基于RNN和Transformer的词级语言建模 代码分析 log_softmax
基于RNN和Transformer的词级语言建模 代码分析 log_softmax
flyfish
Word-level Language Modeling using RNN and Transformer
word_language_model
PyTorch 提供的 word_language_model 示例展示了如何使用循环神经网络RNN(GRU或LSTM)和 Transformer 模型进行词级语言建模 。默认情况下,训练使用Wikitext-2数据集,generate.py可以使用训练好的模型来生成新文本。
源码地址
https://github.com/pytorch/examples/tree/main/word_language_model
文件:model.py
F.log_softmax(output, dim=-1) 在 TransformerModel 的 forward 方法的最后一行中用于将模型的输出转换为对数概率分布,既提高了数值计算的稳定性,又与常用的损失函数(如NLLLoss)兼容.
数值计算的稳定性,请参考该文章的后半部分
https://flyfish.blog.csdn.net/article/details/106405099
1. 概率与对数概率
概率(Probability): 概率是某个事件发生的可能性,值在 [0, 1] 之间。比如,一个事件发生的概率为 P。
对数概率(Log Probability): 对数概率是将概率值
P 取对数后的结果,通常使用自然对数(ln)。对数概率可以表示为:log§,其中 log 是自然对数函数。
2. 对数概率的性质
范围: 因为概率 P 总是介于 0 和 1 之间,所以对数概率 log§ 总是小于或等于零。
当 P=1 时,log(1)=0。
当 0<P<1 时,log§<0。
当 P 趋近于 0 时,log§ 趋近于负无穷。
单调性: 对数函数是单调递增函数,这意味着如果两个概率
两个概率 P1和 P2, 满足 P1 > P2,则对应的对数概率也满足 log(P1) > log(P2)
3. 为什么使用对数概率
数值稳定性: 直接使用概率值进行计算时,若概率值非常小(接近于零),可能导致数值下溢问题。对概率取对数可以将乘法转化为加法,从而避免这种数值不稳定性。
例如,计算多个独立事件的联合概率
P(A∩B)=P(A)⋅P(B),使用对数概率可以转换为加法:
log(P(A∩B))=log(P(A))+log(P(B))。
简化计算: 在某些模型(如隐马尔可夫模型和深度学习模型)中,使用对数概率可以简化似然函数和损失函数的计算。
与损失函数的兼容性: 在深度学习中,常用的损失函数如负对数似然损失(Negative Log-Likelihood Loss, NLLLoss)需要对数概率作为输入。因此,模型输出对数概率是直接兼容这些损失函数的。
4. 对数概率在深度学习中的应用
在神经网络模型(特别是用于分类任务的模型)中,输出通常是一个概率分布。在语言建模任务中,我们希望输出每个词的概率。在训练过程中,为了计算损失,我们使用对数概率。
语言模型: 给定一个句子,模型输出每个词的对数概率。
损失函数: 使用 NLLLoss 来计算预测词与真实词之间的损失。
以下是一个示例,展示如何计算对数概率并使用负对数似然损失
import torch
import torch.nn as nn
import torch.nn.functional as F# 定义一个简单的模型
class SimpleModel(nn.Module):def __init__(self, ntoken, ninp):super(SimpleModel, self).__init__()self.embedding = nn.Embedding(ntoken, ninp)self.decoder = nn.Linear(ninp, ntoken)def forward(self, src):embedded = self.embedding(src)output = self.decoder(embedded)return F.log_softmax(output, dim=-1)# 超参数
ntoken = 10 # 词汇表大小
ninp = 512 # 嵌入维度# 创建模型实例
model = SimpleModel(ntoken, ninp)# 生成假数据
src = torch.randint(0, ntoken, (5, 2)) # 序列长度为5,批次大小为2# 前向传播
log_probs = model(src)# 计算损失
criterion = nn.NLLLoss()
target = torch.randint(0, ntoken, (5, 2)) # 生成目标序列
loss = criterion(log_probs.view(-1, ntoken), target.view(-1))print("Log probabilities shape:", log_probs.shape)
print("Log probabilities:", log_probs)
print("Loss:", loss.item())
加入原始代码
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as pltclass PositionalEncoding(nn.Module):def __init__(self, d_model, dropout=0.1, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe)def forward(self, x):r"""Inputs of forward functionArgs:x: the sequence fed to the positional encoder model (required).Shape:x: [sequence length, batch size, embed dim]output: [sequence length, batch size, embed dim]Examples:>>> output = pos_encoder(x)"""x = x + self.pe[:x.size(0), :]return self.dropout(x)class TransformerModel(nn.Transformer):"""Container module with an encoder, a recurrent or transformer module, and a decoder."""def __init__(self, ntoken, ninp, nhead, nhid, nlayers, dropout=0.5):super(TransformerModel, self).__init__(d_model=ninp, nhead=nhead, dim_feedforward=nhid, num_encoder_layers=nlayers)self.model_type = 'Transformer'self.src_mask = Noneself.pos_encoder = PositionalEncoding(ninp, dropout)self.input_emb = nn.Embedding(ntoken, ninp)self.ninp = ninpself.decoder = nn.Linear(ninp, ntoken)self.init_weights()def _generate_square_subsequent_mask(self, sz):return torch.log(torch.tril(torch.ones(sz,sz)))def init_weights(self):initrange = 0.1nn.init.uniform_(self.input_emb.weight, -initrange, initrange)nn.init.zeros_(self.decoder.bias)nn.init.uniform_(self.decoder.weight, -initrange, initrange)def forward(self, src, has_mask=True):if has_mask:device = src.deviceif self.src_mask is None or self.src_mask.size(0) != len(src):mask = self._generate_square_subsequent_mask(len(src)).to(device)self.src_mask = maskelse:self.src_mask = Nonesrc = self.input_emb(src) * math.sqrt(self.ninp)src = self.pos_encoder(src)output = self.encoder(src, mask=self.src_mask)output = self.decoder(output)return F.log_softmax(output, dim=-1)# Hyperparameters
