一文速通23种设计模式——单例模式、工厂模式、建造者模式、原型模式、代理模式、装饰器模式、组合模式、组合模式、桥接模式、观察者模式、策略模式……
一文速通23种设计模式
写在前面
本文基于结城浩所著《图解设计模式》,其中所使用代码皆为Java版本。
随书代码下载地址-点击“随书下载”
全文15205字,全部读完需要约20分钟。
目录
- 一文速通23种设计模式
- 写在前面
- 第一部分 适应设计模式
- 迭代器模式 (Iterator)
- 代码实现
- 为什么这么做?
- 适配器模式 (Adapter)
- 为什么使用Adapter
- 第二部分 交给子类
- 模板方法模式 (Template Method)
- 为什么这样做?
- 工厂方法模式 (Factory Method)
- 为什么要这么做
- 第三部分 生成实例
- 单例模式 (Singleton)
- 原型模式 (Prototype)
- 为什么要使用原型
- 建造者模式 (Builder)
- 为什么使用建造者
- 抽象工厂模式 (Abstract Factory)
- 为什么使用抽象工厂
- 第四部分 分开考虑
- 桥接模式 (Bridge)
- 为什么要使用桥接模式
- 策略模式 (Strategy)
- 为什么要使用策略
- 第五部分 一致性
- 合成模式 (Composite)
- 为什么要使用合成模式?
- 装饰器模式 (Decorator)
- 为什么使用装饰器?
- 第六部分 访问数据结构
- 访问者模式 (Visitor)
- 为什么要弄得那么复杂
- 责任链模式 (Chain of Responsibility)
- 为什么使用责任链
- 第七部分 简单化
- 外观模式 (Facade)
- 为什么使用外观模式
- 仲裁者模式 (Mediator)
- 为什么使用仲裁者模式
- 第八部分 管理状态
- 观察者模式 (Observer)
- 为什么使用观察者模式
- 备忘录模式 (Memento)
- 为什么要分离负责人和生成者
- 状态模式 (State)
- 为什么使用状态模式
- 第九部分 避免浪费
- 享元模式 (Flyweight)
- 享元模式的拓展
- 代理模式 (Proxy)
- 为什么使用代理人
- 第十部分 用类来表现
- 命令模式 (Command)
- 命令模式的扩展
- 解释器模式 (Interpreter)
- 还有哪些其它的例子?
第一部分 适应设计模式
迭代器模式 (Iterator)
Iterator模式用于在数据集合中按照顺序遍历集合。Iterate有反复做某件事的意思,Iterator中文即为“迭代器”。
在迭代器模式中,有四个角色:
- Iterator 迭代器
- ConcreteIterator 迭代器实现
- Aggregate 集合
- ConcreteAggregate 集合实现
代码实现
以下为一个例子:
集合
public interface Aggregate {public abstract Iterator iterator();
}
迭代器
public interface Iterator {public abstract boolean hasNext();public abstract Object next();
}
集合实现
public class ConcreteAggregate implements Aggregate {private ArrayList<Object> arrayList;public ConcreteAggregate() { arrayList = new ArrayList<>();} //对集合的操作等public Iterator iterator() {return new ConcreteAggregate(this);}
}
迭代器实现
public class ConcreteIterator {private ConcreteAggregate concreteAggregate;private int index;public ConcreteIterator(ConcreteAggregate concreteAggregate) {this.concreteAggregate = concreteAggregate;this.index = 0;}public boolean hasNext() {if(index < concreteAggregate.getLength()) {return true;}return false;}public Object next() {index++;return concreteAggregate.getAtIndex(index);}
}
在这里面,我们创造了一个迭代器和集合接口,并用具体的类实现它们。在集合中,保存了一个迭代器的成员变量,而需要遍历集合元素时(next和hasNext方法),都交给迭代器实现。
为什么这么做?
这样做的目的是,Iterator可以把遍历和实现分开,也就是把遍历交给迭代器实现。这样,我们可以随意变更集合里面装载的是什么元素,都不需要变更迭代器。
设计模式的作用,就是帮助我们编写可复用的类,即将类实现为“组件”。当一个组件改变时,其它组件不会产生什么影响。在之后的设计模式中我们会反复地实现这一目的。
迭代器模式其实也可以完全不使用接口,而只使用具体的类来实现。但是这样会造成类之间的强耦合,不利于我们将其组件化。
适配器模式 (Adapter)
在编程时,经常出现现有程序无法使用,而需要做适当变换才能使用的情况。这种填补“现有程序”和“所需程序”间差异的设计模式就是迭代器模式。
迭代器模式中的角色有以下几种:
- Target 对象
- Client 请求者
- Adaptee 被适配者
- Adapter 适配者
适配器的实现方式有两种。
第一种是使用继承,即,Target为接口,里面有Client需要的方法;Adapter继承Adaptee, 拿到Adaptee里面的所需方法;同时,Adapter继承了Target接口。通过Adapter, Target就可以实现调取到Adaptee里面的方法。
第二种方式是使用委托。这次Adapter是继承Target而非Adaptee。那么Adapter要如何拿到Adaptee里面的方法呢?答案是在Adapter里面设置一个Adaptee成员变量,通过该成员变量来调用方法。
由于较为简单,这里就不给出实例代码了。
为什么使用Adapter
如果我们需要一个方法,为什么不直接在程序中使用,而非要使用adapter呢?
这是因为,在实际开发中,Adaptee通常已经经过了长期的测试,能确保出现问题的概率较低。这样一来,当发生bug时,我们就可以基本确定问题是出在新编写的程序中,而不是发生在Adaptee里面。
此外,如果是长期开发,那么使用Adapter可以实现,不论需要新增加什么功能,都可以通过Adapter适配,而不需要去修改现有代码,避免了与之相关的代码出问题。
第二部分 交给子类
模板方法模式 (Template Method)
在模板方法模式中,父类里面没有方法的具体实现,只有关于如何调用这些方法;方法的实现放在子类中。通过这种办法可以实现让不同对象做出相同行为。
打个比方,有一块用来印刷书籍的刻字版;上面刻好了字,如果涂上蓝墨水,那印出来的书就是蓝色的;使用红墨水,印出来的书就是红色的。
模板方法模式中的角色有以下几种:
- AbstractClass 抽象类
- ConcreteClass 具体类
注意这里的抽象类不是Java语法中的抽象类。在这里的抽象类中,除了有模板方法(即定义子类行为模板的方法),还有子类所有方法的抽象方法。下面是一个父类的例子:
public abstract class Parent {public abstract void open(); //这三个是子类的抽象方法public abstract void print();public abstract void close();public void display() { //这个是行为模板open();for(int i = 0; i < 5; i++ ) {print();}close();}
}
为什么这样做?
这样做的优点在于,父类中已经写好了算法,因此子类无需再次编写。
另外,当有多个子实现类时,如果发现有bug,只需要修改父类即可。这在分散的情况下是无法实现的。
工厂方法模式 (Factory Method)
这个方法与上一个模板方法模式很像,区别在于,该模式是用来生成实例的。
用模板方法模式来构建生成实例的工厂,这就是工厂方法模式。
在工厂方法模式中,父类决定实例生成方式,但不决定要生成的具体的类;具体处理全部交给子类。
在工厂方法模式中,有以下几个角色:
- 产品 Product
- 创建者 Creator
- 具体产品 ConcreteProduct
- 具体创建者 ConcreteCreator
Creator是一个抽象类,里面有create方法(用于定义生成实例的流程),以及工厂方法。
Product也是抽象类,里面定义了具体产品的抽象方法。
ConcreteCreator继承Creator, 拿到了生成实例的流程以及工厂方法,通过实现这些方法,就可以用create方法生成实例。另外,具体生成哪一种实例ConcreteProduct, 也是在这里面定义的。
ConcreteProduct则继承Product, 这里面没有什么特殊的。
为什么要这么做
这样做的妙处就在于,如果我们想要用于生成其它的实例产品,只需要在写一个具体实现类就可以,而创建者的代码不需要经过任何改动。
