Redis中大Key与热Key的解决方案
原文地址:https://mp.weixin.qq.com/s/13p2VCmqC4oc85h37YoBcg
在工作中Redis已经成为必备的一款高性能的缓存数据库,但是在实际的使用过程中,我们常常会遇到两个常见的问题,也就是文章标题所说的大 key与热 key。
一、定义
1.1、什么是大key
-
大 key指的是一个键中包含了大量的数据。(总结一个字就是大)-
占用空间:
大key通常指的是一个键包含了大量的数据,使得该键对应值的占用的内存超出了正常范围。这个大小的阈值并不是固定的,而是相对于 Redis 实例的可用内存而言。当一个键的大小超出了 Redis 实例可用内存时,就可以认为它是一个大key。 -
操作耗时:如果对一个 key 的操作所需的时间过长,导致性能下降或者影响其他请求的处理速度,也可以说这个 key 是
大key。因为这种情况通常是由于该 key 下包含了大量的数据。
-
1.2、什么是热key
-
热 key指的是频繁访问的键。(总结就是热,访问频繁。)-
频繁访问:在某一段时间内被频繁访问的 key 就是
热key。 -
业务方面:比如商城促销的场景下,某个商品的缓存可能就会成为
热key。这种情况下热key反应的不仅是该键的访问频率高,还反映了用户对某个业务功能的热度。 -
性能方面:
热key的频繁访问造成 Redis 的 CPU 占用率过高,造成响应时间延长或者请求阻塞,从而造成系统崩溃。
-
key的大与不大,热与不热要根据自己的业务,从实际情况进行评估。
二、影响
2.1、大 key 的影响
- 内存消耗: 在进行缓存时降低缓存的效率,占用大量的内存空间,使得 Redis 的内存消耗急剧增加,还可能导致 Redis 实例的内存资源不足,甚至出发内存淘汰策略,从而影响系统的正常运行。
- 性能下降:处理大的 key,会耗费更多的 CPU 时间以及带宽,导致 Redis 性能下降。由于 Redis 还是单线程的,处理
大key的操作进而会阻塞其他请求的处理,从而影响系统性能。 - 持久化效率降低: 在进行持久化操作时,
AOF与RDB都会因为该大key耗费更多的时间,从而延迟持久化时间,分布式环境下甚至会造成缓存不一致。 - 网络传输延迟:
大key在进行网络传输时会增加网络传输的延迟,在分布式环境下进行数据同步时可能会造成数据的不一致。
2.2、热 key 的影响
- CPU占用率高: 因为是
热key,所以 CPU 一直占用,进而导致Redis实例的CPU负载增加。 - 请求阻塞:如果 key 有访问优先级,
热key的存在可能导致请求队列中其他的请求被阻塞。 - 响应时间延长:因为
热key,其他的请求被阻塞了造成响应时间延长。 - 性能不均衡:流量访问造成突刺,系统性能的不均衡。
2.3、小结
大key 与 热key 都会给 Redis 实例造成一系列的影响,如内存占用过高,CPU 负载增加,持久化时间变长,性能下降等。
三、原因分析
3.1、大 key 产生的原因
产生 大key 的原因有很多种,下面咱就一起看一下工作中经常遇到的这几种。
3.1.1、存储大量数据
存储了大量数据也是我们经常遇到 大key 的最多的原因了。
比如 String 类型直接保存了一个大的文本或者二进制数据;Hash 结构中存储大量的键值对。
- String
SET zuiyu_large_text_key "very large text content..."
- Hash
HMSET zuiyu_large_hash_key field1 value1 field2 value2 ... fieldN valueN3.1.2、缓存时间设置不合理
缓存时间设置不合理这个造成 大key 的原因大概是个隐藏挺深的老 bug,有的业务场景,使用 Redis 缓存数据,业务是定时往该 key 上写数据,由于该 key 是没有设置缓存时间的造成这个 key 随着时间的流逝,占用的内存越来越多,对于该点,只需要设置一个合理的过期时间即可。
前提是多次写入
不是覆盖,而是追加才会有该问题。
SETEX zuiyu_key_with_expiry value 3600 # 设置过期时间为3600秒3.1.3、数据结构使用不当
在使用 List 数据结构存储数据时,重复的添加数据,造成该 key 越来越大,实际上业务是不需要有重复的数据存在的。
- List
LPUSH zuiyu_large_list_key value3.1.4、小结
大key 的产生根本原因就是在一个 key 下面存储的数据多了。
3.2、热 key 产生的原因
3.2.1、热门数据
热key 的产生一般意味着系统访问火爆了,但是火爆的只是其中一个点或者n个点。类似微博中某个明星的瓜,当上头条的时候,大量的人去访问,造成了该明星所对应的 key 成为 热key。
3.2.2、频繁的更新
某些业务场景,单位时间内一直频繁的对 key 进行更新,该 key 也会成为 热key。
3.2.3、热门搜索
类似于第一中的热门数据,产生了热门数据,该数据对应的热门关键词也被大量的用户去搜索,造成该关键词被频繁访问,最终导致该 key 也称为 热key。
3.2.4、小结
热key 的产生无外乎热门数据,热门数据产生的热门关键词以及对同一个 key 在某段时间内的频繁访问。
四、解决方案
4.1、大key的解决方案
- 合理的数据结构
- 合理的缓存时间
大key进行拆分为多个小key- 定期对
大key进行清理
4.2、热key的解决方案
- 合理的缓存淘汰策略
- 热点数据分片
将热点数据分散到不同的Redis实例,提升系统的吞吐量。
- 缓存预热
在系统启动或者活动高峰开启之前进行缓存预热,提前将需要的数据加载到缓存,减少热点数据首次访问的时间。
- 随机缓存失效时间
避免大量的key同一时间批量失效,造成缓存雪崩与缓存穿透。
- 缓存穿透
使用布隆过滤器进行缓存请求过滤,防止无效请求进入到缓存层。
五、总结
针对 大key 我们要尽可能的避免同一个 key 下大量的数据。
针对 热key 我们要合理设置过期时间,增加布隆过滤器等技术实现无效请求过滤,对即将到来的数据进行缓存预热、热点数据分片处理。
WX 搜索《醉鱼Java》,回复面试,获取2024面试资料。
如果这篇文章对您有所帮助或者启发,帮忙点个关注叭,您的支持是我坚持写作的最大动力。
求一键三连:点赞、收藏、关注。
谢谢支持哟 (__)。
相关文章:
Redis中大Key与热Key的解决方案
原文地址:https://mp.weixin.qq.com/s/13p2VCmqC4oc85h37YoBcg 在工作中Redis已经成为必备的一款高性能的缓存数据库,但是在实际的使用过程中,我们常常会遇到两个常见的问题,也就是文章标题所说的大 key与热 key。 一、定义 1.1…...
)
MySQL 视图(2)
上一篇:MySQL视图(1) 基于其他视图 案例对 WITH [CASCADED | LOCAL] CHECK OPTION 进行释义 创建视图时,可以基于表 / 多个表,也可以使用 其他视图表 / 其他视图 其他视图 的方式进行组合。 总结 更新视图&#x…...