ntoken = 10 # size of vocabulary
ninp = 512 # embedding dimension
nhead = 8 # number of heads in the multiheadattention models
nhid = 512 # the dimension of the feedforward network model in nn.Transformer
nlayers = 2 # the number of nn.TransformerEncoderLayer in nn.TransformerEncoder
dropout = 0.2 # the dropout value# Create model
model = TransformerModel(ntoken, ninp, nhead, nhid, nlayers, dropout)# Example input (sequence length: 5, batch size: 2)
src = torch.randint(0, ntoken, (5, 2))# Forward pass
output = model(src)
print("Output shape:", output.shape) # Should be (sequence length, batch size, ntoken)
print("Output:", output)# Visualize the output
output_np = output.detach().numpy() # Convert to numpy for visualizationplt.figure(figsize=(12, 6))
for i in range(output_np.shape[1]): # Iterate over batch elementsplt.subplot(1, output_np.shape[1], i+1)plt.imshow(output_np[:, i, :], aspect='auto', cmap='viridis')plt.colorbar()plt.title(f"Batch {i+1}")plt.xlabel("Token Index")plt.ylabel("Sequence Position")
plt.show()
在 TransformerModel 的 forward 方法中,return F.log_softmax(output, dim=-1) 的作用是将模型的最终输出转换为对数概率分布。为了更好地理解其意义和用途,我们需要详细解释以下几个方面:
1. output 的来源
在 forward 方法中,output 是经过嵌入层(embedding layer)、位置编码(positional encoding)、编码器(encoder)、和解码器(decoder)处理后的张量。假设输入 src 的形状为 (sequence_length, batch_size),则:
经过嵌入层后,形状为 (sequence_length, batch_size, ninp)。
经过位置编码后,形状保持不变。
经过编码器后,形状仍然保持不变。
最后经过解码器后,形状为 (sequence_length, batch_size, ntoken),其中 ntoken 是词汇表的大小。
2. F.log_softmax(output, dim=-1) 的作用
F.log_softmax 是 PyTorch 中的一个函数,用于计算张量的对数软最大值。
主要功能:
归一化:将输出转换为概率分布形式。
对数变换:取对数以提高数值稳定性。
为什么在 dim=-1 维度上应用:
dim=-1 表示在最后一个维度上应用 log_softmax,即在 ntoken 维度上。这意味着对于每个时间步和每个批次,模型输出的每个向量都被归一化为一个概率分布,并且这些概率值是通过取对数的方式表示的。
3. 应用
语言建模任务中,将模型输出转换为对数概率分布是非常常见的做法。这是因为:
数值稳定性:计算对数概率可以避免溢出或下溢的问题。
损失函数兼容性:在训练过程中,通常使用负对数似然损失(negative log-likelihood loss,NLLLoss)来优化模型参数。NLLLoss 需要对数概率作为输入,因此在前向传播中计算 log_softmax 是必要的。
4. 示例代码
假设我们有一个训练好的 TransformerModel 实例,并且我们输入一些假数据来运行前向传播。F.log_softmax(output, dim=-1) 的具体效果如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math# Define the TransformerModel and PositionalEncoding classes here (from previous messages)# Example input (sequence length: 5, batch size: 2)
src = torch.randint(0, ntoken, (5, 2))# Forward pass
output = model(src)
log_probs = F.log_softmax(output, dim=-1)# Output shape
print("Output shape:", log_probs.shape) # Should be (sequence length, batch size, ntoken)# Output values (log probabilities)
print("Log probabilities:", log_probs)
Output shape: torch.Size([5, 2, 10])
Log probabilities: tensor([[[-1.8122, -1.6211, -2.8076, -2.8982, -3.4530, -1.0481, -3.1035,-3.0695, -6.4251, -3.0296],[-7.1732, -1.0471, -4.7220, -0.9092, -4.7615, -3.8586, -2.5530,-2.2406, -4.5940, -4.3775]],[[-1.8474, -2.3659, -4.0811, -3.3230, -1.9491, -1.2751, -2.2046,-3.1314, -3.8996, -2.3072],[-3.8504, -3.6711, -1.3957, -1.1146, -2.9621, -2.0949, -3.4236,-3.6456, -2.7213, -2.5475]],[[-3.3242, -3.7939, -3.4796, -4.5979, -1.9281, -1.7997, -3.2005,-1.9959, -3.0253, -1.0088],[-4.1581, -0.9709, -4.3932, -0.9737, -5.2762, -2.2979, -3.6968,-3.6558, -4.9326, -2.9538]],[[-2.0125, -1.7920, -2.7189, -3.7525, -2.9609, -2.4254, -3.8162,-2.4056, -4.5775, -1.0567],[-3.5996, -2.0966, -3.8215, -1.6972, -4.0127, -3.1117, -3.2421,-2.7508, -2.3296, -0.9629]],[[-1.7974, -2.0685, -2.4899, -2.8838, -1.9412, -1.7804, -4.3274,-4.6523, -1.6798, -3.0407],[-1.8604, -1.2988, -2.9066, -3.4268, -3.1218, -3.0153, -3.0892,-4.5497, -1.1045, -5.5781]]], grad_fn=<LogSoftmaxBackward0>)
相关文章:
基于RNN和Transformer的词级语言建模 代码分析 log_softmax
基于RNN和Transformer的词级语言建模 代码分析 log_softmax flyfish Word-level Language Modeling using RNN and Transformer word_language_model PyTorch 提供的 word_language_model 示例展示了如何使用循环神经网络RNN(GRU或LSTM)和 Transformer 模型进行词级语言建模…...