第三部分 生成实例
单例模式 (Singleton)
单例模式是面试的重点。有时候,我们希望一个类只会生成一次,例如表示本台计算机的类、表示系统设置的类、表示当前视窗的类等等。此时就需要用到单例模式。
单例模式实现的要点是,确保只会执行一次new MyClass()
在单例模式中,只有一个角色,单例 Singleton, 实例代码如下:
public class Singleton {private static Singleton singleton = new Singleton();private Singleton() {//生成单例的代码}public static Singleton getInstance() {return singleton;}
}
在这里,由于构造函数被设置为私有,因此外界无论如何也不会生成Singleton实例。唯一一次生成实例,是类加载的时候执行static代码,得到了一个Singleton. 之后想在程序里获取,只能通过getInstance()得到。
不过这个方法不是完全的单例,当多线程同时调用getInstance()方法时,是有可能生成多个单例的。要实现完全的单例,需要在getInstance()前面加上synchronized关键字。
public class Singleton {private static Singleton singleton = new Singleton();private Singleton() {//生成单例的代码}public static synchronized Singleton getInstance() {if(null == singleton) {singleton = new Singleton();}return singleton;}
}
原型模式 (Prototype)
通常,当我们需要一个实例时,会通过new关键字来生成。但是在一些情况下,我们会希望能通过现有的实例来生成新的实例,例如以下几种情况:
- 对象很多,如果分别作为一个类,就需要编写许多类文件;
- 生成过程复杂,很难通过类生成,例如图像绘画软件中用户已经画好的图案;
- 想要解耦框架与生成的实例
原型模式登场的角色如下:
- 原型Prototype
- 具体原型ConcretePrototype
- 使用者Client
Prototype用于定义复制实例的方法;ConcretePrototype则负责实现复制实例的方法。Client负责使用该方法生成实例。
具体使用流程可以参考以下使用方法:
public class Main {public static void main() {Client client = new Client();ConcretePrototype proto1 = new ConcretePrototype("-");ConcretePrototype proto2 = new ConcretePrototype("+");client.regist("strong message",proto1);client.regist("warn message",proto2);Product p1 = client.create("strong message");p1.use("hello,world");Product p2 = client.create("warn message");p2.use("hello,world");}
}
在client中使用了一个HashMap来存储键值对,通过名称就可以获取到想要的实例。
在ConcretePrototype中,使用了clone函数,来获取新的实例。
为什么要使用原型
正如我们在上面使用的,只需要一个参数,就可以生成新的原型,而且想要继续添加或者删除也非常简单。如果不使用原型模式,那么每种新的实例都需要创建新的类。另外,这样做因为没有了new关键字,也可以实现框架与实例解耦。
建造者模式 (Builder)
Builder是用来组装复杂实例的。就像建造房子一样,搭建框架,然后自下而上一层一层搭建起来。
Builder模式有以下登场角色:
- 建造者 Builder
- 具体建造者 ConcreteBuilder
- 监工 Director
- 使用者 Client
在这里面,Builder用于定义生成实例的抽象方法;ConcreteBuilder负责实现这些抽象方法,以及返回最终生成的结果的方法。Direct负责使用Builder的方法来生成实例,它负责保证所有类正常工作,并且只调用Builder的方法。
在Builder运行过程中,Client先建立一个ConreteBuilder;再向Director发出请求,Director不断向ConreteBuilder调用生成产品的步骤,直到生成完成,返回给Client.
为什么使用建造者
在建造者模式中,Client并不知道Builder类,它只是向Direct发出一次请求。但是,Client直到调用的是哪个具体的建造者,并将它们发给Director. 这样,Client就可以按照自己的要求,让Director去负责生产一个结果。
同时,Director也不需要关注Client到底提出了什么要求,只要它们是实现Builder的,遵守了其中的规范就可以。
有了这种“可替换性”,组件才有了价值。
抽象工厂模式 (Abstract Factory)
一听这个名字,好像有些不明所以。抽象的工厂能有什么用呢?
类似于抽象方法,我们不关心方法具体实现,只关心方法的参数和返回值;在抽象工厂中,我们不关心零件的具体实现,只关心零件有哪些接口(API),怎么利用这些API把零件组装成产品。
抽象工厂模式有以下几个角色:
- 抽象产品 AbstractProduct
- 抽象工厂 AbstractFactory
- 委托者 Client
- 具体产品 ConcreteProduct
- 具体工厂 ConcreteFactory
抽象产品负责定义抽象工厂生成的抽象零件和产品的接口(API);抽象工厂负责定义生产抽象产品的接口(API);具体产品负责实现抽象产品的接口(API);具体工厂实现抽象工厂的接口(API); 委托者对上述一无所知,它仅仅是调用抽象工厂给出的接口来工作。
原书给出了非常多的代码,给出了很多零件,出于篇幅这里就不全部展现了。
为什么使用抽象工厂
使用抽象工厂的话,增加具体的工厂非常容易,因为需要编写哪些类和实现哪些方法都非常清楚。不过,如果想要增加零件,就需要修改所有具体工厂,此时将非常麻烦。
第四部分 分开考虑
桥接模式 (Bridge)
Bridge是桥的意思,在这里指的是,用桥梁把类的功能层次和类的实现层次连接起来。
类的功能层次指的是,为了不断实现更多的功能,将类一层一层地不断继承,并在每次继承添加新的功能。
类的实现层次则是指,定义父类和子类,父类定义接口,子类实现接口。
这种区别会使得编程变得复杂,我们不清楚应该是在哪一个层次结构中去增加子类。而如果把两种层次拆成独立结构,再用桥接模式连接起来,那么这个问题就解决了。
桥接模式有以下登场角色:
- 抽象化 Abstraction
- 改善后的抽象化 RefinedAbstraction
- 实现者 Implementor
- 具体实现者 ConcreteImplementor
抽象是功能层次的顶层,里面有一个实现者的成员变量(这里使用了委托);改善后的抽象化则是功能层次中添加功能的子类。
实现者是实现层次的顶层,里面有抽象方法接口;再由具体实现者去实现其中的接口。
使用实例如下:
public class Main {public static void main(String[] args) {Abstraction d1 = new Abstraction(new ConcreteImplementor("Hello, China."));Abstraction d2 = new RefinedAbstraction(new ConcreteImplementor("Hello, World."));RefinedAbstraction d3 = new RefinedAbstraction(new ConcreteImplementor("Hello, Universe."));d1.display();d2.display();d3.display();d3.multiDisplay(5); //RefinedAbstraction的新功能}
}
为什么要使用桥接模式
将两个层次分开后,将共容易实现扩展。要增加新功能时,只需要在功能实现一侧增加类,随后所有的实现都可以使用。
策略模式 (Strategy)
这个模式时为了算法而服务的。Strategy的意思是“策略”。针对不同的问题,需要不同的算法,册罗模式就可以运行我们只对算法进行修改,而其它的部分不需要变动。
策略模式有以下登场角色:
- 策略 Strategy
- 具体的策略 ConcreteStrategy
- 上下文 Context
策略复杂定义接口,保证所有具体策略都可以嵌入上下文中;具体策略则是实现接口,编写具体的算法;上下文负责使用策略,调用具体的策略去实现需求。
为什么要使用策略
虽然这样一看,程序好像变复杂了,但是对于实际场景里,算法可能会异常复杂,有时候升值需要交给专门的人处理。由于使用了委托的模式来使用策略,使得策略与上下文解耦,可以很方便的替换或者复用算法。
另外,由于委托降低了耦合度,我们可以实现根据环境自动切换算法,如系统内存低时就切换占用内存少且速度慢的算法,系统内存高时就切换内存呢占用高且快速的算法。这在强耦合程序中是很难实现的。
第五部分 一致性
