基于pytorch的车牌识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一、导入数据
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
from torchvision import datasets
import torchvision.models as models
import torch.nn.functional as F
import torch.nn as nn
import torch,torchvisiondevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
1. 获取类别名
import os,PIL,random,pathlib
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号data_dir = 'F:/host/Data/车牌识别数据/'
data_dir = pathlib.Path(data_dir)data_paths = list(data_dir.glob('*'))
# classeNames = [str(path).split("\\")[1].split("_")[1].split(".")[0] for path in data_paths]
classeNames = []
for path in data_paths:parts = str(path).split(os.sep)if len(parts) > 1:filename = parts[-1]if "_" in filename:name_part = filename.split("_")[1]if "." in name_part:classeNames.append(name_part.split(".")[0])print(classeNames)
输出:

data_paths = list(data_dir.glob('*'))
data_paths_str = [str(path) for path in data_paths]
data_paths_str
输出:

2. 数据可视化
plt.figure(figsize=(14,5))
plt.suptitle("数据示例",fontsize=15)for i in range(18):plt.subplot(3,6,i+1)# plt.xticks([])# plt.yticks([])# plt.grid(False)# 显示图片images = plt.imread(data_paths_str[i])plt.imshow(images)plt.show()

3. 标签数字化
import numpy as npchar_enum = ["京","沪","津","渝","冀","晋","蒙","辽","吉","黑","苏","浙","皖","闽","赣","鲁",\"豫","鄂","湘","粤","桂","琼","川","贵","云","藏","陕","甘","青","宁","新","军","使"]number = [str(i) for i in range(0, 10)] # 0 到 9 的数字
alphabet = [chr(i) for i in range(65, 91)] # A 到 Z 的字母char_set = char_enum + number + alphabet
char_set_len = len(char_set)
label_name_len = len(classeNames[0])# 将字符串数字化
def text2vec(text):vector = np.zeros([label_name_len, char_set_len])for i, c in enumerate(text):idx = char_set.index(c)vector[i][idx] = 1.0return vectorall_labels = [text2vec(i) for i in classeNames]
4. 加载数据文件
import os
import pandas as pd
from torchvision.io import read_image
from torch.utils.data import Dataset
import torch.utils.data as data
from PIL import Imageclass MyDataset(data.Dataset):def __init__(self, all_labels, data_paths_str, transform):self.img_labels = all_labels # 获取标签信息self.img_dir = data_paths_str # 图像目录路径self.transform = transform # 目标转换函数def __len__(self):return len(self.img_labels)def __getitem__(self, index):image = Image.open(self.img_dir[index]).convert('RGB')#plt.imread(self.img_dir[index]) # 使用 torchvision.io.read_image 读取图像label = self.img_labels[index] # 获取图像对应的标签if self.transform:image = self.transform(image)return image, label # 返回图像和标签
total_datadir = 'F:/host/Data/车牌识别数据/'train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std =[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = MyDataset(all_labels, data_paths_str, train_transforms)
total_data

5. 划分数据
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_size,test_size

train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=16,shuffle=True)
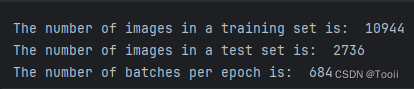
test_loader = torch.utils.data.DataLoader(test_dataset,batch_size=16,shuffle=True)print("The number of images in a training set is: ", len(train_loader)*16)
print("The number of images in a test set is: ", len(test_loader)*16)
print("The number of batches per epoch is: ", len(train_loader))
for X, y in test_loader:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break

