使用智谱 GLM-4-9B 和 SiliconCloud 云服务快速构建一个编码类智能体应用
本篇文章我将介绍使用智谱 AI 最新开源的 GLM-4-9B 模型和 GenAI 云服务 SiliconCloud 快速构建一个 RAG 应用,首先我会详细介绍下 GLM-4-9B 模型的能力情况和开源限制,以及 SiliconCloud 的使用介绍,最后构建一个编码类智能体应用作为测试。
本文首发自博客 使用智谱 GLM-4-9B 和 SiliconCloud 云服务快速构建一个编码类智能体应用
我的新书《LangChain编程从入门到实践》 已经开售!推荐正在学习AI应用开发的朋友购买阅读,此书围绕LangChain梳理了AI应用开发的范式转变,除了LangChain,还涉及其他诸如 LIamaIndex、AutoGen、AutoGPT、Semantic Kernel等热门开发框架。

GLM-4-9B 有多强
智谱家 GLM-4-9B 模型的发布,可以称得上大模型开源领域的又一个里程碑事件,除了开源行为本身值得肯定,我觉得开源出来的模型可以接入线上应用直接使用,可能对我们做应用层的开发者意义更大。话不多说,看 GLM-4-9B 的介绍:
首先 GLM-4-9B 模型结构与 GLM-3-9B 变化不大,主要是模型层数由 28 增加到 40,词表大小由 65024 扩充到 151552、支持的上下文长度支持从 32K、128K 扩展到 128K、1M(GLM-4-9B-Chat-1M),做应用最关注的就是长上下文(多轮对话记忆保持、各种阅读助手、长文本理解等常见场景)能力和 Function Call 能力(工具调用,构建智能体应用的基础)。
1M 的上下文长度(约 200 万中文字符)方面,GLM-4-9B 在大海捞针测试中全绿。

