【人工智能】第一部分:ChatGPT的基本概念和技术背景

🌈个人主页:人不走空
💖系列专栏:算法专题
⏰诗词歌赋:斯是陋室,惟吾德馨

目录
🌈个人主页:人不走空
💖系列专栏:算法专题
⏰诗词歌赋:斯是陋室,惟吾德馨
1.1 引言
1.2 什么是ChatGPT
1.3 发展历程
1.4 Transformer架构简介
1.5 自注意力机制
查询、键和值的定义
计算过程
多头自注意力机制
重要性和应用
1.6 预训练和微调
预训练
微调
作者其他作品:

1.1 引言
随着人工智能技术的不断发展,自然语言处理(NLP)领域取得了显著的进步。ChatGPT,作为一种先进的对话生成模型,展现了令人瞩目的语言理解和生成能力。本文将深入探讨ChatGPT的原理,从基础概念到技术细节,帮助读者全面了解这一革命性技术。
1.2 什么是ChatGPT
ChatGPT是由OpenAI开发的一种基于GPT(Generative Pre-trained Transformer)架构的对话生成模型。GPT系列模型的核心是Transformer,它是一种专门用于处理序列数据(如自然语言)的深度学习模型。通过自注意力机制,Transformer能够有效捕捉和理解上下文中的复杂关系。ChatGPT通过大量的文本数据进行预训练,学习语言的基本结构和模式,然后通过监督学习和强化学习进行微调,使其能够与用户进行自然且流畅的对话。这一过程包括了对特定任务的数据集进行调整,使模型能够在各种应用场景中表现出色。
1.3 发展历程
GPT模型的发展可以追溯到2018年发布的GPT-1。此后,GPT-2和GPT-3相继推出,模型的参数规模和性能也不断提升。每一代GPT模型都在前一代的基础上进行了改进,特别是在模型的规模、训练数据和算法优化等方面。
GPT模型的发展可以追溯到2018年发布的GPT-1。GPT-1模型拥有1.17亿个参数,通过展示Transformer在语言模型中的潜力,引起了广泛关注。此后,OpenAI相继推出了GPT-2和GPT-3,每一代模型的参数规模和性能都得到了显著提升。GPT-2模型的参数数量大幅增加到15亿个,表现出更强的文本生成能力,尽管由于潜在的滥用风险,最初仅限发布部分模型。2020年推出的GPT-3模型,其参数规模跃升至1750亿个,显著提升了对话质量和文本生成的多样性,成为目前广泛使用的版本之一。GPT-3的巨大成功不仅展示了语言模型的强大能力,还激发了对未来更大规模和更复杂模型的研究兴趣。
- GPT-1:拥有1.17亿个参数,展示了Transformer在语言模型中的潜力。
- GPT-2:大幅增加到15亿个参数,表现出更强的文本生成能力,但由于潜在的滥用风险,最初仅限发布部分模型。
- GPT-3:参数规模跃升至1750亿个,显著提升了对话质量和文本生成的多样性,成为目前广泛使用的版本之一。
1.4 Transformer架构简介
Transformer是由Vaswani等人在2017年提出的一种深度学习模型,专为处理序列数据而设计。与传统的循环神经网络(RNN)和长短时记忆网络(LSTM)不同,Transformer完全依赖于注意力机制(Attention Mechanism),显著提高了并行计算能力和训练效率。这一创新架构使得Transformer在处理长序列数据时表现出色,并在多个NLP任务中超越了传统模型的性能。
Transformer模型由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。编码器负责将输入序列转换为一系列隐状态向量,这些向量包含了输入序列的语义信息。具体来说,编码器由多个相同的层叠堆组成,每层包括两个子层:多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feedforward Neural Network)。自注意力机制允许模型在处理每个单词时考虑上下文中的所有其他单词,从而捕捉到更丰富的语言信息。前馈神经网络则对每个位置的向量进行非线性变换,进一步提取特征。
解码器的结构与编码器类似,也由多个相同的层叠堆组成,但在每层中多了一个编码器-解码器注意力子层(Encoder-Decoder Attention),它通过注意力机制将编码器输出的信息引入到解码过程中。解码器根据这些隐状态向量生成输出序列。在生成序列的每一步,解码器会预测下一个单词,并将其作为输入用于生成下一个单词,直到完成整个序列的生成。
GPT模型仅使用了Transformer的解码器部分,通过自注意力机制(Self-Attention)和前馈神经网络(Feedforward Neural Network)来处理和生成文本。在GPT中,解码器使用了自回归方式,即每次生成一个单词,使用之前生成的单词作为上下文输入。自注意力机制在这里发挥了关键作用,使模型能够根据上下文生成连贯且符合语法规则的文本。
此外,Transformer架构的一个重要特点是多头注意力机制(Multi-Head Attention)。这种机制通过将注意力计算分成多个头,每个头在不同的子空间中进行独立的注意力计算,然后将结果拼接起来。这种方式允许模型捕捉到不同层次和维度的语义信息,从而提高了模型的表达能力。
1.5 自注意力机制
自注意力机制是Transformer的核心组件,它通过计算输入序列中各个位置之间的相似度来捕捉长期依赖关系。具体来说,自注意力机制通过查询(Query)、键(Key)和值(Value)三个向量来实现。
查询、键和值的定义
