从头搭hadoop集群--分布式hadoop集群搭建
模板虚拟机安装配置见博文:https://blog.csdn.net/weixin_66158110/article/details/139236148
配置文件信息如下:https://pan.baidu.com/s/1074eD5aNVugEPcjwVvi9jA?pwd=l1xq(提取码:l1xq)
hadoop版本:hadoop-3.1.3
一、克隆模版虚拟机
1、克隆虚拟机
鼠标移动至虚拟机--管理--克隆,除提到页面均点击下一页即可
(1)克隆类型必须选择“创建完整克隆”

(2)编辑名称和位置
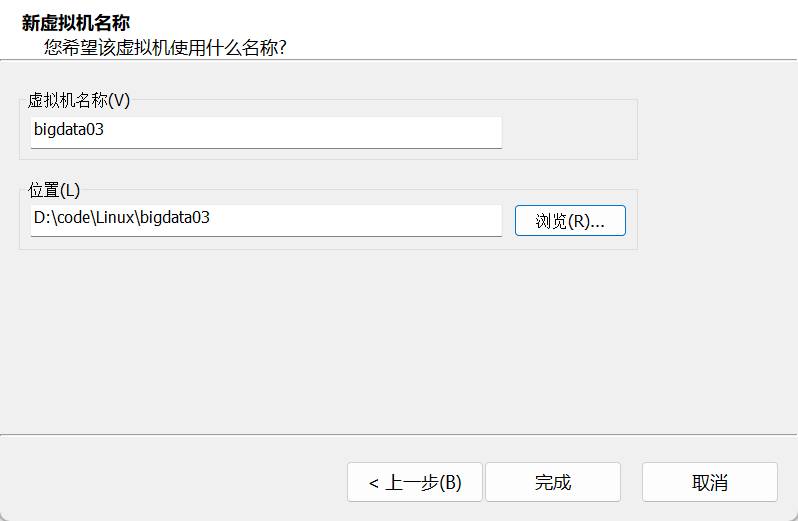
点击完成后等待
再重复上述步骤两遍,分别命名为bigdata04、bigdata05
2、修改克隆机的ip地址
(1)打开虚拟机后进入如下目录
cd /etc/sysconfig/network-scripts(2)编辑ifcfg-ens33文件内容
vi ifcfg-ens33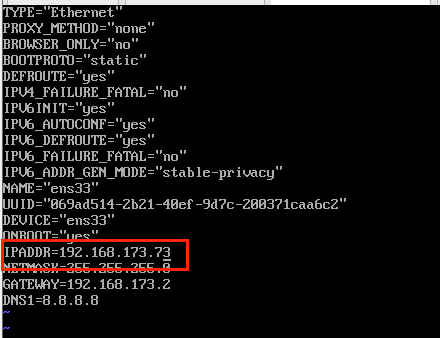
bigdata03、04、05分别改为73、74、75
3、修改克隆机的主机名称
vi /etc/hostnamebigdata03、04、05分别改为bigdata03、bigdata04、bigdata05
完成后把所有虚拟机都重启一下
二、MobaXterm连接三台虚拟机
点击Session进行如下配置
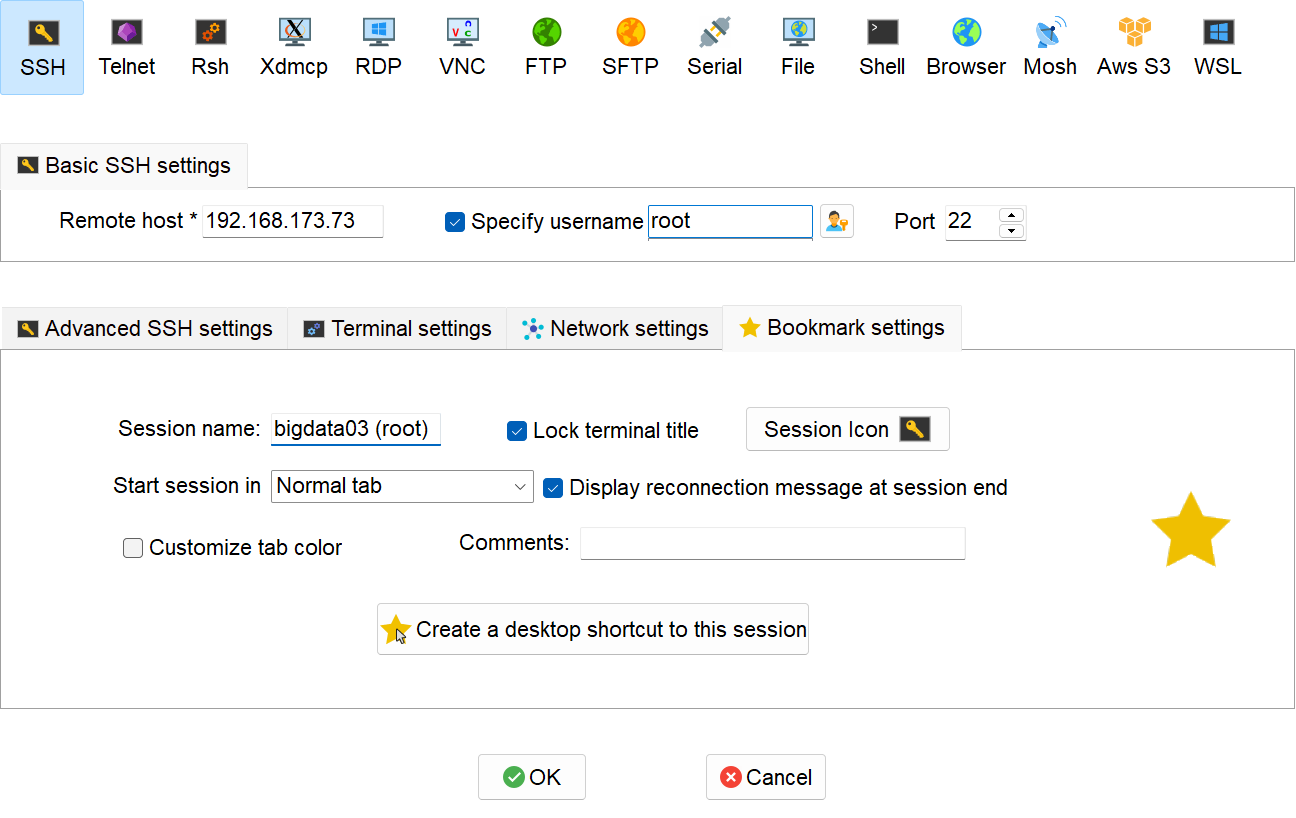
创建成功后如下图
三、在bigdata03安装hadoop
1、上传安装包
在bigdata03左边的输入框输入/opt,点击进入install_packages,将下载好的hadoop压缩包拖入
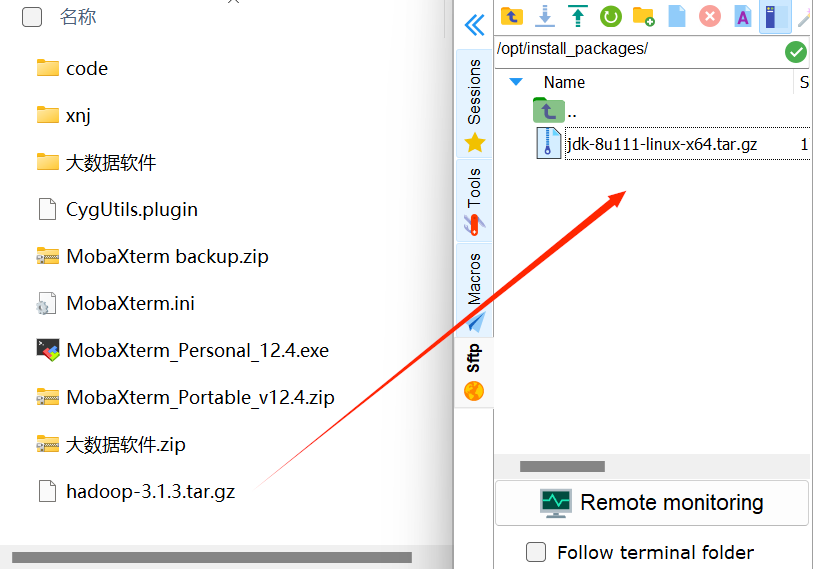
2、输入命令解压
tar -zxvf /opt/install_packages/hadoop-3.1.3.tar.gz -C /opt/softs/3、重命名文件夹
进入到softs目录下
cd /opt/softs修改文件夹名称
mv hadoop-3.1.3/ hadoop3.1.3/4、配置环境变量
(1)编辑配置文件
vim /etc/profile(2)在配置文件末尾加入如下内容
#HADOOP_HOME
export HADOOP_HOME=/opt/softs/hadoop3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbinexport HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root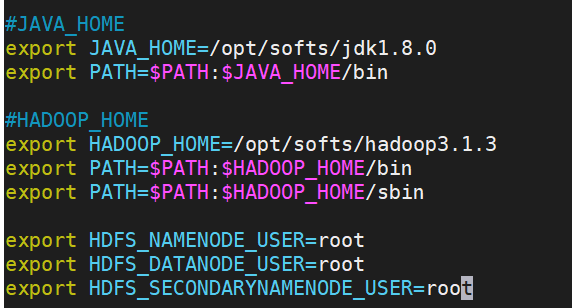
(3) 使配置文件生效
source /etc/profile(4)验证环境变量配置是否生效
echo $HADOOP_HOME显示如下图没问题

