Python爬虫之简单学习BeautifulSoup库,学习获取的对象常用方法,实战豆瓣Top250
BeautifulSoup是一个非常流行的Python库,广泛应用于网络爬虫开发中,用于解析HTML和XML文档,以便于从中提取所需数据。它是进行网页内容抓取和数据挖掘的强大工具。
功能特性
- 易于使用: 提供简洁的API,使得即使是对网页结构不熟悉的开发者也能快速上手。
- 文档解析: 支持多种解析器,包括Python标准库中的HTML解析器以及第三方的lxml解析器,后者速度更快且功能更强大。
- 自动编码识别: 自动将输入文档转换为Unicode编码,输出文档转换为UTF-8编码,简化了编码处理的复杂性。
- 导航与搜索: 提供了丰富的选择器和方法,如 .find(), .find_all(), .select() 等,便于按标签名、属性、类名等查找元素。
- 数据提取: 可以轻松地提取和修改HTML或XML文档中的数据,支持遍历和搜索DOM树,提取文本、属性等信息。
- 灵活的输出格式: 可以将解析后的数据输出为Python对象、字符串或者保存为文件。
目录
安装BeautifulSoup
基本使用
BeautifulSoup获取对象
选择器
1、CSS选择器(select()方法):
2、Tag名:
3、属性选择:
方法
.find_all()
.find()
示例
使用BeautifulSoup爬取豆瓣Top250实例
安装BeautifulSoup
在命令窗口安装
pip install基本使用
我们使用requests库发送请求获取html,获得的是html字符串,在爬虫中,只有正则表达式(re)才可以直接对html字符串进行解析,而对于html字符串我们无法使用xpath语法和bs4语法进行直接提取,需要通过lxml或者bs4对html字符串进行解析,解析为html页面才能进行数据提取。
在xpath中我们使用lxml进行解析,但是在bs4中,我们有很多的解析器对网页进行解析。
这里我们只说一种最常用最简单的解析器"html.parser"
简单来说BeautifulSoup是一个从html字符串提取数据的工具,使用BeautifulSoup分为三步:
第一步 导入BeautifulSoup类,抓取网页同时也导入requests库
from bs4 import BeautifulSoup
import requests第二步 传递初始化参数(HTML代码,HTML解析器),并初始化
这里解析器使用'html.parser',这是python自带的解析器,更方便使用
# html_code:html代码 html.parser:解析器,python自带的解析器
soup = BeautifulSoup(html_code, 'html.parser')第三步 获取实例对象,操作对象获取数据
BeautifulSoup获取对象可以使用选择器和方法。
BeautifulSoup获取对象
选择器
1、CSS选择器(select()方法):
支持ID选择器、类选择器、属性选择器、伪类等
复杂选择
- 组合选择器:可以使用逗号 , 分隔多个选择器来选择多个不同类型的元素。
- 后代选择器:使用空格表示,如 .story a 选取所有.story类内的<a>标签。
- 子选择器:使用 > 表示直接子元素,如 body > p 选取<body>直接下的所有段落。
- 属性选择器:如 [href*=example] 选取所有href属性包含"example"的元素。
- 伪类选择器:如 a:hover、:first-child 等,虽然不是所有CSS伪类在BeautifulSoup中都可用,但一些基本的如:first-child, :last-child等有时也能派上用场。
2、Tag名:
- 直接使用tag名作为属性,如 soup.div 返回第一个<div>标签。
- 支持通过列表索引来定位特定的标签,如 soup.divs[0]。
3、属性选择:
使用[attribute=value]语法,例如 soup.find_all(attrs={'class': 'active'}) 查找所有class为"active"的元素。
方法
.find_all()
查找文档中所有匹配指定条件的tag,返回一个列表。
参数可以精确指定tag名字、属性、文本内容等。
.find()
类似于.find_all(),但只返回第一个匹配的元素。
示例
1、获取所有div标签
soup.find_all('div')
2、获取拥有指定属性的标签(id='even'的div标签)
soup.find_all('div', id='even')如果有多个属性的标签,可以使用字典模式
soup.find_all('div', attrs={"id":"even", "class":"cc"})
soup.find_all('div', id='even',class_='c')使用字典形式,还可以添加样式属性,更加灵活
3、获取标签的属性值
方法1:通过下标方式提取
alist = soup.find_all('a')
# 我想获取a标签的href值
for a in alist:href = a['href']print(href)方法2:利用attrs参数提取
for a in alist:href = a.attrs['href']print(href)使用BeautifulSoup爬取豆瓣Top250实例
网址:豆瓣电影 Top 250
导入库,使用requests向网站发起请求,获取页面响应对象
.status_code状态码为200则请求成功,可以继续下一步
import requests
from bs4 import BeautifulSoupurl = 'https://movie.douban.com/top250'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}# 发送GET请求
response = requests.get(url, headers=headers)
print(response.status_code)打开浏览器开发者工具,找到User-Agent复制

