【深度学习】温故而知新4-手写体识别-多层感知机+CNN网络-完整代码-可运行
多层感知机版本
import torch
import torch.nn as nn
import numpy as np
import torch.utils
from torch.utils.data import DataLoader, Dataset
import torchvision
from torchvision import transforms
import matplotlib.pyplot as plt
import matplotlib
import os
# 前置配置:
matplotlib.use('Agg')
class Config():base_dir = os.path.dirname(os.path.abspath(__file__))device = "cuda" if torch.cuda.is_available() else "cpu"# 超参配置: batch_size=128lr=0.0001
# 数据集初步加工
train_ds = torchvision.datasets.MNIST(os.path.join(Config.base_dir,"data"),train=True,download=False,transform=transforms.ToTensor())
test_ds = torchvision.datasets.MNIST(os.path.join(Config.base_dir,"data"),train=False,download=False,transform=transforms.ToTensor())
# 生成dataLoader
train_dl = DataLoader(train_ds,batch_size=Config.batch_size,shuffle=True)
test_dl = DataLoader(test_ds,batch_size=Config.batch_size)def show_pic_and_label():# 查看dataloaderprint(len(train_dl.dataset))# 查看 它的img 和 labelimgs, labels = next(iter(train_dl))# print(imgs, labels)sample_img = imgs[0:10]sample_label = labels[0:10]print(sample_img,sample_label)for idx,npimg in enumerate(sample_img,1):# plt.subplot()# 也可以挤一挤npimg = npimg.squeeze()# npimg = npimg.reshape(28,28)plt.subplot(1,10,idx)plt.imshow(npimg)plt.axis('off')plt.savefig(os.path.join(Config.base_dir,"1.jpg"))print(sample_label)
# 构建模型
class Model(nn.Module):def __init__(self):super().__init__()# 第一层 28*28, 120self.liner1 = nn.Linear(28*28,120)# 第二层 输出84self.liner2 = nn.Linear(120, 84)# 第三层 输出10self.liner3 = nn.Linear(84,10)def forward(self, input):x = input.view(-1,28*28)# @todo 这里踩坑了,不是nn.ReLU, 而是torch.ReLux = torch.relu(self.liner1(x))x = torch.relu(self.liner2(x))x = self.liner3(x)return xmodel = Model().to(Config.device)
# print(model)
optim = torch.optim.Adam(model.parameters(), lr = Config.lr)loss_fn = nn.CrossEntropyLoss()def model_test():"""确认输入输出是没问题的。"""res = model(torch.randn(10,28*28).to(Config.device))print(res.shape)print(res)
def accuracy(y_pred,y_true):y_pred = (torch.argmax(y_pred,dim=1) == y_true).type(torch.int64)return y_pred.sum()
# 编写训练过程
def train(dataloader, model, loss_fn, optimizer):total_row_count = len(dataloader.dataset)total_batch_count = len(dataloader)total_acc = 0total_loss = 0for X,y in dataloader:X,y = X.to(Config.device),y.to(Config.device)y_pred = model(X)acc = accuracy(y_pred,y)loss = loss_fn(y_pred,y)optimizer.zero_grad()loss.backward()optimizer.step()with torch.no_grad():total_acc+=acctotal_loss+=losstotal_acc = total_acc/total_row_counttotal_loss = total_loss/total_batch_countreturn total_loss, total_acc# 编写测试过程
def test(dataloader, model, loss_fn):total_row_count = len(dataloader.dataset)total_batch_count = len(dataloader)total_acc = 0total_loss = 0with torch.no_grad():for X,y in dataloader:X,y = X.to(Config.device),y.to(Config.device)y_pred = model(X)acc = accuracy(y_pred,y)loss = loss_fn(y_pred,y)total_acc+=acctotal_loss+=losstotal_acc = total_acc/total_row_counttotal_loss = total_loss/total_batch_countreturn total_loss, total_accepochs = 50
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):epoch_loss, epoch_acc = train(train_dl,model,loss_fn,optim)epoch_test_loss, epoch_test_acc = test(test_dl,model,loss_fn)template = "epoch:{:2d}, train_loss:{:.5f}, train_acc:{:.1f}%, test_loss:{:.5f},test_acc:{:.1f}%"print(template.format(epoch, epoch_loss.data.item(), epoch_acc.data.item()*100, epoch_test_loss.data.item(), epoch_test_acc.data.item()*100))#print(epoch, epoch_loss.data.item(),epoch_acc.data.item(),epoch_test_loss.data.item(),epoch_test_acc.data.item())