不过根据英伟达研究团队最近新提出的名为RULER的新基准,这里选用的测试方法(测试的 LWM 声称上下文长度 1M,实际不到 4K)测出来的结果有水分,这个我还会自己测试下。
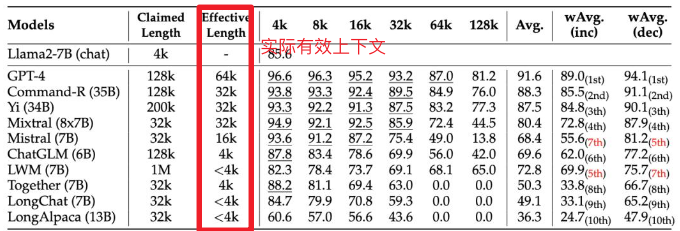
Function Call 能力也属于 gpt-4-turbo 级别,使用 Berkeley Function-Calling Leaderboard 测试集,这个对我来说比较有说服力,有兴趣的可以看看测试集设计,不过毕竟测试集公开,混在训练集里也不好说,这个我也按照相同思路设计了对应的私有中文测试集,引入之前也会再跑一次作为交叉验证。
| Model | Overall Acc. | AST Summary | Exec Summary | Relevance |
|---|---|---|---|---|
| Llama-3-8B-Instruct | 58.88 | 59.25 | 70.01 | 45.83 |
| gpt-4-turbo-2024-04-09 | 81.24 | 82.14 | 78.61 | 88.75 |
| ChatGLM3-6B | 57.88 | 62.18 | 69.78 | 5.42 |
| GLM-4-9B-Chat | 81.00 | 80.26 | 84.40 | 87.92 |
虽然开源,但也存在限制,就是学术研究免费,商业用途需要登记且必须遵守相关条款和条件,详见 Github 项目介绍:https://github.com/THUDM/GLM-4
SiliconCloud 有多好用
SiliconCloud 是硅基流动推出的 GenAI 云服务,这是国内同类产品中我体验最好的一家,便宜且推理速度还快,国外已经有很多类似服务了,比如 Banana, Replicate, Beam, Modal 、OctoAI、ModelZ、BentoML等,这类服务主要用于私有模型或常见开源模型托管,通过它们自研的推理加速引擎、大模型基础设施优化能力,大幅降低大模型的部署及推理成本,降低 AI 应用的成本,加速 AI 产品的落地 。
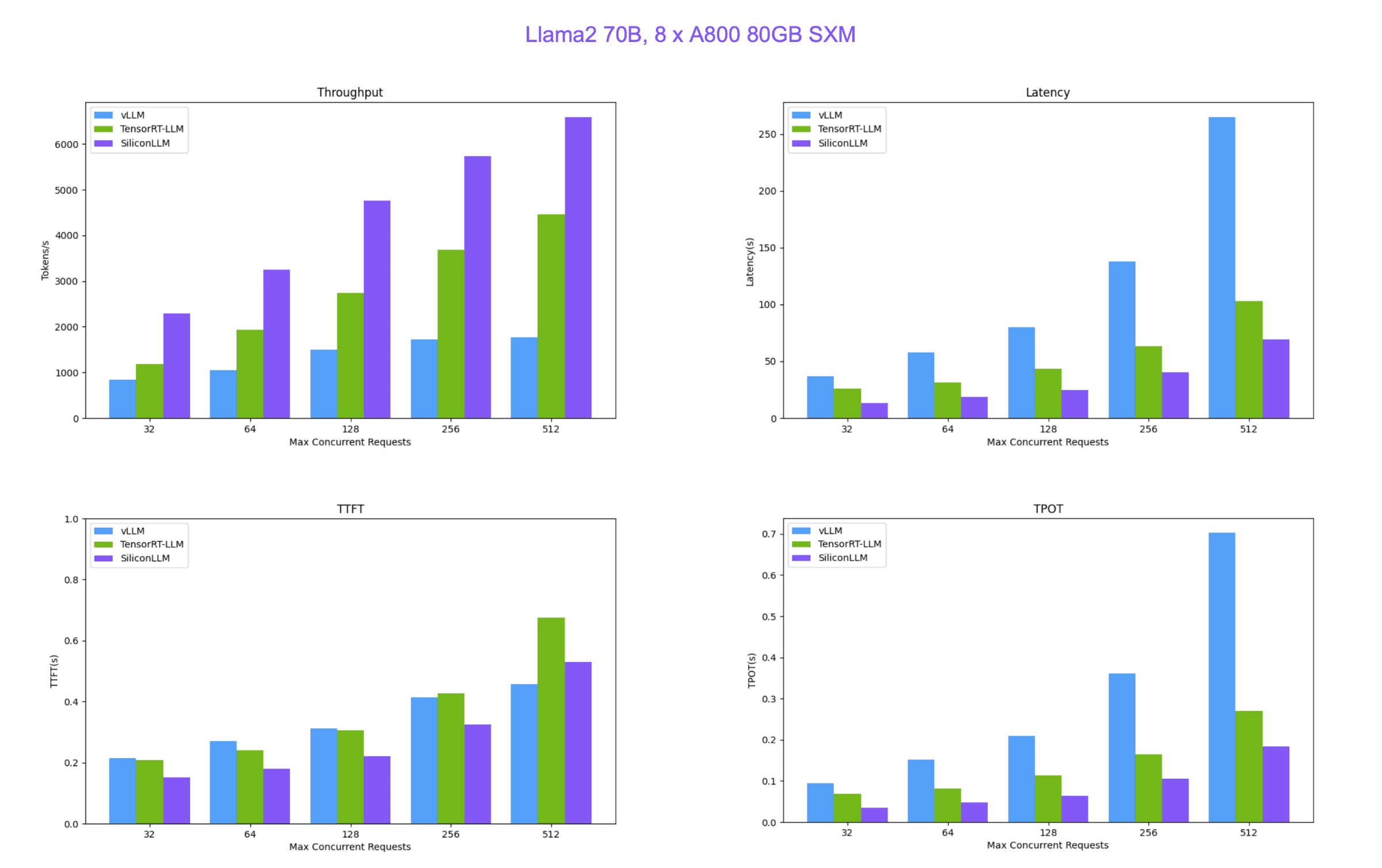
SiliconCloud 便宜又快的原因就在于硅基流动自研的 LLM 推理加速引擎 SiliconLLM ,支持 Llama3、Mixtral、DeepSeek、Baichuan、ChatGLM、Falcon、01-ai(零一万物开源的模型)、GPT-NeoX 等模型加速,下面是 SiliconLLM 与推理框架vLLM(伯克利大学 LMSYS 组织开源)、Tensorrt-LLM(英伟达开源)的性能比较。
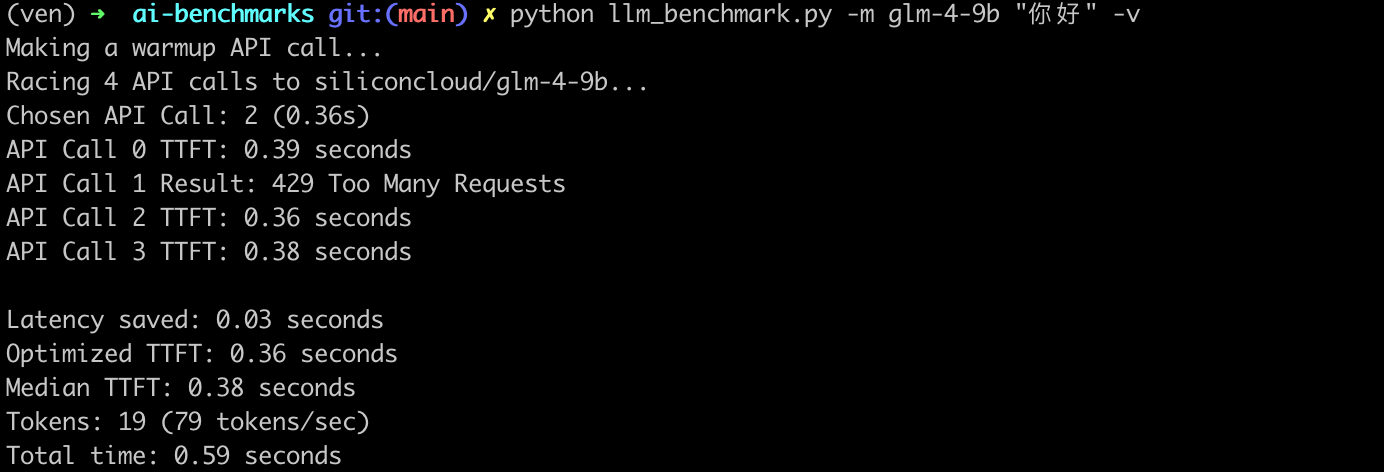
最后补充一组我自己本地随手测试的 API 调用服务吞吐:
- 首次响应时间与最快响应时间差(
Latency saved 0.03s): 表示首次响应时间与最快响应时间之间的差异,这个指标可以反映出大模型 API 服务在处理请求时的波动。 - 优化后的首 token 响应时间(