- 查询(Query):表示当前单词的特征向量,用于查询相关的信息。
- 键(Key):表示上下文中所有单词的特征向量,用于匹配查询向量。
- 值(Value):表示上下文中所有单词的特征向量,用于生成输出。
在实际操作中,查询、键和值向量都是通过对输入序列中的单词嵌入向量进行线性变换得到的。这些变换由训练期间学习到的权重矩阵实现。
计算过程
自注意力机制的计算过程可以分为以下几个步骤:
-
计算相似度:首先,计算查询向量与所有键向量之间的点积,以衡量它们之间的相似度。点积越大,表示查询向量和键向量之间的关系越紧密。
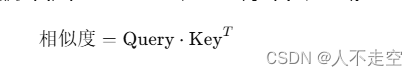 相似度=Query⋅KeyT
相似度=Query⋅KeyT -
归一化权重:将相似度值进行归一化处理,通常使用Softmax函数。这些归一化后的值即为权重,表示每个键对查询的重要程度。
权重=Softmax(相似度)
-
加权求和:用这些权重对所有值向量进行加权平均,从而得到当前查询位置的注意力表示。这一步将各个上下文单词的信息综合起来,生成一个新的表示。
注意力表示=∑(权重×Value)
多头自注意力机制
在Transformer中,自注意力机制不仅仅是单一的,而是通过多头自注意力机制(Multi-Head Attention)来实现。这意味着有多个独立的自注意力机制(即“头”)同时进行计算,每个头在不同的子空间中捕捉不同的上下文信息。具体步骤如下:
- 线性变换:对输入序列进行多个线性变换,生成多个查询、键和值向量。
- 并行计算:每个头独立地计算自注意力,得到多个注意力表示。
- 拼接和变换:将所有头的输出拼接起来,再通过线性变换生成最终的输出表示。
多头自注意力机制通过并行处理和综合不同头的信息,显著提高了模型的表达能力和捕捉复杂依赖关系的能力。
重要性和应用
自注意力机制的引入是Transformer架构的一大创新,解决了传统RNN和LSTM在处理长序列数据时的瓶颈问题。由于自注意力机制能够同时考虑输入序列中的所有位置,它有效地捕捉了长距离依赖关系,使模型在处理长文本、翻译、问答等任务中表现尤为出色。
通过自注意力机制,模型能够更好地理解上下文中的每个单词,并生成更为准确和连贯的输出。这一机制不仅提高了模型的性能,还为后续的改进和发展提供了坚实的基础。随着研究的深入,自注意力机制将在更多的应用场景中展现其独特的优势和潜力。
1.6 预训练和微调
ChatGPT的训练过程分为两个关键阶段:预训练和微调。每个阶段都在模型的性能和应用能力方面起着至关重要的作用。
预训练
预训练阶段是ChatGPT训练过程的基础,在这一阶段,模型在大规模的无监督文本数据上进行训练。预训练的目标是让模型学习语言的基本结构和规律,从而理解和生成自然语言。具体来说,预训练的目标是通过预测给定上下文中的下一个单词来进行学习。这种方法被称为自回归语言建模。
在预训练过程中,模型会处理大量的文本数据,这些数据来自互联网的各种来源,包括书籍、文章、网站内容等。模型通过连续阅读和分析这些文本,学习语言的语法、词汇和常见的句子结构。预训练阶段不需要人工标注的数据,利用的是无监督学习的方式,通过大量数据的训练,模型能够掌握语言的普遍规律。
预训练的步骤如下:
- 数据收集和清洗:收集大量的文本数据并进行清洗,去除噪声和不相关的信息。
- 词嵌入:将文本数据转换为词嵌入向量,这些向量表示文本中的每个单词。
- 自回归建模:训练模型预测每个单词在给定上下文中的概率,通过不断调整模型参数,使其预测更加准确。
通过预训练,模型获得了广泛的语言知识和基本的生成能力,为后续的微调奠定了坚实的基础。
微调
在预训练的基础上,微调阶段通过监督学习和强化学习进一步优化模型,使其在特定任务或领域中表现更为出色。微调的目的是让模型适应具体的应用场景,如对话生成、问答系统、文本摘要等。
微调的步骤如下:
- 任务数据集:收集与特定任务相关的标注数据集,这些数据通常由专家人工标注,包含输入和期望输出对。
- 监督学习:使用任务数据集对预训练模型进行监督学习,通过损失函数和梯度下降优化模型参数,使其在特定任务上的表现更好。
- 强化学习:有时,还会通过强化学习进一步优化模型,利用奖励信号来指导模型生成更符合预期的输出。例如,在对话生成任务中,模型可以通过用户反馈或人工评分来调整生成策略,提升对话的自然性和相关性。
微调过程的目标是使模型在特定领域内达到最佳性能,同时保持其在预训练阶段学到的语言知识。通过微调,模型能够更准确地理解特定任务的需求,并生成更加符合上下文的高质量文本。
作者其他作品:
【Java】Spring循环依赖:原因与解决方法
OpenAI Sora来了,视频生成领域的GPT-4时代来了
[Java·算法·简单] LeetCode 14. 最长公共前缀 详细解读
【Java】深入理解Java中的static关键字
[Java·算法·简单] LeetCode 28. 找出字a符串中第一个匹配项的下标 详细解读
了解 Java 中的 AtomicInteger 类
算法题 — 整数转二进制,查找其中1的数量
深入理解MySQL事务特性:保证数据完整性与一致性
Java企业应用软件系统架构演变史
相关文章:
【人工智能】第一部分:ChatGPT的基本概念和技术背景
人不走空 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌赋:斯是陋室,惟吾德馨 目录 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌…...