Leecode---技巧---颜色分类、下一个排列、寻找重复数
思路: 遍历一遍记录0,1,2的个数,然后再遍历一次,按照0,1,2的个数修改nums即可。 class Solution { public:void sortColors(vector<int>& nums){int n0 0, n1 0, n2 0;for(int x: nums){if(x0) n0;else if(x1) n1;else n2;}for…...

ERC-7401:嵌套 NFT 标准的全新篇章
在数字资产和区块链技术迅速发展的今天,非同质化代币(NFT)已经成为了一种重要的资产形式,广泛应用于艺术、游戏、收藏品等多个领域。随着市场需求的多样化,传统的 NFT 标准如 ERC-721 和 ERC-1155 已经不能完全满足用户…...

代码随想录算法训练营Day6| 242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和
242.有效的字母异位词 知识点补充: 1.遍历HashMap中的值: HashMap<Integer,Integer> map new HashMap<Integer,Integer>(); for(Integer num:map.values()){ } 2.遍历HashMap的键: HashMap<Integer,Integer> map new Ha…...
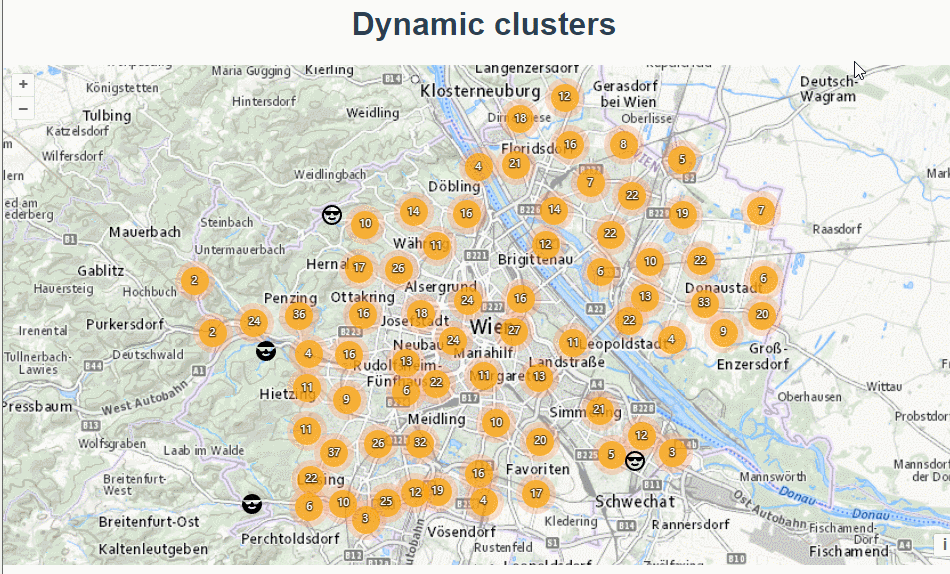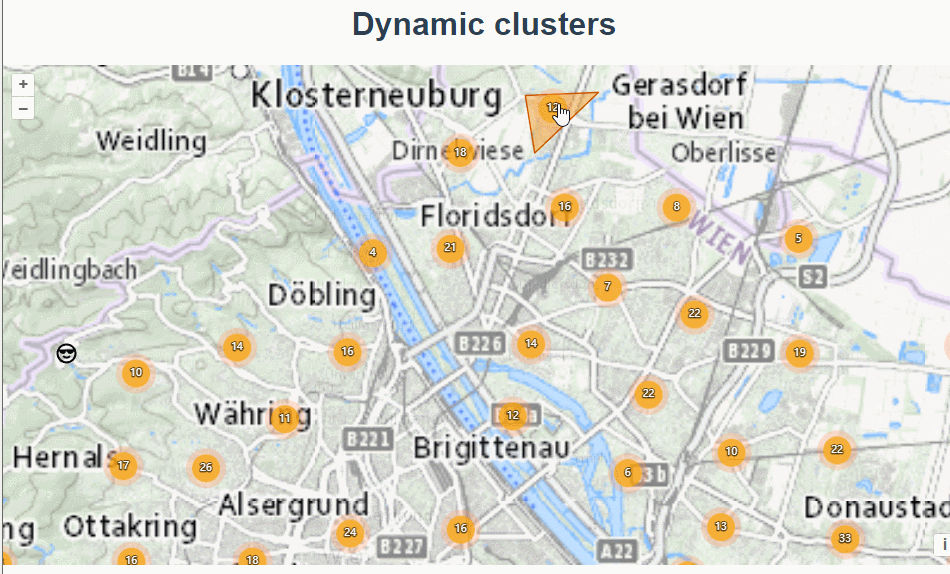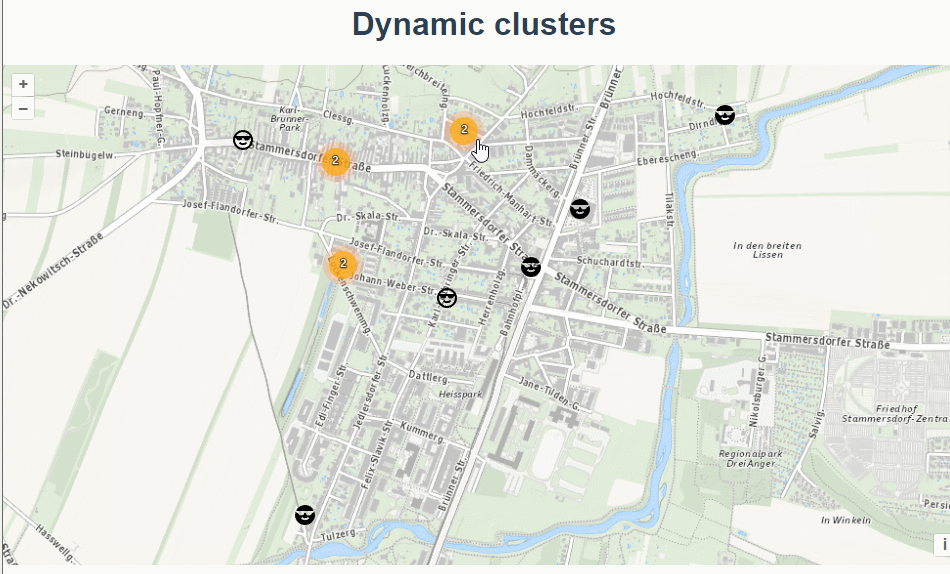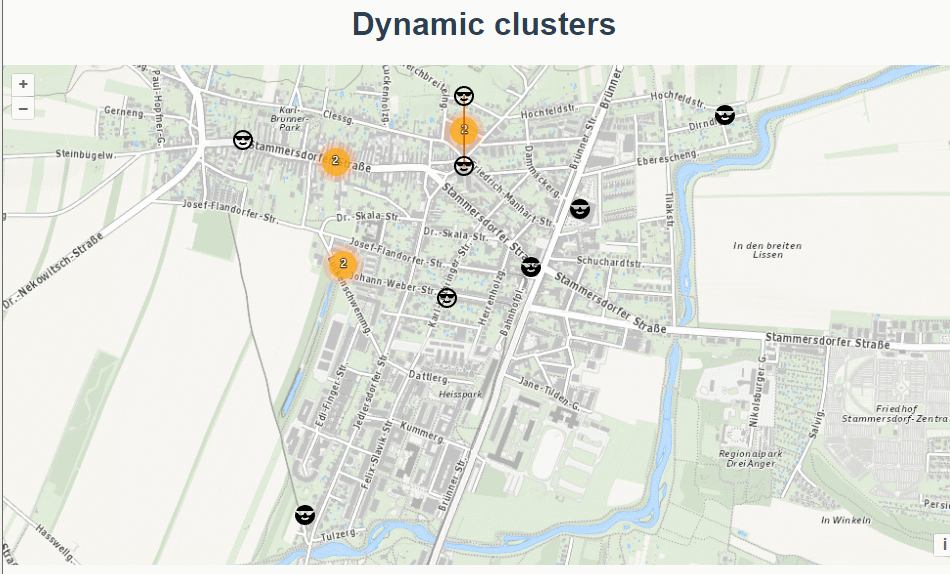
