进阶C语言——数据的存储【详解】
文章目录
- 1. 数据类型介绍
- 1.1 类型的基本归类
- 2. 整形在内存中的存储
- 2.1 原码、反码、补码
- 2.2 大小端介绍
- 2.3 练习
- 3. 浮点型在内存中的存储
- 3.1 一个例子
- 3.2 浮点数存储的规则
1. 数据类型介绍
前面我们已经学习了基本的内置类型:
char //字符数据类型
short //短整型
int //整形
long //长整型
long long //更长的整形
float //单精度浮点数
double //双精度浮点数
以及他们所占存储空间的大小。
类型的意义:
- 使用这个类型开辟内存空间的大小(大小决定了使用范围)。
- 如何看待内存空间的视角
1.1 类型的基本归类
整形家族:
char
unsigned char
signed char
short
unsigned short [int] (int 可省略)
signed short [int] (int 可省略)
int
unsigned int
signed int
long
unsigned long [int] (int 可省略)
signed long [int] (int 可省略)
signed修饰有符号的数(既可以放负数又可以放正数)unsigned只能修饰正数int= [signed] int sigened可以省略char是不是signed char取决于编译器
浮点数家族:
float
double
构造类型:(自定义类型)
> 数组类型> 结构体类型 struct> 枚举类型 enum> 联合类型 union
指针类型
int pi;
char pc;
float pf;
void pv;
空类型:
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型

2. 整形在内存中的存储
一个变量的创建是要在内存中开辟空间的。空间的大小是根据不同的类型而决定的。
接下来我们看看数据在所开辟内存中到底是如何存储的?
比如:
int a = 20;
int b = -10;
我们知道为 a 分配四个字节的空间。
那如何存储?
先了解下面的概念:
2.1 原码、反码、补码
计算机中的整数有三种2进制表示方法,即原码、反码和补码。
三种表示方法均有符号位和数值位两部分,符号位都是用0表示“正”,用1表示“负”,而数值位 正数的原、反、补码都相同。 负整数的三种表示方法各不相同。
原码
直接将数值按照正负数的形式翻译成二进制就可以得到原码。
反码
将原码的符号位不变,其他位依次按位取反就可以得到反码。
补码
反码+1就得到补码。
对于整形来说:数据存放内存中其实存放的是补码。
为什么呢?
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统 一处理;
同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程 是相同的,不需要额外的硬件电路。
#include <stdio.h>
int main()
{int a = 20;////00000000000000000000000000010100 - 原码//00000000000000000000000000010100 - 反码//00000000000000000000000000010100 - 补码//00000014int b = -10;////10000000000000000000000000001010 - -10的原码//11111111111111111111111111110101 - -10的反码//11111111111111111111111111110110 - -10的补码//FFFFFFF6return 0;
}
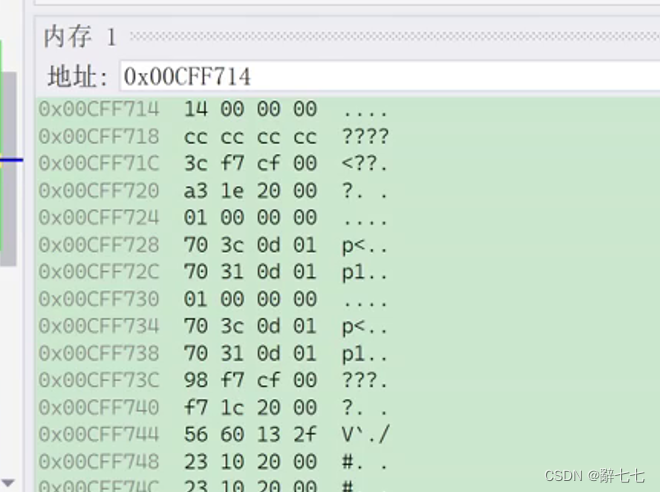
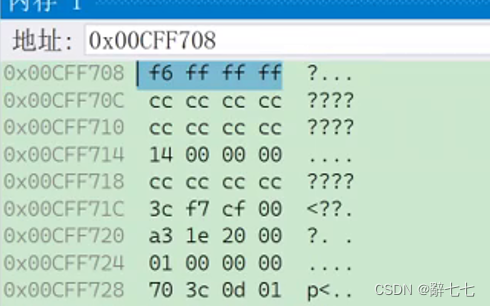
调试后我们可以看到对于a和b分别存储的是补码。但是我们发现顺序有点不对劲。
这是又为什么?
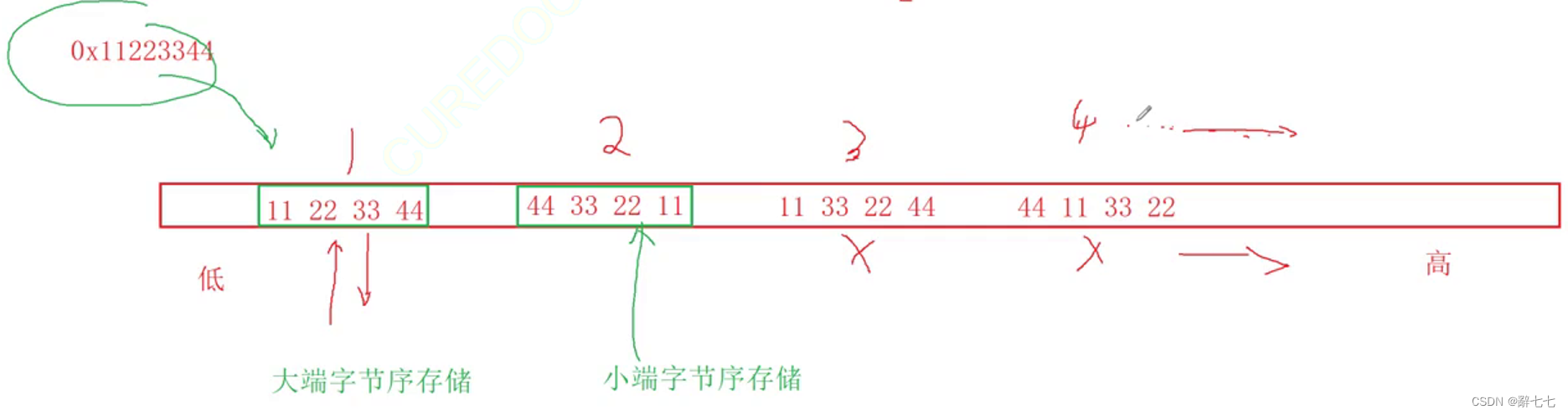
2.2 大小端介绍
什么大端小端:
大端(存储)模式,是指数据的低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中;
小端(存储)模式,是指数据的低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中
画图演示:
为什么有大端和小端:
为什么会有大小端模式之分呢?这是因为在计算机系统中,我们是以字节为单位的,每个地址单元 都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit的char之外,还有16 bit的short 型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因 此就导致了大端存储模式和小端存储模式。
例如:一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为 高字节, 0x22为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高 地址中,即 0x0011中。小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式 还是小端模式
百度2015年系统工程师笔试题:
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。
//如果是大端返回0
//如果是小端返回1
#include <stdio.h>
int check_sys()
{int i = 1;return (*(char*)&i);
}
int main()
{int ret = check_sys();if (ret == 1){printf("小端\n");}else{printf("大端\n");}return 0;
}
运行结果:

2.3 练习
练习1
//1.输出什么?
#include <stdio.h>
int main()
{char a = -1;//10000000000000000000000000000001 原码//11111111111111111111111111111110 反码//11111111111111111111111111111111 补码//11111111 - 截断//整型提升//11111111111111111111111111111111//11111111111111111111111111111110//10000000000000000000000000000001 -1signed char b = -1;//signed char与 char结果一样unsigned char c = -1;//11111111 - 截断//00000000000000000000000011111111无符号数高位直接补零printf("a=%d,b=%d,c=%d", a, b, c);return 0;
}
char的二进制序列计算
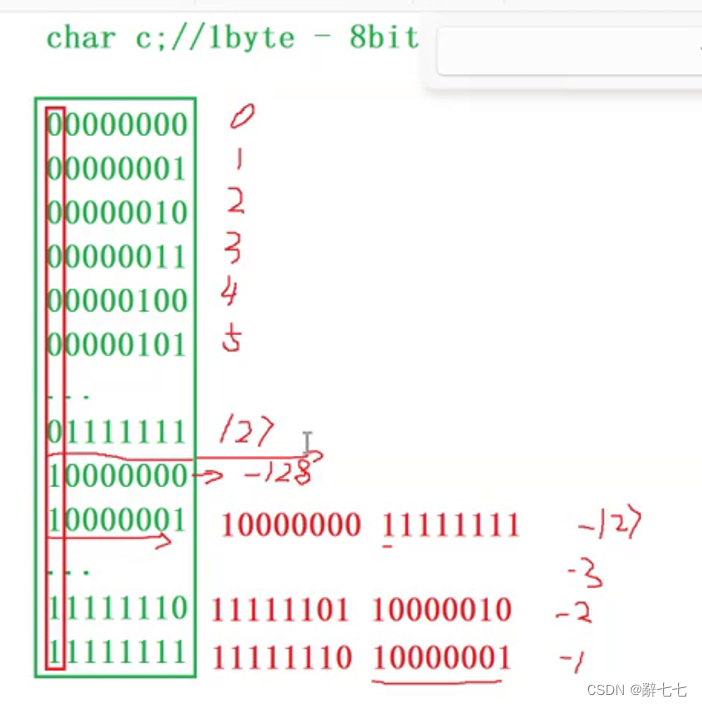
有符号char的取值范围是 (-128~127)
无符号char的取值范围是 (0~255)

%d与%u的输出结果
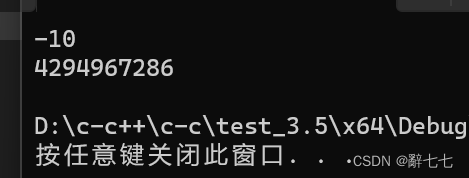
#include <stdio.h>
int main()
{unsigned int num = -10;//10000000000000000000000000001010 原码//11111111111111111111111111110101 反码//11111111111111111111111111110110 补码//无符号数原码补码相同printf("%d\n", num);printf("%u\n", num);return 0;
}

练习2
#include <stdio.h>
int main()
{char a = -128;printf("%u\n", a);return 0;
}

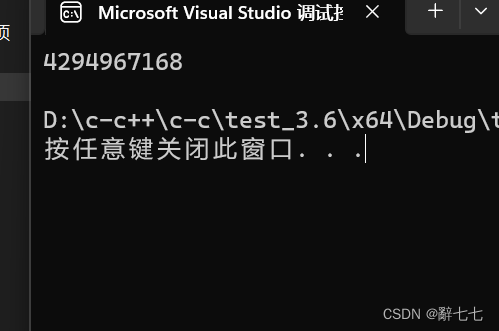
练习3
#include <stdio.h>
int main()
{char a = 128;printf("%u\n", a);return 0;
}
运算过程与练习2的过程相似
运行结果
练习4
#include <stdio.h>
int main()
{int i = -20;unsigned int j = 10;//10000000 00000000 00000000 00010100//11111111 11111111 11111111 11101011//11111111 11111111 11111111 11101100 - (-20)补码//00000000 00000000 00000000 00001010 - (10)原码//11111111 11111111 11111111 11110110 - (i+j)结果,计算机的结果,是存在内存中,是补码//10000000 00000000 00000000 00001010 - 补码变成原码//计算结果 -10printf("%d\n", i + j);return 0;
}
练习5
#include <stdio.h>
#include <windows.h>
int main()
{unsigned int i;for (i = 9; i >= 0; i--){printf("%u\n", i);Sleep(1000);//单位是毫秒}return 0;
}
打印结果:

Sleep(1000)用来降低打印速度的头文件为#include <windows.h>
unsigned 用来打印无符号数,所以当i=-1时,unsigned int i并不会认为i是一个负数,只会认为他是一个很大的正数,-1的补码为 11111111111111111111111111111111
32个全一在计算机的值如下
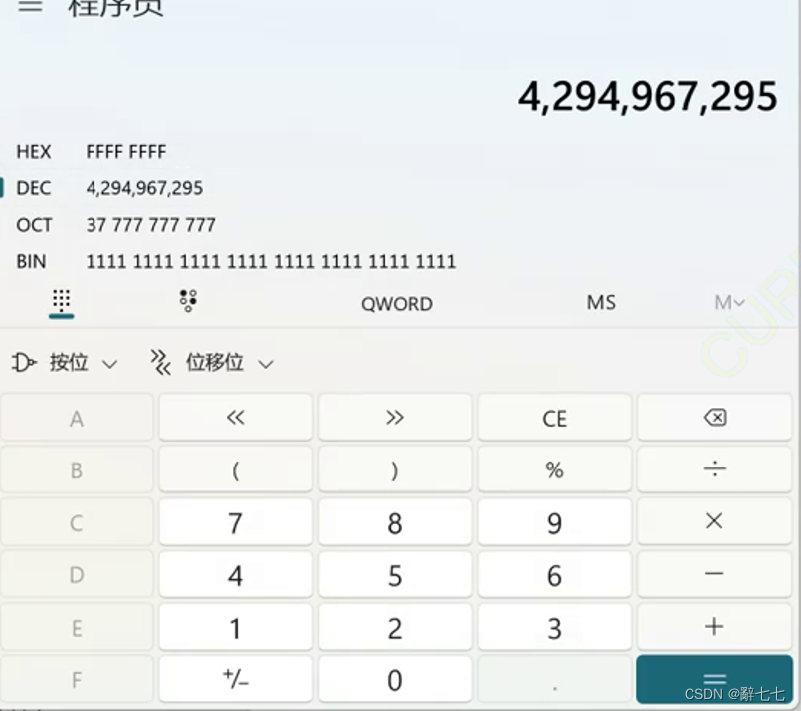
练习6
#include <stdio.h>
//char 类型的取值范围是 -128~127
int main()
{char a[1000];int i;for (i = 0; i < 1000; i++){a[i] = -1 - i;}//-1 -2 -3 -4 -5 -6 ...-127 -128 -129 ... -998 -999 -1000//char -1 -2 -3 -128 127 126 .... 3 2 1 0 -1 -2 -3 ... -128 127 ...//1000个值printf("%d", strlen(a));//strlen 求字符串长度,找到是\0,\0的ASCII码值是0.return 0;
}
运行结果;

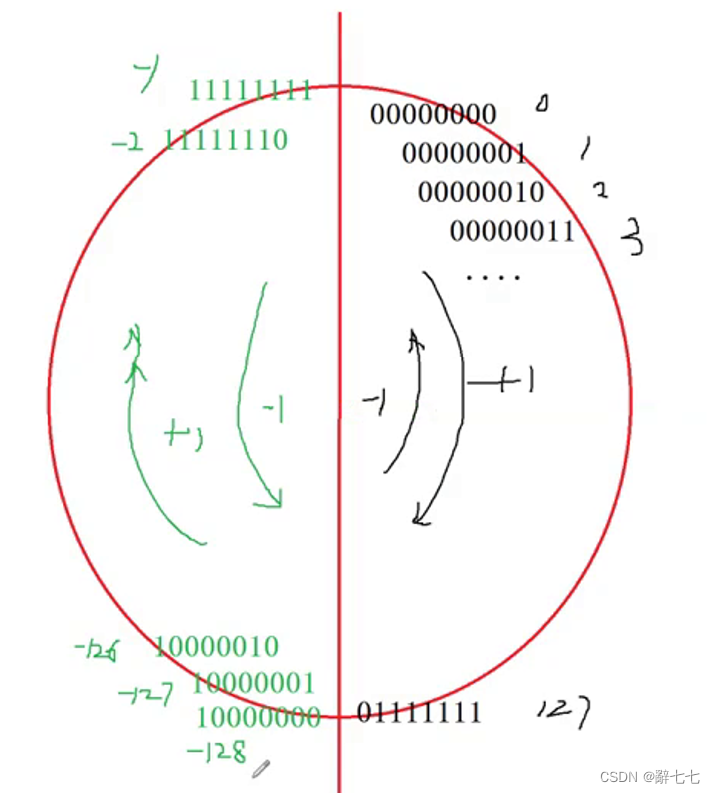
二进制加一减一的图解
练习7
#include <stdio.h>
unsigned char i = 0;
//0~255
int main()
{for (i = 0; i <= 255; i++){printf("hello world\n");}return 0;
}
i的范围是0~255,所以循环里的内容恒成立,所以结果为死循环。
3. 浮点型在内存中的存储
常见的浮点数:
3.14159
1E10
浮点数家族包括: float、double、long double 类型。
浮点数表示的范围:float.h中定义

