python 字符串(str)、列表(list)、元组(tuple)、字典(dict)
学习目标:
1:能够知道如何定义一个字符串; [重点]
使用双引号引起来: 变量名 = "xxxx"
2:能够知道切片的语法格式; [重点]
[起始: 结束]
3:掌握如何定义一个列表; [重点]
使用[ ]引起来: 变量名 = [xx,xx,...]
4:能够说出4个列表相关的方法; [了解]
append()、remove()、len()、sort()、insert()、extend()、reverse()、...
字符串介绍:
介绍:[了解]什么是Python容器:
在现实生活中,我们知道容器是用来存放东西的,比如实验室里的烧杯等。

类似的,在Python中的容器是用来存放数据的。
与此同时,为了操作方便,Python给我们提供了对容器中数据处理的方法,例如增加、删除、修改、查询等。
变量名.函数(x)
在Python中,常见容器有:
(1)字符串:str
(2)列表:list
(3)元组:tuple
(4)字典:dict

(1)字符串:使用双引号引起来的内容;
(2)列表:使用[ ]表示的内容; (可变数据类型)(3)元组:使用( )表示的内容;
(4)字典:使用{ }表示,内部元素是键值对。
例子:
(1)分别定义字符串、列表、元组、字典变量;
(2)使用【type(变量名)】查看变量的类型;
(3)执行程序,观察效果。
# 1.字符串变量a = "itheima"print(a) # itheimaprint(type(a)) # <class 'str'>2.列表b = ["it","heima"]print(b) # ['it', 'heima']print(type(b)) # <class 'list'># 3.元组c = ("it","heima",)print(c) # ('it', 'heima')print(type(c)) # <class 'tuple'># 4.字典
d = {"name":"itheima","age":17}
print(d)
print(type(d)) # <class 'dict'>
注意:Python容器有很多操作方法,但都是使用【变量名.函数(x)】形式完成调用
[掌握]创建字符串
字符串表示文本内容,例如中文文字、学生姓名、一段英文等。
通俗地说,字符串就是使用双引号引起来的内容。
创建字符串语法:
变量名 = "内容"
说明:
字符串可以使用双引号或单引号表示,较常见的是双引号表示。
例子:
例如,一起来完成:
(1)使用双引号表示一个公司名称;
(2)使用单引号表示公司名称;
(3)分别输出变量的类型结果;
(4)思考1:使用字符串与一个数值拼接,会怎样?
(5)思考2:一段使用引号表示的字符串中,还有引号,该怎么处理?
# 1.双引号
strs1 = "大象程序员"
print(strs1)
print(type(strs1)) # <class 'str'># 2.单引号 -扩展strs2 = '大象程序员'print(strs2)print(type(strs2)) # <class 'str'># 1.字符串拼接#a. + 字符串连接符
# b. 字符串只能和字符串数据拼接s1 = "hello"+"world"print(s1)s2 = "hello"+666 # 报错s2 = "hello"+"666"s2 = "hello"+str(666) # 指定数据类型名(变量)print(s2) # A.hello666 B、其他的2.引号? -扩展东升说: "我是38期最帅的男人."a = '东升说: "我是38期最帅的男人."'a = "东升说: \"我是38期最帅的男人.\""a = "东升说: '我是38期最帅的男人.'"
a = """东升说: "我是38期最帅的男人."
""" # 参考
print(a)(1)在实际应用中,创建字符串可以使用:单引号、双引号或三引号,但优先使用双引号;
[掌握]索引:
索引有时也称为下标、编号。
先来看看现实生活中的索引。比如超市门口的储物柜可以通过编号【索引】来找到。

Python字符串的索引,就与储物柜编号类似。比如有个字符串变量:name = 'abcdef',存放效果:

获取字符串元素语法:
变量名[索引值]
说明:
索引值是从0开始计算的。
接着,来看一下字符串长度的表示方式。
| 函数名 | 含义 |
|---|---|
| len(s) | 返回变量s的长度或元素个数。 |
说明:
(1)长度值是从1开始计算的;
(2)索引与长度的关系可表示为:【最大索引值 = 长度 - 1】。
例子 :
(1)定义一个存有HelloWorld的字符串变量;
(2)获取变量中的H和W;
(3)获取变量的总长度;
(4)思考:如何获取变量的最后一个元素d
# 1.定义变量
strs = "HelloWorldABCDE"
# 2.获取元素print(strs[0])print(strs[5])# 3.长度print(len(strs))# 4.访问最后一个元素正常print(strs[9])
print(strs[len(strs)-1]) # 灵活 = 更好维护# 逆向
print(strs[-1])注意:
(1)当使用超出最大索引的值去访问字符串的元素,会报错;
(2)索引与长度的关系是:【最大索引值 = (长度 - 1)】
[掌握]切片
切片指的是:截取字符串中的一部分内容。
切片语法:
[起始:结束]
另外的,当需要每隔几个字符来截取内容时,可以加入步长,语法:
[起始:结束:步长]
说明:
(1)切片语法选取的范围是左闭右开型,即[起始, 结束);
(2)注意:截取内容时,包含起始位,但不包含结束位。
例子:
(1)定义一个字符串变量,内容为:HelloITHEIMA;
(2)截取索引值1到5之间的内容;
(3)截取索引值2到结尾的内容;
(4)截取索引值2到倒数第2个的内容;
(5)截取起始处到索引值为3的内容;
(6)截取索引1到8且每隔2个字母截取一下内容;
(7)截取索引2到10且每隔3个截取一下内容。
# 1.定义变量
strs = "HelloITHEIMA"
# 2.1-5print(strs[1:5])
# 3.2-print(strs[2:12])
# 4.2 - 倒数第2print(strs[2:10])
# 5. -3print(strs[0:3])
# 6 1 8 2print(strs[1:8:2])
# 7. 2 10 3
print(strs[2:10:3])strs = "HelloITHEIMA"
# 3.2-print(strs[2:12])print(strs[2:100])print(strs[2:])# 4.2 - 倒数第2print(strs[2:10])print(strs[2:-2])# 5. -3print(strs[0:3])print(strs[:3])# 从后往前数数,可以使用负数表示; 当从开始处截取时,可以省略起始位; 当截取到结尾处时,可以省略结束位.# 升级: 记住 若要对字符串反转,该怎么做?
print(strs[::-1])字符串的遍历
[掌握]使用for遍历字符串
==目标:==掌握使用for语句遍历字符串。
for循环语法:
for 临时变量 in 序列:
满足条件时,执行的代码1
满足条件时,执行的代码2
……
[else:
当for循环正常执行结束后,执行代码]
例子:
(1)定义一个字符串变量,内容为:ABCDEF;
(2)使用for循环来遍历元素;
(3)执行程序,观察效果。
# 1.定义字符串
strs = "ABCDEF"
# 2.使用for遍历
for temp in strs: # 疑问: 元素对应索引值?print(temp)# 3.扩展 -elsefor temp in strs:print(temp)else:print("所有字符串元素已遍历结束!!")==总结:==
(1)如果想快速获取字符串的所有元素,可以直接使用for循环;
(2)注意:使用for语句遍历字符串时,无法直接显示索引值。
[掌握]使用while遍历字符串
while循环语法:
初始化变量语句
while 循环条件:
循环体语句
改变循环条件的语句 # 先写
接着,再来看看获取长度。
| 函数名 | 含义 |
|---|---|
| len(s) | 返回变量s的长度或元素个数。 |
获取元素值的语法:
变量名[索引值]
例子:
(1)定义一个字符串变量,内容为:ABCDEF;
(2)使用while循环来遍历元素;
(3)执行程序,观察效果。
# 1.定义字符串变量
strs = "ABCDEF"
# 2.写循环
i = 0
# while i < len(strs):
while i <= (len(strs)-1):# 3.访问元素print(strs[i])i += 1# 思考:从后往前输出?? 
==总结:==
(1)如果要获取字符串的所有元素,可以使用while循环;
(2)注意:我们会发现,可以使用for或while来遍历字符串,但优先考虑使用(==for==)循环来遍历。
扩展:断点调试方法:

常用操作方法
[了解]查找元素
==目标:==了解字符串查找方法的使用。
字符串的查找方法指的是查找元素(或子串)在字符串内容的索引位置。
查找方法:
| 函数名 | 含义 |
|---|---|
| find(sub) | 检测sub是否包含在字符串中,如果是,则返回sub所在开始的索引,否则返回-1。 |
| index(sub) | 与find()类似,只不过当sub在字符串中不存在时,会报错误。 |
| rfind(sub) | 从右往左找子串在字符串的某个索引。 |
| count(sub) | 计算sub在字符串中出现的总次数。 |
例子:
(1)定义一个字符串变量,内容为:hello world and itcast and itheima and Python;
(2)分别使用find()和index()函数来查看and所在位置;
(3)思考1:如果查找不存在的内容666,效果如何?
(4)思考2:若要从右往左查找and,该怎么做?若还要获取and出现的总次数呢?
(5)扩展:字符串的操作方法那么多,该怎么记忆呢?

==总结:==
(1)当要查找字符串的某元素时,可以使用find()、index();
(2)注意:实际应用中,优先使用(==find()==)方法查找字符串元素,因为这个方法更稳定。
# 1.定义字符串
name = "hello world and itcast and itheima and Python"
# 2.and -find() index()print(name.find("and"))print(name.index("and"))
# 3.对比find indexprint(name.find("666")) # 稳定print(name.index("666")) # 报错
# 4.从右往左 rightprint(name.rfind("and"))print(name.rindex("and"))
# 总次数print(name.count("and"))
# 5.如何记忆
# a.大佬发
# b.技巧: 看快捷提示
# name.[掌握]修改元素
==目标:==掌握字符串修改方法的使用。
字符串的修改方法,指的是修改字符串中的数据。
| 函数名 | 含义 |
|---|---|
| replace(old, new) | 用于将字符串中的old内容替换成new内容。 |
| split(sep) | 使用指定内容sep来对字符串进行切割。 |
| strip() | 用于去掉字符串前后的空白内容。 |
说明:
修改字符串,就是将字符串原有内容修改为其他结果。
例子:
(1)定义一个字符串变量,内容有: hello itheima big data ;
(2)将变量中的空格替换为666;
(3)使用空格、字符a来分别分割字符串;
(4)去掉字符串的前后空白内容。
# 1.定义字符串strs = "hello itheima big data"
# 2.替换ret1 = strs.replace(" ","666")print(ret1) #" " -暂无数据
# 3.分割 -切割ret2 = strs.split("a")print(ret2)
# 4.去掉空白
strs = " hello itheima big data "print(strs.strip())
result1 = strs.lstrip()
result2 = result1.rstrip()
print(result2)==总结:==
(1)当要对字符串文本内容进行替换数据时,可以使用(replace())方法;
(2)注意:split()常应用与分割字符串数据内容。
列表的基本使用
[掌握]列表的定义
==目标:==掌握如何定义列表。
列表类型为list,是Python中的一种常见类型。
列表可以存放各种数据类型的数据,且列表的长度会随着添加数据的变化而变化。
列表语法:
变量名 = [元素1,元素2,元素3,...]
说明:
列表的多个元素之间使用,逗号分隔。
例如,一起来完成:
(1)定义一个列表变量1,用于存放几个知名大学名称;
(2)定义一个列表变量2,用于存放某学生的姓名、年龄、存款、是否男生等信息;
(3)思考:要把字符串Python转换为列表list类型的值,该怎么做?
# 1.定义列表变量:相同类型lists = ["南京大学","南开大学","南昌大学","东南大学"] # 数组print(type(lists))
# 2.不同类型的数据元素data = ["汪致诚",38,0,True]print(type(data)) # 列表中可以存放多种不同类型的数据
# 3.思考: list()
strs = "Python"
result = list(strs)
print(result) # A.[python] B.[P y t h o n]==总结:==
(1)列表就是一个Python容器,可以用于存放任意类型的数据;
(2)注意:如果要定义一个列表变量,可以使用()符号:==A、[ ]==;B、{ }。
[掌握]访问列表元素和长度
==目标:==掌握如何访问列表元素和长度。
获取列表的元素和长度的方式与字符串一样。
获取列表元素语法:
变量名[索引值]
说明:索引值是从0开始计算的。
再来看一下列表长度的表示方式。
| 函数名 | 含义 |
|---|---|
| len(s) | 返回变量s的长度或元素个数。 |
说明:
(1)长度值是从1开始计算的;
(2)索引与长度的关系可表示为:【最大索引值 = 长度 - 1】。
例如,一起来完成:
(1)获取知名大学名称列表变量的元素总个数;
(2)获取列表变量的第1个和第3个位置对应的元素值;
(3)思考:若直接访问不存在的第100个元素值,会怎样?