这次实验我们爬取电影名称和短语,我们通过观察知道每个电影的信息都包含在一个div中,这个div的class选择器为"info",而我们需要爬取的数据在这个div里面。
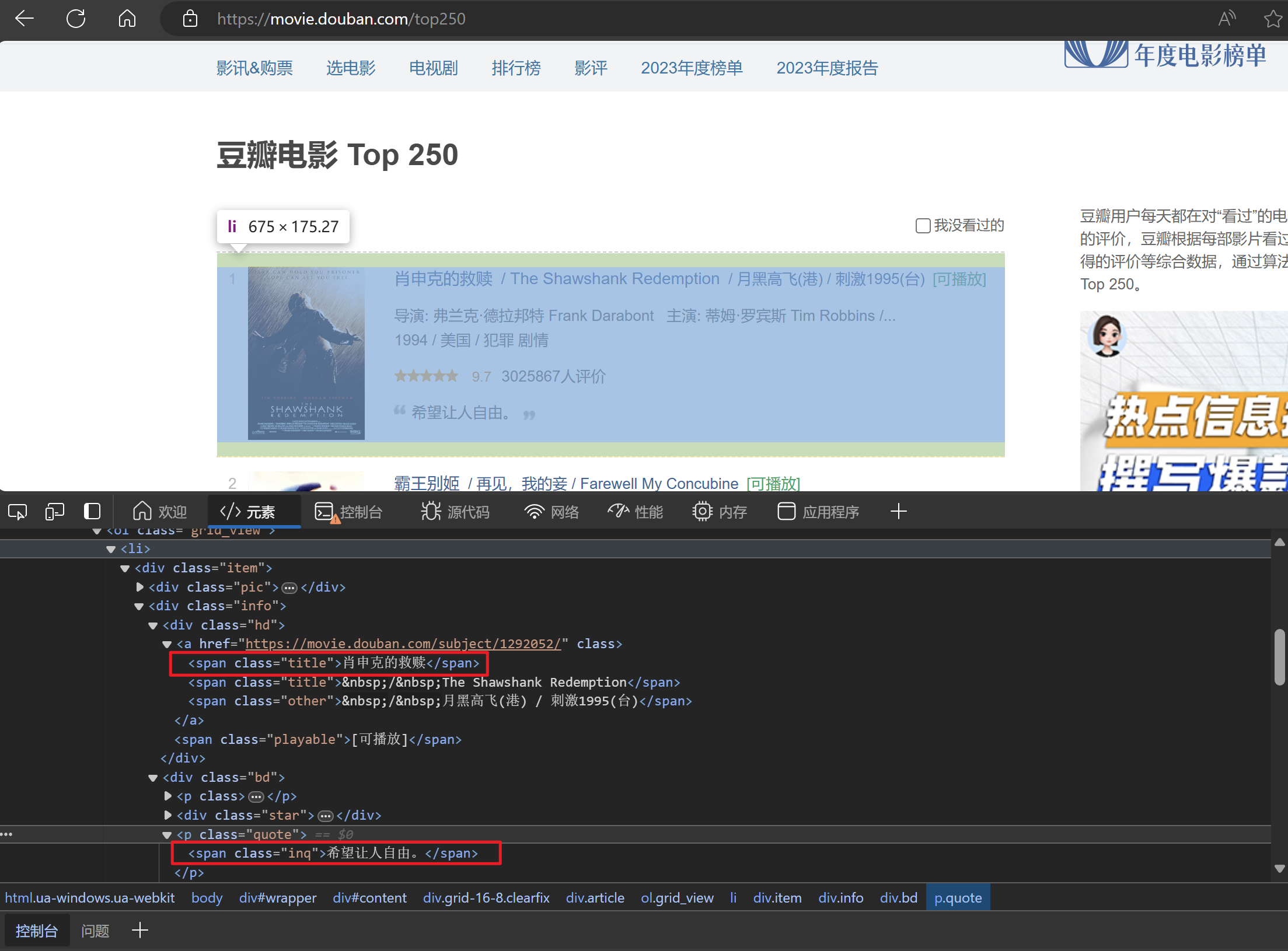
import requests
from bs4 import BeautifulSoupurl = 'https://movie.douban.com/top250'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}# 发送GET请求
response = requests.get(url, headers=headers)if response.status_code == 200:soup = BeautifulSoup(response.text, 'html.parser')divs = soup.find_all('div', class_='info')获取到每个电影外层的div元素后,再嵌套循环,将需要抓取的标签使用.find()和.find_all()方法获取到。
import requests
from bs4 import BeautifulSoupurl = 'https://movie.douban.com/top250'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}# 发送GET请求
