PieCloudDB Database Flink Connector:让数据流动起来
面对客户环境中长期运行的各种类型的传统数据库,如何优雅地设计数据迁移的方案,既能灵活地应对各种数据导入场景和多源异构数据库,又能满足客户对数据导入结果的准确性、一致性、实时性的要求,让客户平滑地迁移到 PieCloudDB 数据库生态,是一个巨大的挑战。PieCloudDB Database 打造了丰富的数据同步工具来实现数据的高效流动,本文将聚焦 PieCloudDB Flink Connector 工具进行详细的介绍。
拓数派旗下 PieCloudDB 是一款云原生分布式虚拟数仓,为企业提供全新基于云数仓数字化解决方案,助力企业建立以数据资产为核心的竞争壁垒,以云资源最优化配置实现无限数据计算可能。PieCloudDB 通过多种创新性技术将物理数仓整合到云原生数据计算平台,实现了分析型数据仓库上云虚拟化,打造了存储计算分离的全新 eMPP 架构,突破了传统 MPP 数据库多种瓶颈限制,打破客户生产环境数据孤岛的同时,也实现了按需瞬间扩缩容,大大减少了存储空间的浪费。
Apache Flink 是一个分布式流计算处理引擎,用于在无界或有界数据流上进行有状态的计算。它在所有的通用集群环境中都可以运行,在任意规模下都可以达到内存级的计算速度。Flink 最初由德国柏林工业大学的 Stratosphere 项目发展而来,是为了支持复杂的大规模数据分析任务而设计的,并于2014年成为 Apache 软件基金会的顶级项目。用户可以运用 Flink 提供的 DataStream API 或 Table SQL API,实现功能强大且高效的实时数据计算能力。此外,Flink 原生支持的 checkpoint 机制可以为用户提供数据的一致性的保证。
Apache Flink 作为一个流处理框架,与其他开源项目和工具的整合非常紧密。经过多年的发展,整个 Flink 社区已经围绕 Flink 构成出了一个丰富的生态系统。PieCloudDB 组件 PieCloudDB Flink Connector 是拓数派团队自研的一款 Flink 连接器, 可用于将来自 Flink 系统中的数据高效地写入 PieCloudDB,配合 Flink 的 checkpoint 机制来保证数据导入结果的精准一次语义。本文将详细介绍 PieCloudDB Flink Connector 的功能和原理,并结合实例进行演示。
1 PieCloudDB Flink Connector 功能介绍
PieCloudDB Flink Connector 可提供多种将 Flink 数据导入 PieCloudDB 的方式,包括 Append-Only 模式和 Merge 模式,以满足不同级别的导入语义。
在接入方式上,PieCloudDB Flink Connector 提供多种选择,包括使用 Flink DataStream API 编写相关的作业代码集成该组件,或者直接利用 Flink SQL 语句使用该组件。
PieCloudDB Flink Connector 提供 Merge 导入模式,采用幂等写方案,配合 Flink 原生支持的 checkpoint 机制,能够保证导入结果的可靠性和一致性。
此外,PieCloudDB Flink Connector 不仅支持支持单表实时数据导入,也可以支持整库实时数据同时导入。不过后者仅支持 Flink DataStream API 的接入方式,不支持使用 Flink SQL 语法。
2 PieCloudDB Flink Connector 原理
2.1 精准一次导入原理
PieCloudDB Flink Connector 中的 PieCloudDBSink、PieCloudDBWriter类分别实现了 Flink 的 StatefulSink、StatefulSinkWriter 接口。
当开启 Flink 的 checkpoint 功能后,在一个特定的 checkpoint 执行期间,PieCloudDBWriter 负责将接收到的数据源源不断地写入内存管道,同时异步线程会将这些数据拷贝到 PieCloudDB 中的内存临时表中。当 PieCloudDB Flink Connector 算子接收到 checkpoint 信号之后,会先等待数据全部拷贝进 PieCloudDB 后,再执行第二个阶段的动作,包括数据的合并以及写入物理表。整个过程中一旦出现异常,Flink 引擎就会自动从上一个 checkpoint 开始恢复作业,保证不会发生数据丢失。