lists = ["南京大学","南开大学","南昌大学","东南大学"]
# 获取总个数print(len(lists))
# 访问元素print(lists[0])print(lists[2])
# 问题
print(lists[100])
# 注意: 当直接通过 变量名[索引值] 访问元素时, 记得索引值不允许超过最大索引值。 -报错!==总结:==
(1)当给列表变量添加新内容后,列表的长度也会变化;
(2)注意:如果要获取列表元素的总个数,可以使用(len(xx))方法。
[掌握]使用for遍历列表
==目标:==掌握使用fo语句遍历列表。
先来看看,for循环语法:
for 临时变量 in 序列:满足条件时,执行的代码1满足条件时,执行的代码2…… [else:当for循环正常执行结束后,执行代码]
例如,一起来完成:
(1)定义一个列表变量,用于存放水果信息,内容为:苹果、香蕉、西瓜、菠萝等;
(2)使用for循环来遍历元素;
(3)执行程序,观察效果。
# 1.定义列表变量
datas = ["苹果","香蕉","西瓜","菠萝"]
# 2.遍历for temp in datas:print(temp)
# 3.查看到索引? 索引值 --> 元素
index = 0 # 引入一个计数器
for temp in datas:print(temp)print(f"{index} --> {temp}")index += 1==总结:==
(1)如果想快速获取列表的所有元素,可以使用for循环;
(2)注意:如果要在for循环中获取列表的索引值,可以引入一个计数器,这句话正确吗?==A、正确==;B、错误。
[了解]使用while遍历列表
==目标:==掌握使用while语句遍历列表。
先来看看,while循环语法:
初始化变量语句 while 循环条件:循环体语句改变循环条件的语句 # 先写
接着,再来看看获取长度。
| 函数名 | 含义 |
|---|---|
| len(s) | 返回变量s的长度或元素个数。 |
获取元素值的语法:
变量名[索引值]
例如,一起来完成:
(1)定义一个列表变量,用于存放水果信息,内容为:苹果、香蕉、西瓜、菠萝等;
(2)使用while循环来遍历元素;
(3)执行程序,观察效果。
datas = ["苹果","香蕉","西瓜","菠萝"]
# 遍历
i = 0
while i < len(datas):print(datas[i])i += 1
i = len(datas)-1while i >= 0:print(datas[i])i -= 1
# 扩展: 切片datas = ["苹果","香蕉","西瓜","菠萝"]
# # 获取除最后一个元素外的其他元素内容print(datas[0:-1])print(datas[:-1])# 获取第2-3个元素内容print(datas[1:3])==总结:==
(1)如果要获取列表的所有元素,可以使用while循环;
(2)注意:在实际应用中,可以优先使用for循环来遍历列表元素,因为for循环简单实用。
操作列表
[掌握]添加元素
==目标:==掌握如何给列表添加元素。
给列表添加元素表示的是:在列表变量的基础上,再添加新元素内容。
添加元素的方法:
| 函数名 | 含义 |
|---|---|
| append(x) | 用于在列表结尾处,添加数据内容x。 |
| insert(index, x) | 用于在列表索引index处,新增一个元素x。 |
| extend(x) | 用于给列表添加另一个列表的所有元素内容,并形成一个完整列表。 |
例如,一起来完成:
(1)定义一个列表变量,存放内容:中国、美国、英国、俄罗斯;
(2)在列表结尾处添加元素:德国;
(3)在元素美国后添加元素:日本;
(4)思考:若要在列表变量的结尾处,再新增元素:100、200、300,该怎么做?
# 1.定义列表的变量
country_list = ["中国","美国","英国","俄罗斯"] # 可变类型
print(f"原始数据:{country_list}")
# 2.添加1个元素到结尾
country_list.append("德国")
print(country_list)
# 3.在某元素后添加country_list.insert(1, "日本")print(country_list)
# 4.批量添加lists = [100,200,300]country_list.extend(lists)print(country_list)
# 5.扩展?lists = [100,200,300] # append添加一个元素
country_list.append(lists)
print(country_list)==总结:==
(1)当要给列表添加元素时,首先应该想到方法:(append());
(2)注意:当给列表添加一个元素后,列表的长度也会增加1。
[掌握]删除元素
==目标:==掌握如何删除列表元素。
删除列表元素指的是:删除列表变量的某元素内容。
删除元素的方法:
| 函数名 | 含义 |
|---|---|
| remove(x) | 删除列表元素值x。 |
| del 变量名[索引] | 根据索引值,删除列表的某个元素。 |
例如,一起来完成:
(1)定义一个列表变量,存放内容:中国、美国、英国、俄罗斯;
(2)使用remove()删除元素:英国;
(3)使用del删除元素:美国;
(4)执行程序,观察效果。
# 1.定义列表的变量
country_list = ["中国","美国","英国","俄罗斯"]
print(country_list)
print(f"原始长度:{len(country_list)}")
# remove()删除
country_list.remove("英国")
print(country_list)
print(f"删除后的长度:{len(country_list)}")
# del 删除del country_list[1]print(country_list)
# 扩展?country_list = ["中国","美国","英国","俄罗斯"]# country_list.pop()# print(country_list)print(country_list[:-1])==总结:==
(1)当要删除列表中的元素时,可以使用方法:A、remove();B、delete();
(2)注意:当删除列表中的一个元素后,列表的长度也会减1。
[掌握]修改元素
==目标:==掌握如何修改列表元素。
修改列表元素指的是:修改列表变量的某元素内容。
修改元素的方法:
| 函数名 | 含义 |
|---|---|
| 变量名[索引] = 值 | 根据索引值,来修改列表中的某个元素值。 |
例如,一起来完成:
(1)定义一个列表变量,存放内容:中国、美国、英国、俄罗斯;
(2)将中国修改为中华人民共和国;
(3)修改俄罗斯为Russia;
(4)执行程序,观察效果。
# 1.定义列表的变量
country_list = ["中国","美国","英国","俄罗斯"]
# 2.修改中国country_list[0] = "中华人民共和国"print(country_list)
# 3.修改俄罗斯country_list[3] = "Russia"
country_list[-1] = "Russia"
print(country_list)==总结:==
(1)如果要修改列表的元素,可以通过索引值来操作,这句话正确吗?==A、正确==;B、错误;
(2)注意:修改列表元素的操作在实际应用中使用较少,了解即可。
[掌握]查找元素
==目标:==掌握列表元素的查找。
查找列表元素指的是:查找列表变量的某元素内容是否存在?
查找元素的方法:
| 函数名 | 含义 |
|---|---|
| len(s) | 返回s的长度或元素个数。 |
| in | 判断指定数据是否在某个列表序列中。如果在就返回True,否则返回False。 |
例如,一起来完成:
(1)因["192.168.1.15", "10.1.1.100", "172.35.46.128","172.32.24.99"]等IP地址存在恶意访问黑马程序员官网,被列为访问黑名单;
(2)获取黑名单IP列表的长度;
(3)从键盘上输入一个IP地址,并用于判断是否是黑名单IP地址?