四、配置三台虚拟机的映射
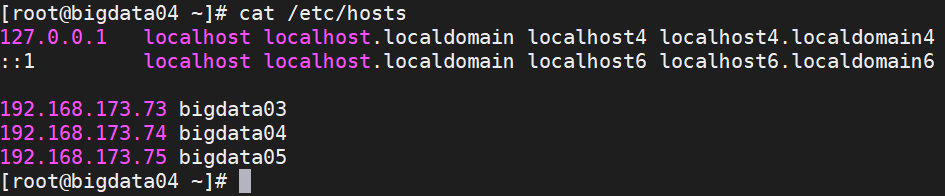
1、编辑hosts文件
vim /etc/hosts在文件末尾加上如下代码
192.168.173.73 bigdata03
192.168.173.74 bigdata04
192.168.173.75 bigdata05
2、将编辑好的hosts文件远程传输给bigdata04、bigdata05
scp /etc/hosts root@bigdata04:/etc/
scp /etc/hosts root@bigdata05:/etc/
3、检查是否传输过去
在bigdata04中输入如下命令
cat /etc/hosts显示如下图成功
五、设置免密登录
以下步骤在bigdata03、bigdata04、bigdata05上均要各自手动执行一次,共执行三次。
1、切换目录
cd /root2、查看隐藏内容
ls -al3、进入.ssh目录
cd .ssh4、生成免密登录的公钥和私钥
ssh-keygen -t rsa命令执行后,回车三次,可以完成公钥和私钥的生成
5、将公钥和私钥发送到要免密的虚拟机上
ssh-copy-id bigdata03ssh-copy-id bigdata04ssh-copy-id bigdata05六、集群规划
| bigdata03 | bigdata04 | bigdata05 | |
| HDFS | NameNode DataNode | SecondNameNode DataNode | DataNode |
| YARN | NodeManager | NodeManager | ResourceManager NodeManager |
集群规划时有两个注意点:
- hdfs中的NameNode和SecondNameNode不要安装在同一个节点上
- yarn中的ResourceManager不要和NameNode和SecondNameNode在同一个节点上
1、在bigdata03中根据集群规划修改配置文件
(1)跳转到配置文件目录下
cd /opt/softs/hadoop3.1.3/etc/hadoop(2)修改hadoop-env.sh
vim hadoop-env.sh输入/JAVA_HOME检索位置,修改第三个位置的JAVA_HOME