if __name__ == "__main__":# model_test()pass# y_pred = torch.tensor([# [1,2,3],# [2,1,3],# [3,2,1],# ])# y_true = torch.tensor([2,0,1])# res = accuracy(y_pred,y_true)# print(res)
(pytorchbook) (base) justin@justin-System-Product-Name:~/Desktop/code/python_project/mypaper$ /home/justin/miniconda3/envs/pytorchbook/bin/python /home/justin/Desktop/code/python_project/mypaper/pytorchbook/chapter4/手写体识别.py
epoch: 0, train_loss:1.17435, train_acc:70.1%, test_loss:0.47829,test_acc:88.7%
epoch: 1, train_loss:0.39913, train_acc:89.5%, test_loss:0.33029,test_acc:91.0%
epoch: 2, train_loss:0.31837, train_acc:91.1%, test_loss:0.28821,test_acc:91.8%
epoch: 3, train_loss:0.28331, train_acc:92.0%, test_loss:0.26157,test_acc:92.5%
epoch: 4, train_loss:0.26049, train_acc:92.5%, test_loss:0.24704,test_acc:93.1%
epoch: 5, train_loss:0.24122, train_acc:93.1%, test_loss:0.22766,test_acc:93.4%
epoch: 6, train_loss:0.22516, train_acc:93.6%, test_loss:0.21446,test_acc:93.7%
epoch: 7, train_loss:0.21048, train_acc:94.0%, test_loss:0.20211,test_acc:94.2%
epoch: 8, train_loss:0.19786, train_acc:94.4%, test_loss:0.19200,test_acc:94.5%
epoch: 9, train_loss:0.18692, train_acc:94.6%, test_loss:0.18458,test_acc:94.7%
epoch:10, train_loss:0.17689, train_acc:95.0%, test_loss:0.17440,test_acc:94.9%
epoch:11, train_loss:0.16766, train_acc:95.2%, test_loss:0.16584,test_acc:95.0%
epoch:12, train_loss:0.15932, train_acc:95.5%, test_loss:0.16011,test_acc:95.3%
epoch:13, train_loss:0.15149, train_acc:95.7%, test_loss:0.15269,test_acc:95.5%
epoch:14, train_loss:0.14443, train_acc:95.9%, test_loss:0.14685,test_acc:95.5%
epoch:15, train_loss:0.13801, train_acc:96.0%, test_loss:0.14179,test_acc:95.7%
epoch:16, train_loss:0.13172, train_acc:96.2%, test_loss:0.13724,test_acc:95.8%
epoch:17, train_loss:0.12594, train_acc:96.3%, test_loss:0.13256,test_acc:96.1%
epoch:18, train_loss:0.12016, train_acc:96.5%, test_loss:0.13012,test_acc:96.1%
epoch:19, train_loss:0.11557, train_acc:96.7%, test_loss:0.12416,test_acc:96.2%
epoch:20, train_loss:0.11037, train_acc:96.8%, test_loss:0.12220,test_acc:96.4%
epoch:21, train_loss:0.10601, train_acc:97.0%, test_loss:0.11851,test_acc:96.5%
epoch:22, train_loss:0.10160, train_acc:97.1%, test_loss:0.11445,test_acc:96.6%
epoch:23, train_loss:0.09774, train_acc:97.2%, test_loss:0.11242,test_acc:96.5%
epoch:24, train_loss:0.09388, train_acc:97.3%, test_loss:0.10876,test_acc:96.6%
epoch:25, train_loss:0.09008, train_acc:97.4%, test_loss:0.10713,test_acc:96.7%
epoch:26, train_loss:0.08692, train_acc:97.5%, test_loss:0.10526,test_acc:96.7%
epoch:27, train_loss:0.08370, train_acc:97.6%, test_loss:0.10490,test_acc:96.8%
epoch:28, train_loss:0.08067, train_acc:97.7%, test_loss:0.10183,test_acc:96.8%
epoch:29, train_loss:0.07805, train_acc:97.7%, test_loss:0.10172,test_acc:96.9%
epoch:30, train_loss:0.07480, train_acc:97.8%, test_loss:0.09779,test_acc:97.0%
epoch:31, train_loss:0.07235, train_acc:97.8%, test_loss:0.09650,test_acc:97.0%
epoch:32, train_loss:0.06958, train_acc:98.0%, test_loss:0.09472,test_acc:97.1%
epoch:33, train_loss:0.06747, train_acc:98.0%, test_loss:0.09349,test_acc:97.1%
epoch:34, train_loss:0.06504, train_acc:98.1%, test_loss:0.09270,test_acc:97.1%
epoch:35, train_loss:0.06236, train_acc:98.2%, test_loss:0.09221,test_acc:97.2%
epoch:36, train_loss:0.06039, train_acc:98.3%, test_loss:0.09187,test_acc:97.2%
epoch:37, train_loss:0.05850, train_acc:98.3%, test_loss:0.08917,test_acc:97.3%
epoch:38, train_loss:0.05624, train_acc:98.4%, test_loss:0.08657,test_acc:97.3%