Optimized TTFT 0.36s):是指在多次请求中,最快的一次首 token 响应时间。 - 首 token 响应时间中位数(
Median TTFT 0.03s):是指在所有请求中,首 token 响应时间的中位数,即一半的请求首 token 响应时间比这个值快,另一半比这个值慢。中位数可以提供一个更稳健的性能指标,因为它不受极端值的影响。 - 生成的 token 数量(
Tokens: 19):表示在请求过程中生成的 token 总数。 - token 生成速率(
79 tokens/sec): 表示每秒生成的 Token 数量,这是衡量大模型 API 服务处理能力的一个指标。 - 总时间(
Total time: 0.59s): 表示从开始发送 HTTP 请求到接收到最后一个 token 的时间,这是整个请求处理过程的总耗时
构建编码类智能体应用
首先前往官网 👉 https://cloud.siliconflow.cn/auth/login 注册 SiliconCloud 账号,无需手机号,邮箱注册即可(值得一提,新用户注册可以得到 42 元免费额度用于体验,相当于 3 亿 tokens),按流程注册,保存好生成的 API-KEY。
开始之前先设置好 SiliconCloud 的 GLM-4-9B-Chat 模型, API 调用方式也与 OpenAI 兼容 ,所以可以直接使用 OpenAI SDK (langchain_openai)来访问 SiliconCloud 上的任意模型。
import os
from langchain_openai import ChatOpenAI
sc_api_key = os.getenv("SC_API_KEY")
llm = ChatOpenAI(base_url="https://api.siliconflow.cn/v1",api_key=sc_api_key,model="zhipuai/glm4-9B-chat")
后续代码和这篇文章 DeepSeek-V2 到底有多强?写一个 AI 编码 Agent 测测看(附详细代码)基本一致,也有着详细解释过程,这里不再赘述,后台回复 DeepSeek可获取完整代码。
相关文章:
使用智谱 GLM-4-9B 和 SiliconCloud 云服务快速构建一个编码类智能体应用
本篇文章我将介绍使用智谱 AI 最新开源的 GLM-4-9B 模型和 GenAI 云服务 SiliconCloud 快速构建一个 RAG 应用,首先我会详细介绍下 GLM-4-9B 模型的能力情况和开源限制,以及 SiliconCloud 的使用介绍,最后构建一个编码类智能体应用作为测试。…...
关于vue2 antd 碰到的问题总结下
1.关于vue2 antd 视图更新问题 1.一种强制更新 Vue2是通过用Object…defineProperty来设置数据的getter和setter实现对数据和以及视图改变的监听的。对于数组和对象这种引用类型来说,getter和setter无法检测到它们内部的变化。用这种 this.$set(this.form, "…...

