计算。
LSA的核心思想是将文本中的词语映射到一个低维的潜在语义空间,使得在这个空间中,语义上相似的词语具有相近的表示。这样,即使文本中的词语不完全相同,只要它们具有相似的语义,它们在潜在语义空间中的表示就会很接近。
LSA在文本挖掘、信息检索、自然语言处理等领域有着广泛的应用。它可以帮助我们更好地理解文本的语义内容,提高文本分类、聚类、相似度计算等任务的性能。同时,LSA也可以用于构建语义相关的词典或主题模型,为文本分析和挖掘提供有力的工具。
需要注意的是,虽然LSA在文本表示和语义挖掘方面具有一定的优势,但它也存在一些局限性。例如,LSA对于文本集合的大小和词语的数量比较敏感,当文本集合较大或词语数量较多时,计算量会显著增加。此外,LSA还需要进行参数的选择和调整,以得到最佳的文本表示效果。
总的来说,LSA是一种有效的文本表示和语义挖掘方法,它可以帮助我们更好地理解和处理文本数据。在实际应用中,我们可以根据具体的需求和场景选择合适的LSA算法和参数设置,以得到最佳的文本表示和语义挖掘效果。
PLSA,全称Probabilistic Latent Semantic Analysis,中文译为概率潜在语义分析,是一种基于统计的文本主题模型。它是在LSA(潜在语义分析)的基础上发展而来的,通过引入概率模型来更好地描述文本、词语和主题之间的关系。