epoch:39, train_loss:0.05456, train_acc:98.4%, test_loss:0.08722,test_acc:97.4%
epoch:40, train_loss:0.05246, train_acc:98.5%, test_loss:0.08660,test_acc:97.4%
epoch:41, train_loss:0.05088, train_acc:98.5%, test_loss:0.08511,test_acc:97.4%
epoch:42, train_loss:0.04919, train_acc:98.6%, test_loss:0.08628,test_acc:97.4%
epoch:43, train_loss:0.04726, train_acc:98.7%, test_loss:0.08620,test_acc:97.4%
epoch:44, train_loss:0.04571, train_acc:98.7%, test_loss:0.08298,test_acc:97.5%
epoch:45, train_loss:0.04408, train_acc:98.8%, test_loss:0.08309,test_acc:97.5%
epoch:46, train_loss:0.04274, train_acc:98.8%, test_loss:0.08241,test_acc:97.5%
epoch:47, train_loss:0.04122, train_acc:98.9%, test_loss:0.08229,test_acc:97.6%
epoch:48, train_loss:0.03967, train_acc:98.9%, test_loss:0.08120,test_acc:97.6%
epoch:49, train_loss:0.03829, train_acc:99.0%, test_loss:0.08134,test_acc:97.5%
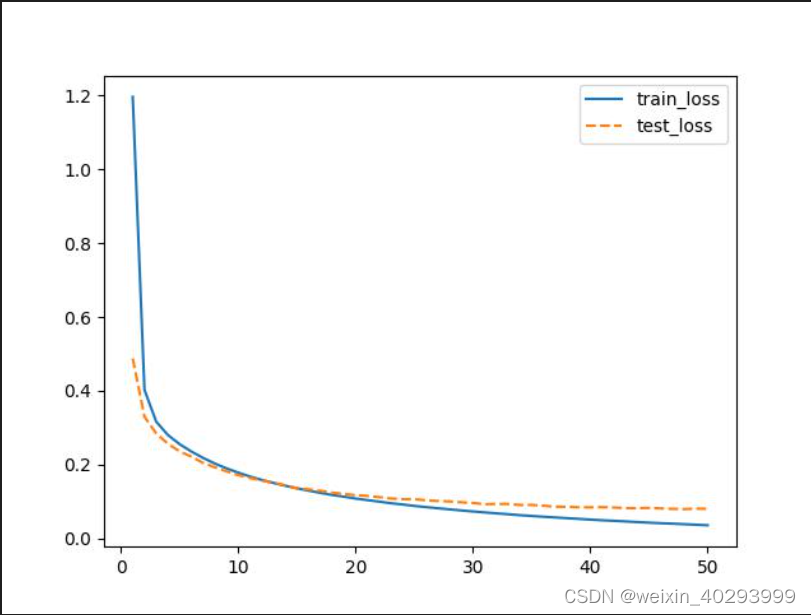
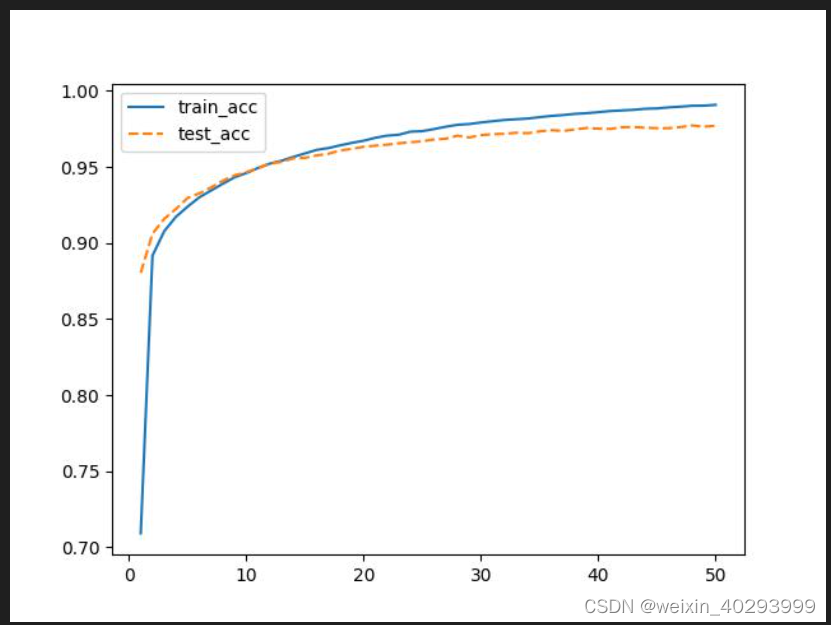
问题1:
epoch: 0, train_loss:1.17435, train_acc:70.1%, test_loss:0.47829,test_acc:88.7%
为什么第一轮训练train_acc要比test_acc掉点不少,是因为第一轮,是刚开始,train按批次比完了,才会到test。因此test是高
那么为什么其它轮,又是test比train低呢?
因为即使train是按批次的,但仍然有可能过拟合,契合的好。所以test是比不过的。
CNN版本
只需要将model换一下,其它的毛也不需要动
class Model(nn.Module):def __init__(self) -> None:super().__init__()self.conv1 = nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5) # 1X28X28 --> 6X24X24 # 池化 6X12X12self.conv2 = nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5) # 6X12X12--> 16X8X8# 池化 16X4X4 self.liner_1 = nn.Linear(16*4*4,256)self.liner_2 = nn.Linear(256,10)def forward(self,input):x = torch.max_pool2d(torch.relu(self.conv1(input)),2)x = torch.max_pool2d(torch.relu(self.conv2(x)),2)# 展平层x = x.view(-1, 16*4*4)x = torch.relu(self.liner_1(x))x = self.liner_2(x)return x# 这里是在学习一种调试的方式
class _Model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)def forward(self, input):a1 = self.conv1(input)a2 = F.max_pool2d(a1,2)a3 = self.conv2(a2)a4 = F.max_pool2d(a3,2)# print()
epoch: 0, train_loss:1.13144, train_acc:74.3%, test_loss:0.36698,test_acc:90.6%
epoch: 1, train_loss:0.30213, train_acc:91.6%, test_loss:0.22672,test_acc:93.5%
epoch: 2, train_loss:0.21874, train_acc:93.7%, test_loss:0.17848,test_acc:94.9%
epoch: 3, train_loss:0.17849, train_acc:94.8%, test_loss:0.14941,test_acc:95.4%
epoch: 4, train_loss:0.15203, train_acc:95.5%, test_loss:0.12645,test_acc:96.2%
epoch: 5, train_loss:0.13339, train_acc:96.1%, test_loss:0.11351,test_acc:96.5%
epoch: 6, train_loss:0.11952, train_acc:96.5%, test_loss:0.09954,test_acc:96.9%
epoch: 7, train_loss:0.10876, train_acc:96.7%, test_loss:0.09198,test_acc:97.3%
epoch: 8, train_loss:0.09943, train_acc:97.1%, test_loss:0.08412,test_acc:97.3%
epoch: 9, train_loss:0.09255, train_acc:97.2%, test_loss:0.07788,test_acc:97.6%
epoch:10, train_loss:0.08576, train_acc:97.4%, test_loss:0.07551,test_acc:97.6%
epoch:11, train_loss:0.08089, train_acc:97.5%, test_loss:0.06757,test_acc:97.9%
epoch:12, train_loss:0.07635, train_acc:97.7%, test_loss:0.06399,test_acc:98.0%
epoch:13, train_loss:0.07175, train_acc:97.8%, test_loss:0.05942,test_acc:98.1%
epoch:14, train_loss:0.06862, train_acc:97.9%, test_loss:0.05657,test_acc:98.2%
epoch:15, train_loss:0.06509, train_acc:98.0%, test_loss:0.05776,test_acc:98.1%
epoch:16, train_loss:0.06273, train_acc:98.1%, test_loss:0.05381,test_acc:98.3%
epoch:17, train_loss:0.05940, train_acc:98.2%, test_loss:0.05134,test_acc:98.4%
epoch:18, train_loss:0.05681, train_acc:98.3%, test_loss:0.05330,test_acc:98.2%
epoch:19, train_loss:0.05434, train_acc:98.4%, test_loss:0.04689,test_acc:98.6%
