python方法
目录
公共方法
1.容器类型之间的转化
2.运算符
3.通用函数
公共方法
1.容器类型之间的转化
# 类型转化
data_str = 'itcast'
data_list = ['hadoop', 'spark', 'hive', 'python', 'hive']
data_tupe = ('hadoop', 'spark', 'hive', 'python', 'hive')
data_set = {'hadoop', 'spark', 'hive', 'python', 'hive'}
data_dict = {'id': 1, 'name': '张三', 'age': 20}字符串的转化
# 字符串的转化
print(list(data_str))
print(tuple(data_str))
print(set(data_str))
# 不能转为kv结构数据
# print(dict(data_str))列表转化
# 列表转化
print('------列表的转化---------')
print(str(data_list)) # '[]'
print(type(str(data_list)))
print(tuple(data_list)) # 元组数据不可修改
print(set(data_list)) # 去重
# 无法转化字典
# print(dict(data_list))
data_list2 = [[1,'a'],[2,'c']]
print(dict(data_list2))元组转化
# 元组转化
print('------元组的转化---------')
print(str(data_tupe))
print(list(data_tupe))
print(set(data_tupe))
# 嵌套的元组可以转为字典
data_tupe2 = ((1,'a'),(2,'b'))
print(dict(data_tupe2))集合转化
# 集合
print('------集合的转化---------')
print(str(data_set)) # '{}'
print(list(data_set))
print(tuple(data_set))
# print(dict(data_set))字典转化
# 字典转化
print('------字典的转化---------')
print(str(data_dict)) # ''
print(list(data_dict))
print(tuple(data_dict))
print(set(data_dict))# 列表转为字符串拼接方式
# str(list) 转化方式 '['a','c']'
# 将列表中的每个元素获取后拼接成字符串 使用join方法
data_list_str = '+'.join(data_list)
print(data_list_str)
data_tuple_str = ','.join(data_tupe)
print(data_tuple_str)
data_set_str = ','.join(data_set)
print(data_set_str)
data_dict_str = ','.join(data_dict)
print(data_dict_str)2.运算符
| 运算符 | 描述 | 支持的容器类型 |
|---|---|---|
| + | 合并 | 字符串、列表、元组 |
| * | 复制 | 字符串、列表、元组 |
| in | 元素是否存在 | 字符串、列表、元组、字典,集合 |
| not in | 元素是否不存在 | 字符串、列表、元组、字典,集合 |
# 运算符的使用
data_str1 = 'itcast'
data_str2 = 'aaaa'
data_list1 = ['hadoop', 'spark', 'hive', 'python', 'hive']
data_list2 = ['a','b']
data_tupe1 = ('hadoop', 'spark', 'hive', 'python', 'hive')
data_tupe2 = ('a','b')
data_set1 = {'hadoop', 'spark', 'hive', 'python', 'hive'}
data_set2 = {'a','b'}
data_dict1 = {'id': 1, 'name': '张三', 'age': 20}
data_dict2 = {'id': 2, 'name': '李四', 'age': 21}# + 运算符
print('+号运算')
print(data_str1+data_str2)
print(data_list1+data_list2)
print(data_tupe1+data_tupe2)
# print(data_set1+data_set2)
# print(data_dict1+data_dict2)
print('*号运算')
print(data_str1*2)
print(data_list1*2)
