数据挖掘 | 实验三 决策树分类算法
文章目录
- 一、目的与要求
- 二、实验设备与环境、数据
- 三、实验内容
- 四、实验小结
一、目的与要求
1)熟悉决策树的原理;
2)熟练使用sklearn库中相关决策树分类算法、预测方法;
3)熟悉pydotplus、 GraphViz等库中决策树模型可视化方法。
二、实验设备与环境、数据
PC机 + Python3.7环境(pycharm、anaconda或其它都可以)
python库: sklearn、pydotplus、 GraphViz等,
提供鸢尾花数据集iris150条记录(150*5)包括一个类标号属性。
三、实验内容
1)算法原理
决策树算法依据对一系列属性取值的判定得出最终决策。在每个非叶子节点上进行一个特征属性的测试,每个分支表示这个特征属性在某个值域上的输出,而每个叶子节点对应于最终决策结果。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点对应的类别作为决策结果。算法的目的是产生一棵泛化性能强,即处理未见数据能力强的决策树。
2)具体要求
1)利用相应库中算法对鸢尾花数据构建决策树;
了解sklearn相关库中决策树分类方法的接口,清洗、预处理处理鸢尾花数据,说明该方法对数据集的要求。
2)可视化决策树;
了解pydotplus、GraphViz等相关库中决策树可视化方法的接口,结合上述构建方法中参数的设置,分析每次构建的树的层数及叶子数目。
3)分别查看训练集、测试集上模型的评估指标(准确率);
对鸢尾花数据进行分割,或使用交叉验证等方法对每次形成的决策树进行评估。
4)(选做)自己编写ID3/C4.5决策树分类算法,构建决策树,并评估模型。
首先对数据进行预处理,主要包括缺失值的处理以及连续属性的离散化方法;然后进行各个模型的实现,包括:数据集中属性的信息增益(或信息增益率、gini指数)的计算;选择最佳划分属性;以及构建决策树的递归方法等。
实验代码:
# -- coding: utf-8 --
import osfrom sklearn import tree
import pydotplus
from sklearn.datasets import load_iris # 从sklearn包里datasets里导入数据集iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.tree import DecisionTreeClassifier # 训练器
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from pylab import *
from sklearn.tree import export_text
import randomos.environ["PATH"] += os.pathsep + r'D:\Environment\Graphviz2.38\bin'
# sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') # 改变标准输出的默认编码
# print(os.environ.get('PATH'))
# Graphviz是一个开源的可视化图形工具,可以很方便的用来绘制结构化的图形网络,支持多种格式输出(需要独立的在系统内安装)
# 导入数据集
iris = load_iris()