合成模式 (Composite)
在操文件系统中,文件夹里面既可以放文件,又可以放文件夹。在这个系统里,我们把它们当作同一种对象来看待。
Composite模式就是用于创造这种结构的模式,它能够是容器与内容具有一致性,从而创造出递归的结构。
在合成模式中,有以下几种角色:
- 组件 Component
- 叶子节点 Leaf
- 组合节点 Composite
- 客户端 Client
Component定义了Composite和Leaf的共同点,使得我们可以将其视作同一物体操作;Composite是容器,继承自Component,类似文件夹;Leaf是内容,也继承自Component,类似文件。
为什么要使用合成模式?
合成模式能够使得客户端可以一致地处理单个对象和组合对象,这样就简化了客户端的代码,提高了代码的可复用性和可维护性。同时,合成模式也使得我们能够更加灵活地组织对象之间的关系,通过树形结构来表示复杂的层次关系,从而更好地模拟现实世界中的部分-整体结构。
装饰器模式 (Decorator)
假设有一块蛋糕胚,往上涂上奶油,那就是奶油蛋糕;再加上巧克力,那就是巧克力奶油蛋糕,以此类推。
这种不断往对象添加装饰的设计模式,就叫做装饰器模式。
装饰器模式中有如下角色:
- 组件 Component
- 具体组件 ConcreteComponent
- 装饰物 Decorator
- 具体装饰物 ConcreteDecorator
Component是核心角色,里面定义有抽象方法,类似于蛋糕胚的角色;ConcreteComponent继承了Component,属于具体的蛋糕;Decoretor也继承自Component,同时内部保存有一个Component成员变量;ConcreteDecorator则继承自Decorator,其实现了Component里面的接口,同时由于持有Component,因此可以对其进行装饰。
为什么使用装饰器?
在装饰器模式中,装饰物和组件都持有一样的接口,这就使得,即使使用了装饰器,原来对组件进行的操作,现在一样可以进行,就好像装饰器“透明”了一样。由于这种一致性,我们也可以实现Composite模式一样的递归结构。
另外,由于这里也使用了委托方法,削弱了耦合关系,所有可以实现动态地增加功能。以及,我们只需要添加装饰器,就可以自由地添加新功能。
第六部分 访问数据结构
访问者模式 (Visitor)
访问者模式与第一章的迭代器模式有一些相似。在遍历数据结构时,我们会想要对其进行处理;而在访问者模式里,数据结构与遍历被分离开来。这样,我们想要增加新的处理方法时,就可以只修改访问者,而尽量不修改数据结构。
在访问者模式中,有以下角色:
- 访问者 Visitor
- 具体访问者 ConcreteVisitor
- 元素 Element
- 具体元素 ConcrementElement
- 对象结构 ObjectStructure
访问者负责声明访问元素的visit方法接口;具体访问者继承自访问者,为每一个不同的具体元素实现visit方法(根据具体元素的参数不同实现重载);
元素则是访问者的访问对象,其中声明了用于接收访问者的accept方法;具体元素实现了accept方法,在参数中接收到访问者角色;对象结构则是元素角色的集合。
由于具体元素接收到了visitor实例,因此可以通过如下语句实现被访问:
public void accept(Visitor v) {v.visit(this);
}
而Visit则会根据此处this传入的对象不同,调用对应的重载函数,实现访问。
public void visit(File file) {//foo
}public void visit(Directory directory) {//foo
}
为什么要弄得那么复杂
正如前文所说,访问者模式的目的就是把数据结构和访问分离开来。通过这样做,提高了不同元素作为不同组件的独立性,在具体元素中只需要实现accept函数就可以被访问到。如果我们把visit方法定义到具体元素里,那么如果想要增加一些功能时,就不得不修改所有的具体元素。
责任链模式 (Chain of Responsibility)
责任链模式,即将多个对象串在一起,按照责任链上的顺序,一个一个地找出应该由谁来负责处理。
责任链模式的登场角色有:
- 处理者 Handler
- 具体处理者 ConcreteHandler
- 请求者 Client
处理者定义了实现请求者需求的通用接口,以及next方法,如果当前具体者无法实现需求就转发到下一个;具体处理者继承自处理者,按照接口实现处理操作的函数;请求者向处理者发出处理请求。
为什么使用责任链
责任链的有点在于其弱化了发出请求的人与处理请求的人的关系。如果不使用该模式,那么就意味着有一个统领性的角色要负责决定把任务发给谁,或者干脆由它完成所有任务。在这种情况下,将降低其作为组件的独立性。
另外,这样做可以实现动态改变责任链;也可以让每个具体处理者专注与自己的工作。
当然,如果十分确定任务需要交给谁,或者程序追求更快的处理速度,那么还是不要使用责任链为好。
第七部分 简单化
外观模式 (Facade)
随着程序的不断开发,其会变得越来越臃肿、越来越难以理解。有不少应用和网站的页面就在朝着这个方向发展。
与其关注哪些庞大的类之间错综复杂的关系,我们不如建立一个窗口,这样只需要对该窗口发出请求即可。这就是外观模式。
外观模式有以下角色:
- 窗口/外观 Facade
- 请求者 Client
- 系统中的所有其它组件
由于外观模式更像是一种思想,因此并没有一个统一的编写风格。例如说,SpringBoot把启动web应用的一大堆方法浓缩到了一句
SpringApplication.run(Main.class,args);
这也是一种外观模式。
为什么使用外观模式
外观模式的重点是可以让复杂的东西看起来简单,例如说后台工作的类以及它们之间的关系。这里的重点就是接口变少了,全部放在内部处理,我们甚至只需要一句话就可以全部拿来使用。
另外一点就是使得程序与外部的关系弱化了。之所以在SpringCloud中可以如此轻松的部署大量SpringBoot程序,与SpringBoot良好的外观模式设计有很大关系。
仲裁者模式 (Mediator)
想象以下,有一个十名成员组成的开发小组,他们之间常常由于代码风格不同、不写注释等原因大打出手。
在这种情况下,就需要有一个中立的仲裁者出来下达指令。随后,团队成员之间将不再交流,而是统一报告给仲裁者,再由仲裁者向所有人下达指示。这就是仲裁者模式。
在仲裁者模式中有以下登场角色:
- 仲裁者/中介者 Mediator
- 具体仲裁者 ConcreteMediator
- 同事 Colleague
- 具体同事 ConcreteColleague
仲裁者负责定义与同事间通信并做出决定的接口;具体仲裁者实现这些接口,其中储存了所有具体同事作为成员变量;
同事则负责定义与仲裁者通信的接口,在其中储存有仲裁者成员变量;具体同事负责实现通信接口。
为什么使用仲裁者模式
在这种模式下,具体仲裁者由于需要处理请求并发送通知,代码会变得比较复杂。但这样集中的好处在于,把所有逻辑集中,方便了代码的统一修改,如果不这样做,那么修改bug或者是增加功能都会变得复杂,尤其是当具体同事越来越多的时候,其中的关系网络将变得异常难以处理。
另外,这样做也有助于实现具体同事的复用,只需要修改具体仲裁者的成员变量即可。
第八部分 管理状态
观察者模式 (Observer)
在观察者模式中,当被观察对象的状态发生变化时,会通知给观察者。观察者模式使用与根据对象状态进行相应处理的场景。
观察者模式中的登场角色有以下几种:
- 观察对象 Subject
- 具体观察对象 ConcreteSubject
- 观察者 Observer
- 具体观察者 ConcreteObserver
观察对象定义了注册观察者、删除观察者和提醒观察者的方法,以及得到被观察对象状态的接口,内部保存有观察者的成员变量;具体观察对象继承自观察对象,实现了得到对象状态的办法getStatus。
观察者负责接收来自观察对象发来的状态变化通知,并声明了update方法接口;具体观察者实现了update方法来获取最新状态。
下面是观察对象的示例:
public abstract class NumberGenerator {private ArrayList observers = new ArrayList(); // 保存Observer们public void addObserver(Observer observer) { // 注册Observerobservers.add(observer);}public void deleteObserver(Observer observer) { // 删除Observerobservers.remove(observer);}public void notifyObservers() { // 向Observer发送通知Iterator it = observers.iterator();while (it.hasNext()) {Observer o = (Observer)it.next();o.update(this);}}
}
当具体观察对象发生更新时,就会调用notifyObservers(), 告知所有观察者。
为什么使用观察者模式
这里还是围绕一个要点:使类成为可复用的组件。
具体观察对象并不知道是谁在观察自己,也不需要知道,只需要把消息告诉观察对象即可。而观察者也不需要知道自己在观察谁,它只需要在观察对象那里注册即可。
在本书中已经出现多次这种课替换性的思想:
- 利用抽象类和接口从具体类中抽出抽象方法
- 将实例作为参数传入类中,或者在类的字段里保存实例,不使用具体类型,而是使用抽象类型和接口。
这样可以让我们轻松实现替换类。
备忘录模式 (Memento)
我们在编写代码时,如果不小心做了删除操作,可以使用ctrl+z来实现撤回。要使用面向对象的方法实现撤销,需亚奥事先保存实例的相关状态信息,并在需要时恢复状态。
通过备忘录模式,就可以实现保存和恢复实例,同时防止对象的封装性遭到破坏。
备忘录模式有如下角色:
- 生成者 Originator
- 备忘录 Memento
- 负责人 Caretaker
生成者负责在状态更新时,生成相应备忘录;如果把之前的备忘录传递给生成者,生成者会把自己恢复到当时的状态。
备忘录会把生成者的内部信息整合在一起,在其内部有两种接口:
- 宽接口,里面有关于恢复对象信息的所有方法的集合,但是由于内部信息过多,因此只有生成者能够访问;
- 窄接口则是给负责人使用的,只有有限的信息,可以防止信息泄露,防止封装性被破坏。
当负责人想要保存生成者状态时,会通知生成者角色,生成者此时会产生被万股并返回到负责人。负责人会在随后一直保存备忘录,以便在需要时回退。但是由于备忘录只对负责人开放窄接口,所有负责人只能把它当作一个黑盒保存起来。
为什么要分离负责人和生成者
为欸什么不直接在生成者中实现撤销功能,而要加一个备忘录呢?
负责人决定的是何时拍摄快照,合适撤销及保存备忘录;生成者则是负责生成备忘录和恢复状态。这样做是为了拆分任务,此时如果想实现多次撤销、保存现在状态等,就可以不用修改生成者。
状态模式 (State)
在状态模式中,我们将用类来实现状态。这可能有些难以理解,我们通常认为,类是名词,而不是形容词。但是在这里,我们就要介绍状态模式。
我们想来想想,不使用类时,我们会怎么表示状态:
使用金库时调用的方法() {if (白天) {报告使用记录} else if (晚上) {报告紧急情况}
}
警铃响起时调用的方法() {报告紧急情况
}
正常通话调用的方法() {if (白天) {正常通话} else if (晚上) {留言通话}
}
而使用了State模式:
表示白天的类 {使用金库时调用的方法() {报告使用记录}警铃响起时调用的方法() {报告紧急情况}正常通话调用的方法() {正常通话}
}表示晚上的类 {使用金库时调用的方法() {}警铃响起时调用的方法() {报告紧急情况}正常通话调用的方法() {留言通话}
}
在状态模式里有如下登场角色:
- 状态 State
- 具体状态 ConcreteState
- 上下文 Context
状态里面定义了根据不同状态进行不同处理的接口,接口里面是那些依赖于状态的方法的集合;具体状态继承状体,实现了那些接口;上下文的成员变量里存储有当前状态的成员变量,此外还提供了供外界调用的接口。
为什么使用状态模式
在编程时,我们经常使用分而治之的办法来应对大规模程序。相比于编写大量的if分支语句,把不同的状态用类拆分开来要好得多。
第九部分 避免浪费
享元模式 (Flyweight)
Flyweight是“轻量级”的意思。使用该设计模式是为了让对象变“轻”。
在Java中使用new来生成实例。为了保存该对象,需要给其分配足够内存空间;如果需要大量对象,那会占据大量空间。享元模式的要带你就是通过共享来避免生成新实例。
享元模式有如下角色:
- 轻量级 Flyweight
- 轻量级工厂 FlyweightFactory
- 请求者 Client
轻量级就是那些被共享的类;在轻量级工厂中生成的轻量级可以实现共享实例;请求者则通过轻量级工厂来拿到轻量级。
轻量级工厂示例如下:
public class FlyweightFactory {// 管理已经生成的BigChar的实例private HashMap pool = new HashMap();// Singleton模式private static FlyweightFactory singleton = new FlyweightFactory();// 构造函数private FlyweightFactory() {}// 获取唯一的实例public static FlyweightFactory getInstance() {return singleton;}// 生成(共享)Flyweight类的实例public synchronized Flyweight getFlyweight(String FlyweightName) {Flyweight bc = (Flyweight)pool.get("" + FlyweightName);if (bc == null) {bc = new Flyweight(FlyweightName); // 生成Flyweight的实例pool.put("" + FlyweightName, bc);}return bc;}
}
这样,如果已经有需要的Flyweight了,就会直接返回,而不是生成新的。
享元模式的拓展
如果我们实现了共享,那就要考虑到共享对象被改变的可能性。也就是说,如果单个Flyweight被改变,那么所有的都会改变。有时候这是好事,有时候我们却不希望发生,但这就是共享的特点。
另外,享元模式不仅是减少了内存的占用,也减少了因为使用new关键字产生的时间开销。
代理模式 (Proxy)
Proxy是“代理人”的意思,它指的是替别人工作的人。但是,如果遇到了不能解决的问题,还是需要交回给委托人处理。
在面向对象编程中,本人和代理人都是对象。如果本人对象太忙了,就交给代理人处理。
代理模式有以下登场角色:
- 主体 Subject
- 代理人 Proxy
- 实际主体 RealSubject
主体定义了代理人和实际主体之间具有一致性的接口,从而使得外界可以透明地调用它们而不需要关注是谁在工作;代理人继承自主体,会尽可能处理请求,同时其中保存有实际主体的成员变量(这里又用到了委托);实际主体也继承自主体,当代理人无法完成时,就会通过成员变量来调用到它。
为什么使用代理人
首先,使用代理人可以提升速度。把一些常用且简单的任务交到代理处,让其快速处理,只有遇复杂问题才交给实际主体。也可以是,在启动程序时,先加载简单且可以快速启动的代理人,这样用户可以更快地开始使用程序;而复杂臃肿的实际主体则放在后台缓慢加载。
不过这里有一个点需要注意,代理模式中的委托和现实是反过来的。现实中是本人委托给代理人处理,而代理模式中是代理人委托本人处理。
我们通常听到的HTTP代理也使用了代理模式。例如说,我们访问网页时,先访问的是能较快访问的缓存,其次才是访问速度较慢的web服务器。
第十部分 用类来表现
命令模式 (Command)
在状态模式里,我们提到了,状态可以是类。在命令模式里,命令也可以是类。
一个类在工作时可以调用自己活其它类的方法,但是这样做并不会留下记录。如果使用命令模式,我们就可以实现管理工作的历史记录。
命令模式非常常见,例如在用户界面中的点击鼠标、按下键盘等,都有命令模式参与其中。
命令模式有如下登场角色:
- 命令 Command
- 具体命令 ConcreteCommand
- 接收者 Receiver
- 请求者 Client
- 发动者 Invoker
命令角色负责定义命令的接口;具体命令继承命令并负责实现这些接口。接收者是执行命令的对象,也就是命令接收者。请求者负责生成具体命令角色并分配接收者角色;发动者是开始执行命令的角色,它会调用命令角色定义的接口API。
整个体系是这样工作的:在发动者发出命令后,请求者(注意发动者和请求者不是同一个概念)会new一个具体命令出来,并将接收者Receiver作为参数传到具体命令的构造函数里。然后,发动者会根据命令角色中定义的接口发出指令到具体角色,具体角色再委托其成员变量里的接收者(在构造函数中传入)来实现命令。
命令模式的扩展
关于命令应该包含哪些信息,其实并没有绝对的答案。根据目的不同,其包含的信息也不同。
此外,通过在具体命令中添加历史功能等,我们就可以实现保存历史记录。这种方式允许我们自由往其中添加新功能。
解释器模式 (Interpreter)
这里就到了最后一个设计模式。前面我们说,状态可以是类,命令可以是类,正在解释器模式里,语法规则也可以是类。
在解释器模式中,程序要解决的问题会用非常简单的“迷你语言”表示出来。而为了能在Java程序中运行迷你语言,就需要有一个解释器来进行翻译。
使用解释器模式后,修改程序时,我们可以只修改迷你语言,而不改动Java代码。
解释器模式有以下角色:
- 抽象表达式 AbstractExpression
- 终结符表达式 TerminalExpression
- 非终结符表达式 NonterminalExpression
- 上下文 Context
- 请求者 Client
抽象表达式定义了迷你语言所有语法都遵循的共同接口;终结符表达式继承抽象表达式,是表示迷你语言结束的表达式;非终结符表达式是迷你语言其余表达式;上下文为解释器进行语法解析提供了必要信息;请求者则利用终结符表达式和非终结符表达式来进行翻译。
在这里作者给出了很长的Java代码示例,用来解释一门控制小车进行前后左右等运动的语言,有兴趣可以参阅源书代码。
还有哪些其它的例子?
最典型的例子之一,我们平时所使用的数据库管理工具,其本身是用C++或者Java语言写的,但是却可以解析SQL语句,这其中就使用到了解释器模式。
以及,例如在Java语言中,如果想要对redis进行事务操作,这其中也经常使用到Lua作为嵌入Java代码的脚本语言,这也用到了解释器。
实际上,正则表达式某种程度也可以看作是解释器翻译的迷你语言。
相关文章:

一文速通23种设计模式——单例模式、工厂模式、建造者模式、原型模式、代理模式、装饰器模式、组合模式、组合模式、桥接模式、观察者模式、策略模式……
一文速通23种设计模式 写在前面 本文基于结城浩所著《图解设计模式》,其中所使用代码皆为Java版本。 随书代码下载地址-点击“随书下载” 全文15205字,全部读完需要约20分钟。 目录 一文速通23种设计模式写在前面 第一部分 适应设计模式迭代器模式 (…...

Lua 基础 04 模块
Lua 基础相关知识 第四期 require 模块,通常是一个表,表里存储了一些字段和函数,单独写在一个 lua 文件。 例如,这是一个 tools.lua 文件,定义了一个局部 tools 表,包含一个 log 函数,可以传…...

速递FineWeb:一个拥有无限潜力的15T Tokens的开源数据集
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提…...

HDLBits答案汇总
一.Getting Started Getting started-CSDN博客 二.Verilog Basics-CSDN博客 Vectors-CSDN博客 Module Hierarchy-CSDN博客 Procedures-CSDN博客 More Verilog Features-CSDN博客 三.Circuits Combinational Basic-CSDN博客 Multiplexers-CSDN博客 Arithmetic-CSDN博客 Karnau…...

云端数据提取:安全、高效地利用无限资源
在当今的大数据时代,企业和组织越来越依赖于云平台存储和处理海量数据。然而,随着数据的指数级增长,数据的安全性和高效的数据处理成为了企业最为关心的议题之一。本文将探讨云端数据安全的重要性,并提出一套既高效又安全的数据提…...
Java开发:Spring Boot 实战教程
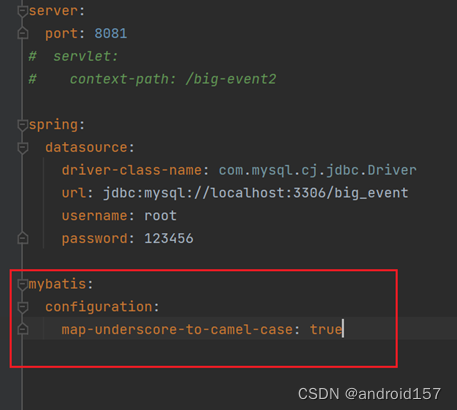
序言 随着技术的快速发展和数字化转型的深入推进,软件开发领域迎来了前所未有的变革。在众多开发框架中,Spring Boot凭借其“约定大于配置”的核心理念和快速开发的能力,迅速崭露头角,成为当今企业级应用开发的首选框架之一。 《…...
【Python3.11版本利用whl文件安装对应的dlib-19.24.1-cp311-cp311-win_amd64.whl库】
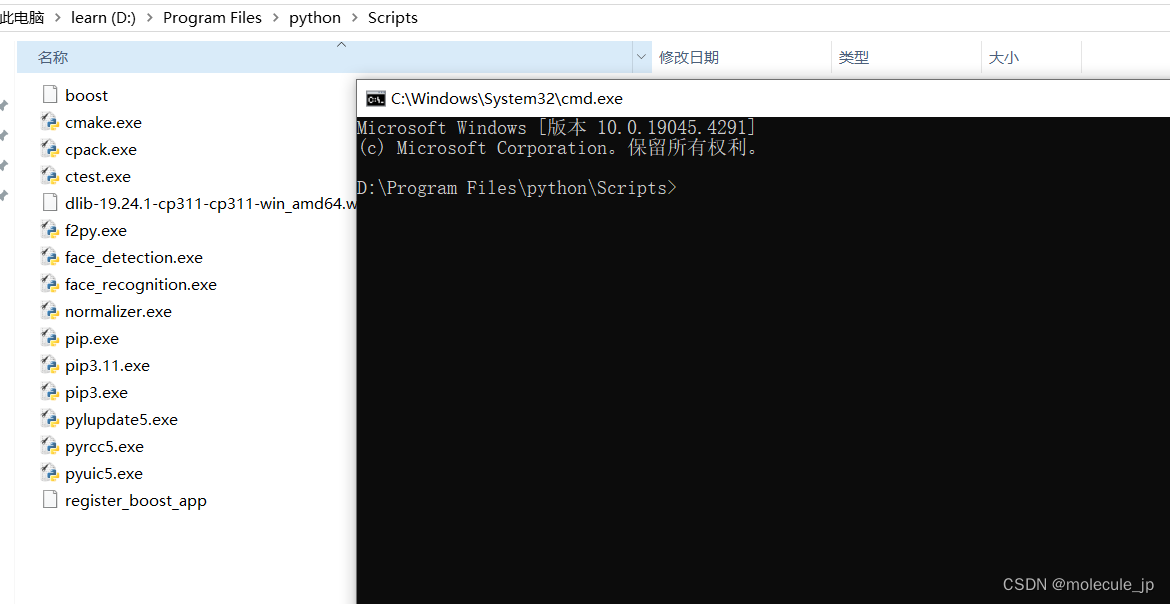
下载Python对应的安装包 找到自己Python版本对应的dlib whl库将网盘下载好的文件放在安装Python的Scripts路径下面接着在该路径输入cmdpip进行安装使用的是国内的源 找到自己Python版本对应的dlib whl库 python 3.11 对应 dlib-19.24.1-cp311-cp311-win_amd64.whl -i 也可以去…...
HW面试常见知识点2——研判分析(蓝队中级版)
🍀文章简介:又到了一年一度的HW时刻,本文写给新手想快速进阶HW蓝中的网安爱好者们, 通读熟练掌握本文面试定个蓝中还是没问题的!大家也要灵活随机应变,不要太刻板的回答) 🍁个人主页…...

鲁教版七年级数学下册-笔记
文章目录 第七章 二元一次方程组1 二元一次方程组2 解二元一次方程组3 二元一次方程组的应用4 二元一次方程与一次函数5 三元一次方程组 第八章 平行线的有关证明1 定义与命题2 证明的必要性3 基本事实与定理4 平行线的判定定理5 平行限的性质定理6 三角形内角和定理 第九章 概…...

带你走进在线直线度测量仪 解析测量方法!
在线直线度测量仪 在线直线度测量仪可安装于生产线上,进行非接触式的无损检测,能检测米直线度尺寸,对截面为圆形的产品,进性直线度检测的帮手。 测量方法 在线直线度拟采用我公司的光电测头对矫直后的棒材直线度进行测量。测量时…...