# 1.定义ip列表
ip_lists = ["192.168.1.15", "10.1.1.100", "172.35.46.128","172.32.24.99"]
# 2.获取长度print(len(ip_lists))
# 3.判断是否是黑名单
temp_ip = input("请输入IP地址:")
if temp_ip in ip_lists:print("Forbidden 403, 你的行为不检点!!!")
else:print("欢迎你!!")==总结:==
(1)如果要判断列表中是否存在某元素值,可以使用()关键字:A、and;==B、in==;
(2)当查找列表元素时,有两种情况,比如:遍历列表中的所有元素、查找某元素是否存在列表中。
[了解]排序操作
==目标:==了解列表的排序操作。
排序通常指按从小到大、从大到小的顺序排列。
操作方法有:
| 函数名 | 含义 |
|---|---|
| reverse() | 将列表进行倒序,即输入顺序与输出顺序相互倒过来。 |
| sort([reverse=False]) | 对列表进行从小到大排序。当设置reverse=True可改为由大到小排序。 |
例如,一起来完成:
(1)定义一个列表变量,存放数据:10、200、20、100、30、0;
(2)将列表数据进行倒序输出;
(3)将列表进行从小到大排序;
(4)思考:若要将列表元素进行从大到小排序,该怎么做呢?
# 1.定义变量
data = [10,200,20,100,30,0]
# 2.倒序
# data.reverse()
# print(data)
# 3.从小到大排序
data.sort()
print(data)
# 4.从大到小排序
# ?? 切片 -先从小到大、倒序
# data.sort()
# data.reverse()
# print(data)
# sort(=True)
# data.sort(reverse=True) # 参数??
# print(data)==总结:==
(1)当要对一批数值型数据做从小到大排序时,可以使用(sort())方法;
(2)注意:在实际应用中对内容的排序,方式有:A、阿拉伯数字排序;B、英文字母排序;C、其他内容排序。
元组
[了解]定义元组
==目标:==了解如何定义元组。
定义元组时,需要使用()小括号,用,逗号隔开各个元素,并且,元组的元素可以是不同类型的数据。
虽然元组从表面上看与列表类似,比如:
列表: [1, 2, 3, 4] 元组: (1, 2, 3, 4)
特别注意,元组的元素只能用来查询,且元素不可以修改、不可以删除、也不可以添加。
元组语法:
变量名 = (元素1,元素2,元素3,...)
说明:
(1)元组元素需要使用()小括号引起来;
(2)元组变量中可以存放不同类型的数据。
例如,一起来完成:
(1)定义一个元组变量1,用来存放多个数值;
(2)定义一个元组变量2,并存放不同类型的数据;
(3)查看变量类型,执行程序,观察效果。
# 1.定义变量1
ts1 = (1,2,3,8,90,)
# 2.定义变量2
ts2 = (True,"男","itheima",)
# 查看类型
print(ts1)
print(type(ts1))
print(type(ts2))
# 扩展?ts = (24) # <class 'int'>
ts = (24,)
print(type(ts))==总结:==
(1)当元组中仅有一个元素时,应该定义为【(元素, )】;
(2)请问:元组的内容可以查询,但不能添加、不能删除、也不能修改,这句话正确吗?==A、正确==;B、错误。
[掌握]常见操作
==目标:==掌握元组的查找。
我们已知道,元组数据只支持查找,且不支持修改、删除和添加。
操作方法有:
| 函数名 | 含义 |
|---|---|
| 元组变量名[索引] | 按索引值查找数据。 |
| index(x) | 查找某个数据,当数据不存在时会报错,语法和列表、字符串的index()方法相同。 |
| len(x) | 表示元组中元素的总个数。 |
| in | 用于判断元素是否出现在元组中。 |
例如,一起来完成:
(1)定义一个元组变量,内容有:Python、MySQL、Linux、Hadoop;
(2)试着给元组变量添加、删除、修改元素,观察效果;
(3)查找元组中的元素:Python、Linux;
(4)查看元组中的元素总个数;
(5)判断Hello是否存在元组变量中?