常见的api:Runtime Object
一.Runtiem的成员方法 1.getRuntime() 当前系统的运行环境 2.exit 停止虚拟机 3.avaliableProcessors 获取Cpu线程的参数 4.maxMemory JVM能从系统中获取总内存大小(单位byte) 5.totalMemory JVM已经从系统中获取总内大小(单位byte) 6.freeMemory JVM剩余内存大小(…...

Linux守护进程揭秘-无声无息运行在后台
在Linux系统中,有一些特殊的进程悄无声息地运行在后台,如同坚实的基石支撑着整个系统的运转。它们就是众所周知的守护进程(Daemon)。本文将为你揭开守护进程的神秘面纱,探讨它们的本质特征、创建过程,以及如何重定向它们的输入输出…...
模型基础笔记0.1.096)
python-Bert(谷歌非官方产品)模型基础笔记0.1.096
python-bert模型基础笔记0.1.015 TODOLIST官网中的微调样例代码Bert模型的微调限制Bert的适合的场景Bert多语言和中文模型Bert模型两大类官方建议模型Bert模型中名字的含义Bert模型包含的文件Bert系列模型参数介绍微调与迁移学习区别Bert微调的方式Pre-training和Fine-tuning区…...

Linux的命令补全脚本
一 linux命令补全脚本 Linux的命令补全脚本是一个强大且高效的工具,它能够极大地提高用户在命令行界面的工作效率。这种脚本通过自动完成部分输入的命令或参数,帮助用户减少敲击键盘的次数并降低出错率。接下来将深入探讨其工作原理、安装方式以及如何自…...

前端 JS 经典:打印对象的 bug
1. 问题 相信这个 console 打印语句的 bug,其实小伙伴们是遇到过的,就是你有一个对象,通过 console,打印一次,然后经过一些处理,再通过 console 打印,发现两次打印的结果是一样的,第…...

大型语言模型简介
大型语言模型简介 大型语言模型 (LLM) 是一种深度学习算法,可以使用非常大的数据集识别、总结、翻译、预测和生成内容。 文章目录 大型语言模型简介什么是大型语言模型?为什么大型语言模型很重要?什么是大型语言模型示例?大型语…...

javaWeb4 Maven
Maven-管理和构建java项目的工具 基于POM的概念 1.依赖管理:管理项目依赖的jar包 ,避免版本冲突 2.统一项目结构:比如统一eclipse IDEA等开发工具 3.项目构建:标准跨平台的自动化项目构建方式。有标准构建流程,能快速…...