在第二个阶段中,PieCloudDB Flink Connector 采用了幂等写方案,来保证不会出现数据重复。具体做法是,当数据全部导入 PieCloudDB 的临时表后,根据表的主键字段以及数据的时序关系进行合并操作,聚合这一段时间内每个主键对应记录的所有增删改操作得到最终结果,只将该结果写入 PieCloudDB 中。
这里的聚合操作是先根据写入数据的主键和时序进行组合,然后删除目标表中该主键对应的记录,最后将最新的修改或新增写入目标表。比如一条主键为1的记录,按照时间顺序发生了修改和删除操作,那么最终结果是将该主键对应的记录从 PieCloudDB 中删除。数据的写入时序与数据在 Flink 中的顺序一致,这些时序信息是通过在临时表扩充一个单独的 bigint 列来对每条数据做跟踪而记录下来的。应用这种幂等写方案,可以确保即使发生了数据重复,也能保证精确一次的导入语义。
上述 checkpoint 机制和幂等写过程如下图所示:
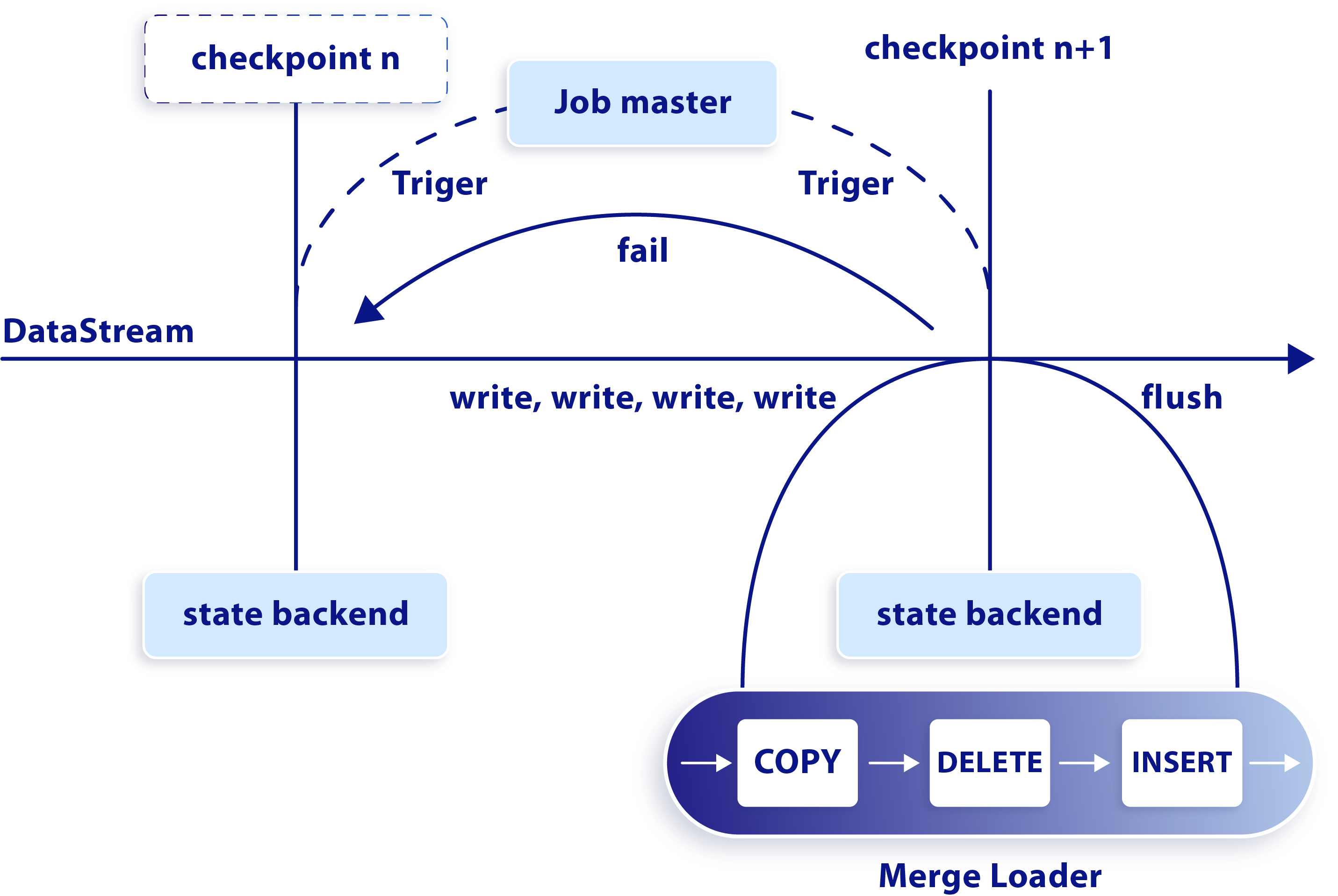
checkpoint 机制及幂等写过程
2.2 整库同步原理
对于整库同步场景来说,需要解决的是多表同时写入的问题和连接池通用性问题。 首先,对于整库同步场景来说,可能会存在多张表同时写入 PieCloudDB Flink Connector,前面处理单表的逻辑可能会导致新表数据处理的不及时,导致数据丢失。PieCloudDB Flink Connector 在内部维护了一套 Loader 池,在同一个 Flink checkpoint 周期内会为每张表都分配一个对应的 Loader,缓存在 Loader 池中。每张表写入的数据都分配给对应的 Loader 来处理,这里的处理逻辑与单表导入的处理逻辑一致。唯一的不同点在于,在 Flink checkpoint 周期结束时,PieCloudDB Flink Connector 会将该 checkpoint 内所有存在数据写入的表都刷入 PieCloudDB 中。
另一个在整库同步场景需要解决的问题是连接池的通用性问题。根据上面的设计,PieCloudDB Flink Connector 的每个实例都会维护一个 Loader 池,每个 Loader 都会占用一个 PieCloudDB 数据库连接。如果用户需要提升导入性能,一般最直接的做法是增加 Flink 作业的并行度,即创建多个 PieCloudDB Flink Connector 的实例来加速整库同步的速度,这对于具有海量历史数据的场景非常有必要。但这样会导致整个 Flink 作业需要的 PieCloudDB 数据库连接非常多,且不可控,因为无论是数据库表的数量,还是作业的并行度,都是无法预估的。仅仅通过设置内部连接池的最大连接数,只会导致作业运行时由于获取不到新的连接而无法处理,进而导致任务失败。
为了解决这一问题,PieCloudDB Flink Connector 在内部设计了一套简易的排队算法:如果数据库连接池的连接数已被占满,那么单个 checkpoint 内新来的表需要进行排队,直到 checkpoint 结束时等待其他表写入数据库并释放连接后,才会将这些排队中的表导入数据库。在此期间,这些排队的表的所有相关数据都会暂存到内存中。为了避免出现内存溢出,这里的原始数据已经提前解析好,只留下可以用于导入过程的关键信息,以大大降低内存使用率,避免出现内存溢出。使用此模型后,整库同步的过程就能保证数据库连接数全程都是可控的,最多不超过并发数和单个 PieCloudDB 数据库连接池最大连接数的乘积。
PieCloudDB Flink Connector 的整库同步功能需配合 PieCloudDB 动态作业执行器来使用,后续的文章中会进一步描述,欢迎关注!
3 PieCloudDB Flink Connector 使用演示
接下来,我们将用 MySQL 作为数据源来演示一下使用 PieCloudDB Flink Connector 将 MySQL 中的数据同步到 PieCloudDB 的过程。
创建 MySQL 源表:
create table student (id int primary key, name varchar(32), score int, sex char(1)); mysql> desc student;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| id | int | NO | PRI | NULL | |
| name | varchar(32) | YES | | NULL | |
| score | int | YES | | NULL | |
| sex | char(1) | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
4 rows in set (0.03 sec)
插入一些数据:
insert into student (id, name, score, sex) values (1, 'student1', 65, '1');
insert into student (id, name, score, sex) values (2, 'student2', 75, '0');
insert into student (id, name, score, sex) values (3, 'student3', 85, '1');
insert into student (id, name, score, sex) values (4, 'student4', 95, '0');mysql> select * from student;
+----+----------+-------+------+
| id | name | score | sex |
+----+----------+-------+------+
| 1 | student1 | 65 | 1 |
| 2 | student2 | 75 | 1 |
| 3 | student3 | NULL | NULL |
| 4 | student4 | NULL | NULL |
+----+----------+-------+------+
4 rows in set (0.01 sec)
创建 PieCloudDB 目标表(可以在 PieCloudDB 云原生管理平台的「数据洞察」功能页面进行):
create table student (id int primary key, name varchar(32), score int, sex char(1)); demo=> \d studentTable "public.student"Column | Type | Collation | Nullable | Default
--------+-----------------------+-----------+----------+---------
id | integer | | not null |
name | character varying(32) | | |
score | integer | | |
sex | character(1) | | |
目前是一张空表:
demo=> select * from student;id | name | score | sex
----+------+-------+-----
(0 rows)
启动 Flink 集群:
ubuntu :: work/flink/flink-1.18.0 >> bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host ubuntu.
Starting taskexecutor daemon on host ubuntu.
[INFo] 1 instance(s) of taskexecutor are already running on ubuntu.
Starting taskexecutor daemon on host ubuntu.
使用 Flink SQL 客户端工具连接集群,导入相关依赖,并开启 checkpoint:
Flink SQL> add jar '/home/frankie/work/download/flink-sql-connector-mysql-cdc-2.4.0.jar';
[INFO] Execute statement succeed.
