数据分析必备:一步步教你如何用Pandas做数据分析(17)
1、Pandas 连接
Pandas 连接的操作实例
Pandas具有与SQL等关系数据库非常相似的功能齐全的高性能内存中连接操作。
Pandas提供单个功能merge作为DataFrame对象之间所有标准数据库联接操作的入口点
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,left_index=False, right_index=False, sort=True)
在这里,我们使用了以下参数:
left − 一个DataFrame对象。
right − 另一个DataFrame对象。
on − 列(名)加入上。必须在左右DataFrame对象中都找到。
left_on − 左侧DataFrame中的列用作键。可以是列名,也可以是长度等于DataFrame长度的数组。
right_on − 右侧DataFrame中的列用作键。可以是列名,也可以是长度等于DataFrame长度的数组。
left_index − 如果为True,则使用左侧DataFrame的索引(行标签)作为其连接键。如果DataFrame具有MultiIndex(分层),则级别数必须与右侧DataFrame中的连接键数匹配。
right_index − 相同的使用作为left_index为正确的数据帧。
how − “左”,“右”,“外”,“内”之一。默认为内部。每种方法已在下面描述。
sort − 排序的结果数据框中加入字典顺序按键。默认情况下为True,在许多情况下,设置为False将大大提高性能。
现在让我们创建两个不同的DataFrame并对其执行合并操作。
import pandas as pd
left = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})
right = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id':['sub2','sub4','sub3','sub6','sub5']})
print(left)
print(right)
运行结果
id Name subject_id
0 1 Alex sub1
1 2 Amy sub2
2 3 Allen sub4
3 4 Alice sub6
4 5 Ayoung sub5id Name subject_id
0 1 Billy sub2
1 2 Brian sub4
2 3 Bran sub3
3 4 Bryce sub6
4 5 Betty sub5
1.1、在一个键上合并两个数据框
import pandas as pd
left = pd.DataFrame({'id': [1, 2, 3, 4, 5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id': ['sub1', 'sub2', 'sub4', 'sub6', 'sub5']})
right = pd.DataFrame({'id': [1, 2, 3, 4, 5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id': ['sub2', 'sub4', 'sub3', 'sub6', 'sub5']})
print(pd.merge(left, right, on='id'))
运行结果
id Name_x subject_id_x Name_y subject_id_y
0 1 Alex sub1 Billy sub2
1 2 Amy sub2 Brian sub4
2 3 Allen sub4 Bran sub3
3 4 Alice sub6 Bryce sub6
4 5 Ayoung sub5 Betty sub5
1.2、在多个键上合并两个数据框
import pandas as pd
left = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})
right = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id':['sub2','sub4','sub3','sub6','sub5']})
print(pd.merge(left,right,on=['id','subject_id']))
运行结果
id Name_x subject_id Name_y
0 4 Alice sub6 Bryce
1 5 Ayoung sub5 Betty
1.3、合并使用“how”参数
合并的how参数指定如何确定要在结果表中包括哪些键。如果左侧或右侧表中均未出现组合键,则联接表中的值为NA。
这里的一个总结如何选择和他们的SQL等价的名字:
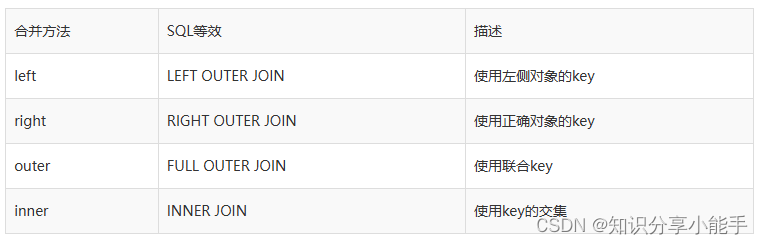
1.4、左连接
import pandas as pd
left = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})
right = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id':['sub2','sub4','sub3','sub6','sub5']})
print(pd.merge(left, right, on='subject_id', how='left'))
运行结果
id_x Name_x subject_id id_y Name_y
0 1 Alex sub1 NaN NaN
1 2 Amy sub2 1.0 Billy
2 3 Allen sub4 2.0 Brian
3 4 Alice sub6 4.0 Bryce
4 5 Ayoung sub5 5.0 Betty
1.5、右连接
import pandas as pd
left = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})
right = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id':['sub2','sub4','sub3','sub6','sub5']})
print(pd.merge(left, right, on='subject_id', how='right'))
运行结果
id_x Name_x subject_id id_y Name_y
0 2.0 Amy sub2 1 Billy
1 3.0 Allen sub4 2 Brian
2 NaN NaN sub3 3 Bran
3 4.0 Alice sub6 4 Bryce
4 5.0 Ayoung sub5 5 Betty
1.6、外连接
import pandas as pdleft = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})right = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id':['sub2','sub4','sub3','sub6','sub5']})print(pd.merge(left, right, how='outer', on='subject_id'))
运行结果
id_x Name_x subject_id id_y Name_y
0 1.0 Alex sub1 NaN NaN
1 2.0 Amy sub2 1.0 Billy
2 NaN NaN sub3 3.0 Bran
3 3.0 Allen sub4 2.0 Brian
4 5.0 Ayoung sub5 5.0 Betty
5 4.0 Alice sub6 4.0 Bryce
1.7、内连接
连接将在索引上执行。联接操作接受调用它的对象。因此,a.join(b)不等于b.join(a)。
import pandas as pdleft = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],'subject_id':['sub1','sub2','sub4','sub6','sub5']})right = pd.DataFrame({'id':[1,2,3,4,5],'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],'subject_id':['sub2','sub4','sub3','sub6','sub5']})print(pd.merge(left, right, on='subject_id', how='inner'))
运行结果
id_x Name_x subject_id id_y Name_y
0 2 Amy sub2 1 Billy
1 3 Allen sub4 2 Brian
2 4 Alice sub6 4 Bryce
3 5 Ayoung sub5 5 Betty
相关文章:
数据分析必备:一步步教你如何用Pandas做数据分析(17)
1、Pandas 连接 Pandas 连接的操作实例 Pandas具有与SQL等关系数据库非常相似的功能齐全的高性能内存中连接操作。 Pandas提供单个功能merge作为DataFrame对象之间所有标准数据库联接操作的入口点 pd.merge(left, right, howinner, onNone, left_onNone, right_onNone,left_i…...
检查用户是否在错误的目录中运行了CMake命令
我们知道,在CMake中执行,我们一般是以下3条命令: mkdir build cd build cmake .. 这样可以避免 生成的一些文件污染 代码目录。 但是有一些不熟悉CMake的依然会直接在当前目录配置,比如 CMake . 那么我们如何在CMakeLists.…...
—— Commitlint(v19.3.0):规范化 Git 提交)
前端工程化工具系列(四)—— Commitlint(v19.3.0):规范化 Git 提交
commitlint 是对 Git 提交的 message 进行校验的工具。 1. 环境要求 v19 以上的 Stylelint,支持 Node.js 的版本为 v18 。 在命令行中输入以下内容后回车,来查看当前系统中 Node.js 的版本。 node -vNode.js 推荐使用 v18.20.3 或者 v20.13.1。 这里使…...