(3)将4个xml文件拖到/opt/softs/hadoop3.1.3/etc/hadoop目录下
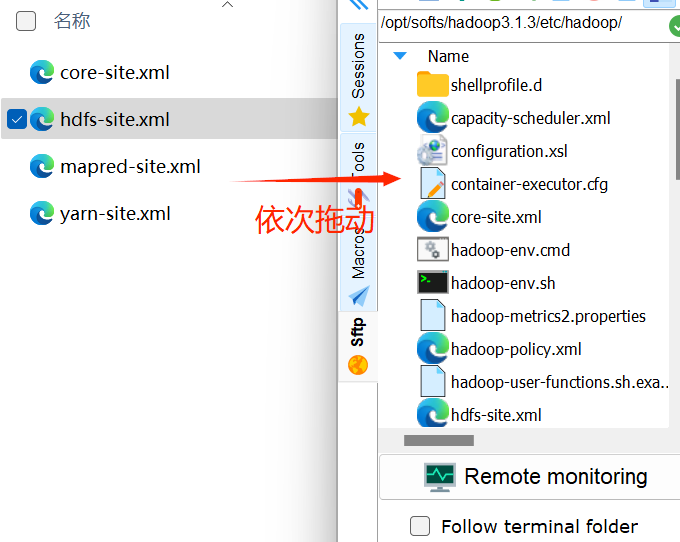
(4)编辑workers
vim workers输入如下内容(一个一行不要并行)
bigdata03
bigdata04
bigdata05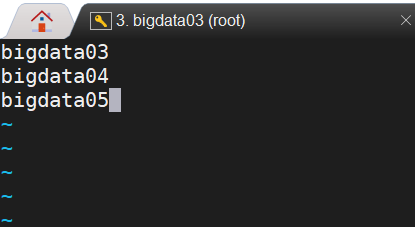
2、将hadoop3.1.3目录传输给bigdata04和05
在bigdata03中执行把东西远程传输过去就行
scp -r /opt/softs/hadoop3.1.3/ root@bigdata04:/opt/softs/scp -r /opt/softs/hadoop3.1.3/ root@bigdata05:/opt/softs/3、将profile文件传输给bigdata04和05
scp /etc/profile root@bigdata04:/etc/scp /etc/profile root@bigdata05:/etc/在bigdata03中传输完后记得在bigdata04和bigdata05中使profile文件生效
source /etc/profileTips:到这里集群的安装就完成了,剩下的内容属于集群初始化
七、在NameNode所在节点(bigdata03)进行初始化
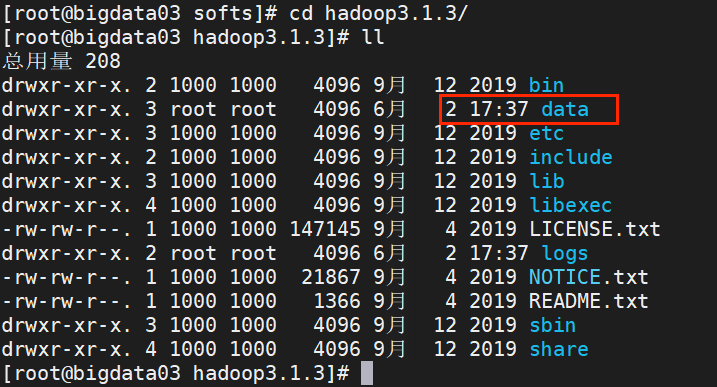
在bigdata03上执行如下语句
hdfs namenode -format完成后/opt/softs/hadoop3.1.3目录下会出现data目录
八、启动hdfs
1、在NameNode(bigdata03)上输入启动命令
start-dfs.sh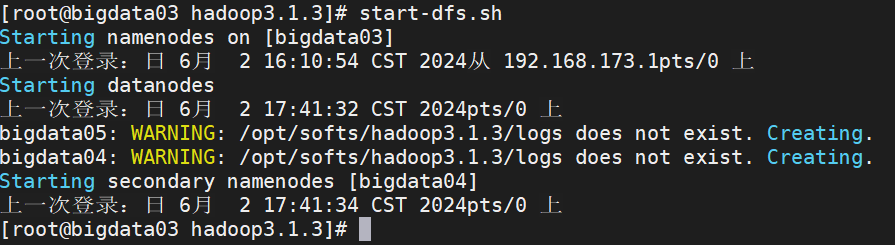
2、 在三台虚拟机上分别输入jps命令,检验输出是否与集群规划一致

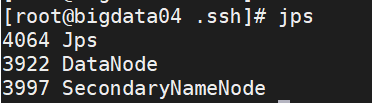

九、在ResourceManager(bigdata05)上启动yarn
1、跳转到指定目录下
cd /opt/softs/hadoop3.1.3/sbin2、启动命令
start-yarn.sh报错:
解决方法:
(1)编辑profile文件
vim /etc/profile在文件末尾添加这两行代码
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root(2)远程传输给另外两台
scp /etc/profile root@bigdata03:/etc/
scp /etc/profile root@bigdata04:/etc/(3)在三台模拟机中都输入如下命令使文件生效
source /etc/profile(4)在bigdata05中重新启动yarn
start-yarn.sh3、再次输入jps检验与集群规划是否一致
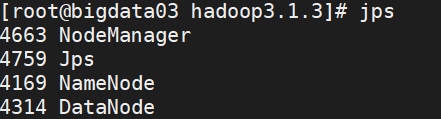
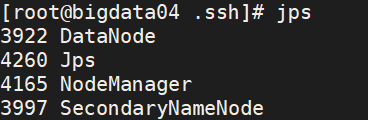
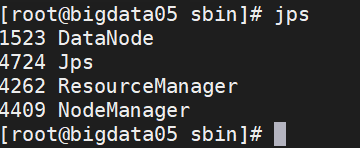
十、关闭hdfs和yarn
开启这两个后在关闭模拟机前都要记得关掉,这很重要!
stop-yarn.sh
stop-dfs.sh使用jps命令检查,只剩下jps说明关闭成功,可以关机了