eclipse连接后端mysql数据库并且查询
教学视频:https://www.bilibili.com/video/BV1mK4y157kE/?spm_id_from333.337.search-card.all.click&vd_source26e80390f500a7ceea611e29c7bcea38本人eclipse和up主不同的地方如下,右键项目名称->build path->configure build path->Libr…...
Windows mstsc
windows mstsc 局域网远程计算机192.168.0.113为例,远程控制命令mstsc...
百度/迅雷/夸克,网盘免费加速,已破!
哈喽,各位小伙伴们好,我是给大家带来各类黑科技与前沿资讯的小武。 之前给大家安利了百度网盘及迅雷的加速方法,详细方法及获取参考之前文章: 刚刚!度盘、某雷已破!速度50M/s! 本次主要介绍夸…...
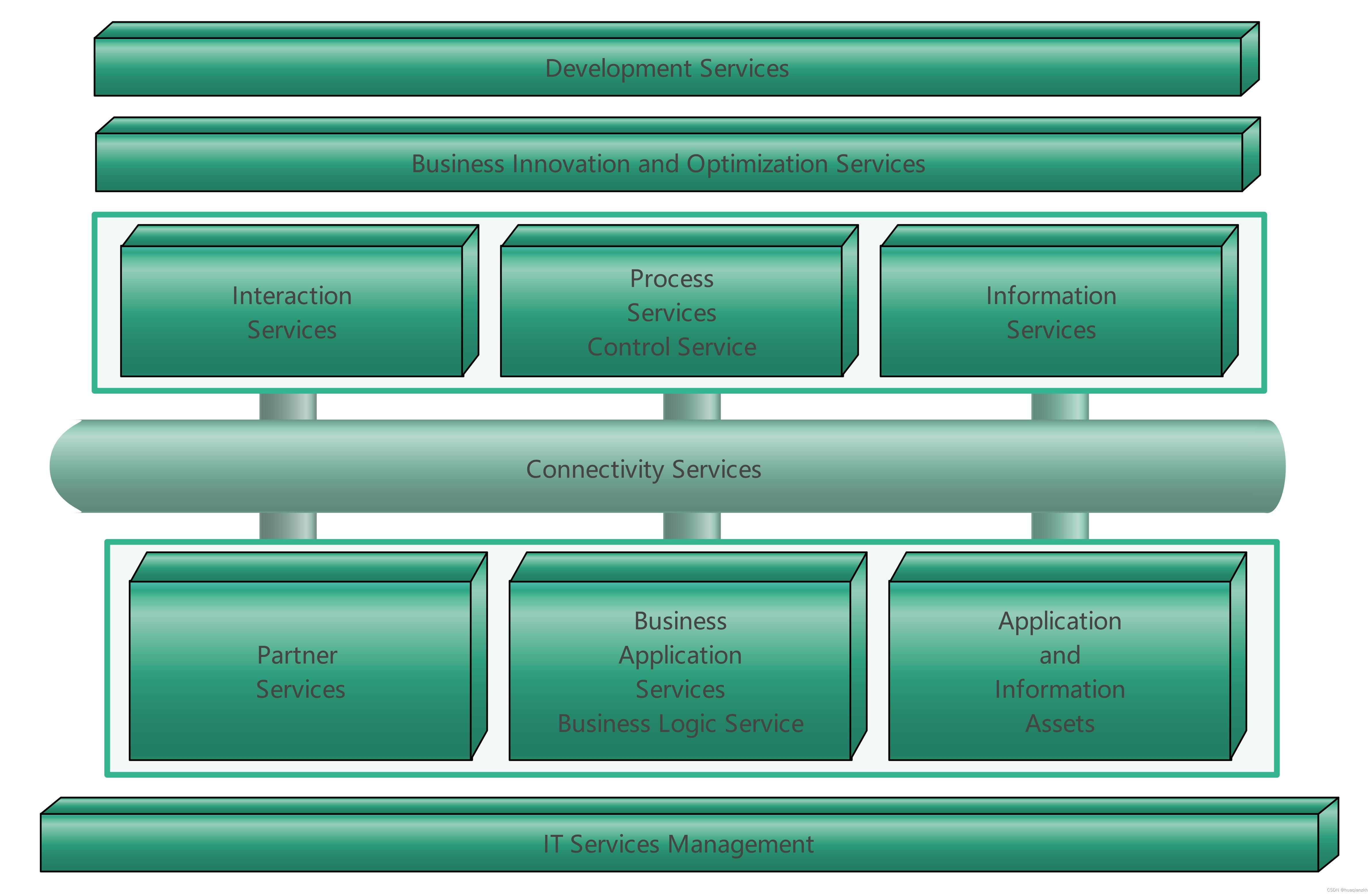
SOA的参考架构
1. 以服务为中心的企业集成架构 IBM的Websphere业务集成参考架构(如图1所示,以下称参考架构)是典型的以服务为中心的企业集成架构。 图1 IBM WebSphere业务集成参考架构 以服务为中心的企业集成采用“关注点分离(Separation of Co…...

前端开发-表单和表格的区别
在前端开发中,表单(Form)和表格(Table)同样具有不同的用途和结构: 前端表单(Form): 数据收集:表单用于收集用户输入的数据,如文本输入、选择选项等。用户交…...

Data Management Controls
Data Browsing and Analysis Data Grid 以标准表格或其他视图格式(例如,带状网格、卡片、瓷砖)显示数据。Vertical Grid 以表格形式显示数据,数据字段显示为行,记录显示为列。Pivot Grid 模拟微软Excel的枢轴表功…...

NextJs 数据篇 - 数据获取 | 缓存 | Server Actions
NextJs 数据篇 - 数据获取 | 缓存 | Server Actions 前言一. 数据获取 fetch1.1 缓存 caching① 服务端组件使用fetch② 路由处理器 GET 请求使用fetch 1.2 重新验证 revalidating① 基于时间的重新验证② 按需重新验证revalidatePathrevalidateTag 1.3 缓存的退出方式 二. Ser…...