三十四、openlayers官网示例Dynamic clusters解析——动态的聚合图层
官网demo地址: https://openlayers.org/en/latest/examples/clusters-dynamic.html 这篇绘制了多个聚合图层。 先初始化地图 ,设置了地图视角的边界extent,限制了地图缩放的范围 initMap() {const raster new TileLayer({source: new XYZ…...
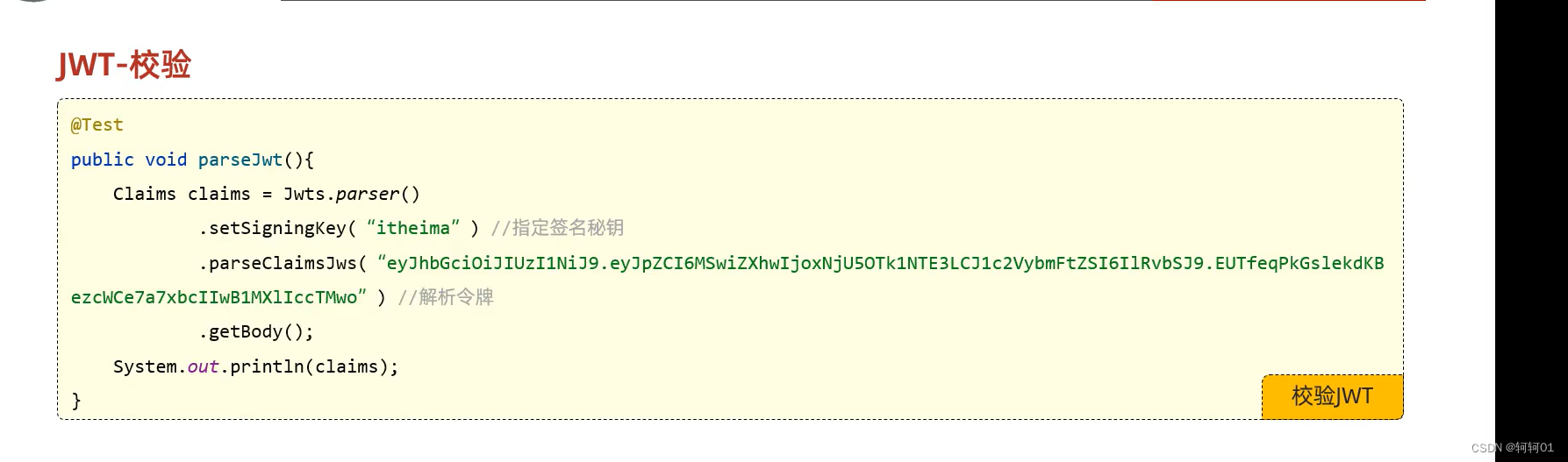
SpringBoot登录认证--衔接SpringBoot案例通关版
文章目录 登录认证登录校验-概述登录校验 会话技术什么是会话呢?cookie Session令牌技术登录认证-登录校验-JWT令牌-介绍JWT SpringBoot案例通关版,上接这篇 