# print(iris)
# print(iris.data) #原数据
# print(iris.target) #目标数据# 构建模型
# 用于构建决策树,创建分类器
# scikit-learn 提供的 DecisionTreeClassifier 类可以做二分类任务
# 模型的训练,拟合数据
clf = tree.DecisionTreeClassifier().fit(iris.data, iris.target)# X: 训练数据,稀疏或稠密矩阵;Y别标签,整型数组# 导出树的结构
r = export_text(clf, feature_names=iris['feature_names']) # 以文本形式输出,决策树模型
print(r)
'''
tree.export_graphviz参数说明
为了能够准确的输出决策树规则,方法tree.export_graphviz当中一下参数必须设置成以下形式。其余参数使用默认的即可。
feature_names:特征名称,顺序必须和训练样本的数据一致
class_names:类别名称,输入的时候,必须要排序。如将原来的[‘1’, ‘0’]设置为[‘0’, ‘1’],注意:数据类型必须为str型的。
filled:填充,必须为True
node_ids:节点id,必须为True
rounded:画的图形边缘是否美化,必须为True
special_characters:必须为True
'''
# 以Graphviz格式导出
dot_data = tree.export_graphviz(clf,out_file=None,feature_names=iris.feature_names,filled=True,impurity=True,rounded=True)graph = pydotplus.graph_from_dot_data(dot_data) # 以DOT数据进行graph绘制
graph.get_nodes()[7].set_fillcolor("#FFF2DD") # 设置显示颜色
graph.write_png('iris.png') # 保存成图片
#
# 训练集、测试集数据分割seed = random.randint(1, 2647483647)
# 随机将样本集合划分为训练集 和测试集,并返回划分好的训练集和测试集数据。
# train_test_split是交叉验证中常用的函数train_data:所要划分的样本特征集,train_target:所要划分的样本结果
# test_size:样本占比,如果是整数的话就是样本的数量
# random_state:是随机数的种子
train, test, train_label, test_label = train_test_split(iris.data, iris.target, test_size=0.3, random_state=seed)
# print(train,train_label)
# print(test,test_label)
# 选用机器学习算法
models = [] # 模型列表 模型算法对象加入列表