相关文章:
从头搭hadoop集群--分布式hadoop集群搭建
模板虚拟机安装配置见博文:https://blog.csdn.net/weixin_66158110/article/details/139236148 配置文件信息如下:https://pan.baidu.com/s/1074eD5aNVugEPcjwVvi9jA?pwdl1xq(提取码:l1xq) hadoop版本:h…...
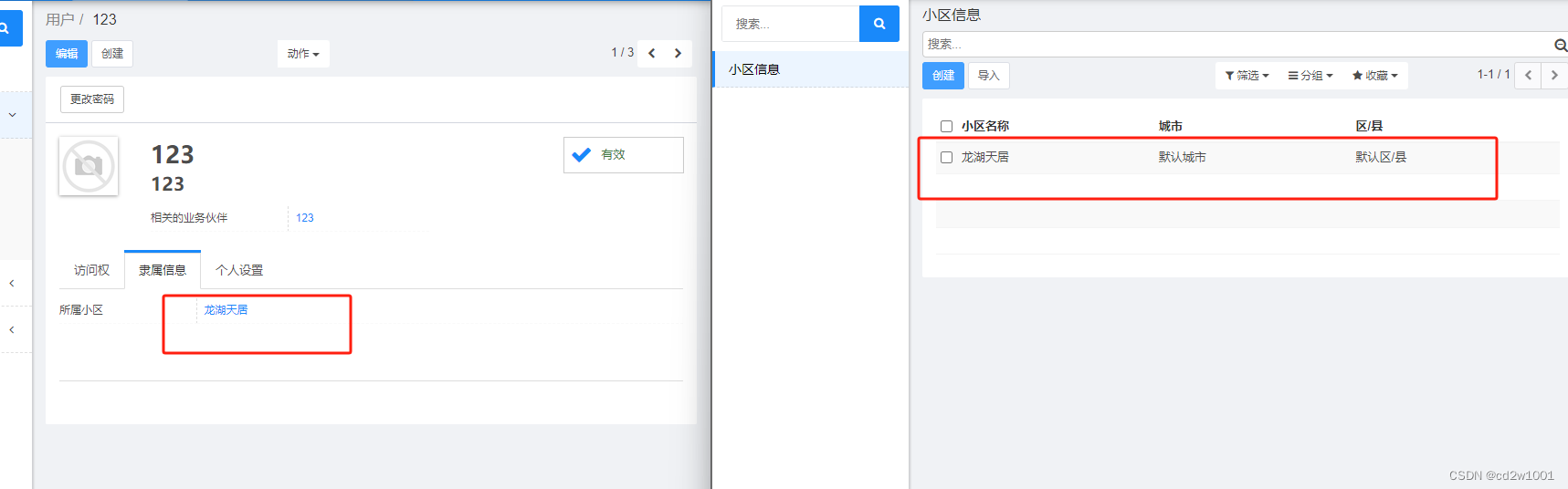
odoo10 权限控制用户只允许看到自己的字段
假设一个小区管理员用户,只想看到自己小区的信息。 首先添加一个用户信息选项卡界面,如下图的 用户 > 隶属信息: 我们在自己创建的user模块中,views文件夹下添加base_user.xml <?xml version"1.0" encoding&q…...
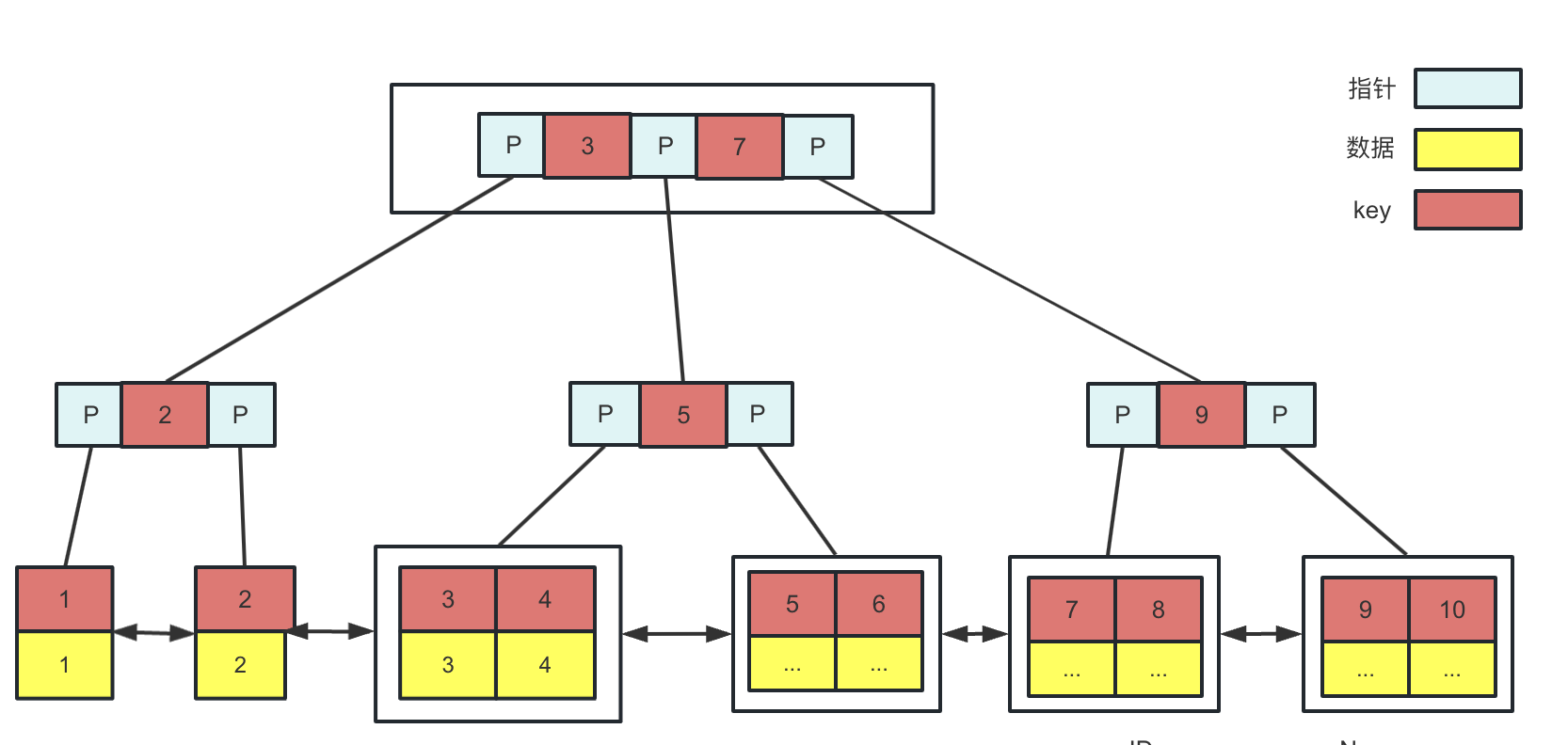
图解Mysql索引原理
概述 是什么 索引像是一本书的目录列表,能根据目录快速的找到具体的书本内容,也就是加快了数据库的查询速度索引本质是一个数据结构索引是在存储引擎层,而不是服务器层实现的,所以,并没有统一的索引标准,…...