二、自建模型
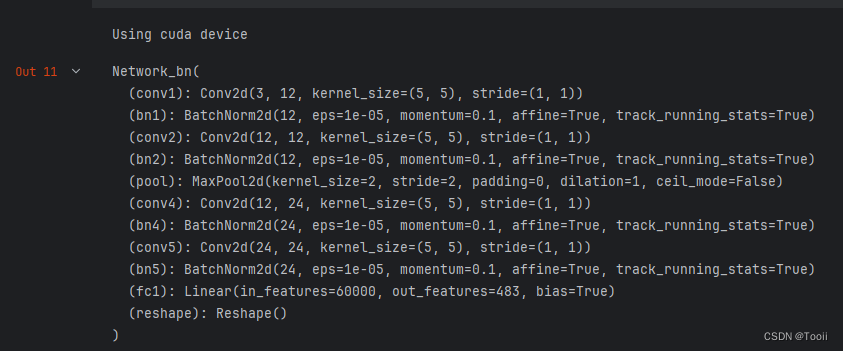
class Network_bn(nn.Module):def __init__(self):super(Network_bn, self).__init__()"""nn.Conv2d()函数:第一个参数(in_channels)是输入的channel数量第二个参数(out_channels)是输出的channel数量第三个参数(kernel_size)是卷积核大小第四个参数(stride)是步长,默认为1第五个参数(padding)是填充大小,默认为0"""self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(12)self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)self.bn2 = nn.BatchNorm2d(12)self.pool = nn.MaxPool2d(2,2)self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)self.bn4 = nn.BatchNorm2d(24)self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)self.bn5 = nn.BatchNorm2d(24)self.fc1 = nn.Linear(24*50*50, label_name_len*char_set_len)self.reshape = Reshape([label_name_len,char_set_len])def forward(self, x):x = F.relu(self.bn1(self.conv1(x))) x = F.relu(self.bn2(self.conv2(x))) x = self.pool(x) x = F.relu(self.bn4(self.conv4(x))) x = F.relu(self.bn5(self.conv5(x))) x = self.pool(x) x = x.view(-1, 24*50*50)x = self.fc1(x)# 最终reshapex = self.reshape(x)return x# 定义Reshape层
class Reshape(nn.Module):def __init__(self, shape):super(Reshape, self).__init__()self.shape = shapedef forward(self, x):return x.view(x.size(0), *self.shape)device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = Network_bn().to(device)
model
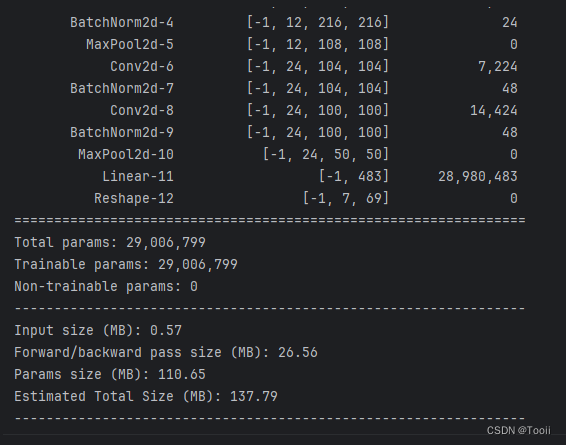
import torchsummary''' 显示网络结构 '''
torchsummary.summary(model, (3, 224, 224))
三、模型训练
1. 优化器与损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=0.0001)loss_model = nn.CrossEntropyLoss()
from torch.autograd import Variabledef test(model, test_loader, loss_model):size = len(test_loader.dataset)num_batches = len(test_loader)model.eval()test_loss, correct = 0, 0with torch.no_grad():for X, y in test_loader:X, y = X.to(device), y.to(device)pred = model(X)test_loss += loss_model(pred, y).item()test_loss /= num_batchesprint(f"Avg loss: {test_loss:>8f} \n")return correct,test_lossdef train(model,train_loader,loss_model,optimizer):model=model.to(device)model.train()for i, (images, labels) in enumerate(train_loader, 0): #0是标起始位置的值。images = Variable(images.to(device))labels = Variable(labels.to(device))optimizer.zero_grad()outputs = model(images)loss = loss_model(outputs, labels)loss.backward()optimizer.step()if i % 1000 == 0: print('[%5d] loss: %.3f' % (i, loss))
2. 模型的训练
test_acc_list = []
test_loss_list = []
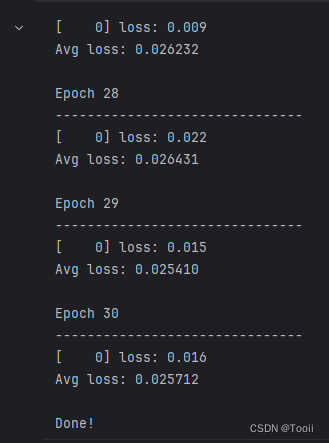
epochs = 30for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train(model,train_loader,loss_model,optimizer)test_acc,test_loss = test(model, test_loader, loss_model)test_acc_list.append(test_acc)test_loss_list.append(test_loss)
print("Done!")
四、结果分析
import numpy as np
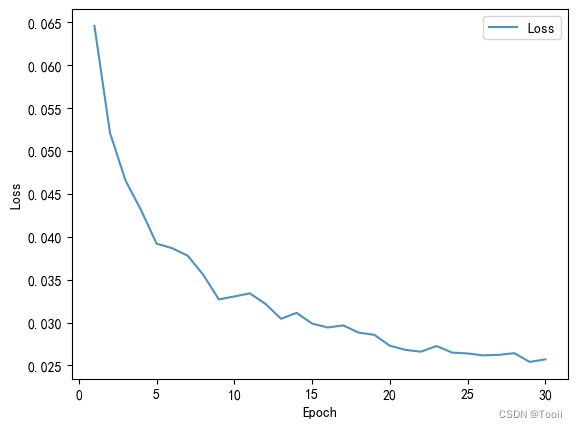
import matplotlib.pyplot as pltx = [i for i in range(1,31)]plt.plot(x, test_loss_list, label="Loss", alpha=0.8)plt.xlabel("Epoch")
plt.ylabel("Loss")plt.legend()
plt.show()
五、个人小结
在本项目中,我构建了一个基于深度学习的车牌识别系统。通过导入必要的库、获取类别名、数据可视化、标签数字化、加载数据文件、划分数据集、创建自定义数据集类、定义网络结构、设置优化器与损失函数、进行模型训练和测试,以及绘制训练过程中的损失曲线,我们对整个流程进行了详细的实践和分析。模型训练结果显示,随着训练的进行,损失逐渐减小,表明模型正在学习并逐渐优化。
相关文章:
基于pytorch的车牌识别
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 一、导入数据 from torchvision.transforms import transforms from torch.utils.data import DataLoader from torchvision import datase…...