print(data_tupe1*2)
# print(data_set1*2)
# print(data_dict1*2)# 判断元素是否在容器总
print('in 语法使用')
if 'it' in data_str1:print('数据在字符串中')
if 'hive' in data_list1:print('数据在列表中')
if 'hive' in data_tupe1:print('数据在元组中')
if 'name' in data_dict2: # 支持key值判断print('key值数据在字典中')
if 'hive' in data_set1:print('数据在集合中')3.通用函数
| 编号 | 函数 | 描述 |
|---|---|---|
| 1 | len() | 计算容器中元素个数 |
| 2 | del 或 del() | 删除 |
| 3 | max() | 返回容器中元素最大值 |
| 4 | min() | 返回容器中元素最小值 |
| 5 | range(start, end, step) | 生成从start到end的数字,步长为 step,供for循环使用 |
| 6 | enumerate() | 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。 |
# 通用函数使用
data_str = 'itcast'
data_list = ['hadoop', 'spark', 'hive', 'python', 'hive']
data_tuple = ('hadoop', 'spark', 'hive', )
data_set = {'hadoop', 'spark', 'hive', 'python', }
data_dict = {'id': 1, 'name': '张三', 'age': 20}# 计算元素个数
print('len方法的使用')
print(len(data_str))
print(len(data_list))
print(len(data_tuple))
print(len(data_set))
print(len(data_dict))# 删除数据
# del 方法删除
print('del方法')
# 数据可修改并有对应下标可以使用下标删除
del data_list[1]
print(data_list)
del data_dict['name']
print(data_dict)# 数据计算方法 max min sum
print('数据值计算方法')
data_list2 = [1,2,3,10,15]
data_tuple2 = (1,2,3,10,15)
print(max(data_list2))
print(min(data_list2))
print(sum(data_list2))
print(sum(data_list2)/len(data_list2))
print('元组数据计算')
print(max(data_tuple2))
print(min(data_tuple2))
print(sum(data_tuple2))
print(sum(data_tuple2)/len(data_tuple2))
print('集合数据计算')
data_set = {1,2,3,10,15}
print(max(data_set))
print(min(data_set))
print(sum(data_set))
print(sum(data_set)/len(data_set))
print('字符串数据计算')
data_str = '1231256'
print(max(data_str))
print(min(data_str))
# print(sum(data_str))
# print(sum(data_str)/len(data_str))# range方法配合for循环使用
print('range方法使用')
data_list3= []
for i in range(1,10):print(i)data_list3.append(i)
print(data_list3)
print(set(data_list3))
print(tuple(data_list3))# 枚举方法 ,给元素数增加编号
data_str2 = enumerate(data_str)
print(data_str2)
# 可以将枚举数据转为列表
# print(list(data_str2))
# 使用for循环遍历枚举数据 # 枚举数取值后就不能在进行取值,也就是准尉list后不能在for循环
for i in data_str2:print(i)
for i in enumerate(data_list):print(i) # 获取的数据类型是元组print(type(i))
for i in enumerate(data_tuple):print(i)
for i in enumerate(data_dict):print(i)相关文章:

python方法
目录 公共方法 1.容器类型之间的转化 2.运算符 3.通用函数 公共方法 1.容器类型之间的转化 # 类型转化 data_str itcast data_list [hadoop, spark, hive, python, hive] data_tupe (hadoop, spark, hive, python, hive) data_set {hadoop, spark, hive, python,…...
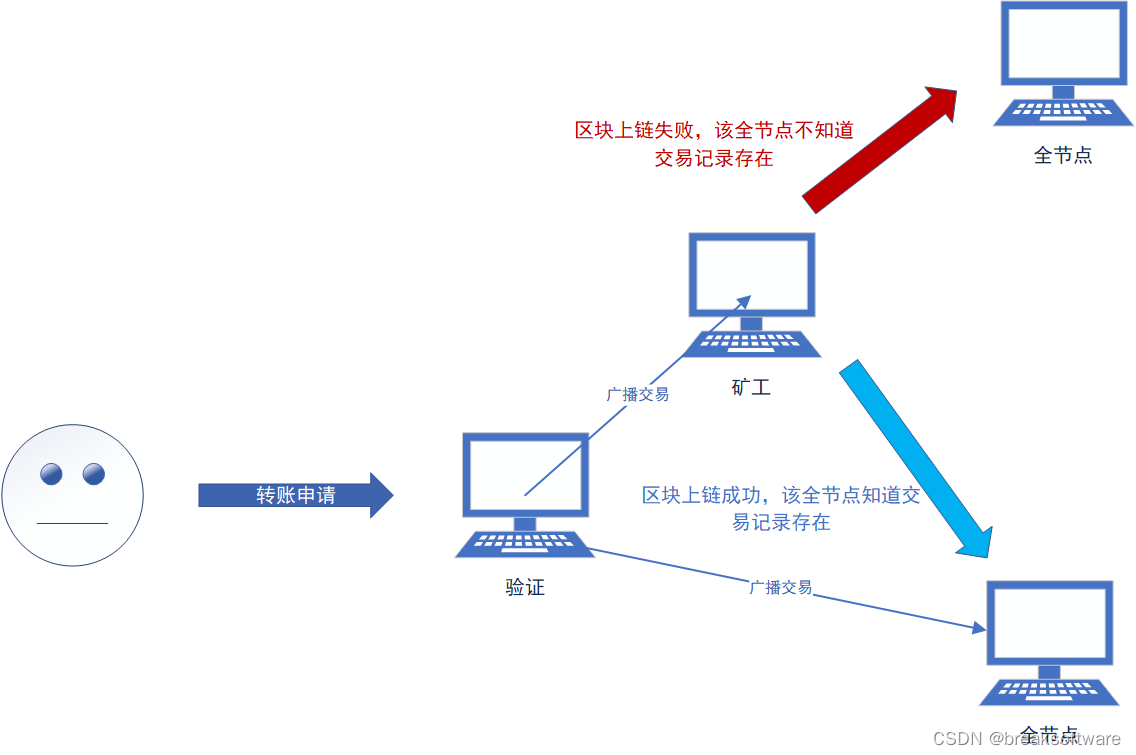
0基础学习区块链技术——去中心化
大纲 去验证的中心化验证者如何验证验证者为什么要去传播 去确认的中心化去存储的中心化 “去中心化”是区块链技术的核心。那么我们该如何理解这个概念呢? 我们可以假想在一次现实转账中,有哪些“中心化”的行为: 判断余额是否足够。即判断…...