3.1 一个例子
浮点数存储的例子:
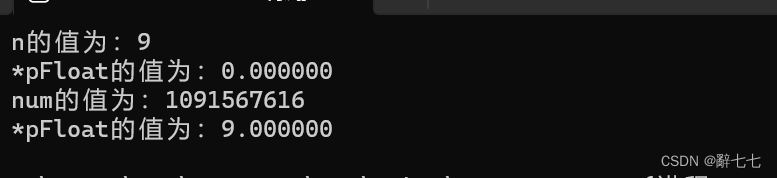
#include <stdio.h>
int main()
{int n = 9;//00000000000000000000000000001001 - 9的补码float* pFloat = (float*)&n;printf("n的值为:%d\n", n);printf("*pFloat的值为:%f\n", *pFloat);*pFloat = 9.0;printf("num的值为:%d\n", n);printf("*pFloat的值为:%f\n", *pFloat);return 0;
}
输出结果:
3.2 浮点数存储的规则
num 和 *pFloat 在内存中明明是同一个数,为什么浮点数和整数的解读结果会差别这么大?
要理解这个结果,一定要搞懂浮点数在计算机内部的表示方法。
详细解读:
根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
- (-1)^S * M * 2^E
- (-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。
- M表示有效数字,大于等于1,小于2。
- 2^E表示指数位。
以5.5举例来说
十进制的5.5,写成二进制是 101.1
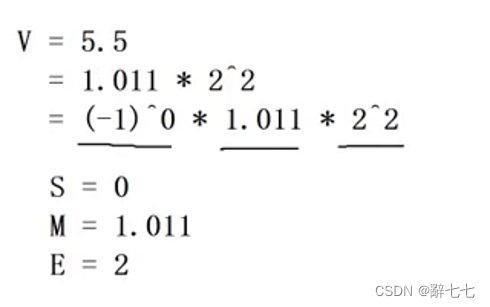
IEEE 754规定:
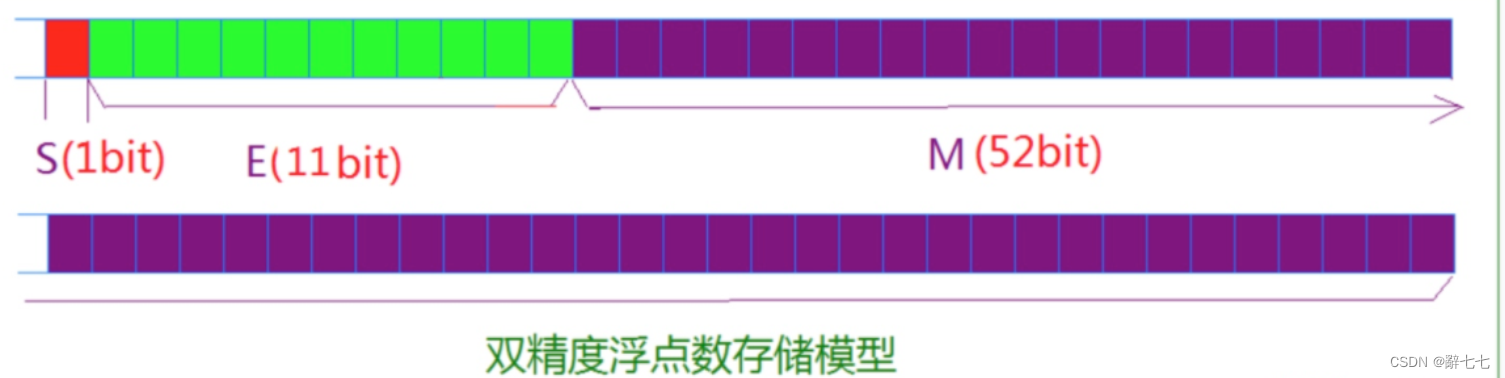
对于32位的浮点数,最高的1位是符号位s,接着的8位是指数E,剩下的23位为有效数字M。