# 1.定义变量
source = ("Python","Linux","MySQL","Hadoop",)
# 2.思考: 添加、删除、修改
# source[0] = "黑马" # 不支持修改
# source.ap # 不支持添加
# del source[0] # 不支持删除
# 3.查找
print(source[0])
print(source[1])
# 4.个数
# print(len(source))
# 5.是否存在
print("Hello" in source)
==总结:==
(1)如果要获取元组的元素总个数,可以使用(len())方法;
(2)注意:元组的数据内容常用于查找,比如是否存在元组中、元素所在索引值等。
[掌握]使用for和while遍历元组
==目标:==掌握for和while遍历元组。
先来看看for循环语法:
for 临时变量 in 序列:满足条件时,执行的代码1满足条件时,执行的代码2……
接着,看一下while循环语法:
初始化变量语句 while 循环条件:循环体语句改变循环条件的语句 # 先写
例如,一起来完成:
(1)定义一个元组变量,存放几个知名的手机品牌;
(2)分别使用for和while循环遍历元组数据;
(3)执行程序,观察效果。
# 1.定义元组变量
phone_lists = ("三星","苹果","OPPO","传音","Mi",)
# 2.遍历元组数据
# forfor temp in phone_lists:print(temp)while
index = len(phone_lists)-1
while index >= 0:print(phone_lists[index])index -= 1==总结:==
(1)注意:元组也是序列,因此可以使用循环来处理;
(2)若要遍历元组的数据内容,优先考虑使用()循环:==A、for==;B、while。
[了解]元组的应用场景
==目标:==了解元组的应用场景。
元组的应用场景较多,但都离不开格式【(元素1, 元素2, ...)】。
常见应用场景有:
(1)当要存放一些固定值和内容时,优先考虑使用元组,比如存储黑马程序员、www.itheima.com、法人、注册地址等; (2)格式化符号后使用%百分号连接的()内容,本质上就是一个元组; (3)元组就是:让列表的数据不可以修改、删除、添加,这样可以保护数据安全; (4)Python函数后面的任意多个参数,也是元组形式。
例如,一起来完成:
(1)定义3个变量:姓名、年龄、身高,并使用格式化符号拼接后再输出;
(2)对两个变量a和b进行互换顺序;
(3)执行程序,观察效果。
# 1.定义元组变量
# 2.拼接name = "金臻韬"age = 23height = 175.00print("姓名:%s, 年龄:%d, 身高:%fcm"%(name,age,height))
# 3.互换位置
a = 18
b = 99
# 元组a,b = b,a
(a,b) = (b,a)
# 其他语言: 引入第3方变量temp = aa = bb = temp
# 按位异或a = a ^ b # 位运算 -先把数据转换二进制b = a ^ ba = a ^ b
print(f"a = {a}")
print(f"ab = {b}")==总结:==
(1)元组的主要用途有存储数据、传递元组数据;
(2)注意:在后期使用中,当看到类似【(元素1, 元素2, ...)】的形式时,可以当成是(元组)类型的数据。
字典介绍
[掌握]什么是字典
==目标:==掌握如何定义字典变量。
先来看看现实生活中的字典。我们知道,可以应用字典来查找汉字。

接着,来看看Python中的字典。比如,定义一个本书:
{"name":"新华字典","page":568,"price":46.5}
仔细观察,会发现Python字典需要使用{ }引起来,且元素形式为键值对。
键值对,可以理解为一一对应的关系,即可以通过键找到值。
比如,通过图片网址找到一张图片。
链接:http://5b0988e595225.cdn.sohucs.com/images/20190823/95dd50dcf9fa4547ba4bafdf65f2c74e.jpeg

字典语法:
变量名 = {键1: 值1, 键2: 值2, ...}
说明:
(1)键、值组合在一起,形成了字典的元素;
(2)字典元素的键是唯一的;
(3)字典元素的值可以重复;
(4)可以使用字典存储大量数据。
例如,一起来完成:
(1)定义一个字典变量,存放一个学生的信息:姓名、性别、住址、年龄等;
(2)输出并查看字典变量值与类型;
(3)思考1:若给字典变量存放两个性别信息,会怎样?
(4)思考2:若给字典变量再存放一个薪酬,与年龄值相同,会怎样?
# 1.定义字典变量
student = {"name":"欧阳芝","sex":"女","address":"广东广州","age":16}
# 2.查看类型和变量值print(type(student)) # <class 'dict'>print(student)
# 3.存放两个性别? sex 键唯一?student = {"name":"欧阳芝","sex":"女","address":"广东广州","age":16,"sex":"Female"}print(student) # 键是唯一的,如果有多个相同的键, 最后的键会把前面的键所对应的值都给覆盖了
# 4.value多个student = {"name":"欧阳芝","sex":"女","address":"广东广州","age":16,"salary":16}print(student) # 值可以重复==总结:==
(1)字典与列表类似,都属于可变数据类型,即当添加元素后,长度也跟着变化;
(2)注意:字典的内部元素形式是键值对,且键是唯一的,这句话正确吗?==A、正确==;B、错误。
[掌握]使用字典
==目标:==掌握字典的简单使用。
通常情况下,使用字典的是获取元素键值对的值。
通过键来访问值的方式有两种。方式1:
变量名[键]
当访问不存在的键时,提升稳定性,可使用方式2:
| 函数名 | 含义 |
|---|---|
| get(key[, default]) | 返回指定键key对应的值,若值不在字典中,则返回默认值。 |
例如,一起来完成:
(1)定义一个字典变量,存放一个学生的信息:姓名、住址、年龄等;
(2)分别使用不同方式去获取字典的姓名、住址值;
(3)思考:当访问不存在的性别信息时,会怎样?