<vs2022><问题记录>visual studio 2022使用console打印输出时,输出窗口不显示内容
前言 本文为问题记录。 问题概述 在使用visual studio 2022编写代码时,如C#,在代码中使用console.writeline来打印某些内容,以便于观察,但发现输出窗口不显示,而代码是完全没有问题的。 解决办法 根据网上提供的办法…...

推荐一个免费的相亲工具
推荐一个免费的相亲工具,步骤如下: 1)微信里面搜索公众号“光源桥”,并关注 2)输入搜索条件进行搜索对象 例如下面搜索:...
写一个盲盒模拟器
最近想写一个小程序,随便写一个玩吧,先想了下功能: 1.有很多盲盒,可以选择模拟开启 2.自定义盲盒,我们可以自定义制作盲盒自己玩 3.用户界面,记录盲盒历史,可以给坏越提意见 所用技术栈&…...

Java使用正则表达式匹配以某个字符开始,某个字符结束
前言 好久没用regex了,之前用的贼溜的东西都忘完了,这次遇到一个东西恰好我觉得用正则表达式会方便一点,所以把这次的开发过程记录一下 这遍文章包括Java如何使用正则表达式去匹配解决正确的表达式却匹配不到数据的问题使用正则表达式却出现栈溢出的问题背景需求 首先我会根…...

