算法金 | 不愧是腾讯,问基础巨细节 。。。

大侠幸会,在下全网同名「算法金」
0 基础转 AI 上岸,多个算法赛 Top
「日更万日,让更多人享受智能乐趣」
最近,有读者参加了腾讯算法岗位的面试,面试着重考察了基础知识,并且提问非常详细。
特别是关于AdaBoost算法的问题,面试官问了很多。
今天,我们就来和大家探讨一下 AdaBoost 算法的相关知识。

1. 概要
1.1 Adaboost 的起源和发展
Adaboost,全称为 Adaptive Boosting,由 Freund 和 Schapire 于 1996 年提出,是一种迭代的机器学习算法。Adaboost 的核心思想是通过组合多个弱分类器(weak classifiers),构建一个强分类器(strong classifier)。这种方法在各种应用场景中取得了显著的成功,尤其在分类问题上表现突出。
1.2 Adaboost 的基本思想
Adaboost 的基本思想是根据上一次分类器的错误率,调整训练样本的权重,使得那些被错误分类的样本在后续的分类器中得到更多的关注。通过不断迭代和调整权重,最终得到一个综合了多个弱分类器的强分类器。
2. Adaboost 的核心知识点
2.1 基础概念
Adaboost 是一种集成学习方法,集成了多个弱分类器来提高整体的分类性能。每个弱分类器的权重根据其分类准确度进行调整。
2.2 工作原理
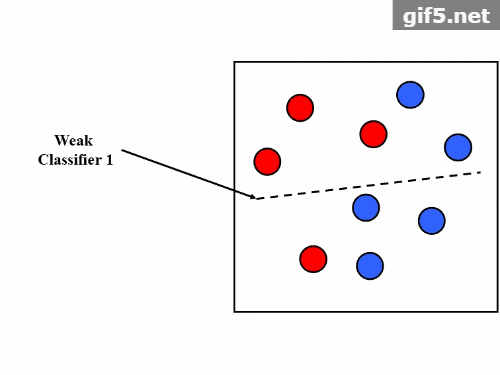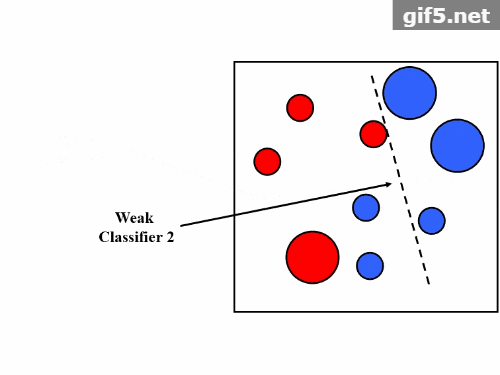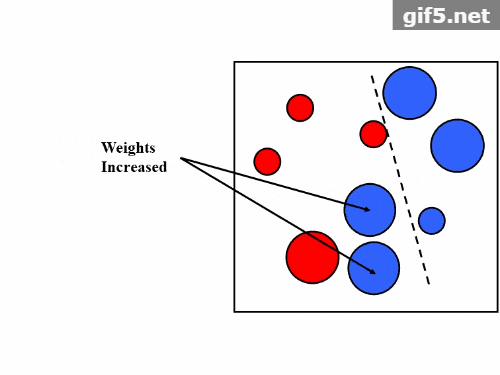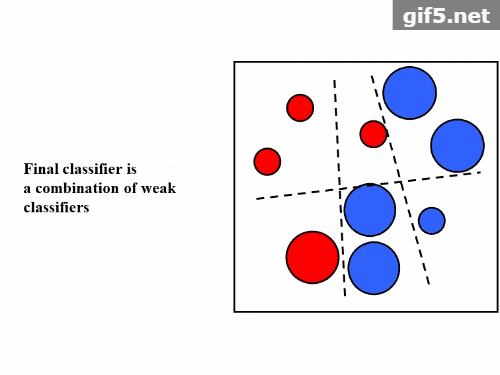
Adaboost 的工作原理可以分为以下几个步骤:
- 初始化样本权重。
- 训练弱分类器。
- 计算弱分类器的错误率。
- 更新样本权重,使错误分类的样本权重增加。
- 构建最终的强分类器。
2.3 算法步骤
- 初始化:为每个训练样本赋予相等的权重。
- 迭代:对于每次迭代:
- 训练一个弱分类器。
- 计算分类误差率。
- 更新样本权重,使误分类样本的权重增加。
- 计算该分类器的权重。
- 组合:将所有弱分类器组合成一个强分类器。
2.4 权重更新机制