索引的强大作用和是否创建的索引越多越好
在经常查询字段上创建索引。 在大数据的情况下,在索引上查找可以提交10倍以上甚至1000倍的速度。 实际测试,不在索引上查找用时12秒左右。建立索引,在索引上查找速度提高只耗时1.1秒左右。当然索引也是一把双刃剑,在一个表上创建索…...
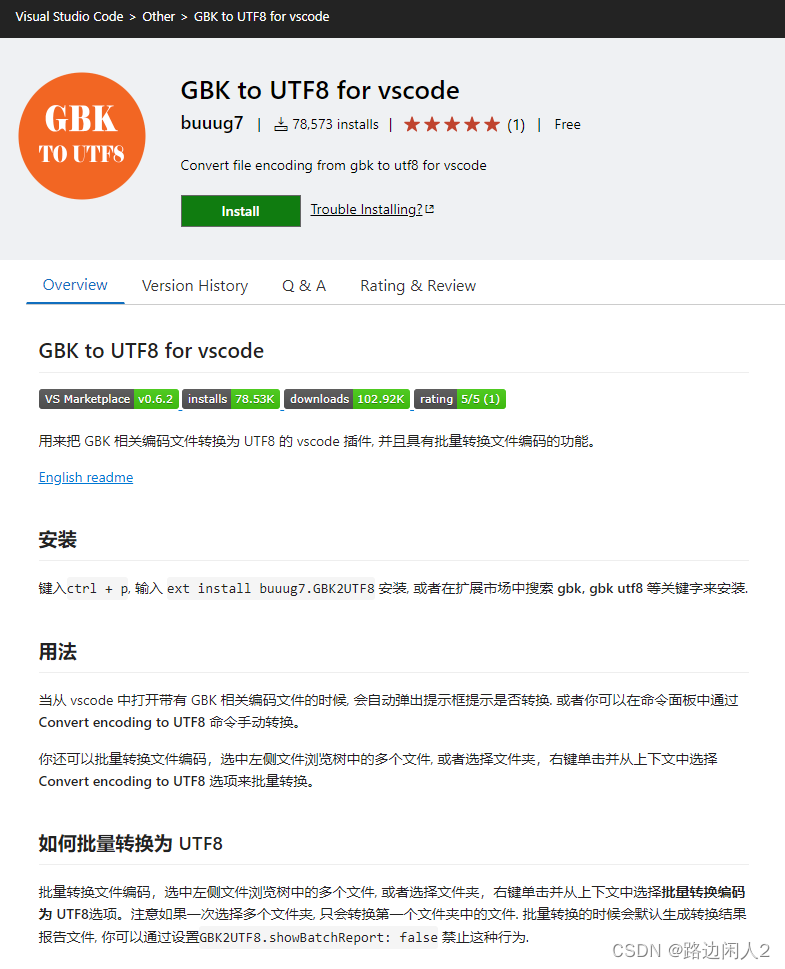
批量GBK转UTF-8
大家都有这样的需求,把GBK编码的源代码转换成utf-8编码的源代码。 毕竟现在UTF-8的支持是很好的。 以前一些旧代码是GBK的,尤其是里面的注释,如果不采用UTF-8,在vscode里面可能看着就是乱码。 试了各种工具,最后发现…...
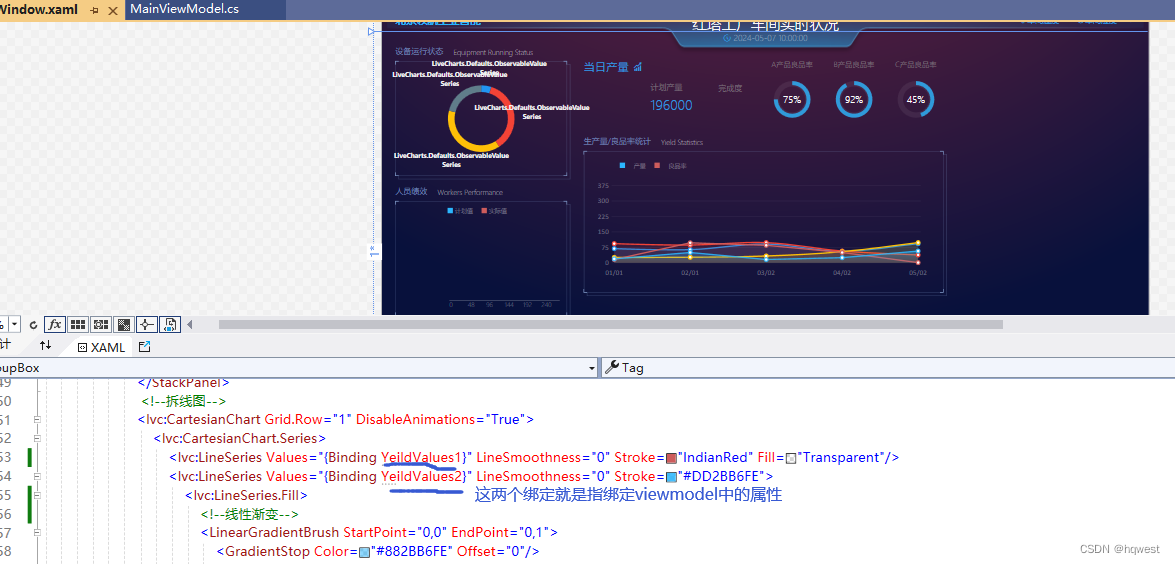
C#WPF数字大屏项目实战08--生产量/良品统计
1、区域划分 生产量/良品统计这部分位于第二列的第二行 2、livechart拆线图 定义折线图,如下: <lvc:CartesianChart> <lvc:CartesianChart.Series> <!--设置Series的类型为 Line 类型, 该类型提供了一些折线图的实现--> <lvc:LineSeries/>…...