models.append(('DecisionTree', DecisionTreeClassifier())) # 决策树
models.append(('GaussianNB', GaussianNB())) # 朴素贝叶斯
models.append(('RandomForest', RandomForestClassifier())) # 随机森林
models.append(('SVM', SVC())) # 支持向量机SVM# 基于测试集test的预测及验证
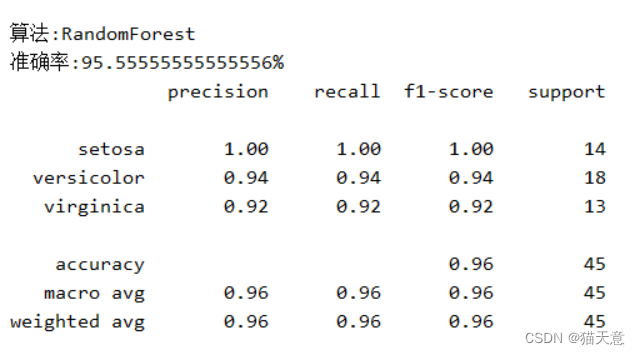
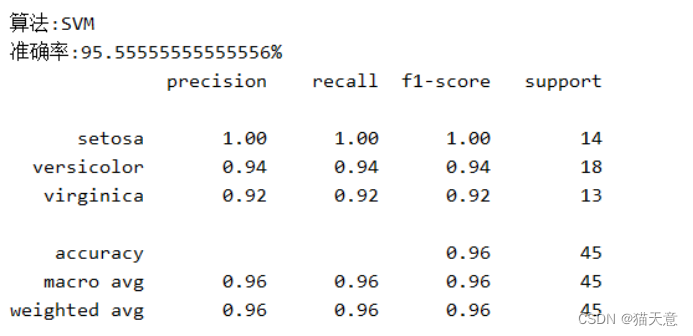
for name, model in models:model.fit(train, train_label) # 进行训练 用训练集和训练标签pre = model.predict(test) # 用测试集进行预测results = model.score(test, test_label) # 结果验证print("算法:{}\n准确率:{}{} ".format(name, results * 100, "%"))print(classification_report(test_label, pre, target_names=iris.target_names))
# 其中列表左边的一列为分类的标签名,右边support列为每个标签的出现次数.avg / total行为各列的均值(support列为总和).
# precision recall f1-score三列分别为各个类别的 精确度/召回率 F1值. F1值是精确度和召回率的调和平均值:
'''
classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息。
主要参数:
y_true:1维数组,或标签指示器数组/稀疏矩阵,目标值。
y_pred:1维数组,或标签指示器数组/稀疏矩阵,分类器返回的估计值。
labels:array,shape = [n_labels],报表中包含的标签索引的可选列表。
target_names:字符串列表,与标签匹配的可选显示名称(相同顺序)。
sample_weight:类似于shape = [n_samples]的数组,可选项,样本权重。
digits:int,输出浮点值的位数.
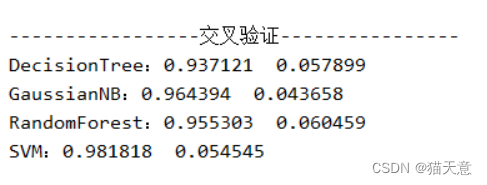
'''# 交叉验证
print("-----------------交叉验证----------------")
X_train, X_test, Y_train, Y_test = train_test_split(iris.data, iris.target)
names = []
scores = []
for name, model in models:cfit = model.fit(X_train, Y_train) # 训练cfit.score(X_test, Y_test) # 分数cv_scores = cross_val_score(model, X_train, Y_train, cv=10) # 分数scores.append(cv_scores) # 加入names.append(name) # 名称加入print("{}:{:.6f} {:.6f}".format(name, cv_scores.mean(), cv_scores.std()))# 算法比较