Python爬虫要掌握哪些东西
学习Python爬虫,你需要掌握以下几个关键方面的知识: 文章目录 Python基础:首先,确保你对Python语言有良好的理解,包括基本语法、数据结构(如列表、字典、集合等)、函数、类和对象、模块和包的使用等。# 有一个数字列表,要创建新的列表,元素是原列表中每个元素的平方 …...
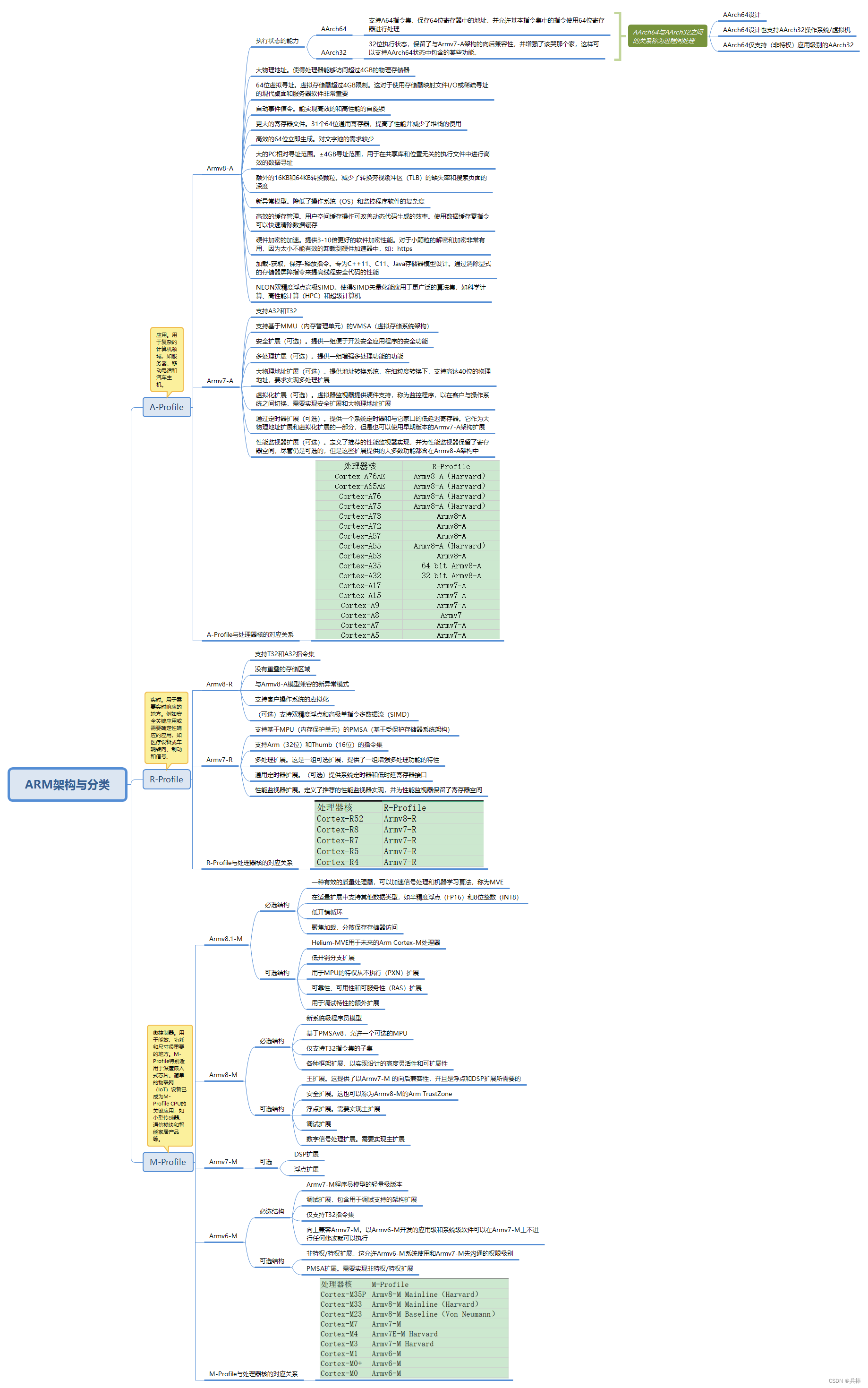
FPGA-ARM架构与分类
ARM架构,曾称进阶精简指令集机器(Advanced RISC Machine)更早称作Acorn RISC Machine,是一个32位精简指令集(RISC)处理器架构。 主要是根据FPGA zynq-7000的芯片编写的知识思维导图总结,废话不多说自取吧 …...
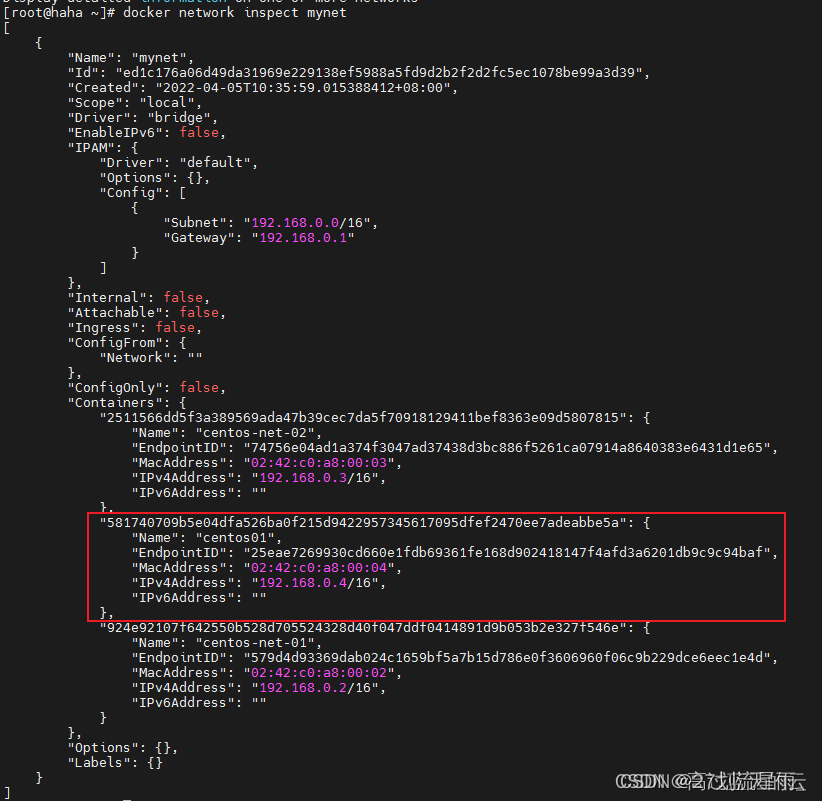
docker网络详解
1. 网络模式 1.1 网络结构 当安装Docker以后,会自动创建三个网络。可以使用docker network ls命令列出这些网络。 $ docker network ls NETWORK ID NAME DRIVER SCOPE 440aefe8afa3 bridge bridge local aa8d6325580f host host …...
设计软件有哪些?效果工具篇(1),渲染100邀请码1a12
设计师会用到很多渲染效果和后期处理的工具,这里我们介绍一些。 1、AfterBurn AfterBurn是为Autodesk 3ds Max开发的专业级别的体积照明和效果插件。它提供了一系列强大的特效功能,包括烟雾、火焰、云彩等。用户可以利用AfterBurn创建逼真的环境效果&a…...