PLSA的基本思想是将文本集合中的每个文本看作是由一组潜在的主题按照某种概率分布生成的,而每个主题则是由一组词语按照另一种概率分布生成的。这样,文本、词语和主题之间就形成了一个概率图模型。
在PLSA中,每个文本被表示为一个主题的概率分布,而每个主题则被表示为一个词语的概率分布。通过训练文本集合,可以学习到这些概率分布,并用于后续的任务,如文本分类、聚类、相似度计算等。
相比于LSA,PLSA具有更强的解释性和灵活性。它不仅可以描述文本和词语之间的共现关系,还可以揭示文本和主题、主题和词语之间的深层关联。这使得PLSA在处理文本数据时更加精确和可靠。
然而,PLSA也存在一些局限性。例如,它需要预先设定主题的数量,而这个数量通常很难确定。此外,PLSA的模型复杂度较高,计算量较大,对于大规模的文本集合可能不太适用。
尽管如此,PLSA在文本挖掘和信息检索等领域仍然具有重要的应用价值。它可以有效地挖掘文本的潜在语义结构,提高文本表示和语义理解的准确性。同时,PLSA也可以与其他文本处理技术相结合,形成更强大的文本分析和挖掘系统。
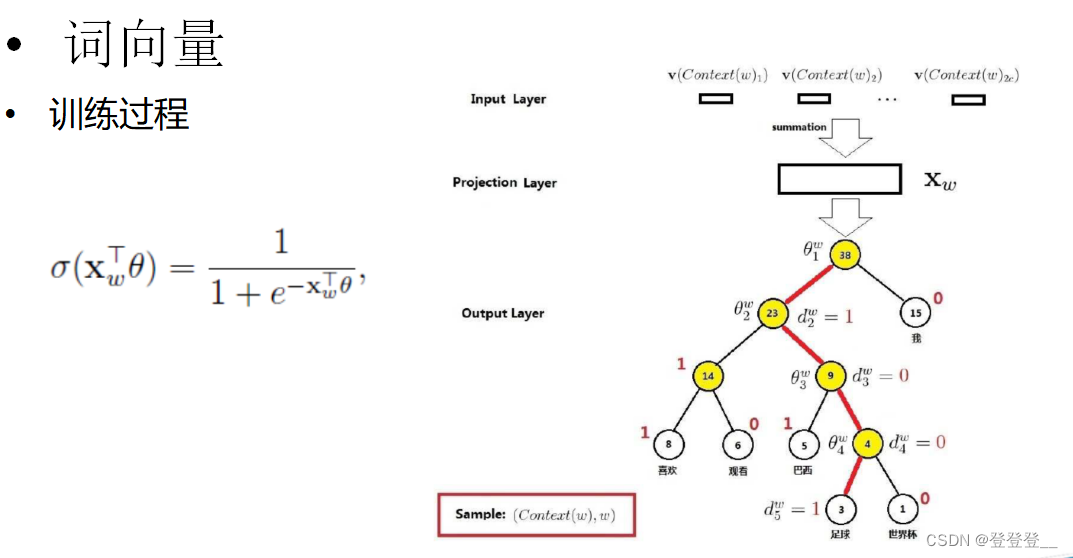
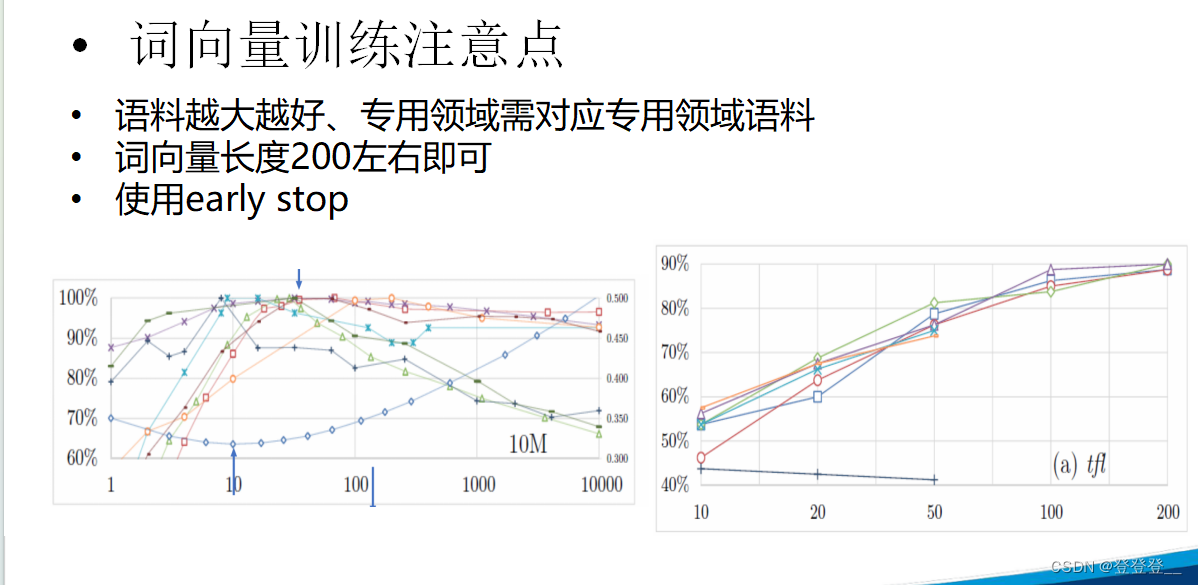
词向量训练
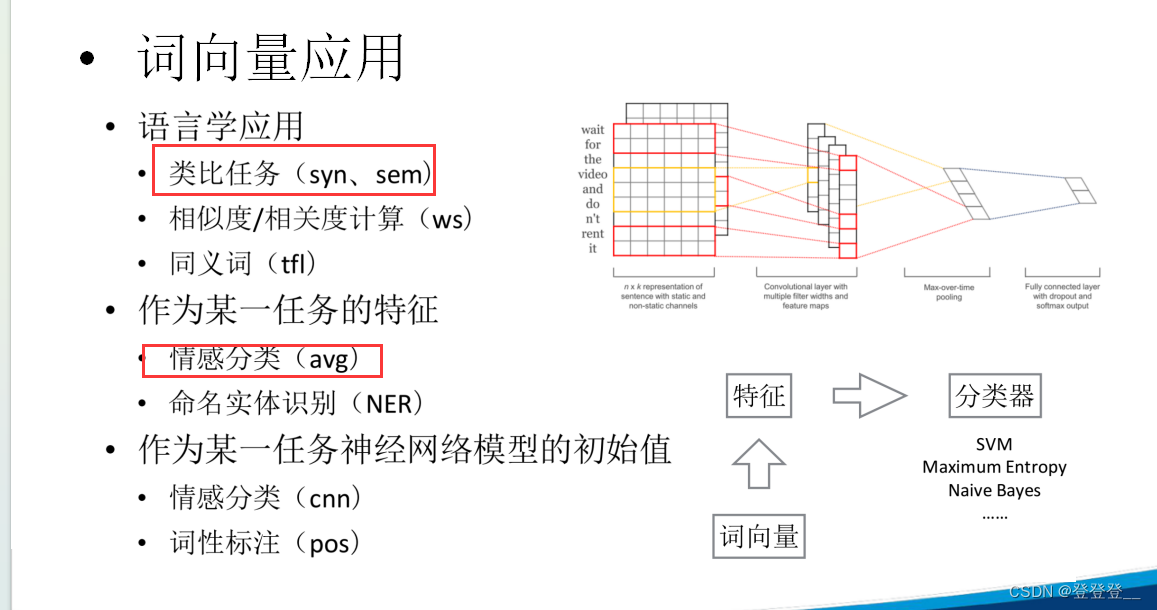
词向量应用
循环神经网络RNN(语义理解)