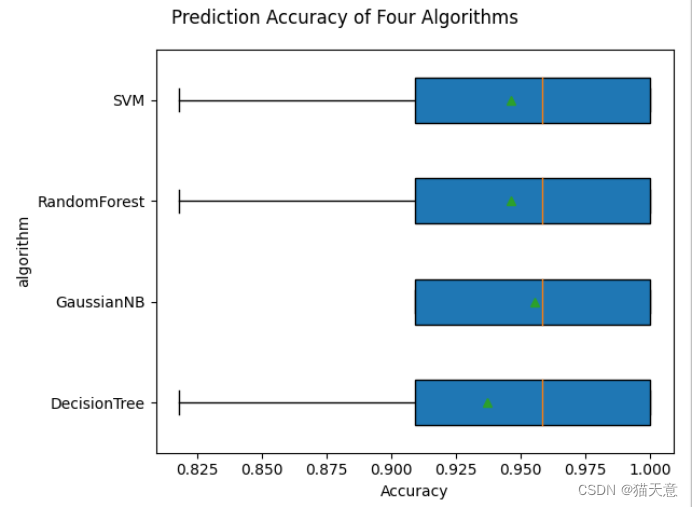
fig = plt.figure() # 创建画布
fig.suptitle('Prediction Accuracy of Four Algorithms') # 设置标题:四种算法准确率比较
ax = fig.add_subplot(1, 1, 1) # 新增子图或区域
# 比如221,指的就是将这块画布分为2×2,然后1对应的就是1号区
# 111 1 * 1 然后1对应的就是1号区
plt.ylabel('algorithm') # 算法
plt.xlabel('Accuracy') # 准确率
# patch_artist控制箱体图的填充,默认值为False, 此时箱体图的颜色指定的是表框的颜色,当取值为True时,color参数的值为箱体图的填充色,用法如下
plt.boxplot(scores, vert=False, patch_artist=True, meanline=False, showmeans=True)
# x :绘图数据。
# vert :是否需要将箱线图垂直放,默认垂直放。
# patch _ artist :是否填充箱体的颜色。
# meanline :是否用线的形式表示均值,默认用点表示。
# showmeans :是否显示均值,默认不显示。
ax.set_yticklabels(names)
plt.show()
实验截图:
决策树结构展示:
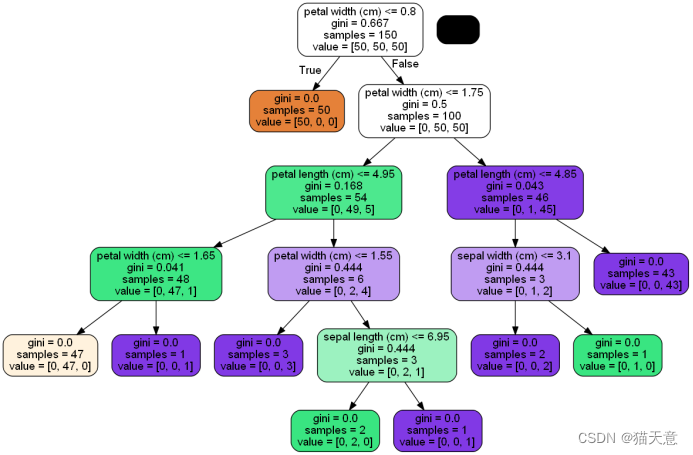
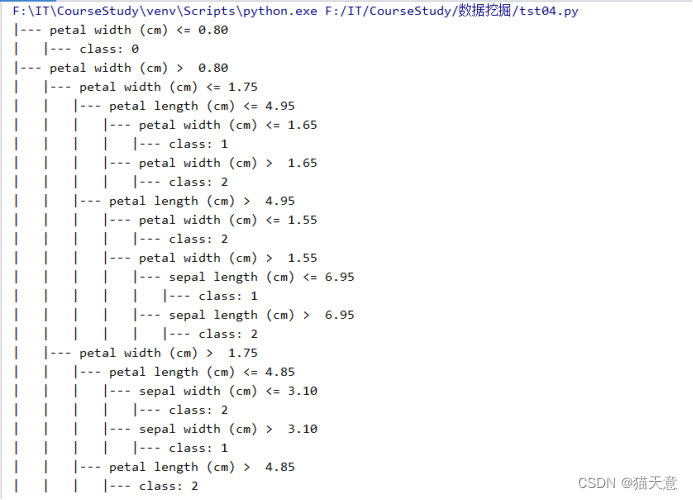
决策树分类器:
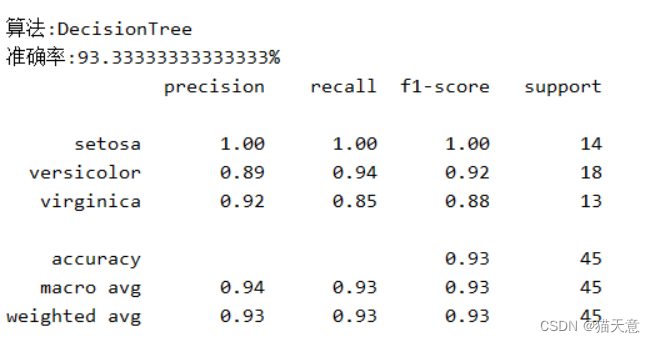
高斯分类器:
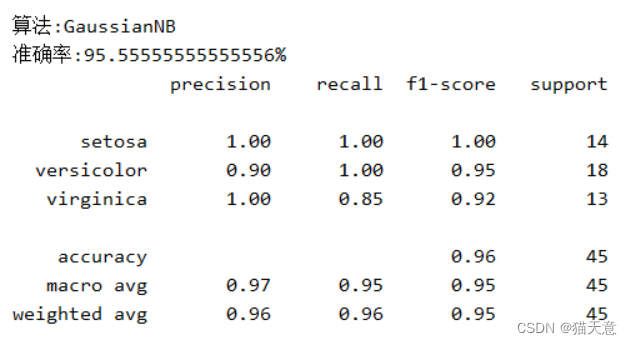
随机森林分类器:
支持向量机分类器:
交叉验证:
预测图:
四、实验小结
总结:
- 通过本次实验加深了我对决策树原理的理解,本次实验使用了4种分类算法进行分类,习了决策树模型的构建过程,分类算法,预测方法,以及决策树的可视化、最后进行交叉验证。
- 本次实验中用到了sklearn库,以及pydotplus库、GraphViz的使用,GraphViz的使用需要下载exe文件安装到电脑中并配置相应的环境变量才可以正常使用。
- 此次实验是通过使用不同算法对鸢尾花数据集进行分类以及预测,对比不同算法的准确率可知,在多次试验后SVM算法的效果较好,鸢尾花数据集还需要多多研究和掌握。
- 这些算法的区别和特点需要清楚,还有背后的原理需要掌握,并且加以实验才能更好的掌握这些知识。
相关文章:
数据挖掘 | 实验三 决策树分类算法
文章目录 一、目的与要求二、实验设备与环境、数据三、实验内容四、实验小结 一、目的与要求 1)熟悉决策树的原理; 2)熟练使用sklearn库中相关决策树分类算法、预测方法; 3)熟悉pydotplus、 GraphViz等库中决策树模型…...