什么叫硬编码?如何避免硬编码
硬编码(Hardcoding或Hard-coding)是指在编写程序时,直接将具体的值(如字符串、数字、路径等)写入源代码中,而不是通过变量、配置文件、数据库查询或其他动态方法来获取这些值。这种方式虽然简单直接&#x…...

RK3588 Android13自定义一个按键实现长按短按
一、kernel修改 diff --git a/arch/arm64/boot/dts/rockchip/rk3588-nvr-demo.dtsi b/arch/arm64/boot/dts/rockchip/rk3588-nvr-demo.dtsi index 5aae5c613825..4cc1223f9cbf 100755 --- a/arch/arm64/boot/dts/rockchip/rk3588-nvr-demo.dtsib/arch/arm64/boot/dts/rockchip…...

映射网络驱动器自动断开的解决方法
如果将驱动器映射到网络共享,映射的驱动器可能会在定期处于非活动状态后断开连接,并且 Windows 资源管理器可能会在映射驱动器的图标上显示红色 X。,出现此行为的原因是,系统可以在指定的超时期限后断开空闲连接, (默认…...
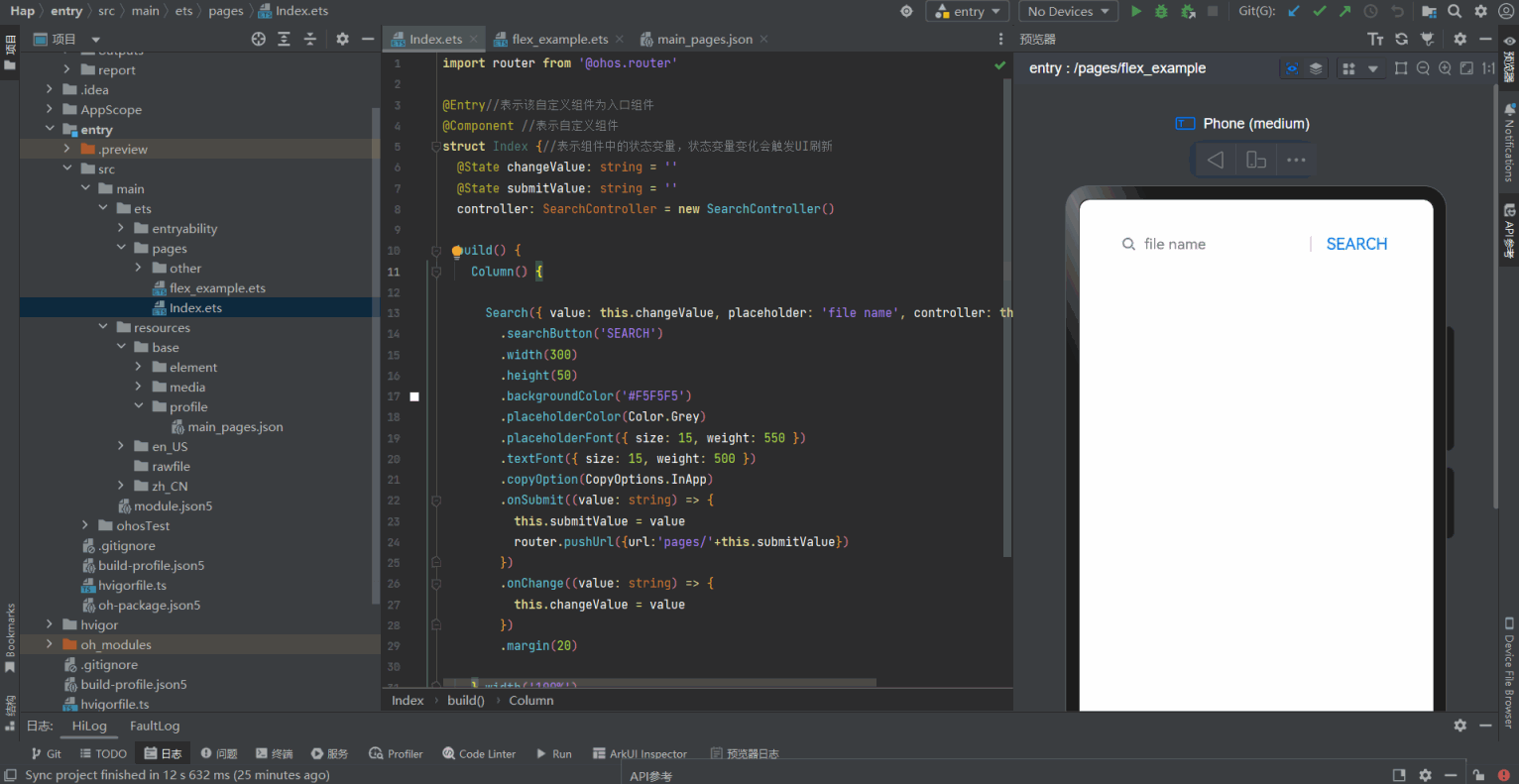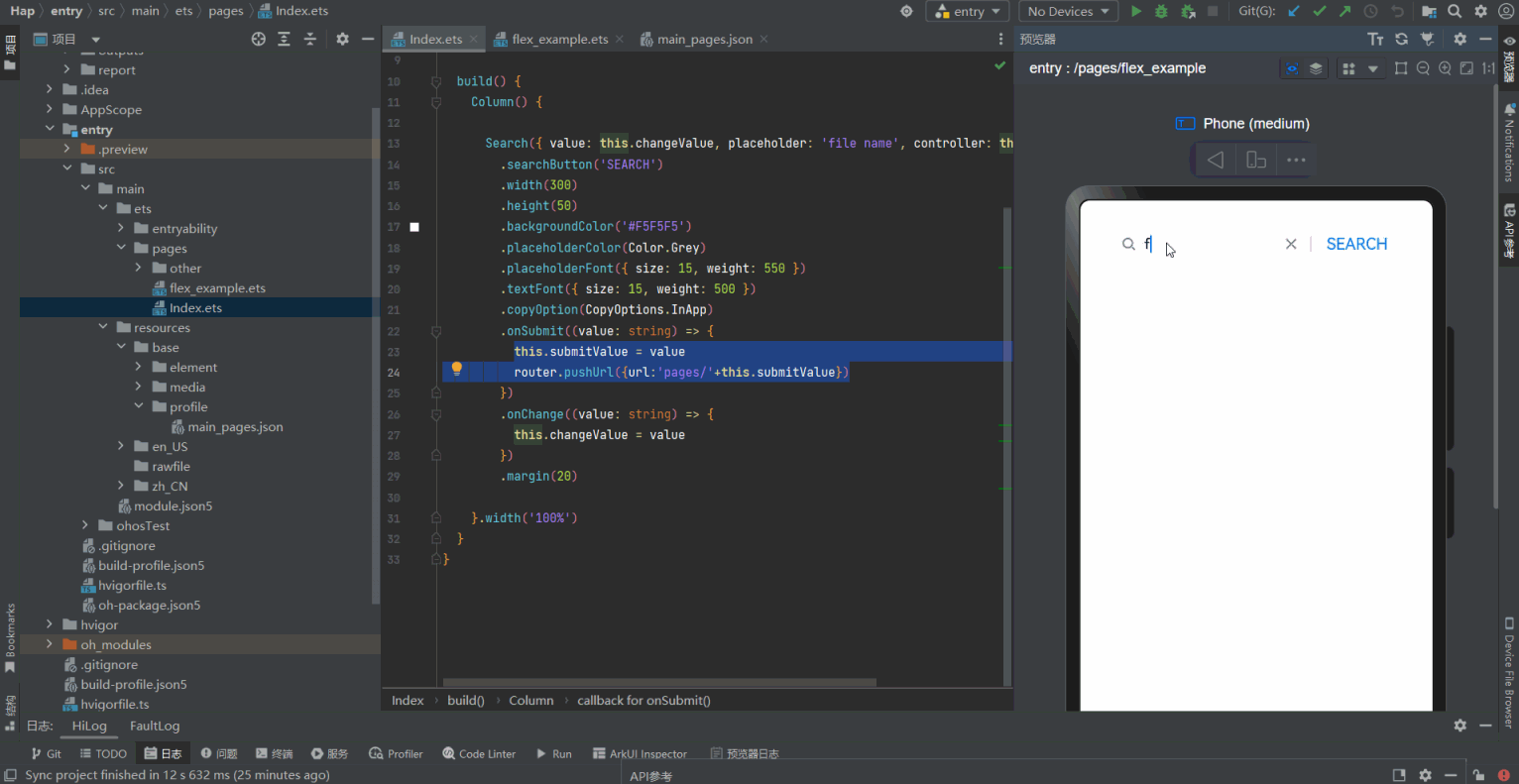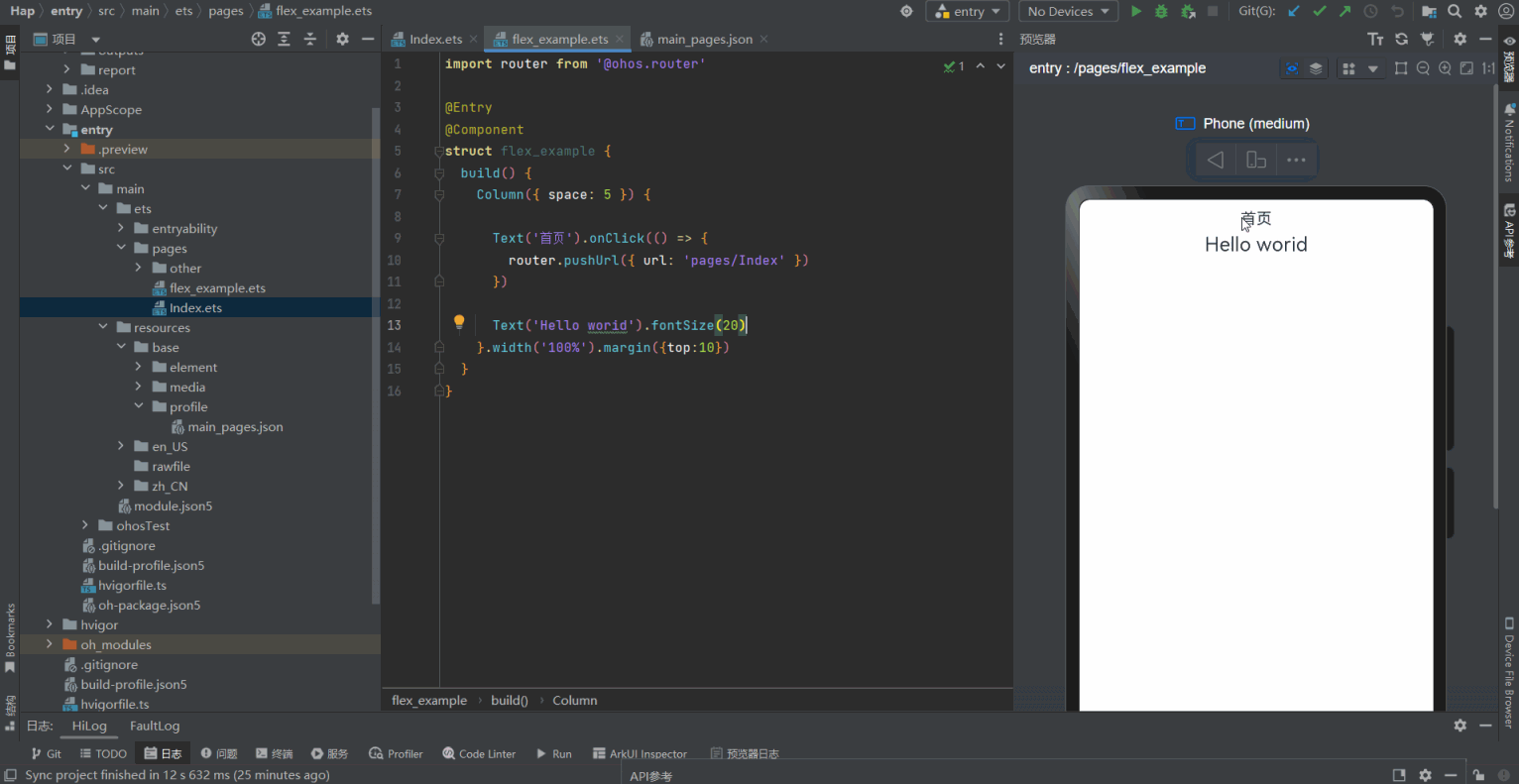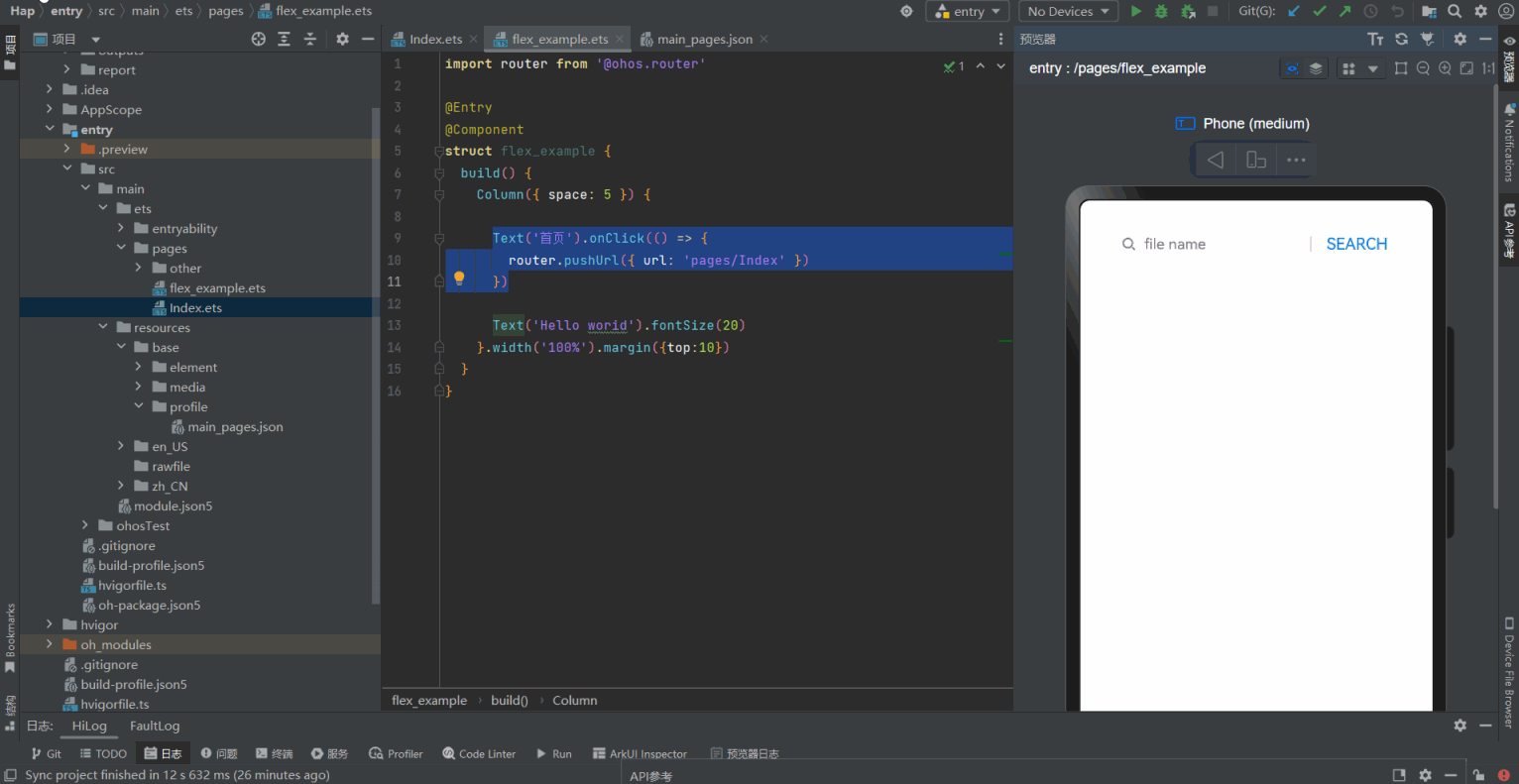
(Arkts界面示例)ets pages Demo(笔记版本0.0.1)
数据类型概述number数值boolean布尔string字符串undefined一个未定义或不存在的值null空object对象Symbol独一无二的值bigint任意大的整数enum枚举any任意unknown未知类型void没有任何返回值的类型never永远不存在的类型 Index.ets 文件 import router from ohos.routerEntry/…...