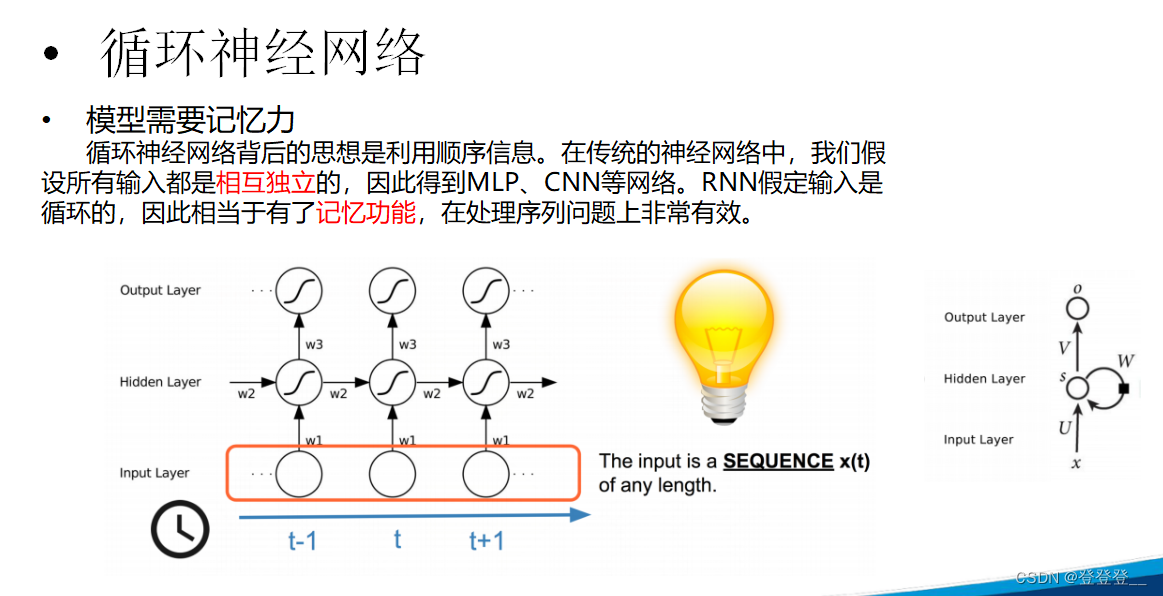
基本原理

基本应用
RNN的缺陷
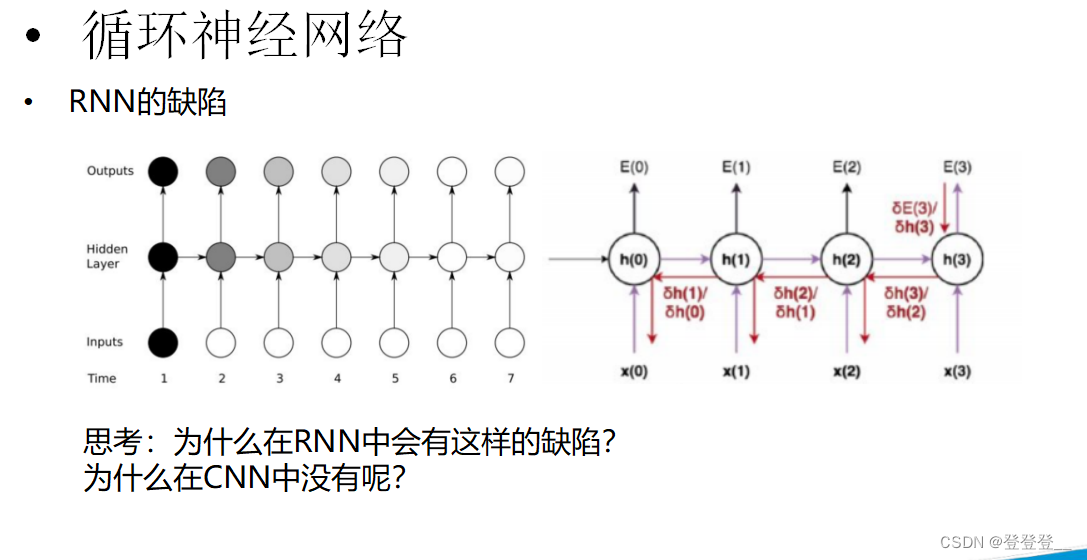
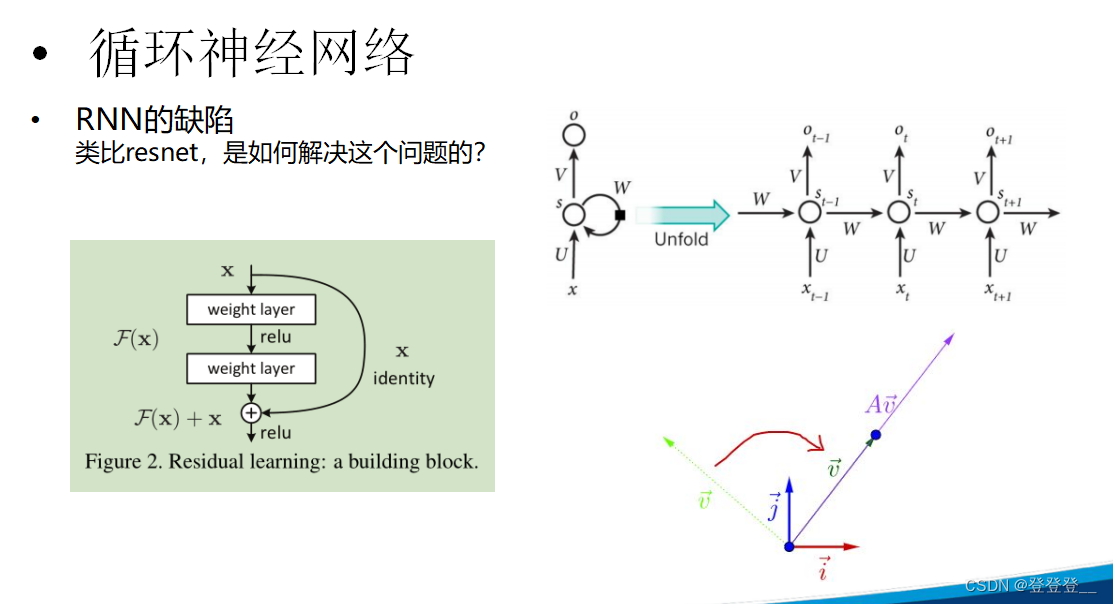
循环神经网络(RNN)在处理序列数据时具有强大的能力,尤其是处理那些前后依赖关系较强的序列数据时。然而,RNN也存在一些缺陷,这些缺陷限制了其在某些任务上的性能和应用范围。以下是RNN的一些主要缺陷:
梯度消失与梯度爆炸:在训练RNN时,梯度在反向传播过程中可能会变得非常小(梯度消失)或非常大(梯度爆炸)。这主要是因为RNN在序列的每个时间步上共享相同的参数,并且在计算梯度时涉及到多个时间步的累积。梯度消失可能导致RNN无法学习到长距离依赖关系,而梯度爆炸则可能导致训练过程不稳定。
难以处理长序列:由于梯度消失问题,RNN在处理长序列时可能会遇到困难。长序列中的信息可能无法在RNN的状态中有效地传递和保留,导致模型无法捕捉到序列的远端依赖关系。
模型结构相对简单:与更复杂的深度学习模型相比,RNN的模型结构相对简单。虽然这有助于减少模型的复杂性和计算量,但也限制了其在处理复杂任务时的性能。例如,RNN可能无法充分捕获序列中的多层次结构和非线性关系。
对输入顺序敏感:RNN在处理序列数据时,对输入的顺序非常敏感。如果序列中的元素顺序发生变化,RNN的性能可能会受到很大影响。这种敏感性在某些任务中可能是有益的,但在其他任务中可能会成为限制。
为了克服这些缺陷,研究者们提出了一系列改进方法,如长短时记忆网络(LSTM)和门控循环单元(GRU)等。这些改进方法通过引入门控机制和记忆单元,增强了RNN处理长序列和捕捉远程依赖关系的能力。此外,随着深度学习技术的不断发展,还涌现出了其他类型的序列模型,如Transformer和BERT等,这些模型在处理序列数据时具有更强的性能和灵活性。
LSTM (特殊的RNN)
练习_聊天机器人实战
相关文章:
深度学习知识与心得
目录 深度学习简介 传统机器学习 深度学习发展 感知机 前馈神经网络 前馈神经网络(BP网络) 深度学习框架讲解 深度学习框架 TensorFlow 一个简单的线性函数拟合过程 卷积神经网络CNN(计算机视觉) 自然语言处理NLP Wo…...