2.5 弱分类器的选择
Adaboost 对弱分类器的选择没有严格的限制,可以使用决策树、线性分类器等。在实践中,决策树桩(决策树深度为1)常被用作弱分类器。

3. Adaboost 的数学基础
3.1 Adaboost 算法公式
Adaboost 的核心在于通过多次迭代训练弱分类器并组合这些弱分类器来构建一个强分类器。在每次迭代中,算法会调整样本的权重,使得那些被误分类的样本在后续的迭代中得到更多的关注。

3.2 损失函数
Adaboost 使用指数损失函数来衡量分类错误的程度。损失函数的形式为:
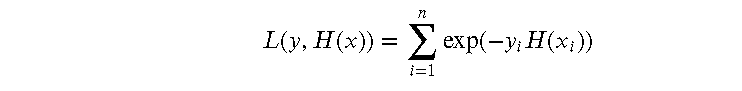
3.3 权重更新公式

代码示范
为了更好地理解 Adaboost 的数学基础,我们将在代码中实现这些公式。
import numpy as np# 初始化样本权重
n_samples = 100
weights = np.ones(n_samples) / n_samples# 假设我们有两个简单的弱分类器
def weak_classifier_1(x):return np.where(x[:, 0] > 0, 1, -1)def weak_classifier_2(x):return np.where(x[:, 1] > 0, 1, -1)# 模拟训练数据
X = np.random.randn(n_samples, 2)
y = np.where(X[:, 0] + X[:, 1] > 0, 1, -1)# 第一次迭代
pred_1 = weak_classifier_1(X)
error_1 = np.sum(weights * (pred_1 != y)) / np.sum(weights)
alpha_1 = 0.5 * np.log((1 - error_1) / error_1)
weights = weights * np.exp(-alpha_1 * y * pred_1)
weights /= np.sum(weights)# 第二次迭代
pred_2 = weak_classifier_2(X)
error_2 = np.sum(weights * (pred_2 != y)) / np.sum(weights)
alpha_2 = 0.5 * np.log((1 - error_2) / error_2)
weights = weights * np.exp(-alpha_2 * y * pred_2)
weights /= np.sum(weights)# 最终分类器
H = alpha_1 * weak_classifier_1(X) + alpha_2 * weak_classifier_2(X)
final_pred = np.sign(H)