力扣1 两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你可以按任意顺序返回…...
AndroidFlutter混合开发
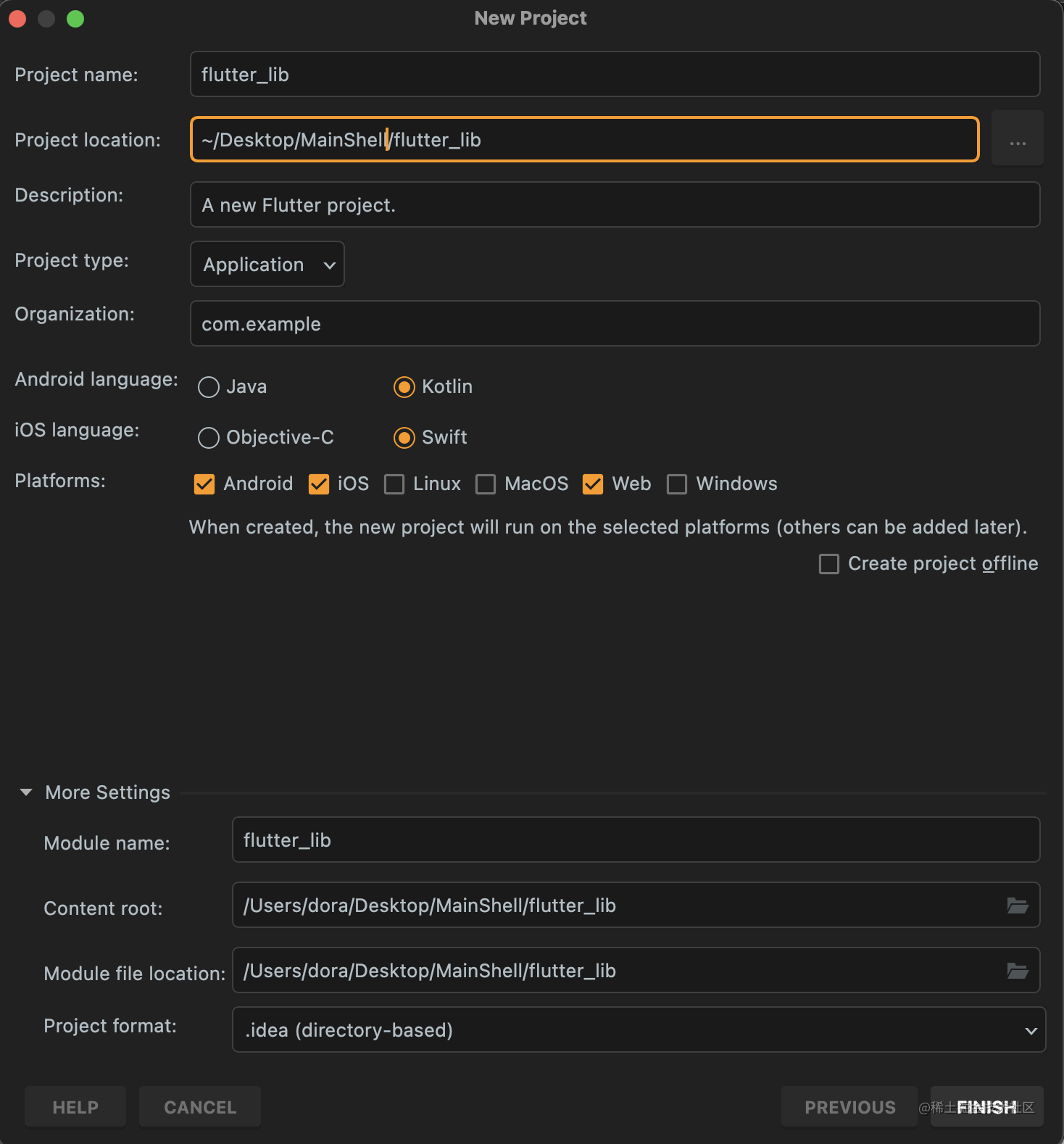
为什么要有混合开发 我们知道,Flutter是可以做跨平台开发的,即一份Flutter的Dart代码,可以编译到多个平台上运行。这么做的好处就是,在不降低多少性能的情况下,尽最大可能的节省开发的时间成本,直接将开发…...
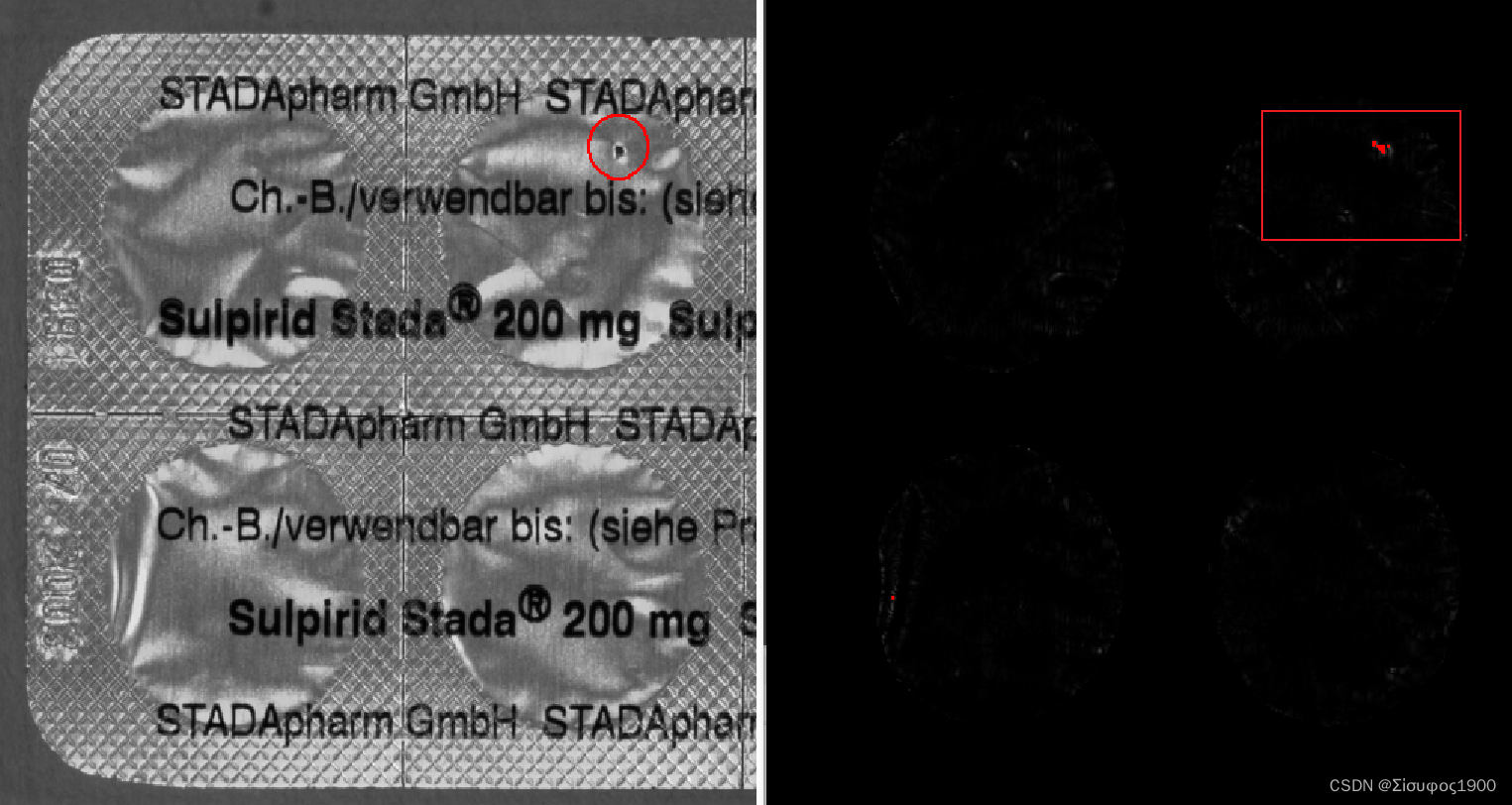
Halcon 光度立体 缺陷检测
一、概述 halcon——缺陷检测常用方法总结(光度立体) - 唯有自己强大 - 博客园 (cnblogs.com) 上周去了康耐视的新品发布会,我真的感觉压力山大,因为VM可以实现现在项目中的80% 的功能,感觉自己的不久就要失业了。同时…...

关于找暑期实习后的一些反思
日期 2024年6月3日 写在前面:距离研究生毕业还有9个月,前端时间一直在不停地投简历,不停地刷笔试题,不停地被拒绝,今天悬着的心终于死透了,心情还是比较糟糕的,可能唯一的安慰就是一篇小论文终于…...

Rust struct
Rust struct 1.实例化需要初始化全部成员变量2.如果需要实例化对象可变,加上mut则所有成员变量均可变 Rust支持通过已实例化的对象,赋值给未赋值的对象的成员变量 #![allow(warnings)] use std::io; use std::error::Error; use std::boxed::Box; use s…...