Qt for Android
文章 USB Qt for android 获取USB设备列表(一)Java方式 获取 Qt for android 获取USB设备列表(二)JNI方式 获取 Qt for android 串口库使用 Qt for android : libusb在android中使用 Qt for Android : 使用libusb做CH340x串口传…...

HTTP 的三次握手
HTTP 的三次握手是指在建立 TCP 连接时,客户端和服务器之间进行的三步握手过程。这个过程确保了双方都能够互相通信,并且同步了彼此的序列号和确认号。 概念: 第一次握手:客户端发送一个 SYN(同步…...

【Text2SQL 论文】T5-SR:使用 T5 生成中间表示来得到 SQL
论文:T5-SR: A Unified Seq-to-Seq Decoding Strategy for Semantic Parsing ⭐⭐⭐ 北大 & 中科大,arXiv:2306.08368 文章目录 一、论文速读二、中间表示:SSQL三、Score Re-estimator四、总结 一、论文速读 本文设计了一个 NL 和 SQL 的…...

【HarmonyOS】应用屏蔽截屏和录屏
【HarmonyOS】应用屏蔽截屏和录屏 一、问题背景: 金融类或者高密性质的应用APP,对于截屏和录屏场景,某些业务下是禁止不允许。 目前这种场景的需求也是非常有必要的,很多电诈都是通过远程录屏软件,获取到账户密码或者…...

[BUG历险记] ERROR: [SIM 211-100] CSim failed with errors
问题重现 在开发HLS过程中,我碰到一个奇怪的现象,同样的工程,在我重装完系统后,不能进行C仿真了,但是综合实现都是可以正常运作的。 vitis的报错也非常奇怪,单单一行: ERROR: [SIM 211-100] C…...
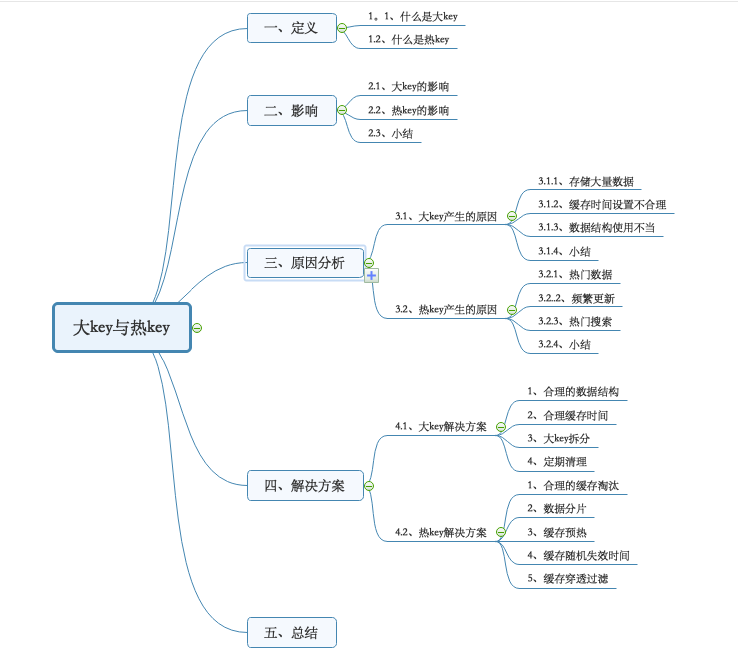
Redis中大Key与热Key的解决方案
原文地址:https://mp.weixin.qq.com/s/13p2VCmqC4oc85h37YoBcg 在工作中Redis已经成为必备的一款高性能的缓存数据库,但是在实际的使用过程中,我们常常会遇到两个常见的问题,也就是文章标题所说的大 key与热 key。 一、定义 1.1…...
)
MySQL 视图(2)
上一篇:MySQL视图(1) 基于其他视图 案例对 WITH [CASCADED | LOCAL] CHECK OPTION 进行释义 创建视图时,可以基于表 / 多个表,也可以使用 其他视图表 / 其他视图 其他视图 的方式进行组合。 总结 更新视图&#x…...