红酒:如何避免红酒过度氧化
红酒过度氧化是影响其品质的重要因素,尤其是在储存和运输过程中。过度氧化的红酒会失去原有的果香和口感,变得平淡无味。因此,避免红酒过度氧化至关重要。以下是一些进一步的措施,可以帮助您保护云仓酒庄雷盛红酒的品质࿱…...
信号量总结(二值信号量、计数型信号量、互斥信号量、优先级翻转、优先级继承))
FreeRTOS学习笔记-基于stm32(9)信号量总结(二值信号量、计数型信号量、互斥信号量、优先级翻转、优先级继承)
一、什么是信号量 信号量是一种队列,用于任务间同步和资源管理的机制,主要用来传递状态。就像是一种特殊的“旗子”或“钥匙”,用来在不同的任务之间进行沟通和协调,确保它们能够正确地配合工作,不会互相干扰。 二、二…...

归并排序——二路归并排序
目录 1、简述 2、复杂度 3、稳定性 4、例子 1、简述 二路归并排序(Merge Sort)是一种基于分治法的排序算法,通过将数组递归地拆分成两部分,分别排序后再合并,从而实现整个数组的有序。二路归并排序具有稳定性和高…...

java-StringBuilder
StringBuilder 是 Java 中一个重要的类,它提供了可变的字符序列,可以用来高效地执行字符串操作,如拼接、替换和删除等。在 Java 编程中,字符串操作是非常常见的,而 StringBuilder 类为我们提供了简单、高效的方式来完成…...

数据结构 | 超详细讲解七大排序(C语言实现,含动图,多方法!)
目录 编辑 排序的概念 常见排序算法 编辑 1.冒泡排序 🍹图解 🥳代码实现 🤔时间复杂度 2.插入排序 🍹图解 🌴深度剖析 🍎代码思路 🥳代码实现 🤔时间复杂度 3.希尔…...

企业自建邮件系统的优势,安全性更高,功能更灵活,维护更便捷
在当今企业信息管理的浪潮中,企业邮件系统显得尤为关键,它不仅加强了内部的沟通效率,还对外展示了企业的专业形象。然而,传统租用企业邮箱服务存在一些不足,如缺乏灵活性、数据管理混乱和难以实现个性化需求࿰…...

Softing工业助力微软解锁工业数据,推动AI技术在工业领域的发展
一 概览 Softing作为全球先进工业通信解决方案供应商之一,与微软合作共同推出了众多工业边缘产品,以实现工业应用中OT和IT的连接。这些产品可在基于微软Azure云平台的IIoT解决方案中轻松集成和运行,并为AI解锁工业数据,还可通过A…...

企微自动化机器人的应用与前景
一、引言 随着信息技术的飞速发展,企业对于提高内部运营效率、降低人力成本的需求日益迫切。在这样的背景下,企微自动化机器人应运而生,以其高效、便捷的特点,迅速成为企业内部的得力助手。本文将深入探讨企微自动化机器人的应用现…...