雪花算法详解及源码分析
雪花算法的简介: 雪花算法用来实现全局唯一ID的业务主键,解决分库分表之后主键的唯一性问题,所以就单从全局唯一性来说,其实有很多的解决方法,比如说UUID、数据库的全局表的自增ID 但是在实际的开发过程中࿰…...
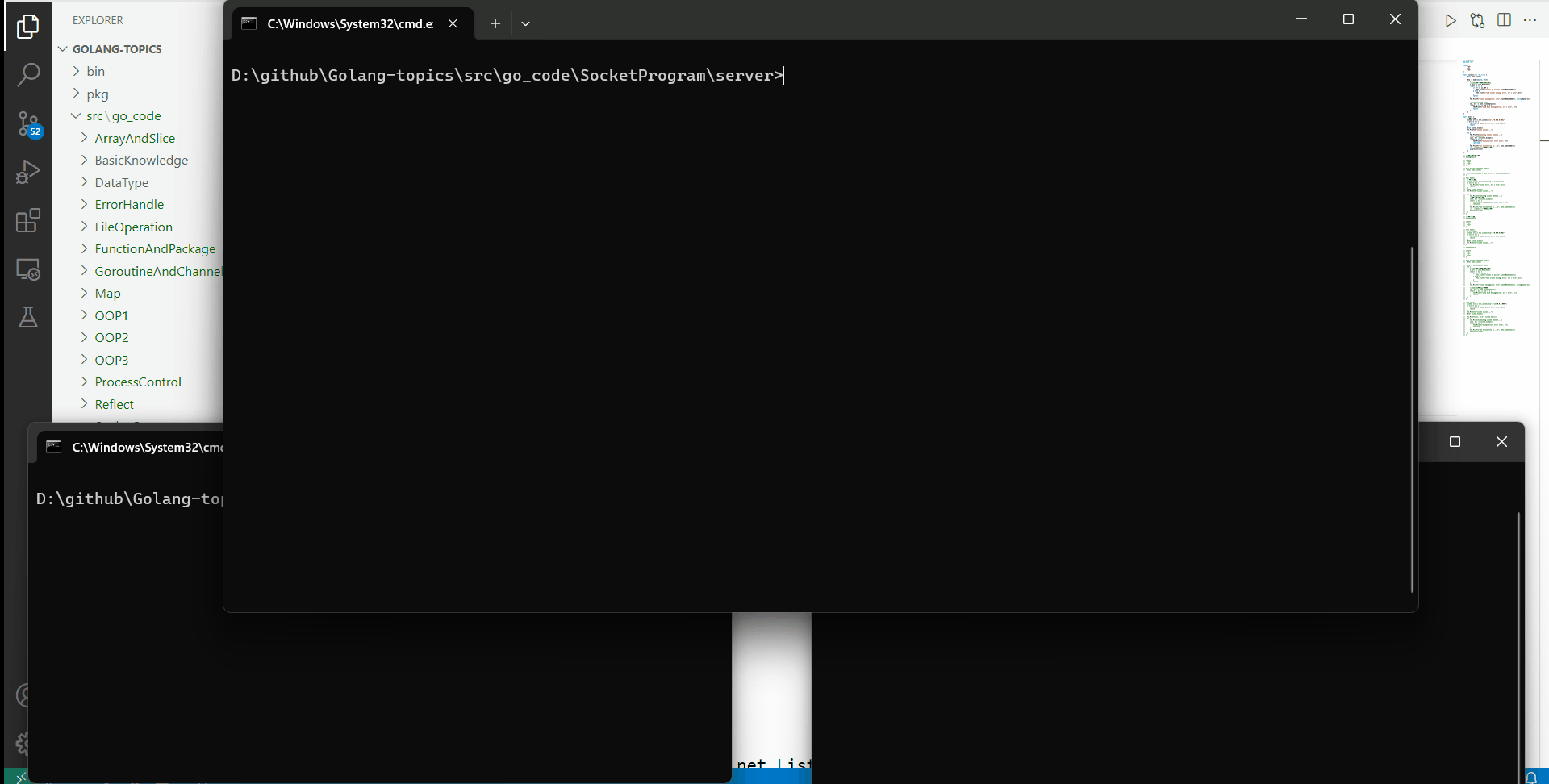