Leecode---技巧---颜色分类、下一个排列、寻找重复数
思路: 遍历一遍记录0,1,2的个数,然后再遍历一次,按照0,1,2的个数修改nums即可。 class Solution { public:void sortColors(vector<int>& nums){int n0 0, n1 0, n2 0;for(int x: nums){if(x0) n0;else if(x1) n1;else n2;}for…...

ERC-7401:嵌套 NFT 标准的全新篇章
在数字资产和区块链技术迅速发展的今天,非同质化代币(NFT)已经成为了一种重要的资产形式,广泛应用于艺术、游戏、收藏品等多个领域。随着市场需求的多样化,传统的 NFT 标准如 ERC-721 和 ERC-1155 已经不能完全满足用户…...

代码随想录算法训练营Day6| 242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和
242.有效的字母异位词 知识点补充: 1.遍历HashMap中的值: HashMap<Integer,Integer> map new HashMap<Integer,Integer>(); for(Integer num:map.values()){ } 2.遍历HashMap的键: HashMap<Integer,Integer> map new Ha…...
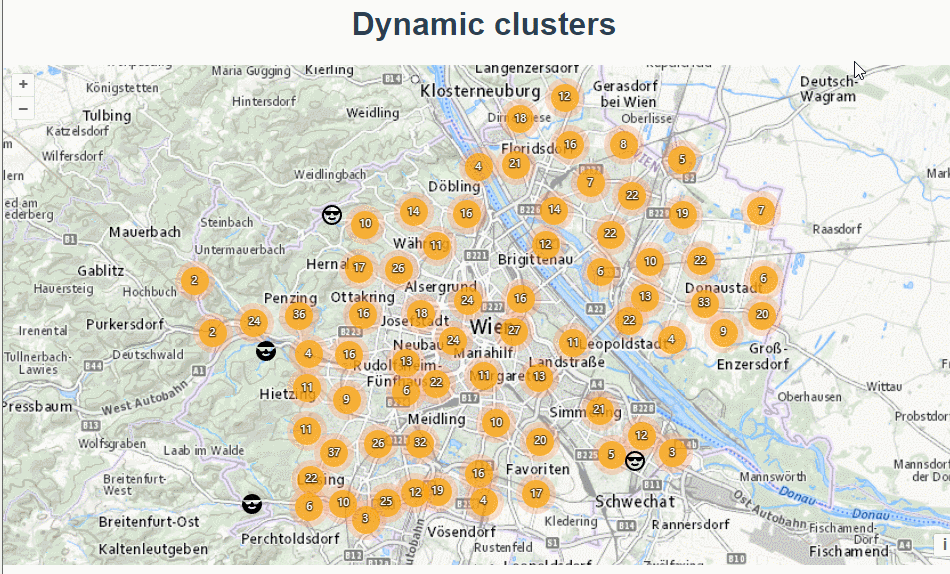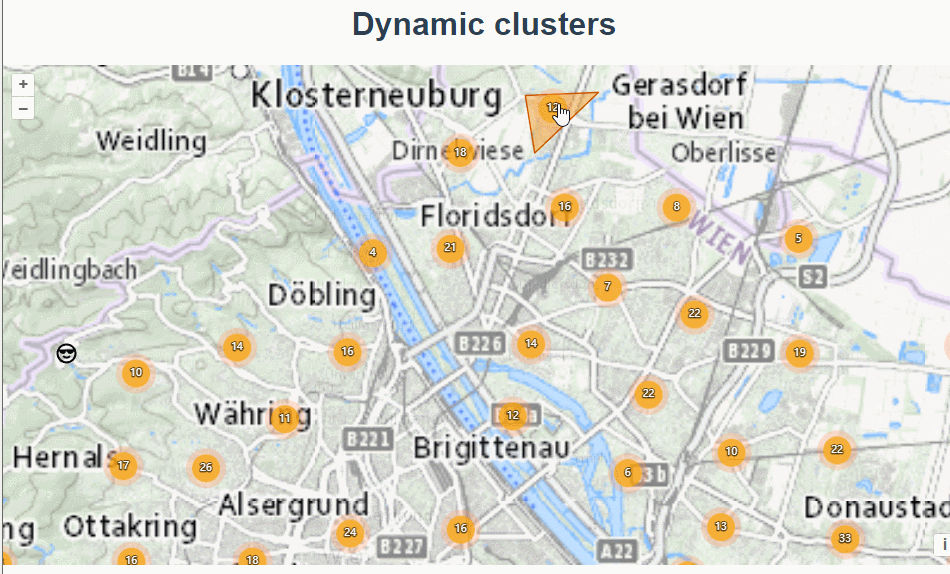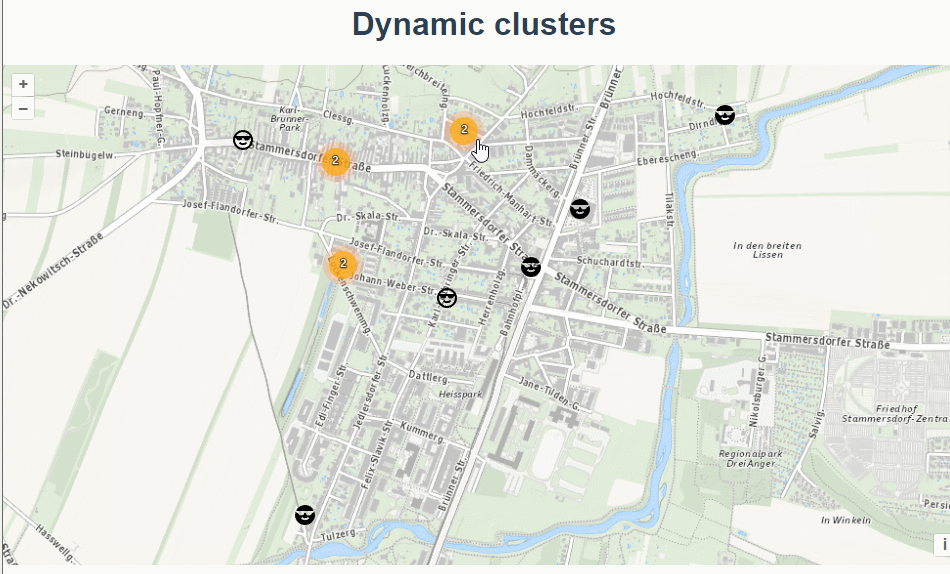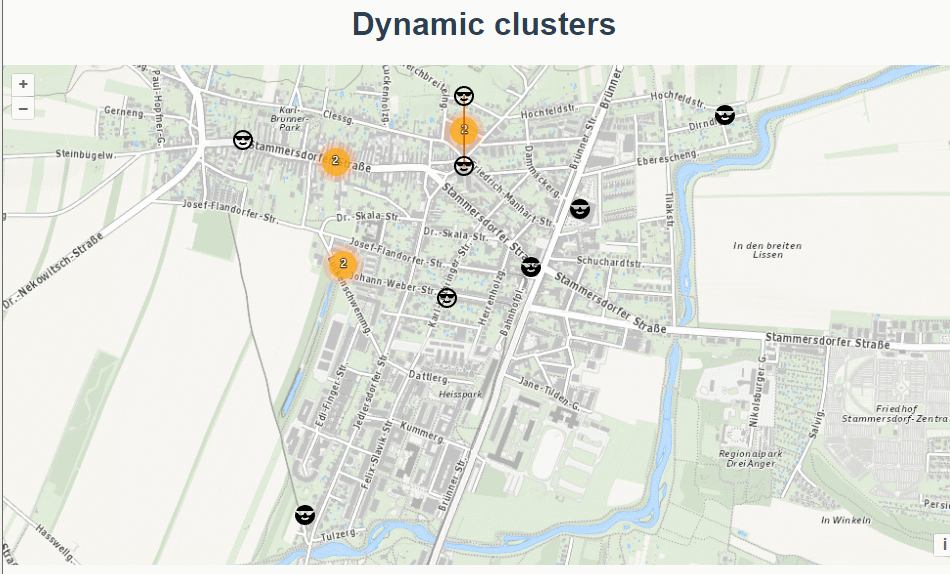
三十四、openlayers官网示例Dynamic clusters解析——动态的聚合图层
官网demo地址: https://openlayers.org/en/latest/examples/clusters-dynamic.html 这篇绘制了多个聚合图层。 先初始化地图 ,设置了地图视角的边界extent,限制了地图缩放的范围 initMap() {const raster new TileLayer({source: new XYZ…...