对于64位的浮点数,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M。
IEEE 754对有效数字M和指数E,还有一些特别规定。
前面说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中xxxxxx表示小数部分。
IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是1,因此可以被舍去,只保存后面的xxxxxx部分。比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。
以32位浮点数为例,留给M只有23位,将第一位的1舍去以后,等于可以保存24位有效数字。
至于指数E,情况就比较复杂。
首先,E为一个无符号整数(unsigned int)
这意味着,如果E为8位,它的取值范围为0255;如果E为11位,它的取值范围为02047。但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。
比如,2^10的E是10,所以保存成32位浮点数时,必须保存10+127=137,即10001001.
例如:
#include <stdio.h>
int main()
{float f = 5.5f;//101.1//(-1)^0 * 1.011 * 2^2 科学表现形式//01000000101100000000000000000000 二进制表现形式//40b00000 十六进制表现形式//return 0;
}
在内存中的存储为十六进制表现形式(由于大小端的原因,顺序有所不同)
然后,指数E从内存中取出还可以再分成三种情况:
E不全为0或不全为1
这时,浮点数就采用下面的规则表示,即指数E的计算值减去127(或1023),得到真实值,再将 有效数字M前加上第一位的1。 比如:
0.5(1/2)的二进制形式为0.1,由于规定正数部分必须为1,即将小数点右移1位,则为
1.0*2^(-1),其阶码为-1+127=126,表示为 01111110,而尾数1.0去掉整数部分为0,补齐0到23位00000000000000000000000,
则其二进 制表示形式为:
0 01111110 00000000000000000000000
E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,
有效数字M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示±0,以及接近于 0的很小的数字。
E全为1
这时,如果有效数字M全为0,表示±无穷大(正负取决于符号位s);
好了,关于浮点数的表示规则,就说到这里。
解释前面的题目:
下面,让我们回到一开始的问题:为什么 0x00000009 还原成浮点数,就成了0.000000 ?
首先,将 0x00000009 拆分,得到第一位符号位s=0,后面8位的指数 E=00000000,最后23位的有效数字 M=000 0000 0000 0000 0000 1001。
9 -> 0000 0000 0000 0000 0000 0000 0000 1001
由于指数E全为0,所以符合上一节的第二种情况。因此,浮点数V就写成:
V=(-1)^0 × 0.00000000000000000001001×2(-126)=1.001×2(-146)
显然,V是一个很小的接近于0的正数,所以用十进制小数表示就是0.000000
再看例题的第二部分。
请问浮点数9.0,如何用二进制表示?还原成十进制又是多少?