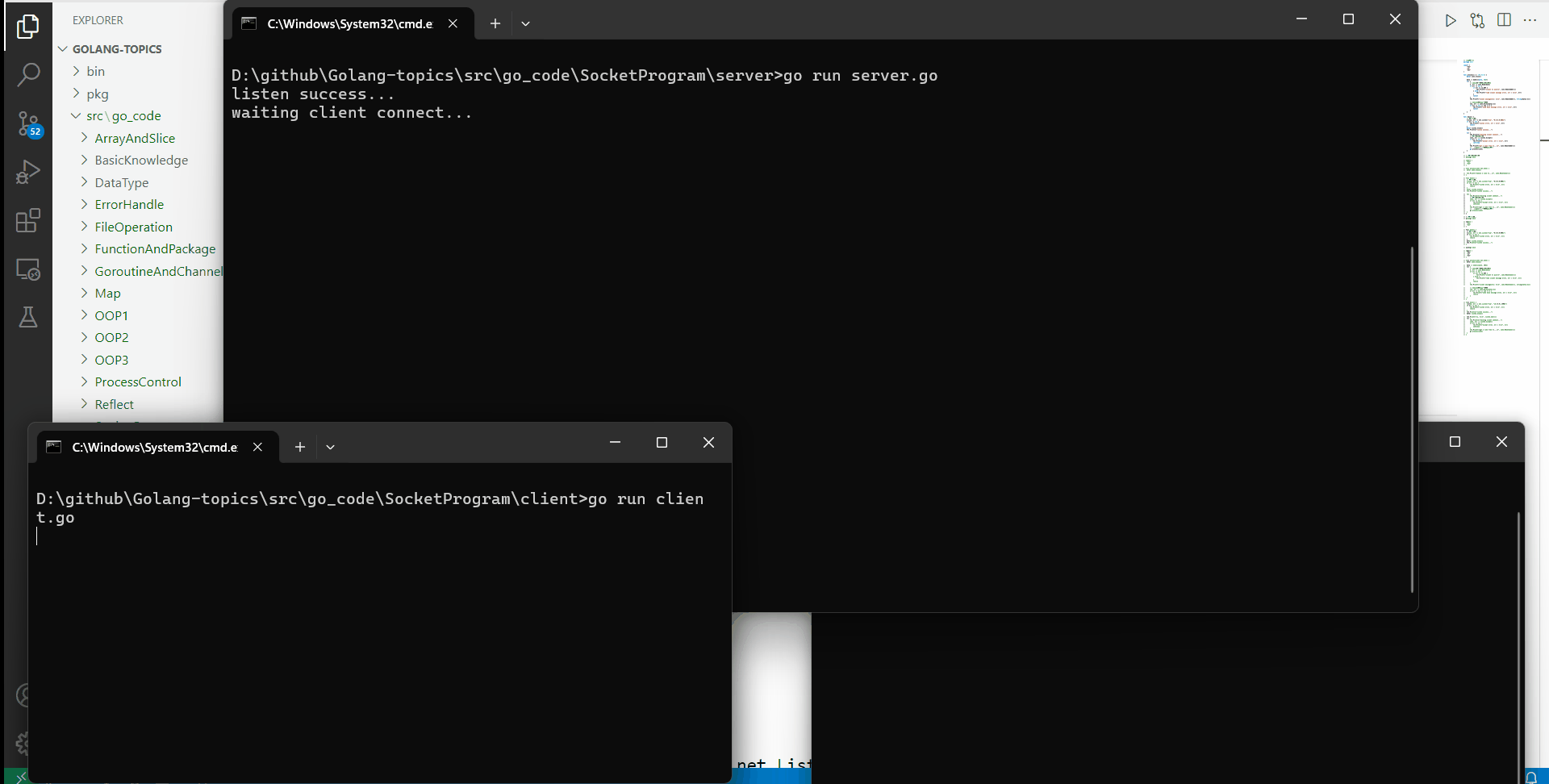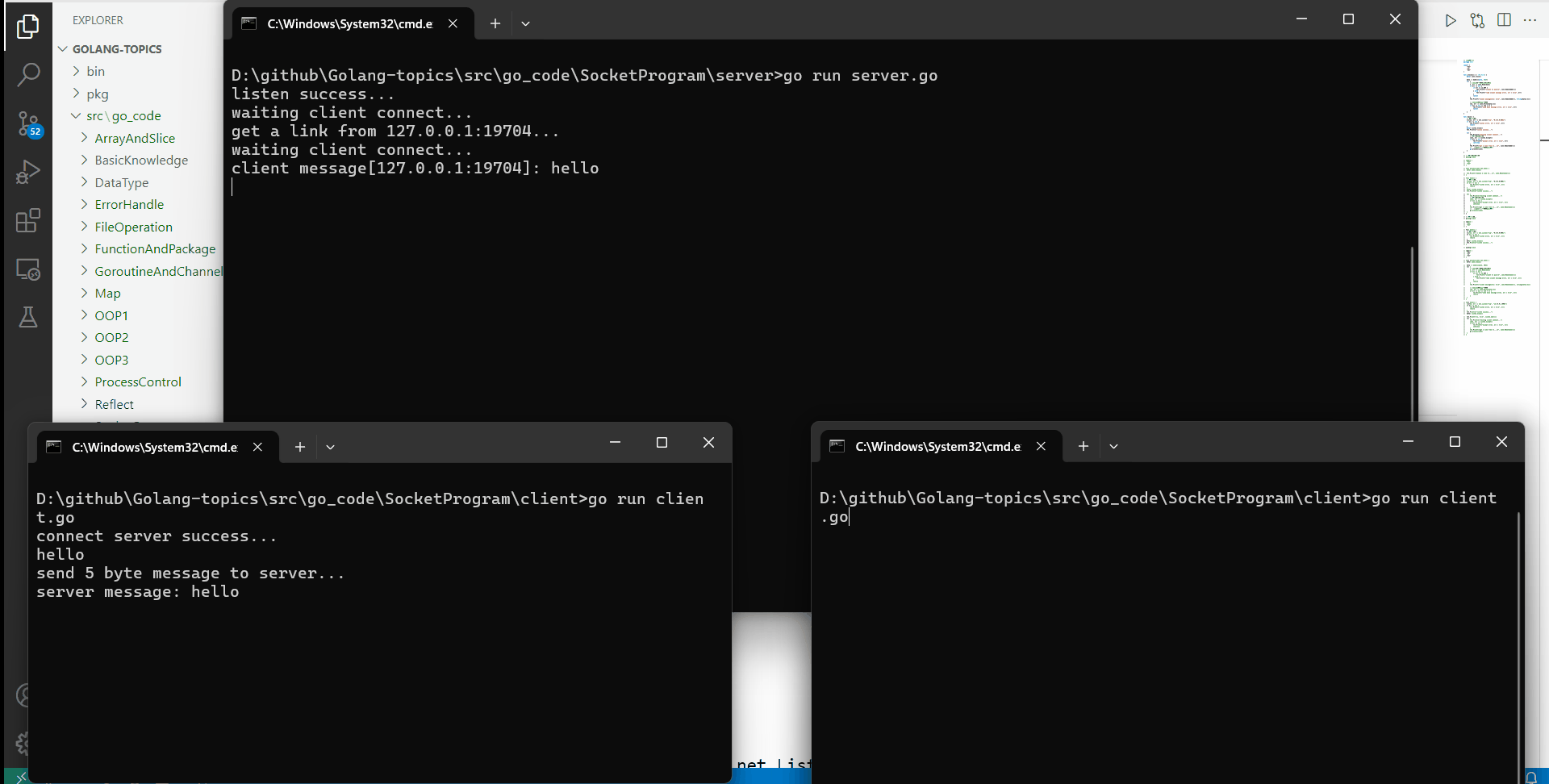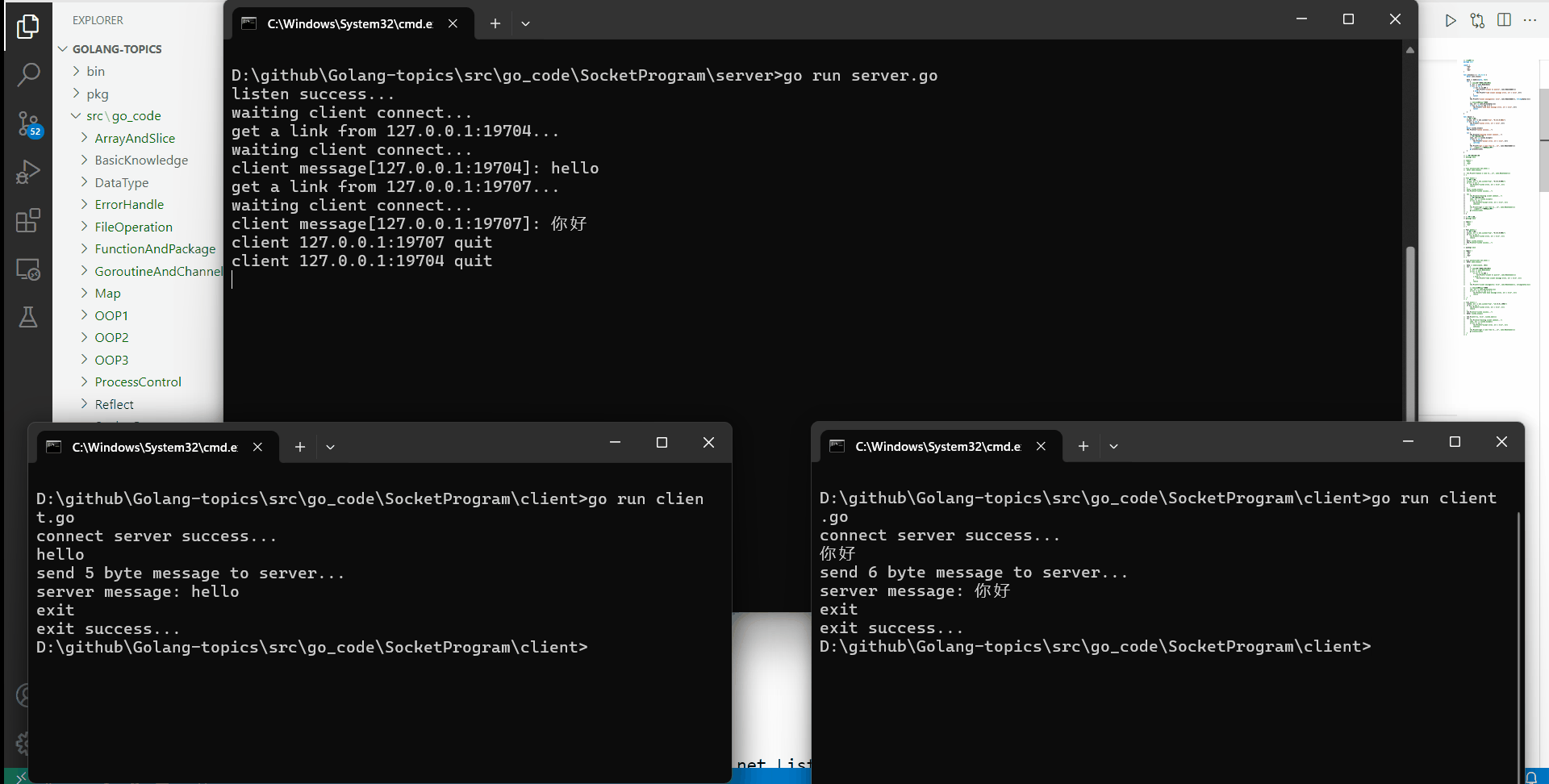
Golang TCP网络编程
文章目录 网络编程介绍TCP网络编程服务器监听客户端连接服务器服务端获取连接向连接中写入数据从连接中读取数据关闭连接/监听器 简易的TCP回声服务器效果展示服务端处理逻辑客户端处理逻辑 网络编程介绍 网络编程介绍 网络编程是指通过计算机网络实现程序间通信的一种编程技术…...