从零开始:如何用Electron将chatgpt-plus.top 打包成EXE文件
文章目录 从零开始:如何用Electron将chatgpt-plus.top 打包成EXE文件准备工作:Node.js和npm国内镜像加速下载初始化你的Electron项目创建你的Electron应用运行你的Electron应用为你的应用设置图标打包成EXE文件结语 从零开始:如何用Electron将…...
基于RNN和Transformer的词级语言建模 代码分析 log_softmax
基于RNN和Transformer的词级语言建模 代码分析 log_softmax flyfish Word-level Language Modeling using RNN and Transformer word_language_model PyTorch 提供的 word_language_model 示例展示了如何使用循环神经网络RNN(GRU或LSTM)和 Transformer 模型进行词级语言建模…...

Python爬虫要掌握哪些东西
学习Python爬虫,你需要掌握以下几个关键方面的知识: 文章目录 Python基础:首先,确保你对Python语言有良好的理解,包括基本语法、数据结构(如列表、字典、集合等)、函数、类和对象、模块和包的使用等。# 有一个数字列表,要创建新的列表,元素是原列表中每个元素的平方 …...
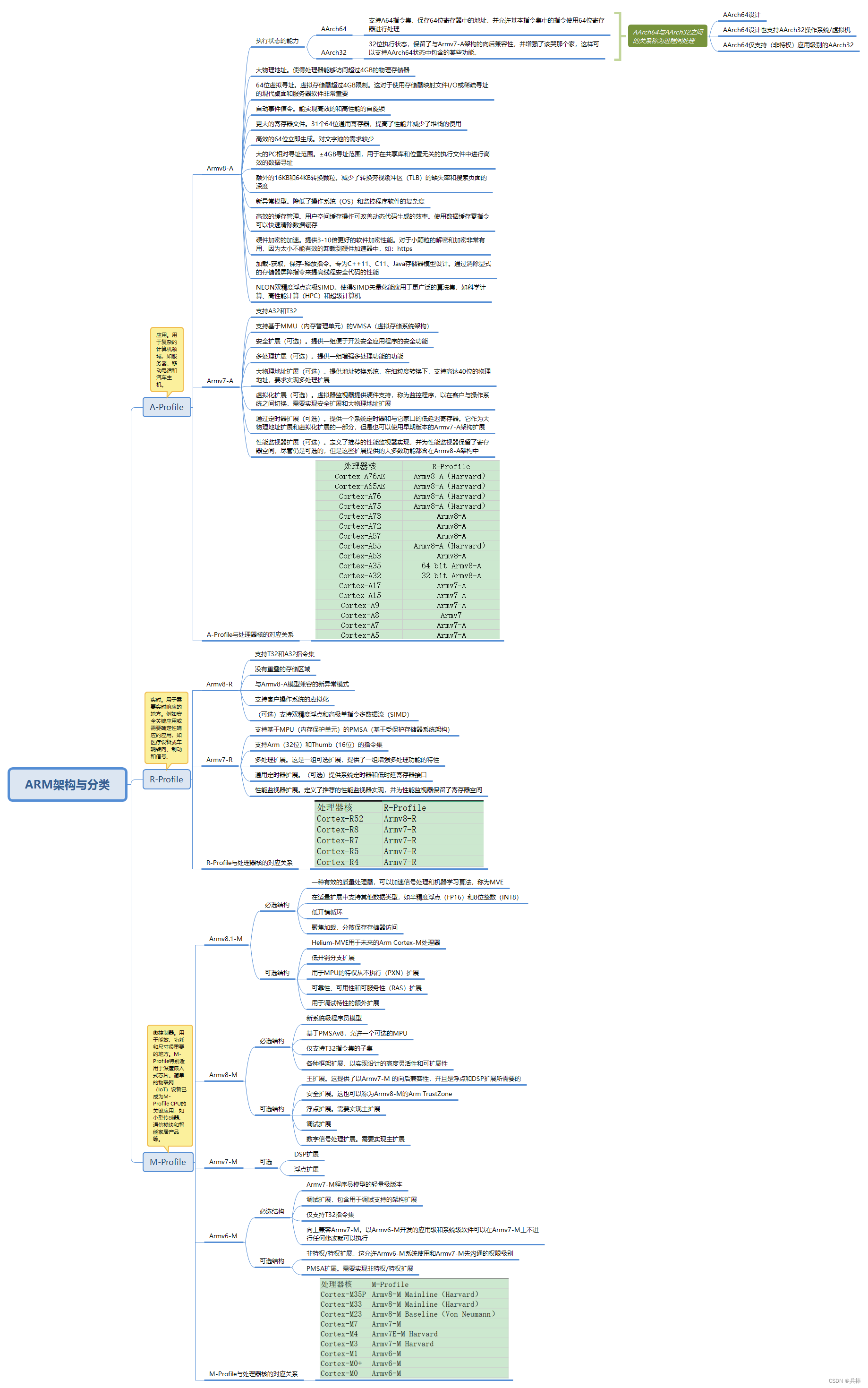
FPGA-ARM架构与分类