登录认证 先讲解基本的登录功能 登录功能本质就是查询操作 那么查询完毕后返回一个Emp对象 如果Emp对象不为空,那…...
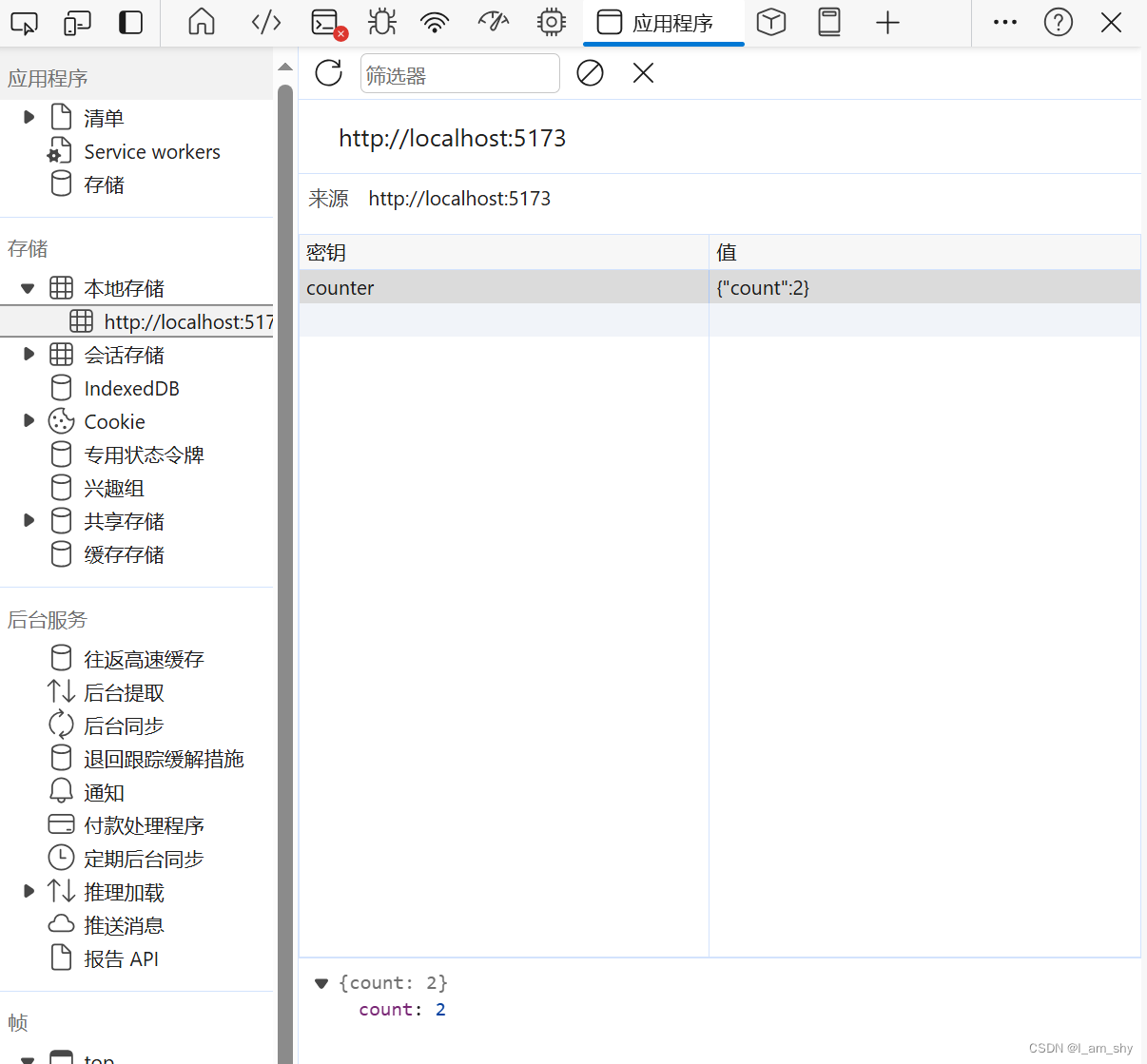
vue3状态管理,pinia的使用
状态管理 我们知道组件与组件之间可以传递信息,那么我们就可以将一个信息作为组件的独立状态(例如,单个组件的颜色)或者共有状态(例如,多个组件是否显示)在组件之传递,…...
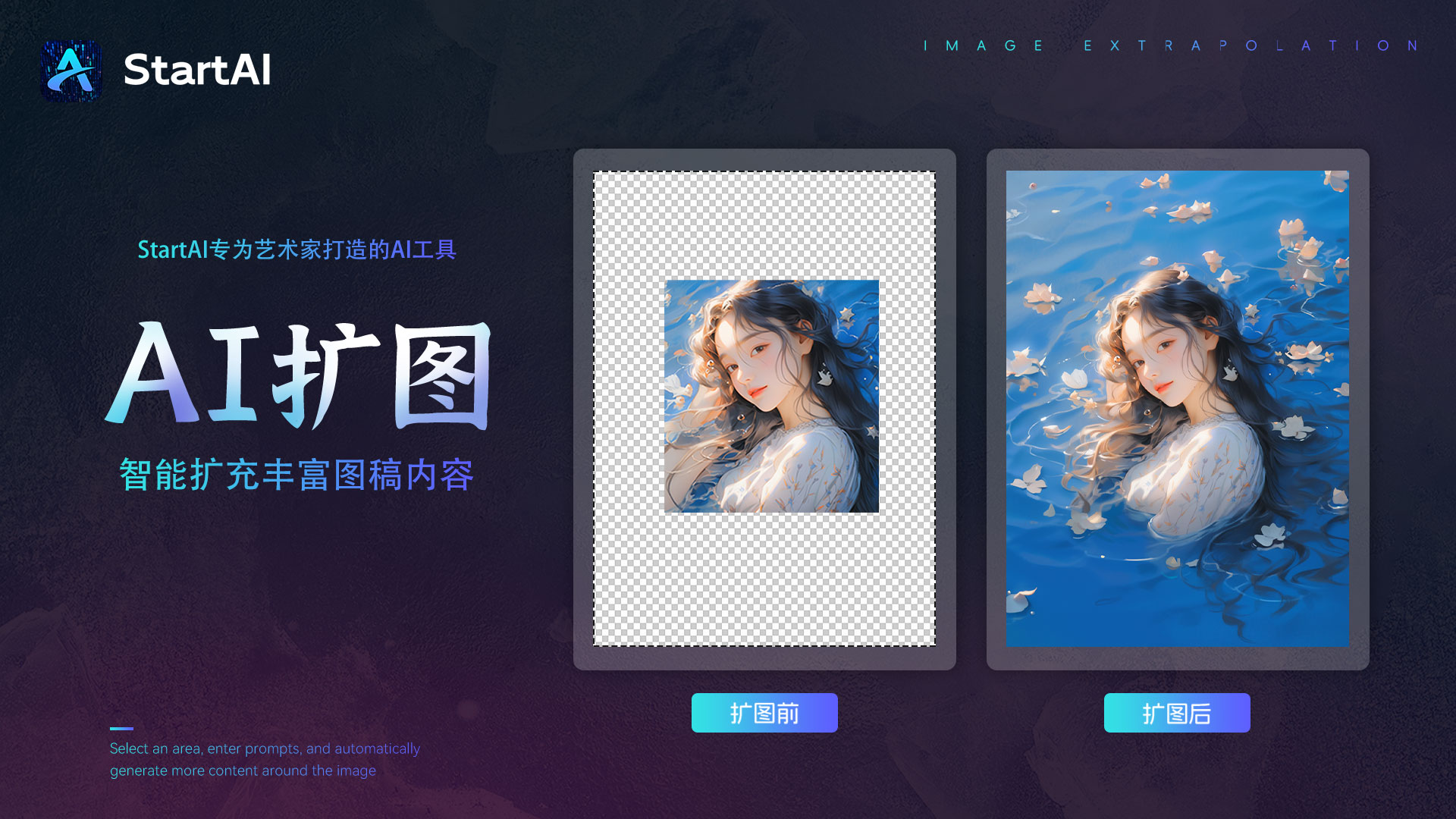
入门到实践,手把手教你用AI绘画!
前言 一款无需魔法的PS插件!下载即用,自带提示词插件,无论你是小白还是大神都能轻松上手,无配置要求,win/mac通通能用! AI绘画工具——StartAI 官网:StartAI官网 (istarry.com.cn) 近段时间…...