# 1.定义变量
student = {"name":"欧阳芝","address":"广东广州","age":16,"sex":"Female"}
# 2.获取值
print(student["name"])
print(student["address"]) # 可以通过键来访问值
# 3.访问不存在的值
# print(student["sex"])
# print(student.get("sex")) # 1. None 2.不报错
# print(student.get("sex","女"))
==总结:==
(1)使用字典时,可以通过键访问值,优先使用【变量名[键]】来访问;
(2)注意:当通过键访问字典的值出错时,可以考虑使用:A、变量名[键];==B、get(键)==。
字典的常见操作
[掌握]添加元素
==目标:==掌握如何给字典添加元素。
添加元素指的是:给字典添加新元素内容。
添加元素语法:
变量名[键] = 值
说明:当要添加多个元素时,则执行多次添加元素的操作。
例如,一起来完成:
(1)定义一个字典变量,存放老师信息:姓名、体重、年龄等;
(2)给老师变量添加一个兴趣爱好;
(3)思考:若给一个空字典添加2个元素,该怎么做?
(4)执行程序,观察效果。
# 1.定义变量
teacher = {"name":"涛哥","weight":95,"age":40}
print(teacher)
# 2.添加一个元素
teacher["gender"] = "男"
print(teacher)
# 3.空字典添加2个元素
# teacher = {}
# teacher["name"] = "方哥"
# teacher["like"] = "爱好工作"
# print(teacher)
# print(type(teacher))==总结:==
(1)当直接给变量内容定义为{ }时,表示是()变量:A、列表;==B、字典==;
(2)注意:字典中的元素不分先后顺序,可任意存储字典的数据。
[了解]删除元素
==目标:==了解如何删除元素。
删除元素指的是:删除字典的某元素,或者清空字典的所有数据。
删除元素方法:
| 函数名 | 含义 |
|---|---|
| del 变量名[键] | 删除指定元素。 |
| clear() | 清空字典的所有元素内容。 |
清空数据的操作,简要来了解一下。
说明:
(1)当要添加新的纯净数据前,要先把原有数据做清空处理;
(2)比如,先搜索酒店、再搜索美食,观察效果链接:百度地图。
例如,一起来完成:
(1)定义一个字典变量,存放老师信息:姓名、体重、年龄等;
(2)试着删除字典的体重元素;
(3)思考:当要给字典变量重新添加数据时,该怎么办?
teacher = {"name":"涛哥","weight":95,"age":40}
# 1.删除体重
del teacher["weight"]
print(teacher)
# 2.重新添加数据
# teacher.clear()
# print(teacher)==总结:==
(1)对于删除字典的元素数据,使用较少,了解即可;
(2)注意:在实际应用中,若需要重新给字典变量添加新数据,建议先使用clear()清空数据。
[掌握]修改元素
==目标:==掌握如何修改字典的元素。
修改元素指的是:对已有元素进行修改,当成功修改后,则会用最新修改的值替换原有值。
修改元素语法:
变量名[键] = 值
例如,一起来完成:
(1)定义一个字典变量,存放老师信息:姓名、体重、年龄等;
(2)修改字典变量的姓名、体重值。
teacher = {"name":"涛哥","weight":95,"age":40}
# 修改姓名
teacher["name"] = "健哥"
# 修改体重
teacher["weight"] = 110
print(teacher)==总结:==
(1)请问:修改和添加字典元素时,都可以采用【变量名[键] = 值】,这句话对吗?A、对;B、错;
(2)注意:修改与添加字典元素的语法一样,要多理解一下应用场景。
[掌握]查找元素
==目标:==掌握如何查找字典的元素值。
查找元素指的是:通过键来访问值。
比如,访问值的方式有两种:
变量名[键]
| 函数名 | 含义 |
|---|---|
| get(key[, default]) | 返回指定键key对应的值,若值不在字典中,则返回默认值。 |
例如,一起来完成:
(1)定义一个字典变量,存放老师信息:姓名、体重、年龄等;
(2)使用两种方式来查看老师的姓名、年龄。
teacher = {"name":"涛哥","weight":95,"age":40}
print(teacher["name"])
print(teacher.get("age")) # 若报错,则优先考虑使用get()==总结:==
(1)为了提升查找字典元素值的稳定性,可以考虑使用()方法:==A、get()==;B、变量名[键]。
生成验证码案例
==目标:==完成生成验证码的案例。
现实生活中,登录APP时,经常要进行验证码识别,比如:

说明:
(1)验证码可以使用字符串 + 循环语句来生成;
(2)仅需将多个动态生成的数字执行拼接处理,即可生成验证码。
例如,一起来完成:
(1)请生成一个由数字、字母组成的6位数的验证码;
(2)文本内容:【抖音】验证码2943AD,用于手机验证码登录,5分钟内有效。验证码提供给他人可能导致账号被盗,请勿泄露,谨防被骗。
import random
# 1.先要有批量文本内容 数字、字母
strs = "0123456789ABCDECGHIJKLMNOPQRSTUVWXYZabcdecghijklmnopqrstuvwxyz"
code = ""
# 2.for循环
for temp in range(6):# 3.动态获取字母或数字 + 拼接index = random.randint(0,len(strs)-1)text = strs[index]# print(text)# 4.生成了验证码code += text
# print(code)
message = f"【抖音】验证码{code},用于手机验证码登录,5分钟内有效。验证码提供给他人可能导致账号被盗,请勿泄露,谨防被骗。"
print(message)相关文章:
python 字符串(str)、列表(list)、元组(tuple)、字典(dict)
学习目标: 1:能够知道如何定义一个字符串; [重点] 使用双引号引起来: 变量名 "xxxx" 2:能够知道切片的语法格式; [重点] [起始: 结束] 3:掌握如何定义一个列表; [重点] 使用[ ]引起来: 变量名 [xx,xx,...] 4:能够说出4个列表相关的方法; [了解] ap…...

【源码】SpringBoot事务注册原理
前言 对于数据库的操作,可能存在脏读、不可重复读、幻读等问题,从而引入了事务的概念。 事务 1.1 事务的定义 事务是指在数据库管理系统中,一系列紧密相关的操作序列,这些操作作为一个单一的工作单元执行。事务的特点是要么全…...