4. 代码示范
4.1 数据准备
在这一部分,我们将使用一个内置的经典数据集——鸢尾花数据集(Iris Dataset)。这个数据集包含了三类鸢尾花的特征,常用于分类算法的演示。
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target# 数据集可视化
sns.pairplot(sns.load_dataset("iris"), hue="species")
plt.show()
说明:
- 我们使用 load_iris() 函数加载鸢尾花数据集,其中 X 为特征数据,y 为标签数据。
- 使用 Seaborn 的 pairplot 函数可视化数据集,展示不同特征之间的关系。
4.2 Adaboost 算法实现
我们将使用 Scikit-learn 的 AdaBoostClassifier 来实现 Adaboost 算法,并进行训练和预测。
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import pandas as pd
import seaborn as sns# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 初始化 Adaboost 分类器
adaboost = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=1),n_estimators=50,learning_rate=1.0,random_state=42
)# 训练模型
adaboost.fit(X_train, y_train)# 预测
y_pred = adaboost.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f'分类准确率: {accuracy:.2f}')
说明:
- 我们将数据集分为训练集和测试集,使用 train_test_split 函数,测试集占 30%。
- 初始化 AdaBoostClassifier,设置基本分类器为决策树桩(DecisionTreeClassifier),迭代次数为 50。
- 训练模型并使用测试集进行预测,计算并输出分类准确率。
运行后输出:
分类准确率: 1.00
4.3 结果分析
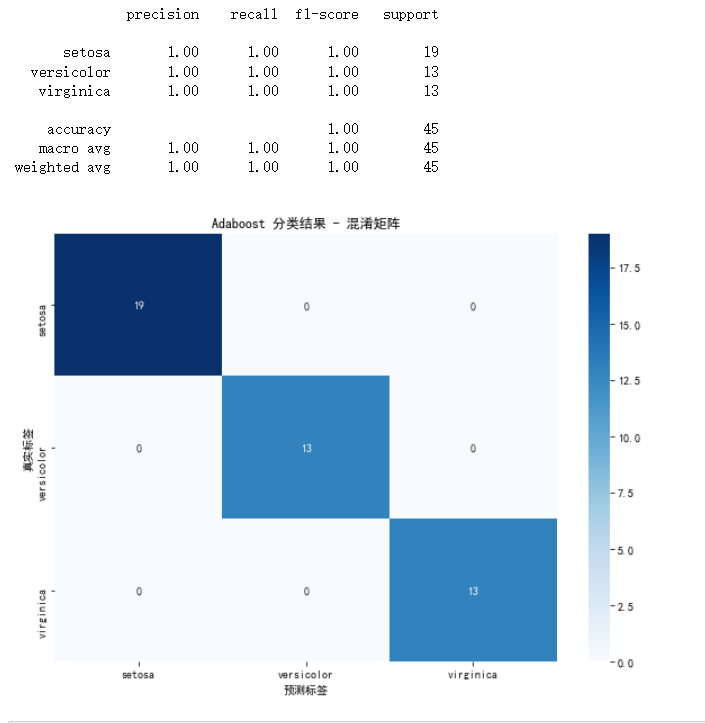
我们将进一步分析模型的性能,包括分类报告和混淆矩阵,并对结果进行可视化。
# 打印分类报告
print(classification_report(y_test, y_pred, target_names=iris.target_names))# 混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
conf_matrix_df = pd.DataFrame(conf_matrix, index=iris.target_names, columns=iris.target_names)# 混淆矩阵可视化
plt.figure(figsize=(10, 7))
sns.heatmap(conf_matrix_df, annot=True, cmap='Blues')
plt.title('Adaboost 分类结果 - 混淆矩阵')
plt.xlabel('预测标签')
plt.ylabel('真实标签')
plt.show()
说明:
- 打印分类报告,包括每个类别的精确率、召回率和 F1 分数,帮助我们评估模型性能。
- 计算混淆矩阵,并将其转换为 DataFrame 格式,便于可视化。
- 使用 Seaborn 的 heatmap 函数可视化混淆矩阵,展示预测标签与真实标签之间的对应关系。
通过代码示范和结果分析,我们可以直观地了解 Adaboost 算法的实现过程及其在分类问题上的表现。
5. Adaboost 的优缺点
5.1 优点
- 高准确率:Adaboost 通过集成多个弱分类器,显著提高了分类准确率。
- 简单易用:Adaboost 的实现和应用相对简单,且无需对弱分类器进行大量调整。
- 鲁棒性:对噪声数据和异常值具有较高的鲁棒性,能够很好地处理复杂的分类问题。
- 无偏性:不容易过拟合,尤其在弱分类器是简单模型的情况下。
5.2 缺点
- 对噪声敏感:在数据中存在大量噪声时,Adaboost 的性能可能会下降,因为噪声数据会被赋予较高的权重。
- 计算复杂度较高:随着迭代次数的增加,计算量也会增加,尤其在处理大规模数据时。
- 需要大量的弱分类器:为了获得理想的分类效果,通常需要集成大量的弱分类器。
5.3 适用场景
- 文本分类:Adaboost 在自然语言处理中的文本分类任务中表现良好。
- 图像识别:用于识别图像中的目标,如人脸识别等。
- 生物信息学:在基因表达数据分类等生物信息学问题中具有广泛应用。
- 金融风控:用于信用评分、欺诈检测等金融领域的风险控制。