Python机器学习预测区间估计工具库之mapie使用详解
概要 在数据科学和机器学习领域,预测的不确定性估计是一个非常重要的课题。Python的mapie库是一种专注于预测区间估计的工具,旨在提供简单易用的接口来计算和评估预测的不确定性。通过mapie库,用户可以为各种回归和分类模型计算预测区间,从而更好地理解模型预测的可靠性。…...

Linux基础指令磁盘管理002
LVM(Logical Volume Manager)是Linux系统中一种灵活的磁盘管理和存储解决方案,它允许用户在物理卷(Physical Volumes, PV)上创建卷组(Volume Groups, VG),然后在卷组上创建逻辑卷&am…...

Python怎么添加库:深入解析与操作指南
Python怎么添加库:深入解析与操作指南 在Python编程中,库(Library)扮演着至关重要的角色。它们为我们提供了大量的函数、类和模块,使得我们可以更高效地编写代码,实现各种功能。那么,Python如何…...

Python | 虚拟环境的增删改查
mkvirtualenv创建虚拟环境 mkvirtualenv是用于在Pyhon中创建虚拟环境的命令。它通过使用vitualenv库来创建一个隔离的Python环境,以便您可以安装特定版本的Python包,而不会影响全局Python环境。 使用方法: 安装virtualenv:pip install vir…...

【MySQL数据库】:MySQL内外连接
目录 内外连接和多表查询的区别 内连接 外连接 左外连接 右外连接 简单案例 内外连接和多表查询的区别 在 MySQL 中,内连接是多表查询的一种方式,但多表查询包含的范围更广泛。外连接也是多表查询的一种具体形式,而多表查询是一个更…...

C# FTP/SFTP 详解及连接 FTP/SFTP 方式示例汇总
文章目录 1、FTP/SFTP基础知识FTPSFTP 2、FTP连接示例3、SFTP连接示例4、总结 在软件开发中,文件传输是一个常见的需求。尤其是在不同的服务器之间传输文件时,FTP(文件传输协议)和SFTP(安全文件传输协议)成…...

二、【源码】实现映射器的注册和使用
源码地址:https://github.com/mybatis/mybatis-3/ 仓库地址:https://gitcode.net/qq_42665745/mybatis/-/tree/02-auto-registry-proxy 实现映射器的注册和使用 这一节的目的主要是实现自动注册映射器工厂 流程: 1.创建MapperRegistry注册…...
Android Compose 十:常用组件列表 监听
1 去掉超出滑动区域时的拖拽的阴影 即 overScrollMode 代码如下 CompositionLocalProvider(LocalOverscrollConfiguration provides null) {LazyColumn() {items(list, key {list.indexOf(it)}){Row(Modifier.animateItemPlacement(tween(durationMillis 250))) {Text(text…...
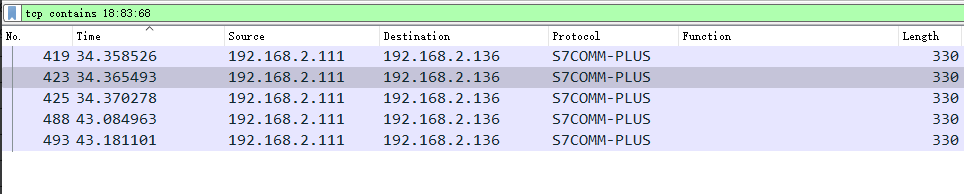
Wireshark 如何查找包含特定数据的数据帧
1、查找包含特定 string 的数据帧 使用如下指令: 双引号中所要查找的字符串 frame contains "xxx" 查找字符串 “heartbeat” 示例: 2、查找包含特定16进制的数据帧 使用如下指令: TCP:在TCP流中查找 tcp contai…...
【深度学习入门篇一】阿里云服务器(不需要配环境直接上手跟学代码)
前言 博主刚刚开始学深度学习,配环境配的心力交瘁,一塌糊涂,不想配环境的刚入门的同伴们可以直接选择阿里云服务器 阿里云天池实验室,在入门阶段跑个小项目完全没有问题,不要自己傻傻的在那配环境配了半天还不匹配&a…...

app,waf笔记
API攻防 知识点: 1、HTTP接口类-测评 2、RPC类接口-测评 3、Web Service类-测评 内容点: SOAP(Simple Object Access Protocol)简单对象访问协议是交换数据的一种协议规范,是一种轻量级的、简单的、基于XML&#…...