先进制造aps专题十 aps项目成功指南
aps项目成功指南 为了保证aps项目的成功 现在国内的aps项目 一是看aps软件本身是不是实现了复杂的排程算法和优化算法,算法引擎使用c高性能编译语言开发,支持工序的复杂关系,考虑副资源约束和特殊规格约束,提供了能考虑各种约束…...

实现Dropdown下拉菜单监听键盘上下键选中功能-React
用过ant design的小伙伴都知道,select组件是支持联想搜索跟上下键选中的效果的,但是在项目中我们可能会遇到用select组件无法实现我们的需求的情况,比如说一个div框,里面有input,又有tag标签,在input中输入…...

Ubuntu系统升级k8s节点的node节点遇到的问题
从1.23版本升级到1.28版本 node节点的是Ubuntu系统20.04的版本 Q1 node节点版本1.23升级1.28失败 解决办法: # 改为阿里云镜像 vim /etc/apt/sources.list.d/kubernetes.list# 新增 deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main# 执…...

前端将DOM元素导出为图片
前端工作中经常会用到把一些元素导出,比如表格,正好项目有遇到导出为excel和导出为图片,就都封装实现了一下,以供其他需求的开发者使用: 1.导出为文档 这个说白了就是下载的功能,传过去检索参数ÿ…...

变现 5w+,一个被严重低估的 AI 蓝海赛道,居然用这个免费的AI绘画工具就能做!
大家好,我是画画的小强,致力于分享各类的 AI 工具,包括 AI 绘画工具、AI 视频工具、AI 写作工具等等。 但单纯地为了学而学,是没有任何意义的。 这些 AI 工具,学会了,用起来,才能发挥出他们的…...
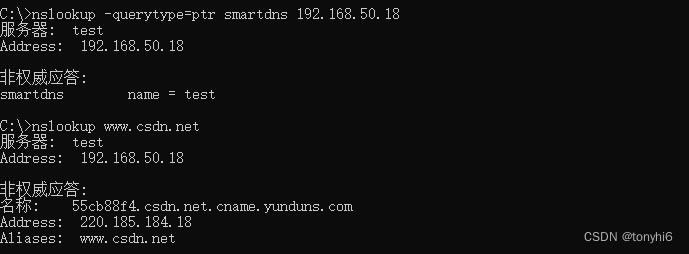
Ubuntu server 24 (Linux) 安装部署smartdns 搭建智能DNS服务器
SmartDNS是推荐本地运行的DNS服务器,SmartDNS接受本地客户端的DNS查询请求,从多个上游DNS服务器获取DNS查询结果,并将访问速度最快的结果返回给客户端,提高网络访问速度和准确性。 支持指定域名IP地址,达到禁止过滤的效…...
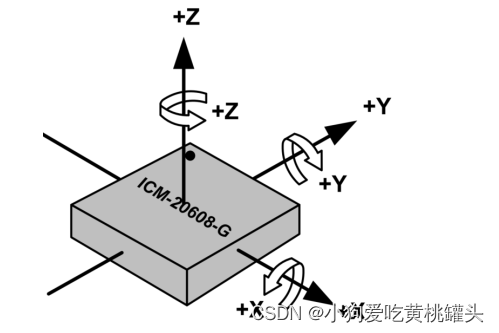
正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-24.5,6 SPI驱动实验-ICM20608 ADC采样值
前言: 本文是根据哔哩哔哩网站上“正点原子[第二期]Linux之ARM(MX6U)裸机篇”视频的学习笔记,在这里会记录下正点原子 I.MX6ULL 开发板的配套视频教程所作的实验和学习笔记内容。本文大量引用了正点原子教学视频和链接中的内容。…...
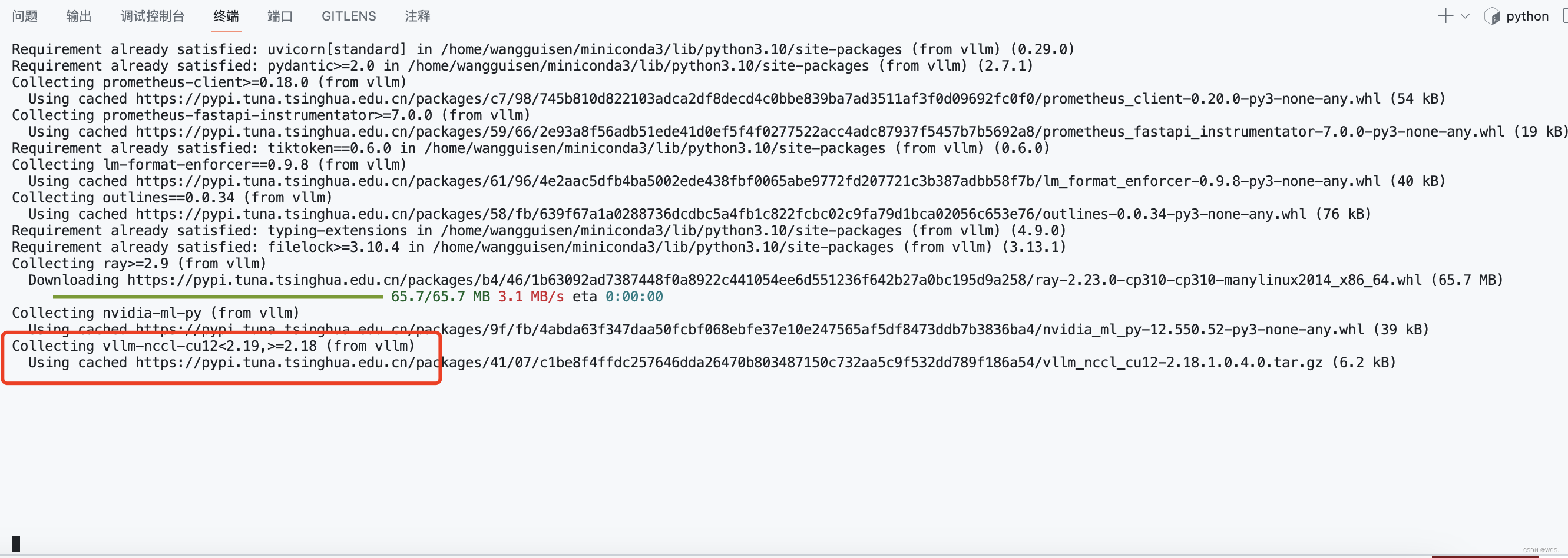
安装vllm的时候卡主:Collecting vllm-nccl-cu12<2.19,>=2.18 (from vllm)
按照vllm的时候卡主: ... Requirement already satisfied: typing-extensions in /home/wangguisen/miniconda3/lib/python3.10/site-packages (from vllm) (4.9.0) Requirement already satisfied: filelock>3.10.4 in /home/wangguisen/miniconda3/lib/python…...
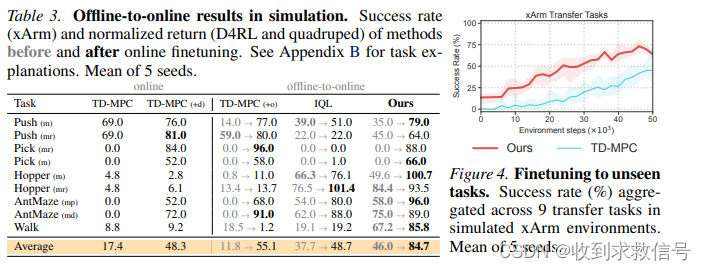
O2O : Finetuning Offline World Models in the Real World
CoRL 2023 Oral paper code Intro 算法基于TD-MPC,利用离线数据训练世界模型,然后在线融合基于集成Q的不确定性估计实现Planning。得到的在线数据将联合离线数据共同训练目标策略。 Method TD-MPC TD-MPC由五部分构成: 状态特征提取 z h θ ( s ) …...
)
嵌入式学习(Day:31 网络编程2:TCP)
client, server browser b/s http p2p peer TCP的特征:1.有链接;2.可靠传输;3.流式套接字 1、模式 C/S 模式 》服务器/客户端模型(服务端1个,客户端很多个) server:socket()-->bind()---…...