Arduino网页服务器:如何将Arduino开发板用作Web服务器
大家好,我是咕噜铁蛋!今天,我将和大家分享一个有趣且实用的项目——如何使用Arduino开发板搭建一个简易的网页服务器。通过这个项目,你可以将Arduino连接到互联网,并通过网页控制或查询Arduino的状态。 一、项目背景与…...

大模型日报2024-06-05
大模型日报 2024-06-05 大模型资讯 AI气象预测取得重大进展:单台桌面电脑即可运行全球天气模型 摘要: 一项新的人工智能天气预测模型已经取得重大进展,该模型能够在一台普通的桌面电脑上运行,预测全球天气。这意味着即使没有复杂的物理计算&a…...

LLM 大模型学习必知必会系列(二):提示词工程-Prompt Engineering 以及实战闯关
角色扮演:在系统指令中告诉千问你需要它扮演的角色,即可沉浸式和该角色对话交流语言风格:简单调整 LLM 的语言风格任务设定:比如旅行规划,小红书文案助手这样的专项任务处理System message 也可以被用于规定 LLM 的答复…...
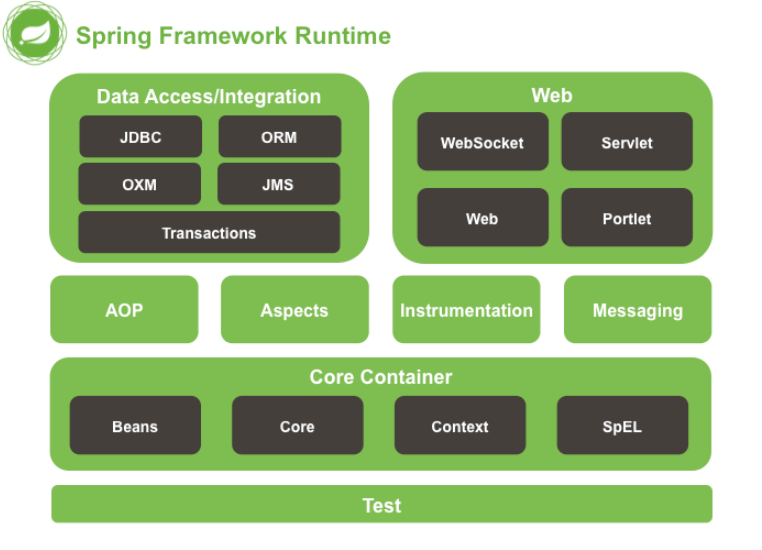
Spring系统学习 - Spring入门
什么是Spring? Spring翻译过来就是春天的意思,字面意思,冠以Spring的意思就是想表示使用这个框架,代表程序员的春天来了,实际上就是让开发更加简单方便,实际上Spring确实做到了。 官网地址:ht…...

Priority_queue
一、priority_queue的介绍和使用 1.1 priority_queue的介绍 1.优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。 2.优先队列类似于堆, 在堆中可以随时插入元素, 并且只能检索最大堆…...

SpringMVC:获取请求数据
1. 通过RequestParma注解接收 /**** value和name都可以使用,互为别名* 如果此处设置了需要什么参数而前端请求时没有提供则会报400(请求参数不一致错误)* required参数用于设置该参数是否为必须传递参数,默认为true必须传递* defa…...