22、matlab锯齿波、三角波、方波:rectpuls()函数/sawtooth()函数/square()函数
1、采样的非周期性矩形 语法 语法1:y rectpuls(t) 返回一个以数组 t 中指示的采样时间采样的连续非周期性单位高度矩形脉冲,该矩形脉冲以 t 0 为中心。 语法2:y rectpuls(t,w) 生成一个宽度为 w 的矩形 参数 t:采样时间 w:矩形宽度…...

手机和WINDOWS电脑蓝牙连接后怎样放歌,无法选择媒体音频 蓝牙媒体音频勾选不上
手机和电脑蓝牙连接后怎样放歌 要将手机通过蓝牙连接到电脑并播放音乐,可以按照以下步骤操作: 确保手机和电脑都支持蓝牙功能,并且蓝牙功能已经开启。 在电脑上,打开“设置”> “设备”> “蓝牙和其他设备”。 点击“添…...
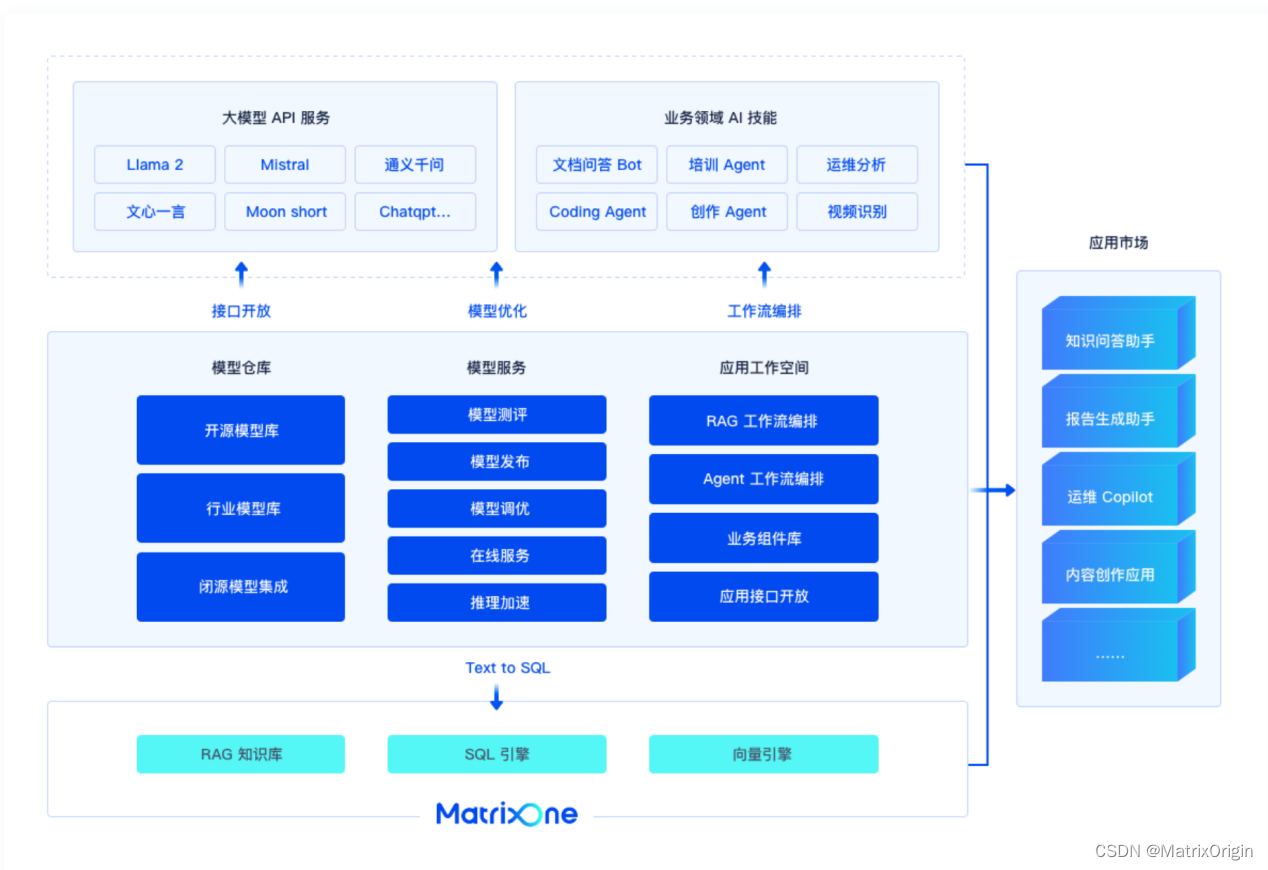
MatrixOne→MatrixOS:矩阵起源的创业史即将用“AI Infra”和“AI Platform”书写新章程
在数字化浪潮的推动下,MatrixOne的故事就像一部科技界的创业史诗,它始于一个简单而宏伟的梦想——构建一个能够支撑起新一代数字世界的操作系统。想象一下,在AIGC时代,数据流动如同“血液”,算法运转如同“心跳”&…...

vue3将自定义组件插入指定dom
需求简要描述 页面渲染了一个 id 为 videoPlayerId 的div盒子,代码自定义了一个名为CustomComponent 的组件,现在需要在vue3中,通过纯 js 的方式将组件 CustomComponent 插入 videoPlayerId 的div中,作为其子节点。 实现代码 C…...

flutter封装日历选择器(单日选择)
简单封装: 引入库:table_calendar import package:generated/l10n.dart; import package:jade/utils/JadeColors.dart; import package:jade/utils/Utils.dart; import package:util/easy_loading_util.dart; import package:flutter/material.dart; im…...