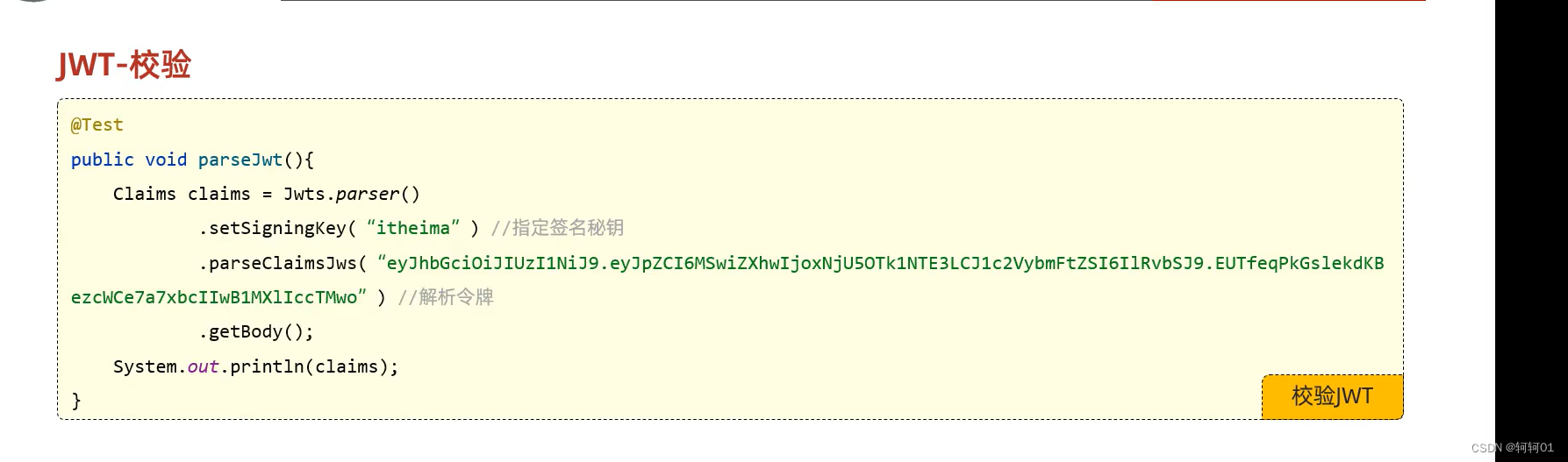
SpringBoot登录认证--衔接SpringBoot案例通关版
文章目录 登录认证登录校验-概述登录校验 会话技术什么是会话呢?cookie Session令牌技术登录认证-登录校验-JWT令牌-介绍JWT SpringBoot案例通关版,上接这篇 登录认证 先讲解基本的登录功能 登录功能本质就是查询操作 那么查询完毕后返回一个Emp对象 如果Emp对象不为空,那…...
vue3状态管理,pinia的使用
状态管理 我们知道组件与组件之间可以传递信息,那么我们就可以将一个信息作为组件的独立状态(例如,单个组件的颜色)或者共有状态(例如,多个组件是否显示)在组件之传递,…...
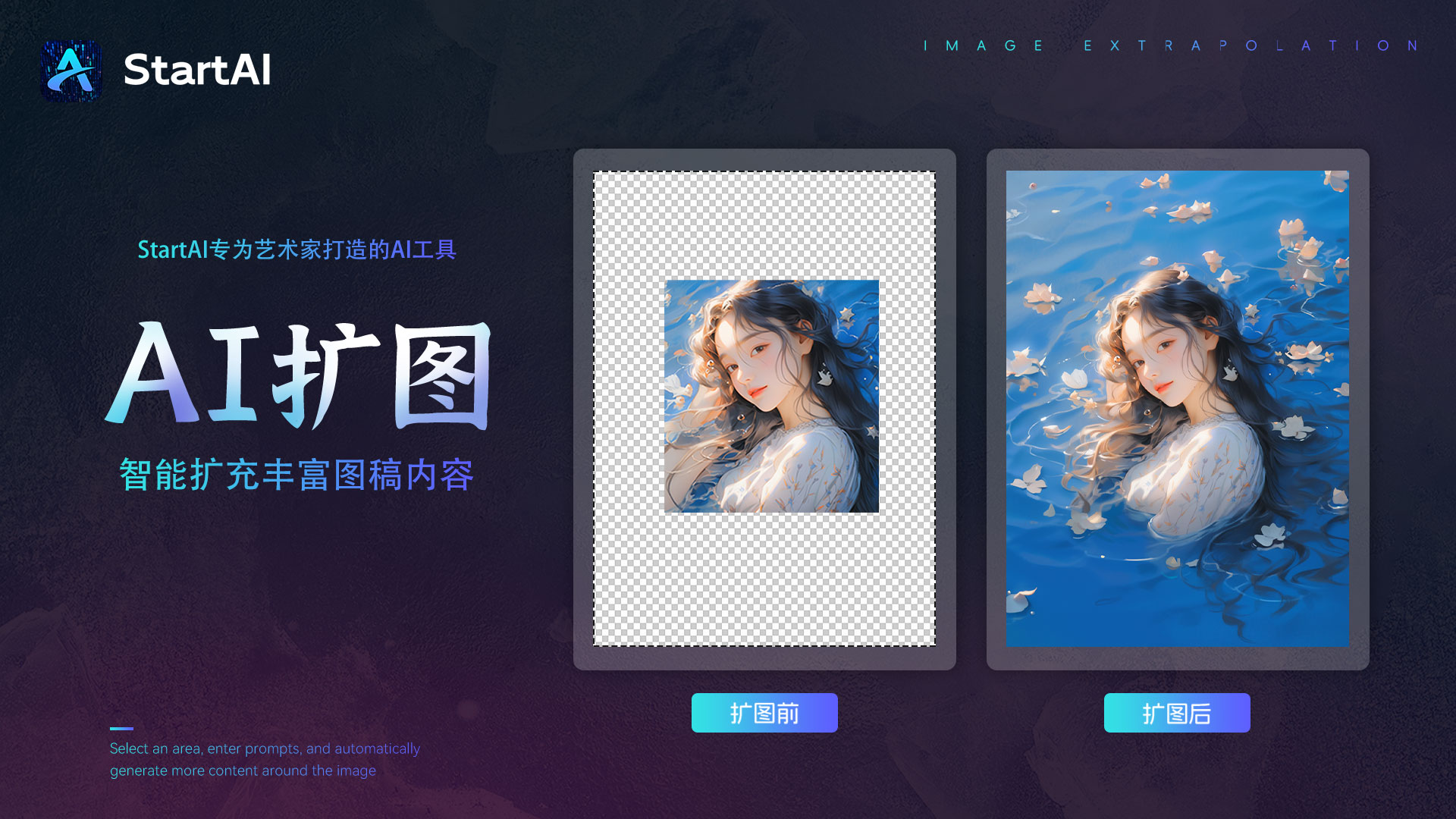
入门到实践,手把手教你用AI绘画!
前言 一款无需魔法的PS插件!下载即用,自带提示词插件,无论你是小白还是大神都能轻松上手,无配置要求,win/mac通通能用! AI绘画工具——StartAI 官网:StartAI官网 (istarry.com.cn) 近段时间…...