首先,浮点数9.0等于二进制的1001.0,即1.001×2^3。
9.0 -> 1001.0 ->(-1)01.00123 -> s=0, M=1.001,E=3+127=130
那么,第一位的符号位s=0,有效数字M等于001后面再加20个0,凑满23位,指数E等于3+127=130,即10000010。
所以,写成二进制形式,应该是s+E+M,即
0 10000010 001 0000 0000 0000 0000 0000
这个32位的二进制数,还原成十进制,正是 1091567616 。
#include <stdio.h>
int main()
{int n = 9;//00000000000000000000000000001001 - 9的补码//0 00000000 00000000000000000001001//E = 1-127 = -126//M = 0.00000000000000000001001//(-1)^0 * 0.00000000000000000001001 * 2^-126float* pFloat = (float*)&n;printf("n的值为:%d\n", n);//9printf("*pFloat的值为:%f\n", *pFloat);//0.0*pFloat = 9.0;//以浮点数的视角,存放浮点型的数字//1001.0//1.001 * 2^3//(-1)^0 * 1.001 * 2^3//S=0//E=3//M=1.001//0 10000010 00100000000000000000000printf("num的值为:%d\n", n);//1,091,567,616printf("*pFloat的值为:%f\n", *pFloat);//9.0return 0;
}
好了,关于数据存储的内容就介绍 到这里了,有什么不懂的地方或者好的建议可以在评论区留言或者私信告诉七七哦!
相关文章:
进阶C语言——数据的存储【详解】
文章目录1. 数据类型介绍1.1 类型的基本归类2. 整形在内存中的存储2.1 原码、反码、补码2.2 大小端介绍2.3 练习3. 浮点型在内存中的存储3.1 一个例子3.2 浮点数存储的规则1. 数据类型介绍 前面我们已经学习了基本的内置类型: char //字符数据类型 short //短整型 …...
KUKA机器人修改机器人名称和IP地址的具体方法示例
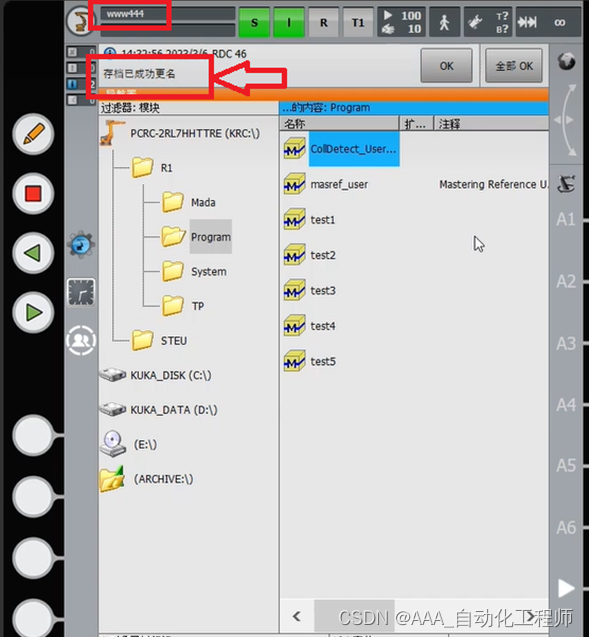
KUKA机器人修改机器人名称和IP地址的具体方法示例 修改机器人名称 如下图所示,首先切换用户组到管理员,输入默认密码:kuka, 如下图所示,点击菜单键—投入运行—机器人数据, 如下图所示,此时可以看到机器人的名称为rrr445, 如下图所示,修改之后,点击左侧的“”…...
【数据分析师求职面试指南】必备基础知识整理
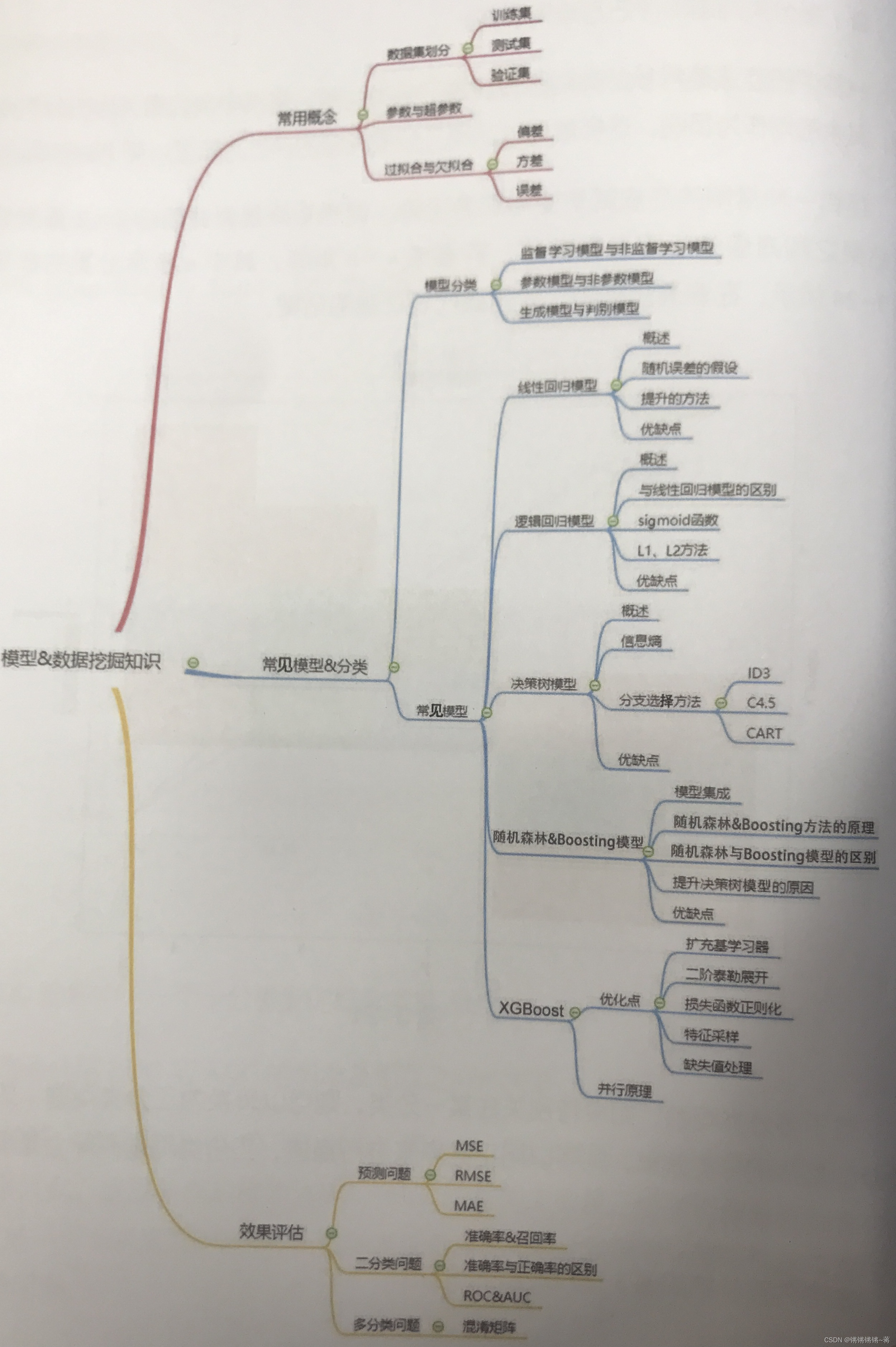
数据分析师基础知识统计 数据分析知识基础概念随机变量常用特征正态分布与大数定律、中心极限定律假设检验模型、数据挖掘知识常用概念数据集划分欠拟合过拟合模型分类方法常见模型介绍线性回归模型:逻辑回归模型决策树模型随机森林模型Boosting模型XGBoost模型模型…...
的原理与应用》)
《开关电源宝典 降压电路(BUCK)的原理与应用》
嗨,硬件攻城狮或电源工程师同行们,我想写本专门解析BUCK电源电路的书籍,以下是“前言”内容的部分摘录以及当前的目录,当前已经完成22万多字500多页了,即使如此,离真正出版书籍,还有很长的路要走…...