SwiftUI调用相机拍照
在 SwiftUI 中实现拍照功能,需要结合 UIViewControllerRepresentable 和 UIImagePickerController 来实现相机功能。下面是一个详细的示例,展示如何使用 SwiftUI 来实现拍照功能: 1. 创建一个 ImagePicker 组件 首先,创建一个 U…...
)
elasticsearch (dsl)
正排索引 和 倒排索引 正排索引:通过id ,查询content 倒排索引:通过content,查询到符合的 ids eg: 正排索引就是通过《静夜思》,找到整片文章。 倒排索引通过“明月”,找到《静夜思》 《望…...

聊聊大模型微调训练全流程的思考
前言 参考现有的中文医疗模型:MedicalGPT、CareGPT等领域模型的训练流程,结合ChatGPT的训练流程,总结如下: 在预训练阶段,模型会从大量无标注文本数据集中学习领域/通用知识;其次使用{有监督微调}(SFT)优化…...

Python变量符号:深入探索与实用指南
Python变量符号:深入探索与实用指南 在Python编程的世界中,变量符号扮演着至关重要的角色。它们不仅是存储数据的容器,更是构建复杂逻辑和算法的基础。然而,对于初学者来说,Python的变量符号可能会带来一些困惑和挑战…...

实验八 页面置换模拟程序设计
网上找到的程序得到的答案经过手算验证是错的,所以自己实现了一个,具体实现看代码吧,多余的操作已经去掉了。 #include <stdio.h> #include <stdlib.h> #include <stdbool.h>#define VM_PAGE 7 /*假设每个页面可以存放10…...

Spring类加载机制揭秘:深度解析“卸载”阶段
1. 引言 在Spring框架中,类的加载和卸载是一个复杂但至关重要的过程。加载主要涉及将类的字节码加载到JVM中,创建对应的Class对象,并准备使其可用的过程。而卸载,则是指当一个类不再被需要时,将其从JVM中清除…...
Jupyter Notebook快速搭建
Jupyter Notebook why Jupyter Notebook Jupyter Notebook 是一个开源的 Web 应用程序,允许你创建和分享包含实时代码、方程、可视化和解释性文本的文档。其应用包括:数据清洗和转换、数值模拟、统计建模、数据可视化、机器学习等等。 Jupyter Notebo…...
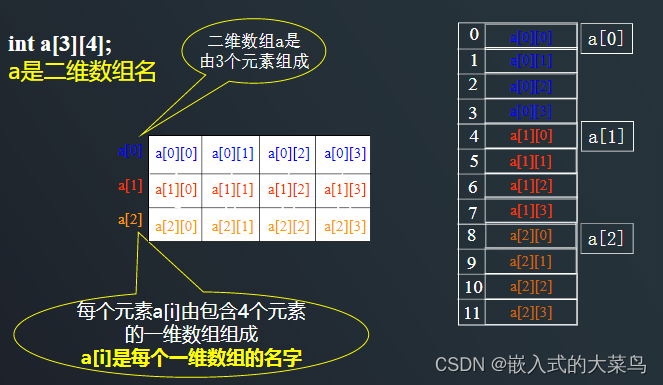
Linux C语言:数组的定义和初始化
一、数组 1、定义 在程序设计中,为了处理方便,把具有相同类型的若干变量按有序的形式组织起来,具有一定顺序关系的若干个变量的集合就是数组 。 2、特点 组成数组的各个变量称为数组的元素数组中各元素的数据类型要求相同元素在内存中是连…...

spring框架限制接口是否要登录过才能访问
1、引入spring 、spring boot依赖,这部分不再多说,正常开发spring boot项目就可以。 2、定义类,实现WebMvcConfigurer接口 package com.hmblogs.config;import com.hmblogs.config.web.interceptor.PortalTokenInterceptor; import org.spri…...