epoch:20, train_loss:0.05175, train_acc:98.5%, test_loss:0.04500,test_acc:98.6%
epoch:21, train_loss:0.05027, train_acc:98.6%, test_loss:0.04645,test_acc:98.5%
epoch:22, train_loss:0.04849, train_acc:98.6%, test_loss:0.04274,test_acc:98.7%
epoch:23, train_loss:0.04600, train_acc:98.6%, test_loss:0.04739,test_acc:98.5%
epoch:24, train_loss:0.04449, train_acc:98.7%, test_loss:0.04360,test_acc:98.7%
epoch:25, train_loss:0.04359, train_acc:98.7%, test_loss:0.04198,test_acc:98.7%
epoch:26, train_loss:0.04115, train_acc:98.8%, test_loss:0.04209,test_acc:98.7%
epoch:27, train_loss:0.03978, train_acc:98.8%, test_loss:0.04147,test_acc:98.7%
epoch:28, train_loss:0.03866, train_acc:98.9%, test_loss:0.03845,test_acc:98.8%
epoch:29, train_loss:0.03721, train_acc:98.9%, test_loss:0.04142,test_acc:98.7%
epoch:30, train_loss:0.03632, train_acc:98.9%, test_loss:0.03916,test_acc:98.8%
epoch:31, train_loss:0.03525, train_acc:98.9%, test_loss:0.04137,test_acc:98.7%
epoch:32, train_loss:0.03364, train_acc:99.0%, test_loss:0.03829,test_acc:98.8%
epoch:33, train_loss:0.03323, train_acc:99.0%, test_loss:0.04090,test_acc:98.7%
epoch:34, train_loss:0.03179, train_acc:99.0%, test_loss:0.03660,test_acc:98.9%
epoch:35, train_loss:0.03125, train_acc:99.1%, test_loss:0.03698,test_acc:98.9%
epoch:36, train_loss:0.03009, train_acc:99.1%, test_loss:0.03624,test_acc:98.8%
epoch:37, train_loss:0.02958, train_acc:99.1%, test_loss:0.03525,test_acc:98.9%
epoch:38, train_loss:0.02902, train_acc:99.1%, test_loss:0.03705,test_acc:98.9%
epoch:39, train_loss:0.02789, train_acc:99.2%, test_loss:0.03579,test_acc:98.9%
epoch:40, train_loss:0.02741, train_acc:99.2%, test_loss:0.03896,test_acc:98.9%
epoch:41, train_loss:0.02604, train_acc:99.2%, test_loss:0.03572,test_acc:98.9%
epoch:42, train_loss:0.02518, train_acc:99.2%, test_loss:0.03741,test_acc:98.7%
epoch:43, train_loss:0.02471, train_acc:99.3%, test_loss:0.03319,test_acc:98.9%
epoch:44, train_loss:0.02413, train_acc:99.3%, test_loss:0.03753,test_acc:98.8%
epoch:45, train_loss:0.02340, train_acc:99.3%, test_loss:0.03333,test_acc:98.9%
epoch:46, train_loss:0.02272, train_acc:99.3%, test_loss:0.03303,test_acc:99.0%
epoch:47, train_loss:0.02188, train_acc:99.3%, test_loss:0.03451,test_acc:98.9%
epoch:48, train_loss:0.02169, train_acc:99.4%, test_loss:0.03433,test_acc:98.9%
epoch:49, train_loss:0.02068, train_acc:99.4%, test_loss:0.03331,test_acc:98.9%
对比一下 cnn的到了98.9,而mlp的只有97.x
函数式API的调用方式
import torch.nn.functional as F
# 这里是在学习一种调试的方式
class _Model(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)def forward(self, input):a1 = self.conv1(input)a2 = F.max_pool2d(a1,2)a3 = self.conv2(a2)a4 = F.max_pool2d(a3,2)# print()class Model1(nn.Module):def __init__(self) -> None:super().__init__()self.conv1 = nn.Conv2d(in_channels=1,out_channels=6,kernel_size=5) # 1X28X28 --> 6X24X24 # 池化 6X12X12self.conv2 = nn.Conv2d(in_channels=6,out_channels=16,kernel_size=5) # 6X12X12--> 16X8X8# 池化 16X4X4 self.liner_1 = nn.Linear(16*4*4,256)self.liner_2 = nn.Linear(256,10)def forward(self,input):x = F.max_pool2d(F.relu(self.conv1(input)),2)x = F.max_pool2d(F.relu(self.conv2(x)),2)# 展平层x = x.view(-1, 16*4*4)x = F.relu(self.liner_1(x))x = self.liner_2(x)return x
相关文章:
【深度学习】温故而知新4-手写体识别-多层感知机+CNN网络-完整代码-可运行
多层感知机版本 import torch import torch.nn as nn import numpy as np import torch.utils from torch.utils.data import DataLoader, Dataset import torchvision from torchvision import transforms import matplotlib.pyplot as plt import matplotlib import os # 前…...