数据仓库之维度建模
维度建模(Dimensional Modeling)是一种用于数据仓库设计的方法,旨在优化查询性能并提高数据的可读性。它通过组织数据为事实表和维度表的形式,提供直观的、易于理解的数据模型,使业务用户能够轻松地进行数据分析和查询…...

解决远程服务器连接报错
最近使用服务器进行数据库连接和使用的时候出现了一个报错: Error response from daemon: Conflict. The container name “/mysql” is already in use by container “1bd3733123219372ea7c9377913da661bb621156d518b0306df93cdcceabb8c4”. You have to remove …...

通过电脑查看Wi-Fi密码的方法,提供三种方式
式一: 右击桌面右下角的网络图标,依次选择【网络和Internet设置】、【WLAN】、【网络和共享中心】。点击已连接的无线网络。依次点击【无线属性】、【安全】,勾选下方【显示字符】即可。 方式二: 在开始菜单输入“cmd”进入命令…...
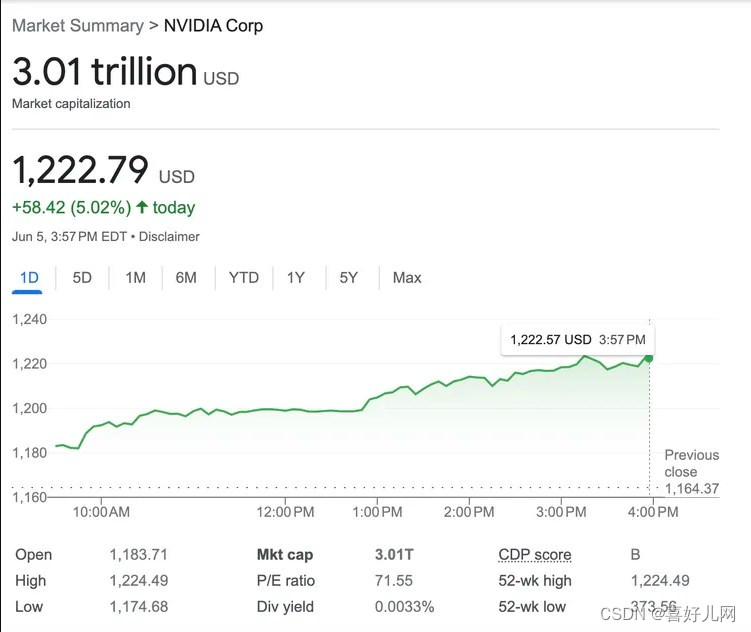
Nvidia 目前的市值为 3.01 万亿美元,超过苹果Apple
人工智能的繁荣将英伟达的市值推高到足以使其成为全球第二大最有价值的公司。 英伟达已成为全球第二大最有价值的公司。周三下午,这家芯片制造巨头的市值达到 3.01 万亿美元,领先于苹果公司的 3 万亿美元。 喜好儿网AIGC专区:https://heehe…...

用langchain搭配最新模型ollama打造属于自己的gpt
langchain 前段时间去玩了一下langchain,熟悉了一下大模型的基本概念,使用等。前段时间meta的ollama模型发布了3.0,感觉还是比较强大的,在了解过后,自己去用前后端代码,调用ollama模型搭建了一个本地的gpt应用。 核心逻辑 开始搭…...

工业互联网基本概念及关键技术(295页PPT)
资料介绍: 工业互联网的核心是通过工业互联网平台把设备、生产线、工厂、供应商、产品和客户紧密地连接融合起来。这种连接能够形成跨设备、跨系统、跨厂区、跨地区的互联互通,从而提高效率,推动整个制造服务体系智能化。同时,工…...
Python pandas openpyxl excel合并单元格,设置边框,背景色
Python pandas openpyxl excel合并单元格,设置边框,背景色 1. 效果图2. 源码参考 1. 效果图 pandas设置单元格背景色,字体颜色,边框 openpyxl合并单元格,设置丰富的字体 2. 源码 # excel数字与列名互转 import o…...