response = requests.get(url, headers=headers)list = []if response.status_code == 200:# 解析html代码soup = BeautifulSoup(response.text, 'html.parser')# 查找此页面的所有div标签,选择器为'info'divs = soup.find_all('div', class_='info')# 遍历获取到的元素,获取电影名称和短语for div in divs:title = div.find_all('span')[0].textsen = div.find('span', class_='inq').textlist.append([title,sen])for l in list:print(l)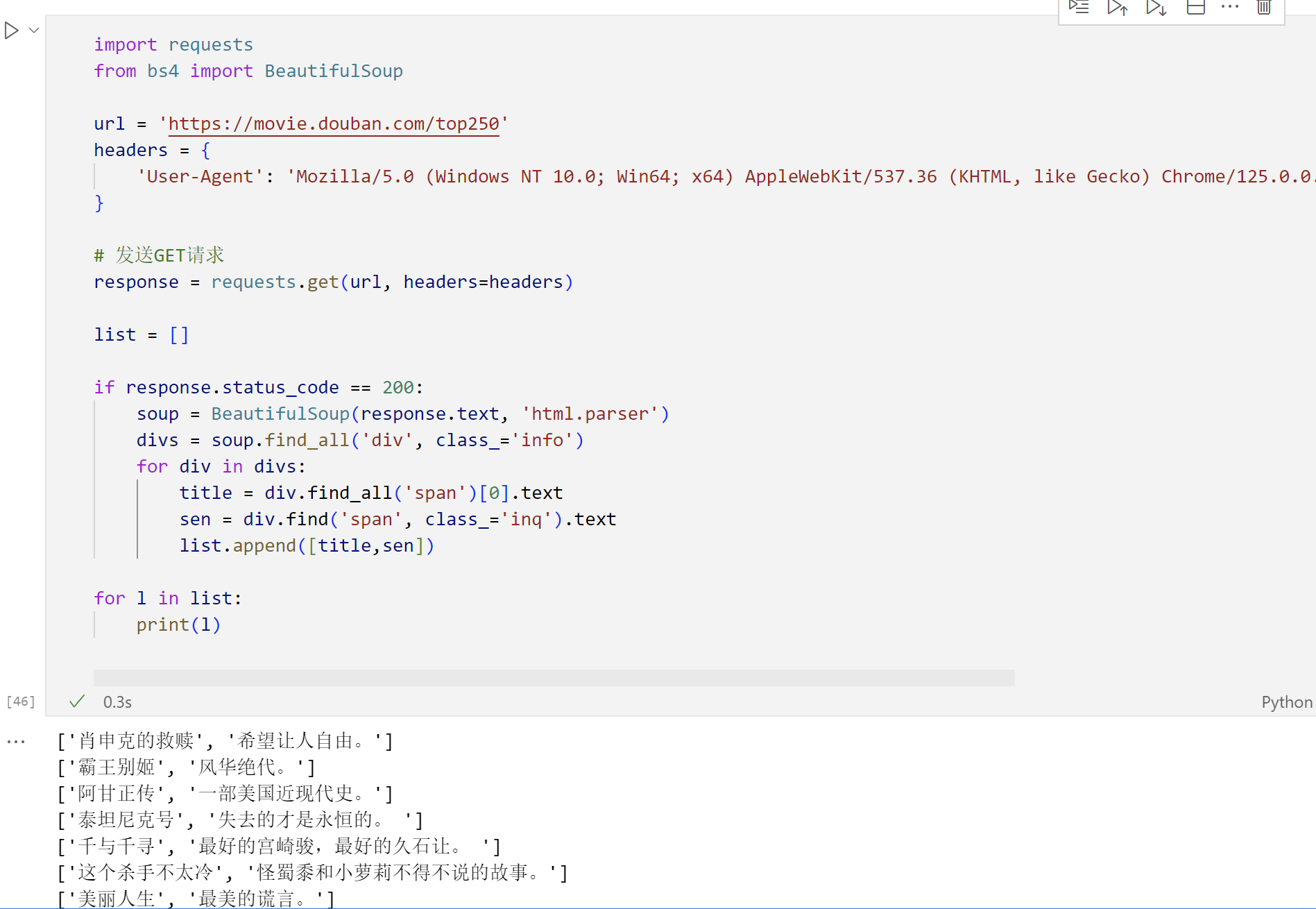
相关文章:
Python爬虫之简单学习BeautifulSoup库,学习获取的对象常用方法,实战豆瓣Top250
BeautifulSoup是一个非常流行的Python库,广泛应用于网络爬虫开发中,用于解析HTML和XML文档,以便于从中提取所需数据。它是进行网页内容抓取和数据挖掘的强大工具。 功能特性 易于使用: 提供简洁的API,使得即使是对网页结构不熟悉…...