Flink SQL> add jar '/home/frankie/work/download/flink-sql-connector-pieclouddb-1.2.0.jar';
[INFO] Execute statement succeed.
Flink SQL> SET 'execution.checkpointing.interval' = '3s';
[INFO] Execute statement succeed.
创建 Flink CDC 源表:
Flink SQL> CREATE TABLE source_student_mysql ( id INT, name STRING, score INT, sex CHAR(1), PRIMARY KEY(id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = 'mysql-host', 'port' = '3306', 'username' = 'root', 'password' = '123456', 'database-name' = 'testdb', 'table-name' = 'student');
[INFO] Execute statement succeed.
创建 Flink PieCloudDB 目标表:
Flink SQL> CREATE TABLE sink_student_pdb ( id INT, name STRING, score INT, sex CHAR(1), PRIMARY KEY(id) NOT ENFORCED ) WITH ( 'connector' = 'pieclouddb', 'hostname' = 'pieclouddb-host', 'port' = 'your-pieclouddb-port', 'username' = 'your-username', 'password' = 'your-password', 'pdb_warehouse' = 'your-pdbwarehouse', 'database-name' = 'demo', 'table-name' = 'student', 'load_mode' = 'merge');
[INFO] Execute statement succeed.
执行导入:
Flink SQL> INSERT INTO sink_student_pdb SELECT * FROM source_student_mysql;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 660b747ef8fb64f95064a461af9924bc
查看 Flink 的 WebUI,可以看到这个数据导入的流任务在持续运行:
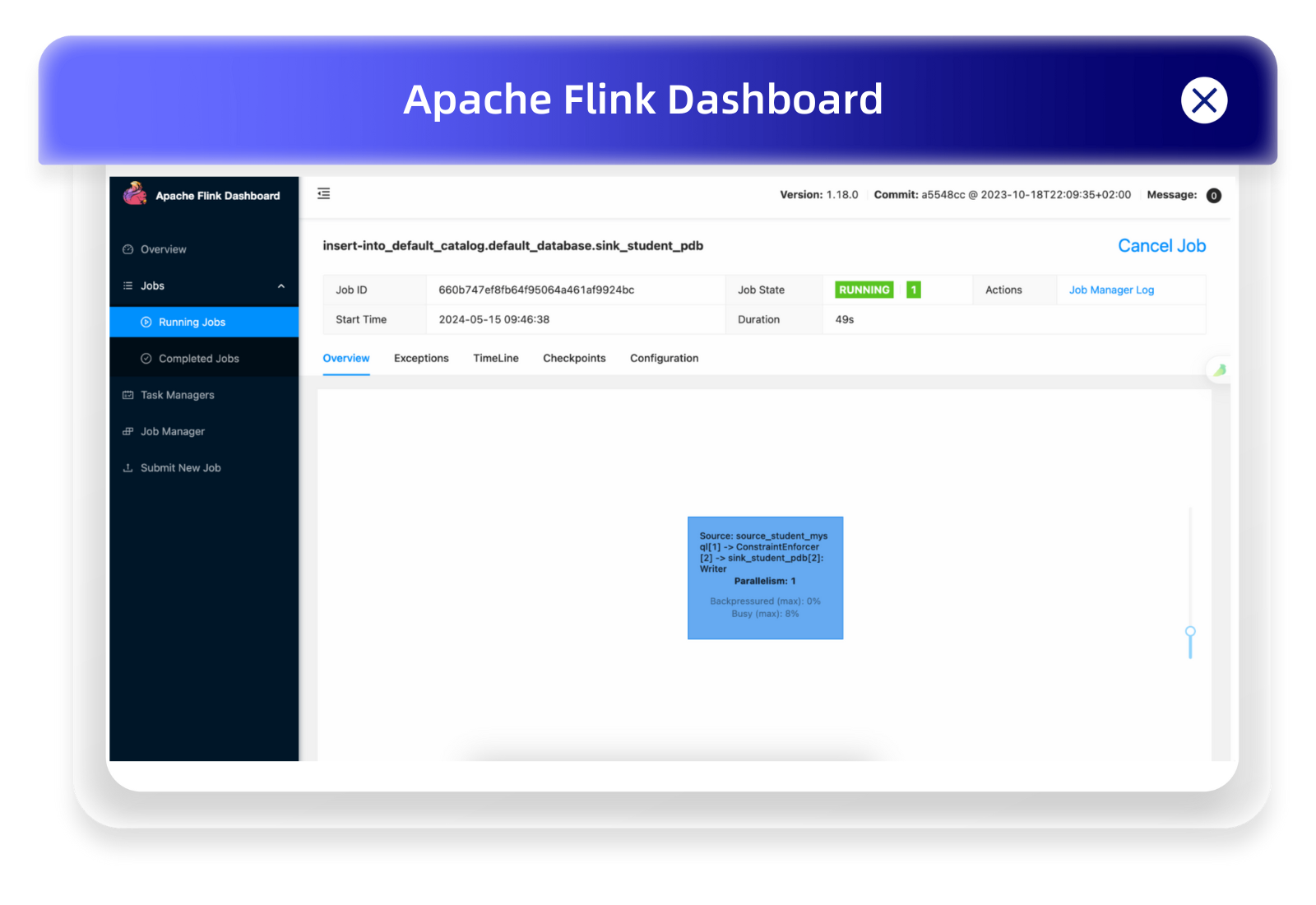
Flink Web 操作界面
查看 PieCloudDB 中的数据,可以看到数据已经正确导入
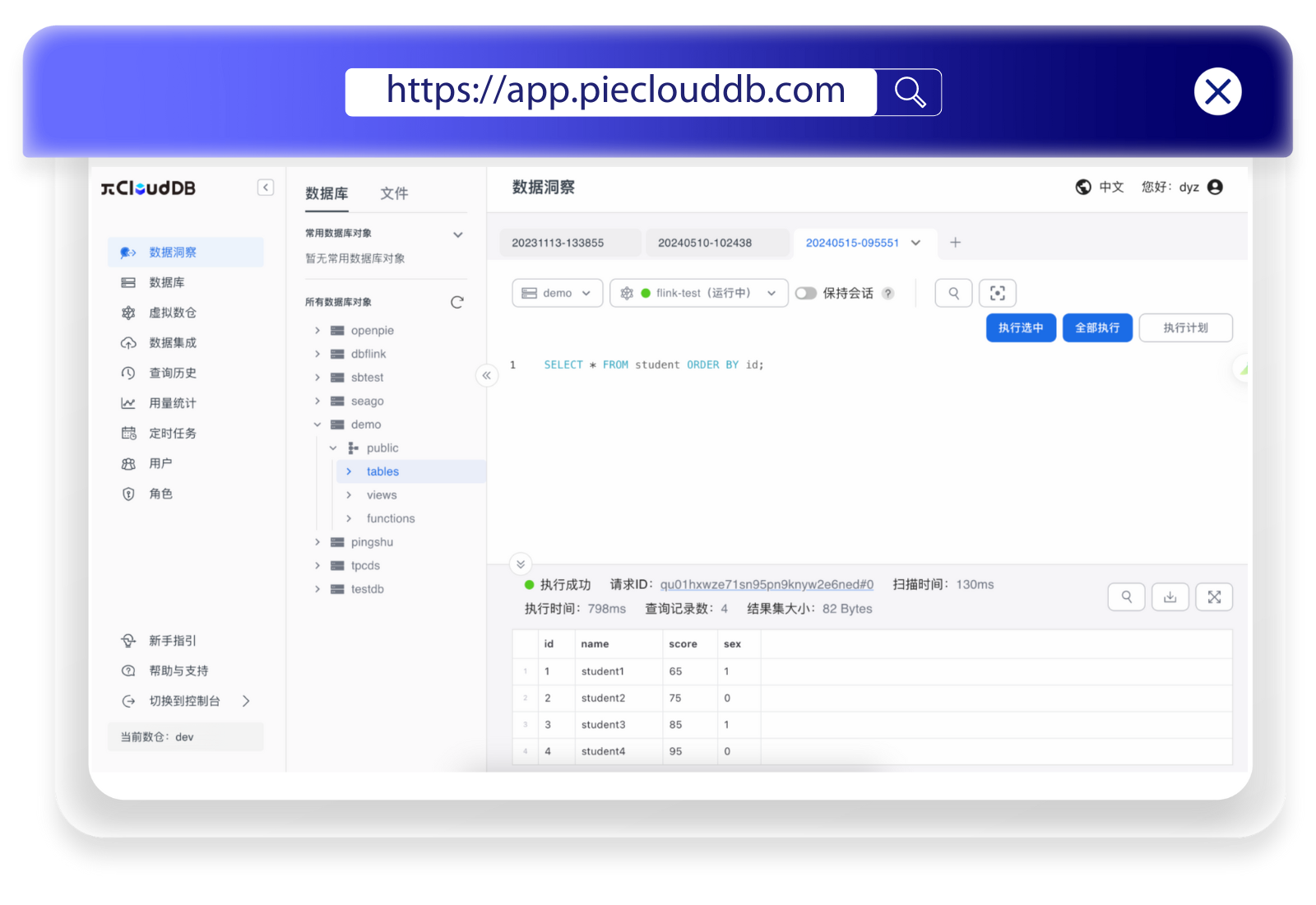
数据成功导入 PieCloudDB
除了使用 Flink SQL 的接入方式之外,PieCloudDB Flink Connector 还支持通过 Flink Datastream API 来使用。
未来,拓数派团队致力于对 PieCloudDB Flink Connector 进行持续的功能增强与迭代升级,计划引入高级特性,如 schema evolution 以及动态加表功能,以满足更复杂的数据处理需求。
同时,PieCloudDB 将持续扩展其数据同步工具组件的生态,致力于打造更为全面和强大的连接工具,包括 Flink、Spark 等大数据处理框架的集成工具,以及 CDC(Change Data Capture)和 Kafka 等实时数据同步工具,让用户将能够实现数据的高效流动和实时处理,进一步释放数据的潜力。
相关文章:
PieCloudDB Database Flink Connector:让数据流动起来
面对客户环境中长期运行的各种类型的传统数据库,如何优雅地设计数据迁移的方案,既能灵活地应对各种数据导入场景和多源异构数据库,又能满足客户对数据导入结果的准确性、一致性、实时性的要求,让客户平滑地迁移到 PieCloudDB 数据…...