大模型应用框架-LangChain
LangChain的介绍和入门 💥 什么是LangChain LangChain由 Harrison Chase 创建于2022年10月,它是围绕LLMs(大语言模型)建立的一个框架,LLMs使用机器学习算法和海量数据来分析和理解自然语言,GPT3.5、GPT4是…...

探索Linux中的强大文本处理工具——sed命令
探索Linux中的强大文本处理工具——sed命令 在Linux系统中,文本处理是一项日常且重要的任务。sed命令作为一个流编辑器,以其强大的文本处理能力而著称。它允许我们在不修改原始文件的情况下,对输入流(文件或管道)进行…...

冯喜运:6.3黄金原油晚间最新行情及独家操作策略指导
【黄金消息面分析】:在全球经济的波动和不确定性中,黄金作为传统的避险资产,其价格走势和市场分析一直是投资者关注的焦点。本周一(北京时间6月3日),现货黄金价格基本持平,交易商正在等待本周公…...

Spark_SparkOnHive_海豚调度跑任务写入Hive表失败解决
背景 前段时间我在海豚上打包程序写hive出现了一个问题,spark程序向hive写数据时,报了如下bug, org.apache.spark.sql.AnalysisException: The format of the existing table test.xx is HiveFileFormat It doesnt match the specified for…...