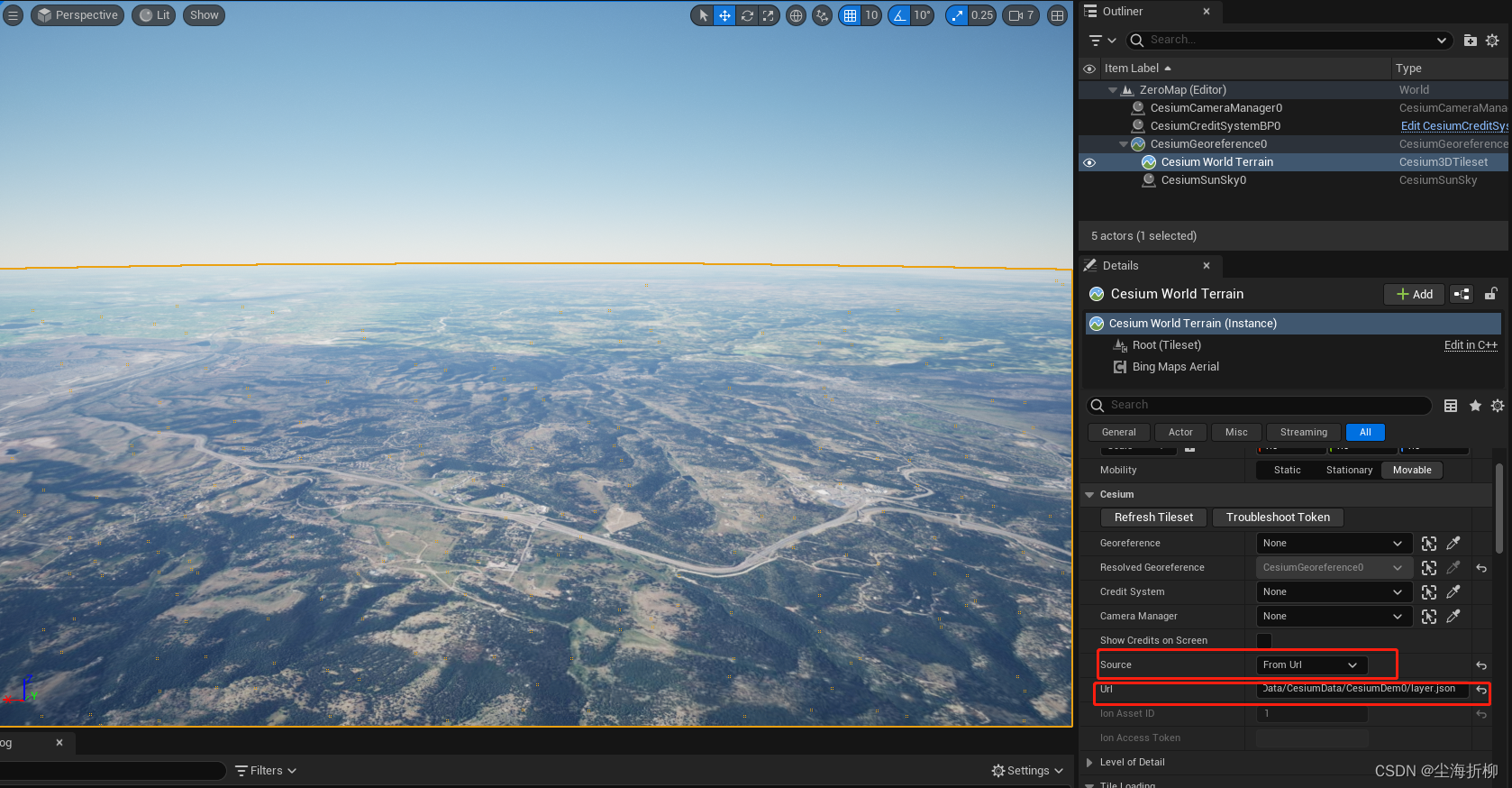
【UE5:CesiumForUnreal】——加载无高度地形数据
目录 1.实现目的 2.数据准备 2.1下载数据 2.2 数据切片 3.加载无地形数据 1.实现目的 在CesiumForUnreal插件中,我们加载地图和地形图层之后,默认都是加载的带有高程信息的地形数据,在实际的项目和开发中,有时候我们需要加载无…...
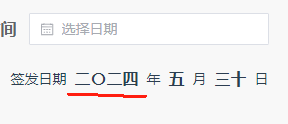
证件/文书类日期中文大写js/ts插件
说明 证件/文书类落款日期中文大写往往会将“零”写作“〇”,而数字依然使用简体“一二三”,而不是“壹贰叁”。 如下: 针对这一点,写了如下转换插件。 代码 function DateToUpperCase(date: Date new Date()) {const chStr …...
))
03JAVA基础(方法/类/封装(构造方法))
目录 1.方法 1.1 方法的定义 1.2 方法的重载 2.类和对象 3.封装 1. private关键字 2. this关键字 3. 封装 4. 构造方法 1.方法 含义: 将具有独立功能的代码块组织成一个整体,具有特殊功能的代码集 注意: 方法必须先创建才可以使用,需要手动调用执行 1.1 方法的定义 格…...