主机CPU访问PCIe设备内存空间和PCIe设备访问主机内存空间
在x86体系架构中,主机CPU访问PCIe设备内存空间和PCIe设备访问主机内存空间的过程涉及多个层次的地址映射和转换。以下是详细的解释: 主机CPU访问PCIe设备内存空间 1. CPU生成虚拟地址(Virtual Address, VA): 在x86架构中&#…...

在家AIAA(美国航空航天学会)文献如何查找下载
今天有位同学的求助文献来自AIAA(美国航空航天学会),下面就讲一下不用求助他人自己就可搞定文献下载的途径并实例操作演示。 首先我们先对AIAA(美国航空航天学会)数据库做个简单的了解: 美国航空航天学会…...

dnf手游版游玩感悟
dnf手游于5月21号正式上线,作为一个dnf端游老玩家,并且偶尔上线ppk,自然下载了手游版,且玩了几天。 不得不说dnf手游的优化做到了极好的程度。 就玩法系统这块,因为dnf属于城镇地下城模式,相比…...
安卓如何书写注册和登录界面
一、如何跳转一个活动 左边的是本活动名称, 右边的是跳转界面活动名称 Intent intent new Intent(LoginActivity.this, RegisterActivity.class); startActivity(intent); finish(); 二、如果在不同的界面传递参数 //发送消息 SharedPreferences sharedPreferen…...