SaaS 电商设计 (十一) 那些高并发电商系统的限流方案设计
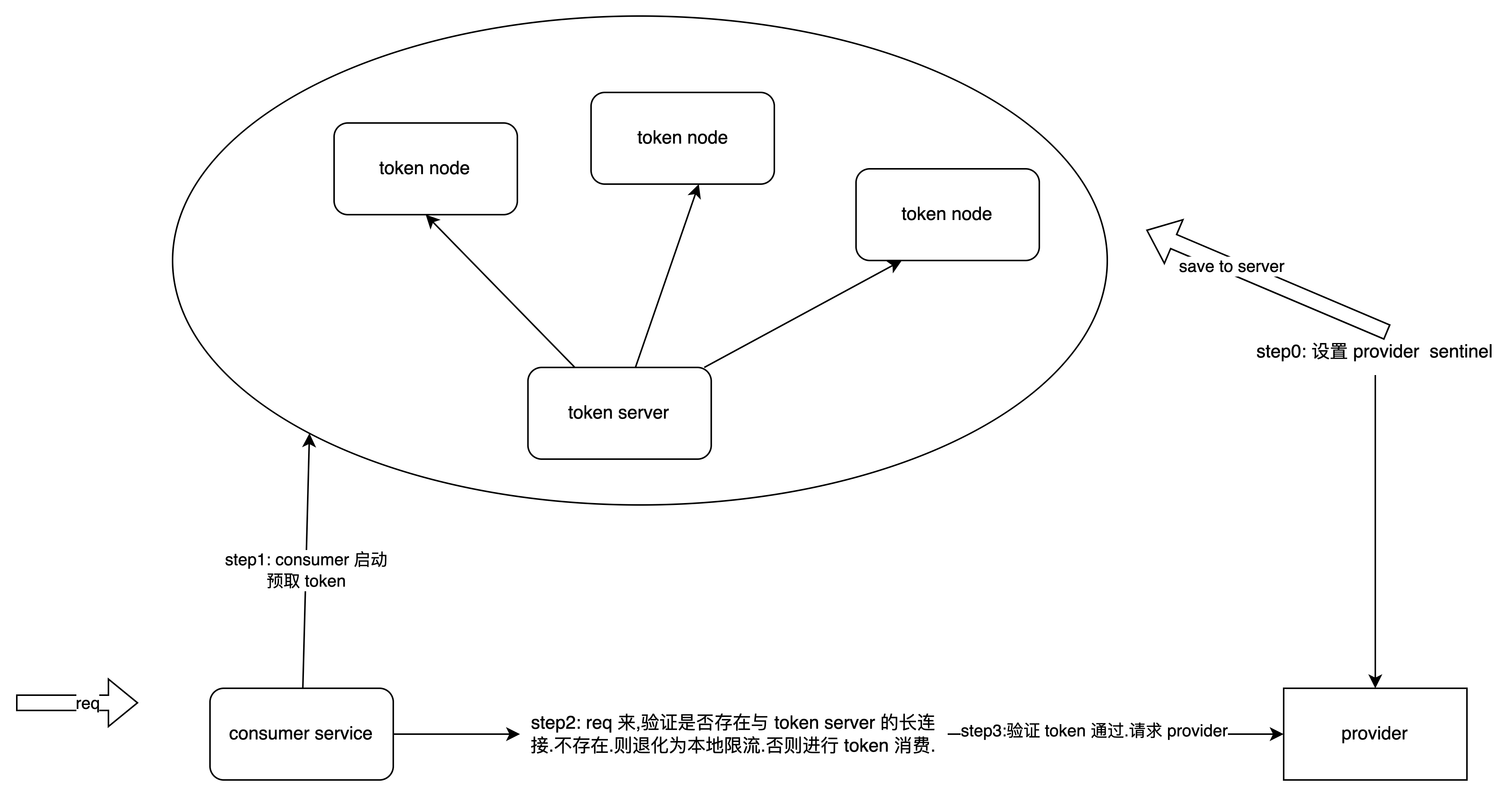
目录 一.什么是限流二.怎么做限流呢2.1 有哪些常见的系统限流算法2.1.1 固定窗口2.1.1 滑动窗口2.1.2 令牌桶2.1.3 漏桶算法 2.2 常见的限流方式2.2.1 单机限流&集群限流2.2.2 前置限流&后置限流 2.3 实际落地是怎么做的2.3.1 流量链路2.3.2 各链路限流2.3.2.1 网关层2…...
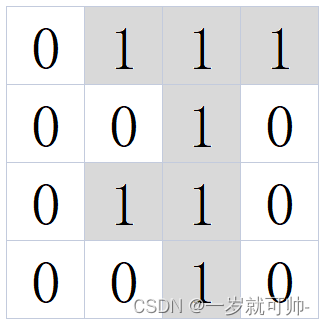
【算法】MT2 棋子翻转
✨题目链接: MT2 棋子翻转 ✨题目描述 在 4x4 的棋盘上摆满了黑白棋子,黑白两色棋子的位置和数目随机,其中0代表白色,1代表黑色;左上角坐标为 (1,1) ,右下角坐标为 (4,4) 。 现在依次有一些翻转操作&#…...
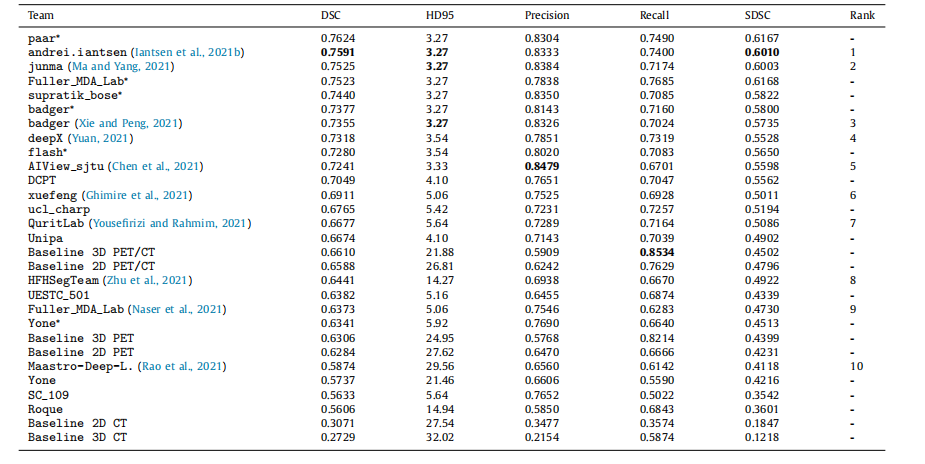
头颈肿瘤在PET/CT中的分割:HECKTOR挑战赛| 文献速递-深度学习肿瘤自动分割
Title 题目 Head and neck tumor segmentation in PET/CT: The HECKTOR challenge 头颈肿瘤在PET/CT中的分割:HECKTOR挑战赛 01 文献速递介绍 高通量医学影像分析,常被称为放射组学,已显示出其在揭示定量影像生物标志物与癌症预后之间关…...