腾讯开源人像照片生成视频模型V-Express
网址 https://github.com/tencent-ailab/V-Express 下面是github里的翻译: 在人像视频生成领域,使用单张图像生成人像视频变得越来越普遍。一种常见的方法是利用生成模型来增强受控发电的适配器。 但是,控制信号的强度可能会有所不同&…...
)
pytorch使用DataParallel并行化保存和加载模型(单卡、多卡各种情况讲解)
话不多说,直接进入正题。 !!!不过要注意一点,本文保存模型采用的都是只保存模型参数的情况,而不是保存整个模型的情况。一定要看清楚再用啊! 1 单卡训练,单卡加载 #保存模型 torc…...
PS初级|写在纸上的字怎么抠成透明背景?
前言 上一次咱们讲了很多很多很多的抠图教程,这次继续。。。最近有小伙伴问我:如果是写在纸上的字,要怎么把它抠成透明背景。 这个其实很简单,直接来说就是选择通道来抠。但有一点要注意的是,写在纸上的字࿰…...

Docker面试整理-Docker的网络是如何工作的?
Docker 的网络功能允许容器以多种方式连接到彼此、宿主机以及外部网络。Docker 使用不同的网络驱动来支持这些连接,每种驱动方式都适用于特定的用途。理解 Docker 的网络是如何工作的,可以帮助你更好地设计和管理容器化应用的通信。 Docker 网络驱动 bridge:默认网络驱动。当…...

告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南
告别激活弹窗:KMS_VL_ALL_AIO智能激活工具完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统激活烦恼吗?每次开机都看到"需要激活"的提…...

2026年主流抓娃娃App大对比,哪个才是你的“抓宝神器”?
在当今快节奏的生活中,年轻人面临着来自学业、工作、社交等多方面的压力。为了缓解这些压力,寻找适合的解压方式成为了大家的共同需求。抓娃娃App作为一种新兴的娱乐方式,正逐渐受到年轻人的喜爱。下面我们就从潮流趋势、科技前沿、行业洞察等…...
)
告别内置ADC的烦恼:用ADS1119搞定STM32/DSP的高精度电压采样(附完整代码)
告别内置ADC的烦恼:用ADS1119搞定STM32/DSP的高精度电压采样(附完整代码) 在嵌入式系统开发中,电压采样是基础却至关重要的环节。许多工程师在使用STM32或DSP内置ADC时,常会遇到精度不足、抗干扰能力差、无法测量差分信…...

Kafka Connect集群部署踩坑实录:从单机到高可用的完整配置与监控方案
Kafka Connect生产级部署实战:高可用架构设计与监控体系构建 当数据管道成为企业核心基础设施时,Kafka Connect的稳定性直接关系到业务连续性。去年某电商大促期间,因单点故障导致数据同步延迟6小时的教训仍历历在目——这正是我们需要深入探…...

基于AI智能体的渗透测试框架:从自动化到智能协同的范式转变
1. 项目概述:一个面向渗透测试的智能体框架最近在整理自己的工具链时,发现了一个挺有意思的项目,叫GH05TCREW/pentestagent。乍一看这个名字,你可能会觉得这又是一个“缝合怪”式的自动化渗透工具,把Nmap、SQLmap之类的…...
Translumo:5分钟掌握Windows实时屏幕翻译终极指南
Translumo:5分钟掌握Windows实时屏幕翻译终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外…...

抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播
抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

Arm Cortex-X2/X3架构解析与性能优化实践
1. Arm Cortex-X2/X3集群架构概述在Armv9架构的高性能计算领域,Cortex-X2和X3代表了当前最先进的CPU设计理念。作为DynamIQ共享单元(DSU)的核心组件,它们通过可配置的缓存层次结构和智能一致性协议,为现代异构计算提供了灵活的解决方案。1.1 …...

qmcdump:专业解决QQ音乐加密音频格式兼容性问题
qmcdump:专业解决QQ音乐加密音频格式兼容性问题 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump 在数字音乐时…...

Go语言AI编程助手SDK:提升Cursor代码理解与生成精准度
1. 项目概述:一个为AI编程而生的Go语言SDK如果你是一名Go语言开发者,同时又在深度使用Cursor这样的AI辅助编程工具,那么你很可能已经感受到了一个痛点:如何让AI更精准、更高效地理解你的代码库,并在此基础上进行智能操…...