ChatGPT 论文翻译指南!解锁高质量翻译的秘密!
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …...
SQLserver通过CLR调用TCP接口
一、SQLserver启用CLR 查看是否开启CRL,如果run_value1,则表示开启 EXEC sp_configure clr enabled; GO RECONFIGURE; GO如果未启用,则执行如下命令启用CLR sp_configure clr enabled, 1; GO RECONFIGURE; GO二、创建 CLR 程序集 创建新项…...
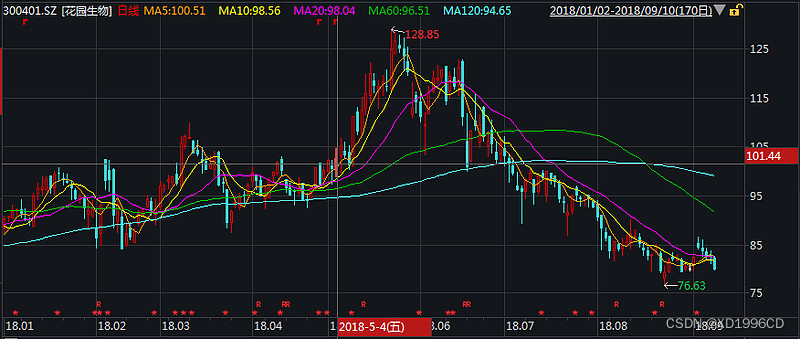
前复权、后复权,技术分析看哪个?价值投资呢?
先说结论, 前复权可以实现技术指标的连续性,适合技术分析, 后复权可以实现股价走势的连续性,适合价值投资者 从头来说,一家公司盈利后,可以选择用盈利购买新的生产设备或者拓展生产,但是…...