Iphone自动化指令每隔固定天数打开闹钟关闭闹钟(二)
1.首先在搜索和操作里搜索“查找日期日程" 1.1.然后过滤条件开始日期选择”是今天“ 1.2.增加过滤条件,日历是这里选择”工作“ 1.3.增加过滤条件,选择标题,是这里选择”workDay“ 1.4选中限制,日历日程只要一个,…...

计算机网络错题答案汇总
王道学习 第1章 计算机网络体系结构 1.1 1.2...

Fortigate防火墙二层接口的几种实现方式
初始配置 FortiGate出厂配置默认地址为192.168.1.99(MGMT接口),可以通过https的方式进行web管理(默认用户名admin,密码为空),不同型号设备用于管理的接口略有不同。 console接口的配置 防火墙…...
如何永久擦除Android手机中的所有个人数据?
在这个数字化的时代,确保您的个人数据的安全和隐私至关重要。如果您计划出售或回收您的Android手机,了解如何正确擦除Android手机是至关重要的。本综合指南将引导您通过安全擦除Android手机的分步过程,以保护您的敏感信息。 手机是极其敏感的…...

使用手机小程序给证件照换底色
临时遇到一个需求,需要给证件照换底色。原始图像如下 最终需要换成红底的。 本次使用一款小程序"泰世茂证件照",打开该小程序,如下图所示 单击开始制作,然后选择二寸红底,如下图所示 然后单击相…...
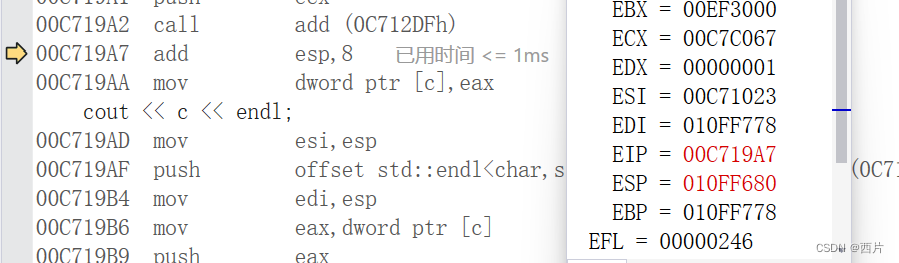
C语言杂谈:函数栈帧,函数调用时到底发生了什么
我们都知道在调用函数时,要为函数在栈上开辟空间,函数后续内容都会在栈帧空间中保存,如非静态局部变量,返回值等。这段空间就叫栈帧。 当函数调用,就会开辟栈帧空间,函数返回时,栈帧空间就会被释…...
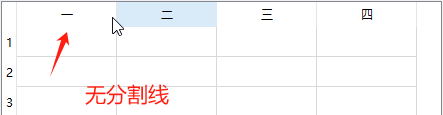
【Qt】win10,QTableWidget表头下无分隔线的问题
1. 现象 2. 原因 win10系统的UI样式默认是这样的。 3. 解决 - 方法1 //横向表头ui->table->horizontalHeader()->setStyleSheet("QHeaderView::section{""border-top:0px solid #E5E5E5;""border-left:0px solid #E5E5E5;""bord…...