正则表达式 0.1v
正则表达式 扩展 --> :% s/\///g //文件里面所有的 / 去掉 * 通配符 \ //转义,让字符变成原本的意思 ^ //行首 $ //行尾 [0-9] //数字 [a-z] //小写字母 [A-Z] //大写字母 把文件的小写字母替换为大写字母? 固定写法 :% s/[a-…...
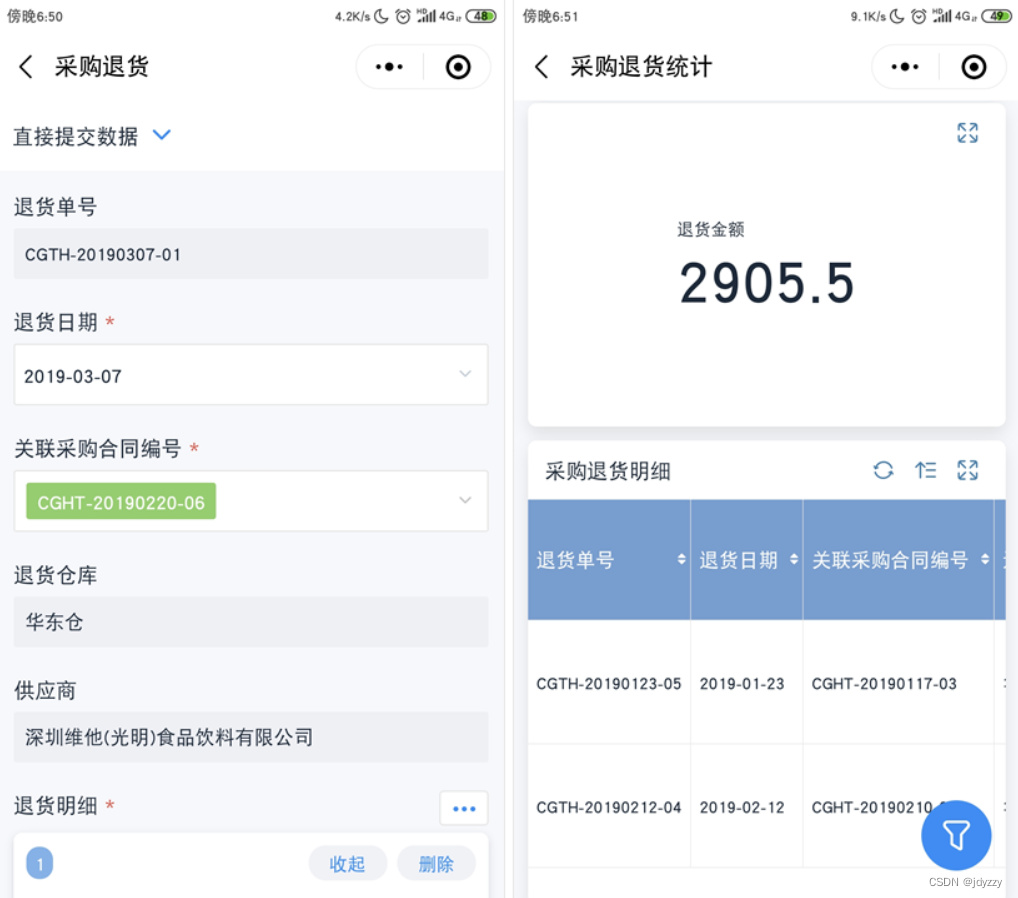
免费的仓库出入库管理软件有哪些?
中小企业因为预算有限,所以希望能在出入库管理软件方面能够减少成本。 但我们必须清醒地认识到,所谓的“永久免费”往往只是一个幌子。这些软件要么是新上市的、功能尚未完善的产品,试图通过免费吸引用户试用;要么在数据安全和客…...
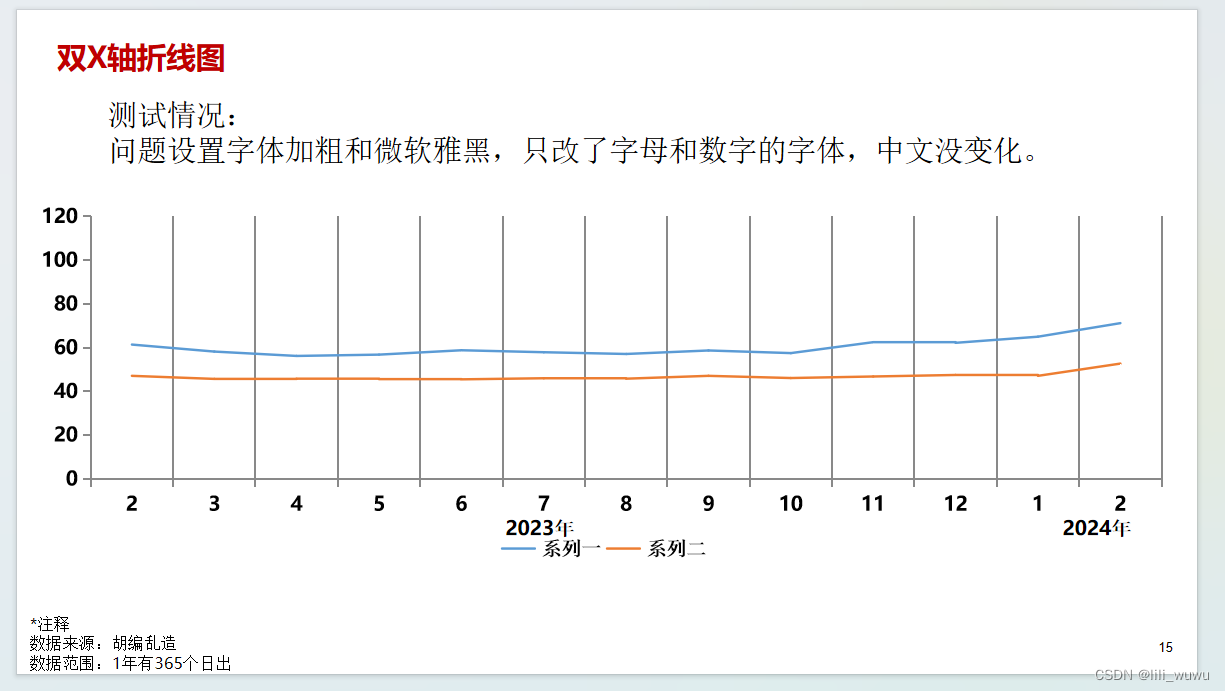
python 办公自动化-生成ppt文本和图
最终样式 代码实现 # 可编辑折线写入文字 成功 # 问题: 设置字体类型和加粗和字体为微软雅黑,是只改了字母和数字的字体,中文没变化 pip install pptx_ea_font 这个库可以解决这个问题 import pandas as pd import pptx_ea_font import mat…...