深度学习 --- stanford cs231 编程作业(assignment1,Q2: SVM分类器)
stanford cs231 编程作业之SVM分类器 写在最前面: 深度学习,或者是广义上的任何学习,都是“行千里路”胜过“读万卷书”的学识。这两天光是学了斯坦福cs231n的一些基础理论,越往后学越觉得没什么。但听的云里雾里的地方也越来越多…...
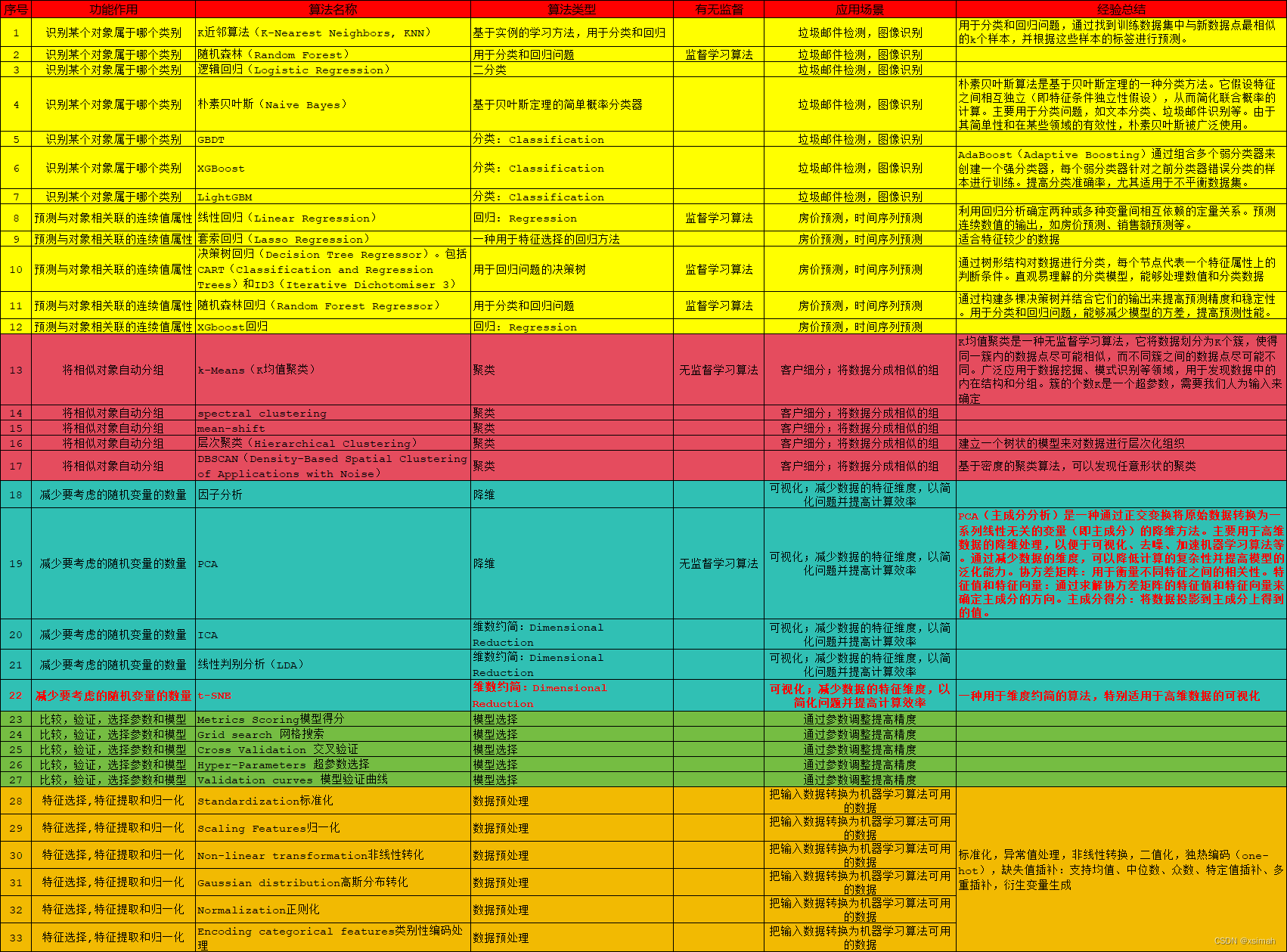
【scikit-learn010】sklearn算法模型清单实战及经验总结(已更新)
1.一直以来想写下基于scikit-learn训练AI算法的系列文章,作为较火的机器学习框架,也是日常项目开发中常用的一款工具,最近刚好挤时间梳理、总结下这块儿的知识体系。 2.熟悉、梳理、总结下scikit-learn框架模型算法包相关技术点及经验。 3.欢迎批评指正,欢迎互三,跪谢一键…...
Rethinking overlooked aspects in vision-language models
探讨多模态视觉语言模型的一些有趣结论欢迎关注 CVHub!https://mp.weixin.qq.com/s/zouNu-g-33_7JoX3Uscxtw1.Introduction 多模态模型架构上的变化不大,数据的差距比较大,输入分辨率和输入llm的视觉token大小是比较关键的,适配器,VIT和语言模型则不是那么关键。InternVL-…...
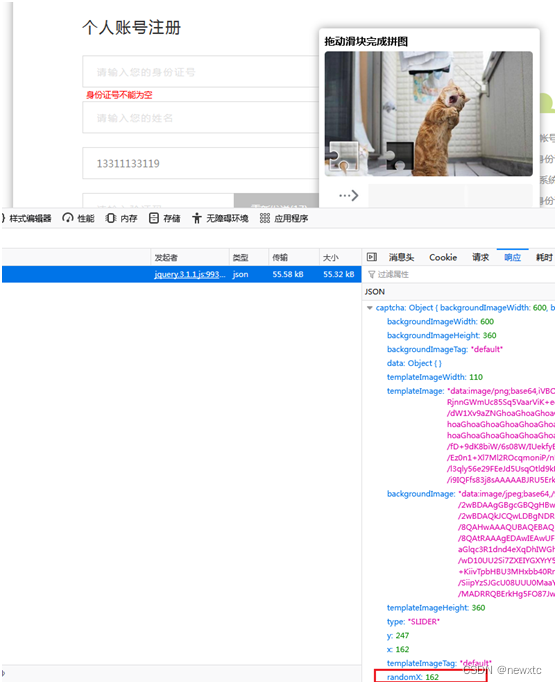
【漯河市人才交流中心_登录安全分析报告-Ajax泄漏滑动距离导致安全隐患】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...
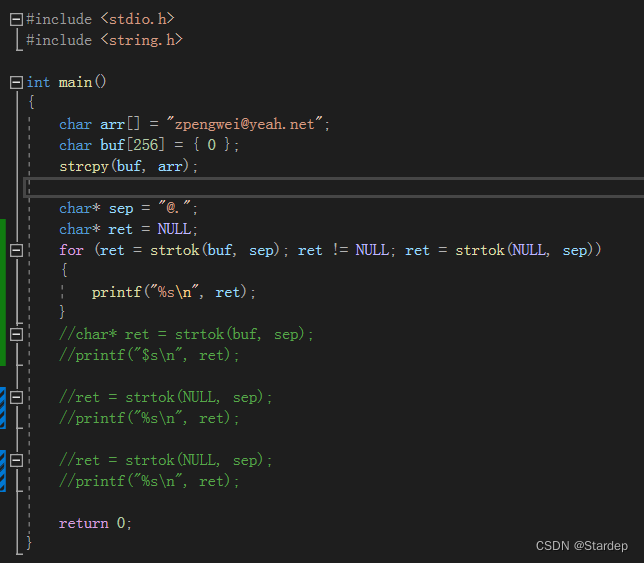
C语言—字符函数和字符串函数
1.字符分类函数 C语言中有一系列的函数是专门做字符分类的,也就是一个字符是属于什么类型的字符的。 这些函数的使用都需要包含一个头文件 ctype.h。 例:将一句话中的小写字母改成大写字母。 2.字符转换函数 头文件:ctype.h C语言提供了2…...