前端怎么debugger排查线上问题
前端怎么debugger排查线上问题 1.问题背景2.问题详细说明3.处理方案a.开发环境怎么找,步骤一样的:b.生产环境怎么找,步骤一样的:还有一种情况就是你的子盒子是使用csshover父盒子出来的, 4.demo地址: 1.问题…...
LabVIEW源程序安全性保护综合方案
LabVIEW源程序安全性保护综合方案 一、硬件加密保护方案 选择和安装硬件设备 选择加密狗和TPM设备:选择Sentinel HASP加密狗和支持TPM(可信平台模块)的计算机主板。 安装驱动和开发工具:安装Sentinel HASP加密狗的驱动程序和开发…...

JS包装类:循环中为什么建议用变量存储str.length进行循环判断?
前言 在Javascript通常我们在遍历一个字符串的时候通常使用的方式是 var str "abcdefg"; for(let i0;i<str.length;i){}但在最近的学习中,有人建议我最好应该是下面这样执行。 var str "abcdefg"; for(let i0,len str.length;i<len;i)…...
)
Android Audio实战——音量默认值修改(一)
在前面的文章《音频配置加载》中我们知道了,Audio 的一些配置信息是由硬件驱动保存到 audio_policy_configuration.xml 文件中,音量的一些默认值也会如此。但是在一些车载设备开发中,需要适配不同车型的需求,一套代码通常要适配多个车型,这就需要在 FW 层进行一些默认值的…...
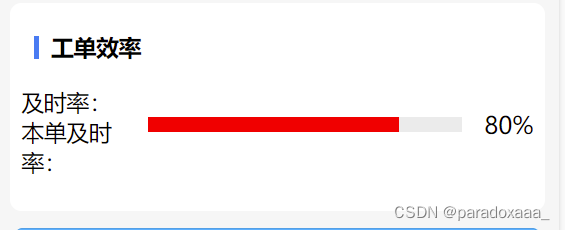
解决uni-app progress控件不显示问题
官方代码: <view class"progress-box"><progress :percent"80" show-info activeColor"red" stroke-width"10" /> </view> 进度条并不在页面中显示,那么我们需要给进度条加上宽高style"…...