[ 抱个拳,总个结 ]
在本文中,我们详细介绍了 Adaboost 算法的核心概念和应用。首先,我们了解了 Adaboost 的起源和基本思想。接着,我们深入探讨了 Adaboost 的工作原理、算法步骤、权重更新机制和弱分类器的选择,并通过代码示范展示了其具体实现过程。
我们还介绍了 Adaboost 的数学基础,包括算法公式、损失函数和权重更新公式,使大侠们对其理论有了更深入的理解。在代码示范部分,我们结合武侠元素的数据集,详细展示了 Adaboost 算法在实际应用中的操作步骤,并对结果进行了可视化和分析。
随后,我们讨论了 Adaboost 的优缺点及其适用场景,帮助大侠们在实际应用中更好地评估和选择该算法。最后,通过具体的经典应用案例,如图像识别和文本分类,我们展示了 Adaboost 在不同领域的强大能力和广泛应用。
希望通过本文的介绍,大侠们能够更全面地了解和掌握 Adaboost 算法,在今后的学习和实践中,灵活运用这一强大的机器学习工具。

[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖
相关文章:
算法金 | 不愧是腾讯,问基础巨细节 。。。
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 最近,有读者参加了腾讯算法岗位的面试,面试着重考察了基础知识,并且提问非常详细。 特别是关于Ada…...
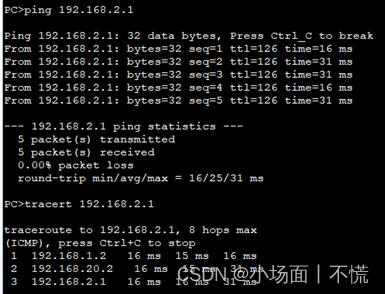
实验9 浮动静态路由配置
--名称-- 一、 原理描述二、 实验目的三、 实验内容四、 实验配置五、 实验步骤 一、 原理描述 浮动静态路由也是一种特殊的静态路由,主要考虑链路冗余。浮动静态路由通过配置一条比主路由优先级低的静态路由,用于保证在主路由失效的情况下,…...
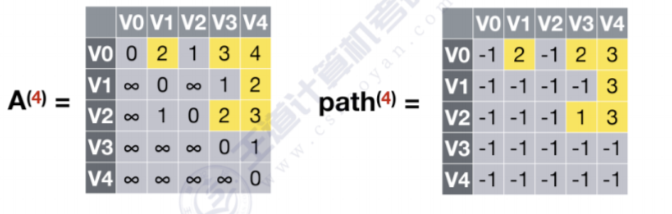
多源最短路径算法–Floyd算法
多源最短路径算法–Floyd算法 Floyd算法是为了求出每一对顶点之间的最短路径 它使用了动态规划的思想,将问题的求解分为了多个阶段 先来个例子,这是个有向图 Floyd算法的运行需要两个矩阵 最短路径矩阵 从当前这个状态看各顶点间的最短路径长度 例…...
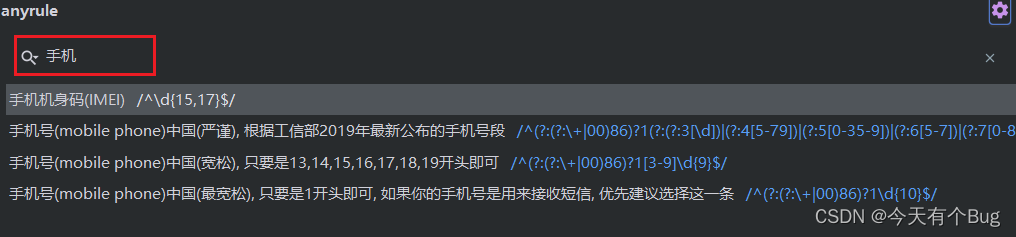
使用Redis缓存实现短信登录逻辑,手机验证码缓存,用户信息缓存
引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency> 加配置 spring:redis:host: 127.0.0.1 #redis地址port: 6379 #端口password: 123456 #密码…...