前端 实现有时间限制的缓存
首先我们需要创建一个名为TimeLimitedCache的构造函数,然后定义一些方法,如set, get,和count。以下是具体的示例代码: // 定义 TimeLimitedCache 构造函数 var TimeLimitedCache function( ) {// 初始化一个空的 cache 对象,用于…...
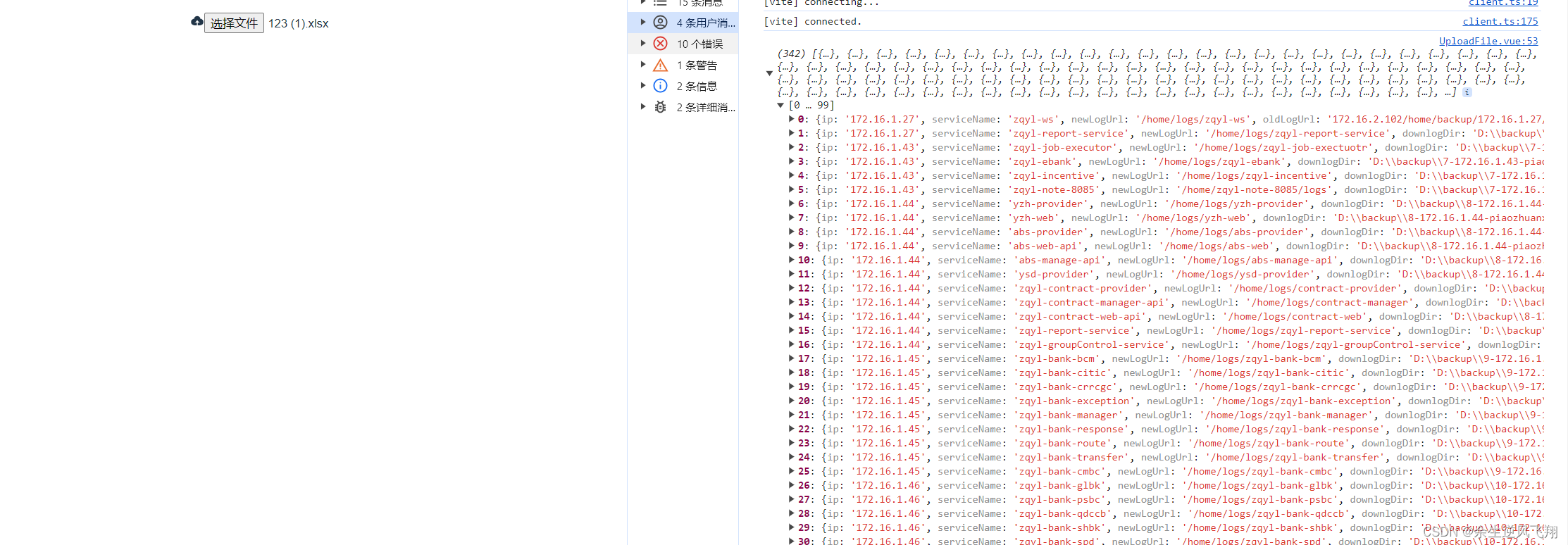
前端将xlsx转成json
第一种方式,用js方式 1.1先安装插件 万事都离不开插件的支持首先要安装两个插件 1.2. 安装xlsx cnpm install xlsx --save注:这块我用的cnpm,原生的是npm,因为镜像的问题安装了cnpm,至于怎么装网上一搜一大堆 1.3安…...