黄仁勋的AI时代:英伟达GPU革命的狂欢与挑战
在最近的COMPUTEX 2024大会上,英伟达创始人黄仁勋发布了最新的Blackwell GPU。这次发布不仅标志着英伟达在AI领域的又一次飞跃,也展示了其对未来技术发展的战略规划。本文将详细解析英伟达最新技术的亮点,探讨其在AI时代的市场地位和未来挑战…...

Linux云计算架构师涨薪班课程内容包含哪些?
第一阶段:Linux云计算运维初级工程师 目标 云计算工程师,Linux运维工程师都必须掌握Linux的基本功,这是一切的根本,必须全部掌握,非常重要,有了这些基础,学习上层业务和云计算等都非常快&#x…...
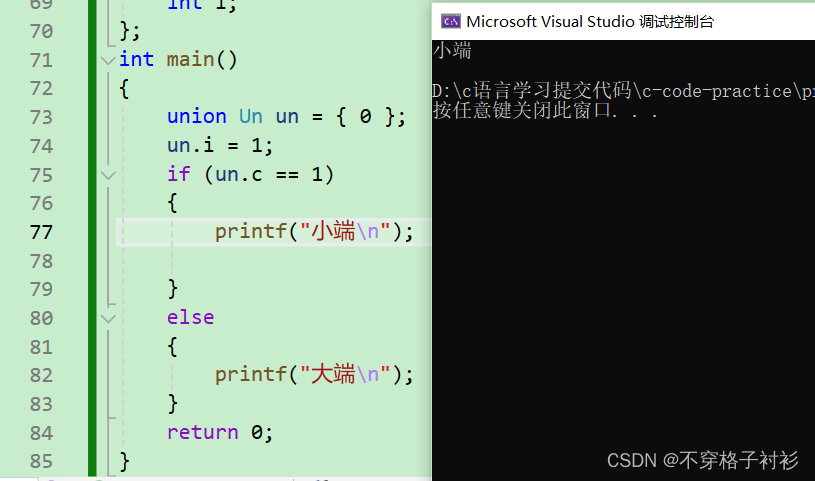
c语言:自定义类型(枚举、联合体)
前言: c语言中中自定义类型不仅有结构体,还有枚举、联合体等类型,上一期我们详细讲解了结构体的初始化,使用,传参和内存对齐等知识,这一期我们来介绍c语言中的其他自定义类型枚举和联合体的知识。 1.位段 …...

2024年适合GISer参加的全国性比赛
作为一名GISer,在校期间参加GIS比赛,不仅能够锻炼和提升自己的GIS专业水平,例如软件操作、开发能力等;还能加强自己团队协作能力、组织能力和沟通能力,此外,还可以给简历加分,增强职场竞争力。 …...
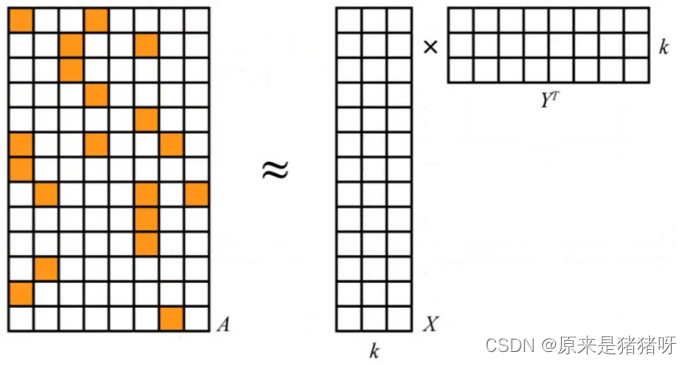
番外篇-用户购物偏好标签BP-推荐算法ALS
引言 推荐系统式信息过载所采用的措施,面对海量的数据信息,从中快速推荐出符合用户特点的物品。 推荐系统是自动化的通过分析用户对历史行为数据,完成用户的个性化建模,从而主动给用户推荐能够满足他们兴趣和需求的软件系统。 数…...