技巧:合并ZIP分卷压缩包
如果ZIP压缩文件文件体积过大,大家可能会选择“分卷压缩”来压缩ZIP文件,那么,如何合并zip分卷压缩包呢?今天我们分享两个ZIP分卷压缩包合并的方法给大家。 方法一: 我们可以将分卷压缩包,通过解压的方式…...
数据挖掘 | 实验三 决策树分类算法
文章目录 一、目的与要求二、实验设备与环境、数据三、实验内容四、实验小结 一、目的与要求 1)熟悉决策树的原理; 2)熟练使用sklearn库中相关决策树分类算法、预测方法; 3)熟悉pydotplus、 GraphViz等库中决策树模型…...

Python机器学习预测区间估计工具库之mapie使用详解
概要 在数据科学和机器学习领域,预测的不确定性估计是一个非常重要的课题。Python的mapie库是一种专注于预测区间估计的工具,旨在提供简单易用的接口来计算和评估预测的不确定性。通过mapie库,用户可以为各种回归和分类模型计算预测区间,从而更好地理解模型预测的可靠性。…...

Linux基础指令磁盘管理002
LVM(Logical Volume Manager)是Linux系统中一种灵活的磁盘管理和存储解决方案,它允许用户在物理卷(Physical Volumes, PV)上创建卷组(Volume Groups, VG),然后在卷组上创建逻辑卷&am…...

Python怎么添加库:深入解析与操作指南
Python怎么添加库:深入解析与操作指南 在Python编程中,库(Library)扮演着至关重要的角色。它们为我们提供了大量的函数、类和模块,使得我们可以更高效地编写代码,实现各种功能。那么,Python如何…...

Python | 虚拟环境的增删改查
mkvirtualenv创建虚拟环境 mkvirtualenv是用于在Pyhon中创建虚拟环境的命令。它通过使用vitualenv库来创建一个隔离的Python环境,以便您可以安装特定版本的Python包,而不会影响全局Python环境。 使用方法: 安装virtualenv:pip install vir…...

【MySQL数据库】:MySQL内外连接
目录 内外连接和多表查询的区别 内连接 外连接 左外连接 右外连接 简单案例 内外连接和多表查询的区别 在 MySQL 中,内连接是多表查询的一种方式,但多表查询包含的范围更广泛。外连接也是多表查询的一种具体形式,而多表查询是一个更…...

C# FTP/SFTP 详解及连接 FTP/SFTP 方式示例汇总
文章目录 1、FTP/SFTP基础知识FTPSFTP 2、FTP连接示例3、SFTP连接示例4、总结 在软件开发中,文件传输是一个常见的需求。尤其是在不同的服务器之间传输文件时,FTP(文件传输协议)和SFTP(安全文件传输协议)成…...

二、【源码】实现映射器的注册和使用
源码地址:https://github.com/mybatis/mybatis-3/ 仓库地址:https://gitcode.net/qq_42665745/mybatis/-/tree/02-auto-registry-proxy 实现映射器的注册和使用 这一节的目的主要是实现自动注册映射器工厂 流程: 1.创建MapperRegistry注册…...
Android Compose 十:常用组件列表 监听
1 去掉超出滑动区域时的拖拽的阴影 即 overScrollMode 代码如下 CompositionLocalProvider(LocalOverscrollConfiguration provides null) {LazyColumn() {items(list, key {list.indexOf(it)}){Row(Modifier.animateItemPlacement(tween(durationMillis 250))) {Text(text…...
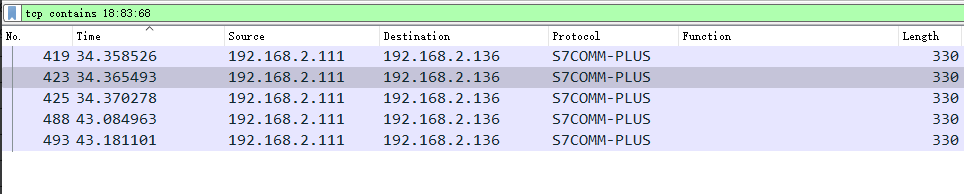
Wireshark 如何查找包含特定数据的数据帧
1、查找包含特定 string 的数据帧 使用如下指令: 双引号中所要查找的字符串 frame contains "xxx" 查找字符串 “heartbeat” 示例: 2、查找包含特定16进制的数据帧 使用如下指令: TCP:在TCP流中查找 tcp contai…...
【深度学习入门篇一】阿里云服务器(不需要配环境直接上手跟学代码)
前言 博主刚刚开始学深度学习,配环境配的心力交瘁,一塌糊涂,不想配环境的刚入门的同伴们可以直接选择阿里云服务器 阿里云天池实验室,在入门阶段跑个小项目完全没有问题,不要自己傻傻的在那配环境配了半天还不匹配&a…...

app,waf笔记
API攻防 知识点: 1、HTTP接口类-测评 2、RPC类接口-测评 3、Web Service类-测评 内容点: SOAP(Simple Object Access Protocol)简单对象访问协议是交换数据的一种协议规范,是一种轻量级的、简单的、基于XML&#…...

数据仓库之维度建模
维度建模(Dimensional Modeling)是一种用于数据仓库设计的方法,旨在优化查询性能并提高数据的可读性。它通过组织数据为事实表和维度表的形式,提供直观的、易于理解的数据模型,使业务用户能够轻松地进行数据分析和查询…...

解决远程服务器连接报错
最近使用服务器进行数据库连接和使用的时候出现了一个报错: Error response from daemon: Conflict. The container name “/mysql” is already in use by container “1bd3733123219372ea7c9377913da661bb621156d518b0306df93cdcceabb8c4”. You have to remove …...