爬山算法的详细介绍
爬山算法(Hill Climbing Algorithm)是一种基于启发式的局部搜索算法,常用于解决优化问题。它的核心思想是从当前解的邻域中选择能够使目标函数值最大(或最小)的下一个解作为当前解,直到找到一个满足问题要求…...

硕士课程 可穿戴设备之作业一
作业一 第一个代码使用的方法是出自于[1]。 框架结构 如下图,不过根据对代码的解读,发现作者在代码中省去了对SSR部件的实现,下文再说。 Troika框架由三个关键部件组成:信号分解,SSR和光谱峰值跟踪。(粗…...
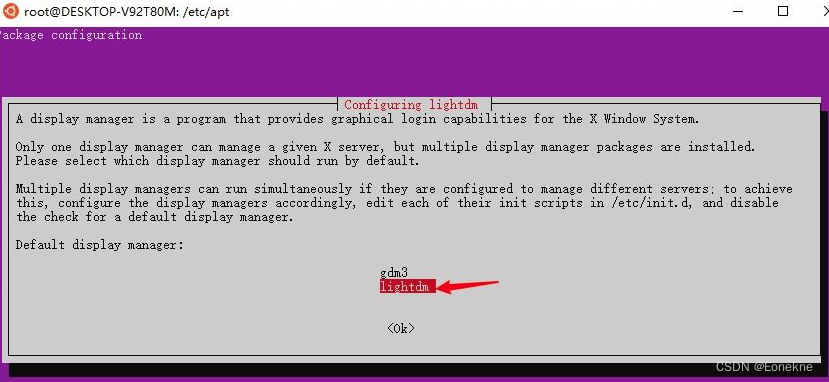
测试记录3:WLS2运行Linux界面
1.WLS1转到WLS2 (1)根据自己的平台,下载WLS2安装包 x64: https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi arm64: https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_arm64.msi (2&…...