探索未来制造,BFT Robotics引领潮流
“买机器人,上BFT” 在这个快速变化的时代,创新和效率是企业发展的关键。BFT Robotics,作为您值得信赖的合作伙伴,专注于为您提供一站式的机器人采购和自动化解决方案。 产品系列: 协作机器人:安全、灵活、…...
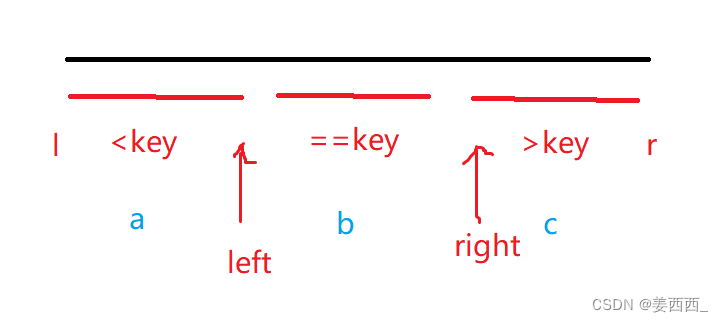
数组中的第K个最大元素 ---- 分治-快排
题目链接 题目: 分析: 这道题很明显是一个top-K问题, 我们很容易想到用堆排序来解决, 堆排序的时间复杂度是O(N*logN), 不符合题意, 所以我们可以用另一种方法:快速选择算法, 他的时间复杂度为O(N)快速选择算法, 其实是基于快排, 进行修改而成, 我们还是使用将"将数组分…...

函数或变量 ‘tfrstft‘ 无法识别
参考博客 Matlab时频工具箱tftb下载及安装_tftb工具箱-CSDN博客 解决。...

在推荐四款软件卸载工具,让流氓软件无处遁形
Revo Uninstaller Revo Uninstaller是一款电脑软件、浏览器插件卸载软件,目前已经有了17年的历史了。可以扫描所有window用户卸载软件后的残留物,并及时清理,避免占用电脑空间。 Revo Uninstaller可以通过命令行卸载软件,可以快速…...
)
「前端+鸿蒙」核心技术HTML5+CSS3(十一)
1、CSS3 简介 CSS3 是层叠样式表的最新标准,它引入了许多新特性来增强网页的表现力。CSS3 不仅增强了现有CSS属性的功能,还引入了新的布局方式、动画、渐变、阴影、边框效果等。 2、CSS3 长度单位 CSS3 引入了一些新的单位,包括但不限于: vw(视口宽度的百分比)vh(视口…...

【高频】如何优化一个SQL语句
使用合适的索引:确保查询中涉及的字段上有合适的索引,避免全表扫描。可以通过 EXPLAIN 命令来查看查询执行计划,判断是否使用了索引。 避免使用通配符查询:尽量避免在查询条件中使用通配符(如 %)ÿ…...
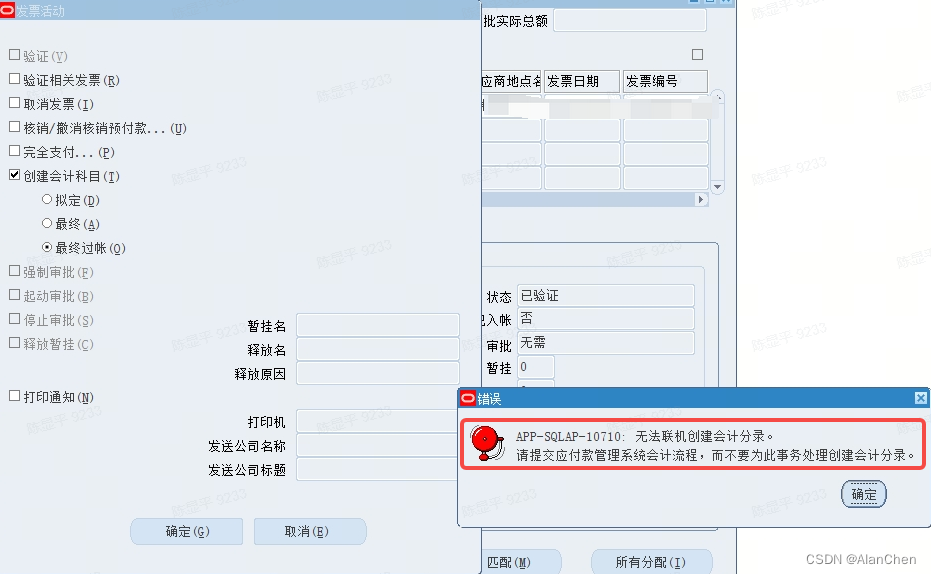
Oracle EBS AP发票创建会计科目提示:APP-SQLAP-10710:无法联机创建会计分录
系统版本 RDBMS : 12.1.0.2.0 Oracle Applications : 12.2.6 问题症状: 提交“创建会计科目”请求提示错误信息如下: APP-SQLAP-10710:无法联机创建会计分录。 请提交应付款管理系统会计流程,而不要为此事务处理创建会计分录解决方法 数据修复SQL脚本: UPDATE ap_invoi…...