「动态规划」买卖股票的最佳时机
力扣原题链接,点击跳转。 给定一个整数数组prices,prices[i]表示股票在第i天的价格。你最多完成2笔交易。你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。设计一个算法计算最大利润。 我们用动态规划的思想来解决…...

Java 并发编程面试二
目录 一、并发编程三要素? 二、实现可见性的方法有哪些? 三、多线程的价值? 四、创建线程的有哪些方式? 五、创建线程的三种方式的对比? 六、Java 线程具有五中基本状态 七、什么是线程池?有哪几种创建方式 八、四种线程池的创建 九、线程池的优点? 十、常用的…...

成功解决“ModuleNotFoundError: No Module Named ‘utils’”错误的全面指南
成功解决“ModuleNotFoundError: No Module Named ‘utils’”错误的全面指南 在Python编程中,遇到ModuleNotFoundError: No Module Named utils这样的错误通常意味着Python解释器无法找到名为utils的模块。这可能是由于多种原因造成的,比如模块确实不存…...
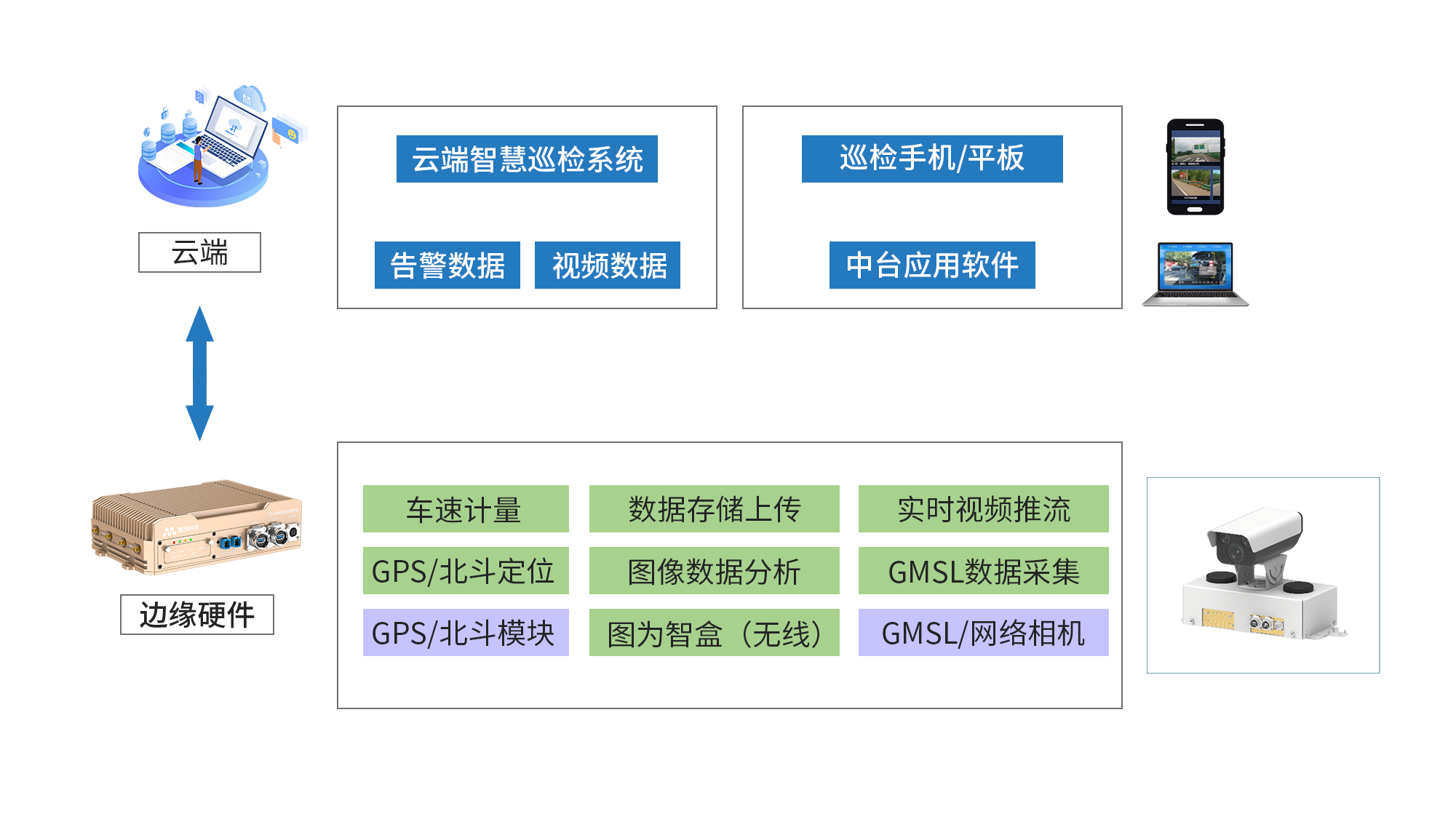
Nvidia Jetson/Orin +FPGA+AI大算力边缘计算盒子:公路智能巡检解决方案
项目背景 中国公路网络庞大,总里程超过535万公里,高速公路里程位居世界前列。面对基础设施存量的不断增长,公路养护管理已迈入“建管养并重”的新时代。随着养护支出的逐年攀升,如何提升养护效率、降低管理成本,成为亟…...

矩池云实战: 用Gemma 4 + Open WebUI打造你的私人OpenAI
在开源 AI 生态中,如何不依赖闭源 API,纯靠开源堆栈搭建出一套具备“深度思考(CoT)&原生多模态顶配开发环境? 答案是:Ollama Gemma-4-31B Open WebUI Ollama Gemma-4-31B Open WebUI 的真正核心价…...

装上这个技能,让你的 OpenClaw 和 Hermes 变身私人旅行规划师
一句话说清楚给小龙虾和马装上 Voyago,以后你只需要说"帮我规划杭州两天一夜",它就会自动帮你查火车票、搜机票、找酒店、查门票、规划路线、搜小红书攻略、算预算,最终输出一份万字级的完整旅行方案——精确到每两个地点之间坐几号…...

从‘阿强爱上阿珍’到程序验证:自然演绎规则在软件测试中的实战应用
逻辑引擎:自然演绎规则在软件质量保障中的工程化实践 当测试工程师面对一段复杂的状态机代码时,他们手中的武器不仅仅是JUnit或Selenium——数理逻辑中的自然演绎规则正在成为新一代质量保障的"秘密武器"。从反证法驱动的边界条件设计…...

深度学习的五大硬边界:数据饥渴、因果失语、鲁棒性脆性、可解释性黑洞与泛化围栏
1. 这不是“AI不行了”,而是你该看清深度学习真正能做什么、不能做什么“Limitations of Deep Learning”这个标题,乍一看像篇学术综述的冷门小节,但在我过去十年带团队落地近百个AI项目的过程中,它其实是每个工程师、产品经理甚至…...

【NotebookLM效应量计算实战指南】:20年统计学专家亲授3大避坑法则与5步精准计算流程
更多请点击: https://kaifayun.com 第一章:NotebookLM效应量计算的核心概念与适用场景 NotebookLM 是 Google 推出的基于用户上传文档进行语义理解与推理的实验性 AI 工具。其“效应量计算”并非内置统计模块,而是指用户在利用 NotebookLM 对…...

数据库局部变量,全局变量,流程控制
前言知识点什么时候用?局部变量调试脚本、存储过程参数、临时存值全局变量获取执行状态、错误处理IF/WHILE条件判断、批量数据处理视图简化复杂查询、统一查询逻辑索引加快查询速度函数封装可复用的计算逻辑存储过程封装复杂业务、批量操作一SQL局部变量变量1.是什么…...

A51汇编器Error 21解析与8051开发实践
1. 解析A51汇编器Error 21的根源与应对策略在8051单片机开发过程中,使用Keil C51工具链的A51汇编器时,开发者常会遇到一个令人困惑的报错:"ERROR #21: EXPRESSION WITH FORWARD REFERENCE NOT PERMITTED"。这个错误看似简单&#x…...

JEECG AI应用平台深度解析:业内唯一 JAVA 版开源 AI 应用平台,如何成为企业级 Dify 替代方案
JeecgBoot AI专题研究 | JEECG AI应用平台的能力全景、对比 Dify 的差异化优势与企业落地实践 为什么企业需要一个「长在业务里」的 AI 应用平台 过去两年,几乎每家公司都在尝试把大模型接进自己的系统。最常见的路径是搭一套 Dify、FastGPT 之类的 LLM 应用平台&a…...
)
医疗票据 OCR 识别 API 多场景落地指南:医保结算 + 商保理赔 + 医疗信息化(附 Python/Java 完整示例)
《医疗 OCR 识别 API 怎么选?(报告单 / 发票 / 检测单)》医疗票据 OCR 识别 API 多场景落地指南:医保结算 商保理赔 医疗信息化(附 Python/Java 完整示例) 导语:每天上万张医疗票据ÿ…...

Maven依赖scope:从编译到打包,一张图理清生命周期与classpath
Maven依赖scope全解析:构建生命周期与classpath的精准控制 当你盯着pom.xml里那些<scope>compile</scope>标签时,是否曾好奇它们究竟如何影响你的构建流程?Maven的依赖scope就像一个个精密的开关,控制着依赖项在编译、…...