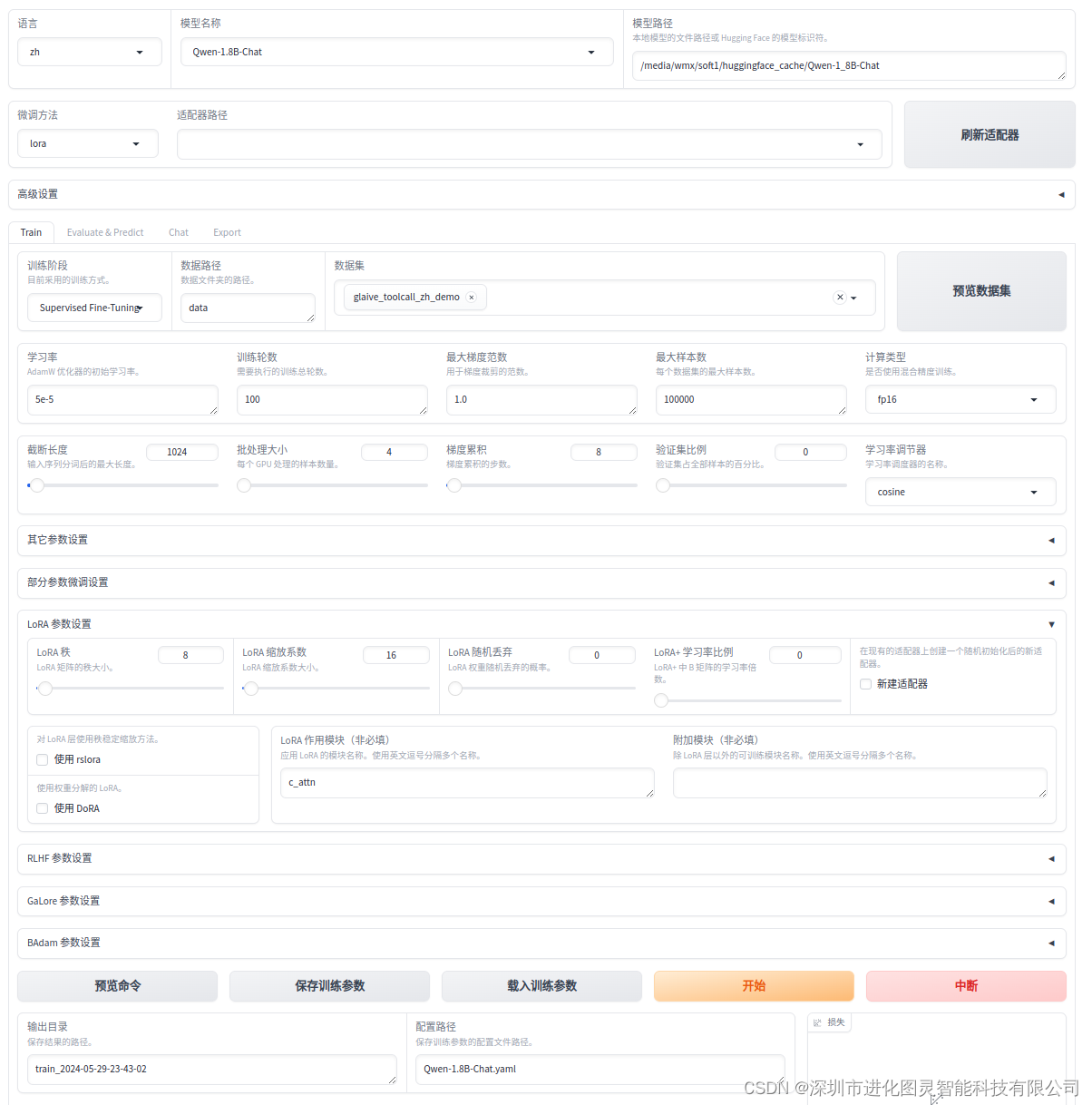
使用LLaMA-Factory微调大模型
使用LLaMA-Factory微调大模型 github 地址 https://github.com/hiyouga/LLaMA-Factory 搭建环境 git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory在 LLaMA-Factory 路径下 创建虚拟环境 conda create -p ./venv python3.10激活环境 c…...