通过电脑查看Wi-Fi密码的方法,提供三种方式
式一: 右击桌面右下角的网络图标,依次选择【网络和Internet设置】、【WLAN】、【网络和共享中心】。点击已连接的无线网络。依次点击【无线属性】、【安全】,勾选下方【显示字符】即可。 方式二: 在开始菜单输入“cmd”进入命令…...
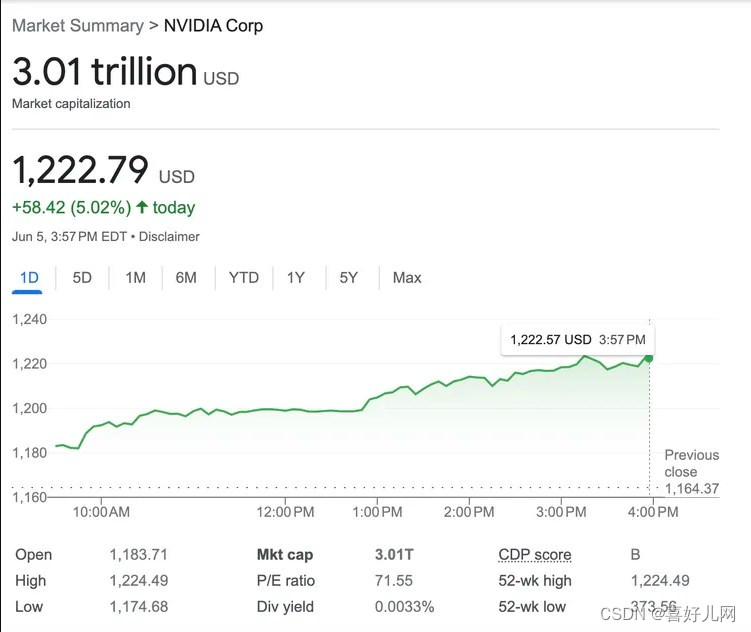
Nvidia 目前的市值为 3.01 万亿美元,超过苹果Apple
人工智能的繁荣将英伟达的市值推高到足以使其成为全球第二大最有价值的公司。 英伟达已成为全球第二大最有价值的公司。周三下午,这家芯片制造巨头的市值达到 3.01 万亿美元,领先于苹果公司的 3 万亿美元。 喜好儿网AIGC专区:https://heehe…...

用langchain搭配最新模型ollama打造属于自己的gpt
langchain 前段时间去玩了一下langchain,熟悉了一下大模型的基本概念,使用等。前段时间meta的ollama模型发布了3.0,感觉还是比较强大的,在了解过后,自己去用前后端代码,调用ollama模型搭建了一个本地的gpt应用。 核心逻辑 开始搭…...

从架构视角理解OBS虚拟摄像头:技术设计与实践路径
从架构视角理解OBS虚拟摄像头:技术设计与实践路径 【免费下载链接】obs-virtual-cam obs-studio plugin to simulate a directshow webcam 项目地址: https://gitcode.com/gh_mirrors/ob/obs-virtual-cam OBS VirtualCam是一个基于DirectShow技术框架的OBS S…...

工业 AI Agent 落地全解:制造业智能化转型的技术架构与场景实践
2025 年被行业称为 AI Agent 元年,Gartner 将 Agentic AI 列为 2025 年顶级技术趋势首位。在智能制造加速推进的背景下,AI Agent 技术正成为破解制造业 AI 落地难、价值转化慢的核心抓手,实现从技术 Demo 到产线落地的跨越,真正融…...

千问3.5-2B应用场景:高校实验报告图解、科研论文插图说明生成、技术文档辅助
千问3.5-2B应用场景:高校实验报告图解、科研论文插图说明生成、技术文档辅助 1. 千问3.5-2B模型简介 千问3.5-2B是Qwen系列中的小型视觉语言模型,专为图片理解与文本生成任务设计。这个模型的核心能力在于:你上传一张图片,再输入…...

抖音无水印视频下载全攻略:从技术突破到行业落地的实战指南
抖音无水印视频下载全攻略:从技术突破到行业落地的实战指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback …...

QWEN-AUDIO功能全解析:声波可视化、情感指令、四种人声,到底怎么用?
QWEN-AUDIO功能全解析:声波可视化、情感指令、四种人声,到底怎么用? 1. 认识QWEN-AUDIO语音合成系统 QWEN-AUDIO是一款基于Qwen3-Audio架构构建的智能语音合成系统,它能够将文字转换成带有情感和温度的自然语音。这个系统最特别…...

FireRedASR Pro长音频处理优化方案:基于LSTM的流式识别
FireRedASR Pro长音频处理优化方案:基于LSTM的流式识别 你有没有遇到过这样的场景?一场长达两小时的会议录音,或者一堂干货满满的讲座,想要把它转成文字,结果发现要么是软件直接卡死,要么就是识别出来的文…...

Polar编码在UCI传输中的关键技术与实现细节
1. Polar编码在UCI传输中的核心作用 当我们需要在5G网络的PUSCH信道上传输UCI(上行控制信息)时,如果信息量超过12比特,Polar编码就成为了标准化的编码方案。这种编码方式之所以被选中,是因为它在短码和中长码场景下都能…...

Linux文件名修改方法大全
在Linux系统中,文件名修改是一个常见且重要的操作。文件名修改可以更好地管理文件和文件夹,使其更具可读性和有序性。通过更改文件名,可以清晰地表达文件的内容和用途,便于快速识别和定位文件。此外,对文件名进行调整还…...

Qwen3-TTS声音克隆实战:3秒复制你的声音,Unity游戏角色秒变话痨
Qwen3-TTS声音克隆实战:3秒复制你的声音,Unity游戏角色秒变话痨 1. 引言:当游戏角色学会"说话" 想象一下这样的场景:你正在开发的RPG游戏中,玩家可以上传自己的声音样本,然后所有NPC都会用玩家…...

物联网毕业设计本科生开题指导
【单片机毕业设计项目分享系列】 🔥 这里是DD学长,单片机毕业设计及享100例系列的第一篇,目的是分享高质量的毕设作品给大家。 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的单片机项目缺少创新和亮点…...