T-Pot多功能蜜罐实践@debian12@FreeBSD
T-Pot介绍 T-Pot是一个集所有功能于一身的、可选择分布式的多构架(amd64,arm64)蜜罐平台,支持20多个蜜罐和很多可视化选项,使用弹性堆栈、动画实时攻击地图和许多安全工具来进一步改善欺骗体验。GitHub - telekom-sec…...

Sed流编辑器总结
sed 是 Unix 和 Linux 系统中的一个强大的流编辑器。它用于对文本进行基本的修改和处理。以下是关于 sed 的详细解说,包括其基本语法,常见用法和一些高级用法。 基本语法 sed [选项] 命令 输入文件常见选项 -e:指定要执行的 sed 命令。-f&a…...

智合同丨AIGC如何助力合同智能应用
#AIGC #合同智能应用 #智合同 AIGC,即人工智能生成内容技术(Artificial Intelligence Generated Content),近期在各个领域发展可谓是如火如荼,那么它在合同智能应用方面可以提供哪些助力? 让我们和智合…...

CSRF 令牌的生成过程和检查过程
在 Django 中,CSRF 令牌的生成和检查过程是通过 Django 的 CSRF 中间件 (CsrfViewMiddleware) 和模板标签 ({% csrf_token %}) 自动处理的。以下是详细的生成和检查过程: CSRF 令牌的生成过程 用户访问页面: 当用户第一次访问页面时,Django 会为用户创建一个会话。如果用户…...

计算机网络学习记录 网络层 Day4(下)
计算机网络学习记录 网络层 Day4 (下) 你好,我是Qiuner. 为记录自己编程学习过程和帮助别人少走弯路而写博客 这是我的 github https://github.com/Qiuner ⭐️ gitee https://gitee.com/Qiuner 🌹 如果本篇文章帮到了你 不妨点个赞吧~ 我…...
3、前端本地环境搭建
前端本地环境搭建 安装node [node下载地址] https://nodejs.org/en/download/prebuilt-installer 选择LTS的版本进行下载 下载后直接双击点击,选择自己想要安装到的目录一直点下一步即可(建议不要安装到c盘) 安装完成后配置环境变量&am…...

Python爬取城市空气质量数据
Python爬取城市空气质量数据 一、思路分析1、寻找数据接口2、发送请求3、解析数据4、保存数据二、完整代码一、思路分析 目标数据所在的网站是天气后报网站,网址为:www.tianqihoubao.com,需要采集武汉市近十年每天的空气质量数据。先看一下爬取后的数据情况: 1、寻找数据…...

【MyBatisPlus条件构造器】
文章目录 什么是条件构造器?使用步骤1. 引入 MyBatisPlus 依赖2. 创建实体类3. 使用条件构造器查询4. 执行查询 示例代码 什么是条件构造器? 条件构造器是 MyBatisPlus 提供的一种灵活的查询条件设置方式,它可以帮助开发者构建复杂的查询条件…...