大模型应用框架-LangChain
LangChain的介绍和入门 💥 什么是LangChain LangChain由 Harrison Chase 创建于2022年10月,它是围绕LLMs(大语言模型)建立的一个框架,LLMs使用机器学习算法和海量数据来分析和理解自然语言,GPT3.5、GPT4是…...

探索Linux中的强大文本处理工具——sed命令
探索Linux中的强大文本处理工具——sed命令 在Linux系统中,文本处理是一项日常且重要的任务。sed命令作为一个流编辑器,以其强大的文本处理能力而著称。它允许我们在不修改原始文件的情况下,对输入流(文件或管道)进行…...

冯喜运:6.3黄金原油晚间最新行情及独家操作策略指导
【黄金消息面分析】:在全球经济的波动和不确定性中,黄金作为传统的避险资产,其价格走势和市场分析一直是投资者关注的焦点。本周一(北京时间6月3日),现货黄金价格基本持平,交易商正在等待本周公…...

Spark_SparkOnHive_海豚调度跑任务写入Hive表失败解决
背景 前段时间我在海豚上打包程序写hive出现了一个问题,spark程序向hive写数据时,报了如下bug, org.apache.spark.sql.AnalysisException: The format of the existing table test.xx is HiveFileFormat It doesnt match the specified for…...
SaaS 电商设计 (十一) 那些高并发电商系统的限流方案设计
目录 一.什么是限流二.怎么做限流呢2.1 有哪些常见的系统限流算法2.1.1 固定窗口2.1.1 滑动窗口2.1.2 令牌桶2.1.3 漏桶算法 2.2 常见的限流方式2.2.1 单机限流&集群限流2.2.2 前置限流&后置限流 2.3 实际落地是怎么做的2.3.1 流量链路2.3.2 各链路限流2.3.2.1 网关层2…...

新手福音:在快马平台上零配置运行第一个yolov11检测程序
今天想和大家分享一个特别适合深度学习新手的体验——在InsCode(快马)平台上零配置运行第一个yolov11目标检测程序。作为计算机视觉的入门项目,目标检测既能带来直观的视觉反馈,又能快速建立成就感,但传统方式的环境配置往往让初学者望而却步…...

AI服务的可观测性与运维
AI服务的可观测性与运维 当 AI 服务从开发环境走向生产,可观测性(Observability)成为运维的基石。传统的监控(CPU、内存、请求量)已不足以应对 AI 系统的复杂性,我们需要深入追踪 每个 AI 交互的细节&#…...

第八章:实战项目案例
第八章:实战项目案例 8.1 项目一:Todo 应用(Vue 3 Pinia) 项目初始化 npm create vitelatest todo-app -- --template vue cd todo-app npm install pinia npm install -D vitejs/plugin-vue项目结构 todo-app/ ├── src/ …...

告别背包焦虑:TQVaultAE如何彻底改变《泰坦之旅》装备管理体验
告别背包焦虑:TQVaultAE如何彻底改变《泰坦之旅》装备管理体验 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 对于《泰坦之旅》玩家来说,最令人沮丧…...

顺丰控股年营收3082亿:净利111亿 现金分红21亿
雷递网 雷建平 4月5日顺丰控股(证券代码:002352)日前发布截至2025年12月31日的财报。财报显示,顺丰控股2025年营收3082.27亿,较上年同期的2844亿元增长8.37%。顺丰控股2025年时效快递业务实现营业收入1,310.5亿元&…...

QueryExcel:解锁3大核心功能的多Excel文件极速查询指南
QueryExcel:解锁3大核心功能的多Excel文件极速查询指南 【免费下载链接】QueryExcel 多Excel文件内容查询工具。 项目地址: https://gitcode.com/gh_mirrors/qu/QueryExcel 直击痛点:数据查询的效率困境 场景一:财务报表核对 月底需从…...
)
Mamba实战:如何用选择性状态空间模型提升你的长序列处理效率(附代码)
Mamba实战:如何用选择性状态空间模型提升你的长序列处理效率(附代码) 在自然语言处理、基因组学和金融时间序列分析等领域,处理长序列数据一直是个棘手的问题。传统Transformer架构虽然强大,但随着序列长度增加&#x…...

零基础玩转YOLO11目标跟踪:完整环境一键部署教程
零基础玩转YOLO11目标跟踪:完整环境一键部署教程 1. 环境准备与快速部署 1.1 系统要求 操作系统:Linux (推荐Ubuntu 20.04/22.04)硬件配置: GPU:NVIDIA显卡 (建议RTX 3060及以上)显存:至少8GB内存:16GB及…...

Nano-Banana在.NET开发中的应用:智能业务逻辑实现
Nano-Banana在.NET开发中的应用:智能业务逻辑实现 将AI能力无缝集成到企业级应用中,让智能业务逻辑开发变得简单高效 1. 开篇:当.NET遇见AI智能业务逻辑 如果你正在开发.NET企业级应用,可能会遇到这样的场景:需要智能…...

碧蓝航线Alas脚本新手通关指南:从安装到精通的4个关键阶段
碧蓝航线Alas脚本新手通关指南:从安装到精通的4个关键阶段 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 碧蓝航…...