R语言基础(一):注释、变量
R语言用于统计分析和绘制图表等操作。不同于Java等其它语言,R用于统计,而不是做一个网站或者软件,所以R的一些开发习惯和其它语言不同。如果你是一个编程小白,那么可以放心大胆的学。如果你是一个有编程基础的人,那么需…...

Java 集合进阶(二)
文章目录一、Set1. 概述2. 哈希值3. 元素唯一性4. 哈希表5. 遍历学生对象6. LinkedHashSet7. TreeSet7.1 自然排序7.2 比较器排序8. 不重复的随机数二、泛型1. 概述2. 泛型类3. 泛型方法4. 泛型接口5. 类型通配符6. 可变参数7. 可变参数的使用一、Set 1. 概述 Set 集合特点&am…...

小孩用什么样的台灯比较好?2023眼科医生青睐的儿童台灯推荐
小孩子属于眼睛比较脆弱的人群,所以选购护眼台灯时,选光线温和的比较好,而且调光、显色效果、色温、防蓝光等方面也要出色,否则容易导致孩子近视。 1、调光。台灯首先是照度高,国AA级+大功率发光࿰…...
Ubuntu c++ MySQL数据库操作
mysql安装sudo apt-get install updatesudo apt-get install mysql-server libmysqlclient-dev mysql-workbenchmysql启动/重启/停止sudo service mysql start/restart/stop登录mysql命令:mysql -uroot -p错误异常:解决办法:修改mysqld.cnf配…...
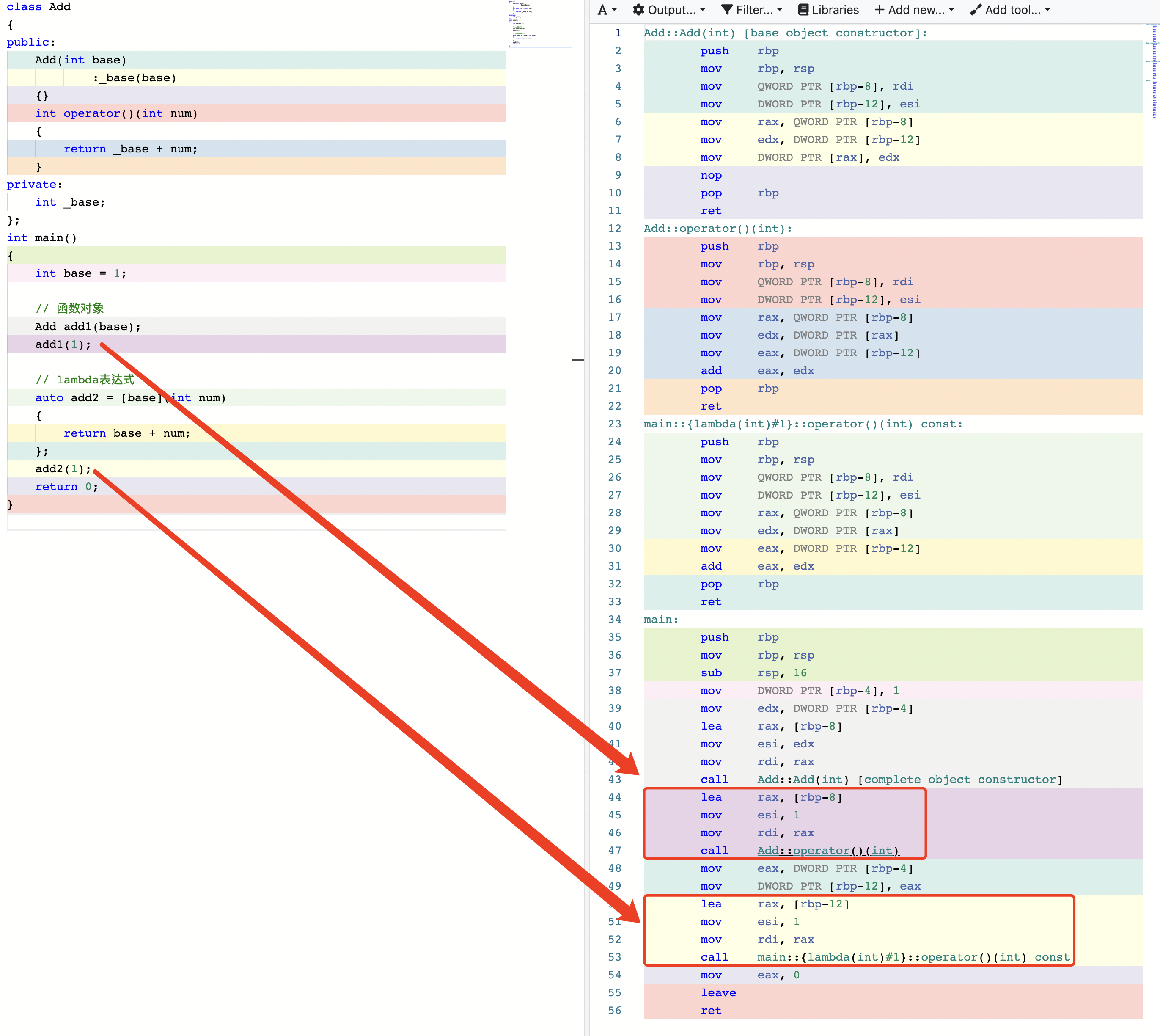
C++11:lambda表达式
文章目录1. 概念2. 语法3. 示例示例1示例2示例3示例44. 捕捉方式基本方式隐式和混合补充5. 传递lambda表达式示例6. 原理7. 内联属性1. 概念 lambda表达式实际上是一个匿名类的成员函数,该类由编译器为lambda创建,该函数被隐式地定义为内联。因此&#…...
【Android -- 开源库】表格 SmartTable 的基本使用
介绍 1. 功能 快速配置自动生成表格;自动计算表格宽高;表格列标题组合;表格固定左序列、顶部序列、第一行、列标题、统计行;自动统计,排序(自定义统计规则);表格图文、序列号、列标…...

自动化测试实战篇(9),jmeter常用断言方法,一文搞懂9种测试字段与JSON断言
Jmeter常用的断言主要有,JSON断言和响应断言这两种方式。 断言主要就是帮助帮助人工进行快速接口信息验证避免繁杂的重复的人工去验证数据 第一种响应断言Apply to:表示应用范围测试字段:针对响应数据进行不同的匹配响应文本响应代码响应信息…...

vue-virtual-scroll-list虚拟列表
当DOM中渲染的列表数据过多时,页面会非常卡顿,非常占用浏览器内存。可以使用虚拟列表来解决这个问题,即使有成百上千条数据,页面DOM元素始终控制在指定数量。 一、参考文档 https://www.npmjs.com/package/vue-virtual-scroll-li…...
C++学习笔记(以供复习查阅)
视频链接 代码讲义 提取密码: 62bb 文章目录1、C基础1.1 C初识(1) 第一个C程序(2)注释(3)变量(4)常量(5)关键字(6)标识符命名规则1.2 …...
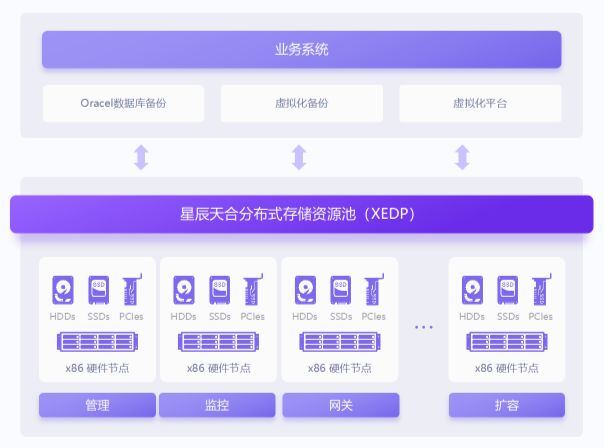
备份时间缩短为原来 1/4,西安交大云数据中心的软件定义存储实践
XEDP 统一数据平台为西安交通大学云平台业务提供可靠的备份空间和强大的容灾能力,同时确保数据安全。西安交通大学(简称“西安交大”)是我国最早兴办、享誉海内外的著名高等学府,是教育部直属重点大学。学校现有兴庆、雁塔、曲江和…...