Python 动态导入库
Python 动态导入库 从一个文件夹下遍历所有.py文件,并利用__Import__()函数实现全局导入 例程 import os # 导入操作系统接口模块 import sys # 导入系统模块# 将当前目录下的 DIR 目录添加到系统路径中,以便后续导入模块 sys.path.append(./DIR)# …...

【WP|8】深入解析WordPress钩子函数
钩子函数(Hook)是WordPress插件和主题开发中最重要的概念之一。钩子函数允许开发者在特定的时刻或事件发生时插入自定义代码,以改变WordPress的默认行为或者添加新功能。钩子分为两种主要类型:动作(Actions)…...

Java集合简略记录
一、集合体系结构 单列集合:Collection 双列集合:Map 二、单列集合 List系列集合:添加的元素是有序、可重复、有索引 有序指的是存和取的顺序是一致的,和之前排序的从小到大是没有任何关系的 Set系列集合:添加的元素是…...

能获取淘宝商品简化链接的浏览器书签
零.冗长的商品链接 访问网页版本淘宝时,浏览器的地址栏显示的链接太长就像这样(此链接非真实商品): 于是使用如下方法 一.使用浏览器书签获取淘宝商品简化链接 1.新建书签 Chrome - 打开书签管理器(CtrlShiftO) - 左侧选择书签…...
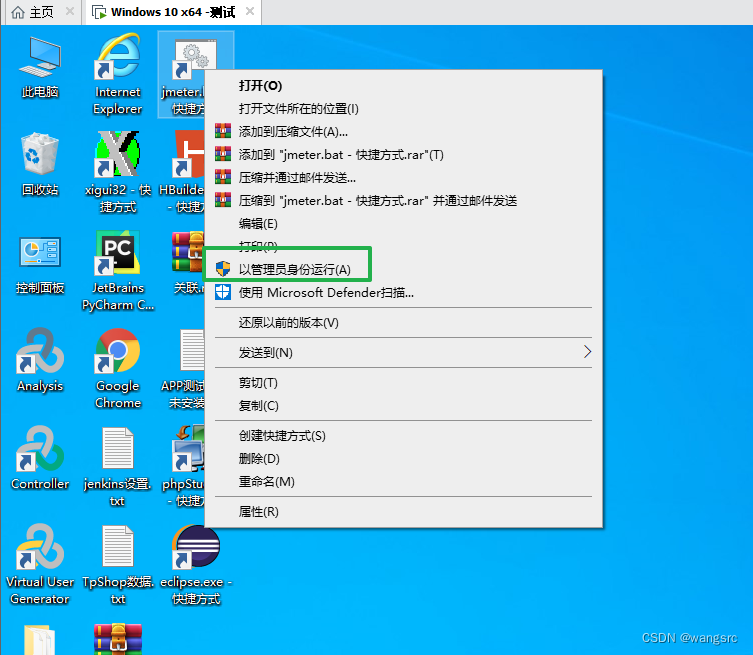
JMeter Plugins Manager---插件安装
参考文章:https://blog.51cto.com/u_14126/6291032 需求: 安装【jpgc - Standard Set】插件 常用插件: 点击下载–报错如下: Failed to apply changes:Cannotapplychanges:Haveno write accessforJMeterdirectories,notpossib…...

docker-compose入门级实战教程
🌟🌌 欢迎来到知识与创意的殿堂 — 远见阁小民的世界!🚀 🌟🧭 在这里,我们一起探索技术的奥秘,一起在知识的海洋中遨游。 🌟🧭 在这里,每个错误都…...

MATLAB sort
对数字数组排序对字符串排序对 cell 数组排序降序排序对多维数组排序对结构体数组排序注意事项 在 MATLAB 中, sort 函数用于对数组进行排序。 sort 函数可以对数字数组、字符串、 cell 数组等进行升序或降序排序。以下是 sort 函数的一些常见用法:…...