ARM架构,曾称进阶精简指令集机器(Advanced RISC Machine)更早称作Acorn RISC Machine,是一个32位精简指令集(RISC)处理器架构。 主要是根据FPGA zynq-7000的芯片编写的知识思维导图总结,废话不多说自取吧 …...
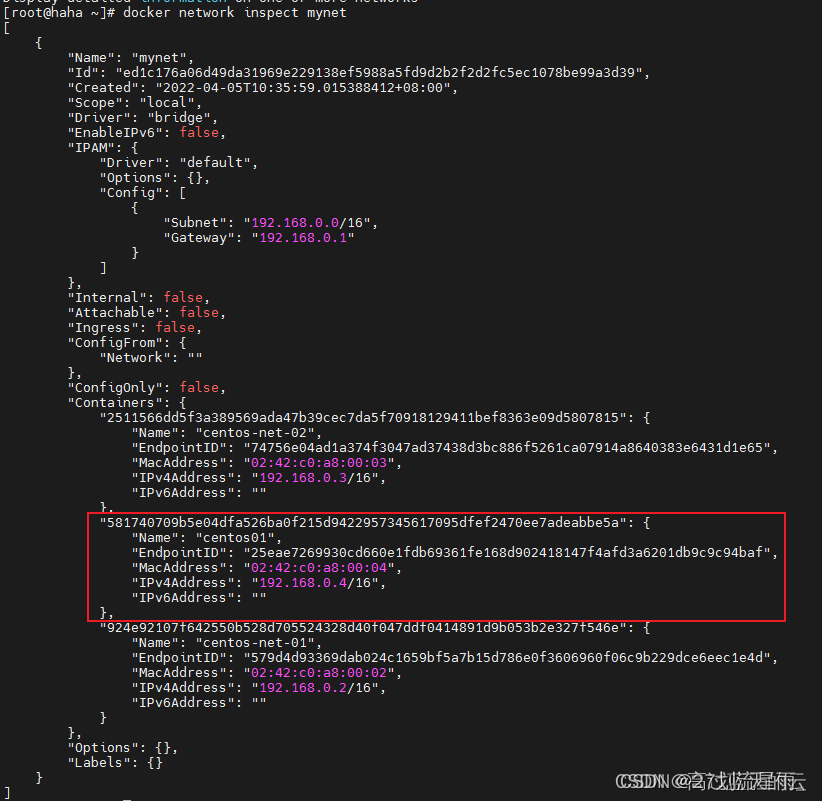
docker网络详解
1. 网络模式 1.1 网络结构 当安装Docker以后,会自动创建三个网络。可以使用docker network ls命令列出这些网络。 $ docker network ls NETWORK ID NAME DRIVER SCOPE 440aefe8afa3 bridge bridge local aa8d6325580f host host …...
设计软件有哪些?效果工具篇(1),渲染100邀请码1a12
设计师会用到很多渲染效果和后期处理的工具,这里我们介绍一些。 1、AfterBurn AfterBurn是为Autodesk 3ds Max开发的专业级别的体积照明和效果插件。它提供了一系列强大的特效功能,包括烟雾、火焰、云彩等。用户可以利用AfterBurn创建逼真的环境效果&a…...

Iphone自动化指令每隔固定天数打开闹钟关闭闹钟(二)
1.首先在搜索和操作里搜索“查找日期日程" 1.1.然后过滤条件开始日期选择”是今天“ 1.2.增加过滤条件,日历是这里选择”工作“ 1.3.增加过滤条件,选择标题,是这里选择”workDay“ 1.4选中限制,日历日程只要一个,…...

计算机网络错题答案汇总
王道学习 第1章 计算机网络体系结构 1.1 1.2...