Python正则表达式:深度解析URL匹配与操作
Python正则表达式:深度解析URL匹配与操作 在Python编程中,正则表达式(Regular Expression,简称regex或regexp)是一种强大的文本处理工具,它可以帮助我们快速匹配、查找、替换复杂的文本模式。在处理URL&am…...

[C][数据结构][顺序表]详细讲解+实现
目录 1.线性表2.顺序表 - SeqList3.实现4.顺序表缺点 1.线性表 线性表(linear list)是n个具有相同特性的数据元素的有限序列线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串…线性表在逻辑上是线性结构࿰…...

vscode运行Java utf-8文件中文乱码报错
问题现象 vscode 运行utf-8 java文,爆出如下错误 hello.java:5: ����: ����GBK�IJ���ӳ���ַ&a…...

Mybatis杂记
group by查询返回map类型 1,2 List<Map<String, Object>> getCount();xml: <select id"getCount" resultType"java.util.HashMap">SELECT company_id, ifnull(sum(count_a count_b),0) ctFROM test.com_countWHERE is_del 0 GROUP BY…...

修改缓存供应商--EhCache
除了我们默认的缓存形式simlpe之外, 我们其实还有许多其他种类的缓存供应 Ehcache就是其中的一种形式 Ehcache在SpringBoot当中的使用: 其实跟我们之前整合第三方的资源是一样的形式 1>导入依赖: <!-- 更换缓存, 将默认使用的 Simple 更换为Ehcache--> <depe…...
20240606更新Toybrick的TB-RK3588开发板在Android12下的内核
20240606更新Toybrick的TB-RK3588开发板在Android12下的内核 2024/6/6 10:51 0、整体编译: 1、cat android12-rk-outside.tar.gz* | tar -xzv 2、cd android12 3、. build/envsetup.sh 4、lunch rk3588_s-userdebug 5、./build.sh -AUCKu -d rk3588-toybrick-x0-a…...

x264 参考帧管理源码分析
x264参考帧管理 在x264中,参考帧的管理是一个重要的组成部分,因为它涉及到视频编码过程中的帧间预测。以下是关于x264参考帧管理的一些关键点: 参考帧的分类:在x264中,帧可以分为几类,包括参考帧、当前编码帧和未使用帧等。 参考帧的作用:参考帧用于帧间预测,通过比较当…...
大语言模型应用与传统程序的不同
大语言模型(LLM) 被描述的神乎其神,无所不能,其实,大语言模型只是一个模型,它能够理解和生成自然语言,唯有依靠应用程序才能够发挥作用。例如,基于大模型可以构建一个最简单的会话机…...