【vue3|第7期】 toRefs 与 toRef 的深入剖析
日期:2024年6月6日 作者:Commas 签名:(ง •_•)ง 积跬步以致千里,积小流以成江海…… 注释:如果您觉得有所帮助,帮忙点个赞,也可以关注我,我们一起成长;如果有不对的地方ÿ…...

Graphormer与YOLOv5跨界应用:从分子结构到材料缺陷的视觉识别
Graphormer与YOLOv5跨界应用:从分子结构到材料缺陷的视觉识别 1. 当图神经网络遇上目标检测 你可能很难想象,一个原本用于分析分子结构的AI模型,和一个专门检测图像中物体的算法,能擦出怎样的火花。这就是我们今天要展示的Graph…...

收藏必备!小白程序员轻松入门大模型:从零排查RAG检索问题
本文针对RAG系统上线后常见的检索问题,提出了从源头到后处理的排查思路。文章首先强调文档入库的重要性,接着深入分析向量化和检索召回环节的常见错误,如模型不一致、表述差异等,并给出解决方案。最后,文章还关注排序和…...

Webfunny前端监控系统安全防护终极指南:SQL注入防护与API鉴权最佳实践
Webfunny前端监控系统安全防护终极指南:SQL注入防护与API鉴权最佳实践 【免费下载链接】webfunny_monitor 【免费社区版】【企业版】Webfunny是一款集全链路监控和埋点系统于一体的大数据分析系统,我们致力于解决线上的疑难杂症和精细化分析业务数据&…...

FanControl:智能调节电脑风扇转速的系统级解决方案
FanControl:智能调节电脑风扇转速的系统级解决方案 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/Fa…...

Lepton AI与FastAPI集成:构建高性能AI API服务的终极指南
Lepton AI与FastAPI集成:构建高性能AI API服务的终极指南 【免费下载链接】leptonai A Pythonic framework to simplify AI service building 项目地址: https://gitcode.com/gh_mirrors/le/leptonai Lepton AI是一个Pythonic框架,专门用于简化AI…...

GLM-4.1V-9B-Base算法应用:融合LSTM时序预测的智能视频内容分析平台
GLM-4.1V-9B-Base算法应用:融合LSTM时序预测的智能视频内容分析平台 1. 引言:当视频分析遇上多模态AI 想象一下这样的场景:一个商场监控室里,安保人员需要同时盯着几十个监控画面;或者一个短视频平台的内容审核团队&…...
别再死记硬背了!用MONAI Transform处理医学图像,这5个实战场景帮你一次搞懂
医学图像处理实战:5个MONAI Transform核心场景解析 医学影像AI开发中最令人头疼的环节,往往不是模型设计,而是数据预处理。我曾见过不少团队花费80%的时间在数据清洗和转换上,却依然难以构建标准化的处理流程。MONAI Transform的出…...
)
SN75453与非门电路设计:如何正确选择上下拉电阻值(附计算公式)
SN75453与非门电路设计:如何正确选择上下拉电阻值(附计算公式) 在数字电路设计中,与非门是最基础的逻辑门之一,而SN75453作为一款经典的TTL与非门芯片,广泛应用于各种控制系统中。但很多工程师在实际应用时…...

【RAG】基于 RAG 的知识库问答系统设计与实现
基于 RAG 的知识库问答系统设计与实现1. 系统介绍2. 技术与方法3. 核心功能代码片段3.1 知识库创建3.2 知识对话问答3.3 知识库清空4. 系统运行效果截图4.1 文件上传与知识库创建4.2 知识库问答4.3 文件删除与知识库清空总结项目代码地址:https://github.com/AI-Mee…...

Pexpect异常处理完全手册:EOF、TIMEOUT等错误的解决之道
Pexpect异常处理完全手册:EOF、TIMEOUT等错误的解决之道 【免费下载链接】pexpect A Python module for controlling interactive programs in a pseudo-terminal 项目地址: https://gitcode.com/gh_mirrors/pe/pexpect Pexpect是一个功能强大的Python模块&a…...