Fortigate防火墙二层接口的几种实现方式
初始配置 FortiGate出厂配置默认地址为192.168.1.99(MGMT接口),可以通过https的方式进行web管理(默认用户名admin,密码为空),不同型号设备用于管理的接口略有不同。 console接口的配置 防火墙…...
如何永久擦除Android手机中的所有个人数据?
在这个数字化的时代,确保您的个人数据的安全和隐私至关重要。如果您计划出售或回收您的Android手机,了解如何正确擦除Android手机是至关重要的。本综合指南将引导您通过安全擦除Android手机的分步过程,以保护您的敏感信息。 手机是极其敏感的…...

使用手机小程序给证件照换底色
临时遇到一个需求,需要给证件照换底色。原始图像如下 最终需要换成红底的。 本次使用一款小程序"泰世茂证件照",打开该小程序,如下图所示 单击开始制作,然后选择二寸红底,如下图所示 然后单击相…...

2025豆包AI高阶视频教程精准提示词合集大模型通用附教程资料大全
📂 资源包含哪些硬核内容?(部分展示) 资源下载地址:https://pan.quark.cn/s/fdeeee266e5b 主要涵盖但不限于以下核心模块: 📖 【AI阅读大师】法! 🎨 【文生图魔方…...

终极TypeScript类型安全指南:LiveTerm接口定义与类型检查最佳实践
终极TypeScript类型安全指南:LiveTerm接口定义与类型检查最佳实践 【免费下载链接】LiveTerm 💻 Build terminal styled websites in minutes! 项目地址: https://gitcode.com/gh_mirrors/li/LiveTerm LiveTerm是一个基于Next.js的终端风格网站构…...

联络中心支付软件市场最新数据披露:规模达41.37亿元,行业格局加速显现
在全球企业数字化转型浪潮汹涌以及客户对便捷支付体验需求日益增长的背景下,联络中心支付软件市场正迎来前所未有的发展机遇。据恒州诚思调研统计,2025年全球联络中心支付软件市场规模约41.37亿元,预计未来将持续保持平稳增长态势,…...

【力扣hot100】 198. 打家劫舍
一、题目你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金, 影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统, 如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。 给定一个代表每个房屋存…...

测试计划详细说明
一份高质量的测试计划本质上是质量风险的防御蓝图,它要在有限资源和无限质量诉求之间找到平衡点。我将从结构、内容、决策逻辑三个维度展开,并提供一个可直接落地的框架。一、测试计划的核心定位测试计划的本质回答三个问题:测什么࿱…...

【架构师通关】理发店排队 + 车库停车,大白话秒懂“进程状态模型”与“PV操作
兄弟们,操作系统的进程管理一直是软考里最让人头疼的“硬骨头” 🦴。什么“阻塞”、“挂起”、“信号量”、“PV操作”,听着就像天书 📚。 但今天,飞哥绝不跟你拽学术名词!咱们就通过“去理发店剪个头” &a…...

VR环保学习机|开启沉浸式环保教育新时代
在环保教育不断升级的今天,如何让公众尤其是青少年真正理解环保的重要性、养成绿色习惯,已经成为教育领域的重要课题。传统的图文讲解虽然内容充足,却往往缺少互动性和代入感,难以让学习者产生深刻的记忆。VR环保学习机正是在这样…...

Phi-4-mini-reasoning实操手册:Web界面响应延迟高?GPU显存占用诊断方法
Phi-4-mini-reasoning实操手册:Web界面响应延迟高?GPU显存占用诊断方法 1. 问题背景与现象分析 当使用Phi-4-mini-reasoning进行推理任务时,Web界面响应延迟高是一个常见问题。这种情况通常表现为: 点击"开始生成"按…...

3步解锁Arduino红外遥控:终极实战指南
3步解锁Arduino红外遥控:终极实战指南 【免费下载链接】Arduino-IRremote Infrared remote library for Arduino: send and receive infrared signals with multiple protocols 项目地址: https://gitcode.com/gh_mirrors/ar/Arduino-IRremote 想要让Arduino…...

S-UI配置文件加密终极指南:保护敏感信息的最佳实践 [特殊字符]
S-UI配置文件加密终极指南:保护敏感信息的最佳实践 🔒 S-UI是一款基于SagerNet/Sing-Box构建的高级Web面板,提供多协议支持和流量管理功能。在使用过程中,配置文件包含大量敏感信息,如API密钥、用户数据和服务器配置&…...