使用C++版本的opencv dnn 部署onnx模型
使用OpenCV的DNN模块在C中部署ONNX模型涉及几个步骤,包括加载模型、预处理输入数据、进行推理以及处理输出。 构建了yolo类,方便调用 yolo.h 文件 #ifndef YOLO_H #define YOLO_H #include <fstream> #include <sstream> #include <io…...

python中实现队列功能
【小白从小学Python、C、Java】 【考研初试复试毕业设计】 【Python基础AI数据分析】 python中实现队列功能 选择题 以下代码最后一次输出的结果是? from collections import deque queue deque() queue.append(1) queue.append(2) queue.append(3) print(【显示】…...

自然资源-关于城镇开发边界局部优化的政策思路梳理
自然资源-关于城镇开发边界局部优化的政策思路梳理 国土空间规划的核心之一是要统筹划定“三区三线”,三条控制线中的城镇开发边界的划定与优化工作,一直是国土空间规划改革的重要组成部分,其有助于遏制城市盲目扩张,强化底线约束…...
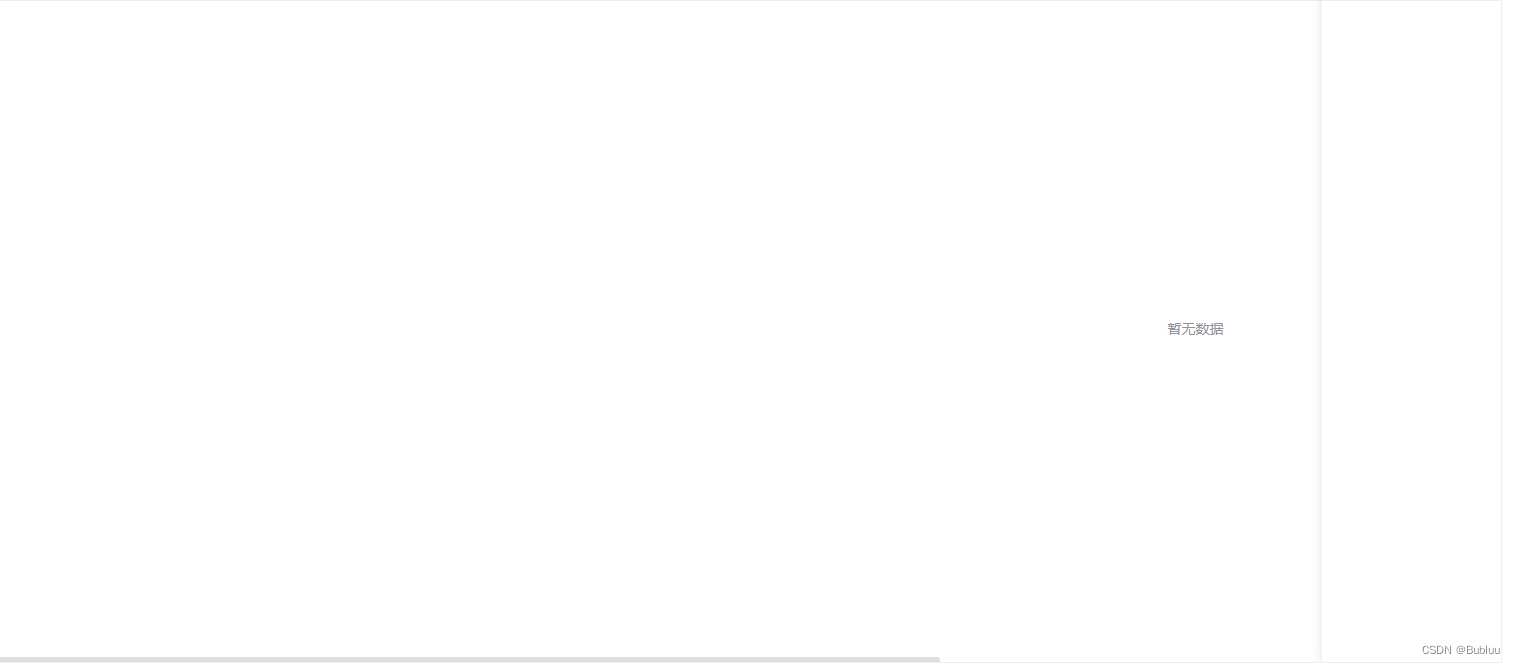
ElementUI的Table组件在无数据情况下让“暂无数据”文本居中显示
::v-deep .el-table__empty-block {width: 100%;min-width: 100%;max-width: 100%; }...
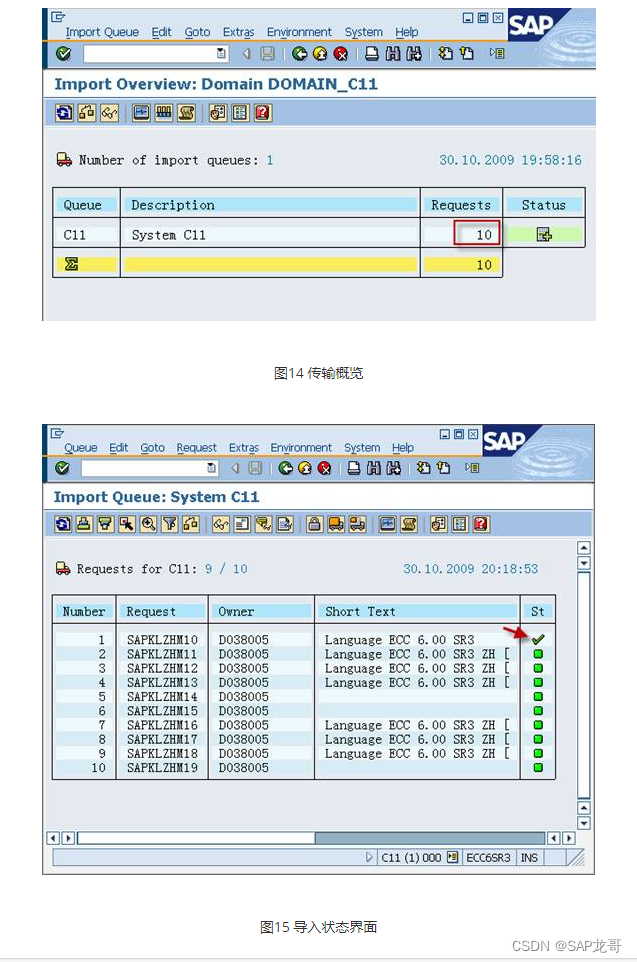