【全开源】废品回收垃圾回收小程序APP公众号源码PHP版本
🌟废品回收小程序:绿色生活的新助手🌱 一、引言 随着环保意识的逐渐提高,废品回收成为了我们日常生活中的重要一环。但是,如何更方便、高效地进行废品回收呢?今天,我要向大家推荐一款超级实用…...
✅)
计算机毕业设计:Python汽车销量数据挖掘与预测系统 Flask框架 scikit-learn 可视化 requests爬虫 AI 大模型(建议收藏)✅
博主介绍:✌全网粉丝10W,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌ > 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与…...

RC4算法逆向实战:从特征识别到魔改对抗
1. RC4算法基础与逆向特征识别 RC4算法作为经典的流加密算法,在CTF竞赛和恶意软件分析中频繁出现。我第一次逆向分析RC4加密的样本时,花了整整三天才确认算法类型——因为当时的我还不熟悉它的特征指纹。现在回头看,识别标准RC4其实有明确的规…...

COMSOL电磁超声仿真技术:基于5.6版本模型,精确检测L形铝板裂纹的电磁超声测量方法
COMSOL电磁超声仿真: Crack detection in L-shaped aluminum plate via electromagnetic ultrasonic measurements 版本为5.6,低于5.6的版本打不开此模型电磁超声检测(EMAT)在工业无损检测领域一直是个热门方向,最近在COMSOL 5.6上…...

注意力机制:AI 也会“走神“和“专注“——信息选择的智慧
注意力机制:AI 也会"走神"和"专注"——信息选择的智慧(Version B) 📚 《从零到一造大脑:AI架构入门之旅》专栏 专栏定位:面向中学生、大学生和 AI 初学者的科普专栏,用大白话和生活化比喻带你从零理解人工智能 本系列共 42 篇,分为八大模块: 📖…...

不只是“生成一张图“:2026年6款真正改变设计工作流的AI界面工具深度测评
AI界面生成工具正在经历从"生成单张界面"到"生成完整产品体验"的代际跃迁。本文深度拆解 UXbot、Figma Make、Google Stitch、Flowstep、Visily AI 和 Moonchild 共6款2026年代表性工具——从设计稿生成到原生代码输出,覆盖完整的产品交付能力谱…...

[WP]vulhub-dc1 flag全收集,靶机通关writeup超级详细,附带知识点讲解
2026/3/28 前言/提示: 本次记录的背景是作者本人积累2年多的基础知识,但是从来没有打过这种集成环境的靶机,所以仅供个人参考,尽管真的很想分享一些自己的思路也许能帮助读者,但是本次记录也大概率会出现手法惊奇&am…...

从 Agent 到 Skill:揭秘 AI 产品经理进阶的真正关键!
文章深入探讨了 AI 产品经理应如何理解和应用 Agent 与 Skill。文章指出,当前许多 AI 产品经理将注意力过度集中于 Agent,而忽略了 Skill 的重要性。实际上,Skill 是定义 Agent 在具体任务中行为、标准和质量的关键。文章详细阐述了 Skill 的…...

2026最新Node.js+NVM全平台安装教程
2026最新Node.jsNVM全平台安装教程 前言 在前端、后端全栈开发中,Node.js 是必不可少的运行环境,而不同项目往往依赖不同的 Node.js 版本,手动安装卸载不仅麻烦还容易冲突。 NVM(Node Version Manager) 作为 Node.j…...

Pandas读写Parquet文件避坑指南:pyarrow和fastparquet引擎怎么选?columns参数真能省内存吗?
Pandas读写Parquet文件避坑指南:引擎选择与内存优化实战解析 当你第一次听说Parquet格式能比CSV节省80%存储空间时,可能和我一样兴奋地立刻把项目里的数据全转成了.parquet后缀。但真正在生产环境部署时,却发现pd.read_parquet()在不同机器上…...

Cats定律测试终极指南:如何确保类型类实例的正确性
Cats定律测试终极指南:如何确保类型类实例的正确性 【免费下载链接】cats Lightweight, modular, and extensible library for functional programming. 项目地址: https://gitcode.com/gh_mirrors/ca/cats Cats是一个轻量级、模块化、可扩展的函数式编程库&…...