MySQL换路径(文件夹)
#MySQL作为免费数据库很受欢迎,即使公司没有使用,自己也可以用。它是一个服务,在点击CtrlAltDelete选择任务管理器后,它在服务那个归类里。 经常整理计算机磁盘分类的小伙伴,如果你们安装了MySQL,并且想移…...

企业诚信管理:构建顾客忠诚的高性价比之道
在当今竞争激烈的市场环境中,企业若想脱颖而出,赢得顾客的长期青睐,必须找到一种高效且高性价比的策略来维系顾客忠诚。售后服务作为这种策略的核心,不仅解决了顾客在购买后的各种问题,还在无形中提升了顾客对品牌的信…...
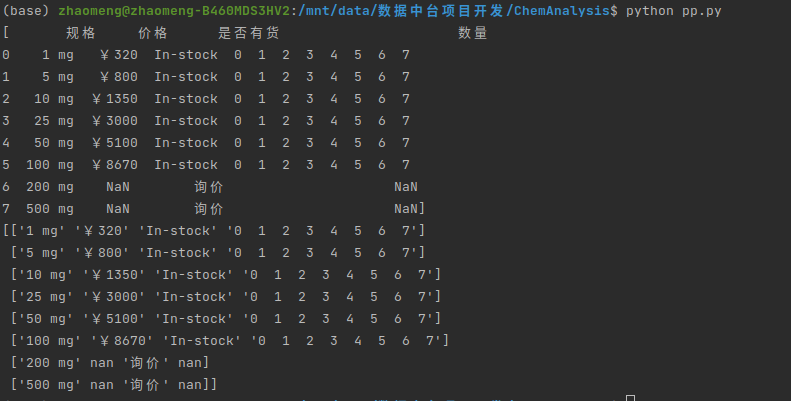
如何利用pandas解析html的表格数据
如何利用pandas解析html的表格数据 我们在编写爬虫的过程中,经常使用的就是parsel、bs4、pyquery等解析库。在博主的工作中经常的需要解析表格形式的html页面,常规的写法是,解析table表格th作为表头,解析td标签作为表格的行数据 …...
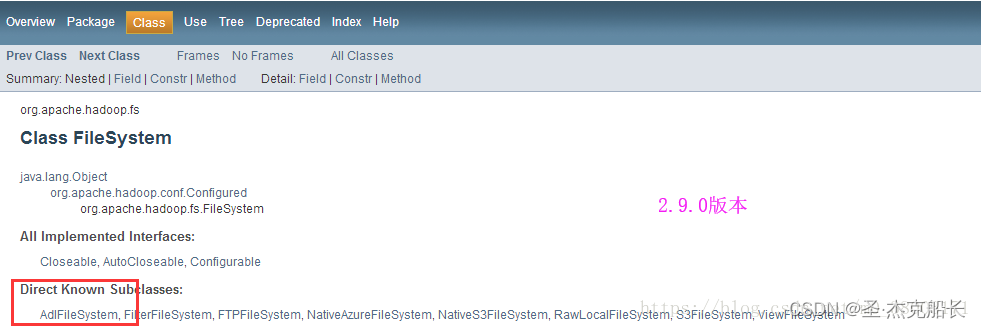
hadoop疑难问题解决_NoClassDefFoundError: org/apache/hadoop/fs/adl/AdlFileSystem
1、问题描述 impala执行查询:select * from stmta_raw limit 10; 报错信息如下: Query: select * from sfmta_raw limit 10 Query submitted at: 2018-04-11 14:46:29 (Coordinator: http://mrj001:25000) ERROR: AnalysisException: Failed to load …...

文件传输基础——Java IO流
系列文章目录 文章目录 系列文章目录前言一、文件的编码二、File类的使用三、RandomAccessFile类的使用 前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站,这篇文章男女通用…...

Mysql时间操作
一、MySql时间戳转换 select unix_timestamp(); #获取时间戳格式时间 select FROM_UNIXTIME(1717399499); #将时间戳转换为普通格式时间二、Mysql时间相加减结果转换为秒 方法1:time_to_sec(timediff(endTime, startTime)) SELECTDISTINCT(column1),min(last_mo…...