ant design的upload组件踩坑记录
antd版本 v4.17.0 1.自定义了onpreview和onchange事件,上传文件后,文件显示有preview的icon但是被禁用,无法调用onpreview事件。 问题展现: 苦苦查找原因,问题出在了这里,当文件没有url的时候,…...
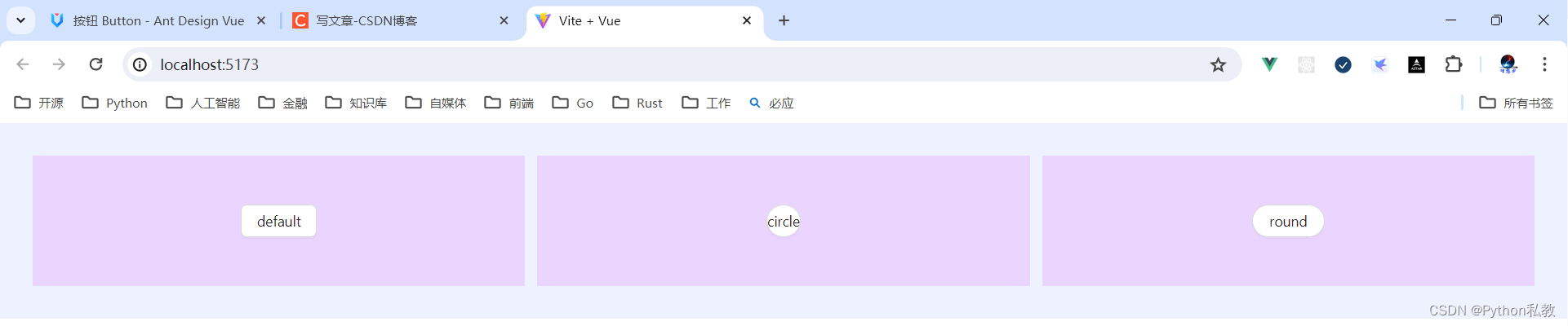
Python私教张大鹏 Vue3整合AntDesignVue之按钮组件
何时使用 标记了一个(或封装一组)操作命令,响应用户点击行为,触发相应的业务逻辑。 在 Ant Design Vue 中我们提供了五种按钮。 主按钮:用于主行动点,一个操作区域只能有一个主按钮。默认按钮࿱…...

【小海实习日记】PHP安装
## PHP环境搭建(Mac) ### php安装 使用brew需要安装homebrew >brew tap shivammathur/php >brew install shivammathur/php/php7.3 >brew link php7.3 这里可以需要homebrew使用代理进行下载,如果代理下载速度还是太慢,建议直接更该国内镜像…...

C++ Primer Chapter 4 Expressions
Chapter 4 Expressions 4.11 类型转换 4.11.2 其他隐式类型转换 数组转换成指针: 在大多数用到数组的表达式中,数组自动转换成指向数组首元素的指针: int ia[10]; int* ipa;♜ 当数组被用作decltype关键字的参数,或者作为取地…...