C语言二级指针、指针数组
一、二级指针 指针变量也是变量,是变量就应有地址,那指针变量的地址存放在哪里?存放在二级指针变量。 此时,*ppa pa,**ppa a。 二、指针数组 指针数组,顾名思义就是存放指针的数组。 数组每个元素为int类…...

python方法
目录 公共方法 1.容器类型之间的转化 2.运算符 3.通用函数 公共方法 1.容器类型之间的转化 # 类型转化 data_str itcast data_list [hadoop, spark, hive, python, hive] data_tupe (hadoop, spark, hive, python, hive) data_set {hadoop, spark, hive, python,…...
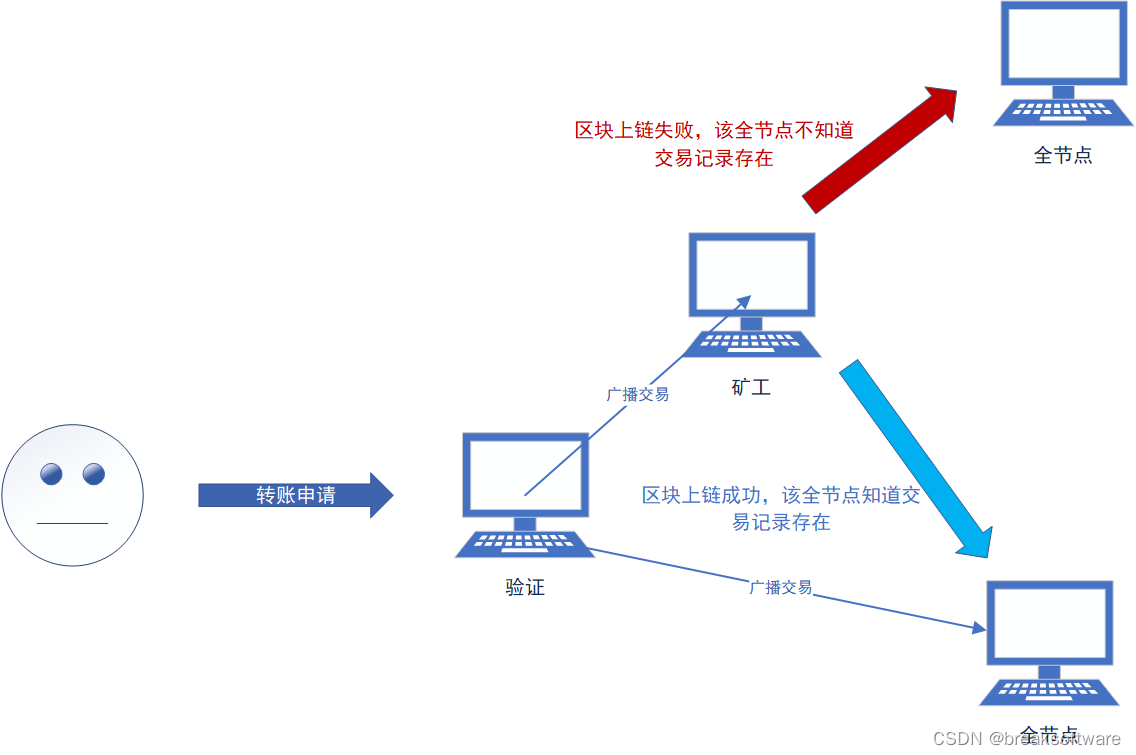
0基础学习区块链技术——去中心化
大纲 去验证的中心化验证者如何验证验证者为什么要去传播 去确认的中心化去存储的中心化 “去中心化”是区块链技术的核心。那么我们该如何理解这个概念呢? 我们可以假想在一次现实转账中,有哪些“中心化”的行为: 判断余额是否足够。即判断…...