气膜体育馆的防火性能分析—轻空间
随着现代体育事业的蓬勃发展,气膜体育馆因其建设快捷、成本低廉、使用灵活等优势,逐渐在全球范围内受到广泛关注。然而,对于这种新型建筑形式,防火性能一直是人们关注的焦点之一。轻空间将详细探讨气膜体育馆的防火性能࿰…...

什么台灯对眼睛好?一文给你分享具体什么台灯对眼睛好!
什么台灯对眼睛好?随着学生们最近陆续返校,家长们和孩子们都忙于开学初的准备工作,而眼睛的健康自然也是他们考虑的一部分。这也是护眼台灯在近年来变得非常普及的原因之一。我自己一直是一个近视的人,而且日常用眼时间也相当长。…...

python-bert模型基础笔记0.1.00
python-bert模型基础笔记0.1.00 bert的适合的场景bert多语言和中文模型bert模型两大类官方建议模型模型中名字的含义标题bert系列模型包含的文件bert系列模型参数参考链接bert的适合的场景 裸跑都非常优秀,句子级别(例如,SST-2)、句子对级别(例如MultiNLI)、单词级别(例…...
STM32G030C8T6:EEPROM读写实验(I2C通信)--M24C64
本专栏记录STM32开发各个功能的详细过程,方便自己后续查看,当然也供正在入门STM32单片机的兄弟们参考; 本小节的目标是,系统主频64 MHZ,采用高速外部晶振,实现PB11,PB10 引脚模拟I2C 时序,对M24C08 的EEPRO…...

opencascade 布尔运算笔记
BRepAlgoAPI_Common 对两个topods求解 没有公共部分也返回结果了 我想要的结果是没有公共部分返回false 在 Open CASCADE 中使用 BRepAlgoAPI_Common 进行布尔操作时,即使两个 TopoDS_Shape 没有公共部分,操作仍会返回一个结果。为了判断两个形状是否确…...

GPT-4o:人工智能新纪元的突破与展望
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

标准化、信息化、数字化、智能化、智慧化与数智化
近年来,标准化、信息化、数字化、智能化、智慧化以及数智化等词汇频繁出现,并逐渐成为业界热议的焦点。在国内,以华为、BAT等为代表的领军企业,不断强调“数字化转型”的重要性,并致力于推动其深入实施。与此同时&…...

14-JavaScript中的点操作符与方括号操作符
JavaScript中的点操作符与方括号操作符:简单理解与应用 笔记分享 在JavaScript中,访问对象的属性有两种常见方式:点操作符(.)和方括号操作符([])。尽管它们在很多情况下可以互换使用࿰…...

智慧大屏是如何实现数据可视化的?
智慧大屏,作为数据可视化的重要载体,已在城市管理、交通监控、商业运营等领域广泛应用。本文旨在阐述智慧大屏实现数据可视化的关键技术和方法,包括数据源管理、数据处理、视觉编码、用户界面与交互设计等。 大屏通过接入企业内部的数据库系…...
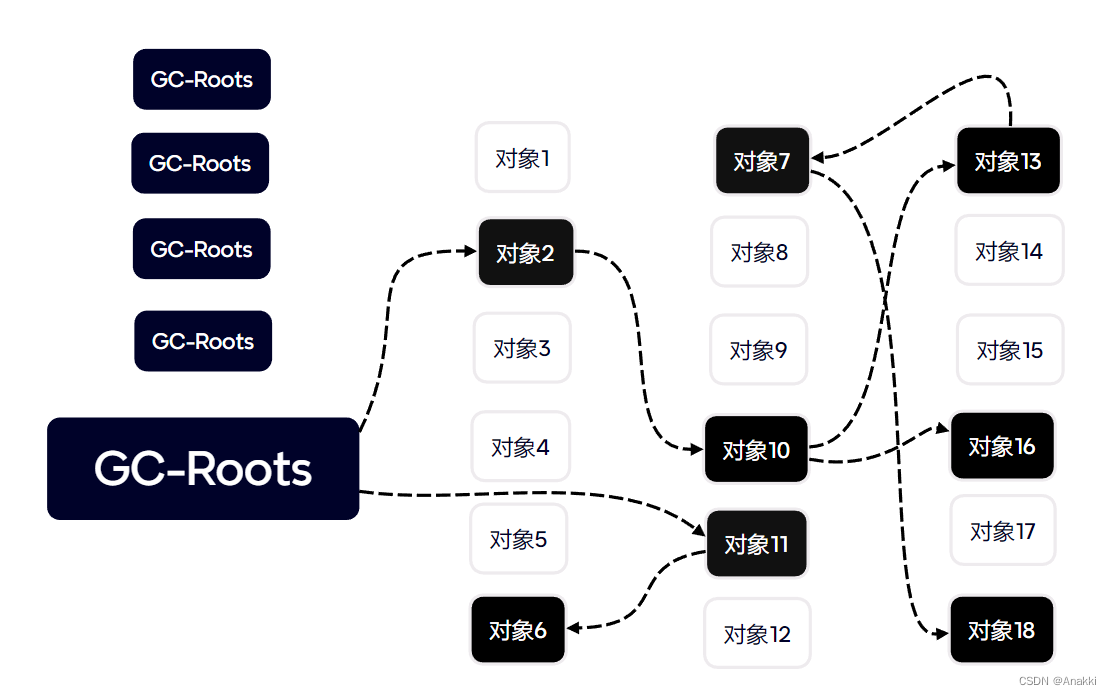
【JVM精通之路】垃圾回收-三色标记算法
首先预期你已经基本了解垃圾回收的相关知识,包括新生代垃圾回收器,老年代垃圾回收器,以及他们的算法,可达性分析等等。 先想象一个场景 最开始黑色节点是GC-Roots的根节点,这些对象有这样的特点因此被选为垃圾回收的根…...