[leetcode hot 150]第一百三十七题,只出现一次的数字Ⅱ
题目: 给你一个整数数组 nums ,除某个元素仅出现 一次 外,其余每个元素都恰出现 三次 。请你找出并返回那个只出现了一次的元素。 你必须设计并实现线性时间复杂度的算法且使用常数级空间来解决此问题。 由于需要常数级空间和线性时间复杂度…...
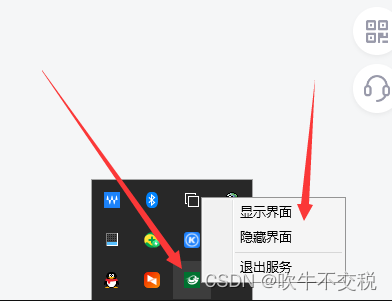
wpf工程中加入Hardcodet.NotifyIcon.Wpf生成托盘
1、在项目中用nuget引入Hardcodet.NotifyIcon.Wpf。如下图所示。 2、在App.xaml中创建托盘界面,代码是写在 App.xaml 里面 注意在application中一定要加入这一行代码: xmlns:tb"http://www.hardcodet.net/taskbar" 然后在<Application.R…...
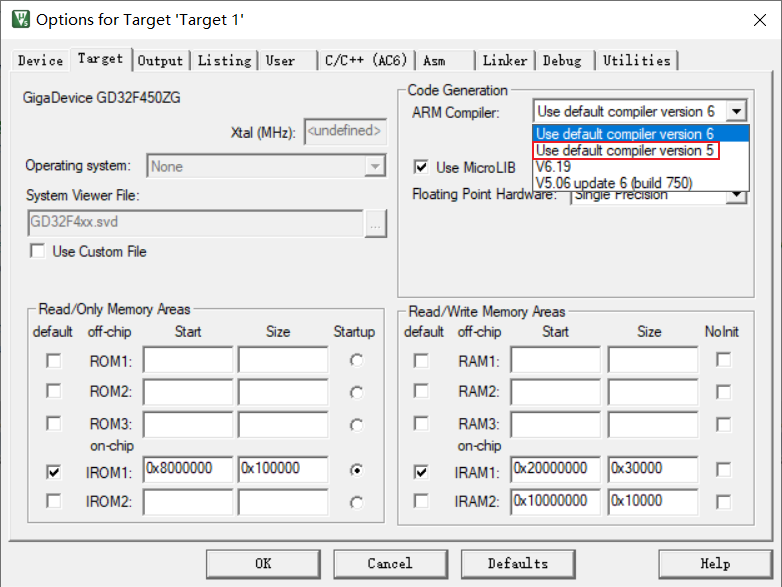
keil下载及安装(社区版本)
知不足而奋进 望远山而前行 目录 文章目录 前言 Keil有官方版本和社区版本,此文章为社区版本安装,仅供参考。 1.keil MDK 2.keil社区版介绍 3.keil下载 (1)打开进入登录界面 (2)点击下载,跳转到信息页面 (3)填写个人信息,点击提交 (4)点击下载…...
python书上的动物是啥
Python的创始人为Guido van Rossum。1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心开发一个新的脚本解释程序,做为ABC语言的一种继承。之所以选中Python作为程序的名字,是因为他是一个叫Monty Python…...
)
GeoServer实战:如何用MBTiles扩展包发布高德/谷歌多层级地图(含WPS扩展配置)
GeoServer高级应用:MBTiles与WPS扩展包深度整合实战指南 引言 在当今地理信息系统(GIS)领域,高效发布多层级地图数据已成为开发者面临的常见挑战。无论是商业地图服务如高德、谷歌地图,还是自定义的矢量切片,都需要一套稳定可靠的…...

5G NR新手必看:PBCH中的MIB数据解析与UE接入实战指南
5G NR新手必看:PBCH中的MIB数据解析与UE接入实战指南 在5G新空口(NR)技术中,物理广播信道(PBCH)承载的主信息块(MIB)是用户设备(UE)实现初始接入的关键。对于…...

5个命名智慧:猫抓cat-catch文件命名系统完全指南
5个命名智慧:猫抓cat-catch文件命名系统完全指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾面对这样的困境:下…...

2025届必备的AI辅助论文方案解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在撰写DeepSeek论文时,要将重点对准模型架构、训练算法以及性能优化方面。首先得…...

YimMenu技术指南:从环境部署到安全应用的全流程实践
YimMenu技术指南:从环境部署到安全应用的全流程实践 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMen…...

通义千问1.8B-Chat应用案例:智能客服问答系统搭建实战
通义千问1.8B-Chat应用案例:智能客服问答系统搭建实战 1. 引言:用轻量模型解决真实业务问题 如果你正在为搭建一个智能客服系统而烦恼,觉得大模型成本太高、部署太复杂,那么这篇文章就是为你准备的。今天,我要分享一…...

LRCGet:三步构建完美离线音乐歌词库的终极指南
LRCGet:三步构建完美离线音乐歌词库的终极指南 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否曾面对庞大的本地音乐收藏,…...

掌握QQ音乐加密格式转换:QMCDecode让你的音乐库重获自由
掌握QQ音乐加密格式转换:QMCDecode让你的音乐库重获自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认…...

抖音无水印视频批量下载:如何免费获取高清内容并高效管理
抖音无水印视频批量下载:如何免费获取高清内容并高效管理 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

如何快速找回加密压缩包密码:ArchivePasswordTestTool实战完全指南
如何快速找回加密压缩包密码:ArchivePasswordTestTool实战完全指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经因…...