AB测试实战
AB测试实战 1、AB测试介绍🐾 很多网站/APP的首页都会挂一张头图(Banner),用来展示重要信息,头图是否吸引人会对公司的营收带来重大影响,一家寿险公司Humana设计了如下三张头图,现在需要决定使用哪一张放到首页&#x…...
)
Java高级面试精粹:问题与解答集锦(六)
Java 面试问题及答案 1. 请解释Java中的多线程概念,并说明如何实现它? 答案: 多线程是指在Java程序中同时运行多个线程的功能。线程是程序执行的最小单元,Java中的多线程可以通过继承Thread类或实现Runnable接口来实现。 继承Th…...
Pixel Couplet Gen 生成效果对比分析:不同参数下的对联质量评估
Pixel Couplet Gen 生成效果对比分析:不同参数下的对联质量评估 1. 引言:当AI遇上传统对联 春节贴对联是中国延续千年的文化传统,但创作一副既工整又有新意的对联并非易事。Pixel Couplet Gen作为一款AI对联生成工具,通过调整Te…...

价值投资中的智能城市废水处理与再利用系统分析
价值投资中的智能城市废水处理与再利用系统分析 关键词:价值投资、智能城市、废水处理、废水再利用、系统分析 摘要:本文聚焦于价值投资视角下的智能城市废水处理与再利用系统。首先介绍了研究的背景,包括目的、预期读者、文档结构和相关术语。接着阐述了智能城市废水处理与…...
)
让你的调试日志五彩斑斓:J-Link RTT高级封装技巧(支持中文、浮点数、十六进制)
让你的调试日志五彩斑斓:J-Link RTT高级封装技巧(支持中文、浮点数、十六进制) 调试是嵌入式开发中不可或缺的一环,而高效的调试工具能显著提升开发效率。J-Link RTT(Real Time Transfer)作为一种无需额外硬…...

FreeRTOS进阶:任务优先级与调度策略深度解析
1. FreeRTOS任务优先级基础 在嵌入式实时操作系统中,任务优先级决定了任务执行的先后顺序。FreeRTOS采用数值越大优先级越高的设计,优先级范围通常为0到(configMAX_PRIORITIES-1)。我刚开始接触FreeRTOS时,经常混淆这个概念,直到在…...

从零搭建无人船:两年实战后,我总结的ArduPilot+Pixhawk避坑全流程
从零搭建无人船:两年实战后,我总结的ArduPilotPixhawk避坑全流程 第一次把无人船放进水里时,GPS信号突然丢失,船体在河中央失控打转——这个惊心动魄的瞬间让我意识到,开源飞控的实战应用远不是下载代码、连接硬件那么…...

像素幻梦效果对比:原生FLUX.1-dev vs 像素幻梦定制版输出质量分析
像素幻梦效果对比:原生FLUX.1-dev vs 像素幻梦定制版输出质量分析 1. 引言 在数字艺术创作领域,像素艺术因其独特的复古美感和现代应用价值而备受关注。Pixel Dream Workshop(像素幻梦)作为基于FLUX.1-dev模型构建的专业像素艺术…...

uniapp 雪花算法封装类
1. uniapp 雪花算法封装类 雪花算法(SnowFlake)生成64位整数ID,具有全局唯一、趋势递增、高性能等特点,适合分布式系统。 1.1. 解决分布式全局唯一ID的方法 1.1.1. UUID UUID做全局ID的弊端:UUID是由数字加字母的形式组成,无法保持递增,它使得聚簇索引(主键值和行数据…...

忍者像素绘卷镜像免配置部署:自动检测GPU型号并加载最优配置
忍者像素绘卷镜像免配置部署:自动检测GPU型号并加载最优配置 1. 产品概览:打破次元壁的像素艺术工作站 忍者像素绘卷是一款基于Z-Image-Turbo深度优化的图像生成工作站,专为像素艺术创作而设计。它将传统漫画创作与现代AI技术相结合&#x…...

DCT-Net人像卡通化效果展示:高清人脸转二次元虚拟形象作品集
DCT-Net人像卡通化效果展示:高清人脸转二次元虚拟形象作品集 一键将真人照片变成二次元虚拟形象,体验AI绘画的神奇魅力 1. 效果惊艳:从真人到二次元的华丽变身 DCT-Net人像卡通化技术能够将普通的人物照片转换成精美的二次元虚拟形象&#x…...

React-primitives项目架构剖析:模块化设计与依赖注入原理
React-primitives项目架构剖析:模块化设计与依赖注入原理 【免费下载链接】react-primitives Primitive React Interfaces Across Targets 项目地址: https://gitcode.com/gh_mirrors/re/react-primitives React-primitives是一个跨平台UI开发框架࿰…...