索引的强大作用和是否创建的索引越多越好
在经常查询字段上创建索引。 在大数据的情况下,在索引上查找可以提交10倍以上甚至1000倍的速度。 实际测试,不在索引上查找用时12秒左右。建立索引,在索引上查找速度提高只耗时1.1秒左右。当然索引也是一把双刃剑,在一个表上创建索…...
批量GBK转UTF-8
大家都有这样的需求,把GBK编码的源代码转换成utf-8编码的源代码。 毕竟现在UTF-8的支持是很好的。 以前一些旧代码是GBK的,尤其是里面的注释,如果不采用UTF-8,在vscode里面可能看着就是乱码。 试了各种工具,最后发现…...
(源码+lw+部署文档+讲解等))
基于深度学习的田间杂草检测系统(YOLOv12/v11/v8/v5模型)(源码+lw+部署文档+讲解等)
摘要田间杂草的生长不仅会影响作物的产量和质量,还会对农田管理造成巨大挑战。传统的杂草检测方法多依赖人工观察,效率低下且受主观因素影响。为了提高田间杂草的检测效率与准确性,本文提出了一种基于深度学习的田间杂草检测系统,…...
的定义和数学物理意义)
偏迹(Partial Trace)的定义和数学物理意义
我们将通过多个计算示例来掌握偏迹(Partial Trace)。1. 偏迹的定义1.1 动机在量子力学中,复合系统 的态用密度矩阵 描述。那么,当我们只关心子系统 时,需要忽略掉其中 的状态,这里通过对子系统 求平…...

企业PTC软件正版化路径与长期价值分析
企业PTC软件正版化路径和长期价值分析我帮一家制造业客户处理软件正版化问题,提醒一句到他们的巨头供应商PTC的许可证使用率常年徘徊在30%左右,年均浪费成本超过800万,这事儿在行业内其实挺普遍的。如果说你正在为软件许可证管理头疼…...

COMSOL电磁超声仿真技术:基于5.6版本模型,精确检测L形铝板裂纹的电磁超声测量方法
COMSOL电磁超声仿真: Crack detection in L-shaped aluminum plate via electromagnetic ultrasonic measurements 版本为5.6,低于5.6的版本打不开此模型电磁超声检测(EMAT)在工业无损检测领域一直是个热门方向,最近在COMSOL 5.6上…...

2026最新Node.js+NVM全平台安装教程
2026最新Node.jsNVM全平台安装教程 前言 在前端、后端全栈开发中,Node.js 是必不可少的运行环境,而不同项目往往依赖不同的 Node.js 版本,手动安装卸载不仅麻烦还容易冲突。 NVM(Node Version Manager) 作为 Node.j…...
:Nuscenes数据集解析与应用)
3D点云检测实战指南-数据准备篇(一):Nuscenes数据集解析与应用
1. Nuscenes数据集基础解析 第一次接触Nuscenes数据集时,我被它庞大的数据量和精细的标注震撼到了。这个由Motional团队打造的自动驾驶数据集,包含了1000个真实驾驶场景,每个场景持续20秒。不同于普通数据集,Nuscenes最吸引我的是…...

LoRa土壤监测与灌溉控制系统方案
当前农业生产中,土壤水分、温度等环境参数是影响作物生长的核心因素,传统种植模式依赖人工经验判断灌溉时机与用量,存在诸多局限。随着智慧农业、精准农业的快速发展,物联网技术在农业灌溉领域的应用日益广泛,LoRa作为…...

提升Node.js应用性能:dotenv环境变量加载的终极优化指南
提升Node.js应用性能:dotenv环境变量加载的终极优化指南 【免费下载链接】dotenv Loads environment variables from .env for nodejs projects. 项目地址: https://gitcode.com/gh_mirrors/do/dotenv 在现代Node.js应用开发中,环境变量管理是确保…...

GNSS导航信号模拟器 卫星导航定位模拟器 GNSS卫星导航定位信号模拟器行业应用解决方案 GNSS模拟器
随着全球卫星导航系统的全面建设与深度应用,各类卫星导航定位授时终端已广泛渗透到交通、物联网、通信、测绘、消费电子等众多领域。但在终端产品的研发、测试、量产全流程中,行业长期面临诸多核心痛点:传统外场实地测试模式需投入大量人力物…...

Qwen3-14B WebUI权限分级:管理员/普通用户/只读访客三类角色配置
Qwen3-14B WebUI权限分级:管理员/普通用户/只读访客三类角色配置 1. 权限分级的重要性与场景需求 在私有化部署Qwen3-14B模型时,企业或团队通常需要根据不同成员的职责分配不同的操作权限。合理的权限分级能够: 保障系统安全:防…...