Nvidia Jetson/Orin +FPGA+AI大算力边缘计算盒子:无人机自主飞行软件平台
案例简介 北京泛化智能科技有限公司(gi)所主导开发的 Generalized Autonomy Aviation System (GAAS) 是为无人机以及城市空中交通 (UAM, Urban Air Mobility) 所设计的开源无人机自主飞行框架。通过 SLAM、路径规划和 Global Optimization Graph 等功能…...

weak的底层原理
weak 引用在 iOS 中通过维护一个全局的弱引用表来实现。当弱引用的对象被释放时,所有指向它的弱引用会被自动置为 nil,从而防止悬挂指针。 弱引用表(Weak Table)的键和值 理解弱引用表的键和值对于理解 weak 引用的底层机制非常重…...

Fish Speech 1.5语音克隆5分钟快速部署:零基础小白也能玩转AI配音
Fish Speech 1.5语音克隆5分钟快速部署:零基础小白也能玩转AI配音 1. 认识Fish Speech 1.5语音克隆技术 Fish Speech 1.5是当前最易上手的开源语音克隆工具之一。想象一下,你只需要录制10秒钟的语音样本,就能让AI用你的声音朗读任何文本——…...

AI编程赋能研发效率:核心能力与实践经验总结
作为常年泡在代码里的开发者,想必大家都有过这样的体验:用AI插件补几行代码很快,但一到实际项目,环境配置、多任务并行、代码审查这些环节还是得靠人工一点点磨;不同的AI编程能力各有优势,切换适配却十分繁…...

MTK新工程创建与调试全攻略,人形机器人的发展历程、技术演进与未来图景。
MTK调试:创建新工程指南 准备工作 确保已安装MTK官方开发环境,包括SDK、驱动程序和必要的工具链。下载最新版本的MTK开发包,解压到指定目录。检查系统环境变量是否配置正确,确保编译工具路径已加入PATH。 工程结构初始化 使用MTK提…...

GME-Qwen2-VL-2B-Instruct保姆级教程:多GPU并行推理加速图文批量匹配效率
GME-Qwen2-VL-2B-Instruct保姆级教程:多GPU并行推理加速图文批量匹配效率 1. 工具简介 GME-Qwen2-VL-2B-Instruct是一个专门用于图文匹配度计算的本地工具,基于先进的多模态模型开发。这个工具解决了传统图文匹配中经常遇到的打分不准问题,…...

终极指南:Permify权限计算优化如何避免深度递归陷阱
终极指南:Permify权限计算优化如何避免深度递归陷阱 【免费下载链接】permify An open-source authorization as a service inspired by Google Zanzibar, designed to build and manage fine-grained and scalable authorization systems for any application. — …...

宝塔面板PHP8.0如何快速安装Redis缓存扩展_在PHP设置的安装扩展模块中一键配置
宝塔面板PHP 8.0下无法一键安装Redis扩展,因官方源无适配预编译包且构建脚本不兼容ZTS/NTS、phpize路径及头文件要求;须用pecl手动编译redis-5.3.7并正确配置php.ini。宝塔面板 PHP 8.0 下无法通过「安装扩展」一键启用 Redis,是因为官方源里…...

TypeScript类型安全进阶:Readonly和Required在状态管理中的妙用
TypeScript类型安全进阶:Readonly和Required在状态管理中的妙用 状态管理是现代前端开发中不可或缺的一环,而TypeScript的类型系统为我们提供了强大的工具来确保状态的安全性。在Redux、MobX等流行状态管理库中,Readonly和Required这两个工具…...

OpenClaw健康助手:Qwen3-32B分析智能穿戴数据生成周报
OpenClaw健康助手:Qwen3-32B分析智能穿戴数据生成周报 1. 为什么需要本地化健康数据分析 去年我开始使用智能手环监测睡眠和运动数据,但很快发现一个问题:所有数据都要上传到厂商云端才能生成报告。作为医疗行业从业者,我深知健…...

快商通:引领智能客服新范式,驱动企业服务数字化转型
在数字化转型加速的今天,智能客服系统已不再是企业的“可选项”,而是提升服务效率、优化客户体验、驱动业务增长的核心基础设施。无论是初创公司还是行业巨头,都面临着如何选择合适智能客服系统、如何将其真正落地并发挥最大价值的挑战。尤其…...
)
生成历史场景数据(实际应用替换为真实数据)
电热冷氢综合能源系统分布式鲁棒优化运行,基于Wasserstein 距离,包含结果绘图和随机优化和鲁棒优化对比场景,代码备注详细最近在搞综合能源系统的兄弟肯定对"不确定性"这词深恶痛绝——电力负荷说变就变,氢能价格跟过山…...