游戏脚本助手,电脑点击器,脚本自动点击识图找图_无限试用版
熊猫精灵脚本助手 分类功能项其他功能管理、插件、生成、中控、进程守护、护盾配置、坐标工具脚本设置窗口设置、绑定设置、运行设置、变量设置、程序设置图色识别Yolo识别、找图识别、点色找色文字识别ocr识别找字、字库识别、验证码识别键鼠操作鼠标操作、键盘操作、录制脚本…...

餐饮店主的AI助手:像素特工Ostrakon-VL快速上手,自动检查厨房卫生与陈列
餐饮店主的AI助手:像素特工Ostrakon-VL快速上手,自动检查厨房卫生与陈列 1. 为什么餐饮店主需要AI视觉助手 想象一下这样的场景:早上开店前,你匆匆拍下厨房的照片,上传到一个系统。几秒钟后,它告诉你&…...

从演示到实战:基于快马平台构建一个功能完整的AI绘画社区应用
今天想和大家分享一个很有意思的实战项目 - 在InsCode(快马)平台上构建一个功能完整的AI绘画社区应用。这个想法来源于阿里悟空官网展示的AI绘画应用场景,但我们要做的是更贴近真实产品的综合性解决方案。 项目整体规划 首先需要明确,一个完整的AI绘画社…...

零基础入门机器人抓取:在快马平台轻松搞定龙虾openclaw安装与第一个程序
最近在学习机器人抓取相关的知识,发现龙虾openclaw是个不错的入门工具。作为一个完全零基础的小白,我在安装和配置环境时遇到了不少困难。好在发现了InsCode(快马)平台,它帮我轻松解决了这些问题。下面分享一下我的学习过程。 了解openclaw …...

新手零基础入门:用快马AI生成你的第一个互联网个人主页
作为一个刚接触编程的新手,想要制作个人主页却不知从何下手是很常见的情况。最近我在InsCode(快马)平台上尝试用AI生成我的第一个网页,整个过程比想象中简单很多,特别适合零基础入门。下面分享我的学习过程和收获。 明确需求很关键 在开始前&…...

工业机器人离线编程与仿真——RobotStudio基础学习3.27
工业机器人离线编程与仿真——RobotStudio基础学习 一、工业机器人离线编程认知 1.1 工业机器人常用编程方法 工业机器人主流编程方法分为示教编程和离线编程两类,二者核心差异体现在编程环境、对生产的影响等方面,具体对比见下表: 示教编…...

自主飞行控制探索:PX4开源飞控的模块化架构与行业应用价值
自主飞行控制探索:PX4开源飞控的模块化架构与行业应用价值 【免费下载链接】PX4-Autopilot PX4 Autopilot Software 项目地址: https://gitcode.com/gh_mirrors/px/PX4-Autopilot PX4开源飞控系统作为无人机领域的核心解决方案,通过模块化架构设计…...

Citra模拟器终极指南:免费畅玩3DS游戏的完整教程
Citra模拟器终极指南:免费畅玩3DS游戏的完整教程 【免费下载链接】citra A Nintendo 3DS Emulator 项目地址: https://gitcode.com/gh_mirrors/cit/citra 任天堂3DS模拟器Citra是一款开源的高性能游戏模拟工具,让PC用户能够流畅体验《精灵宝可梦》…...

告别复杂操作!Wan2.2-I2V-A14B一键生成480P高清视频
告别复杂操作!Wan2.2-I2V-A14B一键生成480P高清视频 1. 视频创作新体验:简单三步生成专业级视频 你是否曾经为制作一段简单的视频而头疼?传统视频制作需要学习复杂的剪辑软件,花费大量时间调整参数,甚至需要专业的拍…...

3分钟搞定Axure中文界面:终极汉化指南让原型设计更简单
3分钟搞定Axure中文界面:终极汉化指南让原型设计更简单 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在为Axure …...