数据容器的通用操作、字符串大小比较 总结完毕!
1.数据容器的通用操作 1)五类数据容器是否都支持while循环/for循环 五类数据容器都支持for循环遍历 列表、元组、字符串都支持while循环,集合、字典不支持(无法下标索引) 尽管遍历的形式不同,但都支持遍历操作 2&a…...
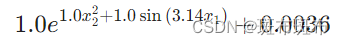
KAN(Kolmogorov-Arnold Network)的理解 3
系列文章目录 第一部分 KAN的理解——数学背景 第二部分 KAN的理解——网络结构 第三部分 KAN的实践——第一个例程 文章目录 系列文章目录前言KAN 的第一个例程 get started 前言 这里记录我对于KAN的探索过程,每次会尝试理解解释一部分问题。欢迎大家和我一起讨…...

剧本杀创作指南2025,解析,从零开始打造沉浸式推理体验
剧本杀创作指南2025,解析,从零开始打造沉浸式推理体验剧本杀作为一种新兴的娱乐方式,近年来在国内迅速崛起。随着市场需求的不断增长,越来越多的创作者开始尝试编写剧本杀剧本。本文将为你提供一份详尽的剧本杀创作指南࿰…...
)
别再死记硬背DH参数表了!用Python从零推导PUMA560机器人正运动学(附完整代码)
用Python实战解析PUMA560机器人运动学:从DH参数到三维可视化 在机器人学领域,正运动学分析是理解机械臂运动原理的基础。许多初学者面对抽象的Denavit-Hartenberg(DH)参数和复杂的坐标系变换时,常常陷入死记硬背的困境…...

如何提高SEO关键词优化推广的转化率
如何提高SEO关键词优化推广的转化率 在当今数字化时代,搜索引擎优化(SEO)已经成为企业在网络上获得曝光和流量的关键手段。在SEO中,关键词优化是提高网站排名的核心环节。单纯依靠关键词优化,并不能保证高转化率。如何…...

OpenClaw多模型对比:Qwen3-14b_int4_awq与开源小模型任务表现
OpenClaw多模型对比:Qwen3-14b_int4_awq与开源小模型任务表现 1. 测试背景与动机 最近在折腾OpenClaw自动化工作流时,发现一个关键问题:同样的任务脚本,换不同的大模型后端,执行效果差异巨大。为了找到最适合个人办公…...

系统辨识避坑指南:为什么你的脉冲响应总不准?从相关分析法到参数优化
系统辨识避坑指南:为什么你的脉冲响应总不准?从相关分析法到参数优化 系统辨识是控制工程中的一项基础技术,而脉冲响应作为系统动态特性的直接反映,其准确性直接影响后续控制器设计。但在实际工程中,许多开发者常遇到脉…...

BIOS更新全攻略:从版本检查到安全升级的实用指南
1. BIOS更新前的必要准备 每次打开电脑时,那个一闪而过的黑底白字界面就是BIOS(基本输入输出系统),它就像是电脑硬件的"总指挥"。我见过太多人因为盲目刷BIOS导致主板报废的案例,所以更新前一定要做好这些准…...

【ROS2】DDS通信协议在自动驾驶中的关键应用
1. DDS协议如何成为自动驾驶的"神经系统" 想象一下自动驾驶汽车在城市道路穿行的场景:激光雷达每秒产生数十万点云数据、摄像头实时捕捉高清图像、毫米波雷达持续监测周围物体运动状态——这些海量数据需要在感知、预测、决策模块间高速流转,任…...

智能能耗管理系统如何助力轨道交通实现绿色低碳运营
1. 轨道交通能耗管理的痛点与转型机遇 每天早高峰的地铁站里,黑压压的人群挤满站台,列车一趟接一趟地运送乘客。很少有人注意到,这些看似平常的运营背后,隐藏着惊人的能源消耗。以某一线城市地铁系统为例,单条线路年用…...

【2026 CVPR】Asking like Socrates: Socrates helps VLMs understand remote sensing images
RS-EoT (Remote Sensing Evidence-of-Thought) 研究旨在解决视觉语言模型(VLM)在处理遥感图像时的“虚假推理”问题 。 文章目录 核心问题 核心思想 核心方法 A. 数据合成:SocraticAgent Data Statistics B. 训练策略:两阶段渐进式强化学习 (RL) C. 训练策略 实验验证 主要…...
)
玉米脱粒机的毕业设计(论文+12张CAD图纸+开题报告+任务书……)
玉米脱粒机作为农业机械化的重要设备,其核心作用在于通过机械结构与动力系统的协同,实现玉米果穗与籽粒的高效分离。传统人工脱粒效率低、劳动强度大,而机械化脱粒通过旋转滚筒与筛网的配合,可显著提升处理速度,同时降…...