容器多机部署eureka及相关集群服务出现 Request execution failed with message: AuthScheme is null
预期部署方案:两个eureka三个相关应用 注册时应用出现:Request execution failed with message: Cannot invoke “Object.getClass()” because “authScheme” is null,一开始认为未正确传递eureka配置的账户密码,例:…...

Windows XP图标主题完整指南:如何为现代Linux系统注入经典怀旧风格
Windows XP图标主题完整指南:如何为现代Linux系统注入经典怀旧风格 【免费下载链接】Windows-XP Remake of classic YlmfOS theme with some mods for icons to scale right 项目地址: https://gitcode.com/gh_mirrors/win/Windows-XP 还在为现代Linux桌面环…...

华为MateBook D 2018 BIOS隐藏选项实战:手动解锁TPM2.0迎战Win11
1. 为什么需要手动解锁TPM2.0 去年Windows 11正式发布时,很多华为MateBook D 2018用户都遇到了一个尴尬问题:明明硬件配置完全达标,却因为BIOS里找不到TPM2.0开关而无法升级。我当时也卡在这个环节整整两天,直到发现原来TPM功能被…...

auto-rednote:自动化信息整理工具的设计原理与实战应用
1. 项目概述与核心价值 最近在整理个人笔记和知识库时,我遇到了一个几乎所有内容创作者和开发者都会头疼的问题:如何高效地将散落在各处的、格式不一的“红色笔记”(比如微信收藏、网页剪藏、临时备忘录)自动整理成结构化的、可检…...

终极指南:如何用Python轻松解锁QQ音乐资源,打造个人音乐库
终极指南:如何用Python轻松解锁QQ音乐资源,打造个人音乐库 【免费下载链接】MCQTSS_QQMusic QQ音乐解析 项目地址: https://gitcode.com/gh_mirrors/mc/MCQTSS_QQMusic 你是否曾遇到过这样的困扰?在QQ音乐上发现了一首心仪的歌曲&…...

私有云时代来临:AI NAS如何重塑你的数字生活?
超越传统存储,打造你的私人云端 在信息爆炸的时代,随着个人存储需求的激增和变化,以及个体对数据隐私和安全性的日益重视,外加AI的技术加持,一种大家也许并不熟知的存储解决方案——NAS迎来了发展机遇。 NAS是Network …...

Arccos Golf数据获取与Python分析实战:开源工具包逆向工程API
1. 项目概述:一个高尔夫数据爱好者的开源工具箱 如果你和我一样,既是个高尔夫爱好者,又对数据分析和自动化工具着迷,那么你很可能听说过Arccos Golf这个平台。它是一个通过传感器和手机应用来追踪每一次击球、分析球场表现的系统。…...

低成本传感器动态校准:SenDaL框架原理与应用
1. 低成本传感器校准的行业痛点与SenDaL解决方案在智能家居和工业物联网领域,我们经常面临一个尴尬的境地:高精度传感器价格昂贵难以大规模部署,而低成本传感器的数据质量又令人担忧。以PM2.5监测为例,专业级β射线传感器的价格可…...

【高光谱图像数据处理实战】基于Python的ENVI图像交互式裁剪与光谱数据预处理
前言在处理高光谱图像数据(Hyperspectral Imaging, HSI)时,我们常常需要面对两个核心问题:一是如何从庞大的三维数据立方体(Data Cube)中高效、准确地提取感兴趣区域(ROI)…...

GDB与QEMU实现的可逆调试技术详解
1. 可逆调试技术概述可逆调试(Reversible Debugging)是一种革命性的调试技术,它允许开发者在程序执行过程中不仅能够向前执行,还能向后追溯程序状态。想象一下,如果你在调试时发现了一个内存损坏问题,传统的…...

2026出海技术观察:云API接口迭代的能力边界与业务增量空间
摘要:2026年AI出海告别粗放扩张,底层技术适配能力成为竞争核心。云API接口迭代持续优化跨境对接、算力调度与合规适配体系,补齐传统出海技术短板,为企业全球化精细化运营提供坚实支撑。一、2026 AI出海新格局:底层接口…...