Kafka重平衡导致无限循环消费问题
1. 问题描述 Kafka消费者消费消息超过了5分钟,不停的触发重平衡,消费者的offset因为重平衡提交失败,重复拉取消费,重复消费。 2. 问题原因 kafka默认的消息消费超时时间max.poll.interval.ms 300000, 也就是5分钟,…...

执行shell脚本时为什么要写成./test.sh,而不是test.sh?
一定要写成 ./test.sh,而不是 test.sh 运行其它二进制的程序也一样! 直接写 test.sh,linux 系统会去 PATH (系统环境)里寻找有没有叫 test.sh 的! 而只有 /bin, /sbin, /usr/bin,/usr/sbin 这…...
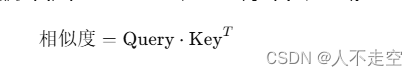
【人工智能】第一部分:ChatGPT的基本概念和技术背景
人不走空 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌赋:斯是陋室,惟吾德馨 目录 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌…...

雪花算法详解及源码分析
雪花算法的简介: 雪花算法用来实现全局唯一ID的业务主键,解决分库分表之后主键的唯一性问题,所以就单从全局唯一性来说,其实有很多的解决方法,比如说UUID、数据库的全局表的自增ID 但是在实际的开发过程中࿰…...

GD32F407的片上FLASH除了存代码,还能这样玩?一个实战项目教你存用户配置
GD32F407片上FLASH的进阶玩法:构建高可靠用户配置存储系统 第一次接触GD32F407的片上FLASH时,大多数开发者可能只把它当作存放固件代码的普通存储器。直到某次项目需要保存设备参数,我才意识到这片FLASH区域藏着更多可能性——它完全可以替代…...

PoeCharm完全攻略:角色构建效率提升与优化指南——解决流放之路玩家的数值困境
PoeCharm完全攻略:角色构建效率提升与优化指南——解决流放之路玩家的数值困境 【免费下载链接】PoeCharm Path of Building Chinese version 项目地址: https://gitcode.com/gh_mirrors/po/PoeCharm 引言:流放之路玩家的三大核心痛点 流放之路作…...
)
告别手动回复!用Python+uiautomation2给Android微信做个24小时值班机器人(附完整代码)
Android微信自动化:用uiautomation2打造全天候智能应答系统 深夜11点,你的手机突然亮起——又是一位老客户发来产品咨询。而此时,你开发的微信机器人已经自动识别关键词,秒回了详细的产品参数和购买链接。这不是科幻场景ÿ…...

Janus-Pro-7B惊艳效果:同一张建筑照片生成写实/水彩/线稿三种风格图
Janus-Pro-7B惊艳效果:同一张建筑照片生成写实/水彩/线稿三种风格图 1. 从一张照片到三种艺术风格 想象一下,你手里有一张普通的建筑照片,可能是你旅行时拍的,也可能是工作中需要用的素材。现在,你希望它能变成三种完…...

3MF插件全面指南:打造高效3D打印工作流
3MF插件全面指南:打造高效3D打印工作流 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 3MF插件是Blender中实现3D打印工作流的重要工具,它能帮助用…...

SEO 关键词工具哪个最准确
SEO关键词工具哪个最准确? 在当今的互联网时代,SEO(搜索引擎优化)已经成为了网站流量增长的关键。而在SEO优化过程中,关键词研究是非常重要的一环。作为网站运营者,选择一个准确的SEO关键词工具至关重要。…...

3步重塑邮件体验:Markdown Here如何让技术沟通更优雅
3步重塑邮件体验:Markdown Here如何让技术沟通更优雅 【免费下载链接】markdown-here Google Chrome, Firefox, and Thunderbird extension that lets you write email in Markdown and render it before sending. 项目地址: https://gitcode.com/gh_mirrors/ma/m…...

2025届学术党必备的AI辅助写作工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 维普AIGC检测系统专门针对学术文本里人工智能生成的内容来开展识别 , 用户在提交…...

tts-vue本地语音合成解决方案:从技术原理到生产实践
tts-vue本地语音合成解决方案:从技术原理到生产实践 【免费下载链接】tts-vue 🎤 微软语音合成工具,使用 Electron Vue ElementPlus Vite 构建。 项目地址: https://gitcode.com/gh_mirrors/tt/tts-vue 一、破解本地化语音合成的技…...

突破安卓截图封锁:Xposed-Disable-FLAG_SECURE技术探秘与实战指南
突破安卓截图封锁:Xposed-Disable-FLAG_SECURE技术探秘与实战指南 【免费下载链接】Xposed-Disable-FLAG_SECURE Xposed Module to Disable FLAG_SECURE, enabling screenshots, screen sharing and recording in apps that normally wouldnt allow it. 项目地址:…...