我国近视眼的人数已经超过了六亿,国老花眼人数超过三亿人
眼镜是一种用于矫正视力问题、改善视力、减轻眼睛疲劳的光学器件,在我们的生活中不可忽略的一部分,那么我国眼镜市场发展情况是怎样了?下面小编通过可视化互动平台对我国眼镜市场的状况进行分析。我国是一个近视眼高发的国家,据统…...
设计模式(十八)----行为型模式之策略模式
1、概述 先看下面的图片,我们去旅游选择出行模式有很多种,可以骑自行车、可以坐汽车、可以坐火车、可以坐飞机。 作为一个程序猿,开发需要选择一款开发工具,当然可以进行代码开发的工具有很多,可以选择Idea进行开发&a…...
VUE3入门基础:input元素的type属性值说明
说明 在Vue 3中,<input>元素的type属性可以设置不同的类型,以适应不同的输入需求。 常见的type属性取值如下: text:默认值,用于输入文本。password:用于输入密码,输入内容会被隐藏。em…...

关于供应链,一文教你全面了解什么是供应链
什么是供应链?供应链是指产品生产和流通过程中所涉及的原材料供应商、生产商、分销商、零售商以及最终消费者等成员通过与上游、下游成员的连接 (linkage) 组成的网络结构。也即是由物料获取、物料加工、并将成品送到用户手中这一过程所涉及的企业和企业部门组成的一…...

Scope作用域简单记录分析
类型 singleton 单例作用域 prototype 原型作用域 request web作用域,请求作用域,生命周期跟request相同,请求开始bean被创建,请求结束bean被销毁 session web作用域,会话作用域,会话开始bean被创建,会话结束bean被销毁 application web作用域,应用程序作用域,应用程序创建…...

ChatGPT创作恋爱甜文
林欣是一个长相可爱、性格呆萌的小姑娘,她年纪轻轻就失去了父母,独自一人面对世界的冷漠和残酷。 虽然经历了这样的打击,但她并没有沉沦,反而更加努力地去生活。 她找到了一份服务员的工作,每天在餐厅里穿梭…...

Wwise音频文件处理终极指南:3步完成游戏音效解包与替换
Wwise音频文件处理终极指南:3步完成游戏音效解包与替换 【免费下载链接】wwiseutil Tools for unpacking and modifying Wwise SoundBank and File Package files. 项目地址: https://gitcode.com/gh_mirrors/ww/wwiseutil 还在为游戏音频文件无法编辑而烦恼…...
)
OpenART mini变身智能小车“眼睛”:基于颜色识别的自动追踪实战(附完整Python代码)
OpenART mini变身智能小车“眼睛”:基于颜色识别的自动追踪实战 在智能机器人领域,视觉感知一直是赋予机器"智慧"的关键技术。而OpenART mini作为一款轻量级视觉模块,正逐渐成为创客和嵌入式开发者的首选工具。本文将带您深入探索如…...

技能与代码审计融合实践:构建安全开发思维与实战靶场
1. 项目概述:技能与代码审计的融合实践最近在和一些做安全开发的朋友聊天,大家普遍有个感受:现在单纯会写代码,或者单纯懂点安全皮毛,已经越来越不够用了。一个功能上线,开发觉得逻辑完美,但安全…...

从2018到2023:Unity WebGL内存管理变迁史与你的2G内存墙突破指南
Unity WebGL内存管理演进与2G内存墙突破实战 引言 2018年的某个深夜,当我第一次在Chrome控制台看到"Out of Memory"的红色警告时,完全没意识到这会成为接下来五年与Unity WebGL缠斗的开端。那个使用Unity 2017.3构建的医疗可视化项目ÿ…...

容器镜像深度分析:Quaid工具的设计原理与DevOps实践
1. 项目概述:Quaid,一个为现代开发者打造的容器镜像分析利器如果你和我一样,日常工作中需要频繁地处理Docker镜像,无论是进行安全审计、优化镜像体积,还是单纯地想搞清楚一个镜像里到底“藏”了什么,那你一…...

别再照搬教科书了!聊聊西门子温度模块里那个‘奇怪’的热电偶采样电路
西门子温度模块热电偶采样电路的设计玄机:为何打破教科书常规? 第一次拆解西门子S7-1200系列温度模块时,我的目光被热电偶输入电路牢牢钉住了——这个电路竟然没有按照教科书上的经典差分放大结构来设计!更令人困惑的是࿰…...
)
特斯拉Model 3车主必看:用华为随行WiFi+流量卡,低成本搞定车载WiFi(附Type-C供电方案)
特斯拉Model 3车主必看:低成本车载WiFi实战指南 特斯拉Model 3的车载娱乐系统依赖网络连接,但官方高级娱乐服务的月费让不少车主犹豫。更糟的是,部分地区的4G信号覆盖不佳,导致在线音乐、实时路况等功能形同虚设。本文将分享一套经…...

Godot 4动态网格切割:实现实时物理破坏效果
1. 项目概述与核心价值 最近在Godot社区里,一个名为 cloudofoz/godot-smashthemesh 的开源项目引起了我的注意。乍一看这个标题,可能会觉得有些抽象——“粉碎网格”?但当你深入了解后,会发现它精准地解决了一个在3D游戏开发&am…...

Display-Lock:窗口状态锁定技术原理与C#实战
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫Stateford/Display-Lock。乍一看这个名字,可能有点摸不着头脑,Stateford听起来像个人名或者组织名,Display-Lock直译是“显示锁定”。但当你深入进去,会发现…...

2026营销策划岗位怎么提升个人能力水平:从创意执行到策略操盘
流量碎片化、用户圈层化、渠道多元化,靠灵感和经验吃饭的时代正在过去。那些只会讲创意、不懂数据验证的策划人,正在逐渐失去话语权;而能用数据驱动策略、用效果证明价值的营销策划专家,却成为各大品牌争抢的对象。今天这篇文章&a…...