好用软件推荐
软件功能相关介绍地址FastStone截图(长截图、定时截图等)CSDNhttps://www.faststone.org/FSCaptureDownload.htmQuicker快捷访问https://getquicker.net/https://getquicker.net/...
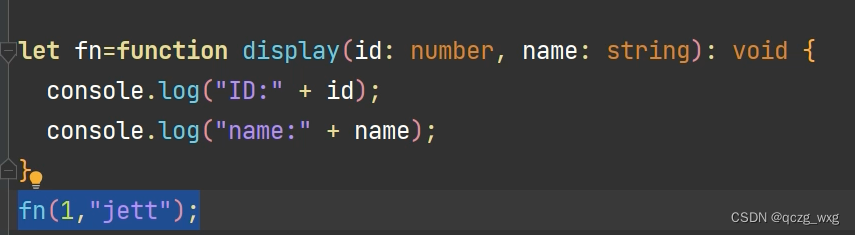
王学岗鸿蒙开发(北向)——————(二)TS基本语法详解
1,Ts(TypeScript)语法相当于JAVAScript类型,鸿蒙arkTs是基于TS语言的,当然artTs也融合了其它的语言。 2,本篇文章是基于n9版本。注意,有些语法是已经不能用的。 3, 4,变量:用来存储数据,数字字母组成,数字不…...
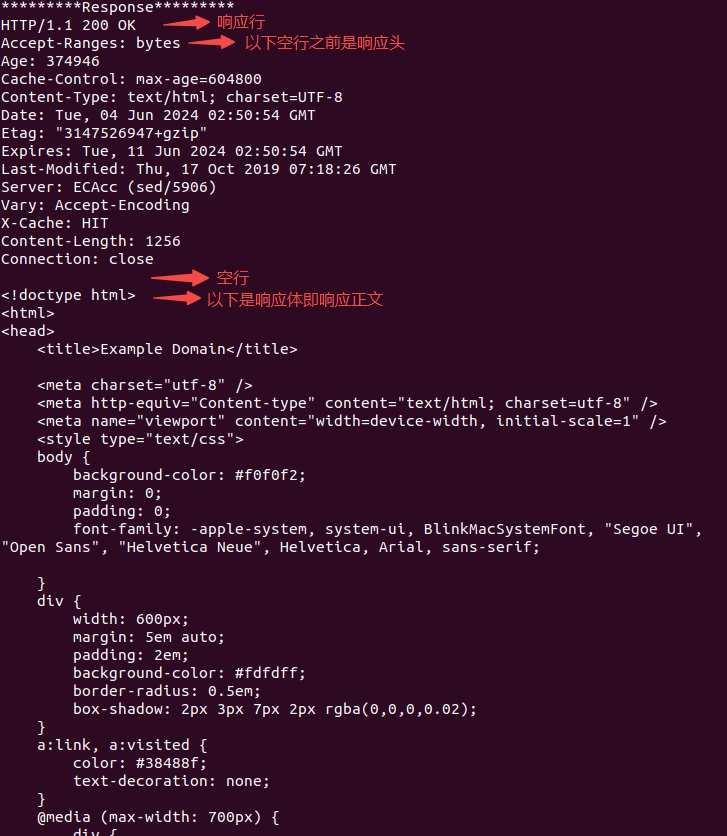
【网络协议 | HTTP】HTTP总结与全梳理(一) —— HTTP协议超详细教程
🔥博客简介:开了几个专栏,针对 Linux 和 rtos 系统,嵌入式开发和音视频开发,结合多年工作经验,跟大家分享交流嵌入式软硬件技术、音视频技术的干货。 ✍️系列专栏:C/C、Linux、rtos、嵌入式…...

IDEA Services窗口:一站式掌控多服务启动与端口监控
1. 为什么你需要Services窗口 作为一个常年和微服务打交道的开发者,我最头疼的就是同时管理五六个服务模块。每次启动项目都要开一堆终端窗口,查看日志得像玩连连看一样在不同窗口间切换。更崩溃的是,当某个服务启动失败时,往往要…...

Qwen-Image-Edit-F2P教程:Gradio界面实时交互调试+生成过程进度条可视化原理
Qwen-Image-Edit-F2P教程:Gradio界面实时交互调试生成过程进度条可视化原理 想玩转AI图像编辑,但被复杂的命令行和漫长的等待劝退?今天,我们来点不一样的。我将带你深入一个开箱即用的AI图像编辑工具——Qwen-Image-Edit-F2P&…...

OpenClaw安全指南:千问3.5-9B本地化部署权限控制
OpenClaw安全指南:千问3.5-9B本地化部署权限控制 1. 为什么需要关注OpenClaw的安全配置? 去年冬天,我在调试一个自动整理文档的OpenClaw任务时,差点酿成大祸。当时脚本误将整个Downloads文件夹的内容按修改日期排序后࿰…...

千问3.5-2B实战案例:在线考试截图作弊行为特征识别与标记
千问3.5-2B实战案例:在线考试截图作弊行为特征识别与标记 1. 项目背景与挑战 在线教育平台的监考人员每天需要审核大量考试截图,人工识别作弊行为存在以下痛点: 效率低下:平均每张截图需要30秒人工检查标准不一:不同…...

造相-Z-Image本地部署全记录:无需网络,RTX 4090专属优化方案
造相-Z-Image本地部署全记录:无需网络,RTX 4090专属优化方案 你是否曾为部署一个AI绘画模型而焦头烂额?面对复杂的依赖、漫长的网络下载、以及最令人头疼的“爆显存”问题,是不是感觉手头这张强大的RTX 4090显卡有力使不出&#…...

OpenClaw数据清洗实战:千问3.5-27B处理混乱Excel表格
OpenClaw数据清洗实战:千问3.5-27B处理混乱Excel表格 1. 当Excel遇上非结构化数据:我的真实痛点 上周五下午6点,市场部的同事突然发来一份"紧急需求"——一份从20多个渠道手工合并的Excel文件,需要在下班前完成数据清…...

网站 SEO 推广代运营需要多长时间才能见效_什么是网站 SEO 推广代运营
什么是网站 SEO 推广代运营 在当前竞争激烈的互联网市场中,网站 SEO 推广代运营(Search Engine Optimization,SEO)已经成为提升网站流量和品牌知名度的重要手段。SEO 推广代运营是指通过一系列优化策略,提升网站在搜索…...
)
别再死磕PPO了!用DPO微调你的大模型,成本直降80%(附Colab实战代码)
低成本微调大模型实战:DPO算法在Colab上的高效实现 当我在深夜调试第17版PPO训练脚本时,Colab突然弹出的"GPU内存不足"错误提示让我彻底崩溃。作为个人开发者,我们既没有企业级的计算资源,又渴望让开源模型理解人类的真…...

python pyoxidizer
# 关于PyOxidizer的一些思考 最近在Python打包工具领域,有个工具引起了不小的讨论,那就是PyOxidizer。如果你经常需要将Python代码打包成可执行文件,或者部署到没有Python环境的机器上,可能会对这个工具感兴趣。 它到底是什么 PyO…...
)
新手必看:从零到一搞定CTFHub Web入门题(HTTP协议+信息泄露实战)
从零构建CTF Web安全实战能力:HTTP协议与信息泄露攻防指南 当你第一次接触CTF竞赛中那些看似神秘的Web题目时,是否感到无从下手?本文将带你系统掌握Web安全的两大基石——HTTP协议操纵与信息泄露挖掘,通过CTFHub实战平台构建完整的…...